 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Review of methods for Textureless Object Recognition
Oct 31, 2019
Textureless object recognition has become a significant task in Computer Vision with the advent of Robotics and its applications in manufacturing sector. It has been very challenging to get good performance because of its lack of discriminative features and reflectance properties. Hence, the approaches used for textured objects cannot be applied for textureless objects. A lot of work has been done in the last 20 years, especially in the recent 5 years after the TLess and other textureless dataset were introduced. In our research, we plan to combine image processing techniques (for feature enhancement) along with deep learning techniques (for object recognition). Here we present an overview of the various existing work in the field of textureless object recognition, which can be broadly classified into View-based, Feature-based and Shape-based. We have also added a review of few of the research papers submitted at the International Conference on Smart Multimedia, 2018. Index terms: Computer Vision, Textureless object detection, Textureless object recognition, Feature-based, Edge detection, Deep Learning
Distilling Pixel-Wise Feature Similarities for Semantic Segmentation
Oct 31, 2019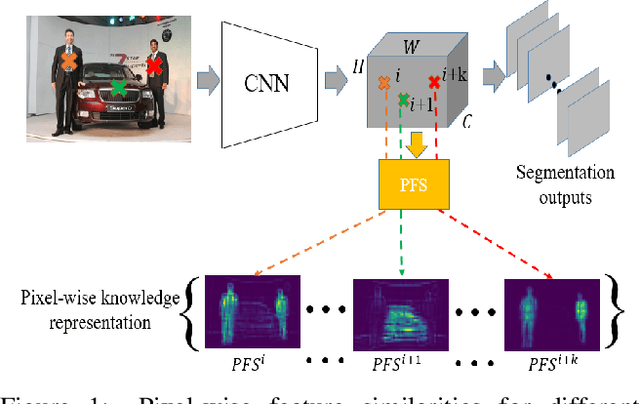

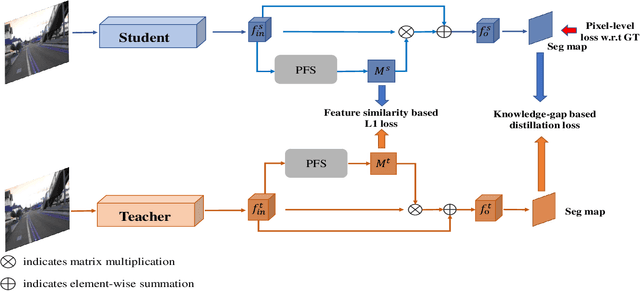
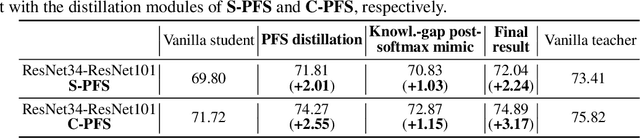
Among the neural network compression techniques, knowledge distillation is an effective one which forces a simpler student network to mimic the output of a larger teacher network. However, most of such model distillation methods focus on the image-level classification task. Directly adapting these methods to the task of semantic segmentation only brings marginal improvements. In this paper, we propose a simple, yet effective knowledge representation referred to as pixel-wise feature similarities (PFS) to tackle the challenging distillation problem of semantic segmentation. The developed PFS encodes spatial structural information for each pixel location of the high-level convolutional features, which helps guide the distillation process in an easier way. Furthermore, a novel weighted pixel-level soft prediction imitation approach is proposed to enable the student network to selectively mimic the teacher network's output, according to their pixel-wise knowledge-gaps. Extensive experiments are conducted on the challenging datasets of Pascal VOC 2012, ADE20K and Pascal Context. Our approach brings significant performance improvements compared to several strong baselines and achieves new state-of-the-art results.
