 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking Curriculum Learning with Incremental Labels and Adaptive Compensation
Jan 13, 2020
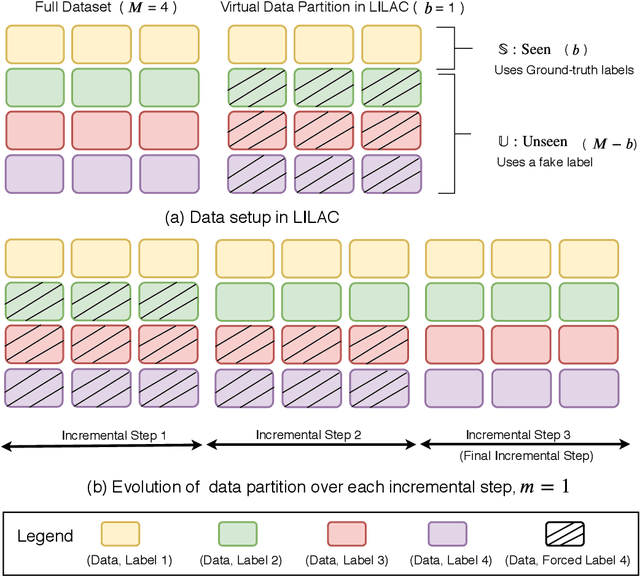
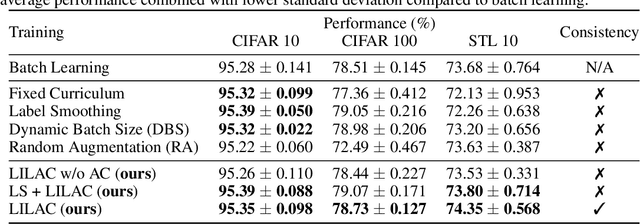
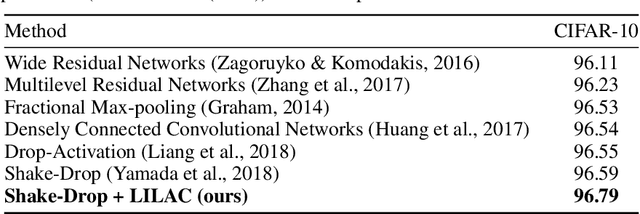
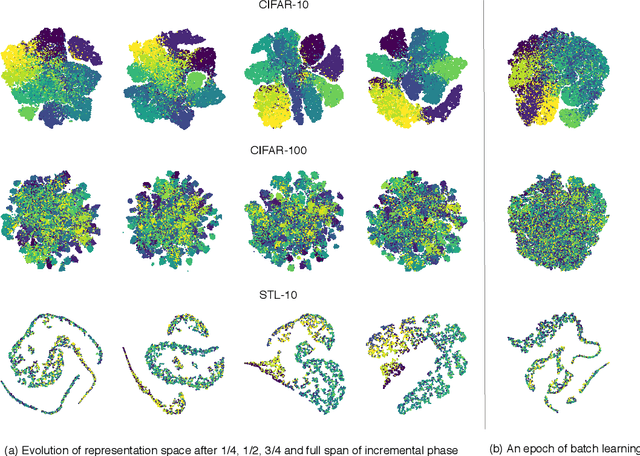
Like humans, deep networks learn better when samples are organized and introduced in a meaningful order or curriculum (Weinshall et al., 2018). While con-ventional approaches to curriculum learning emphasize the difficulty of samples as the core incremental strategy, it forces networks to learn from small subsets of data while introducing pre-computation overheads. In this work, we propose Learning with Incremental Labels and Adaptive Compensation(LILAC), which takes a novel approach to curriculum learning. LILAC emphasizes incrementally learning labels instead of incrementally learning difficult samples. It works in two distinct phases: first, in the incremental label introduction phase, we recursively reveal ground-truth labels in small installments while using a fake label for the remaining data. In the adaptive compensation phase, we compensate for failed predictions by adaptively altering the target vector to a smoother distribution. We evaluate LILAC against the closest comparable methods in batch and curriculum learning and label smoothing, across three standard image benchmarks, CIFAR-10, CIFAR-100, and STL-10. We show that our method outperforms batch learning with higher mean recognition accuracy as well as lower standard deviation in performance consistently across all benchmarks. We further extend LILAC to show the highest performance on CIFAR-10 for methods using simple data augmentation while exhibiting label-order invariance among other properties.
