 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deviation Based Pooling Strategies For Full Reference Image Quality Assessment
May 06, 2015
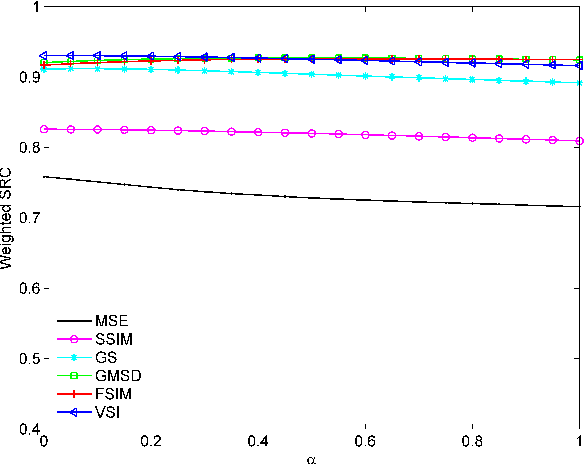
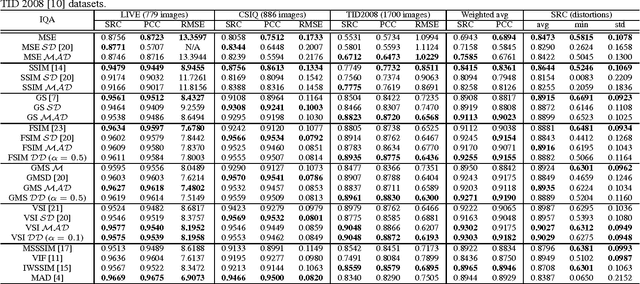
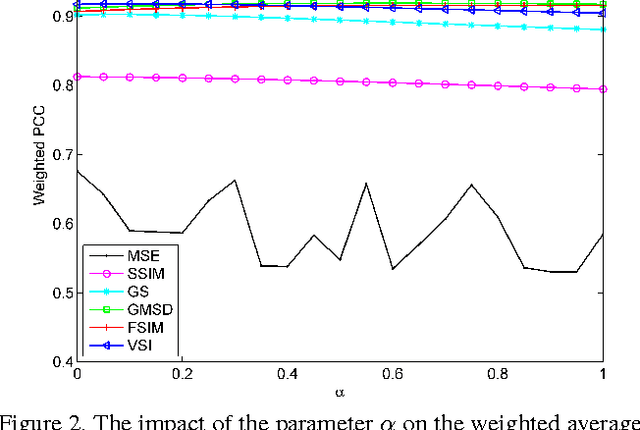
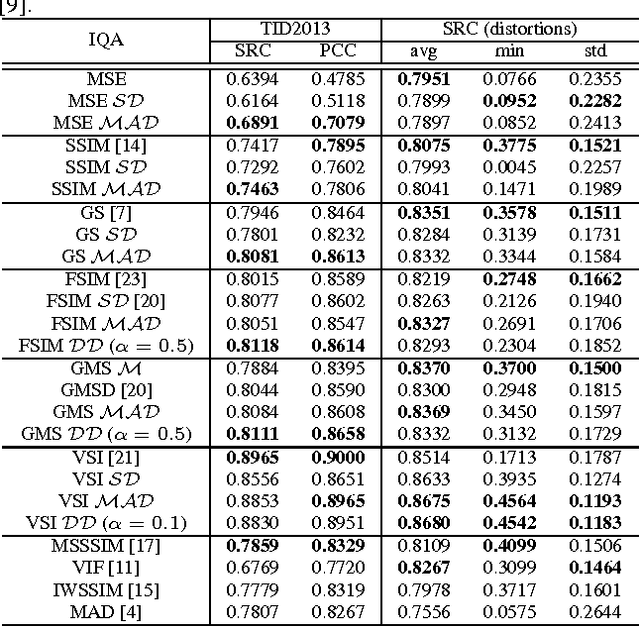
The state-of-the-art pooling strategies for perceptual image quality assessment (IQA) are based on the mean and the weighted mean. They are robust pooling strategies which usually provide a moderate to high performance for different IQAs. Recently, standard deviation (SD) pooling was also proposed. Although, this deviation pooling provides a very high performance for a few IQAs, its performance is lower than mean poolings for many other IQAs. In this paper, we propose to use the mean absolute deviation (MAD) and show that it is a more robust and accurate pooling strategy for a wider range of IQAs. In fact, MAD pooling has the advantages of both mean pooling and SD pooling. The joint computation and use of the MAD and SD pooling strategies is also considered in this paper. Experimental results provide useful information on the choice of the proper deviation pooling strategy for different IQA models.
