 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
iVOA: Introspective Vision for Obstacle Avoidance
Mar 04, 2019
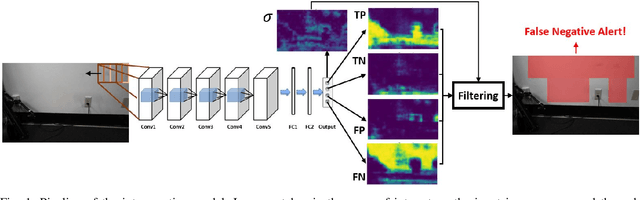

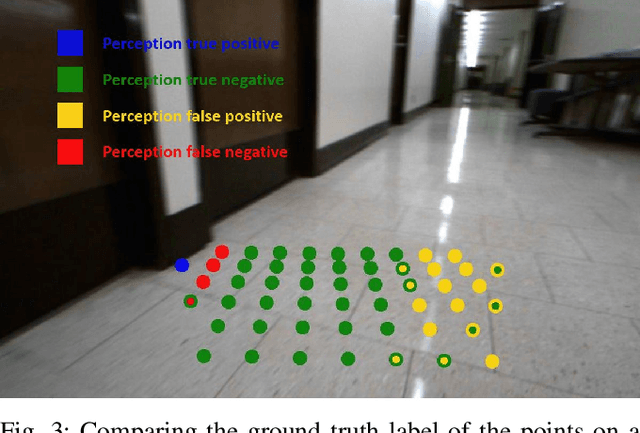

Vision, as an inexpensive yet information rich sensor, is commonly used for perception on autonomous mobile robots. Unfortunately, accurate vision-based perception requires a number of assumptions about the environment to hold -- some examples of such assumptions, depending on the perception algorithm at hand, include purely lambertian surfaces, texture-rich scenes, absence of aliasing features, and refractive surfaces. In this paper, we present an approach for introspective vision for obstacle avoidance (iVOA) -- by leveraging a supervisory sensor that is occasionally available, we detect failures of stereo vision-based perception from divergence in plans generated by vision and the supervisory sensor. By projecting the 3D coordinates where the plans agree and disagree onto the images used for vision-based perception, iVOA generates a training set of reliable and unreliable image patches for perception. We then use this training dataset to learn a model of which image patches are likely to cause failures of the vision-based perception algorithm. Using this model, iVOA is then able to predict whether the relevant image patches in the observed images are likely to cause failures due to vision (both false positives and false negatives). We empirically demonstrate with extensive real-world data from both indoor and outdoor environments, the ability of iVOA to accurately predict the failures of two distinct vision algorithms.
Single-bit-per-weight deep convolutional neural networks without batch-normalization layers for embedded systems
Jul 22, 2019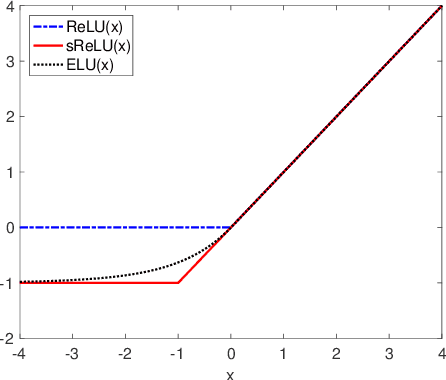
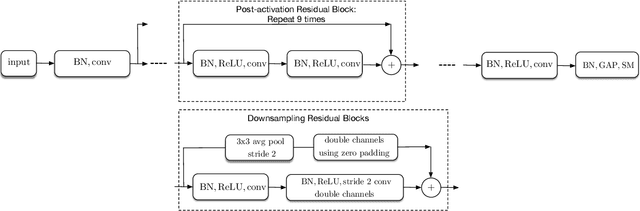
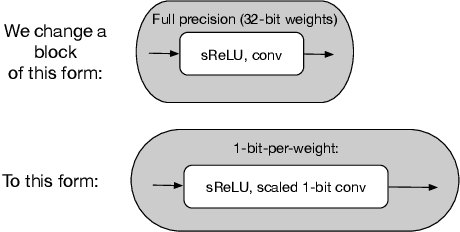
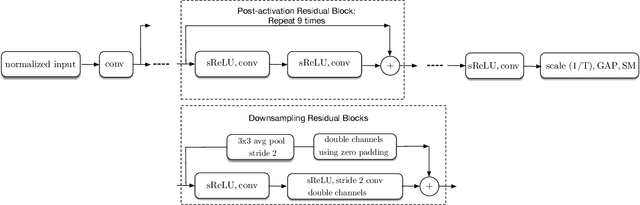
Batch-normalization (BN) layers are thought to be an integrally important layer type in today's state-of-the-art deep convolutional neural networks for computer vision tasks such as classification and detection. However, BN layers introduce complexity and computational overheads that are highly undesirable for training and/or inference on low-power custom hardware implementations of real-time embedded vision systems such as UAVs, robots and Internet of Things (IoT) devices. They are also problematic when batch sizes need to be very small during training, and innovations