ShapeShifter: Robust Physical Adversarial Attack on Faster R-CNN Object Detector
Sep 03, 2018
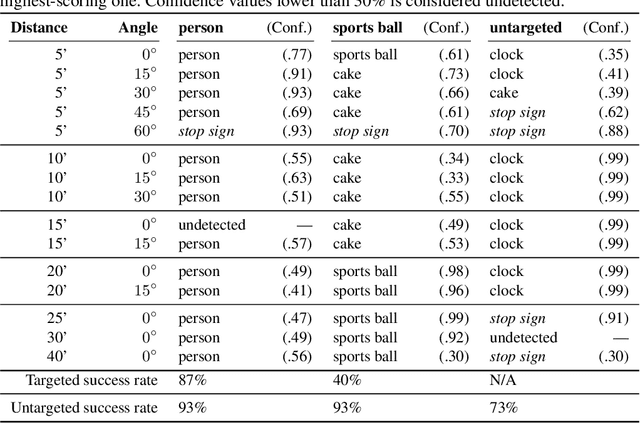

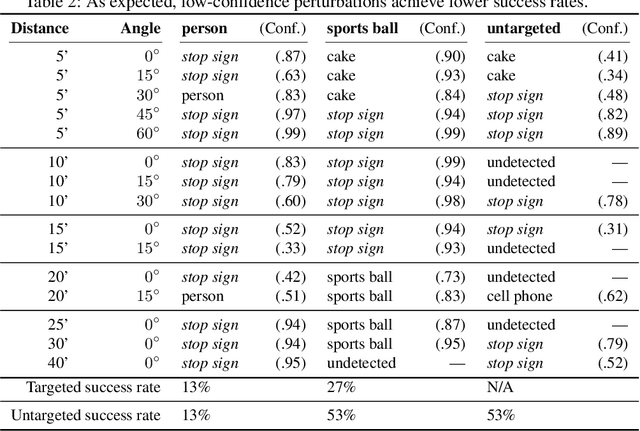
Given the ability to directly manipulate image pixels in the digital input space, an adversary can easily generate imperceptible perturbations to fool a Deep Neural Network (DNN) image classifier, as demonstrated in prior work. In this work, we propose ShapeShifter, an attack that tackles the more challenging problem of crafting physical adversarial perturbations to fool image-based object detectors like Faster R-CNN. Attacking an object detector is more difficult than attacking an image classifier, as it needs to mislead the classification results in multiple bounding boxes with different scales. Extending the digital attack to the physical world adds another layer of difficulty, because it requires the perturbation to be robust enough to survive real-world distortions due to different viewing distances and angles, lighting conditions, and camera limitations. We show that the Expectation over Transformation technique, which was originally proposed to enhance the robustness of adversarial perturbations in image classification, can be successfully adapted to the object detection setting. ShapeShifter can generate adversarially perturbed stop signs that are consistently mis-detected by Faster R-CNN as other objects, posing a potential threat to autonomous vehicles and other safety-critical computer vision systems.
