 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Reduced Reference Image Quality Measure Using Bessel K Forms Model for Tetrolet Coefficients
Dec 18, 2011
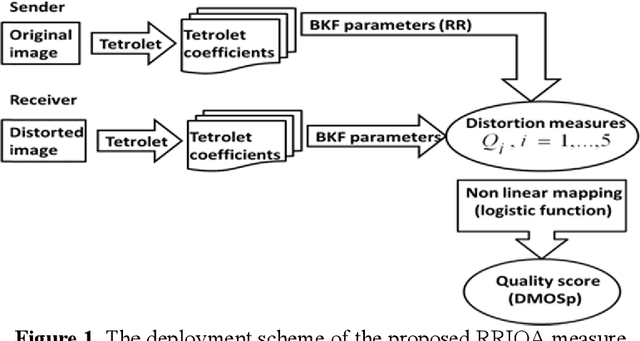
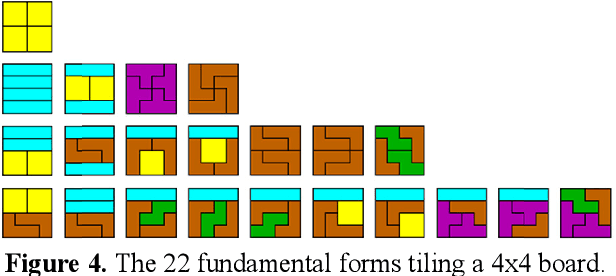
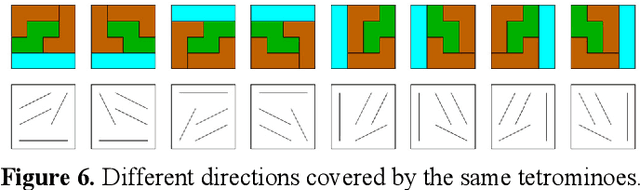
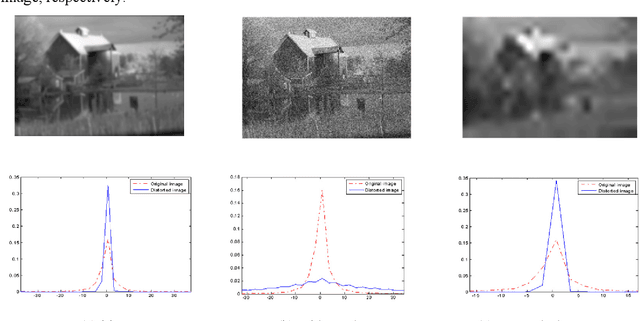
In this paper, we introduce a Reduced Reference Image Quality Assessment (RRIQA) measure based on the natural image statistic approach. A new adaptive transform called "Tetrolet" is applied to both reference and distorted images. To model the marginal distribution of tetrolet coefficients Bessel K Forms (BKF) density is proposed. Estimating the parameters of this distribution allows to summarize the reference image with a small amount of side information. Five distortion measures based on the BKF parameters of the original and processed image are used to predict quality scores. A comparison between these measures is presented showing a good consistency with human judgment.
