 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Removal of Parameter Adjustment of Frangi Filters in Case of Coronary Angiograms
Dec 07, 2018
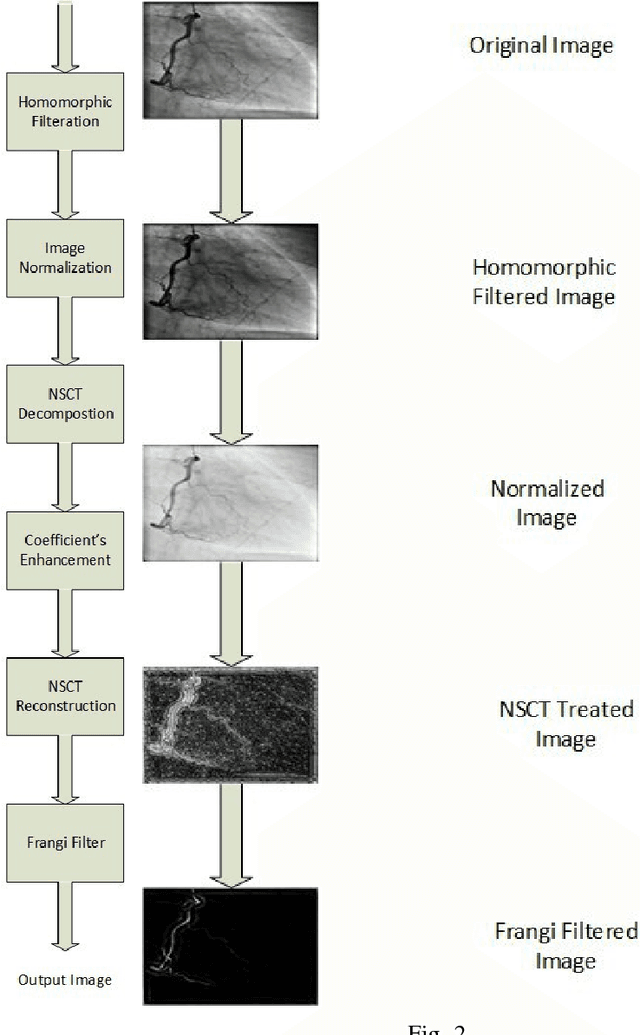
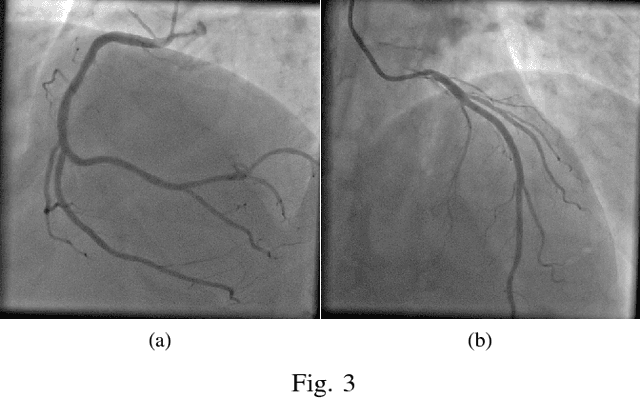

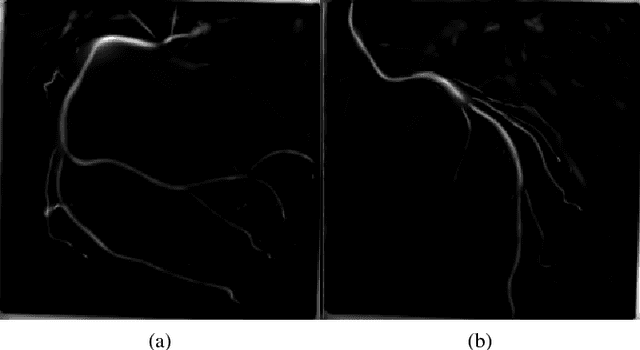
Frangi Filters are one of the widely used filters for enhancing vessels in medical images. Since they were first proposed, the threshold of the vesselness function of Frangi Filters is to be arranged for each individual application. These thresholds are changed manually for individual fluoroscope, for enhancing coronary angiogram images. Hence it is felt, there is a need of mitigating the tuning procedure of threshold values for every fluoroscope. The current papers approach has been devised in order to treat the coronary angiogram images uniformly, irrespective of the fluoroscopes through which they were obtained and the patient demographics for further stenosis detection. This problem to the best of our knowledge has not been addressed yet. In the approach, before feeding the image to Frangi Filters, non uniform illumination of the input image is removed using homomorphic filters and the image is enhanced using Non Subsampled Contourlet Transform (NSCT). The experiment was conducted on the data that has been accumulated from various hospitals in India and the results obtained verifies dependency removal of parameters without compromising the results obtained by Frangi filters.
