 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hybrid Kronecker Product Decomposition and Approximation
Dec 06, 2019
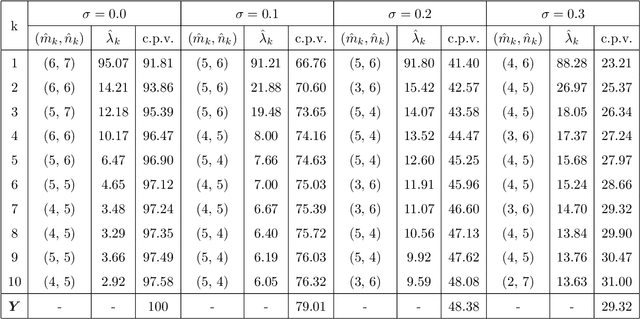

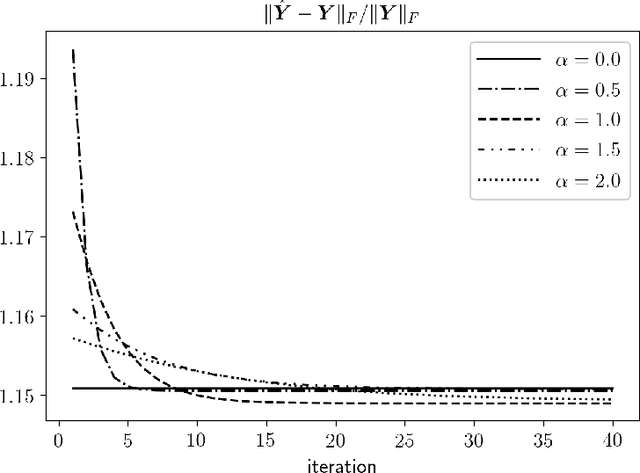
Discovering the underlying low dimensional structure of high dimensional data has attracted a significant amount of researches recently and has shown to have a wide range of applications. As an effective dimension reduction tool, singular value decomposition is often used to analyze high dimensional matrices, which are traditionally assumed to have a low rank matrix approximation. In this paper, we propose a new approach. We assume a high dimensional matrix can be approximated by a sum of a small number of Kronecker products of matrices with potentially different configurations, named as a hybird Kronecker outer Product Approximation (hKoPA). It provides an extremely flexible way of dimension reduction compared to the low-rank matrix approximation. Challenges arise in estimating a hKoPA when the configurations of component Kronecker products are different or unknown. We propose an estimation procedure when the set of configurations are given and a joint configuration determination and component estimation procedure when the configurations are unknown. Specifically, a least squares backfitting algorithm is used when the configuration is given. When the configuration is unknown, an iterative greedy algorithm is used. Both simulation and real image examples show that the proposed algorithms have promising performances. The hybrid Kronecker product approximation may have potentially wider applications in low dimensional representation of high dimensional data
Black-box Adversarial Attacks on Video Recognition Models
Apr 10, 2019
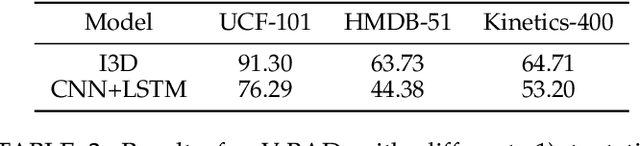
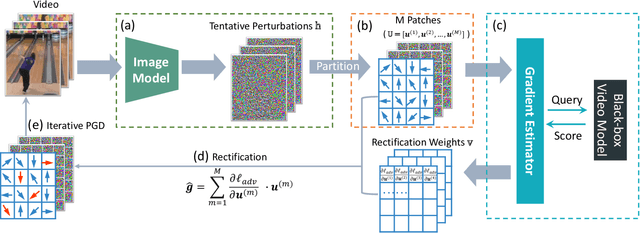

Deep neural networks (DNNs) are known for their vulnerability to adversarial examples. These are examples that have undergone a small, carefully crafted perturbation, and which can easily fool a DNN into making misclassifications at test time. Thus far, the field of adversarial research has mainly focused on image models, under either a white-box setting, where an adversary has full access