Optimal Transport Based Generative Autoencoders
Oct 16, 2019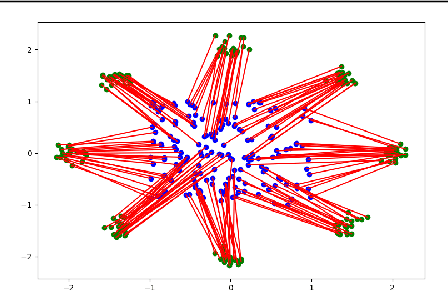
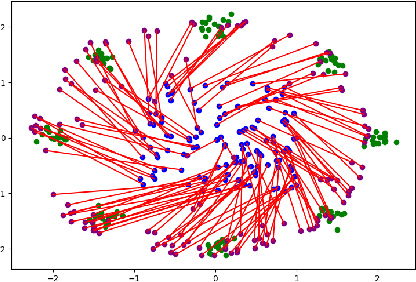
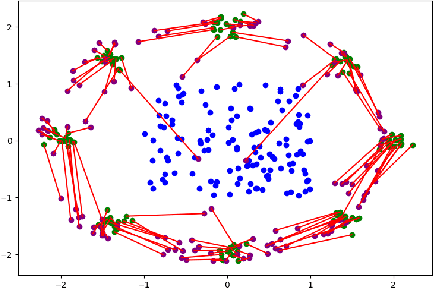

The field of deep generative modeling is dominated by generative adversarial networks (GANs). However, the training of GANs often lacks stability, fails to converge, and suffers from model collapse. It takes an assortment of tricks to solve these problems, which may be difficult to understand for those seeking to apply generative modeling. Instead, we propose two novel generative autoencoders, AE-OTtrans and AE-OTgen, which rely on optimal transport instead of adversarial training. AE-OTtrans and AEOTgen, unlike VAE and WAE, preserve the manifold of the data; they do not force the latent distribution to match a normal distribution, resulting in greater quality images. AEOTtrans and AE-OTgen also produce images of higher diversity compared to their predecessor, AE-OT. We show that AE-OTtrans and AE-OTgen surpass GANs in the MNIST and FashionMNIST datasets. Furthermore, We show that AE-OTtrans and AE-OTgen do state of the art on the MNIST, FashionMNIST, and CelebA image sets comapred to other non-adversarial generative models.
