 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Long-MIL: Scaling Long Contextual Multiple Instance Learning for Histopathology Whole Slide Image Analysis
Nov 21, 2023
Histopathology image analysis is the golden standard of clinical diagnosis for Cancers. In doctors daily routine and computer-aided diagnosis, the Whole Slide Image (WSI) of histopathology tissue is used for analysis. Because of the extremely large scale of resolution, previous methods generally divide the WSI into a large number of patches, then aggregate all patches within a WSI by Multi-Instance Learning (MIL) to make the slide-level prediction when developing computer-aided diagnosis tools. However, most previous WSI-MIL models using global-attention without pairwise interaction and any positional information, or self-attention with absolute position embedding can not well handle shape varying large WSIs, e.g. testing WSIs after model deployment may be larger than training WSIs, since the model development set is always limited due to the difficulty of histopathology WSIs collection. To deal with the problem, in this paper, we propose to amend position embedding for shape varying long-contextual WSI by introducing Linear Bias into Attention, and adapt it from 1-d long sequence into 2-d long-contextual WSI which helps model extrapolate position embedding to unseen or under-fitted positions. We further utilize Flash-Attention module to tackle the computational complexity of Transformer, which also keep full self-attention performance compared to previous attention approximation work. Our method, Long-contextual MIL (Long-MIL) are evaluated on extensive experiments including 4 dataset including WSI classification and survival prediction tasks to validate the superiority on shape varying WSIs. The source code will be open-accessed soon.
Self-Guided Open-Vocabulary Semantic Segmentation
Dec 07, 2023Vision-Language Models (VLMs) have emerged as promising tools for open-ended image understanding tasks, including open vocabulary segmentation. Yet, direct application of such VLMs to segmentation is non-trivial, since VLMs are trained with image-text pairs and naturally lack pixel-level granularity. Recent works have made advancements in bridging this gap, often by leveraging the shared image-text space in which the image and a provided text prompt are represented. In this paper, we challenge the capabilities of VLMs further and tackle open-vocabulary segmentation without the need for any textual input. To this end, we propose a novel Self-Guided Semantic Segmentation (Self-Seg) framework. Self-Seg is capable of automatically detecting relevant class names from clustered BLIP embeddings and using these for accurate semantic segmentation. In addition, we propose an LLM-based Open-Vocabulary Evaluator (LOVE) to effectively assess predicted open-vocabulary class names. We achieve state-of-the-art results on Pascal VOC, ADE20K and CityScapes for open-vocabulary segmentation without given class names, as well as competitive performance with methods where class names are given. All code and data will be released.
Catastrophic Forgetting in Deep Learning: A Comprehensive Taxonomy
Dec 16, 2023Deep Learning models have achieved remarkable performance in tasks such as image classification or generation, often surpassing human accuracy. However, they can struggle to learn new tasks and update their knowledge without access to previous data, leading to a significant loss of accuracy known as Catastrophic Forgetting (CF). This phenomenon was first observed by McCloskey and Cohen in 1989 and remains an active research topic. Incremental learning without forgetting is widely recognized as a crucial aspect in building better AI systems, as it allows models to adapt to new tasks without losing the ability to perform previously learned ones. This article surveys recent studies that tackle CF in modern Deep Learning models that use gradient descent as their learning algorithm. Although several solutions have been proposed, a definitive solution or consensus on assessing CF is yet to be established. The article provides a comprehensive review of recent solutions, proposes a taxonomy to organize them, and identifies research gaps in this area.
Movement Primitive Diffusion: Learning Gentle Robotic Manipulation of Deformable Objects
Dec 15, 2023Policy learning in robot-assisted surgery (RAS) lacks data efficient and versatile methods that exhibit the desired motion quality for delicate surgical interventions. To this end, we introduce Movement Primitive Diffusion (MPD), a novel method for imitation learning (IL) in RAS that focuses on gentle manipulation of deformable objects. The approach combines the versatility of diffusion-based imitation learning (DIL) with the high-quality motion generation capabilities of Probabilistic Dynamic Movement Primitives (ProDMPs). This combination enables MPD to achieve gentle manipulation of deformable objects, while maintaining data efficiency critical for RAS applications where demonstration data is scarce. We evaluate MPD across various simulated tasks and a real world robotic setup on both state and image observations. MPD outperforms state-of-the-art DIL methods in success rate, motion quality, and data efficiency.