to model parameters, or a black-box setting where an adversary can only query the target model for probabilities or labels. Whilst several white-box attacks have been proposed for video models, black-box video attacks are still unexplored. To close this gap, we propose the first black-box video attack framework, called V-BAD. V-BAD is a general framework for adversarial gradient estimation and rectification, based on Natural Evolution Strategies (NES). In particular, V-BAD utilizes \textit{tentative perturbations} transferred from image models, and \textit{partition-based rectifications} found by the NES on partitions (patches) of tentative perturbations, to obtain good adversarial gradient estimates with fewer queries to the target model. V-BAD is equivalent to estimating the projection of an adversarial gradient on a selected subspace. Using three benchmark video datasets, we demonstrate that V-BAD can craft both untargeted and targeted attacks to fool two state-of-the-art deep video recognition models. For the targeted attack, it achieves $>$93\% success rate using only an average of $3.4 \sim 8.4 \times 10^4$ queries, a similar number of queries to state-of-the-art black-box image attacks. This is despite the fact that videos often have two orders of magnitude higher dimensionality than static images. We believe that V-BAD is a promising new tool to evaluate and improve the robustness of video recognition models to black-box adversarial attacks.
HSI based colour image equalization using iterative nth root and nth power
Dec 31, 2014
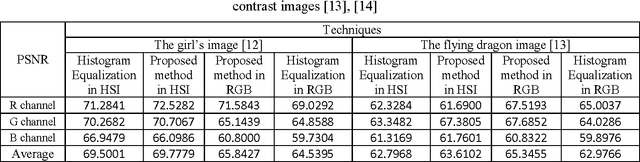
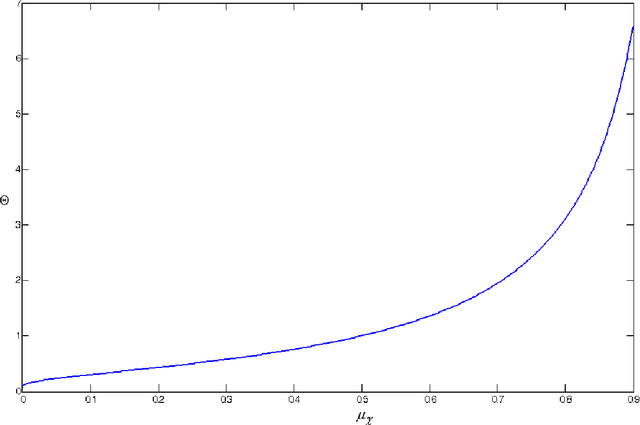
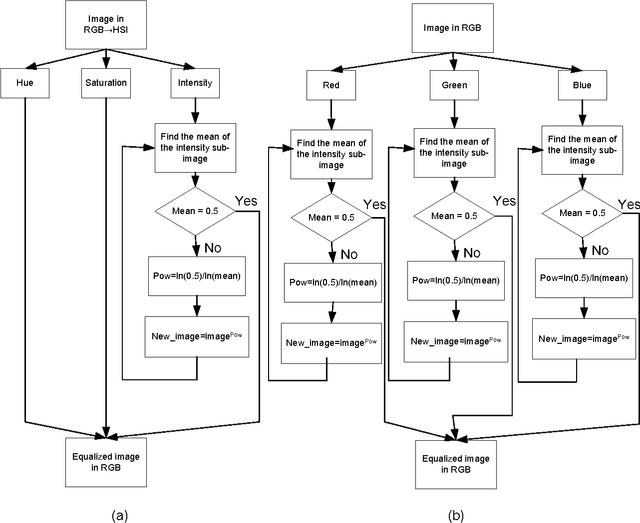
In this paper an equalization technique for colour images is introduced. The method is based on nth root and nth power equalization approach but with optimization of the mean of the image in different colour channels such as RGB and HSI. The performance of the proposed method has been measured by the means of peak signal to noise ratio. The proposed algorithm has been compared with conventional histogram equalization and the visual and quantitative experimental results are showing that the proposed method over perform the histogram equalization.