such as residual connections introduced more recently than BN layers could potentially have lessened their impact. In this paper we aim to quantify the benefits BN layers offer in image classification networks, in comparison with alternative choices. In particular, we study networks that use shifted-ReLU layers instead of BN layers. We found, following experiments with wide residual networks applied to the ImageNet, CIFAR 10 and CIFAR 100 image classification datasets, that BN layers do not consistently offer a significant advantage. We found that the accuracy margin offered by BN layers depends on the data set, the network size, and the bit-depth of weights. We conclude that in situations where BN layers are undesirable due to speed, memory or complexity costs, that using shifted-ReLU layers instead should be considered; we found they can offer advantages in all these areas, and often do not impose a significant accuracy cost.
Deep Dilated Convolutional Nets for the Automatic Segmentation of Retinal Vessels
May 28, 2019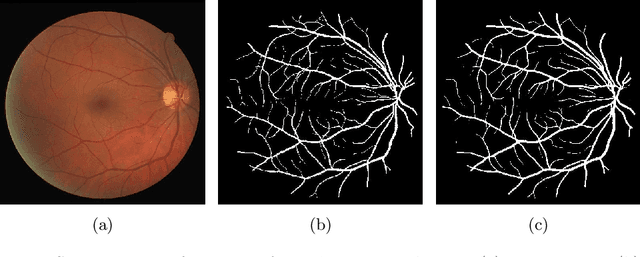
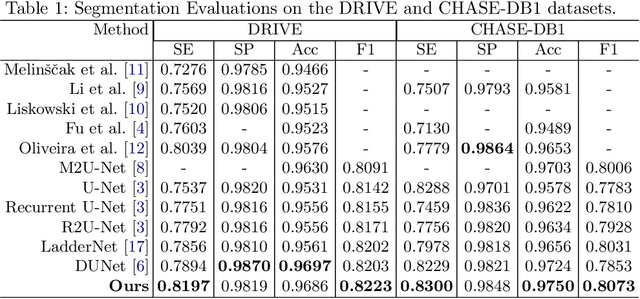
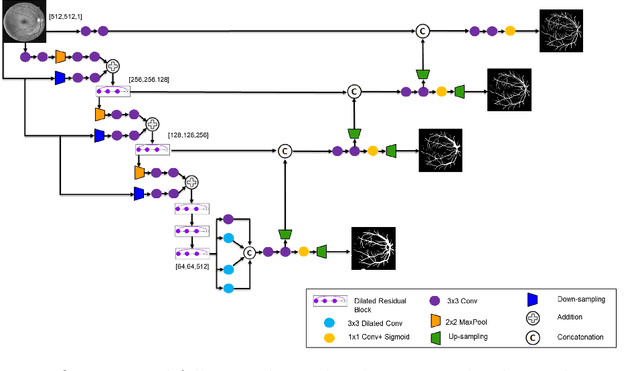
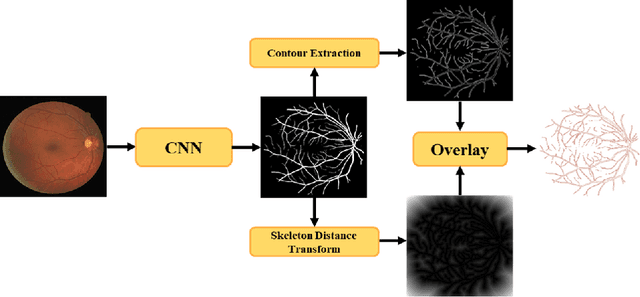
The reliable segmentation of retinal vasculature can provide the means to diagnose and monitor the progression of a variety of diseases affecting the blood vessel network, including diabetes and hypertension. We leverage the power of convolutional neural networks to devise a reliable and fully automated method that can accurately detect, segment, and analyze retinal vessels. In particular, we propose a novel, fully convolutional deep neural network with an encoder-decoder architecture that employs dilated spatial pyramid pooling with multiple dilation rates to recover the lost content in the encoder and add multiscale contextual information to the decoder. We also propose a simple yet effective way of quantifying and tracking the widths of retinal vessels through direct use of the segmentation predictions. Unlike previous deep-learning-based approaches to retinal vessel segmentation that mainly rely on patch-wise analysis, our proposed method leverages a whole-image approach during training and inference, resulting in more efficient training and faster inference through the access of global content in the image. We have tested our method on three publicly available datasets, and our state-of-the-art results on both the DRIVE and CHASE-DB1 datasets attest to the effectiveness of our approach.
