 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CRUR: Coupled-Recurrent Unit for Unification, Conceptualization and Context Capture for Language Representation -- A Generalization of Bi Directional LSTM
Nov 22, 2019
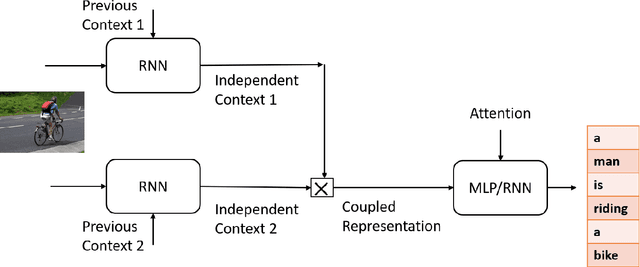

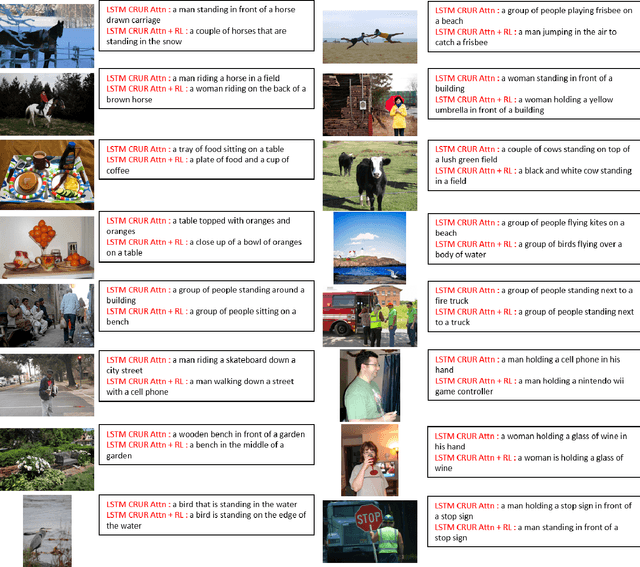
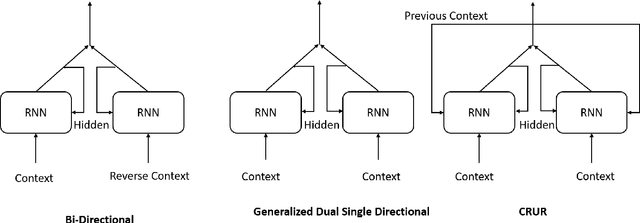
In this work we have analyzed a novel concept of sequential binding based learning capable network based on the coupling of recurrent units with Bayesian prior definition. The coupling structure encodes to generate efficient tensor representations that can be decoded to generate efficient sentences and can describe certain events. These descriptions are derived from structural representations of visual features of images and media. An elaborated study of the different types of coupling recurrent structures are studied and some insights of their performance are provided. Supervised learning performance for natural language processing is judged based on statistical evaluations, however, the truth is perspective, and in this case the qualitative evaluations reveal the real capability of the different architectural strengths and variations. Bayesian prior definition of different embedding helps in better characterization of the sentences based on the natural language structure related to parts of speech and other semantic level categorization in a form which is machine interpret-able and inherits the characteristics of the Tensor Representation binding and unbinding based on the mutually orthogonality. Our approach has surpassed some of the existing basic works related to image captioning.
Improving Facial Emotion Recognition Systems Using Gradient and Laplacian Images
Feb 12, 2019

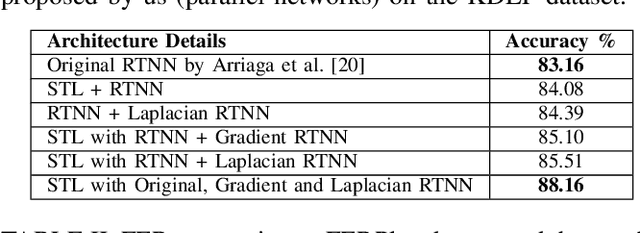
In this work, we have proposed several enhancements to improve the performance of any facial emotion recognition (FER) system. We believe that the changes in the positions of the fiducial points and the intensities capture the crucial information regarding the emotion of a face image. We propose the use of the gradient and the Laplacian of the input image together with the original input into a convolutional neural network (CNN). These modifications help the network learn additional information from the gradient and Laplacian of the images. However, the plain CNN is not able to extract this information from the raw images. We have performed a number of experiments on two well known datasets KDEF and FERplus. Our approach enhances the already high performance of state-of-the-art FER systems by 3 to 5%.