SeFM: A Sequential Feature Point Matching Algorithm for Object 3D Reconstruction
Dec 07, 2018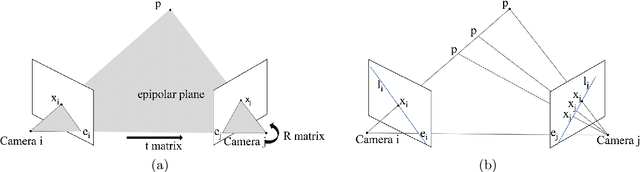
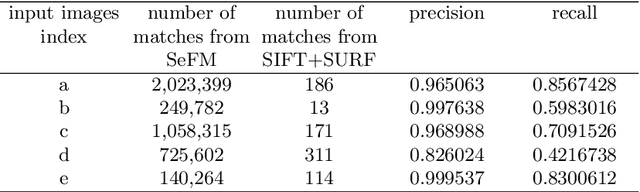
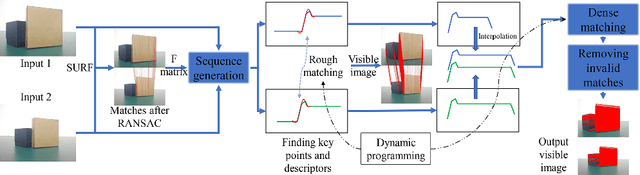
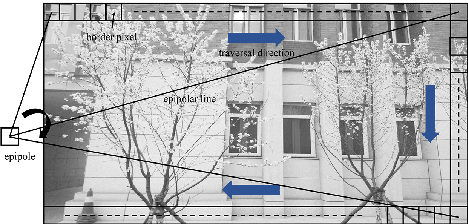
3D reconstruction is a fundamental issue in many applications and the feature point matching problem is a key step while reconstructing target objects. Conventional algorithms can only find a small number of feature points from two images which is quite insufficient for reconstruction. To overcome this problem, we propose SeFM a sequential feature point matching algorithm. We first utilize the epipolar geometry to find the epipole of each image. Rotating along the epipole, we generate a set of the epipolar lines and reserve those intersecting with the input image. Next, a rough matching phase, followed by a dense matching phase, is applied to find the matching dot-pairs using dynamic programming. Furthermore, we also remove wrong matching dot-pairs by calculating the validity. Experimental results illustrate that SeFM can achieve around 1,000 to 10,000 times matching dot-pairs, depending on individual image, compared to conventional algorithms and the object reconstruction with only two images is semantically visible. Moreover, it outperforms conventional algorithms, such as SIFT and SURF, regarding precision and recall.
Detecting Repeating Objects using Patch Correlation Analysis
Apr 11, 2019



In this paper we describe a new method for detecting and counting a repeating object in an image. While the method relies on a fairly sophisticated deformable part model, unlike existing techniques it estimates the model parameters in an unsupervised fashion thus alleviating the need for a user-annotated training data and avoiding the associated specificity. This automatic fitting process is carried out by exploiting the recurrence of small image patches associated with the repeating object and analyzing their spatial correlation. The analysis allows us to reject outlier patches, recover the visual and shape parameters of the part model, and detect the object instances efficiently. In order to achieve a practical system which is able to cope with diverse images, we describe a simple and intuitive active-learning procedure that updates the object classification by querying the user on very few carefully chosen marginal classifications. Evaluation of the new method against the state-of-the-art techniques demonstrates its ability to achieve higher accuracy through a better user experience.