pISTA-SENSE-ResNet for Parallel MRI Reconstruction
Sep 24, 2019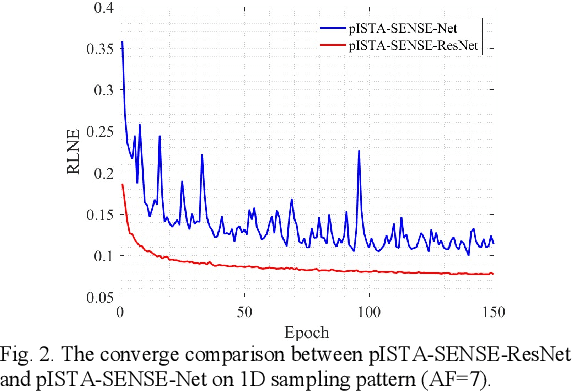
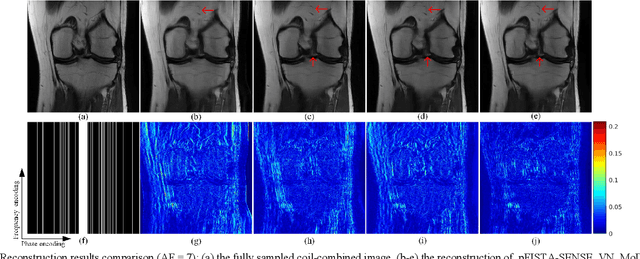
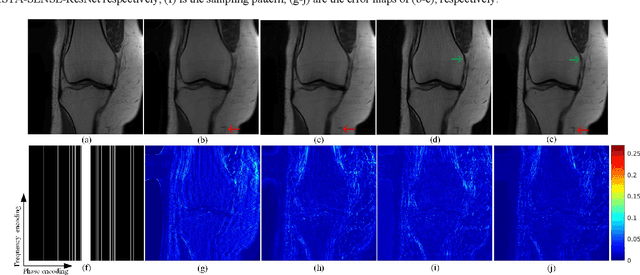
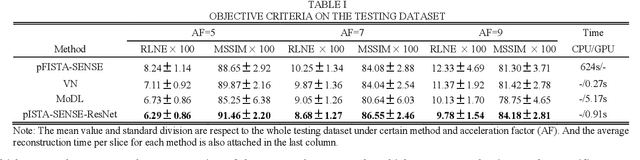
Magnetic resonance imaging has been widely applied in clinical diagnosis, however, is limited by its long data acquisition time. Although imaging can be accelerated by sparse sampling and parallel imaging, achieving promising reconstruction images with a fast reconstruction speed remains a challenge. Recently, deep learning approaches have attracted a lot of attention for its encouraging reconstruction results but without a proper interpretability. In this letter, to enable high-quality image reconstruction for the parallel magnetic resonance imaging, we design the network structure from the perspective of sparse iterative reconstruction and enhance it with the residual structure. The experimental results of a public knee dataset show that compared with the optimization-based method and the latest deep learning parallel imaging methods, the proposed network has less error in reconstruction and is more stable under different acceleration factors.
Central Similarity Hashing via Hadamard matrix
Aug 01, 2019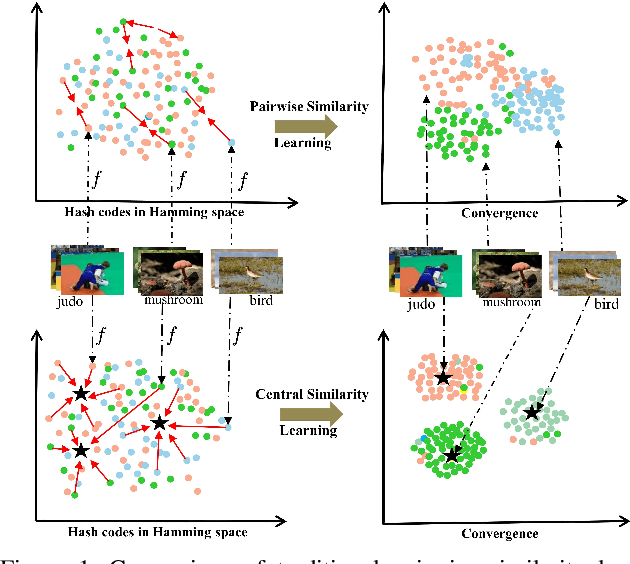
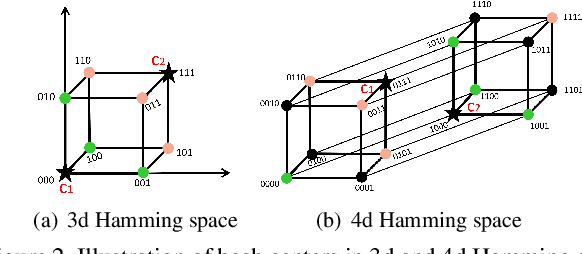
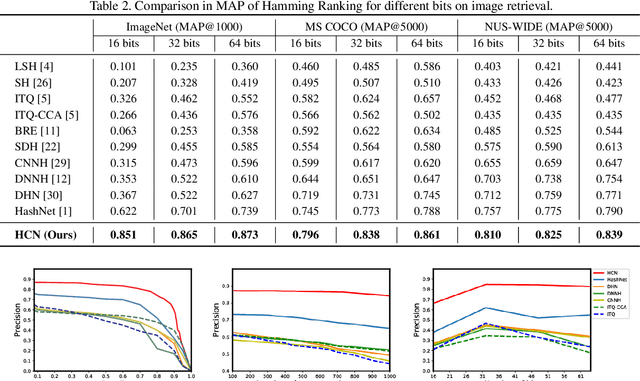
Hashing has been widely used for efficient large-scale multimedia data retrieval. Most existing methods learn hashing functions from data pairwise similarity to generate binary hash codes. However, in practice we find only learning from the local relationships of pairwise similarity cannot capture the global distribution of large-scale data, which would degrade the discriminability of the generated hash codes and harm the retrieval performance. To overcome this limitation, we propose a new global similarity metric, termed as \emph{central similarity}, to learn better hashing functions. The target of central similarity learning is to encourage hash codes for similar data pairs to be close to a common center and those for dissimilar pairs to converge to different centers in the Hamming space, which substantially improves retrieval accuracy. In order to