 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Local Context Normalization: Revisiting Local Normalization
Dec 13, 2019
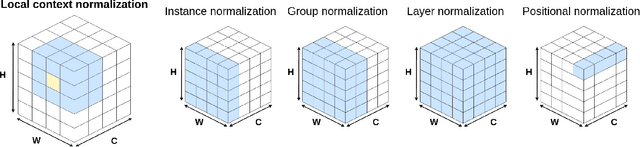
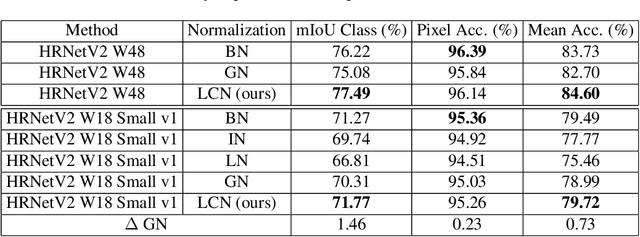
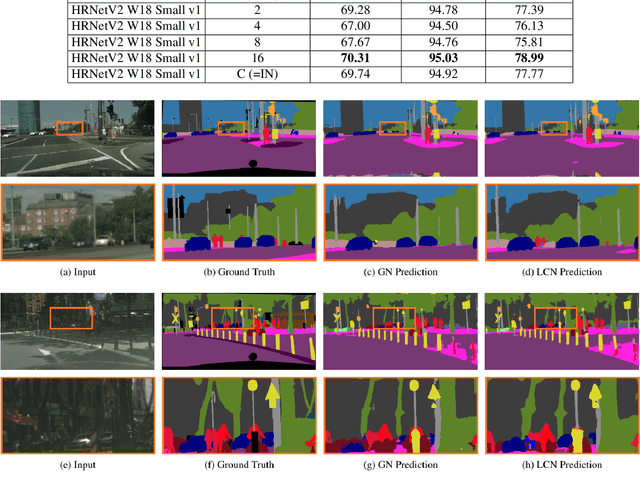

Normalization layers have been shown to improve convergence in deep neural networks. In many vision applications the local spatial context of the features is important, but most common normalization schemes includingGroup Normalization (GN), Instance Normalization (IN), and Layer Normalization (LN) normalize over the entire spatial dimension of a feature. This can wash out important signals and degrade performance. For example, in applications that use satellite imagery, input images can be arbitrarily large; consequently, it is nonsensical to normalize over the entire area. Positional Normalization (PN), on the other hand, only normalizes over a single spatial position at a time. A natural compromise is to normalize features by local context, while also taking into account group level information. In this paper, we propose Local Context Normalization (LCN): a normalization layer where every feature is normalized based on a window around it and the filters in its group. We propose an algorithmic solution to make LCN efficient for arbitrary window sizes, even if every point in the image has a unique window. LCN outperforms its Batch Normalization (BN), GN, IN, and LN counterparts for object detection, semantic segmentation, and instance segmentation applications in several benchmark datasets, while keeping performance independent of the batch size and facilitating transfer learning.
Quantile Representation for Indirect Immunofluorescence Image Classification
Feb 06, 2014
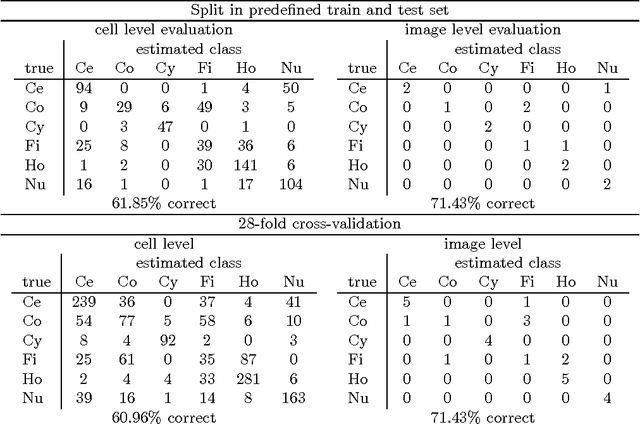
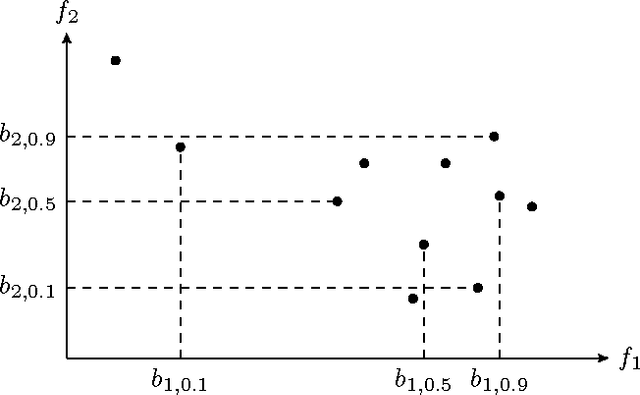
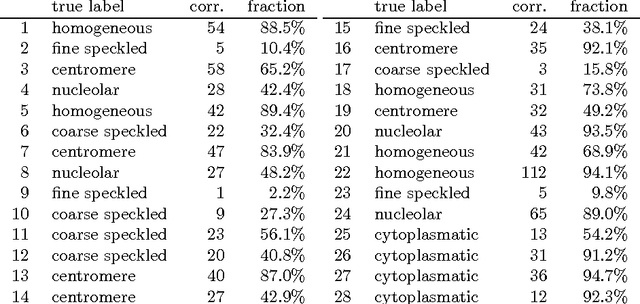