AdversarialNAS: Adversarial Neural Architecture Search for GANs
Dec 04, 2019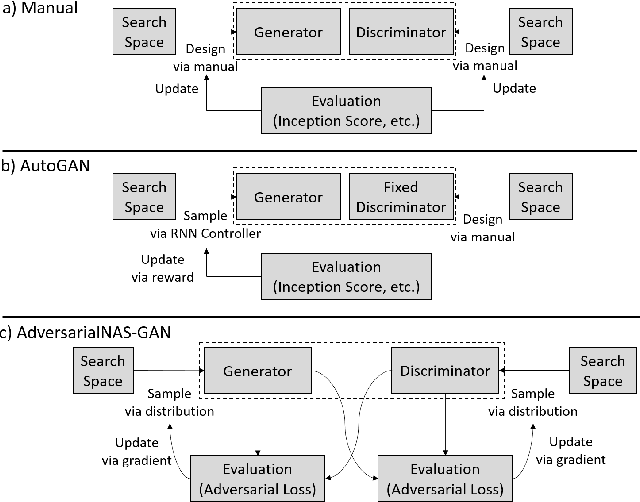
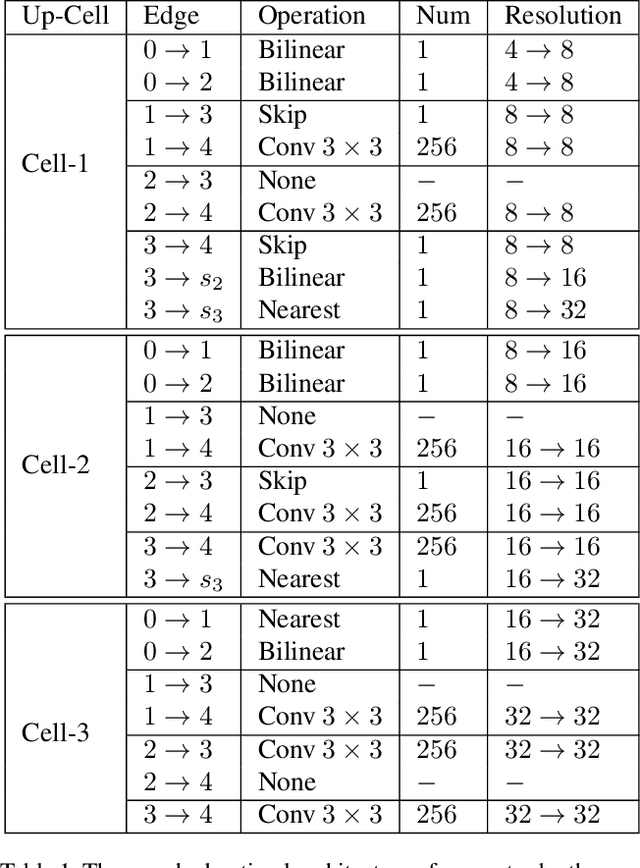
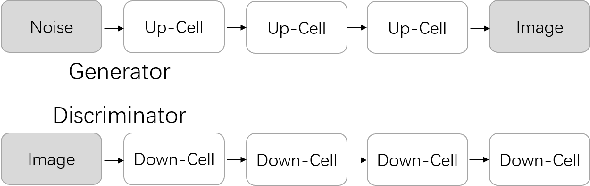
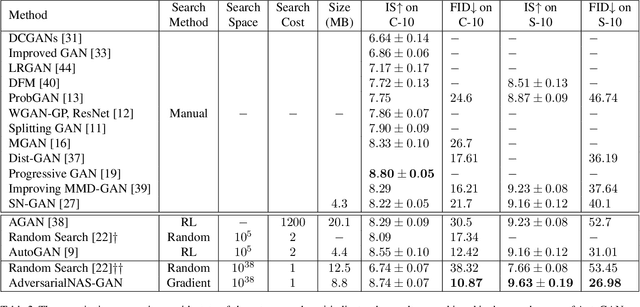
Neural Architecture Search (NAS) that aims to automate the procedure of architecture design has achieved promising results in many computer vision fields. In this paper, we propose an AdversarialNAS method specially tailored for Generative Adversarial Networks (GANs) to search for a superior generative model on the task of unconditional image generation. The proposed method leverages an adversarial searching mechanism to search for the architectures of generator and discriminator simultaneously in a differentiable manner. Therefore, the searching algorithm considers the relevance and balance between the two networks leading to search for a superior generative model. Besides, AdversarialNAS does not need any extra evaluation metric to evaluate the performance of the architecture in each searching iteration, which is very efficient and can take only 1 GPU day to search for an optimal network architecture in a large search space ($10^{38}$). Experiments demonstrate the effectiveness and superiority of our method. The discovered generative model sets a new state-of-the-art FID score of $10.87$ and highly competitive Inception Score of $8.74$ on CIFAR-10. Its transferability is also proven by setting new state-of-the-art FID score of $26.98$ and Inception score of $9.63$ on STL-10. Our code will be released to facilitate the related academic and industrial study.