principally formulate the central similarity learning, we define a new concept, \emph{hash center}, to be a set of points scattered in the Hamming space with a sufficient distance between each other, and propose to use Hadamard matrix to construct high-quality hash centers efficiently. Based on these definitions and designs, we devise a new hash center network (HCN) that learns hashing functions by optimizing the central similarity w.r.t.\ these hash centers. The central similarity learning and HCN are generic and can be applied for both image and video hashing. Extensive experiments for both image and video retrieval demonstrate HCN can generate cohesive hash codes for similar data pairs and dispersed hash codes for dissimilar pairs, and achieve noticeable boost in retrieval performance, i.e. 4\%-13\% in MAP over latest state-of-the-arts. The codes are in: \url{https://github.com/yuanli2333/Hadamard-Matrix-for-hashing}
SuperTML: Two-Dimensional Word Embedding and Transfer Learning Using ImageNet Pretrained CNN Models for the Classifications on Tabular Data
Mar 22, 2019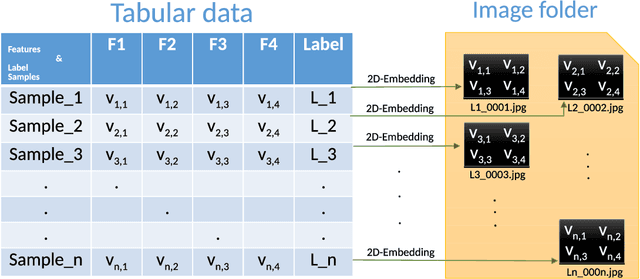


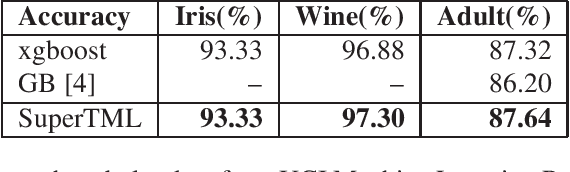
Tabular data is the most commonly used form of data in industry. Gradient Boosting Trees, Support Vector Machine, Random Forest, and Logistic Regression are typically used for classification tasks on tabular data. DNN models using categorical embeddings are also applied in this task, but all attempts thus far have used one-dimensional embeddings. The recent work of Super Characters method using two-dimensional word embeddings achieved the state of art result in text classification tasks, showcasing the promise of this new approach. In this paper, we propose the SuperTML method, which borrows the idea of Super Characters method and two-dimensional embeddings to address the problem of classification on tabular data. For each input of tabular data, the features are first projected into two-dimensional embeddings like an image, and then this image is fed into fine-tuned two-dimensional CNN models for classification. Experimental results have shown that the proposed SuperTML method had achieved state-of-the-art results on both large and small datasets.
