 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast and High Quality Highlight Removal from A Single Image
Dec 01, 2015
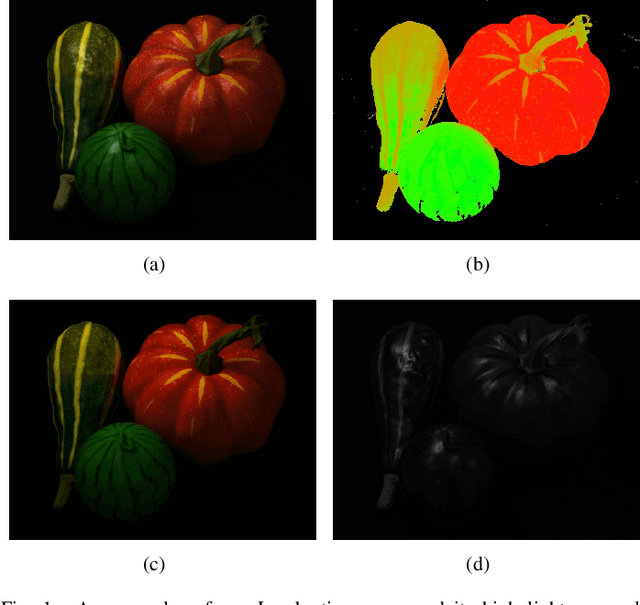

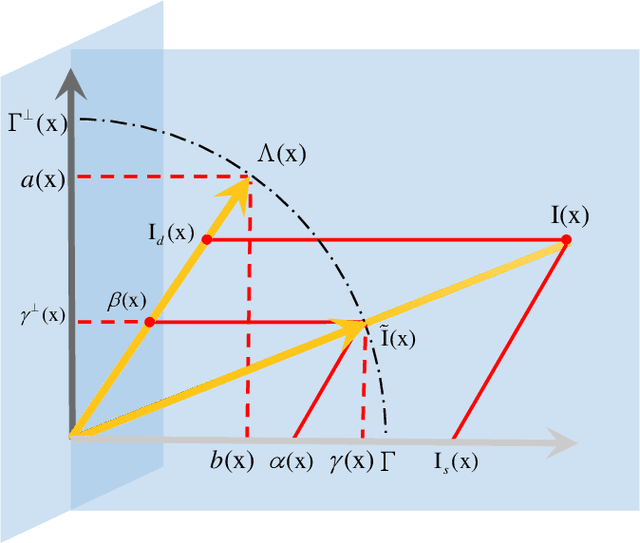
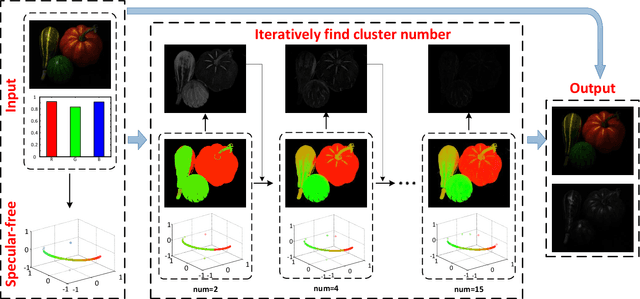
Specular reflection exists widely in photography and causes the recorded color deviating from its true value, so fast and high quality highlight removal from a single nature image is of great importance. In spite of the progress in the past decades in highlight removal, achieving wide applicability to the large diversity of nature scenes is quite challenging. To handle this problem, we propose an analytic solution to highlight removal based on an L2 chromaticity definition and corresponding dichromatic model. Specifically, this paper derives a normalized dichromatic model for the pixels with identical diffuse color: a unit circle equation of projection coefficients in two subspaces that are orthogonal to and parallel with the illumination, respectively. In the former illumination orthogonal subspace, which is specular-free, we can conduct robust clustering with an explicit criterion to determine the cluster number adaptively. In the latter illumination parallel subspace, a property called pure diffuse pixels distribution rule (PDDR) helps map each specular-influenced pixel to its diffuse component. In terms of efficiency, the proposed approach involves few complex calculation, and thus can remove highlight from high resolution images fast. Experiments show that this method is of superior performance in various challenging cases.
MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance
Sep 26, 2019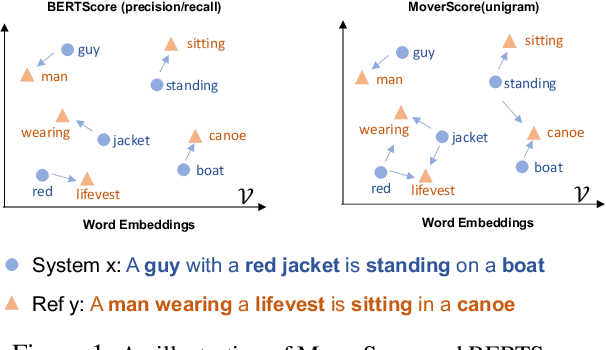
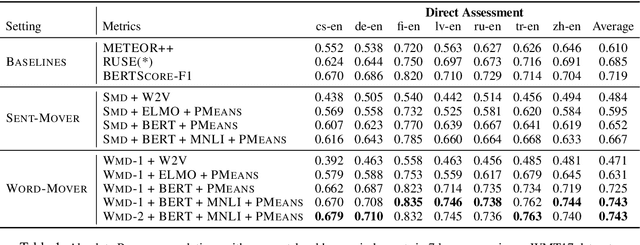
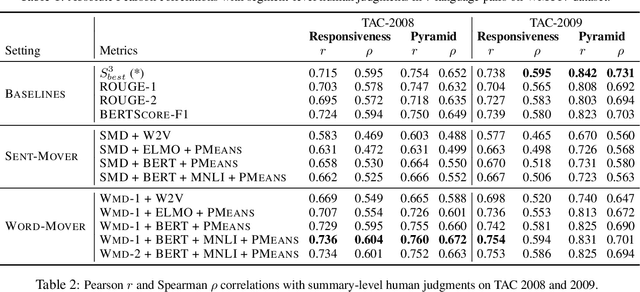
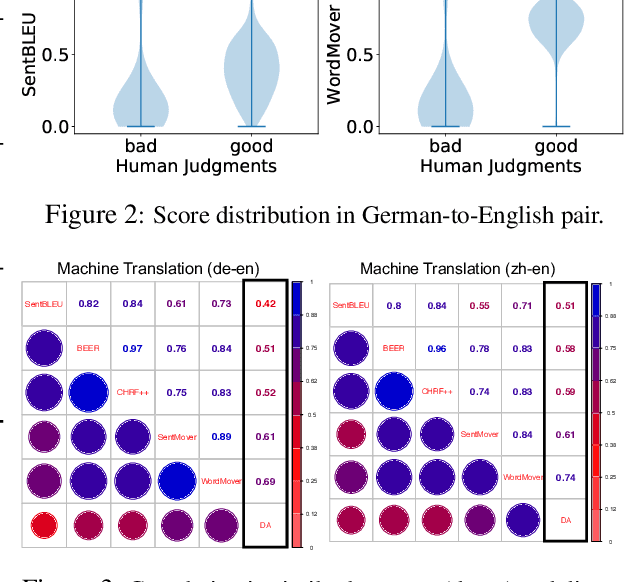
A robust evaluation metric has a profound impact on the development of text generation systems. A desirable metric compares system output against references based on their semantics rather than surface forms. In this paper we investigate strategies to encode system and reference texts to devise a metric that shows a high correlation with human judgment of text quality. We validate our new metric, namely MoverScore, on a number of text generation tasks including summarization, machine translation, image captioning, and data-to-text generation, where the outputs are produced by a variety of neural and non-neural systems. Our findings suggest that metrics combining contextualized representations with a distance measure perform the best. Such metrics also demonstrate strong generalization capability across tasks. For ease-of-use we make our metrics available as web service.