Quantum-Inspired Hamiltonian Monte Carlo for Bayesian Sampling
Dec 04, 2019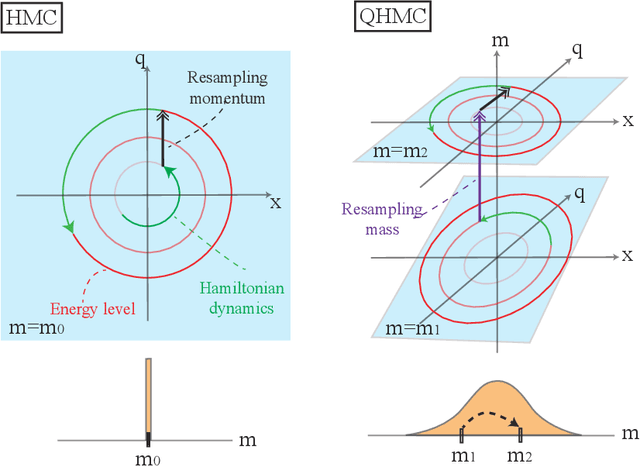
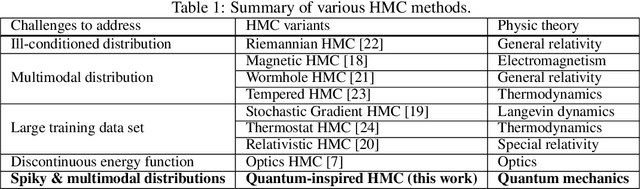
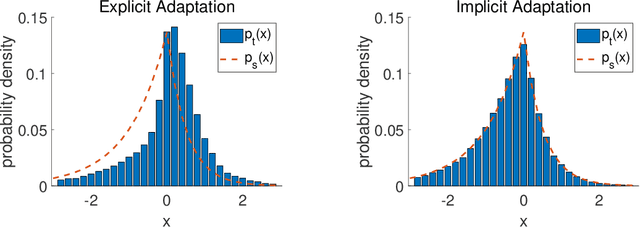
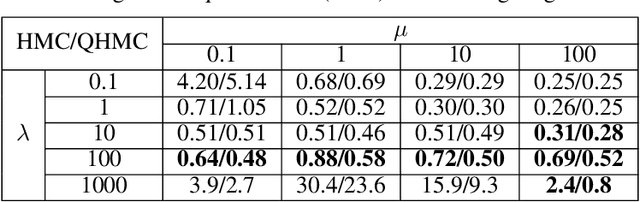
Hamiltonian Monte Carlo (HMC) is an efficient Bayesian sampling method that can make distant proposals in the parameter space by simulating a Hamiltonian dynamical system. Despite its popularity in machine learning and data science, HMC is inefficient to sample from spiky and multimodal distributions. Motivated by the energy-time uncertainty relation from quantum mechanics, we propose a Quantum-Inspired Hamiltonian Monte Carlo algorithm (QHMC). This algorithm allows a particle to have a random mass with a probability distribution rather than a fixed mass. We prove the convergence property of QHMC in the spatial domain and in the time sequence. We further show why such a random mass can improve the performance when we sample a broad class of distributions. In order to handle the big training data sets in large-scale machine learning, we develop a stochastic gradient version of QHMC using Nos\'e-Hoover thermostat called QSGNHT, and we also provide theoretical justifications about its steady-state distributions. Finally in the experiments, we demonstrate the effectiveness of QHMC and QSGNHT on synthetic examples, bridge regression, image denoising and neural network pruning. The proposed QHMC and QSGNHT can indeed achieve much more stable and accurate sampling results on the test cases.