Feature Learning to Automatically Assess Radiographic Knee Osteoarthritis Severity
Aug 23, 2019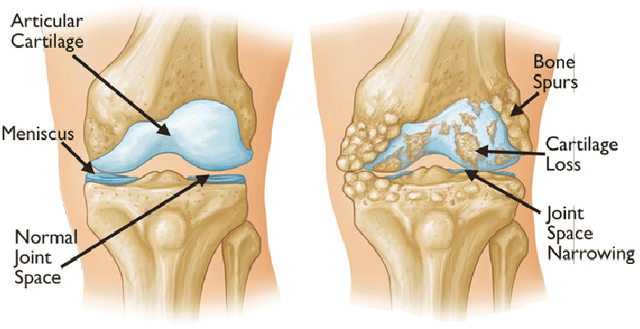
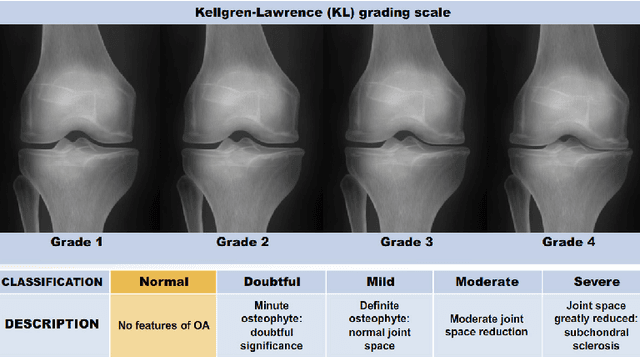
This chapter presents the investigations and the results of feature learning using convolutional neural networks to automatically assess knee osteoarthritis (OA) severity and the associated clinical and diagnostic features of knee OA from X-ray images. Also, this chapter demonstrates that feature learning in a supervised manner is more effective than using conventional handcrafted features for automatic detection of knee joints and fine-grained knee OA image classification. In the general machine learning approach to automatically assess knee OA severity, the first step is to localize the region of interest that is to detect and extract the knee joint regions from the radiographs, and the next step is to classify the localized knee joints based on a radiographic classification scheme such as Kellgren and Lawrence grades. First, the existing approaches for detecting (or localizing) the knee joint regions based on handcrafted features are reviewed and outlined. Next, three new approaches are introduced: 1) to automatically detect the knee joint region using a fully convolutional network, 2) to automatically assess the radiographic knee OA using CNNs trained from scratch for classification and regression of knee joint images to predict KL grades in ordinal and continuous scales, and 3) to quantify the knee OA severity optimizing a weighted ratio of two loss functions: categorical cross entropy and mean-squared error using multi-objective convolutional learning and ordinal regression. Two public datasets: the OAI and the MOST are used to evaluate the approaches with promising results that outperform existing approaches. In summary, this work primarily contributes to the field of automated methods for localization (automatic detection) and quantification (image classification) of radiographic knee OA.
iSAID: A Large-scale Dataset for Instance Segmentation in Aerial Images
May 30, 2019
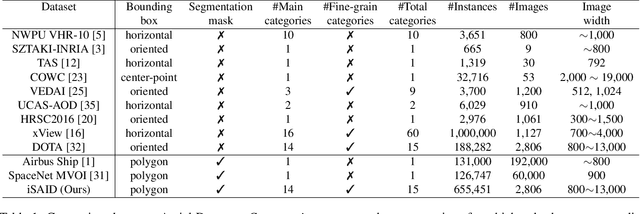
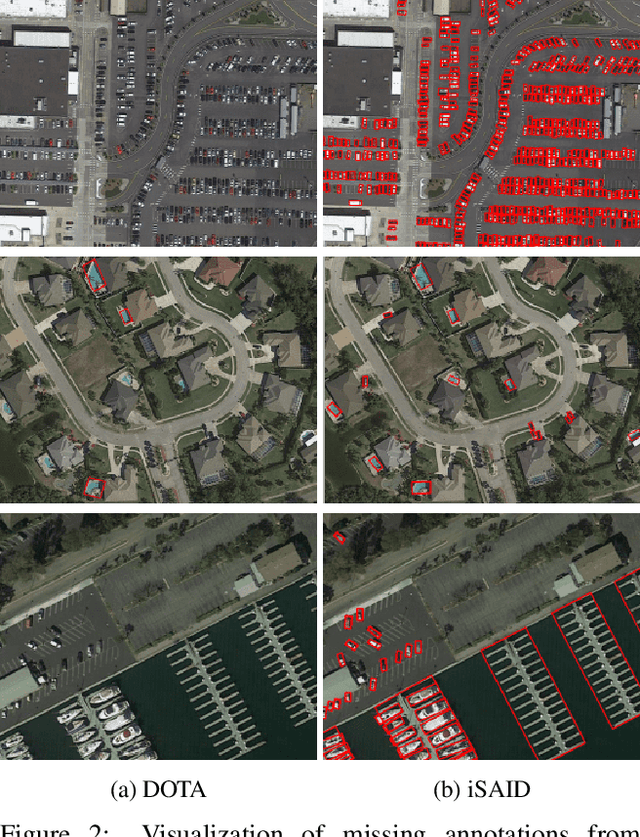
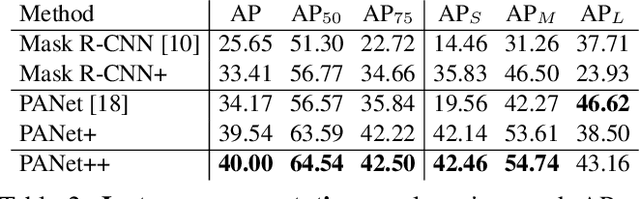
