 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SegTHOR: Segmentation of Thoracic Organs at Risk in CT images
Dec 12, 2019
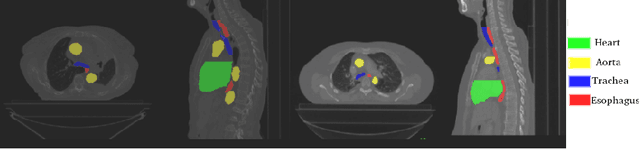
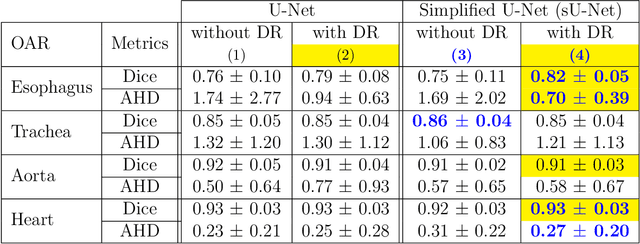
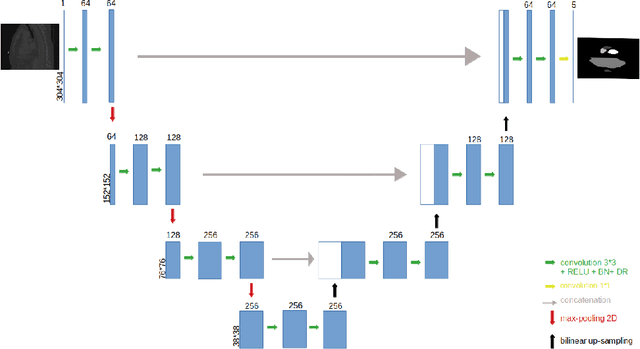
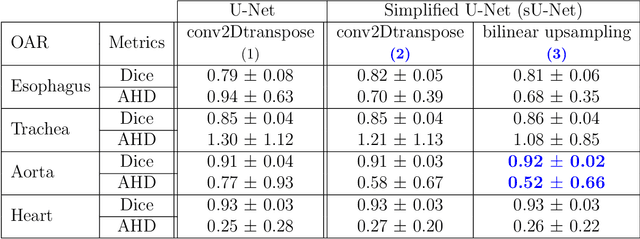
In the era of open science, public datasets, along with common experimental protocol, help in the process of designing and validating data science algorithms; they also contribute to ease reproductibility and fair comparison between methods. Many datasets for image segmentation are available, each presenting its own challenges; however just a very few exist for radiotherapy planning. This paper is the presentation of a new dataset dedicated to the segmentation of organs at risk (OARs) in the thorax, i.e. the organs surrounding the tumour that must be preserved from irradiations during radiotherapy. This dataset is called SegTHOR (Segmentation of THoracic Organs at Risk). In this dataset, the OARs are the heart, the trachea, the aorta and the esophagus, which have varying spatial and appearance characteristics. The dataset includes 60 3D CT scans, divided into a training set of 40 and a test set of 20 patients, where the OARs have been contoured manually by an experienced radiotherapist. Along with the dataset, we present some baseline results, obtained using both the original, state-of-the-art architecture U-Net and a simplified version. We investigate different configurations of this baseline architecture that will serve as comparison for future studies on the SegTHOR dataset. Preliminary results show that room for improvement is left, especially for smallest organs.