Offline handwritten mathematical symbol recognition utilising deep learning
Oct 16, 2019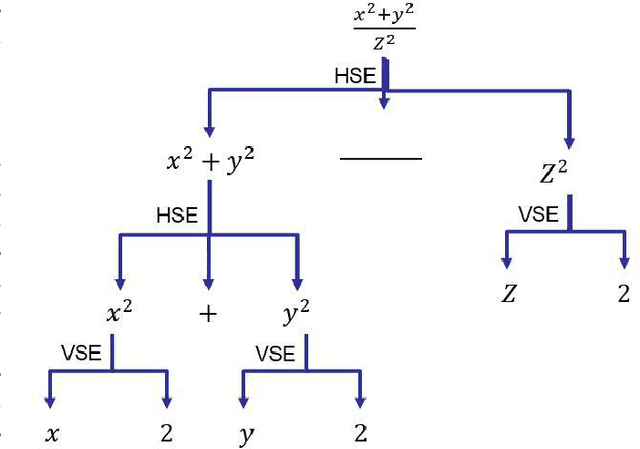
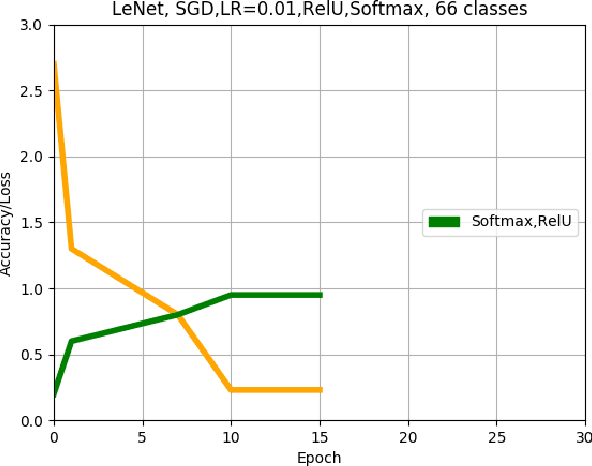
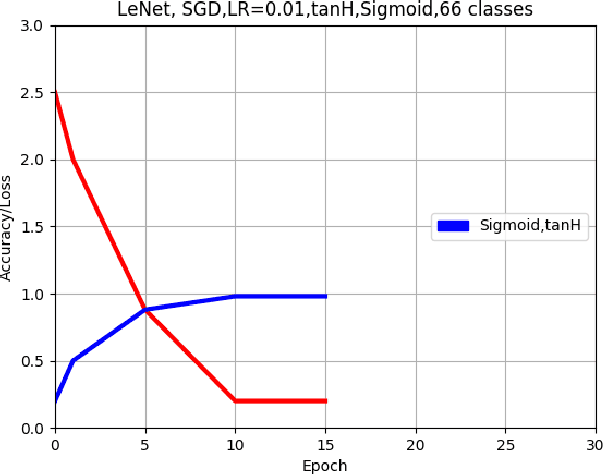
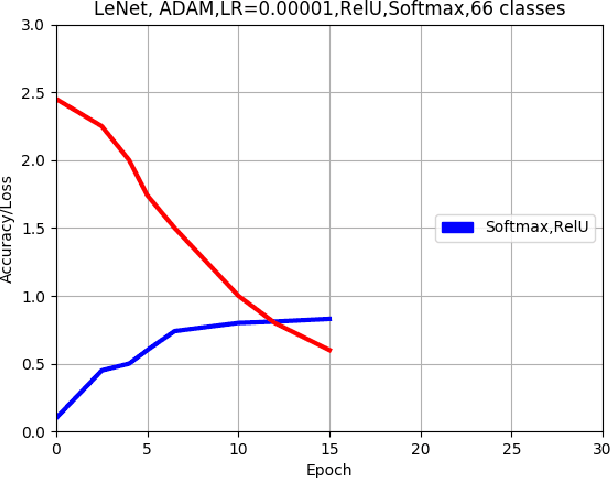
This paper describes an approach for offline recognition of handwritten mathematical symbols. The process of symbol recognition in this paper includes symbol segmentation and accurate classification for over 300 classes. Many multidimensional mathematical symbols need both horizontal and vertical projection to be segmented. However, some symbols do not permit to be projected and stop segmentation, such as the root symbol. Besides, many mathematical symbols are structurally similar, specifically in handwritten such as 0 and null. There are more than 300 Mathematical symbols. Therefore, designing an accurate classifier for more than 300 classes is required. This paper initially addresses the issue regarding segmentation using Simple Linear Iterative Clustering (SLIC). Experimental results indicate that the accuracy of the designed kNN classifier is 84% for salient, 57% Histogram of Oriented Gradient (HOG), 53% for Linear Binary Pattern (LBP) and finally 43% for pixel intensity of raw image for 66 classes. 87 classes using modified LeNet represents 90% accuracy. Finally, for 101 classes, SqueezeNet ac