Optimized Deep Learning Models for AUV Seabed Image Analysis
Nov 17, 2023Using autonomous underwater vehicles, or AUVs, has completely changed how we gather data from the ocean floor. AUV innovation has advanced significantly, especially in the analysis of images, due to the increasing need for accurate and efficient seafloor mapping. This blog post provides a detailed summary and comparison of the most current advancements in AUV seafloor image processing. We will go into the realm of undersea technology, covering everything through computer and algorithmic advancements to advances in sensors and cameras. After reading this page through to the end, you will have a solid understanding of the most up-to-date techniques and tools for using AUVs to process seabed photos and how they could further our comprehension of the ocean floor
Universal Incomplete-View CT Reconstruction with Prompted Contextual Transformer
Dec 13, 2023Despite the reduced radiation dose, suitability for objects with physical constraints, and accelerated scanning procedure, incomplete-view computed tomography (CT) images suffer from severe artifacts, hampering their value for clinical diagnosis. The incomplete-view CT can be divided into two scenarios depending on the sampling of projection, sparse-view CT and limited-angle CT, each encompassing various settings for different clinical requirements. Existing methods tackle with these settings separately and individually due to their significantly different artifact patterns; this, however, gives rise to high computational and storage costs, hindering its flexible adaptation to new settings. To address this challenge, we present the first-of-its-kind all-in-one incomplete-view CT reconstruction model with PROmpted Contextual Transformer, termed ProCT. More specifically, we first devise the projection view-aware prompting to provide setting-discriminative information, enabling a single model to handle diverse incomplete-view CT settings. Then, we propose artifact-aware contextual learning to provide the contextual guidance of image pairs from either CT phantom or publicly available datasets, making ProCT capable of accurately removing the complex artifacts from the incomplete-view CT images. Extensive experiments demonstrate that ProCT can achieve superior performance on a wide range of incomplete-view CT settings using a single model. Remarkably, our model with only image-domain information surpasses the state-of-the-art dual-domain methods that require the access to raw data. The code is available at: https://github.com/Masaaki-75/proct
A Foundational Multimodal Vision Language AI Assistant for Human Pathology
Dec 13, 2023The field of computational pathology has witnessed remarkable progress in the development of both task-specific predictive models and task-agnostic self-supervised vision encoders. However, despite the explosive growth of generative artificial intelligence (AI), there has been limited study on building general purpose, multimodal AI assistants tailored to pathology. Here we present PathChat, a vision-language generalist AI assistant for human pathology using an in-house developed foundational vision encoder pretrained on 100 million histology images from over 100,000 patient cases and 1.18 million pathology image-caption pairs. The vision encoder is then combined with a pretrained large language model and the whole system is finetuned on over 250,000 diverse disease agnostic visual language instructions. We compare PathChat against several multimodal vision language AI assistants as well as GPT4V, which powers the commercially available multimodal general purpose AI assistant ChatGPT-4. When relevant clinical context is provided with the histology image, PathChat achieved a diagnostic accuracy of 87% on multiple-choice questions based on publicly available cases of diverse tissue origins and disease models. Additionally, using open-ended questions and human expert evaluation, we found that overall PathChat produced more accurate and pathologist-preferable responses to diverse queries related to pathology. As an interactive and general vision language AI assistant that can flexibly handle both visual and natural language inputs, PathChat can potentially find impactful applications in pathology education, research, and human-in-the-loop clinical decision making.