Do Neural Networks Show Gestalt Phenomena? An Exploration of the Law of Closure
Mar 21, 2019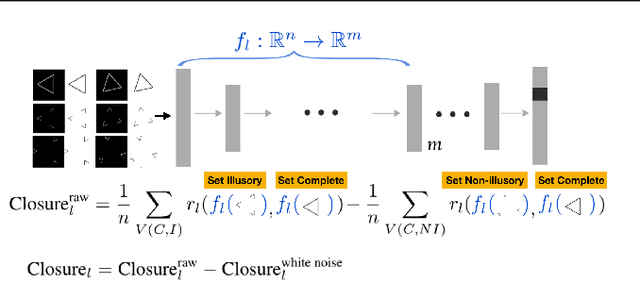
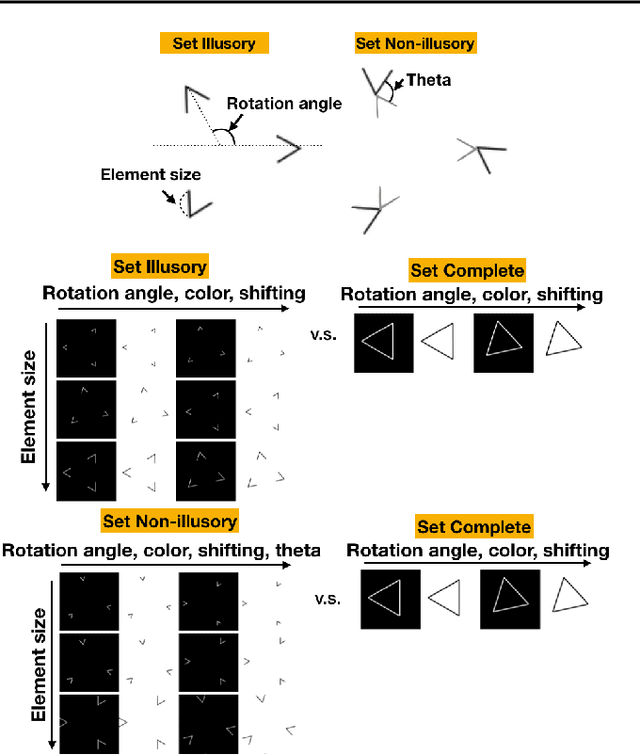
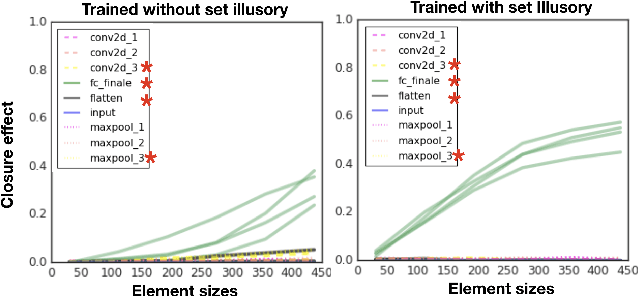
One characteristic of human visual perception is the presence of `Gestalt phenomena,' that is, that the whole is something other than the sum of its parts. A natural question is whether image-recognition networks show similar effects. Our paper investigates one particular type of Gestalt phenomenon, the law of closure, in the context of a feedforward image classification neural network (NN). This is a robust effect in human perception, but experiments typically rely on measurements (e.g., reaction time) that are not available for artificial neural nets. We describe a protocol for identifying closure effect in NNs, and report on the results of experiments with simple visual stimuli. Our findings suggest that NNs trained with natural images do exhibit closure, in contrast to networks with randomized weights or networks that have been trained on visually random data. Furthermore, the closure effect reflects something beyond good feature extraction; it is correlated with the network's higher layer features and ability to generalize.