Existing Earth Vision datasets are either suitable for semantic segmentation or object detection. In this work, we introduce the first benchmark dataset for instance segmentation in aerial imagery that combines instance-level object detection and pixel-level segmentation tasks. In comparison to instance segmentation in natural scenes, aerial images present unique challenges e.g., a huge number of instances per image, large object-scale variations and abundant tiny objects. Our large-scale and densely annotated Instance Segmentation in Aerial Images Dataset (iSAID) comes with 655,451 object instances for 15 categories across 2,806 high-resolution images. Such precise per-pixel annotations for each instance ensure accurate localization that is essential for detailed scene analysis. Compared to existing small-scale aerial image based instance segmentation datasets, iSAID contains 15$\times$ the number of object categories and 5$\times$ the number of instances. We benchmark our dataset using two popular instance segmentation approaches for natural images, namely Mask R-CNN and PANet. In our experiments we show that direct application of off-the-shelf Mask R-CNN and PANet on aerial images provide suboptimal instance segmentation results, thus requiring specialized solutions from the research community.
Visuallly Grounded Generation of Entailments from Premises
Sep 21, 2019
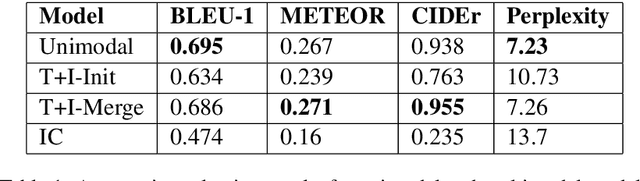
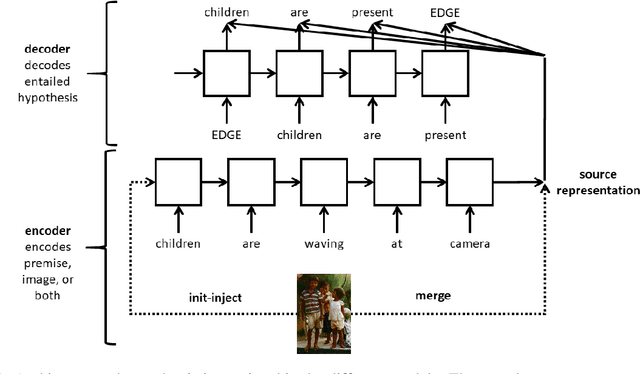

Natural Language Inference (NLI) is the task of determining the semantic relationship between a premise and a hypothesis. In this paper, we focus on the {\em generation} of hypotheses from premises in a multimodal setting, to generate a sentence (hypothesis) given an image and/or its description (premise) as the input. The main goals of this paper are (a) to investigate whether it is reasonable to frame NLI as a generation task; and (b) to consider the degree to which grounding textual premises in visual information is beneficial to generation. We compare different neural architectures, showing through automatic and human evaluation that entailments can indeed be generated successfully. We also show that multimodal models outperform unimodal models in this task, albeit marginally.