Learning Cascaded Siamese Networks for High Performance Visual Tracking
May 08, 2019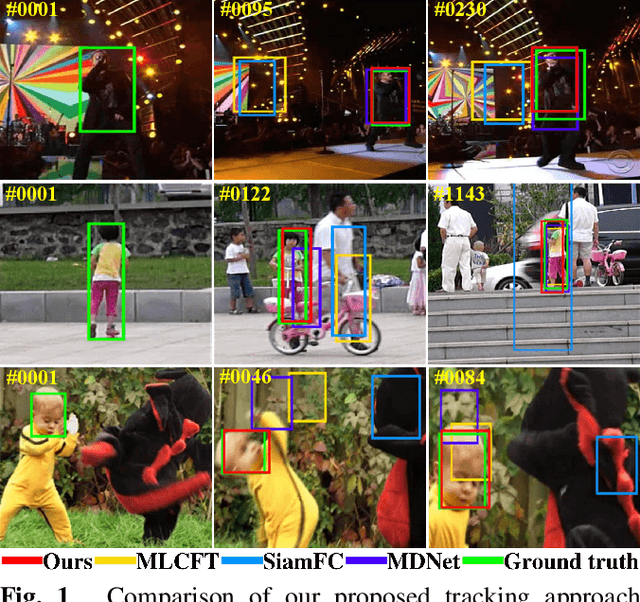
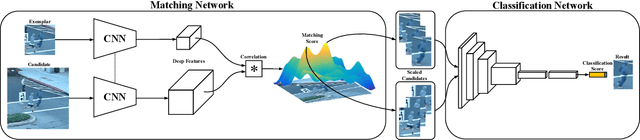
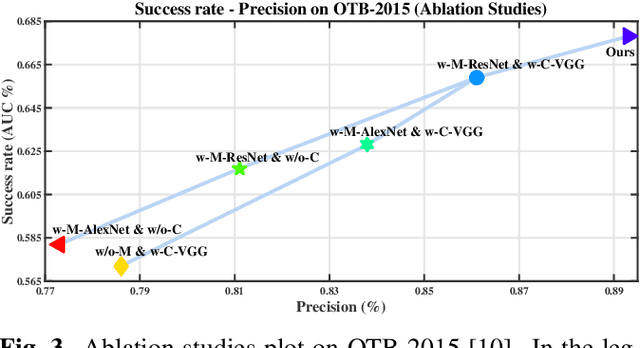
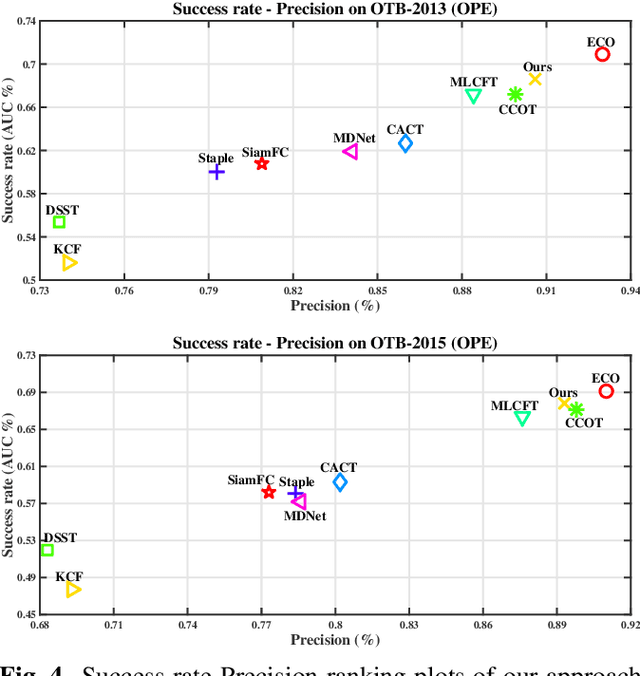
Visual tracking is one of the most challenging computer vision problems. In order to achieve high performance visual tracking in various negative scenarios, a novel cascaded Siamese network is proposed and developed based on two different deep learning networks: a matching subnetwork and a classification subnetwork. The matching subnetwork is a fully convolutional Siamese network. According to the similarity score between the exemplar image and the candidate image, it aims to search possible object positions and crop scaled candidate patches. The classification subnetwork is designed to further evaluate the cropped candidate patches and determine the optimal tracking results based on the classification score. The matching subnetwork is trained offline and fixed online, while the classification subnetwork performs stochastic gradient descent online to learn more target-specific information. To improve the tracking performance further, an effective classification subnetwork update method based on both similarity and classification scores is utilized for updating the classification subnetwork. Extensive experimental results demonstrate that our proposed approach achieves state-of-the-art performance in recent benchmarks.