Analytical shape determination of fiber-like objects with Virtual Image Correlation
Jan 15, 2010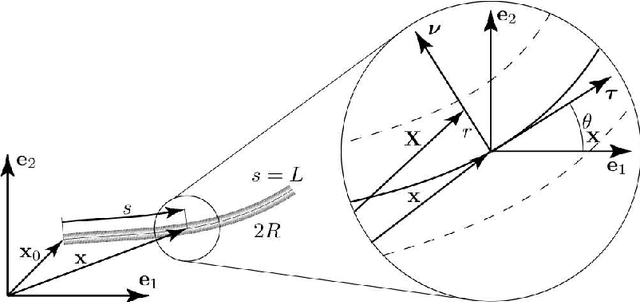
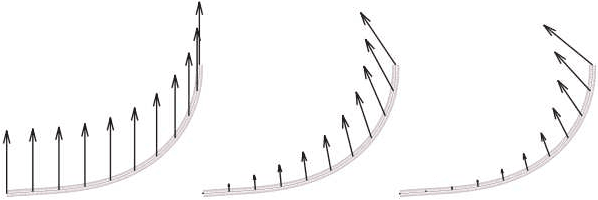

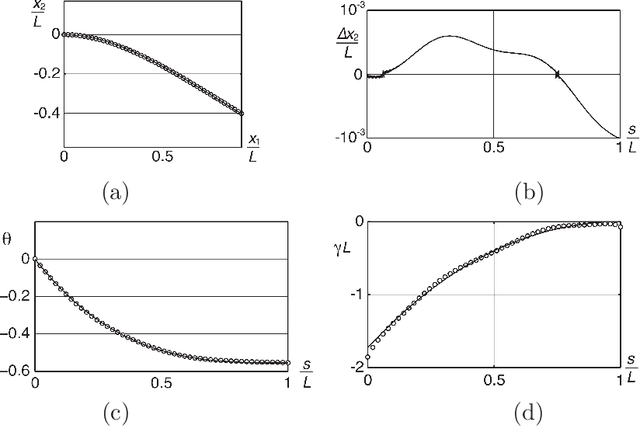
This paper reports a method allowing for the determination of the shape of deformed fiber-like objects. Compared to existing methods, it provides analytical results including the local slope and curvature which are of first importance, for instance, in beam mechanics. The presented VIC (Virtual Image Correlation) method consists in looking for the best correlation between the image of the fiber-like object and a virtual beam image, using an algorithm close to the Digital Image Correlation method developed in experimental solid mechanics. The computation only involves the part of the image in the vicinity of the fiber: the method is thus insensitive to the picture background and the computational cost remains low. Two examples are reported: the first proves the precision of the method, the second its ability to identify a complex shape with multiple loops.