BooVAE: A scalable framework for continual VAE learning under boosting approach
Aug 30, 2019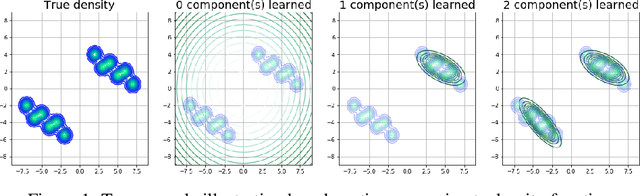
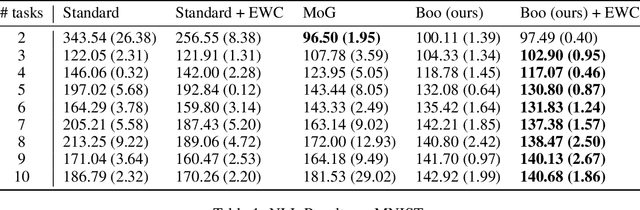
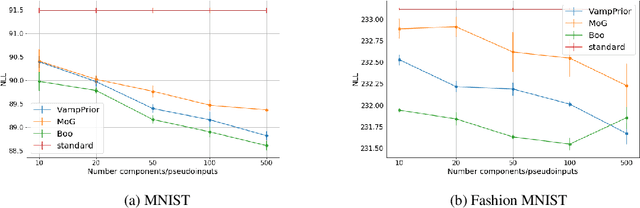
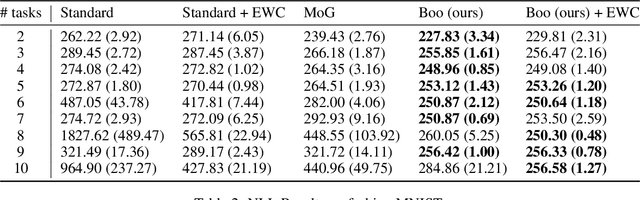
Variational Auto Encoders (VAE) are capable of generating realistic images, sounds and video sequences. From practitioners point of view, we are usually interested in solving problems where tasks are learned sequentially, in a way that avoids revisiting all previous data at each stage. We address this problem by introducing a conceptually simple and scalable end-to-end approach of incorporating past knowledge by learning prior directly from the data. We consider scalable boosting-like approximation for intractable theoretical optimal prior. We provide empirical studies on two commonly used benchmarks, namely MNIST and Fashion MNIST on disjoint sequential image generation tasks. For each dataset proposed method delivers the best results or comparable to SOTA, avoiding catastrophic forgetting in a fully automatic way.