Structural Similarity Index SSIMplified: Is there really a simpler concept at the heart of image quality measurement?
May 25, 2015The Structural Similarity Index (SSIM) is generally considered to be a milestone in the recent history of Image Quality Assessment (IQA). Alas, SSIM's accepted development from the product of three heuristic factors continues to obscure it's real underlying simplicity. Starting instead from a symmetric-antisymmetric reformulation we first show SSIM to be a contrast or visibility function in the classic sense. Furthermore, the previously enigmatic structural covariance is revealed to be the difference of variances. The second step, eliminating the intrinsic quadratic nature of SSIM, allows a near linear correlation with human observer scores, and without invoking the usual, but arbitrary, sigmoid model fitting. We conclude that SSIM can be re-interpreted in terms of perceptual masking: it is essentially equivalent to a normalised error or noise visibility function (NVF), and, furthermore, the NVF alone explains it success in modelling perceptual image quality. We use the term Dissimilarity Quotient (DQ) for the specifically anti/symmetric SSIM derived NVF. It seems that IQA researchers may now have two choices: 1) Continue to use the complex SSIM formula, but noting that SSIM only works coincidentally since the covariance term is actually the mean square error (MSE) in disguise. 2) Use the simplest of all perceptually-masked image quality metrics, namely NVF or DQ. On this choice Occam is clear: in the absence of differences in predictive ability, the fewer assumptions that are made, the better.
How close are we to understanding image-based saliency?
Sep 26, 2014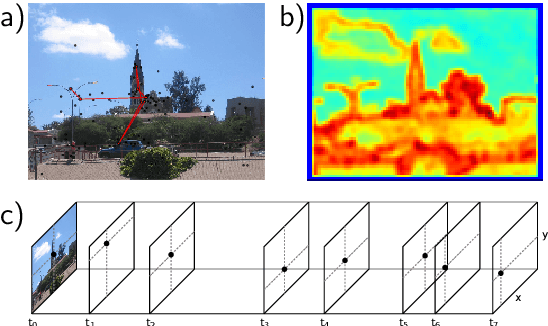

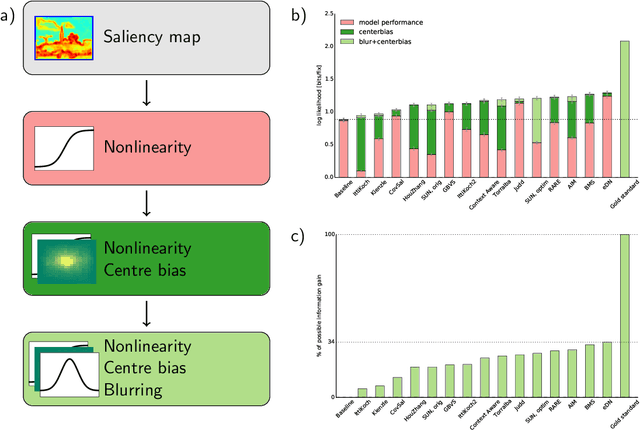
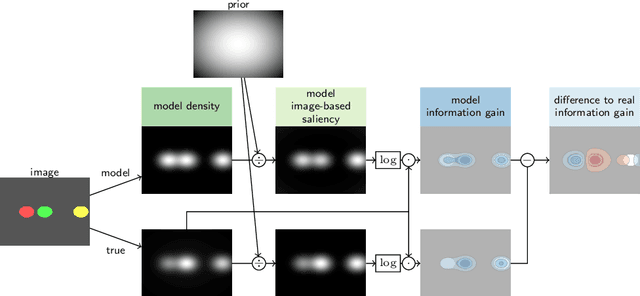
Within the set of the many complex factors driving gaze placement, the properities of an image that are associated with fixations under free viewing conditions have been studied extensively. There is a general impression that the field is close to understanding this particular association. Here we frame saliency models probabilistically as point processes, allowing the calculation of log-likelihoods and bringing saliency evaluation into the domain of information. We compared the information gain of state-of-the-art models to a gold standard and find that only one third of the explainable spatial information is captured. We additionally provide a principled method to show where and how models fail to capture information in the fixations. Thus, contrary to previous assertions, purely spatial saliency remains a significant challenge.