Context-Aware Synthesis and Placement of Object Instances
Dec 07, 2018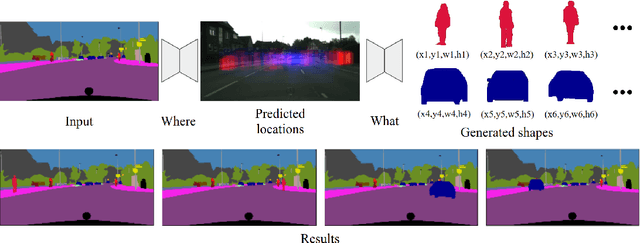

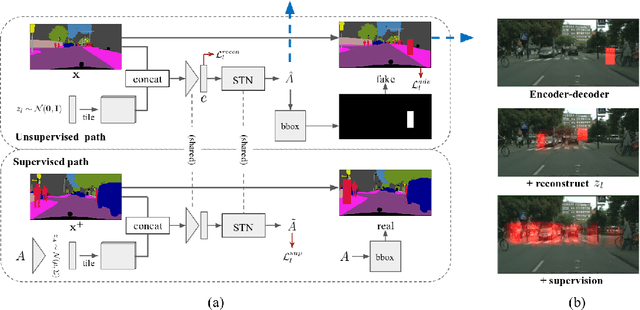
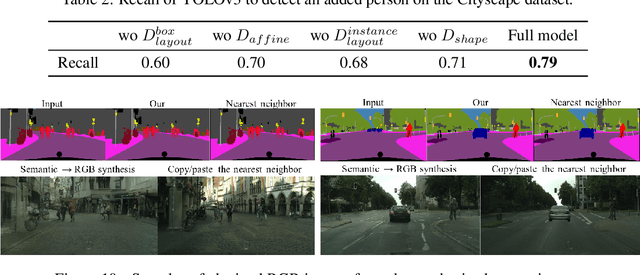
Learning to insert an object instance into an image in a semantically coherent manner is a challenging and interesting problem. Solving it requires (a) determining a location to place an object in the scene and (b) determining its appearance at the location. Such an object insertion model can potentially facilitate numerous image editing and scene parsing applications. In this paper, we propose an end-to-end trainable neural network for the task of inserting an object instance mask of a specified class into the semantic label map of an image. Our network consists of two generative modules where one determines where the inserted object mask should be (i.e., location and scale) and the other determines what the object mask shape (and pose) should look like. The two modules are connected together via a spatial transformation network and jointly trained. We devise a learning procedure that leverage both supervised and unsupervised data and show our model can insert an object at diverse locations with various appearances. We conduct extensive experimental validations with comparisons to strong baselines to verify the effectiveness of the proposed network.
Towards Building the Semantic Map from a Monocular Camera with a Multi-task Network
Jan 17, 2019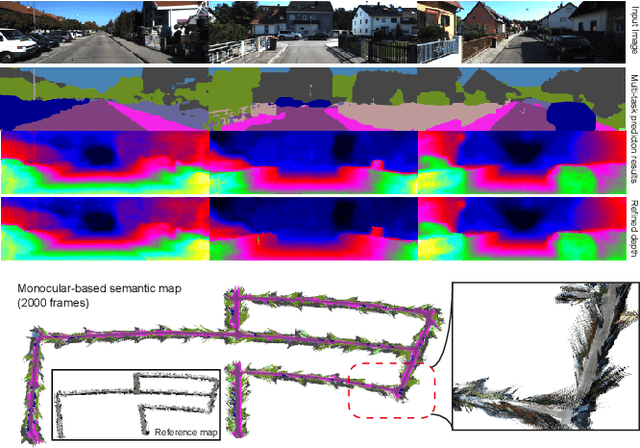
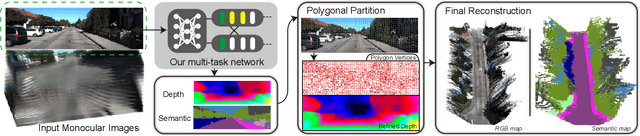