Dragonfly Algorithm and its Applications in Applied Science -- Survey
Nov 25, 2019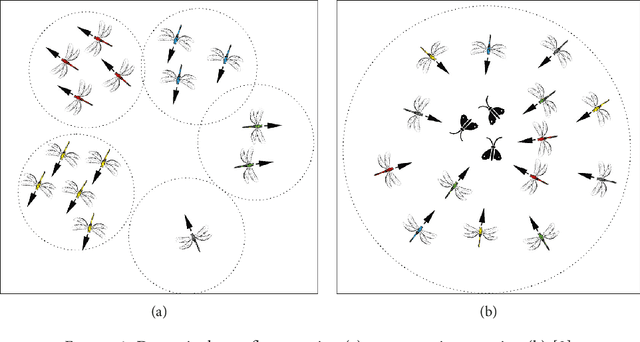
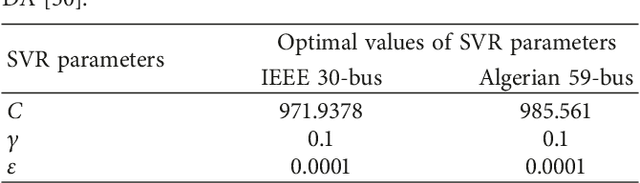
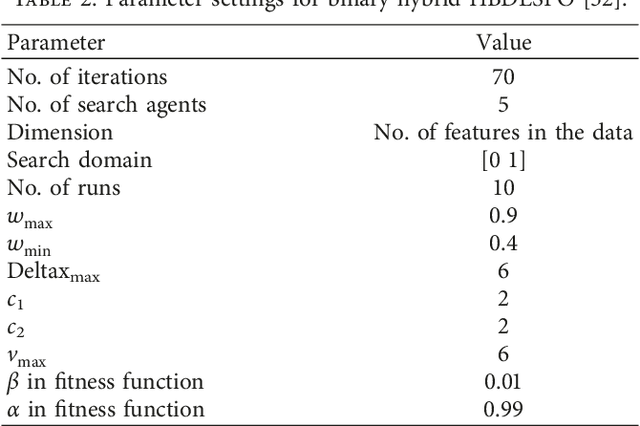
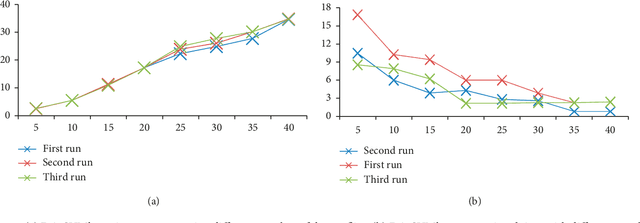
One of the most recently developed heuristic optimization algorithms is dragonfly by Mirjalili. Dragonfly algorithm has shown its ability to optimizing different real world problems. It has three variants. In this work, an overview of the algorithm and its variants is presented. Moreover, the hybridization versions of the algorithm are discussed. Furthermore, the results of the applications that utilized dragonfly algorithm in applied science are offered in the following area: Machine Learning, Image Processing, Wireless, and Networking. It is then compared with some other metaheuristic algorithms. In addition, the algorithm is tested on the CEC-C06 2019 benchmark functions. The results prove that the algorithm has great exploration ability and its convergence rate is better than other algorithms in the literature, such as PSO and GA. In general, in this survey the strong and weak points of the algorithm are discussed. Furthermore, some future works that will help in improving the algorithm's weak points are recommended. This study is conducted with the hope of offering beneficial information about dragonfly algorithm to the researchers who want to study the algorithm.
