 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Augmenting Supervised Neural Networks with Unsupervised Objectives for Large-scale Image Classification
Jun 21, 2016
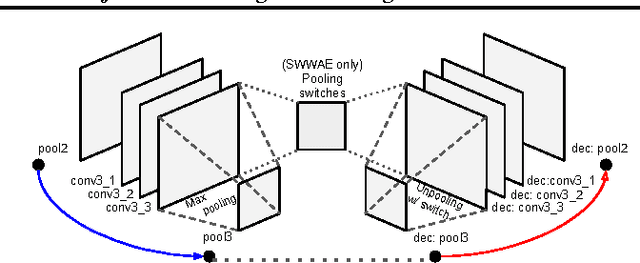
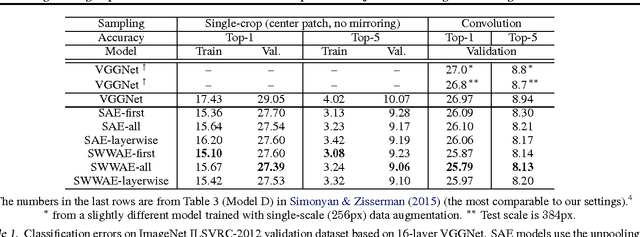
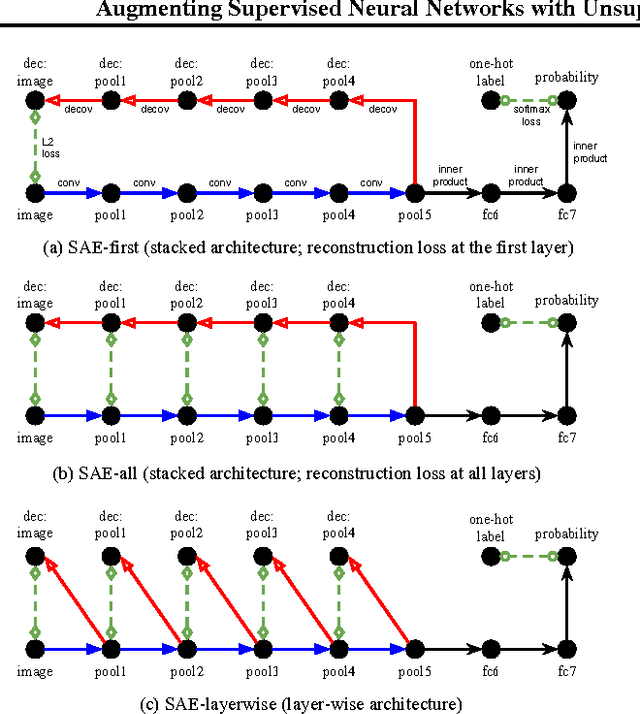
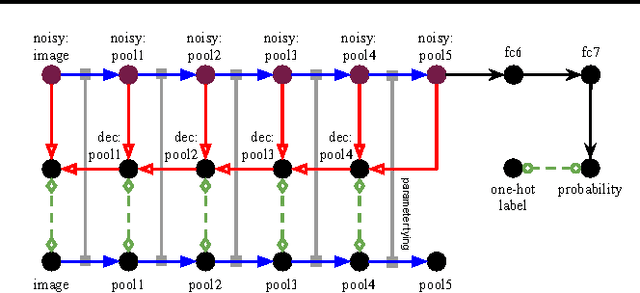
Unsupervised learning and supervised learning are key research topics in deep learning. However, as high-capacity supervised neural networks trained with a large amount of labels have achieved remarkable success in many computer vision tasks, the availability of large-scale labeled images reduced the significance of unsupervised learning. Inspired by the recent trend toward revisiting the importance of unsupervised learning, we investigate joint supervised and unsupervised learning in a large-scale setting by augmenting existing neural networks with decoding pathways for reconstruction. First, we demonstrate that the intermediate activations of pretrained large-scale classification networks preserve almost all the information of input images except a portion of local spatial details. Then, by end-to-end training of the entire augmented architecture with the reconstructive objective, we show improvement of the network performance for supervised tasks. We evaluate several variants of autoencoders, including the recently proposed "what-where" autoencoder that uses the encoder pooling switches, to study the importance of the architecture design. Taking the 16-layer VGGNet trained under the ImageNet ILSVRC 2012 protocol as a strong baseline for image classification, our methods improve the validation-set accuracy by a noticeable margin.