Deep Q learning for fooling neural networks
Nov 13, 2018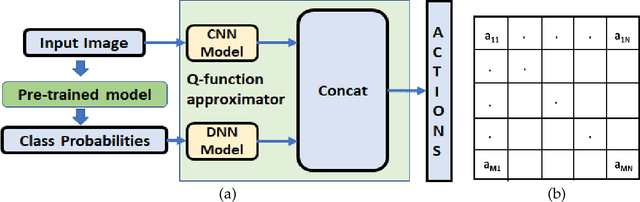

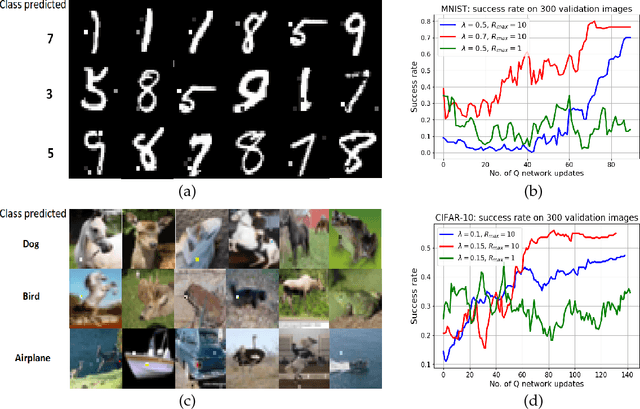
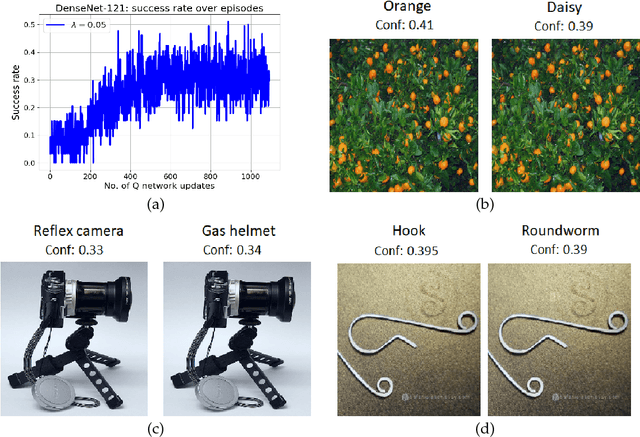
Deep learning models are vulnerable to external attacks. In this paper, we propose a Reinforcement Learning (RL) based approach to generate adversarial examples for the pre-trained (target) models. We assume a semi black-box setting where the only access an adversary has to the target model is the class probabilities obtained for the input queries. We train a Deep Q Network (DQN) agent which, with experience, learns to attack only a small portion of image pixels to generate non-targeted adversarial images. Initially, an agent explores an environment by sequentially modifying random sets of image pixels and observes its effect on the class probabilities. At the end of an episode, it receives a positive (negative) reward if it succeeds (fails) to alter the label of the image. Experimental results with MNIST, CIFAR-10 and Imagenet datasets demonstrate that our RL framework is able to learn an effective attack policy.
Graph Representation Learning: A Survey
Sep 03, 2019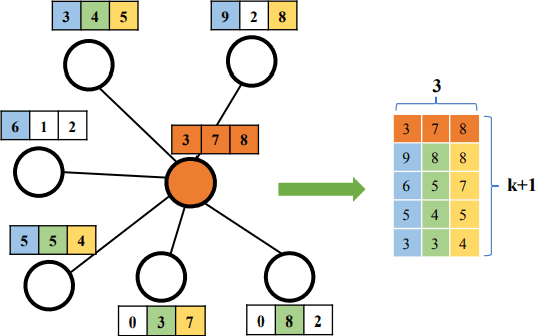
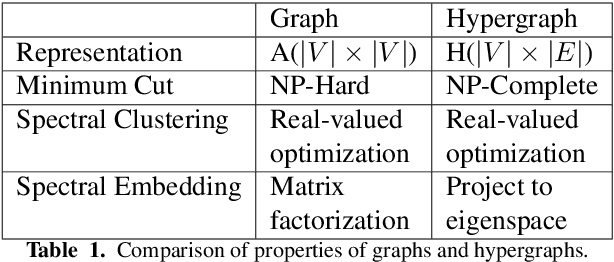
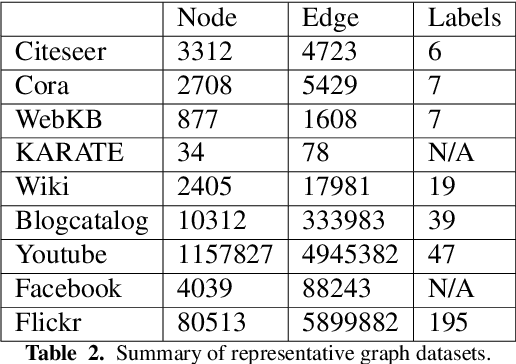
Research on graph representation learning has received a lot of attention in recent years since many data in real-world applications come in form of graphs. High-dimensional graph data are often in irregular form, which makes them more difficult to analyze than image/video/audio data defined on regular lattices. Various graph embedding techniques have been developed to convert the raw graph data into a low-dimensional vector representation while preserving the intrinsic graph properties. In this review, we first explain the graph embedding task and its challenges. Next, we review a wide range of graph embedding techniques with insights. Then, we evaluate several state-of-the-art methods against small and large datasets and compare their performance. Finally, potential applications and future directions are presented.