So2Sat LCZ42: A Benchmark Dataset for Global Local Climate Zones Classification
Dec 19, 2019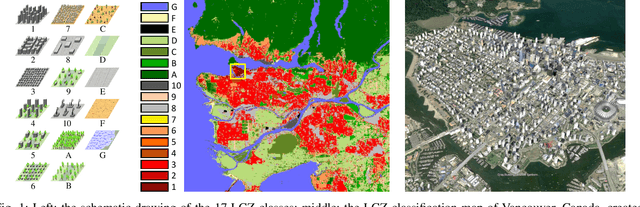
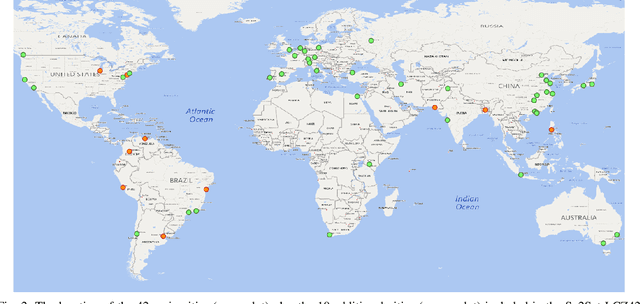

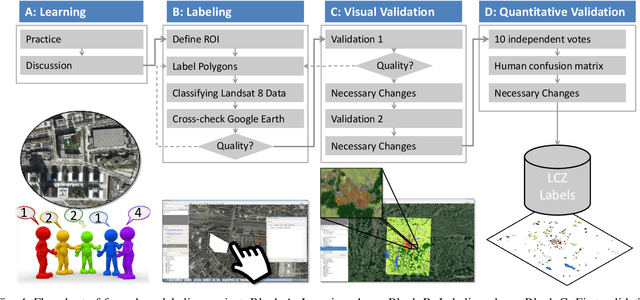
Access to labeled reference data is one of the grand challenges in supervised machine learning endeavors. This is especially true for an automated analysis of remote sensing images on a global scale, which enables us to address global challenges such as urbanization and climate change using state-of-the-art machine learning techniques. To meet these pressing needs, especially in urban research, we provide open access to a valuable benchmark dataset named "So2Sat LCZ42," which consists of local climate zone (LCZ) labels of about half a million Sentinel-1 and Sentinel-2 image patches in 42 urban agglomerations (plus 10 additional smaller areas) across the globe. This dataset was labeled by 15 domain experts following a carefully designed labeling work flow and evaluation process over a period of six months. As rarely done in other labeled remote sensing dataset, we conducted rigorous quality assessment by domain experts. The dataset achieved an overall confidence of 85%. We believe