Variational Disparity Estimation Framework for Plenoptic Image
Apr 18, 2018
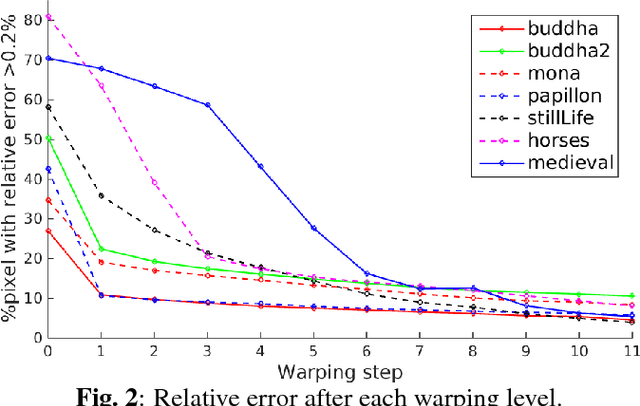
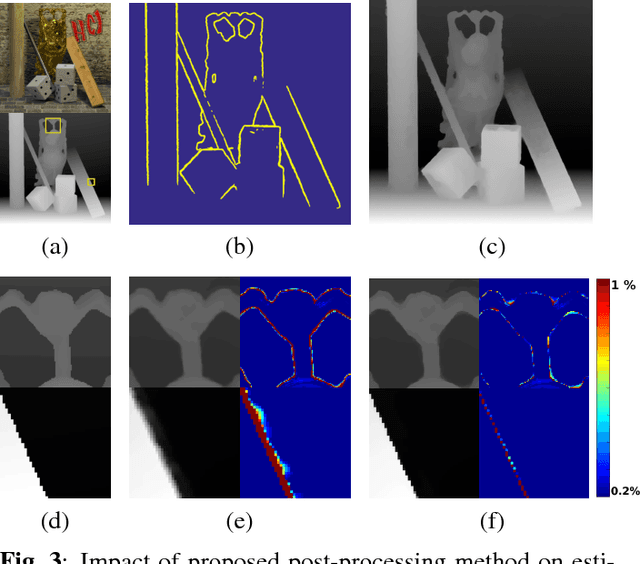
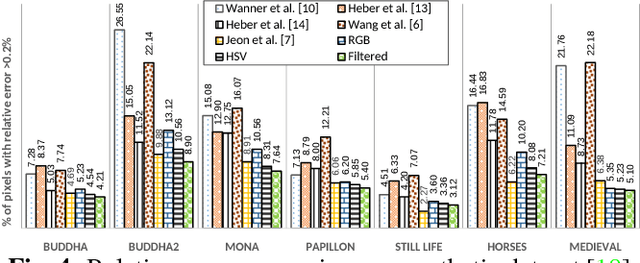
This paper presents a computational framework for accurately estimating the disparity map of plenoptic images. The proposed framework is based on the variational principle and provides intrinsic sub-pixel precision. The light-field motion tensor introduced in the framework allows us to combine advanced robust data terms as well as provides explicit treatments for different color channels. A warping strategy is embedded in our framework for tackling the large displacement problem. We also show that by applying a simple regularization term and a guided median filtering, the accuracy of displacement field at occluded area could be greatly enhanced. We demonstrate the excellent performance of the proposed framework by intensive comparisons with the Lytro software and contemporary approaches on both synthetic and real-world datasets.