* International Conference on Machine Learning (ICML), 2016
Bipartite Conditional Random Fields for Panoptic Segmentation
Dec 11, 2019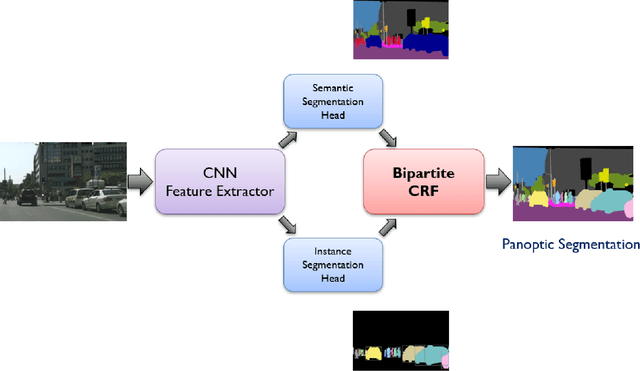
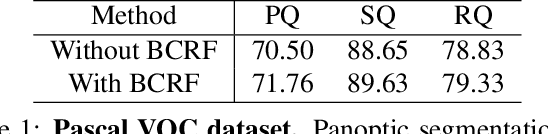
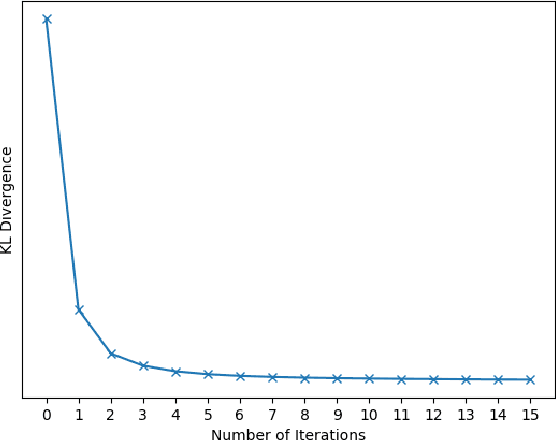

We tackle the panoptic segmentation problem with a conditional random field (CRF) model. Panoptic segmentation involves assigning a semantic label and an instance label to each pixel of a given image. At each pixel, the semantic label and the instance label should be compatible. Furthermore, a good panoptic segmentation should have a number of other desirable properties such as the spatial and color consistency of the labeling (similar looking neighboring pixels should have the same semantic label and the instance label). To tackle this problem, we propose a CRF model, named Bipartite CRF or BCRF, with two types of random variables for semantic and instance labels. In this formulation, various energies are defined within and across the two types of random variables to encourage a consistent panoptic segmentation. We propose a mean-field-based efficient inference algorithm for solving the CRF and empirically show its convergence properties. This algorithm is fully differentiable, and therefore, BCRF inference can be included as a trainable module in a deep network. In the experimental evaluation, we quantitatively and qualitatively show that the BCRF yields superior panoptic segmentation results in practice.
Learning Multi-Human Optical Flow
Oct 24, 2019
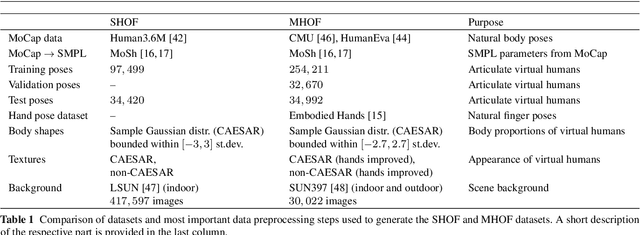
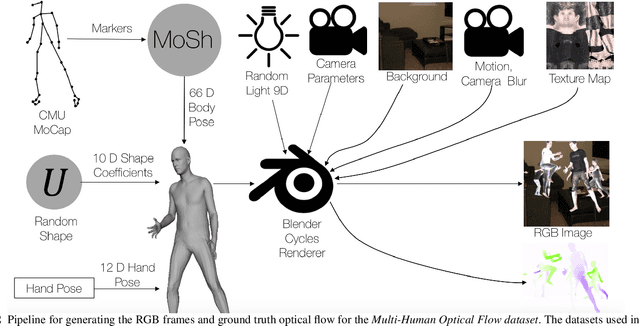
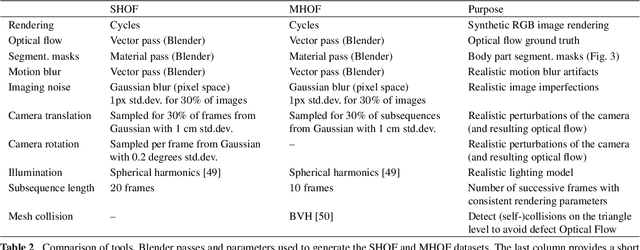
The optical flow of humans is well known to be useful for the analysis of human action. Recent optical flow methods focus on training deep networks to approach the problem. However, the training data used by them does not cover the domain of human motion. Therefore, we develop a dataset of multi-human optical flow and train optical flow networks on this dataset. We use a 3D model of the human body and motion capture data to synthesize realistic flow fields in both single- and multi-person images. We then train optical flow networks to estimate human flow fields from pairs of images. We demonstrate that our trained networks are more accurate than a wide range of top methods on held-out test data and that they can generalize well to real image sequences. The code, trained models and the dataset are available for research.