this LCZ dataset is a first step towards an unbiased globallydistributed dataset for urban growth monitoring using machine learning methods, because LCZ provide a rather objective measure other than many other semantic land use and land cover classifications. It provides measures of the morphology, compactness, and height of urban areas, which are less dependent on human and culture. This dataset can be accessed from http://doi.org/10.14459/2018mp1483140.
Off-the-grid model based deep learning (O-MODL)
Dec 27, 2018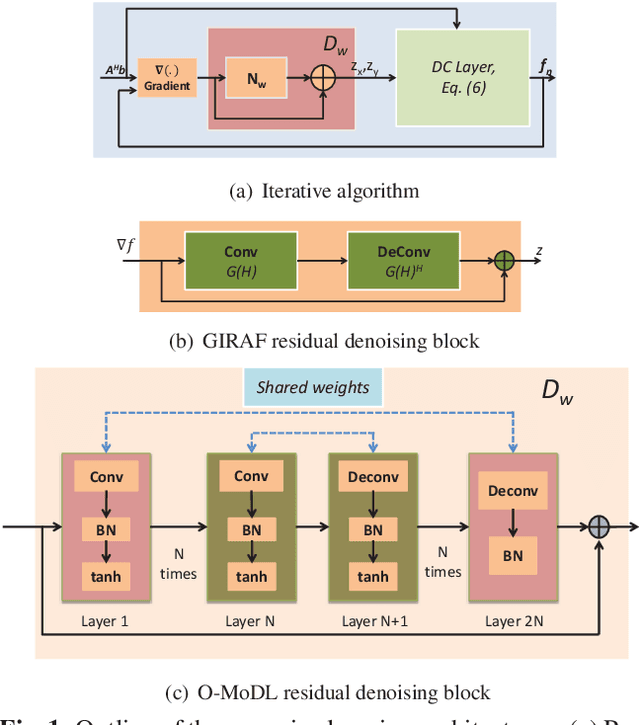
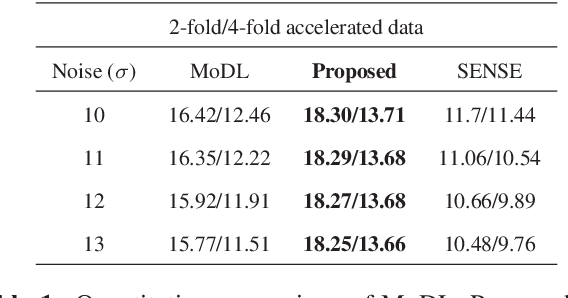
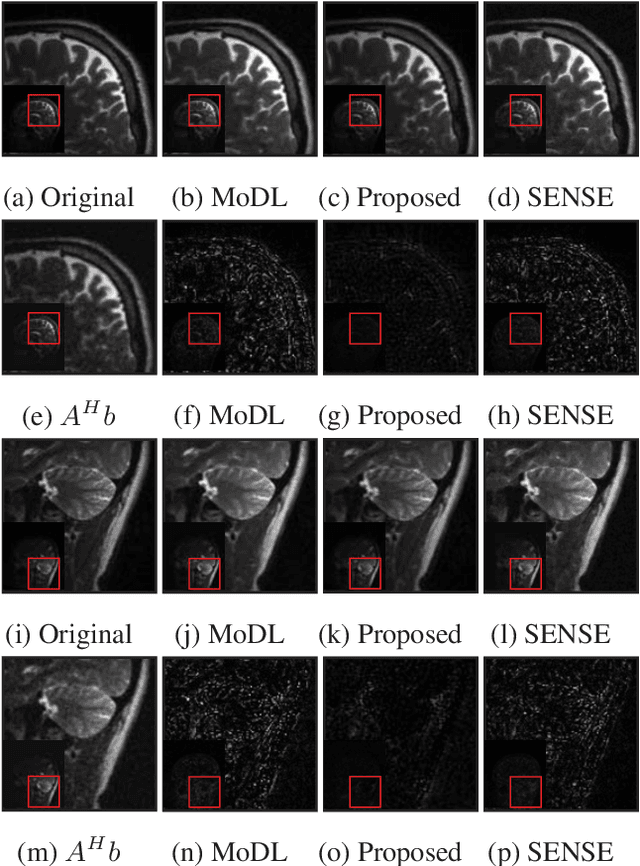
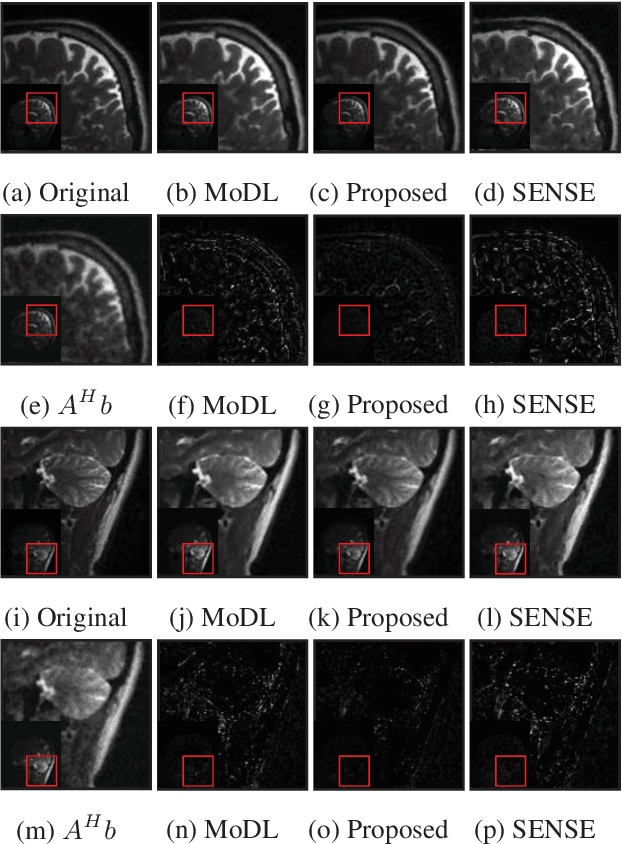
We introduce a model based off-the-grid image reconstruction algorithm using deep learned priors. The main difference of the proposed scheme with current deep learning strategies is the learning of non-linear annihilation relations in Fourier space. We rely on a model based framework, which allows us to use a significantly smaller deep network, compared to direct approaches that also learn how to invert the forward model. Preliminary comparisons against image domain MoDL approach demonstrates the potential of the off-the-grid formulation. The main benefit of the proposed scheme compared to structured low-rank methods is the quite significant reduction in computational complexity.