Compare More Nuanced:Pairwise Alignment Bilinear Network For Few-shot Fine-grained Learning
Apr 11, 2019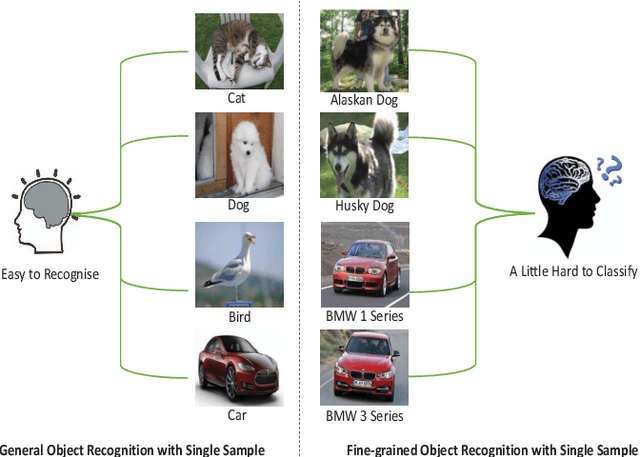
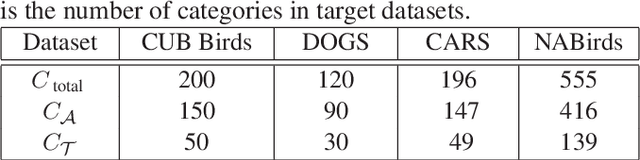
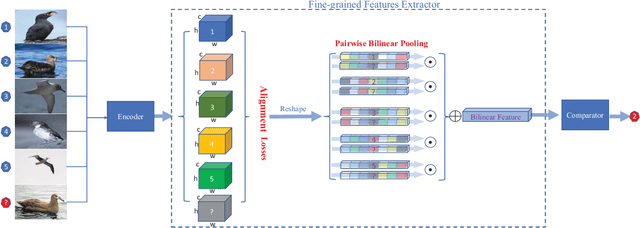
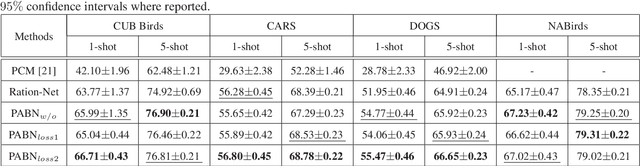
The recognition ability of human beings is developed in a progressive way. Usually, children learn to discriminate various objects from coarse to fine-grained with limited supervision. Inspired by this learning process, we propose a simple yet effective model for the Few-Shot Fine-Grained (FSFG) recognition, which tries to tackle the challenging fine-grained recognition task using meta-learning. The proposed method, named Pairwise Alignment Bilinear Network (PABN), is an end-to-end deep neural network. Unlike traditional deep bilinear networks for fine-grained classification, which adopt the self-bilinear pooling to capture the subtle features of images, the proposed model uses a novel pairwise bilinear pooling to compare the nuanced differences between base images and query images for learning a deep distance metric. In order to match base image features with query image features, we design feature alignment losses before the proposed pairwise bilinear pooling. Experiment results on four fine-grained classification datasets and one generic few-shot dataset demonstrate that the proposed model outperforms both the state-ofthe-art few-shot fine-grained and general few-shot methods.