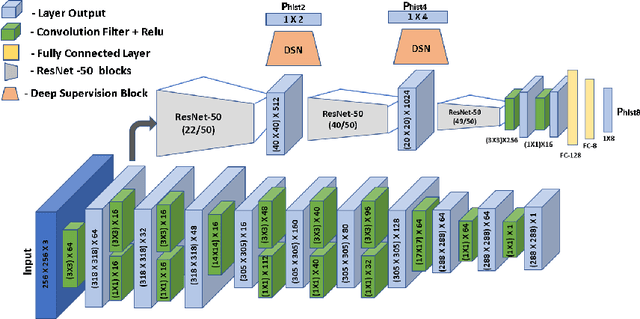
Cross-Spectrum Dual-Subspace Pairing for RGB-infrared Cross-Modality Person Re-Identification
Feb 29, 2020

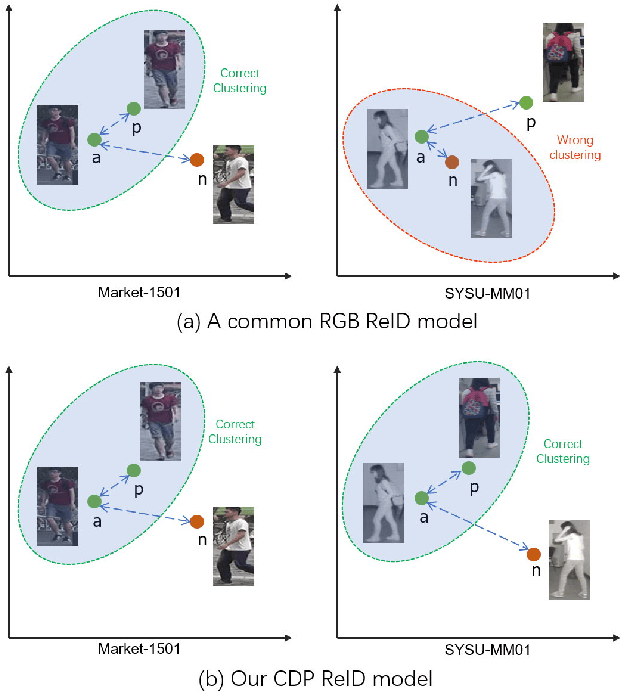

Due to its potential wide applications in video surveillance and other computer vision tasks like tracking, person re-identification (ReID) has become popular and been widely investigated. However, conventional person re-identification can only handle RGB color images, which will fail at dark conditions. Thus RGB-infrared ReID (also known as Infrared-Visible ReID or Visible-Thermal ReID) is proposed. Apart from appearance discrepancy in traditional ReID caused by illumination, pose variations and viewpoint changes, modality discrepancy produced by cameras of the different spectrum also exists, which makes RGB-infrared ReID more difficult. To address this problem, we focus on extracting the shared cross-spectrum features of different modalities. In this paper, a novel multi-spectrum image generation method is proposed and the generated samples are utilized to help the network to find discriminative information for re-identifying the same person across modalities. Another challenge of RGB-infrared ReID is that the intra-person (images from the same person) discrepancy is often larger than the inter-person (images from different persons) discrepancy, so a dual-subspace pairing strategy is proposed to alleviate this problem. Combining those two parts together, we also design a one-stream neural network combining the aforementioned methods to extract compact representations of person images, called Cross-spectrum Dual-subspace Pairing (CDP) model. Furthermore, during the training process, we also propose a Dynamic Hard Spectrum Mining method to automatically mine more hard samples from hard spectrum based on the current model state to further boost the performance. Extensive experimental results on two public datasets, SYSU-MM01 with RGB + near-infrared images and RegDB with RGB + far-infrared images, have demonstrated the efficiency and generality of our proposed method.