An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
Jul 21, 2015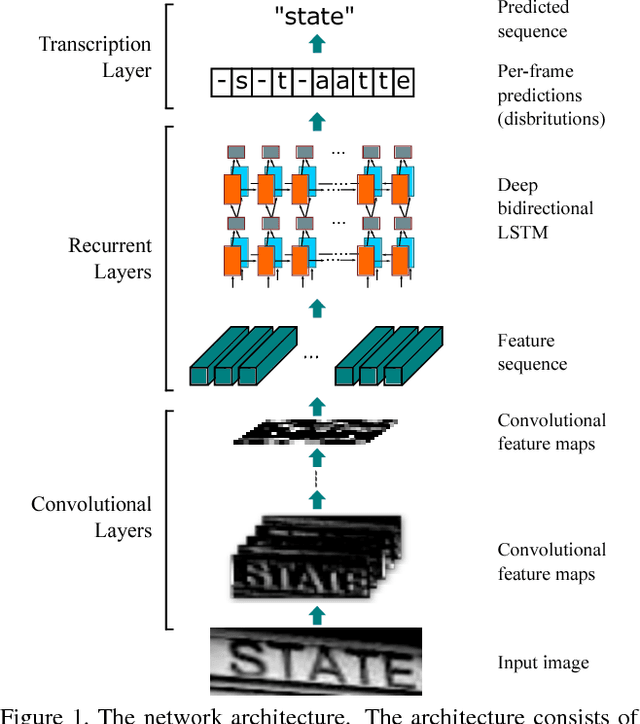
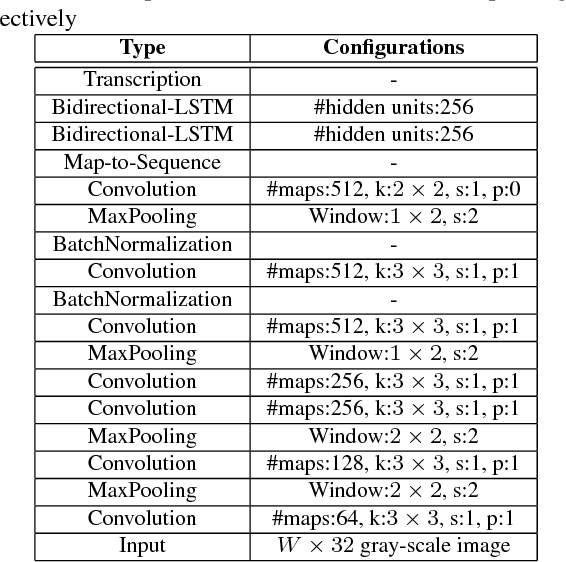
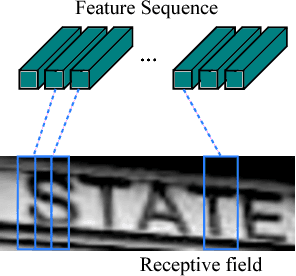
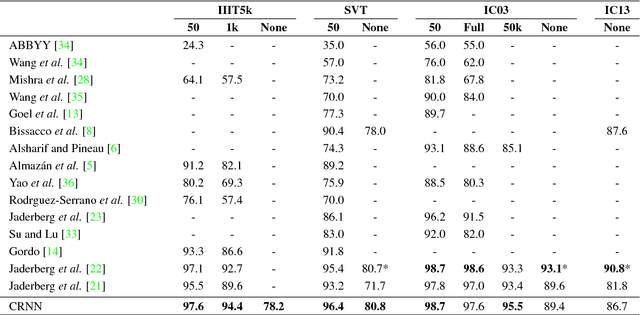
Image-based sequence recognition has been a long-standing research topic in computer vision. In this paper, we investigate the problem of scene text recognition, which is among the most important and challenging tasks in image-based sequence recognition. A novel neural network architecture, which integrates feature extraction, sequence modeling and transcription into a unified framework, is proposed. Compared with previous systems for scene text recognition, the proposed architecture possesses four distinctive properties: (1) It is end-to-end trainable, in contrast to most of the existing algorithms whose components are separately trained and tuned. (2) It naturally handles sequences in arbitrary lengths, involving no character segmentation or horizontal scale normalization. (3) It is not confined to any predefined lexicon and achieves remarkable performances in both lexicon-free and lexicon-based scene text recognition tasks. (4) It generates an effective yet much smaller model, which is more practical for real-world application scenarios. The experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets, demonstrate the superiority of the proposed algorithm over the prior arts. Moreover, the proposed algorithm performs well in the task of image-based music score recognition, which evidently verifies the generality of it.