Identity-Free Facial Expression Recognition using conditional Generative Adversarial Network
Mar 19, 2019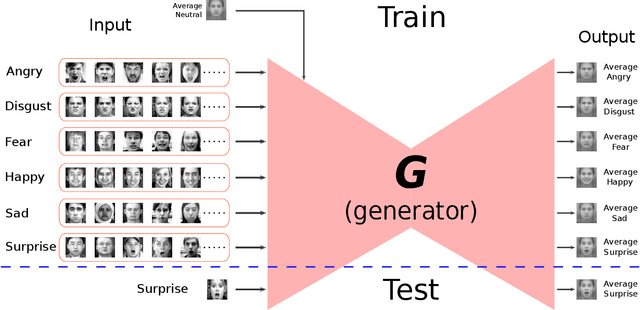
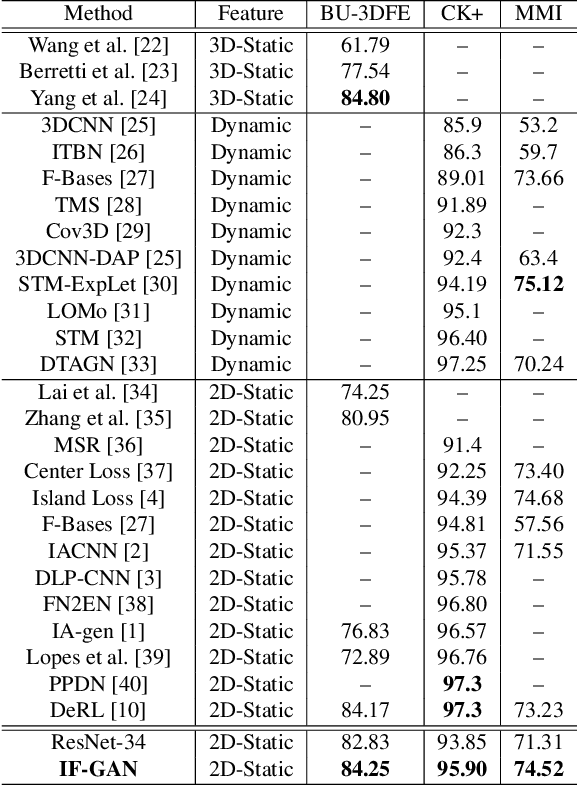
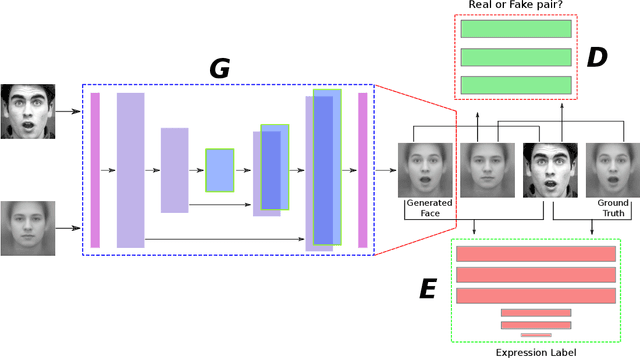

In this paper, we proposed a novel Identity-free conditional Generative Adversarial Network (IF-GAN) to explicitly reduce inter-subject variations for facial expression recognition. Specifically, for any given input face image, a conditional generative model was developed to transform an average neutral face, which is calculated from various subjects showing neutral expressions, to an average expressive face with the same expression as the input image. Since the transformed images have the same synthetic "average" identity, they differ from each other by only their expressions and thus, can be used for identity-free expression classification. In this work, an end-to-end system was developed to perform expression transformation and expression recognition in the IF-GAN framework. Experimental results on three facial expression datasets have demonstrated that the proposed IF-GAN outperforms the baseline CNN model and achieves comparable or better performance compared with the state-of-the-art methods for facial expression recognition.