Totally Deep Support Vector Machines
Dec 12, 2019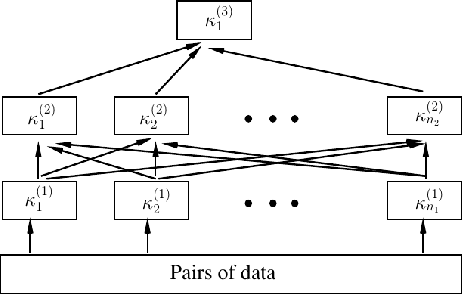

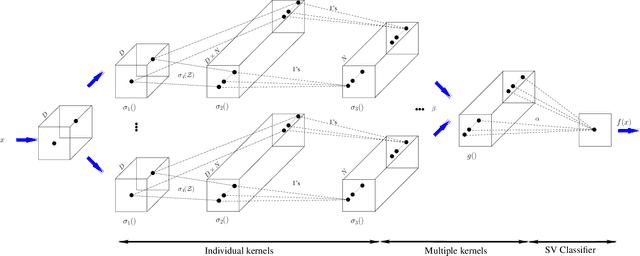
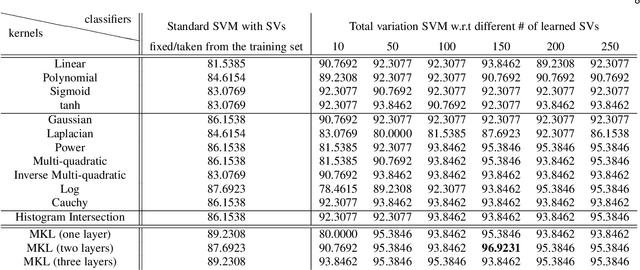
Support vector machines (SVMs) have been successful in solving many computer vision tasks including image and video category recognition especially for small and mid-scale training problems. The principle of these non-parametric models is to learn hyperplanes that separate data belonging to different classes while maximizing their margins. However, SVMs constrain the learned hyperplanes to lie in the span of support vectors, fixed/taken from training data, and this reduces their representational power and may lead to limited generalization performances. In this paper, we relax this constraint and allow the support vectors to be learned (instead of being fixed/taken from training data) in order to better fit a given classification task. Our approach, referred to as deep total variation support vector machines, is parametric and relies on a novel deep architecture that learns not only the SVM and the kernel parameters but also the support vectors, resulting into highly effective classifiers. We also show (under a particular setting of the activation functions in this deep architecture) that a large class of kernels and their combinations can be learned. Experiments conducted on the challenging task of skeleton-based action recognition show the outperformance of our deep total variation SVMs w.r.t different baselines as well as the related work.