MRI Brain Tumor Segmentation using Random Forests and Fully Convolutional Networks
Sep 13, 2019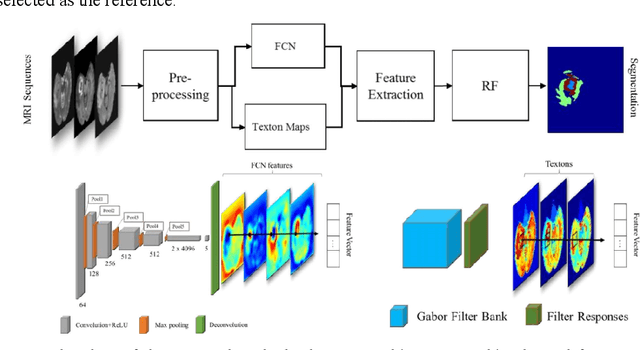

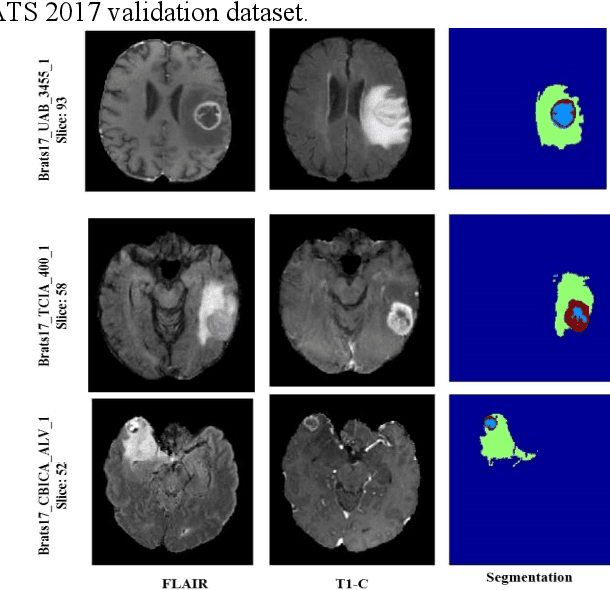
In this paper, we propose a novel learning based method for automated segmentation of brain tumor in multimodal MRI images, which incorporates two sets of machine -learned and hand crafted features. Fully convolutional networks (FCN) forms the machine learned features and texton based features are considered as hand-crafted features. Random forest (RF) is used to classify the MRI image voxels into normal brain tissues and different parts of tumors, i.e. edema, necrosis and enhancing tumor. The method was evaluated on BRATS 2017 challenge dataset. The results show that the proposed method provides promising segmentations. The mean Dice overlap measure for automatic brain tumor segmentation against ground truth is 0.86, 0.78 and 0.66 for whole tumor, core and enhancing tumor, respectively.
* Published in the pre-conference proceeding of "2017 International MICCAI BraTS Challenge"
Attention Guided Metal Artifact Correction in MRI using Deep Neural Networks
Oct 19, 2019



An attention guided scheme for metal artifact correction in MRI using deep neural network is proposed in this paper. The inputs of the networks are two distorted images obtained with dual-polarity readout gradients. With MR image generation module and the additional data consistency loss to the previous work [1], the network is trained to estimate the frequency-shift map, off-resonance map, and attention map. The attention map helps to produce better distortion-corrected images by weighting on more relevant distortion-corrected images where two distortion-corrected images are produced with half of the frequency-shift maps. In this paper, we observed that in a real MRI environment, two distorted images obtained with opposite polarities of readout gradient showed artifacts in a different region. Therefore, we proved that using the attention map was important in that it reduced the residual ripple and pile-up artifacts near metallic implants.
