 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Real-time Global Inference Network for One-stage Referring Expression Comprehension
Dec 07, 2019
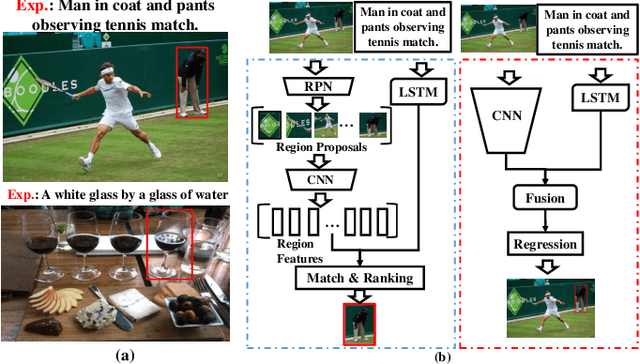
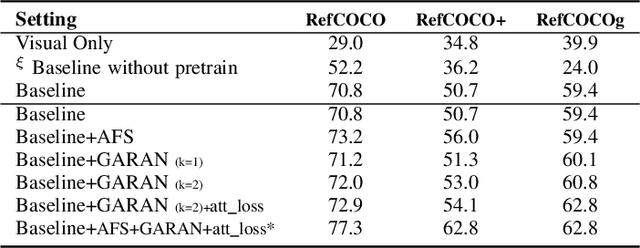
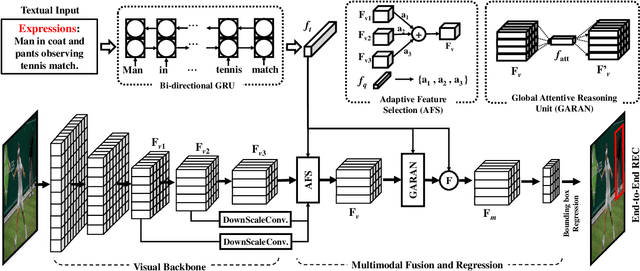

Referring Expression Comprehension (REC) is an emerging research spot in computer vision, which refers to detecting the target region in an image given an text description. Most existing REC methods follow a multi-stage pipeline, which are computationally expensive and greatly limit the application of REC. In this paper, we propose a one-stage model towards real-time REC, termed Real-time Global Inference Network (RealGIN). RealGIN addresses the diversity and complexity issues in REC with two innovative designs: the Adaptive Feature Selection (AFS) and the Global Attentive ReAsoNing unit (GARAN). AFS adaptively fuses features at different semantic levels to handle the varying content of expressions. GARAN uses the textual feature as a pivot to collect expression-related visual information from all regions, and thenselectively diffuse such information back to all regions, which provides sufficient context for modeling the complex linguistic conditions in expressions. On five benchmark datasets, i.e., RefCOCO, RefCOCO+, RefCOCOg, ReferIt and Flickr30k, the proposed RealGIN outperforms most prior works and achieves very competitive performances against the most advanced method, i.e., MAttNet. Most importantly, under the same hardware, RealGIN can boost the processing speed by about 10 times over the existing methods.
Kernel Task-Driven Dictionary Learning for Hyperspectral Image Classification
Feb 10, 2015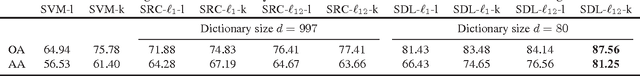

Dictionary learning algorithms have been successfully used in both reconstructive and discriminative tasks, where the input signal is represented by a linear combination of a few dictionary atoms. While these methods are usually developed under $\ell_1$ sparsity constrain (prior) in the input domain, recent studies have demonstrated the advantages of sparse representation using structured sparsity priors in the kernel domain. In this paper, we propose a supervised dictionary learning algorithm in the kernel domain for hyperspectral image classification. In the proposed formulation, the dictionary and classifier are obtained jointly for optimal classification performance. The supervised formulation is task-driven and provides learned features from the hyperspectral data that are well suited for the classification task. Moreover, the proposed algorithm uses a joint ($\ell_{12}$) sparsity prior to enforce collaboration among the neighboring pixels. The simulation results illustrate the efficiency of the proposed dictionary learning algorithm.