In the diagnosis of autoimmune diseases, an important task is to classify images of slides containing several HEp-2 cells. All cells from one slide share the same label, and by classifying cells from one slide independently, some information on the global image quality and intensity is lost. Considering one whole slide as a collection (a bag) of feature vectors, however, poses the problem of how to handle this bag. A simple, and surprisingly effective, approach is to summarize the bag of feature vectors by a few quantile values per feature. This characterizes the full distribution of all instances, thereby assuming that all instances in a bag are informative. This representation is particularly useful when each bag contains many feature vectors, which is the case in the classification of the immunofluorescence images. Experiments on the classification of indirect immunofluorescence images show the usefulness of this approach.
FAN: Feature Adaptation Network for Surveillance Face Recognition and Normalization
Nov 26, 2019
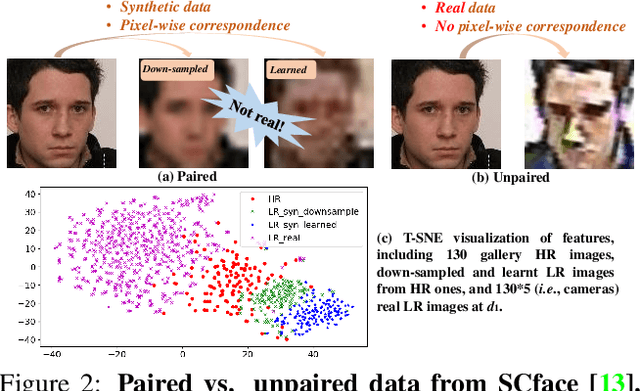

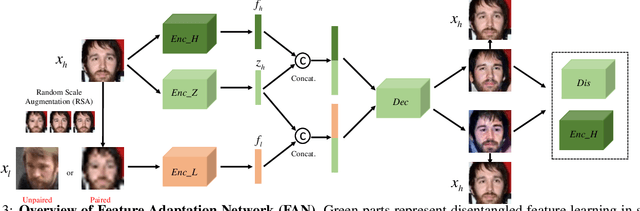
This paper studies face recognition (FR) and normalization in surveillance imagery. Surveillance FR is a challenging problem that has great values in law enforcement. Despite recent progress in conventional FR, less effort has been devoted to surveillance FR. To bridge this gap, we propose a Feature Adaptation Network (FAN) to jointly perform surveillance FR and normalization. Our face normalization mainly acts on the aspect of image resolution, closely related to face super-resolution. However, previous face super-resolution methods require paired training data with pixel-to-pixel correspondence, which is typically unavailable between real low- and high-resolution faces. Our FAN can leverage both paired and unpaired data as we disentangle the features into identity and non-identity components and adapt the distribution of the identity features, which breaks the limit of current face super-resolution methods. We further propose a random scale augmentation scheme to learn resolution robust identity features, with advantages over previous fixed scale augmentation. Extensive experiments on LFW, WIDER FACE, QUML-SurvFace and SCface datasets have demonstrated the superiority of our proposed method compared to the state of the arts on surveillance face recognition and normalization.