Pixel-aware Deep Function-mixture Network for Spectral Super-Resolution
Mar 24, 2019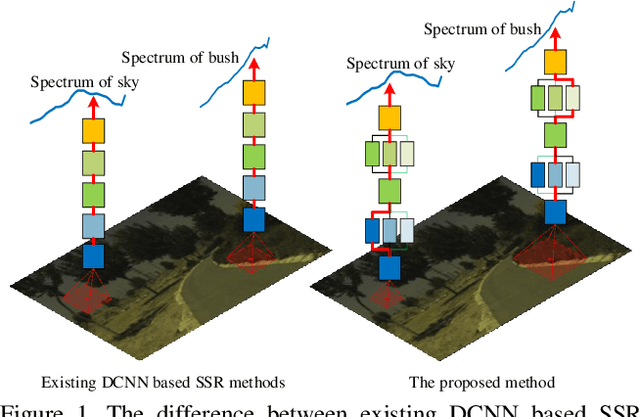
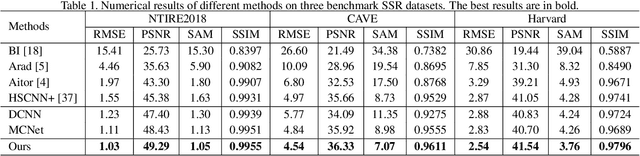
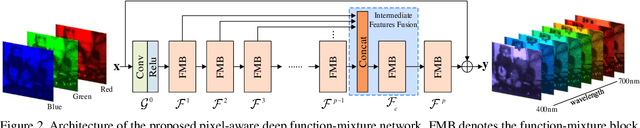
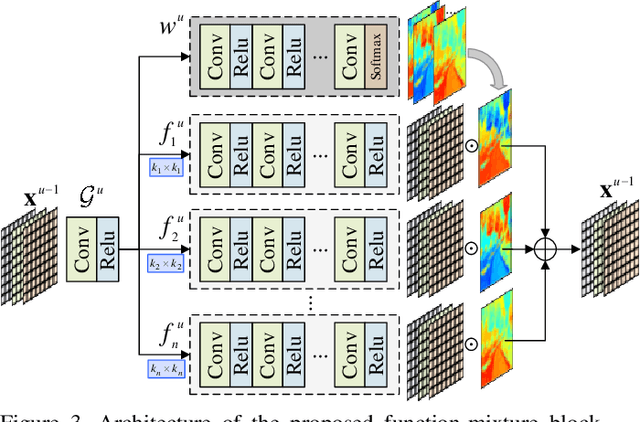
Spectral super-resolution (SSR) aims at generating a hyperspectral image (HSI) from a given RGB image. Recently, a promising direction for SSR is to learn a complicated mapping function from the RGB image to the HSI counterpart using a deep convolutional neural network. This essentially involves mapping the RGB context within a size-specific receptive field centered at each pixel to its spectrum in the HSI. The focus thereon is to appropriately determine the receptive field size and establish the mapping function from RGB context to the corresponding spectrum. Due to their differences in category or spatial position, pixels in HSIs often require different-sized receptive fields and distinct mapping functions. However, few efforts have been invested to explicitly exploit this prior. To address this problem, we propose a pixel-aware deep function-mixture network for SSR, which is composed of a new class of modules, termed function-mixture (FM) blocks. Each FM block is equipped with some basis functions, i.e., parallel subnets of different-sized receptive fields. Besides, it incorporates an extra subnet as a mixing function to generate pixel-wise weights, and then linearly mixes the outputs of all basis functions with those generated weights. This enables us to pixel-wisely determine the receptive field size and the mapping function. Moreover, we stack several such FM blocks to further increase the flexibility of the network in learning the pixel-wise mapping. To encourage feature reuse, intermediate features generated by the FM blocks are fused in late stage, which proves to be effective for boosting the SSR performance. Experimental results on three benchmark HSI datasets demonstrate the superiority of the proposed method.
Unsupervised automatic classification of Scanning Electron Microscopy (SEM) images of CD4+ cells with varying extent of HIV virion infection
Apr 30, 2019
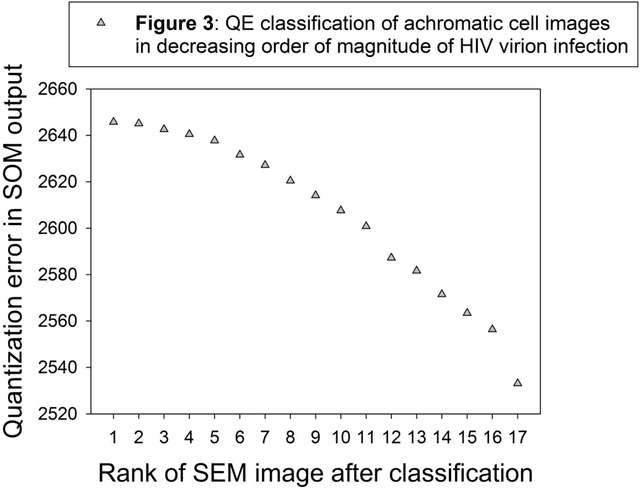
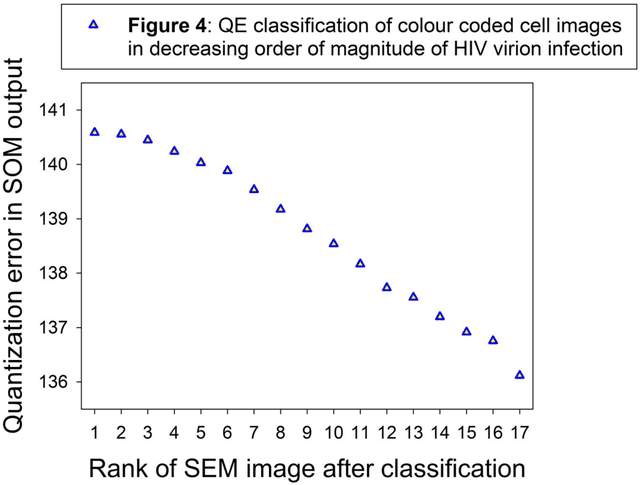
Archiving large sets of medical or cell images in digital libraries may require ordering randomly scattered sets of image data according to specific criteria, such as the spatial extent of a specific local color or contrast content that reveals different meaningful states of a physiological structure, tissue, or cell in a certain order, indicating progression or recession of a pathology, or the progressive response of a cell structure to treatment. Here we used a Self Organized Map (SOM)-based, fully automatic and unsupervised, classification procedure described in our earlier work and applied it to sets of minimally processed grayscale and/or color processed Scanning Electron Microscopy (SEM) images of CD4+ T-lymphocytes (so-called helper cells) with varying extent of HIV virion infection. It is shown that the quantization error in the SOM output after training permits to scale the spatial magnitude and the direction of change (+ or -) in local pixel contrast or color across images of a series with a reliability that exceeds that of any human expert. The procedure is easily implemented and fast, and represents a promising step towards low-cost automatic digital image archiving with minimal intervention of a human operator.