Single-bit-per-weight deep convolutional neural networks without batch-normalization layers for embedded systems
Jul 16, 2019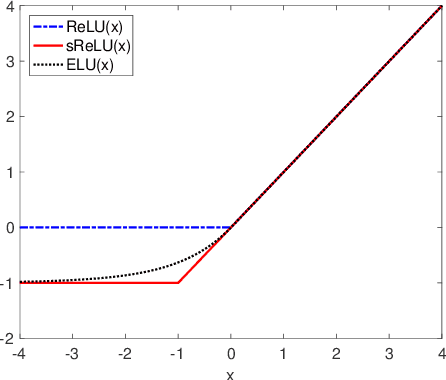
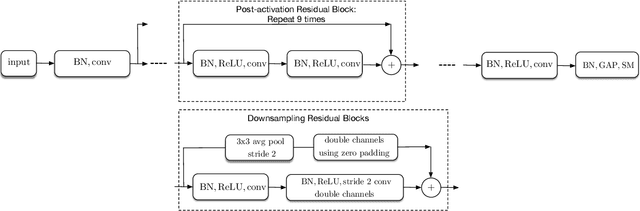
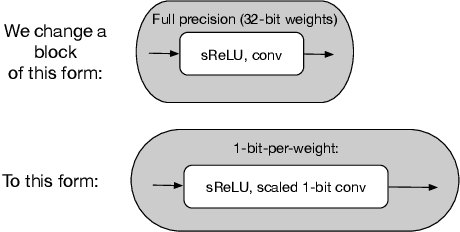
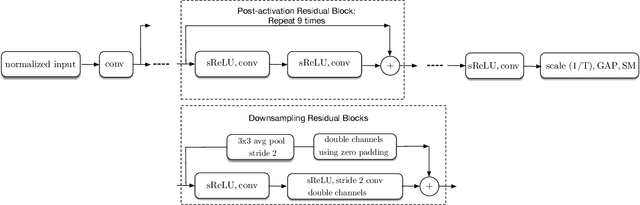
Batch-normalization (BN) layers are thought to be an integrally important layer type in today's state-of-the-art deep convolutional neural networks for computer vision tasks such as classification and detection. However, BN layers introduce complexity and computational overheads that are highly undesirable for training and/or inference on low-power custom hardware implementations of real-time embedded vision systems such as UAVs, robots and Internet of Things (IoT) devices. They are also problematic when batch sizes need to be very small during training, and innovations such as residual connections introduced more recently than BN layers could potentially have lessened their impact. In this paper we aim to quantify the benefits BN layers offer in image classification networks, in comparison with alternative choices. In particular, we study networks that use shifted-ReLU layers instead of BN layers. We found, following experiments with wide residual networks applied to the ImageNet, CIFAR 10 and CIFAR 100 image classification datasets, that BN layers do not consistently offer a significant advantage. We found that the accuracy margin offered by BN layers depends on the data set, the network size, and the bit-depth of weights. We conclude that in situations where BN layers are undesirable due to speed, memory or complexity costs, that using shifted-ReLU layers instead should be considered; we found they can offer advantages in all these areas, and often do not impose a significant accuracy cost.
Improved Embeddings with Easy Positive Triplet Mining
Apr 08, 2019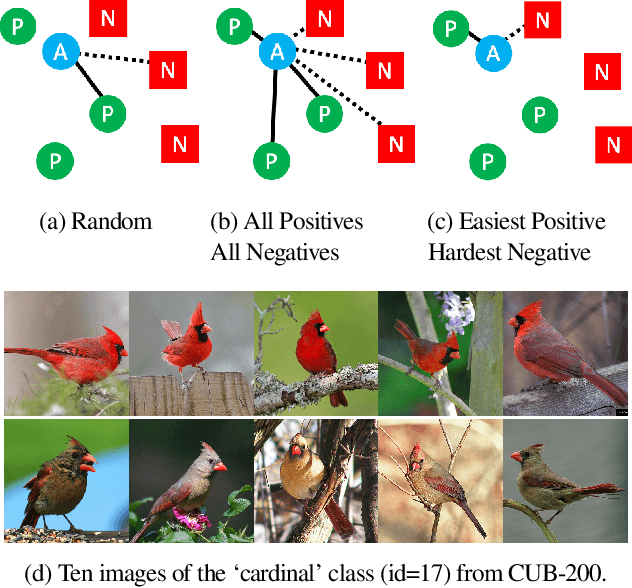
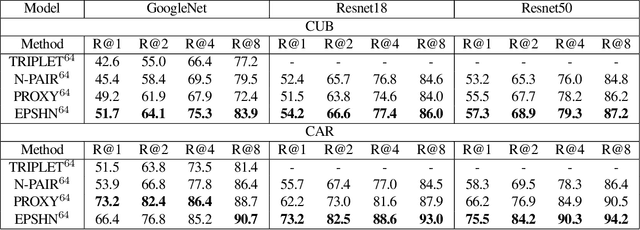