Semantic Fisher Scores for Task Transfer: Using Objects to Classify Scenes
May 27, 2019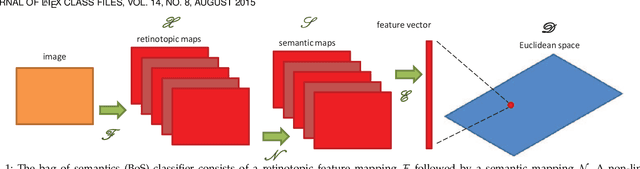

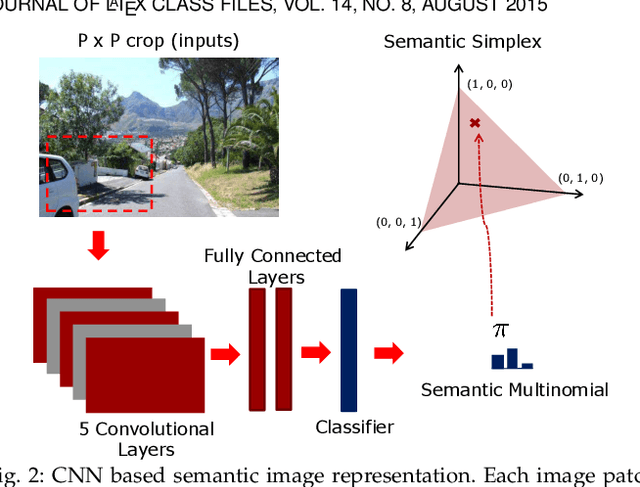

The transfer of a neural network (CNN) trained to recognize objects to the task of scene classification is considered. A Bag-of-Semantics (BoS) representation is first induced, by feeding scene image patches to the object CNN, and representing the scene image by the ensuing bag of posterior class probability vectors (semantic posteriors). The encoding of the BoS with a Fisher vector(FV) is then studied. A link is established between the FV of any probabilistic model and the Q-function of the expectation-maximization(EM) algorithm used to estimate its parameters by maximum likelihood. A network implementation of the MFA Fisher Score (MFA-FS), denoted as the MFAFSNet, is finally proposed to enable end-to-end training. Experiments with various object CNNs and datasets show that the approach has state-of-the-art transfer performance. Somewhat surprisingly, the scene classification results are superior to those of a CNN explicitly trained for scene classification, using a large scene dataset (Places). This suggests that holistic analysis is insufficient for scene classification. The modeling of local object semantics appears to be at least equally important. The two approaches are also shown to be strongly complementary, leading to very large scene classification gains when combined, and outperforming all previous scene classification approaches by a sizeable margin
Deep Learning with Gaussian Differential Privacy
Dec 10, 2019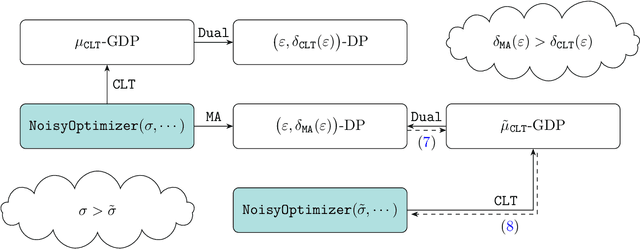
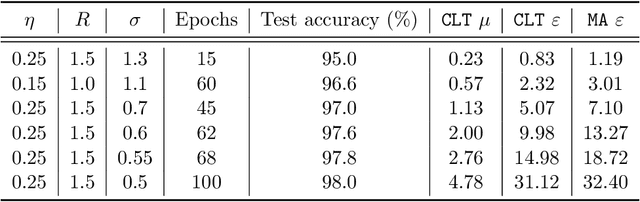
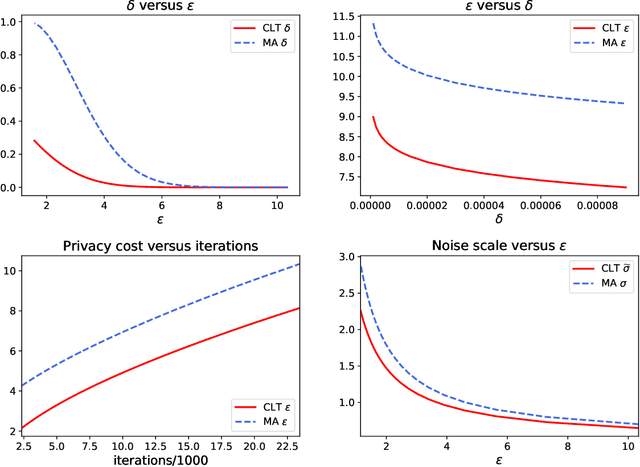
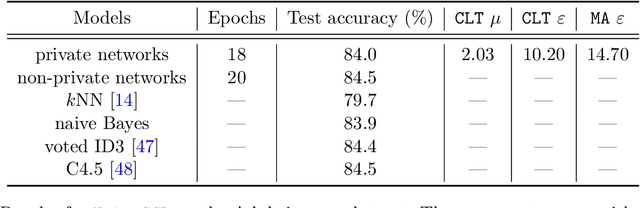
Deep learning models are often trained on datasets that contain sensitive information such as individuals' shopping transactions, personal contacts, and medical records. An increasingly important line of work therefore has sought to train neural networks subject to privacy constraints that are specified by differential privacy or its divergence-based relaxations. These privacy definitions, however, have weaknesses in handling certain