Transfer Learning in 4D for Breast Cancer Diagnosis using Dynamic Contrast-Enhanced Magnetic Resonance Imaging
Nov 08, 2019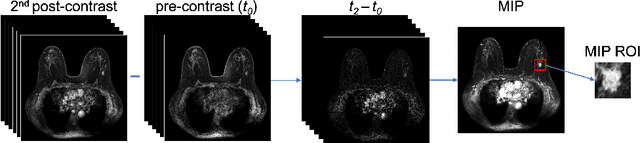
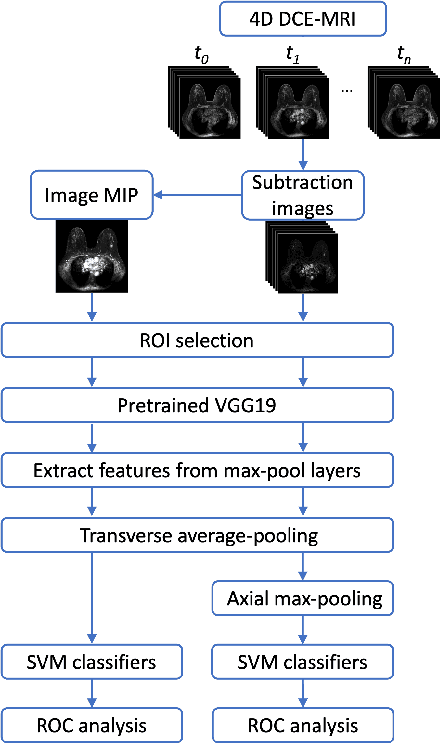
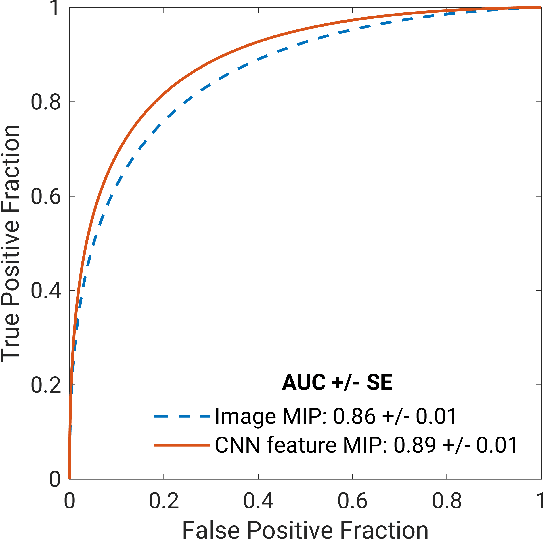
Deep transfer learning using dynamic contrast-enhanced magnetic resonance imaging (DCE-MRI) has shown strong predictive power in characterization of breast lesions. However, pretrained convolutional neural networks (CNNs) require 2D inputs, limiting the ability to exploit the rich 4D (volumetric and temporal) image information inherent in DCE-MRI that is clinically valuable for lesion assessment. Training 3D CNNs from scratch, a common method to utilize high-dimensional information in medical images, is computationally expensive and is not best suited for moderately sized healthcare datasets. Therefore, we propose a novel approach using transfer learning that incorporates the 4D information from DCE-MRI, where volumetric information is collapsed at feature level by max pooling along the projection perpendicular to the transverse slices and the temporal information is contained either in second-post contrast subtraction images. Our methodology yielded an area under the receiver operating characteristic curve of 0.89+/-0.01 on a dataset of 1161 breast lesions, significantly outperforming a previous approach that incorporates the 4D information in DCE-MRI by the use of maximum intensity projection (MIP) images.
Repeatability of Multiparametric Prostate MRI Radiomics Features
Jul 16, 2018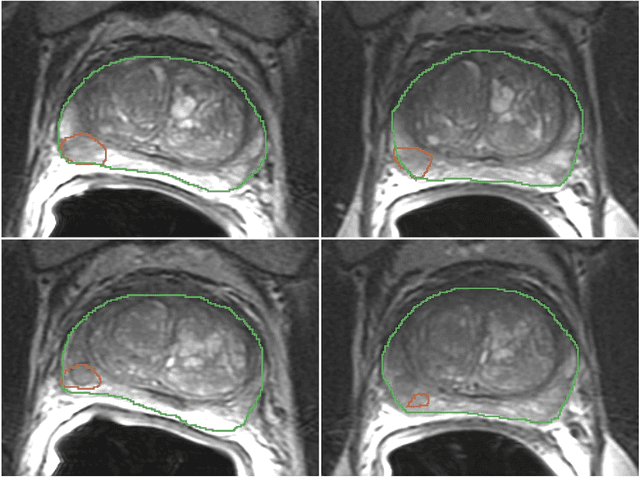
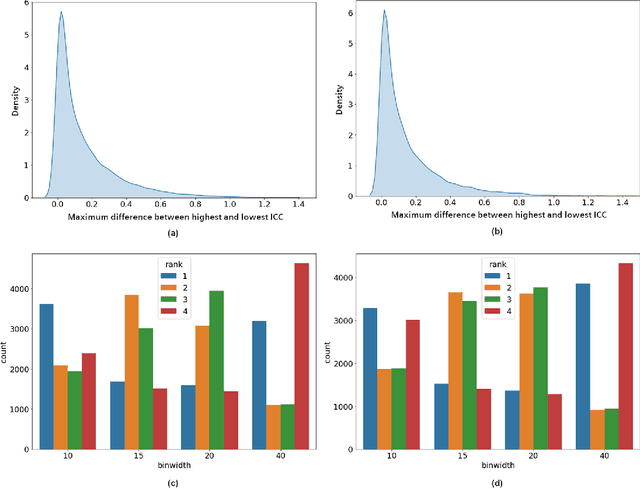
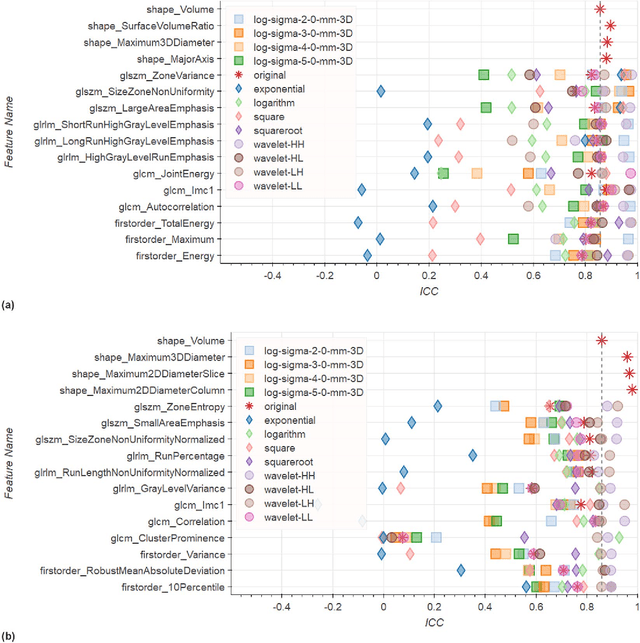
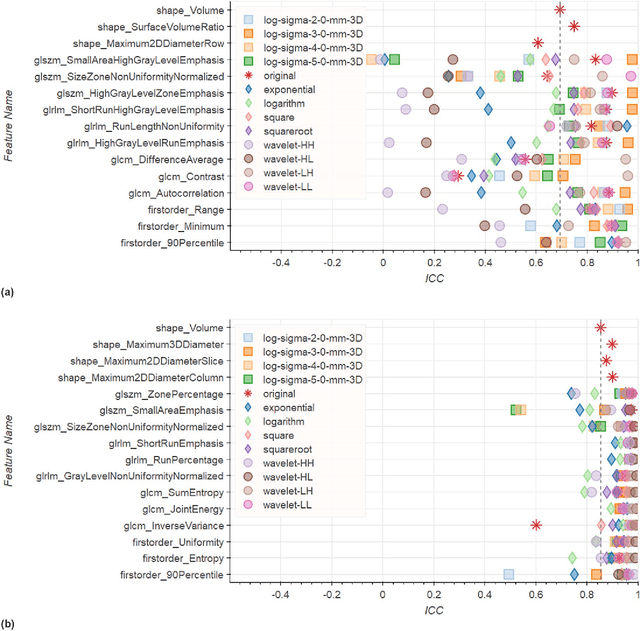