Occupancy Detection in Vehicles Using Fisher Vector Image Representation
Dec 20, 2013


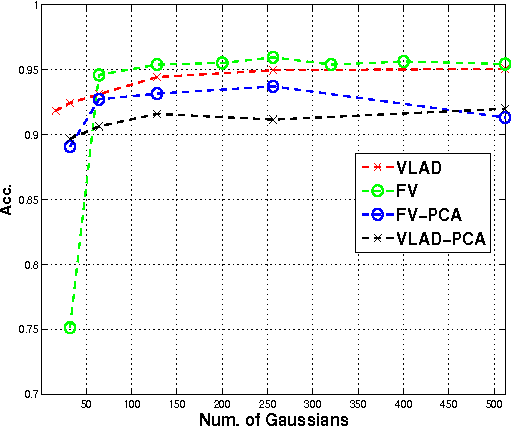
Due to the high volume of traffic on modern roadways, transportation agencies have proposed High Occupancy Vehicle (HOV) lanes and High Occupancy Tolling (HOT) lanes to promote car pooling. However, enforcement of the rules of these lanes is currently performed by roadside enforcement officers using visual observation. Manual roadside enforcement is known to be inefficient, costly, potentially dangerous, and ultimately ineffective. Violation rates up to 50%-80% have been reported, while manual enforcement rates of less than 10% are typical. Therefore, there is a need for automated vehicle occupancy detection to support HOV/HOT lane enforcement. A key component of determining vehicle occupancy is to determine whether or not the vehicle's front passenger seat is occupied. In this paper, we examine two methods of determining vehicle front seat occupancy using a near infrared (NIR) camera system pointed at the vehicle's front windshield. The first method examines a state-of-the-art deformable part model (DPM) based face detection system that is robust to facial pose. The second method examines state-of- the-art local aggregation based image classification using bag-of-visual-words (BOW) and Fisher vectors (FV). A dataset of 3000 images was collected on a public roadway and is used to perform the comparison. From these experiments it is clear that the image classification approach is superior for this problem.
Deep Decomposition Learning for Inverse Imaging Problems
Nov 25, 2019



Deep learning is emerging as a new paradigm for solving inverse imaging problems. However, the deep learning methods often lack the assurance of traditional physics-based methods due to the lack of physical information considerations in neural network training and deploying. The appropriate supervision and explicit calibration by the information of the physic model can enhance the neural network learning and its practical performance. In this paper, inspired by the geometry that data can be decomposed by two components from the null-space of the forward operator and the range space of its pseudo-inverse, we train neural networks to learn the two components and therefore learn the decomposition, i.e. we explicitly reformulate the neural network layers as learning range-nullspace decomposition functions with reference to the layer inputs, instead of learning unreferenced functions. We show that the decomposition networks not only produce superior results, but also enjoy good interpretability and generalization. We demonstrate the advantages of decomposition learning on different inverse problems including compressive sensing and image super-resolution as examples.
ColorFool: Semantic Adversarial Colorization
Nov 25, 2019



Adversarial attacks that generate small L_p-norm perturbations to mislead classifiers have limited success in black-box settings and with unseen classifiers. These attacks are also fragile with defenses that use denoising filters and to adversarial training procedures. Instead, adversarial attacks that generate unrestricted perturbations are more robust to defenses, are generally more successful in black-box settings and are more transferable to unseen classifiers. However, unrestricted perturbations may be noticeable to humans. In this paper, we propose a content-based black-box adversarial attack that generates unrestricted perturbations by exploiting image semantics to selectively modify colors within chosen ranges that are perceived as natural by humans. We show that the proposed approach, ColorFool, outperforms in terms of success rate, robustness to defense frameworks and transferability five state-of-the-art adversarial attacks on two different tasks, scene and object classification, when attacking three state-of-the-art deep neural networks using three standard datasets. We will make the code of the proposed approach and the whole evaluation framework publicly available.