important primitives (composition and subsampling), thereby giving loose or complicated privacy analyses of training neural networks. In this paper, we consider a recently proposed privacy definition termed f-differential privacy [17] for a refined privacy analysis of training neural networks. Leveraging the appealing properties of f-differential privacy in handling composition and subsampling, this paper derives analytically tractable expressions for the privacy guarantees of both stochastic gradient descent and Adam used in training deep neural networks, without the need of developing sophisticated techniques as [3] did. Our results demonstrate that the f-differential privacy framework allows for a new privacy analysis that improves on the prior analysis [3], which in turn suggests tuning certain parameters of neural networks for a better prediction accuracy without violating the privacy budget. These theoretically derived improvements are confirmed by our experiments in a range of tasks in image classification, text classification, and recommender systems.
Optimal Transport Based Generative Autoencoders
Oct 16, 2019
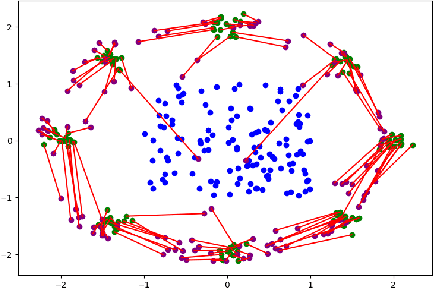

The field of deep generative modeling is dominated by generative adversarial networks (GANs). However, the training of GANs often lacks stability, fails to converge, and suffers from model collapse. It takes an assortment of tricks to solve these problems, which may be difficult to understand for those seeking to apply generative modeling. Instead, we propose two novel generative autoencoders, AE-OTtrans and AE-OTgen, which rely on optimal transport instead of adversarial training. AE-OTtrans and AEOTgen, unlike VAE and WAE, preserve the manifold of the data; they do not force the latent distribution to match a normal distribution, resulting in greater quality images. AEOTtrans and AE-OTgen also produce images of higher diversity compared to their predecessor, AE-OT. We show that AE-OTtrans and AE-OTgen surpass GANs in the MNIST and FashionMNIST datasets. Furthermore, We show that AE-OTtrans and AE-OTgen do state of the art on the MNIST, FashionMNIST, and CelebA image sets comapred to other non-adversarial generative models.