Augmenting learning using symmetry in a biologically-inspired domain
Oct 01, 2019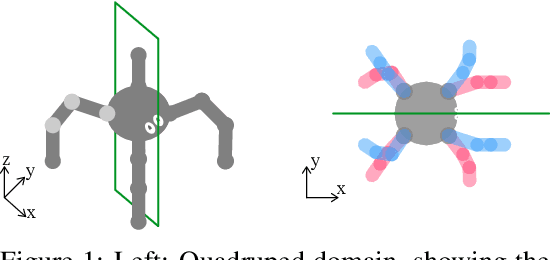
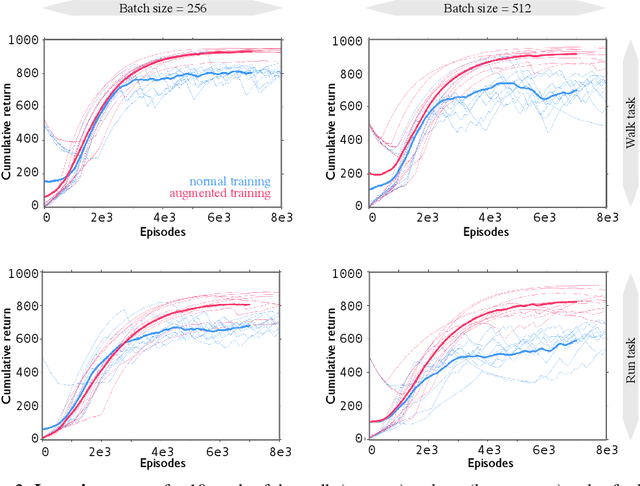
Invariances to translation, rotation and other spatial transformations are a hallmark of the laws of motion, and have widespread use in the natural sciences to reduce the dimensionality of systems of equations. In supervised learning, such as in image classification tasks, rotation, translation and scale invariances are used to augment training datasets. In this work, we use data augmentation in a similar way, exploiting symmetry in the quadruped domain of the DeepMind control suite (Tassa et al. 2018) to add to the trajectories experienced by the actor in the actor-critic algorithm of Abdolmaleki et al. (2018). In a data-limited regime, the agent using a set of experiences augmented through symmetry is able to learn faster. Our approach can be used to inject knowledge of invariances in the domain and task to augment learning in robots, and more generally, to speed up learning in realistic robotics applications.
Spatial Logics and Model Checking for Medical Imaging (Extended Version)
Nov 14, 2018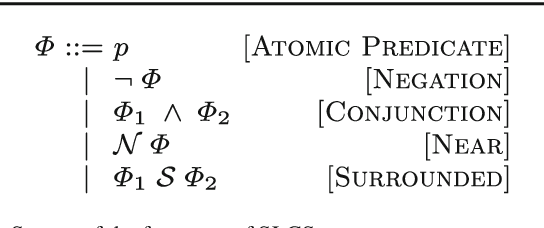
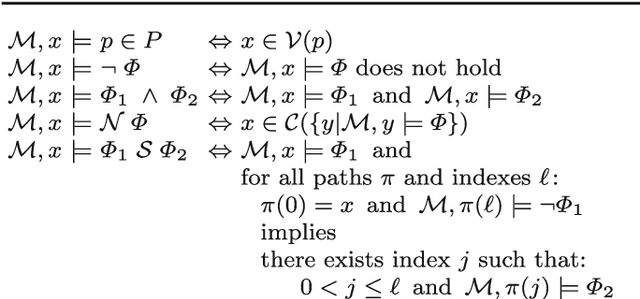

Recent research on spatial and spatio-temporal model checking provides novel image analysis methodologies, rooted in logical methods for topological spaces. Medical Imaging (MI) is a field where such methods show potential for ground-breaking innovation. Our starting point is SLCS, the Spatial Logic for Closure Spaces -- Closure Spaces being a generalisation of topological spaces, covering also discrete space structures -- and topochecker, a model-checker for SLCS (and extensions thereof). We introduce the logical language ImgQL ("Image Query Language"). ImgQL extends SLCS with logical operators describing distance and region similarity. The spatio-temporal model checker topochecker is correspondingly enhanced with state-of-the-art algorithms, borrowed from computational image processing, for efficient implementation of distancebased operators, namely distance transforms. Similarity between regions is defined by means of a statistical similarity operator, based on notions from statistical texture analysis. We illustrate our approach by means of two examples of analysis of Magnetic Resonance images: segmentation of glioblastoma and its oedema, and segmentation of rectal carcinoma.