AANet: Attribute Attention Network for Person Re-Identifications
Dec 19, 2019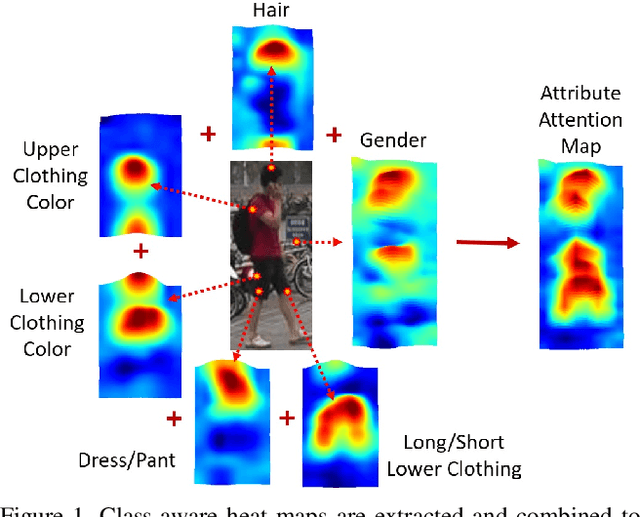
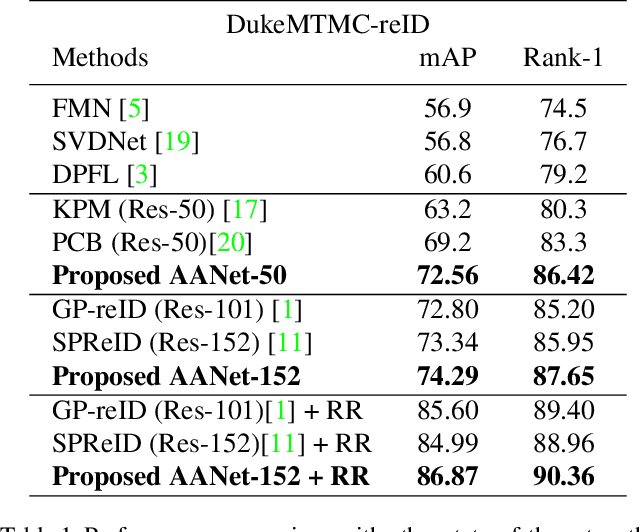

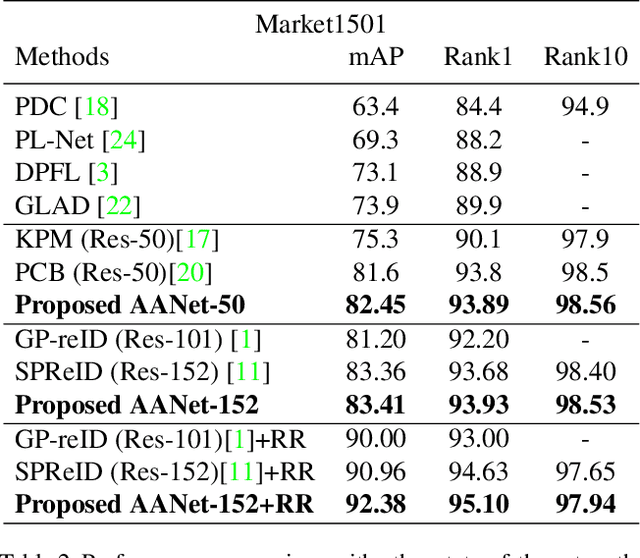
This paper proposes Attribute Attention Network (AANet), a new architecture that integrates person attributes and attribute attention maps into a classification framework to solve the person re-identification (re-ID) problem. Many person re-ID models typically employ semantic cues such as body parts or human pose to improve the re-ID performance. Attribute information, however, is often not utilized. The proposed AANet leverages on a baseline model that uses body parts and integrates the key attribute information in an unified learning framework. The AANet consists of a global person ID task, a part detection task and a crucial attribute detection task. By estimating the class responses of individual attributes and combining them to form the attribute attention map (AAM), a very strong discriminatory representation is constructed. The proposed AANet outperforms the best state-of-the-art method arXiv:1711.09349v3 [cs.CV] using ResNet-50 by 3.36% in mAP and 3.12% in Rank-1 accuracy on DukeMTMC-reID dataset. On Market1501 dataset, AANet achieves 92.38% mAP and 95.10% Rank-1 accuracy with re-ranking, outperforming arXiv:1804.00216v1 [cs.CV], another state of the art method using ResNet-152, by 1.42% in mAP and 0.47% in Rank-1 accuracy. In addition, AANet can perform person attribute prediction (e.g., gender, hair length, clothing length etc.), and localize the attributes in the query image.