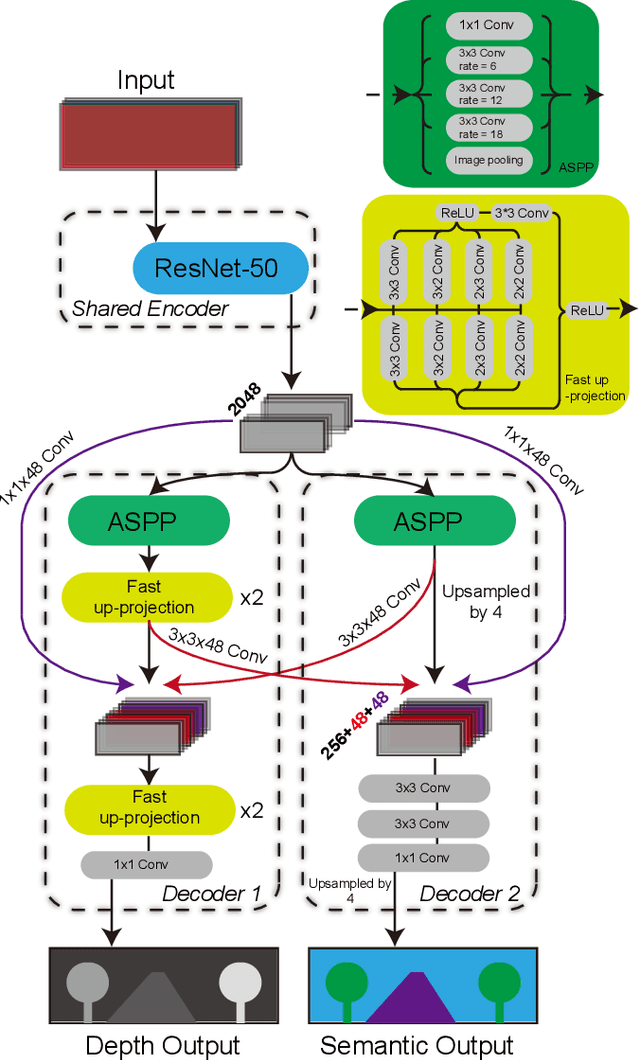
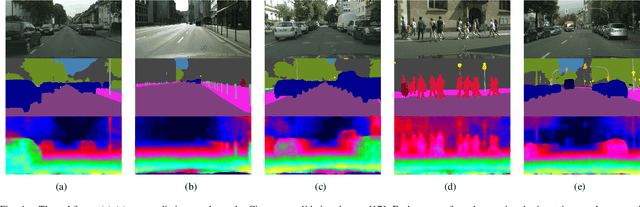
In many robotic applications, especially for the autonomous driving, understanding the semantic information and the geometric structure of surroundings are both essential. Semantic 3D maps, as a carrier of the environmental knowledge, are then intensively studied for their abilities and applications. However, it is still challenging to produce a dense outdoor semantic map from a monocular image stream. Motivated by this target, in this paper, we propose a method for large-scale 3D reconstruction from consecutive monocular images. First, with the correlation of underlying information between depth and semantic prediction, a novel multi-task Convolutional Neural Network (CNN) is designed for joint prediction. Given a single image, the network learns low-level information with a shared encoder and separately predicts with decoders containing additional Atrous Spatial Pyramid Pooling (ASPP) layers and the residual connection which merits disparities and semantic mutually. To overcome the inconsistency of monocular depth prediction for reconstruction, post-processing steps with the superpixelization and the effective 3D representation approach are obtained to give the final semantic map. Experiments are compared with other methods on both semantic labeling and depth prediction. We also qualitatively demonstrate the map reconstructed from large-scale, difficult monocular image sequences to prove the effectiveness and superiority.