In this study we assessed the repeatability of the values of radiomics features for small prostate tumors using test-retest? Multiparametric Magnetic Resonance Imaging (mpMRI) images. The premise of radiomics is that quantitative image features can serve as biomarkers characterizing disease. For such biomarkers to be useful, repeatability is a basic requirement, meaning its value must remain stable between two scans, if the conditions remain stable. We investigated repeatability of radiomics features under various preprocessing and extraction configurations including various image normalization schemes, different image pre-filtering, 2D vs 3D texture computation, and different bin widths for image discretization. Image registration as means to re-identify regions of interest across time points was evaluated against human-expert segmented regions in both time points. Even though we found many radiomics features and preprocessing combinations with a high repeatability (Intraclass Correlation Coefficient (ICC) > 0.85), our results indicate that overall the repeatability is highly sensitive to the processing parameters (under certain configurations, it can be below 0.0). Image normalization, using a variety of approaches considered, did not result in consistent improvements in repeatability. There was also no consistent improvement of repeatability through the use of pre-filtering options, or by using image registration between timepoints to improve consistency of the region of interest localization. Based on these results we urge caution when interpreting radiomics features and advise paying close attention to the processing configuration details of reported results. Furthermore, we advocate reporting all processing details in radiomics studies and strongly recommend making the implementation available.