More Knowledge is Better: Cross-Modality Volume Completion and 3D+2D Segmentation for Intracardiac Echocardiography Contouring
Dec 09, 2018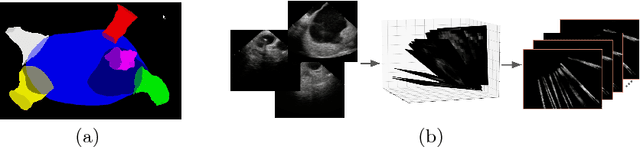
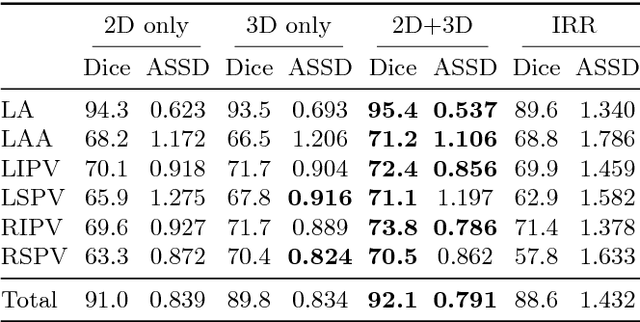
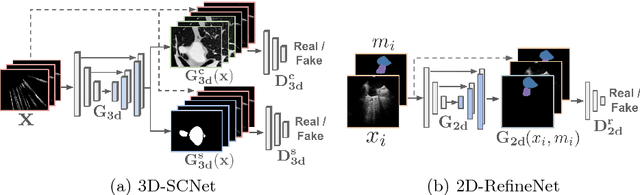
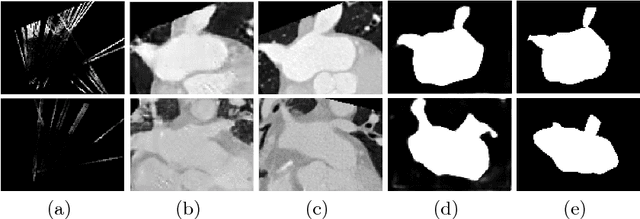
Using catheter ablation to treat atrial fibrillation increasingly relies on intracardiac echocardiography (ICE) for an anatomical delineation of the left atrium and the pulmonary veins that enter the atrium. However, it is a challenge to build an automatic contouring algorithm because ICE is noisy and provides only a limited 2D view of the 3D anatomy. This work provides the first automatic solution to segment the left atrium and the pulmonary veins from ICE. In this solution, we demonstrate the benefit of building a cross-modality framework that can leverage a database of diagnostic images to supplement the less available interventional images. To this end, we develop a novel deep neural network approach that uses the (i) 3D geometrical information provided by a position sensor embedded in the ICE catheter and the (ii) 3D image appearance information from a set of computed tomography cardiac volumes. We evaluate the proposed approach over 11,000 ICE images collected from 150 clinical patients. Experimental results show that our model is significantly better than a direct 2D image-to-image deep neural network segmentation, especially for less-observed structures.
CNN based Multi-Instance Multi-Task Learning for Syndrome Differentiation of Diabetic Patients
Jan 19, 2019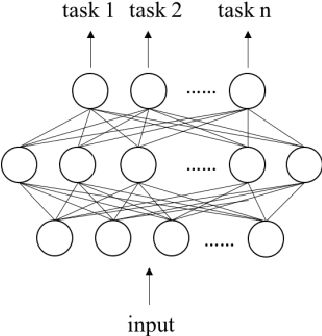
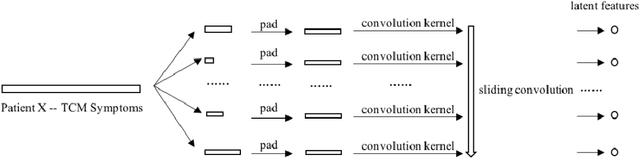

Syndrome differentiation in Traditional Chinese Medicine (TCM) is the process of understanding and reasoning body condition, which is the essential step and premise of effective treatments. However, due to its complexity and lack of standardization, it is challenging to achieve. In this study, we consider each patient's record as a one-dimensional image and symptoms as pixels, in which missing and negative values are represented by zero pixels. The objective is to find relevant symptoms first and then map them to proper syndromes, that is similar to the object detection problem in computer vision. Inspired from it, we employ multi-instance multi-task learning combined with the convolutional neural network (MIMT-CNN) for syndrome differentiation, which takes region proposals as input and output image labels directly. The neural network consists of region proposals generation, convolutional layer, fully connected layer, and max pooling (multi-instance pooling) layer followed by the sigmoid function in each syndrome prediction task for image representation learning and final results generation. On the diabetes dataset, it performs better than all other baseline methods. Moreover, it shows stability and reliability to generate results, even on the dataset with small sample size, a large number of missing values and noises.