* 6 pages, 5 figures
3D Surface Reconstruction by Pointillism
Oct 04, 2018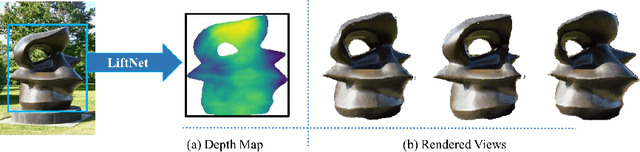
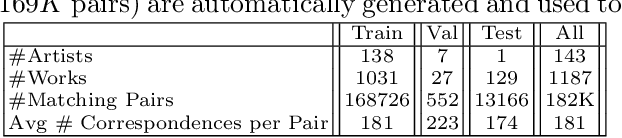
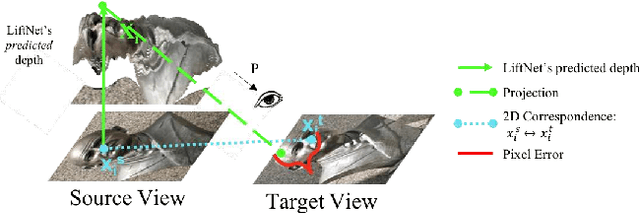

The objective of this work is to infer the 3D shape of an object from a single image. We use sculptures as our training and test bed, as these have great variety in shape and appearance. To achieve this we build on the success of multiple view geometry (MVG) which is able to accurately provide correspondences between images of 3D objects under varying viewpoint and illumination conditions, and make the following contributions: first, we introduce a new loss function that can harness image-to-image correspondences to provide a supervisory signal to train a deep network to infer a depth map. The network is trained end-to-end by differentiating through the camera. Second, we develop a processing pipeline to automatically generate a large scale multi-view set of correspondences for training the network. Finally, we demonstrate that we can indeed obtain a depth map of a novel object from a single image for a variety of sculptures with varying shape/texture, and that the network generalises at test time to new domains (e.g. synthetic images).
Generating Synthetic X-ray Images of a Person from the Surface Geometry
May 14, 2018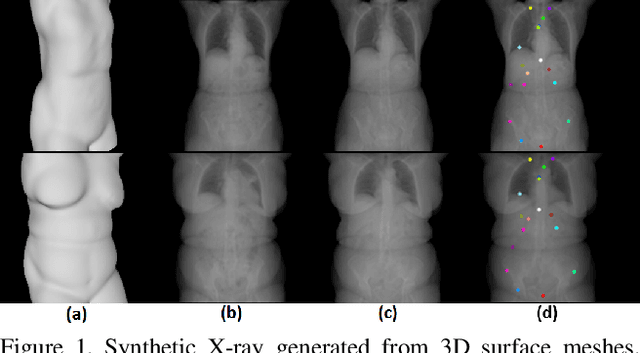
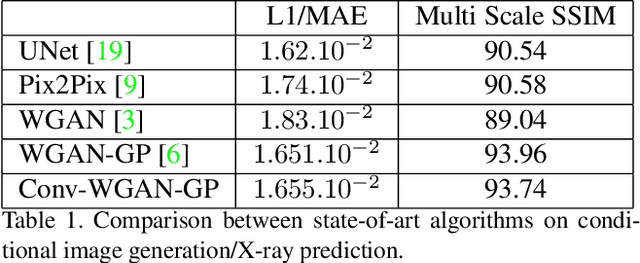
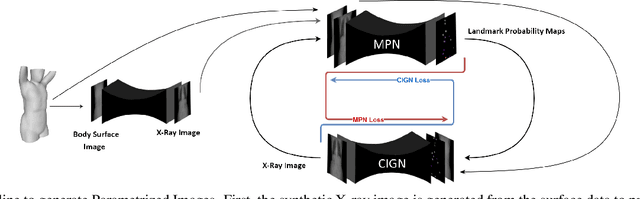
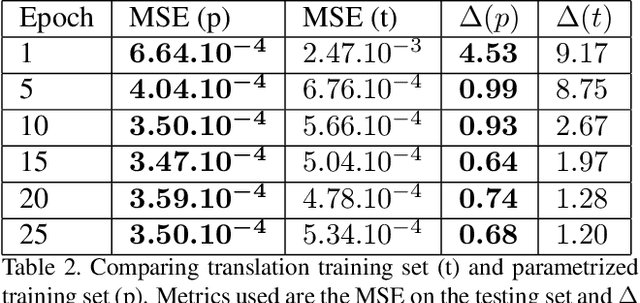
We present a novel framework that learns to predict human anatomy from body surface. Specifically, our approach generates a synthetic X-ray image of a person only from the person's surface geometry. Furthermore, the synthetic X-ray image is parametrized and can be manipulated by adjusting a set of body markers which are also generated during the X-ray image prediction. With the proposed framework, multiple synthetic X-ray images can easily be generated by varying surface geometry. By perturbing the parameters, several additional synthetic X-ray images can