Does Learning Require Memorization? A Short Tale about a Long Tail
Jun 12, 2019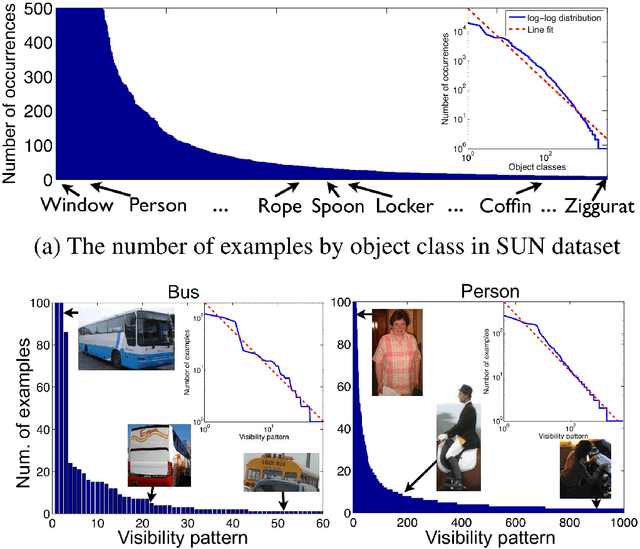

State-of-the-art results on image recognition tasks are achieved using over-parameterized learning algorithms that (nearly) perfectly fit the training set. This phenomenon is referred to as data interpolation or, informally, as memorization of the training data. The question of why such algorithms generalize well to unseen data is not adequately addressed by the standard theoretical frameworks and, as a result, significant theoretical and experimental effort has been devoted to understanding the properties of such algorithms. We provide a simple and generic model for prediction problems in which interpolating the dataset is necessary for achieving close-to-optimal generalization error. The model is motivated and supported by the results of several recent empirical works. In our model, data is sampled from a mixture of subpopulations and the frequencies of these subpopulations are chosen from some prior. The model allows to quantify the effect of not fitting the training data on the generalization performance of the learned classifier and demonstrates that memorization is necessary whenever frequencies are long-tailed. Image and text data are known to follow such distributions and therefore our results establish a formal link between these empirical phenomena. To the best of our knowledge, this is the first general framework that demonstrates statistical benefits of plain memorization for learning. Our results also have concrete implications for the cost of ensuring differential privacy in learning.
Geometry-aware Generation of Adversarial and Cooperative Point Clouds
Dec 24, 2019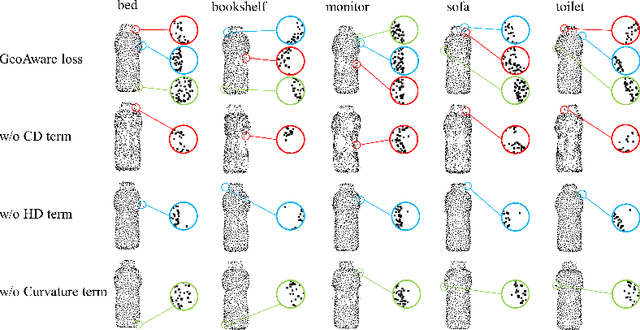
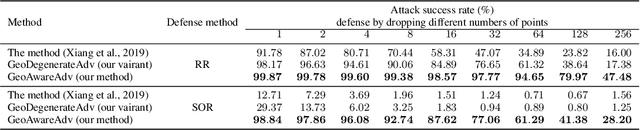
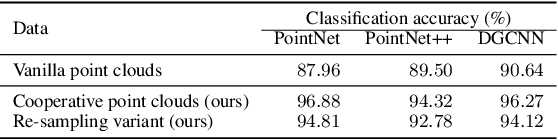
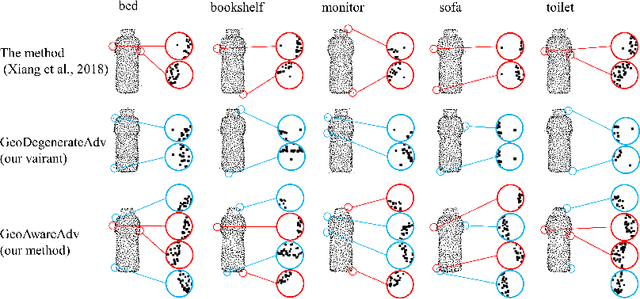
Recent studies show that machine learning models are vulnerable to adversarial examples. In 2D image domain, these examples are obtained by adding imperceptible noises to natural images. This paper studies adversarial generation of point clouds by learning to deform those approximating object surfaces of certain categories. As 2D manifolds embedded in the 3D Euclidean space, object surfaces enjoy the general properties of smoothness and fairness. We thus argue that in order to achieve imperceptible surface shape deformations, adversarial point clouds should have the same properties with similar degrees of smoothness/fairness to the benign ones, while being close to the benign ones as well when measured under certain distance metrics of point clouds. To this end, we propose a novel loss function to account for imperceptible, geometry-aware deformations of point clouds, and use the proposed loss in an adversarial objective to attack representative models of point set classifiers. Experiments show that our proposed method achieves stronger attacks than existing methods, without introduction of noticeable outliers and surface irregularities. In this work, we also investigate an opposite direction that learns to deform point clouds of object surfaces in the same geometry-aware, but cooperative manner. Cooperatively generated point clouds are more favored by machine learning models in terms of improved classification confidence or accuracy. We present experiments verifying that our proposed objective succeeds in learning cooperative shape deformations.