Deep convolutional Gaussian processes
Oct 06, 2018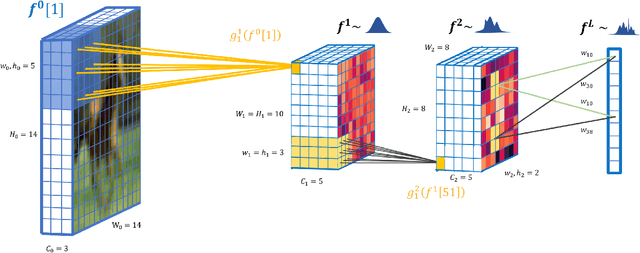
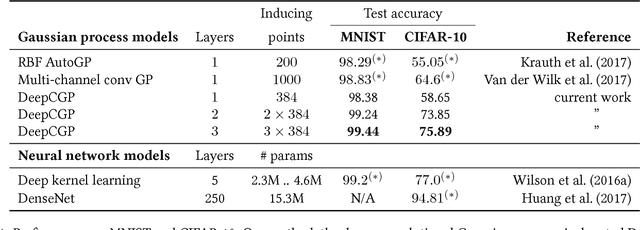
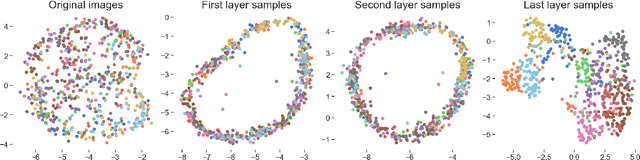
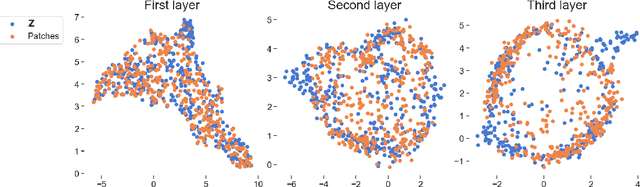
We propose deep convolutional Gaussian processes, a deep Gaussian process architecture with convolutional structure. The model is a principled Bayesian framework for detecting hierarchical combinations of local features for image classification. We demonstrate greatly improved image classification performance compared to current Gaussian process approaches on the MNIST and CIFAR-10 datasets. In particular, we improve CIFAR-10 accuracy by over 10 percentage points.
Deep Q learning for fooling neural networks
Nov 13, 2018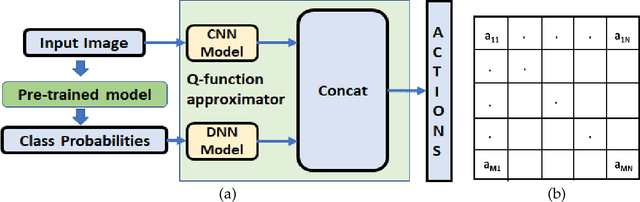

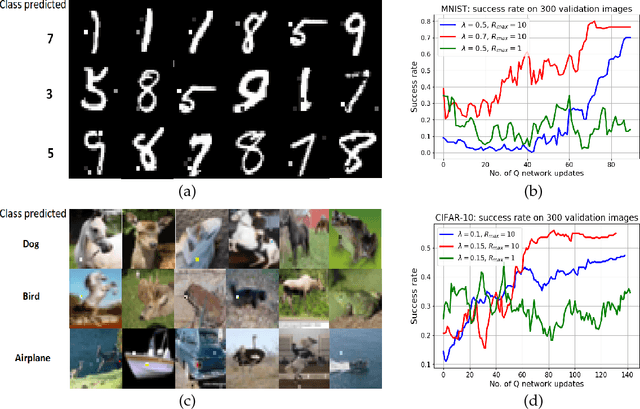
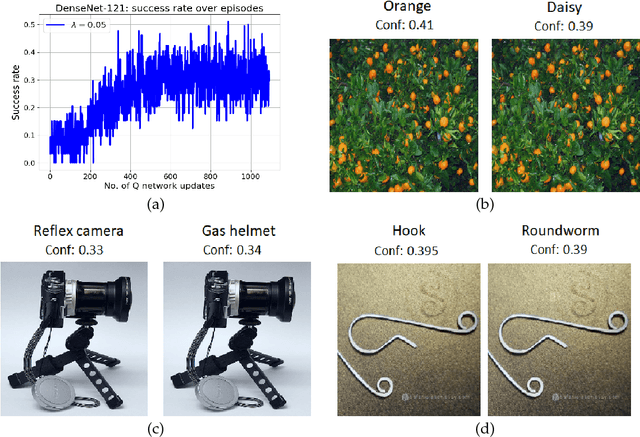
Deep learning models are vulnerable to external attacks. In this paper, we propose a Reinforcement Learning (RL) based approach to generate adversarial examples for the pre-trained (target) models. We assume a semi black-box setting where the only access an adversary has to the target model is the class probabilities obtained for the input queries. We train a Deep Q Network (DQN) agent which, with experience, learns to attack only a small portion of image pixels to generate non-targeted adversarial images. Initially, an agent explores an environment by sequentially modifying random sets of image pixels and observes its effect on the class probabilities. At the end of an episode, it receives a positive (negative) reward if it succeeds (fails) to alter the label of the image. Experimental results with MNIST, CIFAR-10 and Imagenet datasets demonstrate that our RL framework is able to learn an effective attack policy.