Learning Human Objectives by Evaluating Hypothetical Behavior
Dec 05, 2019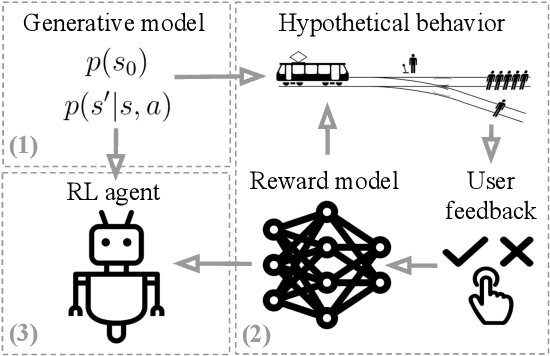
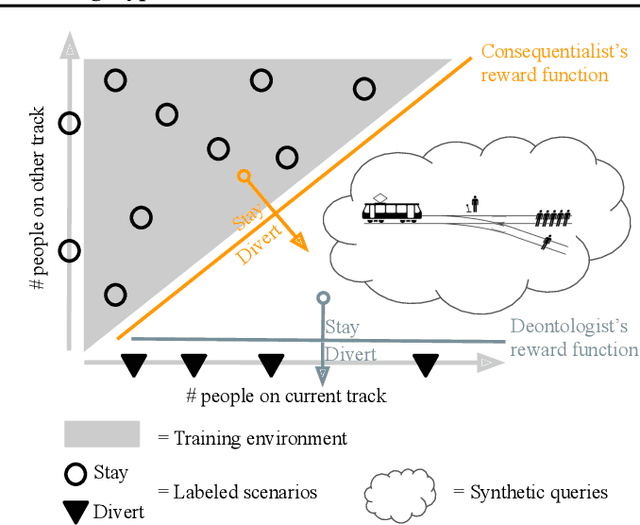
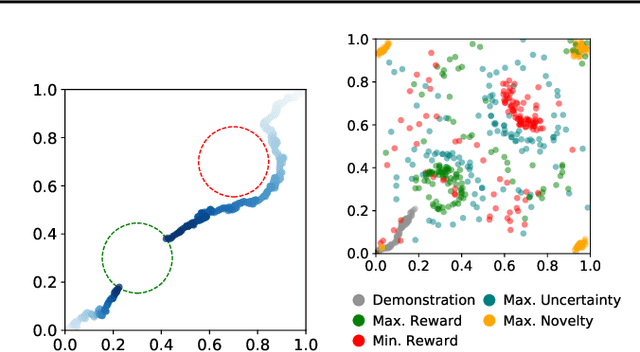
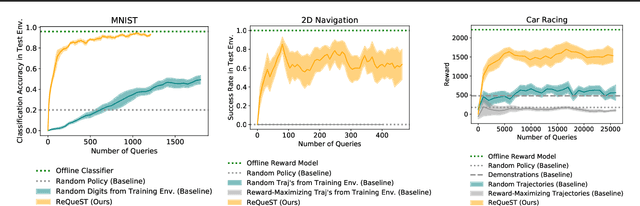
We seek to align agent behavior with a user's objectives in a reinforcement learning setting with unknown dynamics, an unknown reward function, and unknown unsafe states. The user knows the rewards and unsafe states, but querying the user is expensive. To address this challenge, we propose an algorithm that safely and interactively learns a model of the user's reward function. We start with a generative model of initial states and a forward dynamics model trained on off-policy data. Our method uses these models to synthesize hypothetical behaviors, asks the user to label the behaviors with rewards, and trains a neural network to predict the rewards. The key idea is to actively synthesize the hypothetical behaviors from scratch by maximizing tractable proxies for the value of information, without interacting with the environment. We call this method reward query synthesis via trajectory optimization (ReQueST). We evaluate ReQueST with simulated users on a state-based 2D navigation task and the image-based Car Racing video game. The results show that ReQueST significantly outperforms prior methods in learning reward models that transfer to new environments with different initial state distributions. Moreover, ReQueST safely trains the reward model to detect unsafe states, and corrects reward hacking before deploying the agent.