Computational Ceramicology
Nov 22, 2019Field archeologists are called upon to identify potsherds, for which purpose they rely on their experience and on reference works. We have developed two complementary machine-learning tools to propose identifications based on images captured on site. One method relies on the shape of the fracture outline of a sherd; the other is based on decorative features. For the outline-identification tool, a novel deep-learning architecture was employed, one that integrates shape information from points along the inner and outer surfaces. The decoration classifier is based on relatively standard architectures used in image recognition. In both cases, training the classifiers required tackling challenges that arise when working with real-world archeological data: paucity of labeled data; extreme imbalance between instances of the different categories; and the need to avoid neglecting rare classes and to take note of minute distinguishing features of some classes. The scarcity of training data was overcome by using synthetically-produced virtual potsherds and by employing multiple data-augmentation techniques. A novel form of training loss allowed us to overcome the problems caused by under-populated classes and non-homogeneous distribution of discriminative features.
Incorporating physical constraints in a deep probabilistic machine learning framework for coarse-graining dynamical systems
Jan 06, 2020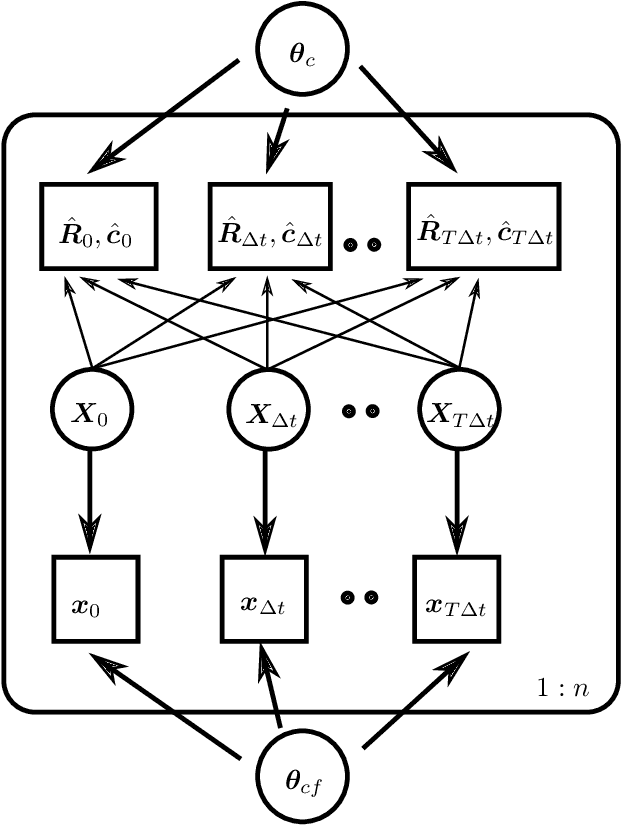

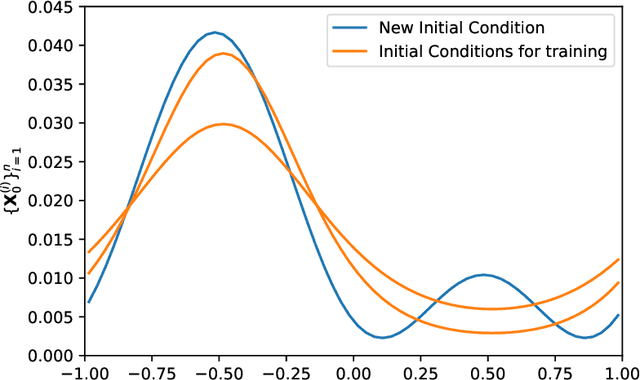
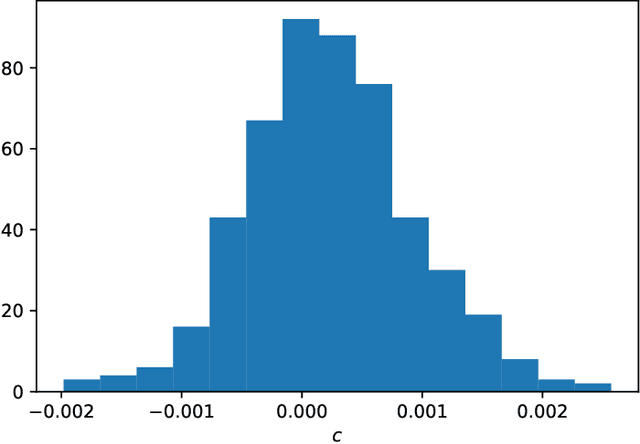
Data-based discovery of effective, coarse-grained (CG) models of high-dimensional dynamical systems presents a unique challenge in computational physics and particularly in the context of multiscale problems. The present paper offers a data-based, probablistic perspective that enables the quantification of predictive uncertainties. One of the outstanding problems has been the introduction of physical constraints in the probabilistic machine learning objectives. The primary utility of such constraints stems from the undisputed physical laws such as