 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Holoported Characters: Real-time Free-viewpoint Rendering of Humans from Sparse RGB Cameras
Dec 12, 2023
We present the first approach to render highly realistic free-viewpoint videos of a human actor in general apparel, from sparse multi-view recording to display, in real-time at an unprecedented 4K resolution. At inference, our method only requires four camera views of the moving actor and the respective 3D skeletal pose. It handles actors in wide clothing, and reproduces even fine-scale dynamic detail, e.g. clothing wrinkles, face expressions, and hand gestures. At training time, our learning-based approach expects dense multi-view video and a rigged static surface scan of the actor. Our method comprises three main stages. Stage 1 is a skeleton-driven neural approach for high-quality capture of the detailed dynamic mesh geometry. Stage 2 is a novel solution to create a view-dependent texture using four test-time camera views as input. Finally, stage 3 comprises a new image-based refinement network rendering the final 4K image given the output from the previous stages. Our approach establishes a new benchmark for real-time rendering resolution and quality using sparse input camera views, unlocking possibilities for immersive telepresence.
Mining Gaze for Contrastive Learning toward Computer-Assisted Diagnosis
Dec 12, 2023Obtaining large-scale radiology reports can be difficult for medical images due to various reasons, limiting the effectiveness of contrastive pre-training in the medical image domain and underscoring the need for alternative methods. In this paper, we propose eye-tracking as an alternative to text reports, as it allows for the passive collection of gaze signals without disturbing radiologist's routine diagnosis process. By tracking the gaze of radiologists as they read and diagnose medical images, we can understand their visual attention and clinical reasoning. When a radiologist has similar gazes for two medical images, it may indicate semantic similarity for diagnosis, and these images should be treated as positive pairs when pre-training a computer-assisted diagnosis (CAD) network through contrastive learning. Accordingly, we introduce the Medical contrastive Gaze Image Pre-training (McGIP) as a plug-and-play module for contrastive learning frameworks. McGIP uses radiologist's gaze to guide contrastive pre-training. We evaluate our method using two representative types of medical images and two common types of gaze data. The experimental results demonstrate the practicality of McGIP, indicating its high potential for various clinical scenarios and applications.
A Simple Recipe for Contrastively Pre-training Video-First Encoders Beyond 16 Frames
Dec 12, 2023Understanding long, real-world videos requires modeling of long-range visual dependencies. To this end, we explore video-first architectures, building on the common paradigm of transferring large-scale, image--text models to video via shallow temporal fusion. However, we expose two limitations to the approach: (1) decreased spatial capabilities, likely due to poor video--language alignment in standard video datasets, and (2) higher memory consumption, bottlenecking the number of frames that can be processed. To mitigate the memory bottleneck, we systematically analyze the memory/accuracy trade-off of various efficient methods: factorized attention, parameter-efficient image-to-video adaptation, input masking, and multi-resolution patchification. Surprisingly, simply masking large portions of the video (up to 75%) during contrastive pre-training proves to be one of the most robust ways to scale encoders to videos up to 4.3 minutes at 1 FPS. Our simple approach for training long video-to-text models, which scales to 1B parameters, does not add new architectural complexity and is able to outperform the popular paradigm of using much larger LLMs as an information aggregator over segment-based information on benchmarks with long-range temporal dependencies (YouCook2, EgoSchema).
Boosting Latent Diffusion with Flow Matching
Dec 12, 2023Recently, there has been tremendous progress in visual synthesis and the underlying generative models. Here, diffusion models (DMs) stand out particularly, but lately, flow matching (FM) has also garnered considerable interest. While DMs excel in providing diverse images, they suffer from long training and slow generation. With latent diffusion, these issues are only partially alleviated. Conversely, FM offers faster training and inference but exhibits less diversity in synthesis. We demonstrate that introducing FM between the Diffusion model and the convolutional decoder offers high-resolution image synthesis with reduced computational cost and model size. Diffusion can then efficiently provide the necessary generation diversity. FM compensates for the lower resolution, mapping the small latent space to a high-dimensional one. Subsequently, the convolutional decoder of the LDM maps these latents to high-resolution images. By combining the diversity of DMs, the efficiency of FMs, and the effectiveness of convolutional decoders, we achieve state-of-the-art high-resolution image synthesis at $1024^2$ with minimal computational cost. Importantly, our approach is orthogonal to recent approximation and speed-up strategies for the underlying DMs, making it easily integrable into various DM frameworks.