Global Transformer U-Nets for Label-Free Prediction of Fluorescence Images
Jul 02, 2019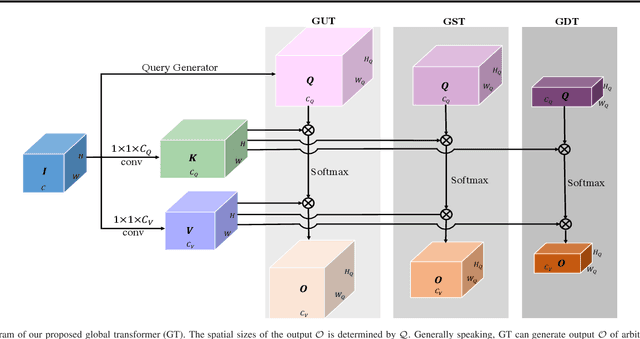

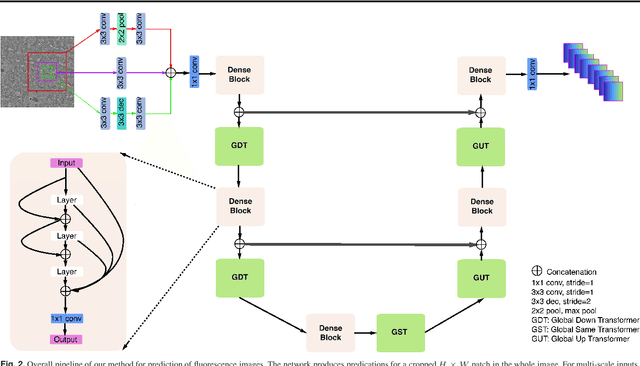
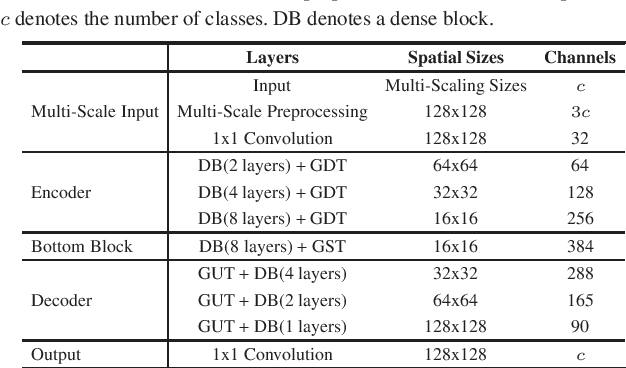
Visualizing the details of different cellular structures is of great importance to elucidate cellular functions. However, it is challenging to obtain high quality images of different structures directly due to complex cellular environments. Fluorescence microscopy is a popular technique to label different structures but has several drawbacks. In particular, labeling is time consuming and may affect cell morphology, and simultaneous labels are inherently limited. This raises the need of building computational models to learn relationships between unlabeled and labeled fluorescence images, and to infer fluorescent labels of other unlabeled fluorescence images. We propose to develop a novel deep model for fluorescence image prediction. We first propose a novel network layer, known as the global transformer layer, that fuses global information from inputs effectively. The proposed global transformer layer can generate outputs with arbitrary dimensions, and can be employed for all the regular, down-sampling, and up-sampling operators. We then incorporate our proposed global transformer layers and dense blocks to build an U-Net like network. We believe such a design can promote feature reusing between layers. In addition, we propose a multi-scale input strategy to encourage networks to capture features at different scales. We conduct evaluations across various label-free prediction tasks to demonstrate the effectiveness of our approach. Both quantitative and qualitative results show that our method outperforms the state-of-the-art approach significantly. It is also shown that our proposed global transformer layer is useful to improve the fluorescence image prediction results.