conservation of mass, energy etc that they represent. Furthermore and apart from leading to physically realistic predictions, they can significantly reduce the requisite amount of training data which for high-dimensional, multiscale systems are expensive to obtain (Small Data regime). We formulate the coarse-graining process by employing a probabilistic state-space model and account for the aforementioned equality constraints as virtual observables in the associated densities. We demonstrate how probabilistic inference tools can be employed to identify the coarse-grained variables in combination with deep neural nets and their evolution model without ever needing to define a fine-to-coarse (restriction) projection and without needing time-derivatives of state variables. Furthermore, it is capable of reconstructing the evolution of the full, fine-scale system and therefore the observables of interest need not be selected a priori. We demonstrate the efficacy of the proposed framework by applying it to systems of interacting particles and an image-series of a nonlinear pendulum.
Semi-blind Sparse Image Reconstruction with Application to MRFM
Mar 21, 2012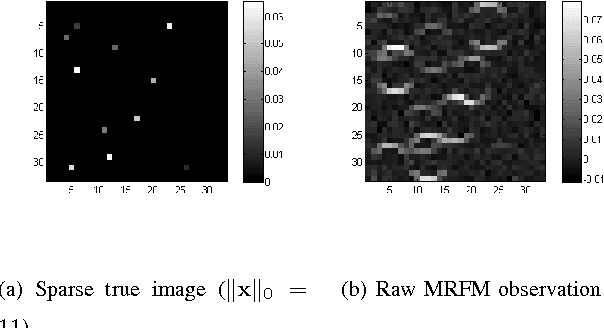

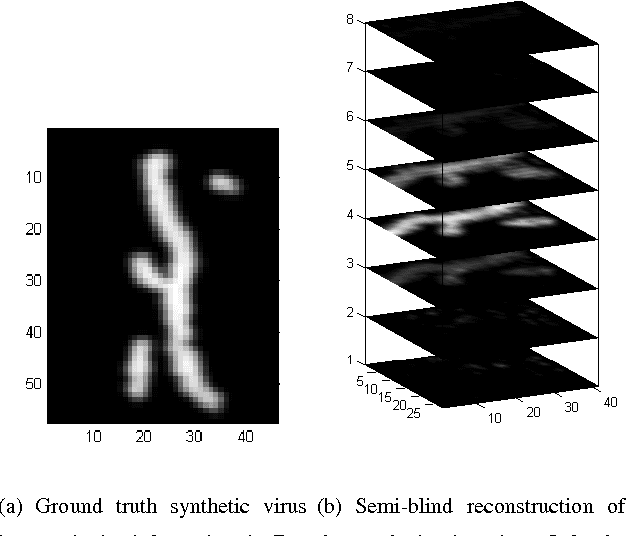

We propose a solution to the image deconvolution problem where the convolution kernel or point spread function (PSF) is assumed to be only partially known. Small perturbations generated from the model are exploited to produce a few principal components explaining the PSF uncertainty in a high dimensional space. Unlike recent developments on blind deconvolution of natural images, we assume the image is sparse in the pixel basis, a natural sparsity arising in magnetic resonance force microscopy (MRFM). Our approach adopts a Bayesian Metropolis-within-Gibbs sampling framework. The performance of our Bayesian semi-blind algorithm for sparse images is superior to previously proposed semi-blind algorithms such as the alternating minimization (AM) algorithm and blind algorithms developed for natural images. We illustrate our myopic algorithm on real MRFM tobacco virus data.