be generated from the same surface geometry. As a result, our approach offers a potential to overcome the training data barrier in the medical domain. This capability is achieved by learning a pair of networks - one learns to generate the full image from the partial image and a set of parameters, and the other learns to estimate the parameters given the full image. During training, the two networks are trained iteratively such that they would converge to a solution where the predicted parameters and the full image are consistent with each other. In addition to medical data enrichment, our framework can also be used for image completion as well as anomaly detection.
Mesh-based Camera Pairs Selection and Occlusion-Aware Masking for Mesh Refinement
May 21, 2019
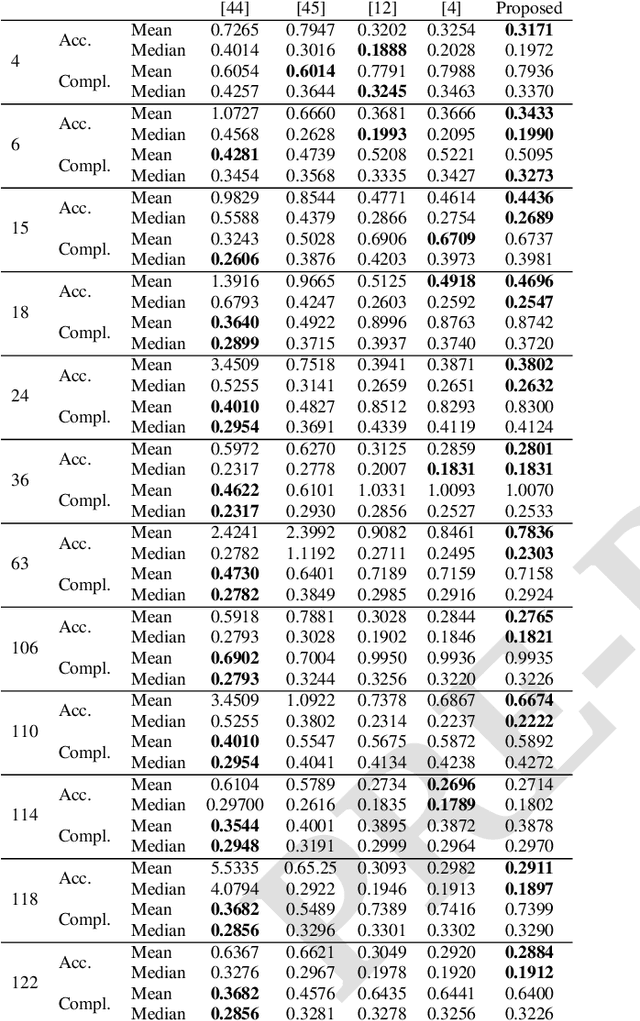


Many Multi-View-Stereo algorithms extract a 3D mesh model of a scene, after fusing depth maps into a volumetric representation of the space. Due to the limited scalability of such representations, the estimated model does not capture fine details of the scene. Therefore a mesh refinement algorithm is usually applied; it improves the mesh resolution and accuracy by minimizing the photometric error induced by the 3D model into pairs of cameras. The choice of these pairs significantly affects the quality of the refinement and usually relies on sparse 3D points belonging to the surface. Instead, in this paper, to increase the quality of pairs selection, we exploit the 3D model (before the refinement) to compute five metrics: scene coverage, mutual image overlap, image resolution, camera parallax, and a new symmetry term. To improve the refinement robustness, we also propose an explicit method to manage occlusions, which may negatively affect the computation of the photometric error. The proposed method takes into account the depth of the model while computing the similarity measure and its gradient. We quantitatively and qualitatively validated our approach on publicly available datasets against state of the art reconstruction methods.