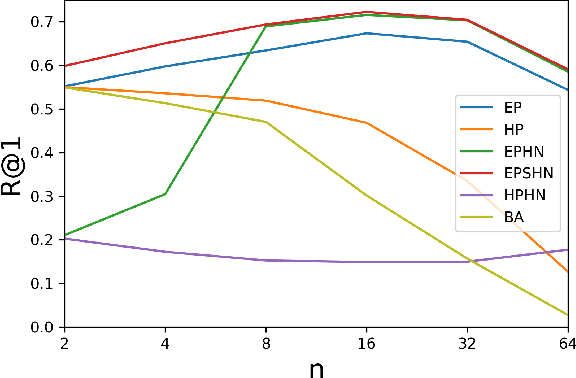
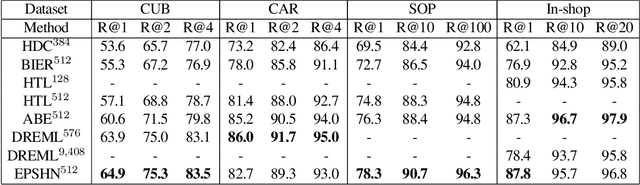
Deep metric learning seeks to define an embedding where semantically similar images are embedded to nearby locations, and semantically dissimilar images are embedded to distant locations. Substantial work has focused on loss functions and strategies to learn these embeddings by pushing images from the same class as close together in the embedding space as possible. In this paper, we propose an alternative, loosened embedding strategy that requires the embedding function only map each training image to the most similar examples from the same class, an approach we call "Easy Positive" mining. We provide a collection of experiments and visualizations that highlight that this Easy Positive mining leads to embeddings that are more flexible and generalize better to new unseen data. This simple mining strategy yields recall performance that exceeds state of the art approaches (including those with complicated loss functions and ensemble methods) on image retrieval datasets including CUB, Stanford Online Products, In-Shop Clothes and Hotels-50K.
Rethinking deep active learning: Using unlabeled data at model training
Nov 19, 2019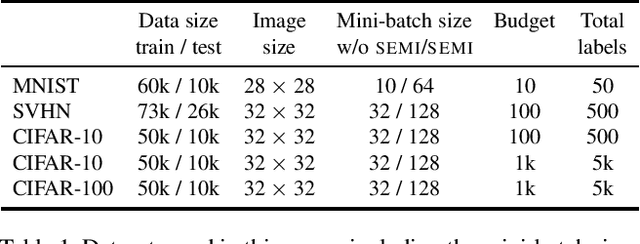
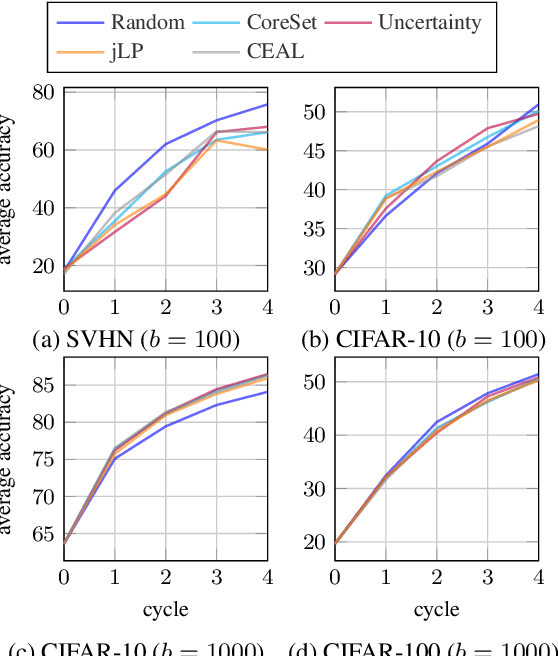
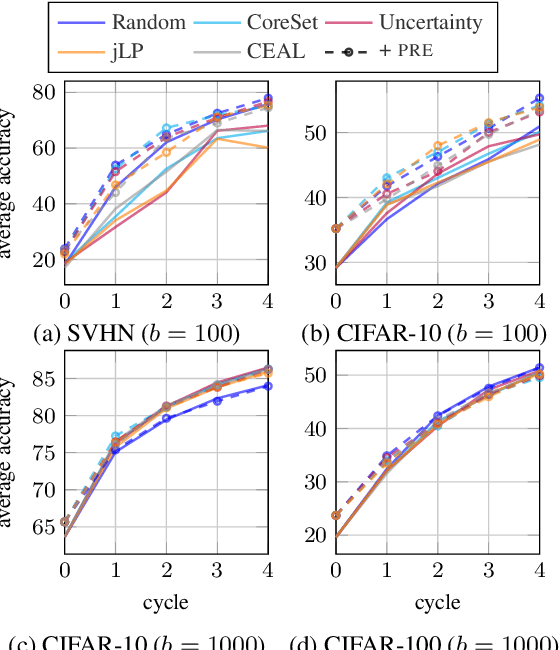
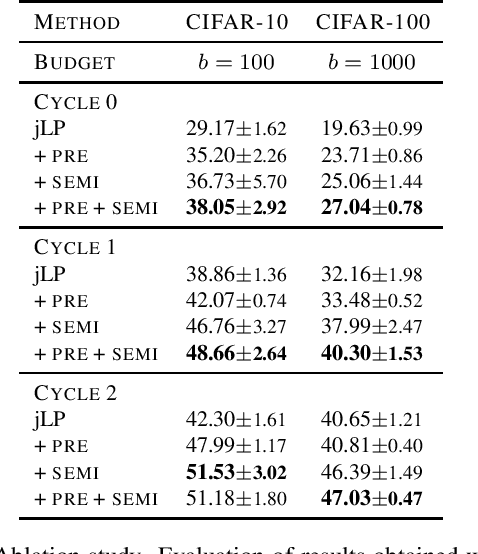
Active learning typically focuses on training a model on few labeled examples alone, while unlabeled ones are only used for acquisition. In this work we depart from this setting by using both labeled and unlabeled data during model training across active learning cycles. We do so by using unsupervised feature learning at the beginning of the active learning pipeline and semi-supervised learning at every active learning cycle, on all available data. The former has not been investigated before in active learning, while the study of latter in the context of deep learning is scarce and recent