Occlusion-guided compact template learning for ensemble deep network-based pose-invariant face recognition
Apr 15, 2019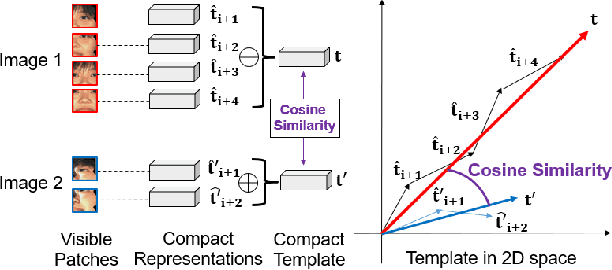

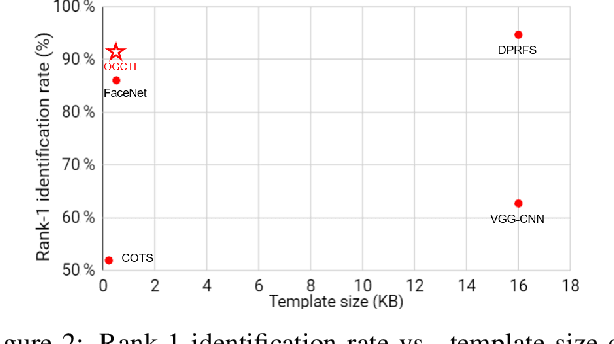
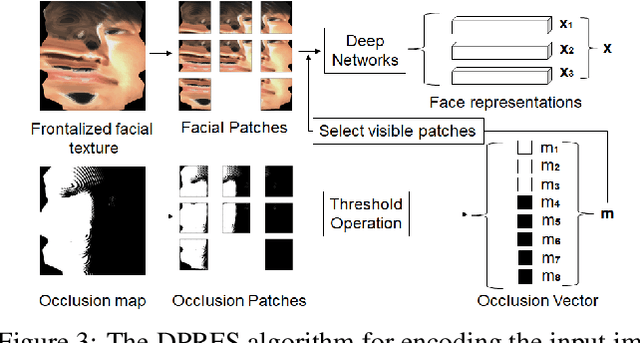
Concatenation of the deep network representations extracted from different facial patches helps to improve face recognition performance. However, the concatenated facial template increases in size and contains redundant information. Previous solutions aim to reduce the dimensionality of the facial template without considering the occlusion pattern of the facial patches. In this paper, we propose an occlusion-guided compact template learning (OGCTL) approach that only uses the information from visible patches to construct the compact template. The compact face representation is not sensitive to the number of patches that are used to construct the facial template and is more suitable for incorporating the information from different view angles for image-set based face recognition. Instead of using occlusion masks in face matching (e.g., DPRFS [38]), the proposed method uses occlusion masks in template construction and achieves significantly better image-set based face verification performance on a challenging database with a template size that is an order-of-magnitude smaller than DPRFS.
EDUCE: Explaining model Decisions through Unsupervised Concepts Extraction
May 28, 2019
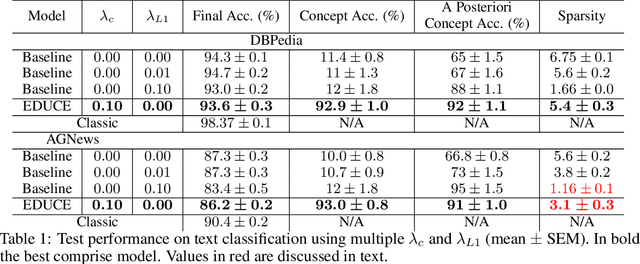


With the advent of deep neural networks, some research focuses towards understanding their black-box behavior. In this paper, we propose a new type of self-interpretable models, that are, architectures designed to provide explanations along with their predictions. Our method proceeds in two stages and is trained end-to-end: first, our model builds a low-dimensional binary representation of any input where each feature denotes the presence or absence of concepts. Then, it computes a prediction only based on this binary representation through a simple linear model. This allows an easy interpretation of the model's output in terms of presence of particular concepts in the input. The originality of our approach lies in the fact that concepts are automatically discovered at training time, without the need for additional supervision. Concepts correspond to a set of patterns, built on local low-level features (e.g a part of an image, a word in a sentence), easily identifiable from the other concepts. We experimentally demonstrate the relevance of our approach using classification tasks on two types of data, text and image, by showing its predictive performance and interpretability.