An Overview of Computational Approaches for Analyzing Interpretation
Nov 09, 2018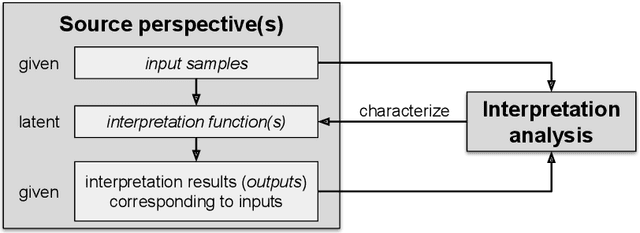
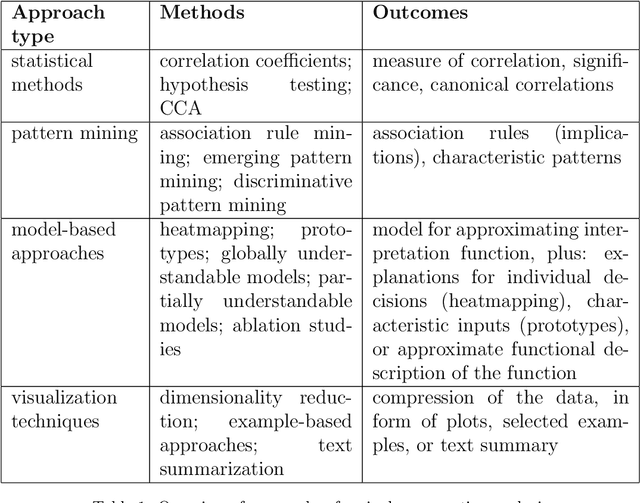
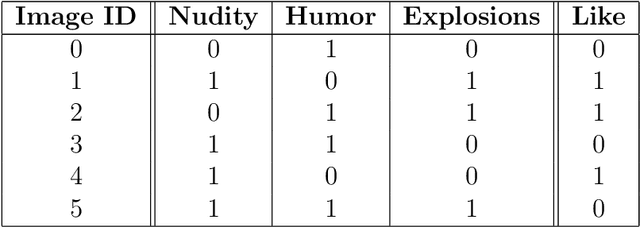

It is said that beauty is in the eye of the beholder. But how exactly can we characterize such discrepancies in interpretation? For example, are there any specific features of an image that makes person A regard an image as beautiful while person B finds the same image displeasing? Such questions ultimately aim at explaining our individual ways of interpretation, an intention that has been of fundamental importance to the social sciences from the beginning. More recently, advances in computer science brought up two related questions: First, can computational tools be adopted for analyzing ways of interpretation? Second, what if the "beholder" is a computer model, i.e., how can we explain a computer model's point of view? Numerous efforts have been made regarding both of these points, while many existing approaches focus on particular aspects and are still rather separate. With this paper, in order to connect these approaches we introduce a theoretical framework for analyzing interpretation, which is applicable to interpretation of both human beings and computer models. We give an overview of relevant computational approaches from various fields, and discuss the most common and promising application areas. The focus of this paper lies on interpretation of text and image data, while many of the presented approaches are applicable to other types of data as well.