SQuINTing at VQA Models: Interrogating VQA Models with Sub-Questions
Jan 20, 2020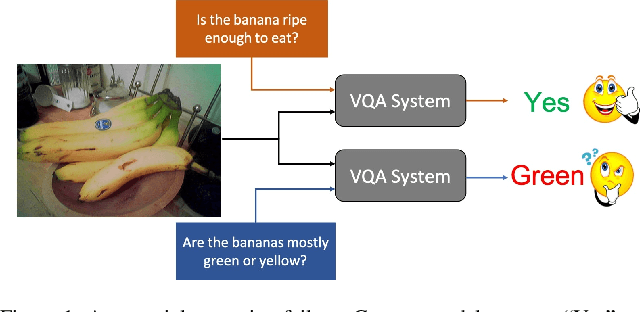

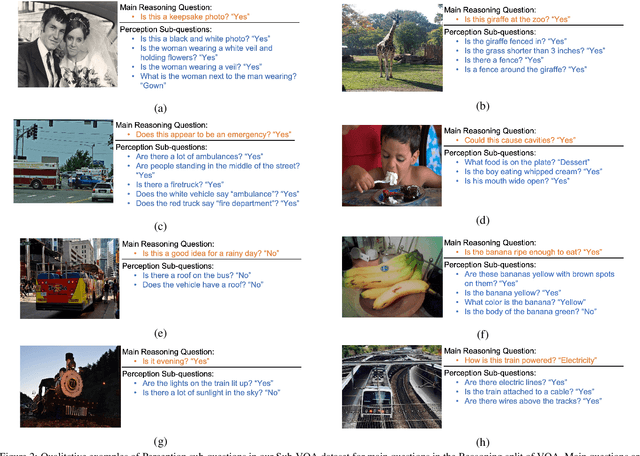
Existing VQA datasets contain questions with varying levels of complexity. While the majority of questions in these datasets require perception for recognizing existence, properties, and spatial relationships of entities, a significant portion of questions pose challenges that correspond to reasoning tasks -- tasks that can only be answered through a synthesis of perception and knowledge about the world, logic and / or reasoning. This distinction allows us to notice when existing VQA models have consistency issues -- they answer the reasoning question correctly but fail on associated low-level perception questions. For example, models answer the complex reasoning question "Is the banana ripe enough to eat?" correctly, but fail on the associated perception question "Are the bananas mostly green or yellow?" indicating that the model likely answered the reasoning question correctly but for the wrong reason. We quantify the extent to which this phenomenon occurs by creating a new Reasoning split of the VQA dataset and collecting Sub-VQA, a new dataset consisting of 200K new perception questions which serve as sub questions corresponding to the set of perceptual tasks needed to effectively answer the complex reasoning questions in the Reasoning split. Additionally, we propose an approach called Sub-Question Importance-aware Network Tuning (SQuINT), which encourages the model to attend do the same parts of the image when answering the reasoning question and the perception sub questions. We show that SQuINT improves model consistency by 7.8%, also marginally improving its performance on the Reasoning questions in VQA, while also displaying qualitatively better attention maps.
Computational Ceramicology
Nov 22, 2019Field archeologists are called upon to identify potsherds, for which purpose they rely on their experience and on reference works. We have developed two complementary machine-learning tools to propose identifications based on images captured on site. One method relies on the shape of the fracture outline of a sherd; the other is based on decorative features. For the outline-identification tool, a novel deep-learning architecture was employed, one that integrates shape information from points along the inner and outer surfaces. The decoration classifier is based on relatively standard architectures used in image recognition. In both cases, training the classifiers required tackling challenges that arise when working with real-world archeological data: paucity of labeled data; extreme imbalance between instances of the different categories; and the need to avoid neglecting rare classes and to take note of minute distinguishing features of some classes. The scarcity of training data was overcome by using synthetically-produced virtual potsherds and by employing multiple data-augmentation techniques. A novel form of training loss allowed us to overcome the problems caused by under-populated classes and non-homogeneous distribution of discriminative features.