CT-To-MR Conditional Generative Adversarial Networks for Ischemic Stroke Lesion Segmentation
Apr 30, 2019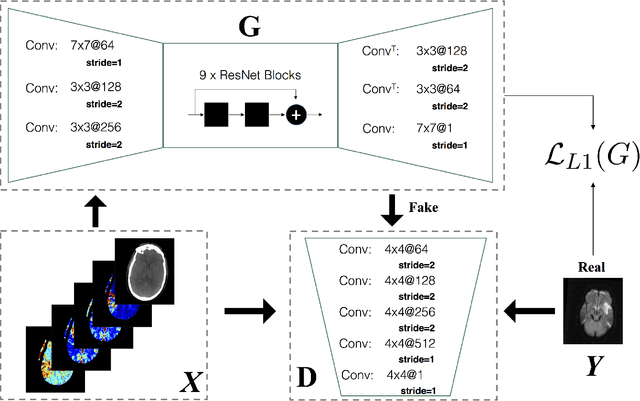
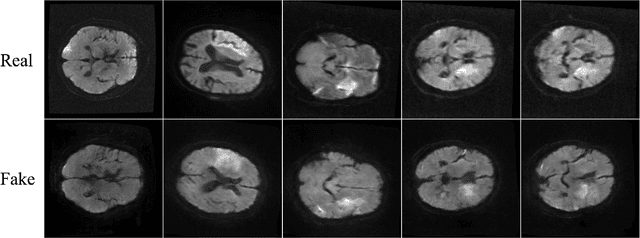

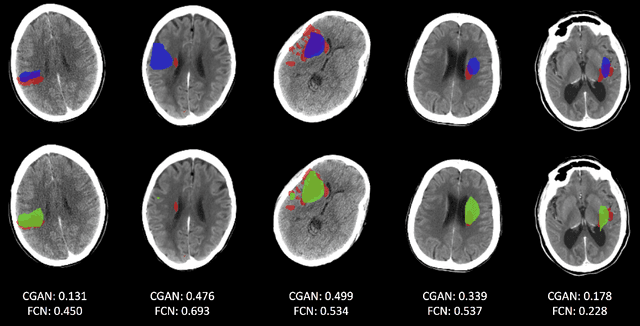
Infarcted brain tissue resulting from acute stroke readily shows up as hyperintense regions within diffusion-weighted magnetic resonance imaging (DWI). It has also been proposed that computed tomography perfusion (CTP) could alternatively be used to triage stroke patients, given improvements in speed and availability, as well as reduced cost. However, CTP has a lower signal to noise ratio compared to MR. In this work, we investigate whether a conditional mapping can be learned by a generative adversarial network to map CTP inputs to generated MR DWI that more clearly delineates hyperintense regions due to ischemic stroke. We detail the architectures of the generator and discriminator and describe the training process used to perform image-to-image translation from multi-modal CT perfusion maps to diffusion weighted MR outputs. We evaluate the results both qualitatively by visual comparison of generated MR to ground truth, as well as quantitatively by training fully convolutional neural networks that make use of generated MR data inputs to perform ischemic stroke lesion segmentation. Segmentation networks trained using generated CT-to-MR inputs result in at least some improvement on all metrics used for evaluation, compared with networks that only use CT perfusion input.