Local Context Normalization: Revisiting Local Normalization
Dec 12, 2019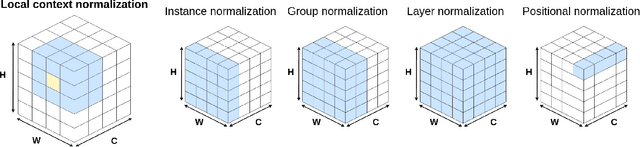
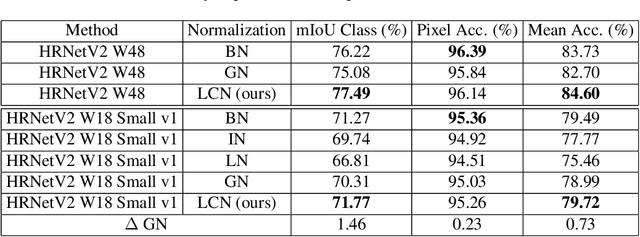
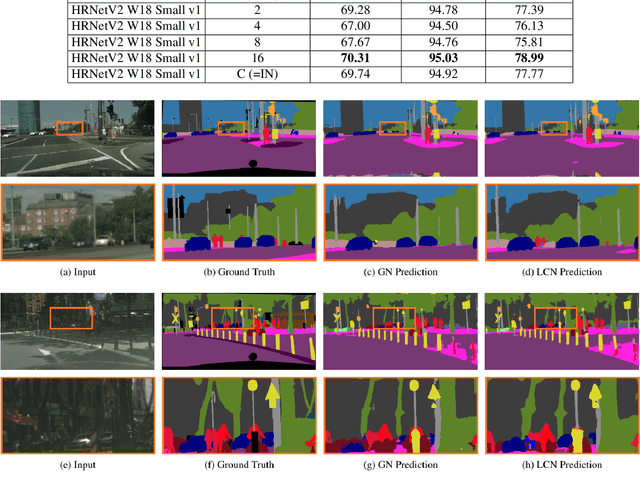

Normalization layers have been shown to improve convergence in deep neural networks. In many vision applications the local spatial context of the features is important, but most common normalization schemes includingGroup Normalization (GN), Instance Normalization (IN), and Layer Normalization (LN) normalize over the entire spatial dimension of a feature. This can wash out important signals and degrade performance. For example, in applications that use satellite imagery, input images can be arbitrarily large; consequently, it is nonsensical to normalize over the entire area. Positional Normalization (PN), on the other hand, only normalizes over a single spatial position at a time. A natural compromise is to normalize features by local context, while also taking into account group level information. In this paper, we propose Local Context Normalization (LCN): a normalization layer where every feature is normalized based on a window around it and the filters in its group. We propose an algorithmic solution to make LCN efficient for arbitrary window sizes, even if every point in the image has a unique window. LCN outperforms its Batch Normalization (BN), GN, IN, and LN counterparts for object detection, semantic segmentation, and instance segmentation applications in several benchmark datasets, while keeping performance independent of the batch size and facilitating transfer learning.