Sparseout: Controlling Sparsity in Deep Networks
Apr 17, 2019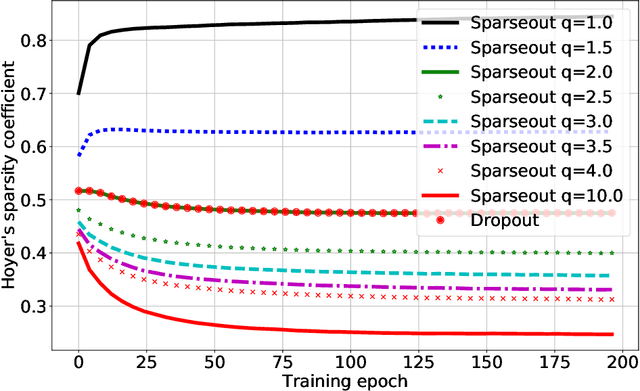

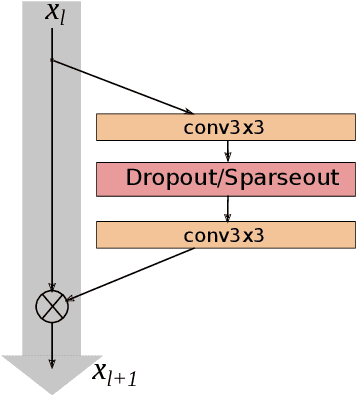
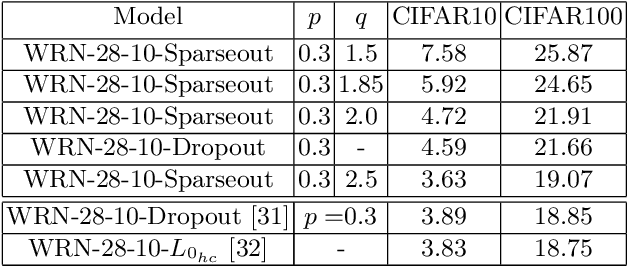
Dropout is commonly used to help reduce overfitting in deep neural networks. Sparsity is a potentially important property of neural networks, but is not explicitly controlled by Dropout-based regularization. In this work, we propose Sparseout a simple and efficient variant of Dropout that can be used to control the sparsity of the activations in a neural network. We theoretically prove that Sparseout is equivalent to an $L_q$ penalty on the features of a generalized linear model and that Dropout is a special case of Sparseout for neural networks. We empirically demonstrate that Sparseout is computationally inexpensive and is able to control the desired level of sparsity in the activations. We evaluated Sparseout on image classification and language modelling tasks to see the effect of sparsity on these tasks. We found that sparsity of the activations is favorable for language modelling performance while image classification benefits from denser activations. Sparseout provides a way to investigate sparsity in state-of-the-art deep learning models. Source code for Sparseout could be found at \url{https://github.com/najeebkhan/sparseout}.
Scale-Equivariant Neural Networks with Decomposed Convolutional Filters
Sep 24, 2019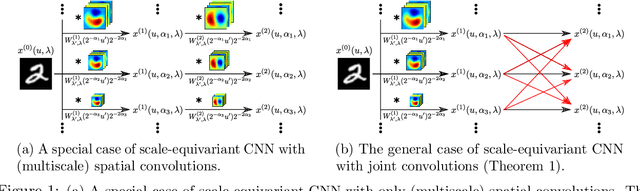
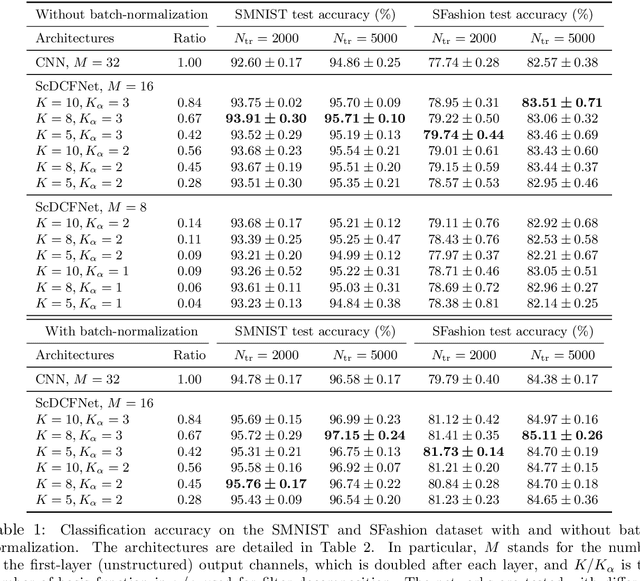
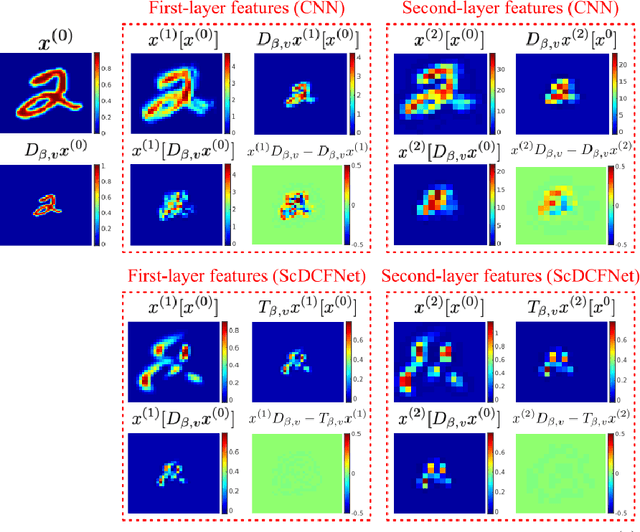
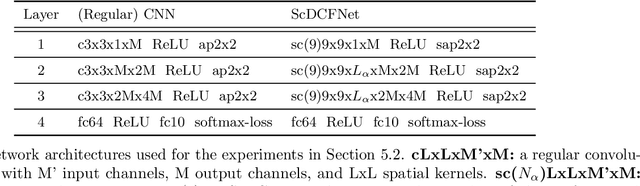