HistoNet: Predicting size histograms of object instances
Dec 11, 2019


We propose to predict histograms of object sizes in crowded scenes directly without any explicit object instance segmentation. What makes this task challenging is the high density of objects (of the same category), which makes instance identification hard. Instead of explicitly segmenting object instances, we show that directly learning histograms of object sizes improves accuracy while using drastically less parameters. This is very useful for application scenarios where explicit, pixel-accurate instance segmentation is not needed, but there lies interest in the overall distribution of instance sizes. Our core applications are in biology, where we estimate the size distribution of soldier fly larvae, and medicine, where we estimate the size distribution of cancer cells as an intermediate step to calculate the tumor cellularity score. Given an image with hundreds of small object instances, we output the total count and the size histogram. We also provide a new data set for this task, the FlyLarvae data set, which consists of 11,000 larvae instances labeled pixel-wise. Our method results in an overall improvement in the count and size distribution prediction as compared to state-of-the-art instance segmentation method Mask R-CNN.
Advanced Capsule Networks via Context Awareness
Apr 02, 2019
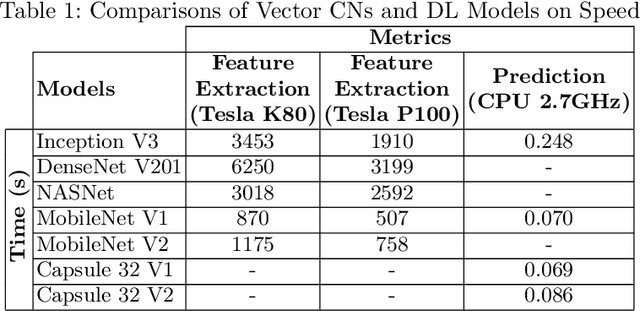
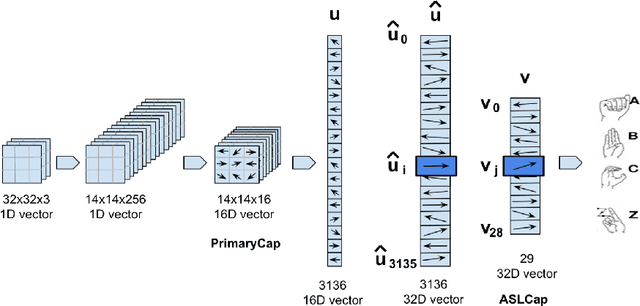
Capsule Networks (CN) offer new architectures for Deep Learning (DL) community. Though its effectiveness has been demonstrated in MNIST and smallNORB datasets, the networks still face challenges in other datasets for images with distinct contexts. In this research, we improve the design of CN (Vector version) namely we expand more Pooling layers to filter image backgrounds and increase Reconstruction layers to make better image restoration. Additionally, we perform experiments to compare accuracy and speed of CN versus DL models. In DL models, we utilize Inception V3 and DenseNet V201 for powerful computers besides NASNet, MobileNet V1 and MobileNet V2 for small and embedded devices. We evaluate our models on a fingerspelling alphabet dataset from American Sign Language (ASL). The results show that CNs perform comparably to DL models while dramatically reducing training time. We also make a demonstration and give a link for the purpose of illustration.