Review of Visual Saliency Detection with Comprehensive Information
Sep 14, 2018



Visual saliency detection model simulates the human visual system to perceive the scene, and has been widely used in many vision tasks. With the acquisition technology development, more comprehensive information, such as depth cue, inter-image correspondence, or temporal relationship, is available to extend image saliency detection to RGBD saliency detection, co-saliency detection, or video saliency detection. RGBD saliency detection model focuses on extracting the salient regions from RGBD images by combining the depth information. Co-saliency detection model introduces the inter-image correspondence constraint to discover the common salient object in an image group. The goal of video saliency detection model is to locate the motion-related salient object in video sequences, which considers the motion cue and spatiotemporal constraint jointly. In this paper, we review different types of saliency detection algorithms, summarize the important issues of the existing methods, and discuss the existent problems and future works. Moreover, the evaluation datasets and quantitative measurements are briefly introduced, and the experimental analysis and discission are conducted to provide a holistic overview of different saliency detection methods.
Sliced Wasserstein Generative Models
Apr 13, 2019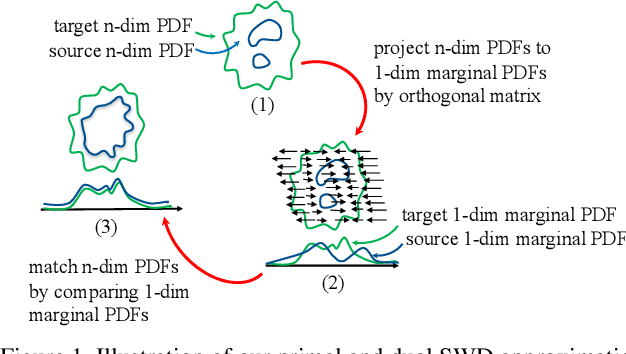
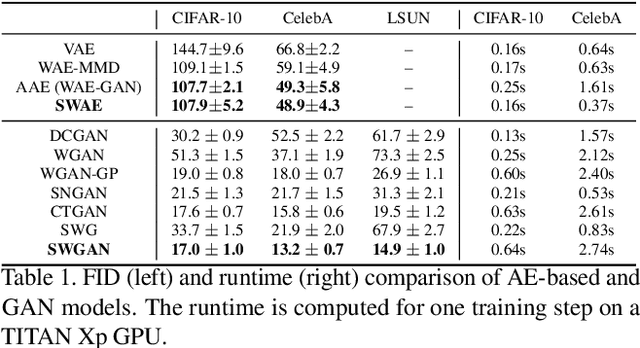
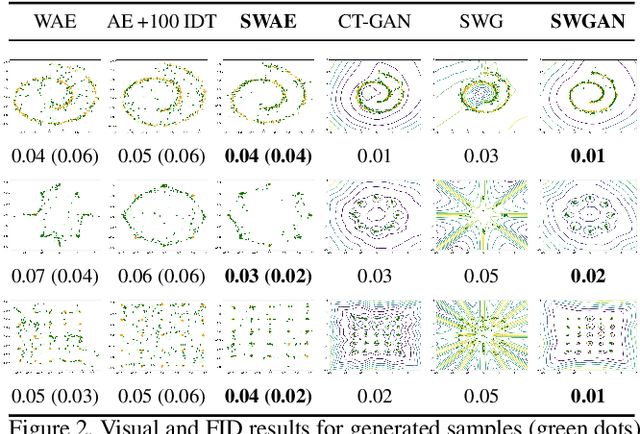
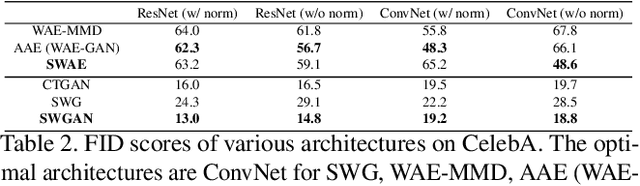
In generative modeling, the Wasserstein distance (WD) has emerged as a useful metric to measure the discrepancy between generated and real data distributions. Unfortunately, it is challenging to approximate the WD of high-dimensional distributions. In contrast, the sliced Wasserstein distance (SWD) factorizes high-dimensional distributions into their multiple one-dimensional marginal distributions and is thus easier to approximate. In this paper, we introduce novel approximations of the primal and dual SWD. Instead of using a large number of random projections, as it is done by conventional SWD approximation methods, we propose to approximate SWDs with a small number of parameterized orthogonal projections in an end-to-end deep learning fashion. As concrete applications of our SWD approximations, we design two types of differentiable SWD blocks to equip modern generative frameworks---Auto-Encoders (AE) and Generative Adversarial Networks (GAN). In the experiments, we not only show the superiority of the proposed generative models on standard image synthesis benchmarks, but also demonstrate the state-of-the-art performance on challenging high resolution image and video generation in an unsupervised manner.