findings are not conclusive with respect to its benefit. Our idea is orthogonal to acquisition strategies by using more data, much like ensemble methods use more models. By systematically evaluating on a number of popular acquisition strategies and datasets, we find that the use of unlabeled data during model training brings a surprising accuracy improvement in image classification, compared to the differences between acquisition strategies. We thus explore smaller label budgets, even one label per class.
MarioNETte: Few-shot Face Reenactment Preserving Identity of Unseen Targets
Nov 19, 2019
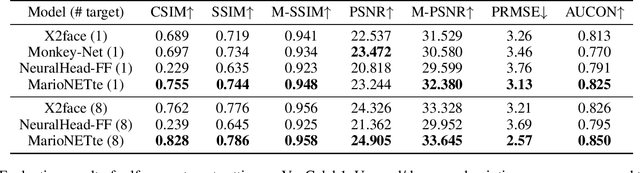
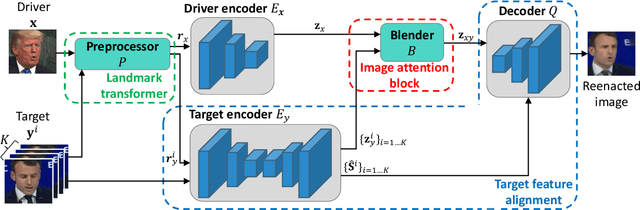
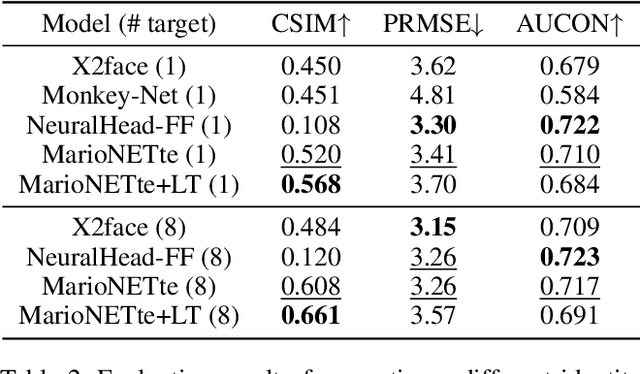
When there is a mismatch between the target identity and the driver identity, face reenactment suffers severe degradation in the quality of the result, especially in a few-shot setting. The identity preservation problem, where the model loses the detailed information of the target leading to a defective output, is the most common failure mode. The problem has several potential sources such as the identity of the driver leaking due to the identity mismatch, or dealing with unseen large poses. To overcome such problems, we introduce components that address the mentioned problem: image attention block, target feature alignment, and landmark transformer. Through attending and warping the relevant features, the proposed architecture, called MarioNETte, produces high-quality reenactments of unseen identities in a few-shot setting. In addition, the landmark transformer dramatically alleviates the identity preservation problem by isolating the expression geometry through landmark disentanglement. Comprehensive experiments are performed to verify that the proposed framework can generate highly realistic faces, outperforming all other baselines, even under a significant mismatch of facial characteristics between the target and the driver.