Localized Symbolic Knowledge Distillation for Visual Commonsense Models
Dec 12, 2023Instruction following vision-language (VL) models offer a flexible interface that supports a broad range of multimodal tasks in a zero-shot fashion. However, interfaces that operate on full images do not directly enable the user to "point to" and access specific regions within images. This capability is important not only to support reference-grounded VL benchmarks, but also, for practical applications that require precise within-image reasoning. We build Localized Visual Commonsense models, which allow users to specify (multiple) regions as input. We train our model by sampling localized commonsense knowledge from a large language model (LLM): specifically, we prompt an LLM to collect commonsense knowledge given a global literal image description and a local literal region description automatically generated by a set of VL models. With a separately trained critic model that selects high-quality examples, we find that training on the localized commonsense corpus can successfully distill existing VL models to support a reference-as-input interface. Empirical results and human evaluations in a zero-shot setup demonstrate that our distillation method results in more precise VL models of reasoning compared to a baseline of passing a generated referring expression to an LLM.
Hybrid Whale-Mud-Ring Optimization for Precise Color Skin Cancer Image Segmentation
Nov 22, 2023Timely identification and treatment of rapidly progressing skin cancers can significantly contribute to the preservation of patients' health and well-being. Dermoscopy, a dependable and accessible tool, plays a pivotal role in the initial stages of skin cancer detection. Consequently, the effective processing of digital dermoscopy images holds significant importance in elevating the accuracy of skin cancer diagnoses. Multilevel thresholding is a key tool in medical imaging that extracts objects within the image to facilitate its analysis. In this paper, an enhanced version of the Mud Ring Algorithm hybridized with the Whale Optimization Algorithm, named WMRA, is proposed. The proposed approach utilizes bubble-net attack and mud ring strategy to overcome stagnation in local optima and obtain optimal thresholds. The experimental results show that WMRA is powerful against a cluster of recent methods in terms of fitness, Peak Signal to Noise Ratio (PSNR), and Mean Square Error (MSE).
Atlantis: Enabling Underwater Depth Estimation with Stable Diffusion
Dec 19, 2023Monocular depth estimation has experienced significant progress on terrestrial images in recent years, largely due to deep learning advancements. However, it remains inadequate for underwater scenes, primarily because of data scarcity. Given the inherent challenges of light attenuation and backscattering in water, acquiring clear underwater images or precise depth information is notably difficult and costly. Consequently, learning-based approaches often rely on synthetic data or turn to unsupervised or self-supervised methods to mitigate this lack of data. Nonetheless, the performance of these methods is often constrained by the domain gap and looser constraints. In this paper, we propose a novel pipeline for generating photorealistic underwater images using accurate terrestrial depth data. This approach facilitates the training of supervised models for underwater depth estimation, effectively reducing the performance disparity between terrestrial and underwater environments. Contrary to prior synthetic datasets that merely apply style transfer to terrestrial images without altering the scene content, our approach uniquely creates vibrant, non-existent underwater scenes by leveraging terrestrial depth data through the innovative Stable Diffusion model. Specifically, we introduce a unique Depth2Underwater ControlNet, trained on specially prepared \{Underwater, Depth, Text\} data triplets, for this generation task. Our newly developed dataset enables terrestrial depth estimation models to achieve considerable improvements, both quantitatively and qualitatively, on unseen underwater images, surpassing their terrestrial pre-trained counterparts. Moreover, the enhanced depth accuracy for underwater scenes also aids underwater image restoration techniques that rely on depth maps, further demonstrating our dataset's utility. The dataset will be available at https://github.com/zkawfanx/Atlantis.
Land use/land cover classification of fused Sentinel-1 and Sentinel-2 imageries using ensembles of Random Forests
Dec 19, 2023The study explores the synergistic combination of Synthetic Aperture Radar (SAR) and Visible-Near Infrared-Short Wave Infrared (VNIR-SWIR) imageries for land use/land cover (LULC) classification. Image fusion, employing Bayesian fusion, merges SAR texture bands with VNIR-SWIR imageries. The research aims to investigate the impact of this fusion on LULC classification. Despite the popularity of random forests for supervised classification, their limitations, such as suboptimal performance with fewer features and accuracy stagnation, are addressed. To overcome these issues, ensembles of random forests (RFE) are created, introducing random rotations using the Forest-RC algorithm. Three rotation approaches: principal component analysis (PCA), sparse random rotation (SRP) matrix, and complete random rotation (CRP) matrix are employed. Sentinel-1 SAR data and Sentinel-2 VNIR-SWIR data from the IIT-Kanpur region constitute the training datasets, including SAR, SAR with texture, VNIR-SWIR, VNIR-SWIR with texture, and fused VNIR-SWIR with texture. The study evaluates classifier efficacy, explores the impact of SAR and VNIR-SWIR fusion on classification, and significantly enhances the execution speed of Bayesian fusion code. The SRP-based RFE outperforms other ensembles for the first two datasets, yielding average overall kappa values of 61.80% and 68.18%, while the CRP-based RFE excels for the last three datasets with average overall kappa values of 95.99%, 96.93%, and 96.30%. The fourth dataset achieves the highest overall kappa of 96.93%. Furthermore, incorporating texture with SAR bands results in a maximum overall kappa increment of 10.00%, while adding texture to VNIR-SWIR bands yields a maximum increment of approximately 3.45%.