Encoding the input scale information explicitly into the representation learned by a convolutional neural network (CNN) is beneficial for many vision tasks especially when dealing with multiscale input signals. We study, in this paper, a scale-equivariant CNN architecture with joint convolutions across the space and the scaling group, which is shown to be both sufficient and necessary to achieve scale-equivariant representations. To reduce the model complexity and computational burden, we decompose the convolutional filters under two pre-fixed separable bases and truncate the expansion to low-frequency components. A further benefit of the truncated filter expansion is the improved deformation robustness of the equivariant representation. Numerical experiments demonstrate that the proposed scale-equivariant neural network with decomposed convolutional filters (ScDCFNet) achieves significantly improved performance in multiscale image classification and better interpretability than regular CNNs at a reduced model size.
Towards Improving Generalization of Deep Networks via Consistent Normalization
Aug 31, 2019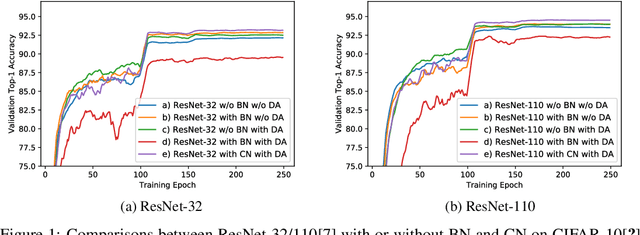
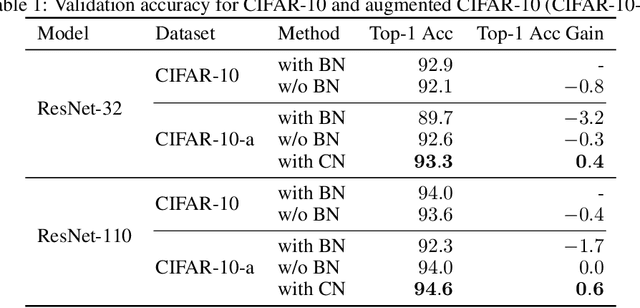

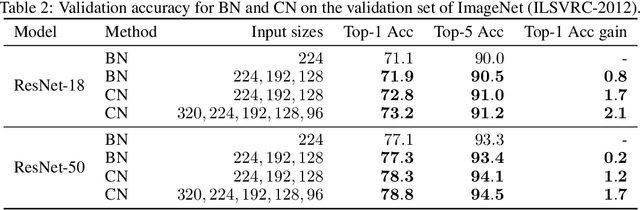
Batch Normalization (BN) was shown to accelerate training and improve generalization of Convolutional Neural Networks (ConvNets), which typically use the Conv-BN couple as building block. However, this work shows a common phenomenon that the Conv-BN module does not necessarily outperform the networks trained without using BN, especially when data augmentation is presented in training. We find that this phenomenon occurs because there is inconsistency between the distribution of the augmented data and that of the normalized representation. To address this issue, we propose Consistent Normalization (CN) that not only retains the advantages of the existing normalization methods, but also achieves state-of-the-art performance on various tasks including image classification, segmentation, and machine translation. The code will be released to facilitate reproducibility.