SoDeep: a Sorting Deep net to learn ranking loss surrogates
Apr 08, 2019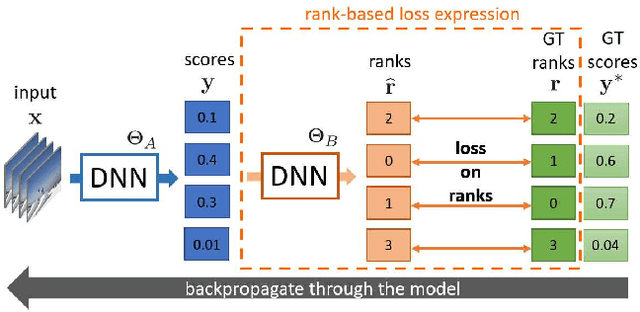

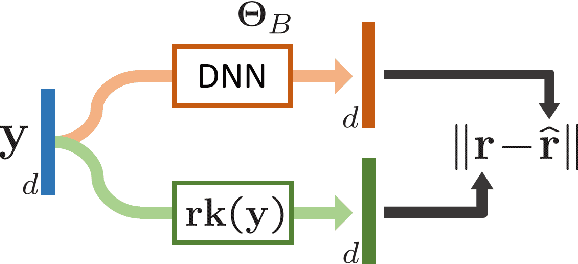

Several tasks in machine learning are evaluated using non-differentiable metrics such as mean average precision or Spearman correlation. However, their non-differentiability prevents from using them as objective functions in a learning framework. Surrogate and relaxation methods exist but tend to be specific to a given metric. In the present work, we introduce a new method to learn approximations of such non-differentiable objective functions. Our approach is based on a deep architecture that approximates the sorting of arbitrary sets of scores. It is trained virtually for free using synthetic data. This sorting deep (SoDeep) net can then be combined in a plug-and-play manner with existing deep architectures. We demonstrate the interest of our approach in three different tasks that require ranking: Cross-modal text-image retrieval, multi-label image classification and visual memorability ranking. Our approach yields very competitive results on these three tasks, which validates the merit and the flexibility of SoDeep as a proxy for sorting operation in ranking-based losses.
Deep Learning vs. Traditional Computer Vision
Oct 30, 2019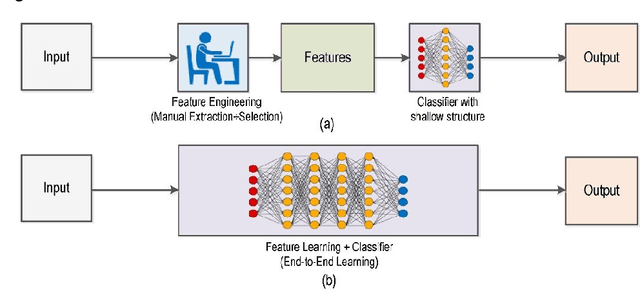
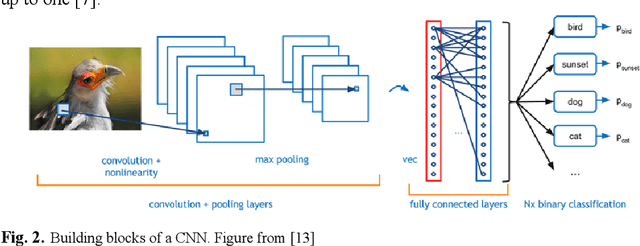
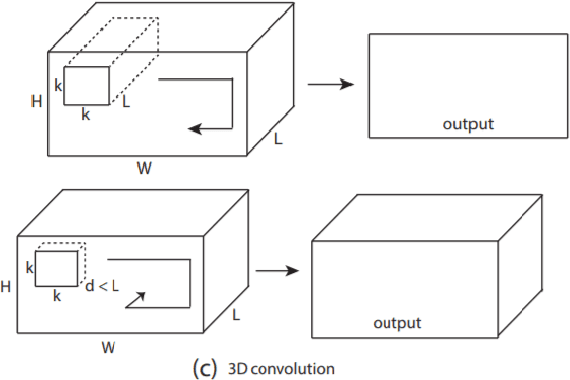
Deep Learning has pushed the limits of what was possible in the domain of Digital Image Processing. However, that is not to say that the traditional computer vision techniques which had been undergoing progressive development in years prior to the rise of DL have become obsolete. This paper will analyse the benefits and drawbacks of each approach. The aim of this paper is to promote a discussion on whether knowledge of classical computer vision techniques should be maintained. The paper will also explore how the two sides of computer