Do LLMs Work on Charts? Designing Few-Shot Prompts for Chart Question Answering and Summarization
Dec 17, 2023A number of tasks have been proposed recently to facilitate easy access to charts such as chart QA and summarization. The dominant paradigm to solve these tasks has been to fine-tune a pretrained model on the task data. However, this approach is not only expensive but also not generalizable to unseen tasks. On the other hand, large language models (LLMs) have shown impressive generalization capabilities to unseen tasks with zero- or few-shot prompting. However, their application to chart-related tasks is not trivial as these tasks typically involve considering not only the underlying data but also the visual features in the chart image. We propose PromptChart, a multimodal few-shot prompting framework with LLMs for chart-related applications. By analyzing the tasks carefully, we have come up with a set of prompting guidelines for each task to elicit the best few-shot performance from LLMs. We further propose a strategy to inject visual information into the prompts. Our experiments on three different chart-related information consumption tasks show that with properly designed prompts LLMs can excel on the benchmarks, achieving state-of-the-art.
Latent Space Editing in Transformer-Based Flow Matching
Dec 17, 2023This paper strives for image editing via generative models. Flow Matching is an emerging generative modeling technique that offers the advantage of simple and efficient training. Simultaneously, a new transformer-based U-ViT has recently been proposed to replace the commonly used UNet for better scalability and performance in generative modeling. Hence, Flow Matching with a transformer backbone offers the potential for scalable and high-quality generative modeling, but their latent structure and editing ability are as of yet unknown. Hence, we adopt this setting and explore how to edit images through latent space manipulation. We introduce an editing space, which we call $u$-space, that can be manipulated in a controllable, accumulative, and composable manner. Additionally, we propose a tailored sampling solution to enable sampling with the more efficient adaptive step-size ODE solvers. Lastly, we put forth a straightforward yet powerful method for achieving fine-grained and nuanced editing using text prompts. Our framework is simple and efficient, all while being highly effective at editing images while preserving the essence of the original content. Our code will be publicly available at https://taohu.me/lfm/
Diffusion Handles: Enabling 3D Edits for Diffusion Models by Lifting Activations to 3D
Dec 06, 2023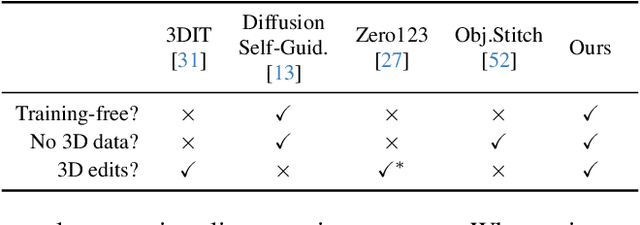


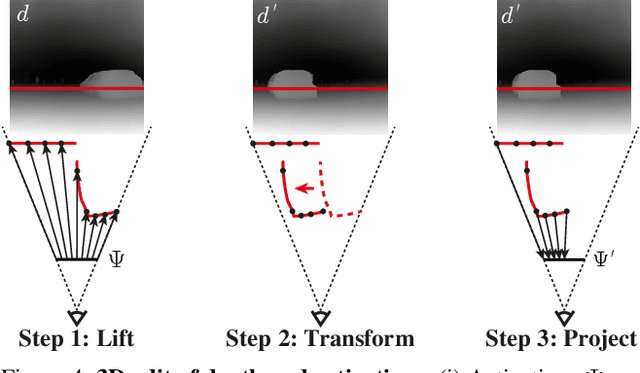
Diffusion Handles is a novel approach to enabling 3D object edits on diffusion images. We accomplish these edits using existing pre-trained diffusion models, and 2D image depth estimation, without any fine-tuning or 3D object retrieval. The edited results remain plausible, photo-real, and preserve object identity. Diffusion Handles address a critically missing facet of generative image based creative design, and significantly advance the state-of-the-art in generative image editing. Our key insight is to lift diffusion activations for an object to 3D using a proxy depth, 3D-transform the depth and associated activations, and project them back to image space. The diffusion process applied to the manipulated activations with identity control, produces plausible edited images showing complex 3D occlusion and lighting effects. We evaluate Diffusion Handles: quantitatively, on a large synthetic data benchmark; and qualitatively by a user study, showing our output to be more plausible, and better than prior art at both, 3D editing and identity control. Project Webpage: https://diffusionhandles.github.io/