Hallucinating Dense Optical Flow from Sparse Lidar for Autonomous Vehicles
Aug 30, 2018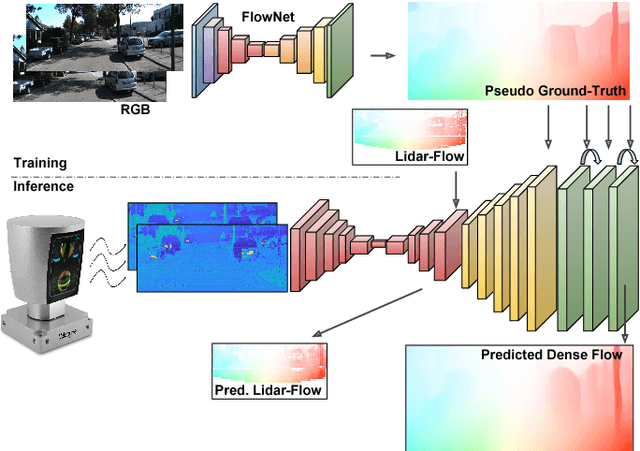
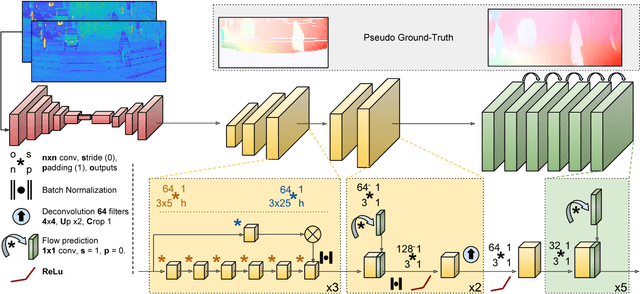
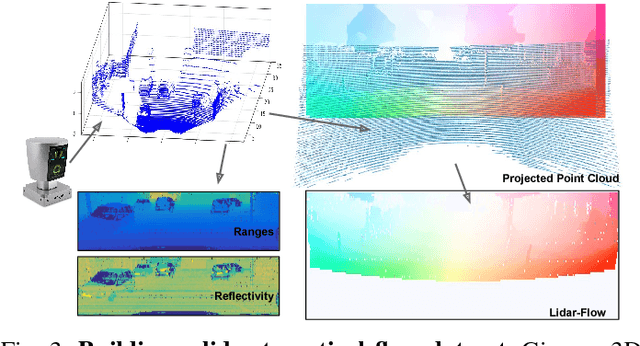

In this paper we propose a novel approach to estimate dense optical flow from sparse lidar data acquired on an autonomous vehicle. This is intended to be used as a drop-in replacement of any image-based optical flow system when images are not reliable due to e.g. adverse weather conditions or at night. In order to infer high resolution 2D flows from discrete range data we devise a three-block architecture of multiscale filters that combines multiple intermediate objectives, both in the lidar and image domain. To train this network we introduce a dataset with approximately 20K lidar samples of the Kitti dataset which we have augmented with a pseudo ground-truth image-based optical flow computed using FlowNet2. We demonstrate the effectiveness of our approach on Kitti, and show that despite using the low-resolution and sparse measurements of the lidar, we can regress dense optical flow maps which are at par with those estimated with image-based methods.