vision can be combined. Several recent hybrid methodologies are reviewed which have demonstrated the ability to improve computer vision performance and to tackle problems not suited to Deep Learning. For example, combining traditional computer vision techniques with Deep Learning has been popular in emerging domains such as Panoramic Vision and 3D vision for which Deep Learning models have not yet been fully optimised
Fast and High Quality Highlight Removal from A Single Image
Dec 01, 2015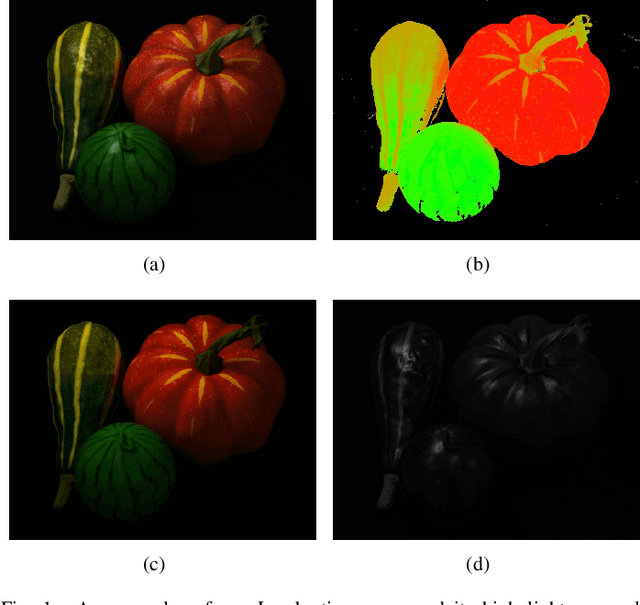

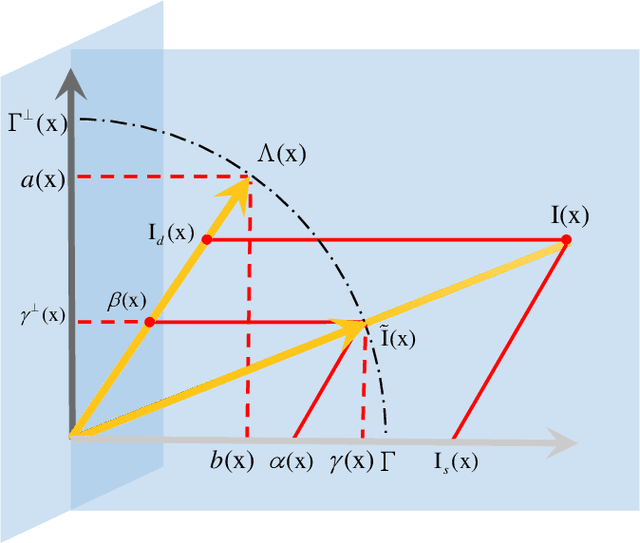
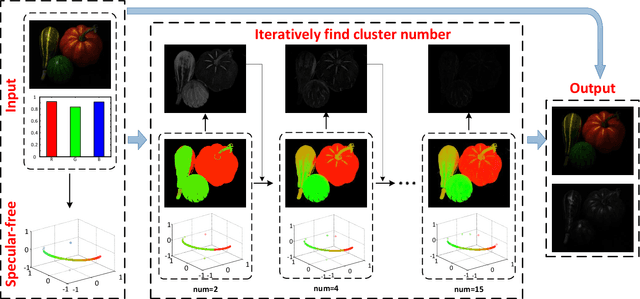
Specular reflection exists widely in photography and causes the recorded color deviating from its true value, so fast and high quality highlight removal from a single nature image is of great importance. In spite of the progress in the past decades in highlight removal, achieving wide applicability to the large diversity of nature scenes is quite challenging. To handle this problem, we propose an analytic solution to highlight removal based on an L2 chromaticity definition and corresponding dichromatic model. Specifically, this paper derives a normalized dichromatic model for the pixels with identical diffuse color: a unit circle equation of projection coefficients in two subspaces that are orthogonal to and parallel with the illumination, respectively. In the former illumination orthogonal subspace, which is specular-free, we can conduct robust clustering with an explicit criterion to determine the cluster number adaptively. In the latter illumination parallel subspace, a property called pure diffuse pixels distribution rule (PDDR) helps map each specular-influenced pixel to its diffuse component. In terms of efficiency, the proposed approach involves few complex calculation, and thus can remove highlight from high resolution images fast. Experiments show that this method is of superior performance in various challenging cases.