Edge-Semantic Learning Strategy for Layout Estimation in Indoor Environment
Jan 03, 2019

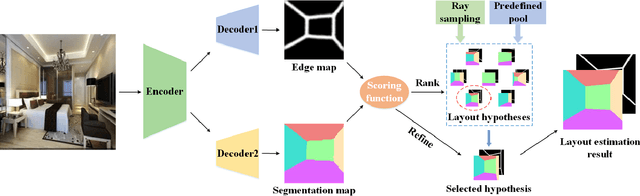
Visual cognition of the indoor environment can benefit from the spatial layout estimation, which is to represent an indoor scene with a 2D box on a monocular image. In this paper, we propose to fully exploit the edge and semantic information of a room image for layout estimation. More specifically, we present an encoder-decoder network with shared encoder and two separate decoders, which are composed of multiple deconvolution (transposed convolution) layers, to jointly learn the edge maps and semantic labels of a room image. We combine these two network predictions in a scoring function to evaluate the quality of the layouts, which are generated by ray sampling and from a predefined layout pool. Guided by the scoring function, we apply a novel refinement strategy to further optimize the layout hypotheses. Experimental results show that the proposed network can yield accurate estimates of edge maps and semantic labels. By fully utilizing the two different types of labels, the proposed method achieves state-of-the-art layout estimation performance on benchmark datasets.
ORSIm Detector: A Novel Object Detection Framework in Optical Remote Sensing Imagery Using Spatial-Frequency Channel Features
Jan 23, 2019
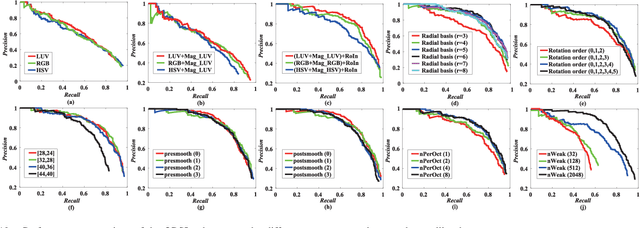
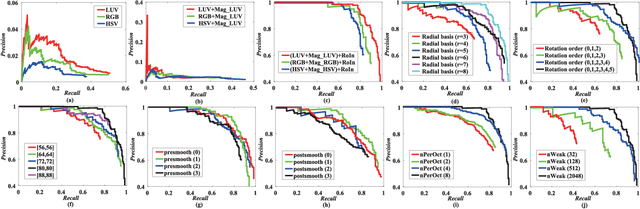
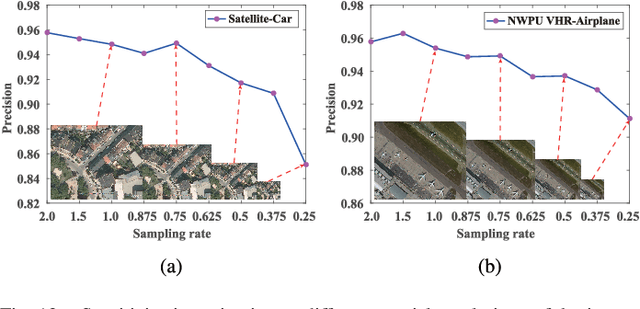
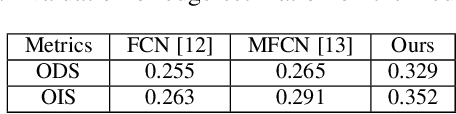
With the rapid development of spaceborne imaging techniques, object detection in optical remote sensing imagery has drawn much attention in recent decades. While many advanced works have been developed with powerful learning algorithms, the incomplete feature representation still cannot meet the demand for effectively and efficiently handling image deformations, particularly objective scaling and rotation. To this end, we propose a novel object detection framework, called optical remote sensing imagery detector (ORSIm detector), integrating diverse channel features extraction, feature learning, fast image pyramid matching, and boosting strategy. ORSIm detector adopts a novel spatial-frequency channel feature (SFCF) by jointly considering the rotation-invariant channel features constructed in frequency domain and the original spatial channel features (e.g., color channel, gradient magnitude). Subsequently, we refine SFCF using learning-based strategy in order to obtain the high-level or semantically meaningful features. In the test phase, we achieve a fast and coarsely-scaled channel computation by mathematically estimating a scaling factor in the image domain. Extensive experimental results conducted on the two different airborne datasets are performed to demonstrate the superiority and effectiveness in comparison with previous state-of-the-art methods.