Quantile Representation for Indirect Immunofluorescence Image Classification
Feb 06, 2014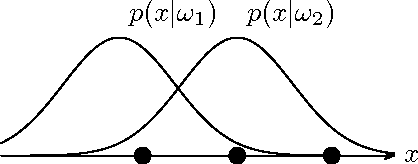
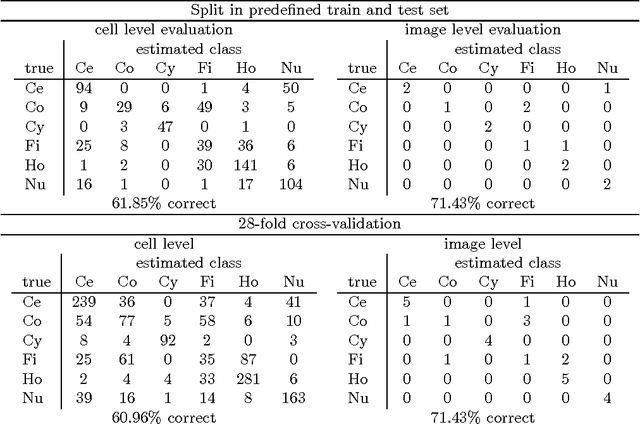
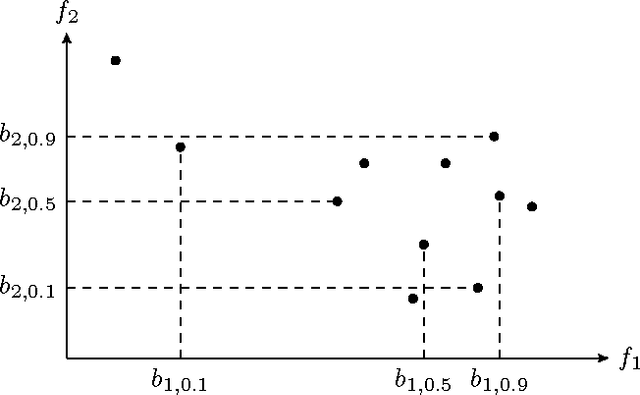
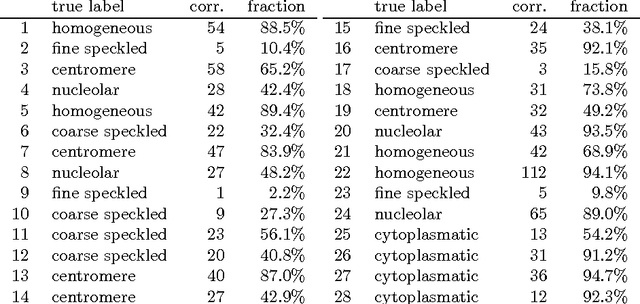
In the diagnosis of autoimmune diseases, an important task is to classify images of slides containing several HEp-2 cells. All cells from one slide share the same label, and by classifying cells from one slide independently, some information on the global image quality and intensity is lost. Considering one whole slide as a collection (a bag) of feature vectors, however, poses the problem of how to handle this bag. A simple, and surprisingly effective, approach is to summarize the bag of feature vectors by a few quantile values per feature. This characterizes the full distribution of all instances, thereby assuming that all instances in a bag are informative. This representation is particularly useful when each bag contains many feature vectors, which is the case in the classification of the immunofluorescence images. Experiments on the classification of indirect immunofluorescence images show the usefulness of this approach.