Large Area 3D Human Pose Detection Via Stereo Reconstruction in Panoramic Cameras
Jul 01, 2019
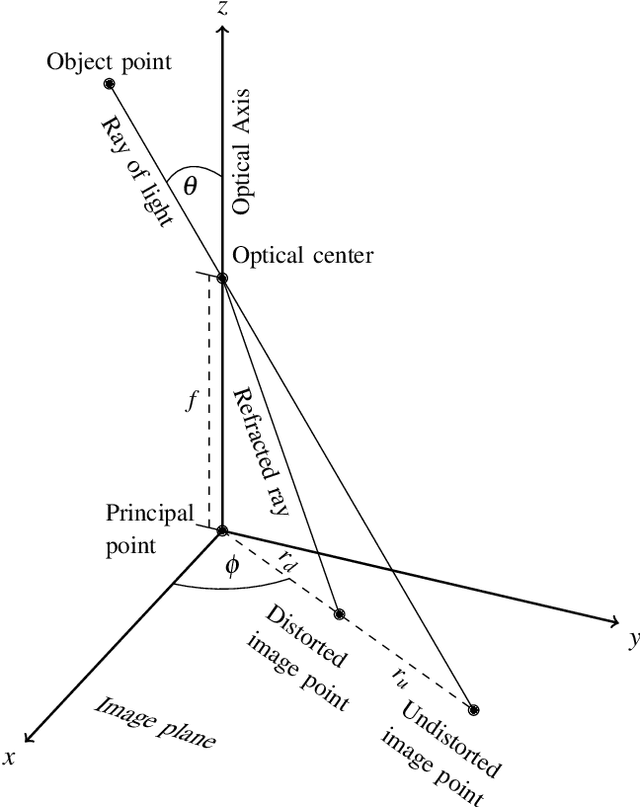
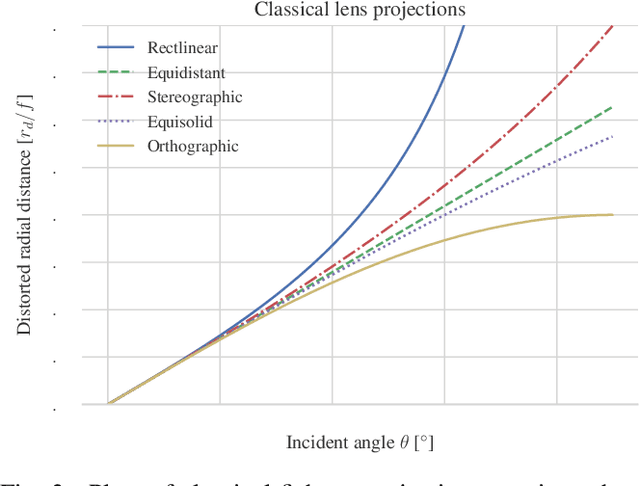

We propose a novel 3D human pose detector using two panoramic cameras. We show that transforming fisheye perspectives to rectilinear views allows a direct application of two-dimensional deep-learning pose estimation methods, without the explicit need for a costly re-training step to compensate for fisheye image distortions. By utilizing panoramic cameras, our method is capable of accurately estimating human poses over a large field of view. This renders our method suitable for ergonomic analyses and other pose based assessments.