Self-Guided Open-Vocabulary Semantic Segmentation
Dec 07, 2023Vision-Language Models (VLMs) have emerged as promising tools for open-ended image understanding tasks, including open vocabulary segmentation. Yet, direct application of such VLMs to segmentation is non-trivial, since VLMs are trained with image-text pairs and naturally lack pixel-level granularity. Recent works have made advancements in bridging this gap, often by leveraging the shared image-text space in which the image and a provided text prompt are represented. In this paper, we challenge the capabilities of VLMs further and tackle open-vocabulary segmentation without the need for any textual input. To this end, we propose a novel Self-Guided Semantic Segmentation (Self-Seg) framework. Self-Seg is capable of automatically detecting relevant class names from clustered BLIP embeddings and using these for accurate semantic segmentation. In addition, we propose an LLM-based Open-Vocabulary Evaluator (LOVE) to effectively assess predicted open-vocabulary class names. We achieve state-of-the-art results on Pascal VOC, ADE20K and CityScapes for open-vocabulary segmentation without given class names, as well as competitive performance with methods where class names are given. All code and data will be released.
Steal My Artworks for Fine-tuning? A Watermarking Framework for Detecting Art Theft Mimicry in Text-to-Image Models
Nov 22, 2023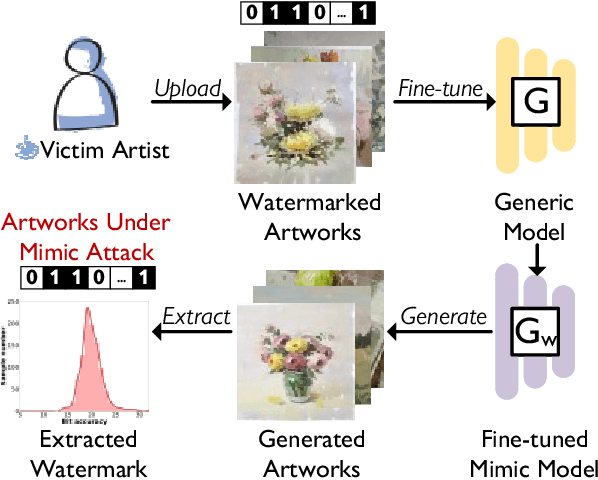
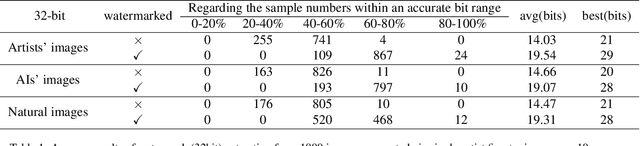
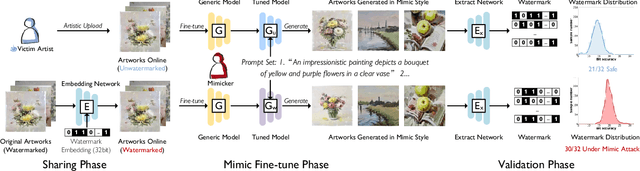
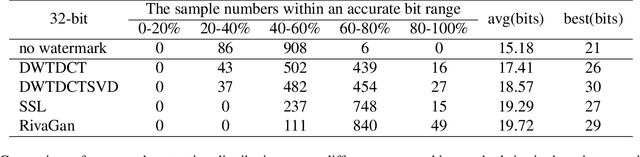
The advancement in text-to-image models has led to astonishing artistic performances. However, several studios and websites illegally fine-tune these models using artists' artworks to mimic their styles for profit, which violates the copyrights of artists and diminishes their motivation to produce original works. Currently, there is a notable lack of research focusing on this issue. In this paper, we propose a novel watermarking framework that detects mimicry in text-to-image models through fine-tuning. This framework embeds subtle watermarks into digital artworks to protect their copyrights while still preserving the artist's visual expression. If someone takes watermarked artworks as training data to mimic an artist's style, these watermarks can serve as detectable indicators. By analyzing the distribution of these watermarks in a series of generated images, acts of fine-tuning mimicry using stolen victim data will be exposed. In various fine-tune scenarios and against watermark attack methods, our research confirms that analyzing the distribution of watermarks in artificially generated images reliably detects unauthorized mimicry.