WSOD with PSNet and Box Regression
Nov 26, 2019
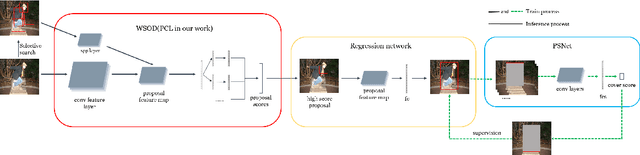
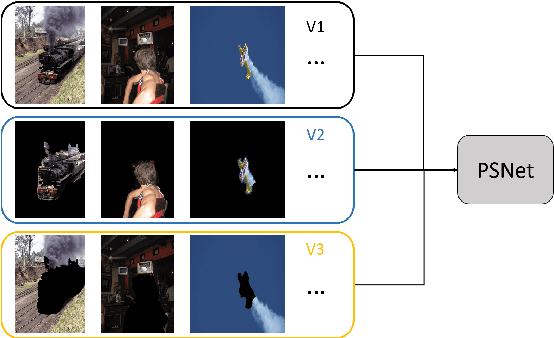

Weakly supervised object detection(WSOD) task uses only image-level annotations to train object detection task. WSOD does not require time-consuming instance-level annotations, so the study of this task has attracted more and more attention. Previous weakly supervised object detection methods iteratively update detectors and pseudo-labels, or use feature-based mask-out methods. Most of these methods do not generate complete and accurate proposals, often only the most discriminative parts of the object, or too many background areas. To solve this problem, we added the box regression module to the weakly supervised object detection network and proposed a proposal scoring network (PSNet) to supervise it. The box regression module modifies proposal to improve the IoU of proposal and ground truth. PSNet scores the proposal output from the box regression network and utilize the score to improve the box regression module. In addition, we take advantage of the PRS algorithm for generating a more accurate pseudo label to train the box regression module. Using these methods, we train the detector on the PASCAL VOC 2007 and 2012 and obtain significantly improved results.
Visual Explanation for Deep Metric Learning
Sep 27, 2019
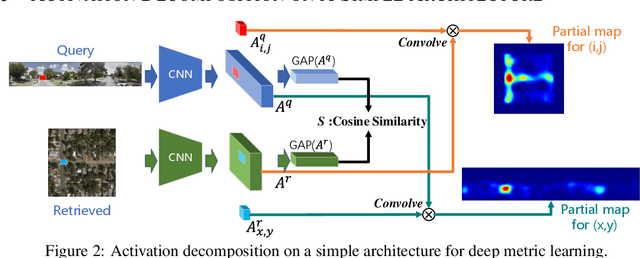
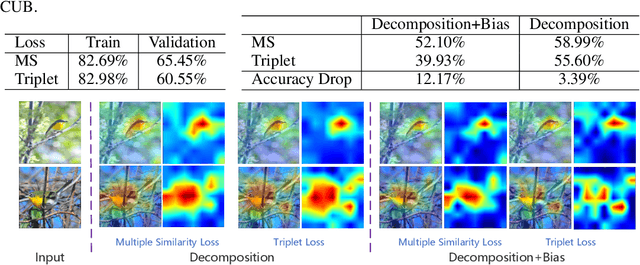
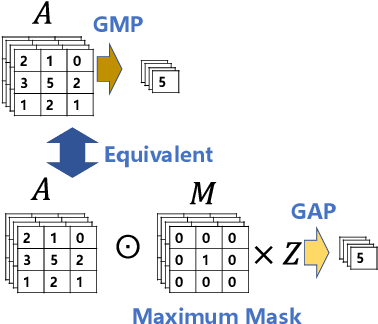
This work explores the visual explanation for deep metric learning and its applications. As an important problem for learning representation, metric learning has attracted much attention recently, while the interpretation of such model is not as well studied as classification. To this end, we propose an intuitive idea to show where contributes the most to the overall similarity of two input images by decomposing the final activation. Instead of only providing the overall activation map of each image, we propose to generate point-to-point activation intensity between two images so that the relationship between different regions is uncovered. We show that the proposed framework can be directly deployed to a large range of metric learning applications and provides valuable information for understanding the model. Furthermore, our experiments show its effectiveness on two potential applications, i.e. cross-view pattern discovery and interactive retrieval.