Estimating 3D Camera Pose from 2D Pedestrian Trajectories
Dec 12, 2019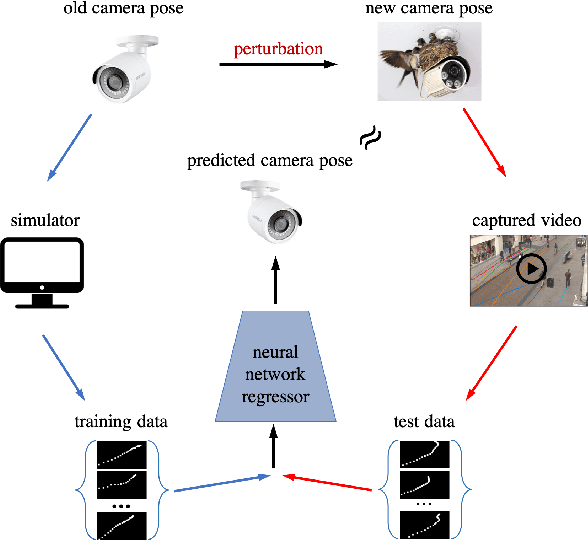
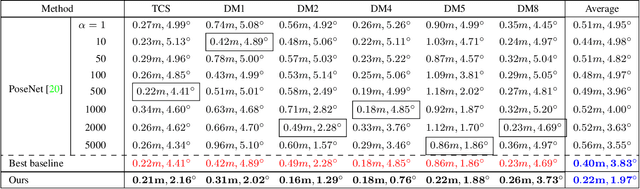
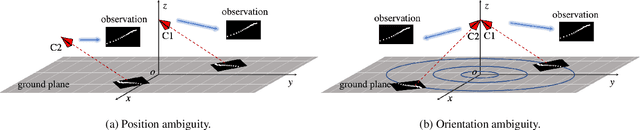
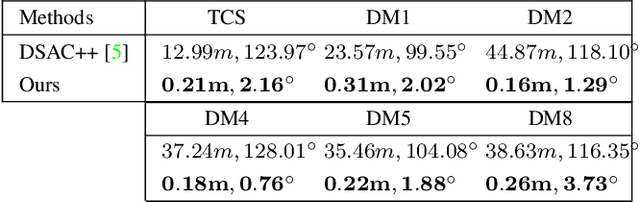
We consider the task of re-calibrating the 3D pose of a static surveillance camera, whose pose may change due to external forces, such as birds, wind, falling objects or earthquakes. Conventionally, camera pose estimation can be solved with a PnP (Perspective-n-Point) method using 2D-to-3D feature correspondences, when 3D points are known. However, 3D point annotations are not always available or practical to obtain in real-world applications. We propose an alternative strategy for extracting 3D information to solve for camera pose by using pedestrian trajectories. We observe that 2D pedestrian trajectories indirectly contain useful 3D information that can be used for inferring camera pose. To leverage this information, we propose a data-driven approach by training a neural network (NN) regressor to model a direct mapping from 2D pedestrian trajectories projected on the image plane to 3D camera pose. We demonstrate that our regressor trained only on synthetic data can be directly applied to real data, thus eliminating the need to label any real data. We evaluate our method across six different scenes from the Town Centre Street and DUKEMTMC datasets. Our method achieves an average location error of $0.22m$ and orientation error of $1.97^\circ$.
Fashion++: Minimal Edits for Outfit Improvement
Apr 19, 2019

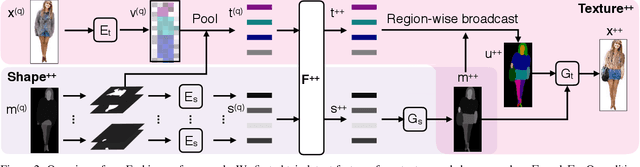
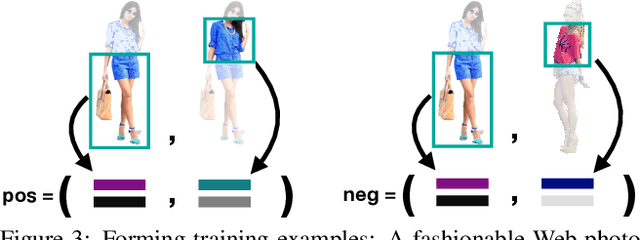
Given an outfit, what small changes would most improve its fashionability? This question presents an intriguing new vision challenge. We introduce Fashion++, an approach that proposes minimal adjustments to a full-body clothing outfit that will have maximal impact on its fashionability. Our model consists of a deep image generation neural network that learns to synthesize clothing conditioned on learned per-garment encodings. The latent encodings are explicitly factorized according to shape and texture, thereby allowing direct edits for both fit/presentation and color/patterns/material, respectively. We show how to bootstrap Web photos to automatically train a fashionability model, and develop an activation maximization-style approach to transform the input image into its more fashionable self. The edits suggested range from swapping in a new garment to tweaking its color, how it is worn (e.g., rolling up sleeves), or its fit (e.g., making pants baggier). Experiments demonstrate that Fashion++ provides successful edits, both according to automated metrics and human opinion. Project page is at http://vision.cs.utexas.edu/projects/FashionPlus.