Offline handwritten mathematical symbol recognition utilising deep learning
Oct 16, 2019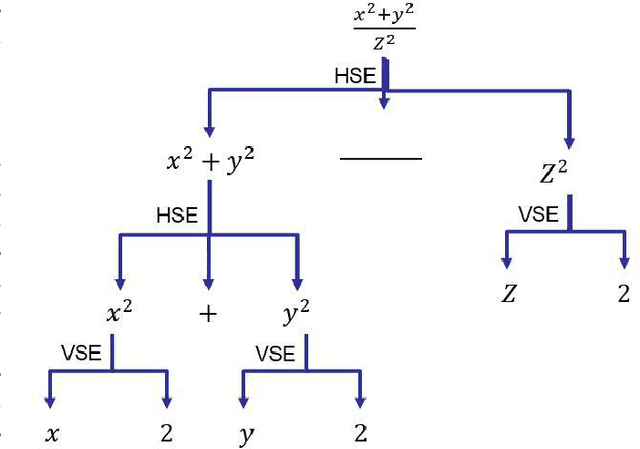
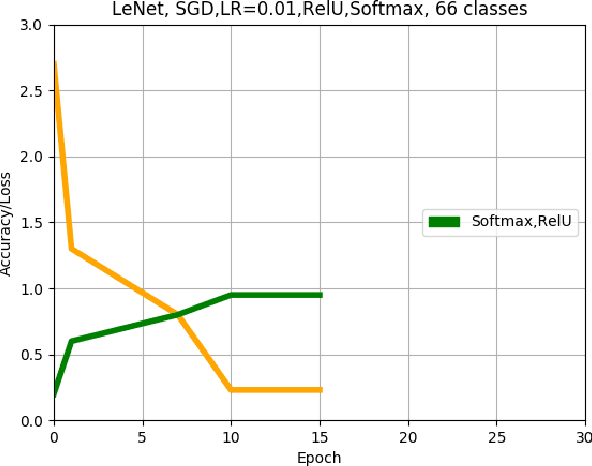
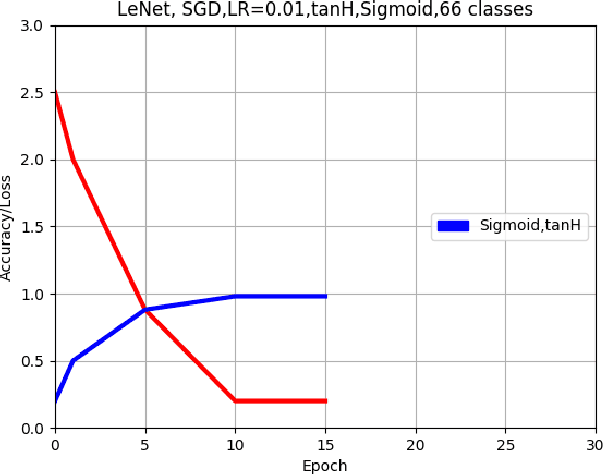
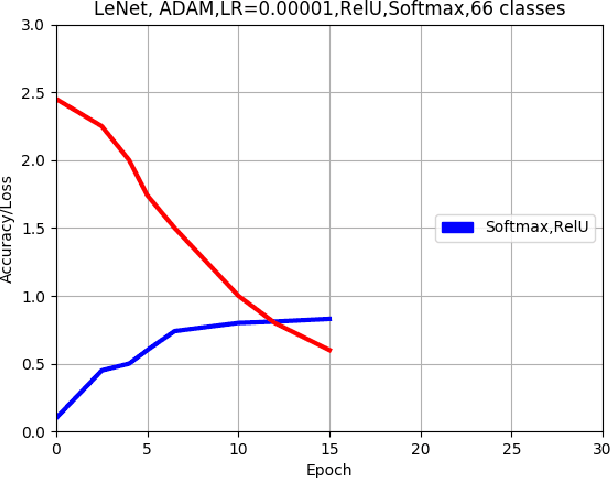
This paper describes an approach for offline recognition of handwritten mathematical symbols. The process of symbol recognition in this paper includes symbol segmentation and accurate classification for over 300 classes. Many multidimensional mathematical symbols need both horizontal and vertical projection to be segmented. However, some symbols do not permit to be projected and stop segmentation, such as the root symbol. Besides, many mathematical symbols are structurally similar, specifically in handwritten such as 0 and null. There are more than 300 Mathematical symbols. Therefore, designing an accurate classifier for more than 300 classes is required. This paper initially addresses the issue regarding segmentation using Simple Linear Iterative Clustering (SLIC). Experimental results indicate that the accuracy of the designed kNN classifier is 84% for salient, 57% Histogram of Oriented Gradient (HOG), 53% for Linear Binary Pattern (LBP) and finally 43% for pixel intensity of raw image for 66 classes. 87 classes using modified LeNet represents 90% accuracy. Finally, for 101 classes, SqueezeNet ac