Towards End-to-End Text Spotting in Natural Scenes
Jun 17, 2019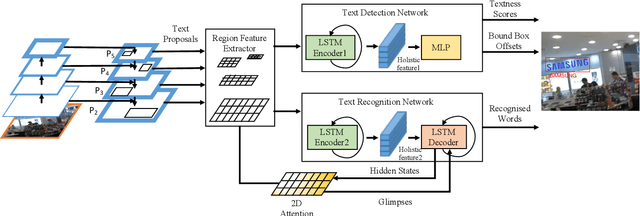
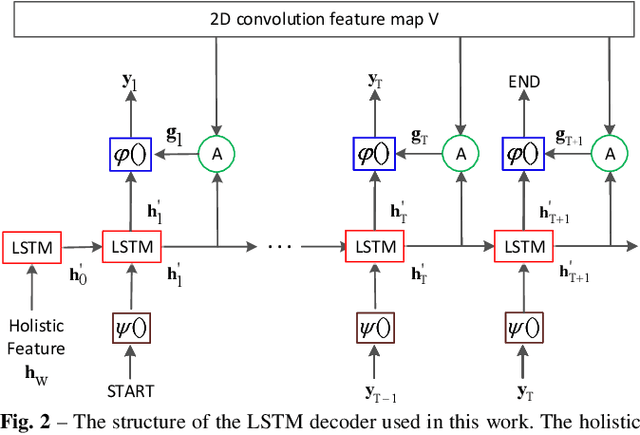


Text spotting in natural scene images is of great importance for many image understanding tasks. It includes two sub-tasks: text detection and recognition. In this work, we propose a unified network that simultaneously localizes and recognizes text with a single forward pass, avoiding intermediate processes such as image cropping and feature re-calculation, word separation, and character grouping. In contrast to existing approaches that consider text detection and recognition as two distinct tasks and tackle them one by one, the proposed framework settles these two tasks concurrently. The whole framework can be trained end-to-end and is able to handle text of arbitrary shapes. The convolutional features are calculated only once and shared by both detection and recognition modules. Through multi-task training, the learned features become more discriminate and improve the overall performance. By employing the $2$D attention model in word recognition, the irregularity of text can be robustly addressed. It provides the spatial location for each character, which not only helps local feature extraction in word recognition, but also indicates an orientation angle to refine text localization. Our proposed method has achieved state-of-the-art performance on several standard text spotting benchmarks, including both regular and irregular ones.
An Infinite Parade of Giraffes: Expressive Augmentation and Complexity Layers for Cartoon Drawing
Nov 08, 2018
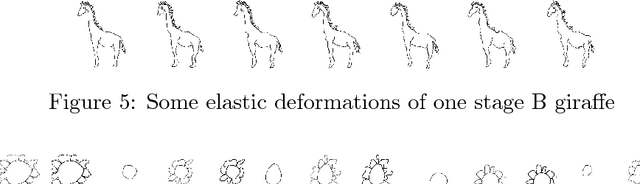
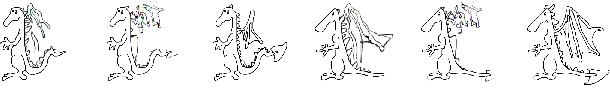
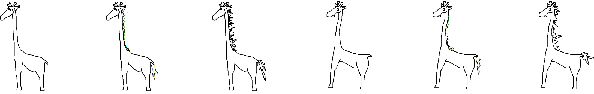
In this paper, we explore creative image generation constrained by small data. To partially automate the creation of cartoon sketches consistent with a specific designer's style, where acquiring a very large original image set is impossible or cost prohibitive, we exploit domain specific knowledge for a huge reduction in original image requirements, creating an effectively infinite number of cartoon giraffes from just nine original drawings. We introduce "expressive augmentations" for cartoon sketches, mathematical transformations that create broad domain appropriate variation, far beyond the usual affine transformations, and we show that chained GANs models trained on the temporal stages of drawing or "complexity layers" can effectively add character appropriate details and finish new drawings in the designer's style. We discuss the application of these tools in design processes for textiles, graphics, architectural elements and interior design.