Generating Adaptive and Robust Filter Sets Using an Unsupervised Learning Framework
Nov 21, 2018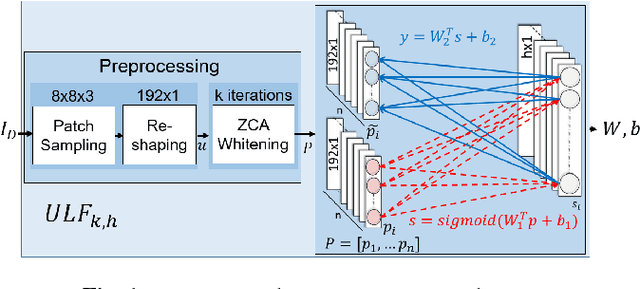
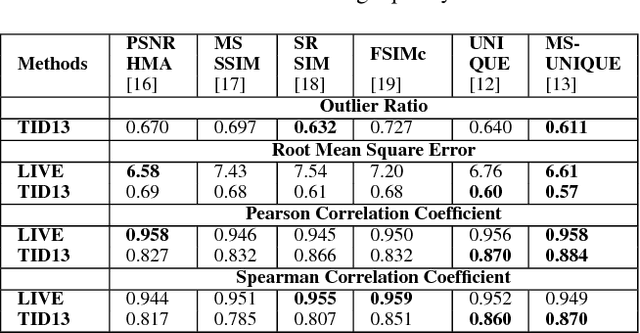
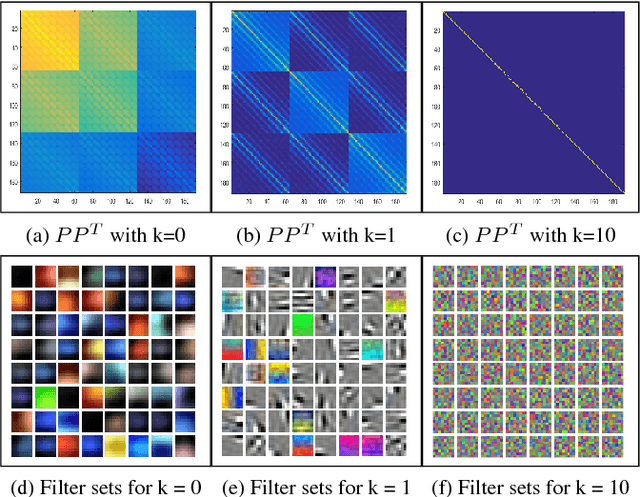
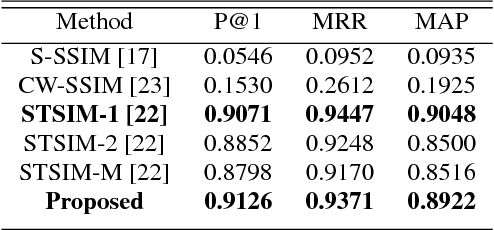
In this paper, we introduce an adaptive unsupervised learning framework, which utilizes natural images to train filter sets. The applicability of these filter sets is demonstrated by evaluating their performance in two contrasting applications - image quality assessment and texture retrieval. While assessing image quality, the filters need to capture perceptual differences based on dissimilarities between a reference image and its distorted version. In texture retrieval, the filters need to assess similarity between texture images to retrieve closest matching textures. Based on experiments, we show that the filter responses span a set in which a monotonicity-based metric can measure both the perceptual dissimilarity of natural images and the similarity of texture images. In addition, we corrupt the images in the test set and demonstrate that the proposed method leads to robust and reliable retrieval performance compared to existing methods.
* Paper:5 pages, 5 figures, 3 tables and Poster [Ancillary files]