Efficient Image Retrieval via Decoupling Diffusion into Online and Offline Processing
Nov 27, 2018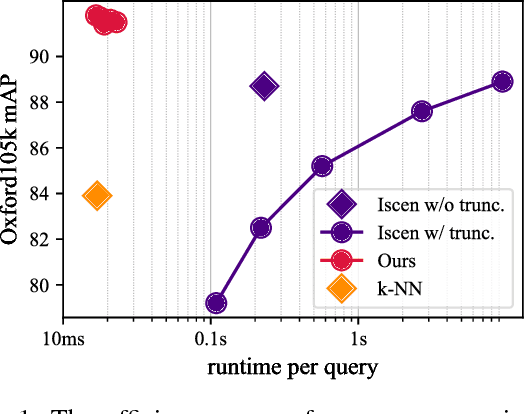
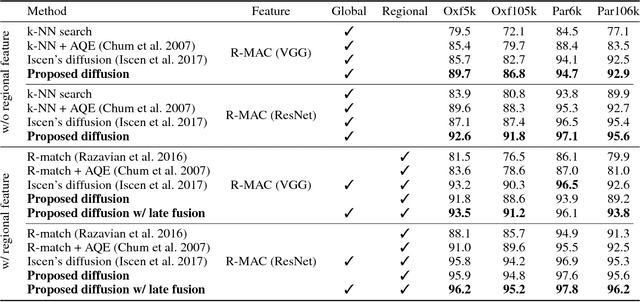
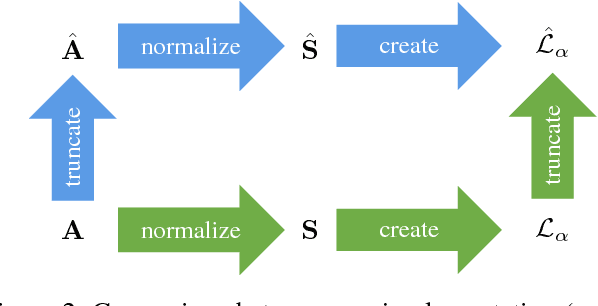
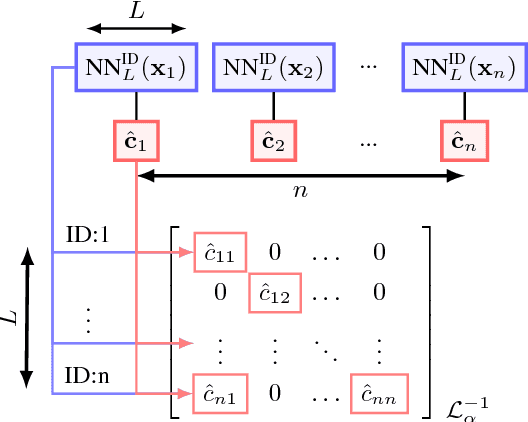
Diffusion is commonly used as a ranking or re-ranking method in retrieval tasks to achieve higher retrieval performance, and has attracted lots of attention in recent years. A downside to diffusion is that it performs slowly in comparison to the naive k-NN search, which causes a non-trivial online computational cost on large datasets. To overcome this weakness, we propose a novel diffusion technique in this paper. In our work, instead of applying diffusion to the query, we pre-compute the diffusion results of each element in the database, making the online search a simple linear combination on top of the k-NN search process. Our proposed method becomes 10~ times faster in terms of online search speed. Moreover, we propose to use late truncation instead of early truncation in previous works to achieve better retrieval performance.