Deep Learning with Gaussian Differential Privacy
Dec 10, 2019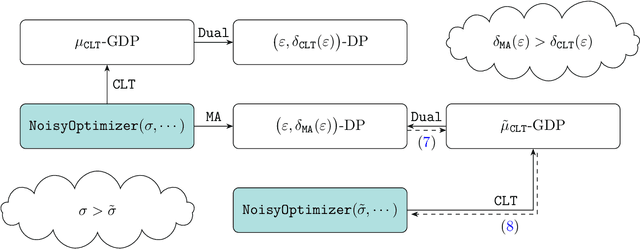
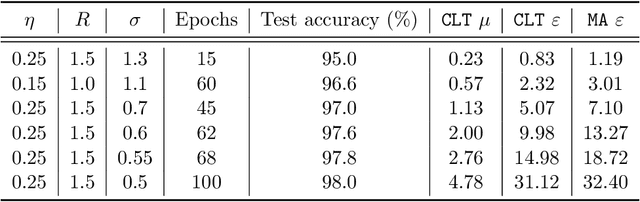
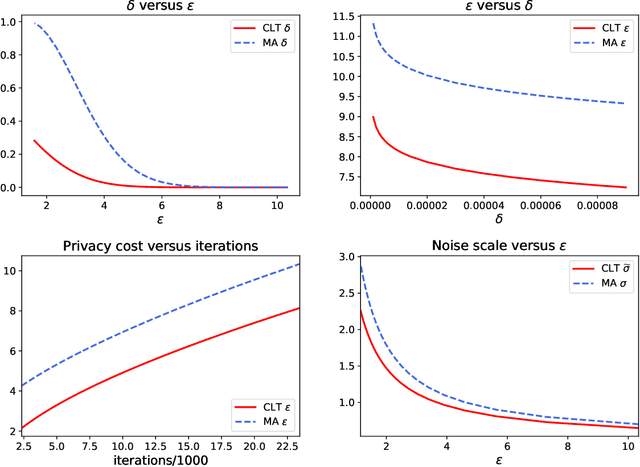
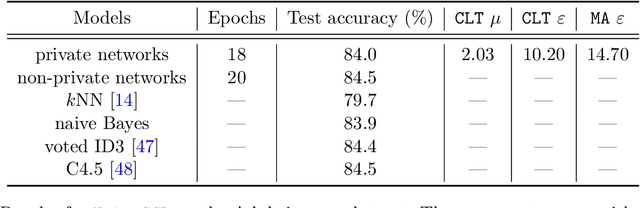
Deep learning models are often trained on datasets that contain sensitive information such as individuals' shopping transactions, personal contacts, and medical records. An increasingly important line of work therefore has sought to train neural networks subject to privacy constraints that are specified by differential privacy or its divergence-based relaxations. These privacy definitions, however, have weaknesses in handling certain important primitives (composition and subsampling), thereby giving loose or complicated privacy analyses of training neural networks. In this paper, we consider a recently proposed privacy definition termed f-differential privacy [17] for a refined privacy analysis of training neural networks. Leveraging the appealing properties of f-differential privacy in handling composition and subsampling, this paper derives analytically tractable expressions for the privacy guarantees of both stochastic gradient descent and Adam used in training deep neural networks, without the need of developing sophisticated techniques as [3] did. Our results demonstrate that the f-differential privacy framework allows for a new privacy analysis that improves on the prior analysis [3], which in turn suggests tuning certain parameters of neural networks for a better prediction accuracy without violating the privacy budget. These theoretically derived improvements are confirmed by our experiments in a range of tasks in image classification, text classification, and recommender systems.