Geometry-aware Generation of Adversarial and Cooperative Point Clouds
Dec 24, 2019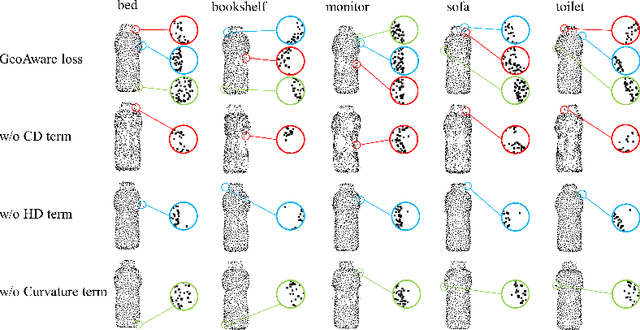
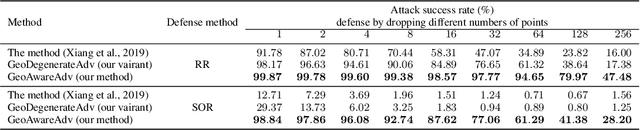
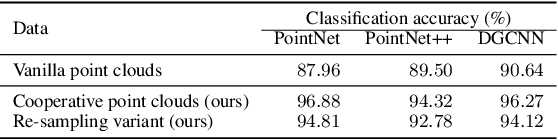
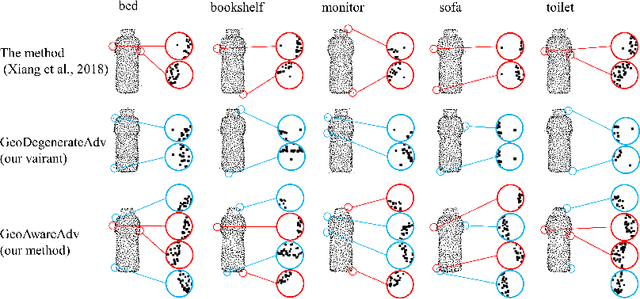
Recent studies show that machine learning models are vulnerable to adversarial examples. In 2D image domain, these examples are obtained by adding imperceptible noises to natural images. This paper studies adversarial generation of point clouds by learning to deform those approximating object surfaces of certain categories. As 2D manifolds embedded in the 3D Euclidean space, object surfaces enjoy the general properties of smoothness and fairness. We thus argue that in order to achieve imperceptible surface shape deformations, adversarial point clouds should have the same properties with similar degrees of smoothness/fairness to the benign ones, while being close to the benign ones as well when measured under certain distance metrics of point clouds. To this end, we propose a novel loss function to account for imperceptible, geometry-aware deformations of point clouds, and use the proposed loss in an adversarial objective to attack representative models of point set classifiers. Experiments show that our proposed method achieves stronger attacks than existing methods, without introduction of noticeable outliers and surface irregularities. In this work, we also investigate an opposite direction that learns to deform point clouds of object surfaces in the same geometry-aware, but cooperative manner. Cooperatively generated point clouds are more favored by machine learning models in terms of improved classification confidence or accuracy. We present experiments verifying that our proposed objective succeeds in learning cooperative shape deformations.
SeFM: A Sequential Feature Point Matching Algorithm for Object 3D Reconstruction
Dec 07, 2018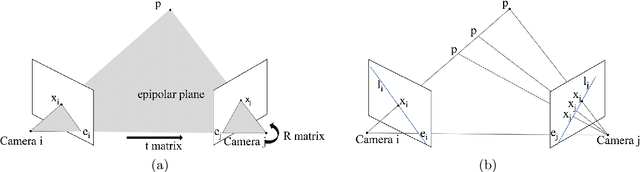
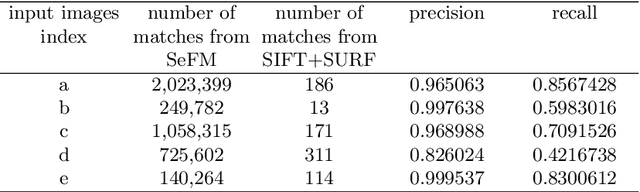
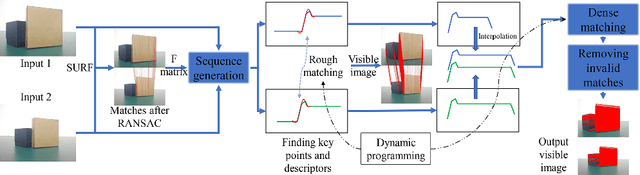
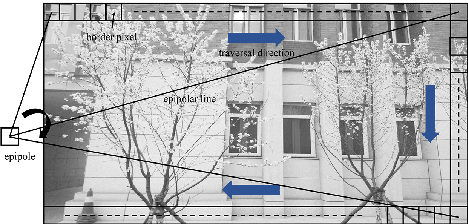
3D reconstruction is a fundamental issue in many applications and the feature point matching problem is a key step while reconstructing target objects. Conventional algorithms can only find a small number of feature points from two images which is quite insufficient for reconstruction. To overcome this problem, we propose SeFM a sequential feature point matching algorithm. We first utilize the epipolar geometry to find the epipole of each image. Rotating along the epipole, we generate a set of the epipolar lines and reserve those intersecting with the input image. Next, a rough matching phase, followed by a dense matching phase, is applied to find the matching dot-pairs using dynamic programming. Furthermore, we also remove wrong matching dot-pairs by calculating the validity. Experimental results illustrate that SeFM can achieve around 1,000 to 10,000 times matching dot-pairs, depending on individual image, compared to conventional algorithms and the object reconstruction with only two images is semantically visible. Moreover, it outperforms conventional algorithms, such as SIFT and SURF, regarding precision and recall.