Deep Visual City Recognition Visualization
May 06, 2019

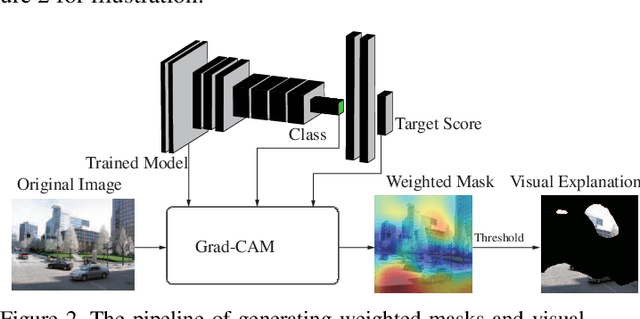
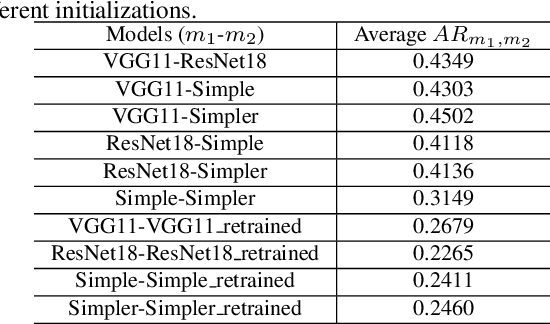
Understanding how cities visually differ from each others is interesting for planners, residents, and historians. We investigate the interpretation of deep features learned by convolutional neural networks (CNNs) for city recognition. Given a trained city recognition network, we first generate weighted masks using the known Grad-CAM technique and to select the most discriminate regions in the image. Since the image classification label is the city name, it contains no information of objects that are class-discriminate, we investigate the interpretability of deep representations with two methods. (i) Unsupervised method is used to cluster the objects appearing in the visual explanations. (ii) A pretrained semantic segmentation model is used to label objects in pixel level, and then we introduce statistical measures to quantitatively evaluate the interpretability of discriminate objects. The influence of network architectures and random initializations in training, is studied on the interpretability of CNN features for city recognition. The results suggest that network architectures would affect the interpretability of learned visual representations greater than different initializations.
An Improving Framework of regularization for Network Compression
Dec 11, 2019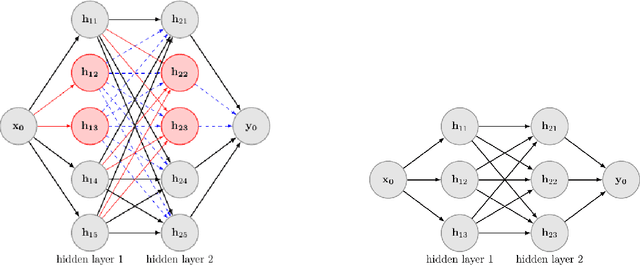
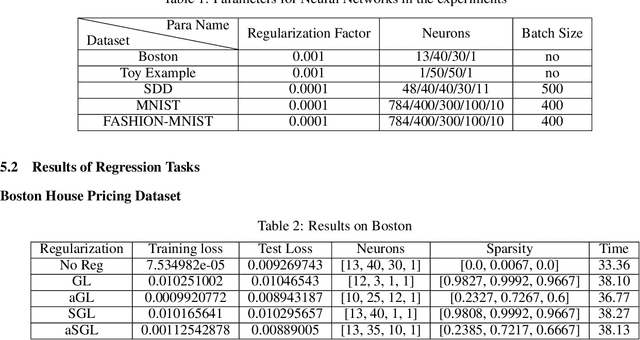

Deep Neural Networks have achieved remarkable success relying on the developing high computation capability of GPUs and large-scale datasets with increasing network depth and width in image recognition, object detection and many other applications. However, due to the expensive computation and intensive memory, researchers have concentrated on designing compression methods in recent years. In this paper, we briefly summarize the existing advanced techniques that are useful in model compression at first. After that, we give a detailed description on group lasso regularization and its variants. More importantly, we propose an improving framework of partial regularization based on the relationship between neurons and connections of adjacent layers. It is reasonable and feasible with the help of permutation property of neural network . Experiment results show that partial regularization methods brings improvements such as higher classification accuracy in both training and testing stages on multiple datasets. Since our regularizers contain the computation of less parameters, it shows competitive performances in terms of the total running time of experiments. Finally, we analysed the results and draw a conclusion that the optimal network structure must exist and depend on the input data.