Spatial Logics and Model Checking for Medical Imaging (Extended Version)
Nov 14, 2018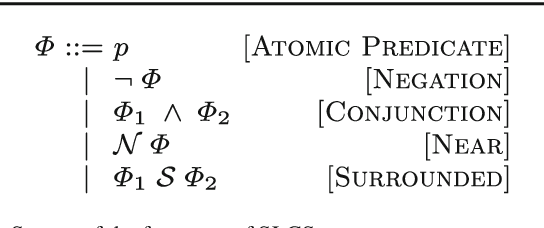
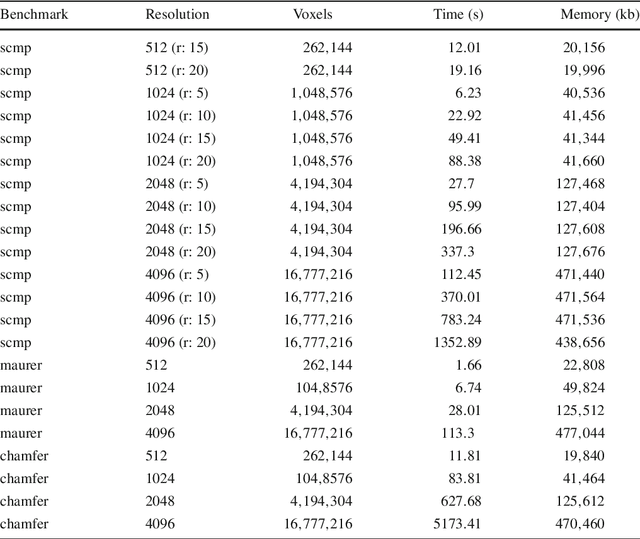
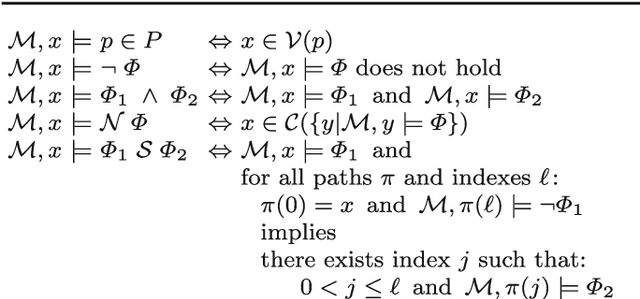

Recent research on spatial and spatio-temporal model checking provides novel image analysis methodologies, rooted in logical methods for topological spaces. Medical Imaging (MI) is a field where such methods show potential for ground-breaking innovation. Our starting point is SLCS, the Spatial Logic for Closure Spaces -- Closure Spaces being a generalisation of topological spaces, covering also discrete space structures -- and topochecker, a model-checker for SLCS (and extensions thereof). We introduce the logical language ImgQL ("Image Query Language"). ImgQL extends SLCS with logical operators describing distance and region similarity. The spatio-temporal model checker topochecker is correspondingly enhanced with state-of-the-art algorithms, borrowed from computational image processing, for efficient implementation of distancebased operators, namely distance transforms. Similarity between regions is defined by means of a statistical similarity operator, based on notions from statistical texture analysis. We illustrate our approach by means of two examples of analysis of Magnetic Resonance images: segmentation of glioblastoma and its oedema, and segmentation of rectal carcinoma.