Fast and Efficient Model for Real-Time Tiger Detection In The Wild
Sep 03, 2019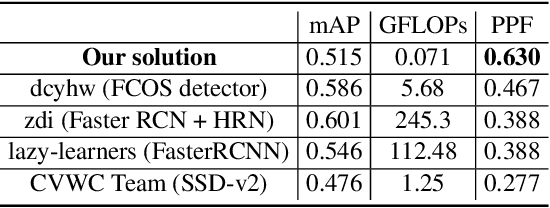
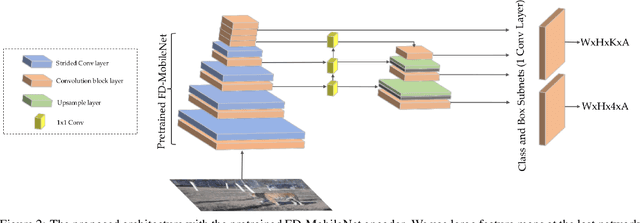


The highest accuracy object detectors to date are based either on a two-stage approach such as Fast R-CNN or one-stage detectors such as Retina-Net or SSD with deep and complex backbones. In this paper we present TigerNet - simple yet efficient FPN based network architecture for Amur Tiger Detection in the wild. The model has 600k parameters, requires 0.071 GFLOPs per image and can run on the edge devices (smart cameras) in near real time. In addition, we introduce a two-stage semi-supervised learning via pseudo-labelling learning approach to distill the knowledge from the larger networks. For ATRW-ICCV 2019 tiger detection sub-challenge, based on public leaderboard score, our approach shows superior performance in comparison to other methods.
Repeatability of Multiparametric Prostate MRI Radiomics Features
Jul 16, 2018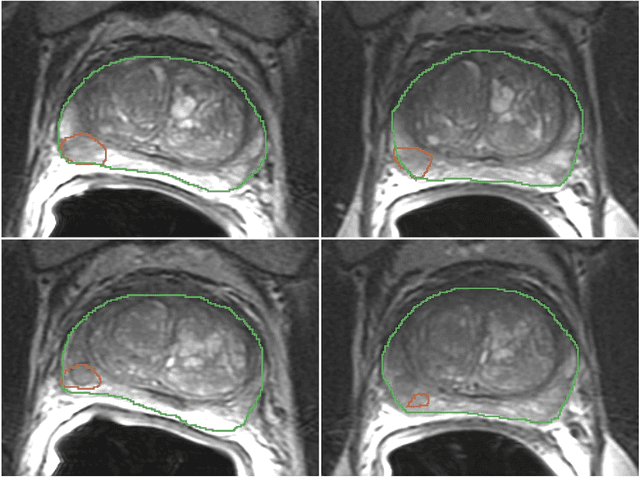
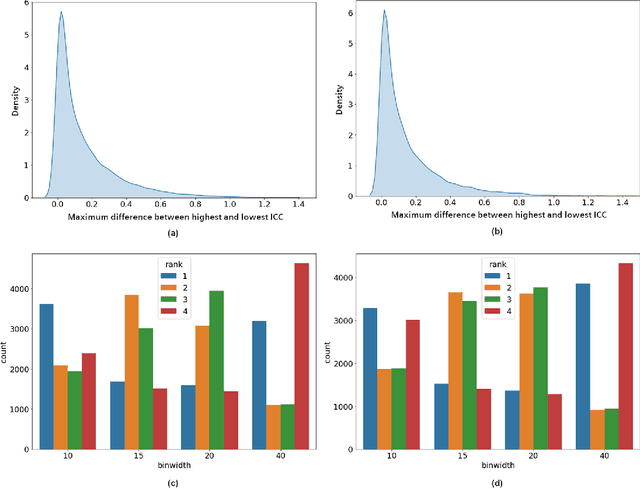
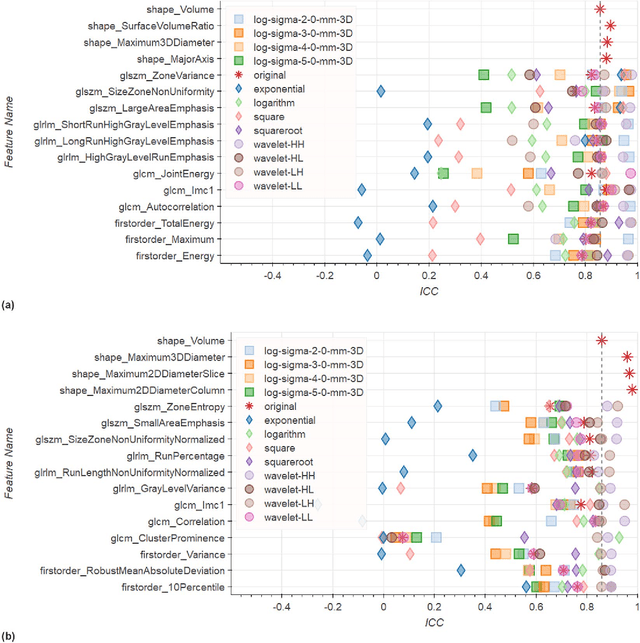
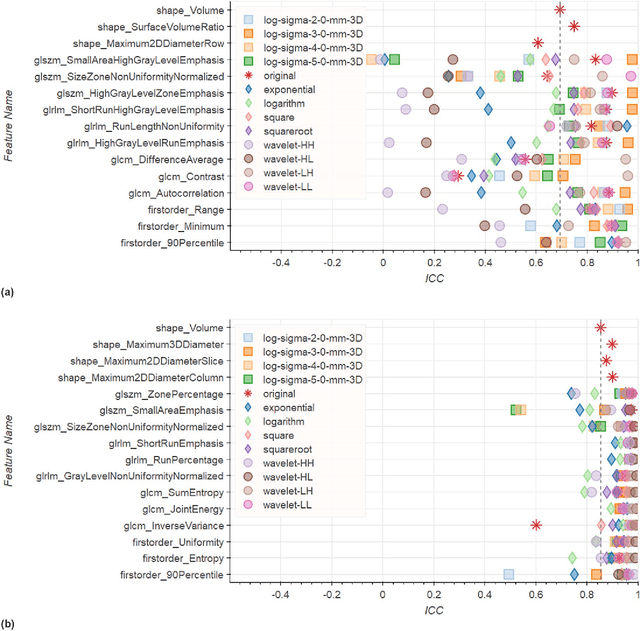
In this study we assessed the repeatability of the values of radiomics features for small prostate tumors using test-retest? Multiparametric Magnetic Resonance Imaging (mpMRI) images. The premise of radiomics is that quantitative image features can serve as biomarkers characterizing disease. For such biomarkers to be useful, repeatability is a basic requirement, meaning its value must remain stable between two scans, if the conditions remain stable. We investigated repeatability of radiomics features under various preprocessing and extraction configurations including various image normalization schemes, different image pre-filtering, 2D vs 3D texture computation, and different bin widths for image discretization. Image registration as means to re-identify regions of interest across time points was evaluated against human-expert segmented regions in both time points. Even though we found many radiomics features and preprocessing combinations with a high repeatability (Intraclass Correlation Coefficient (ICC) > 0.85), our results indicate that overall the repeatability is highly sensitive to the processing parameters (under certain configurations, it can be below 0.0). Image normalization, using a variety of approaches considered, did not result in consistent improvements in repeatability. There was also no consistent improvement of repeatability through the use of pre-filtering options, or by using image registration between timepoints to improve consistency of the region of interest localization. Based on these results we urge caution when interpreting radiomics features and advise paying close attention to the processing configuration details of reported results. Furthermore, we advocate reporting all processing details in radiomics studies and strongly recommend making the implementation available.
A Hypersensitive Breast Cancer Detector
Jan 23, 2020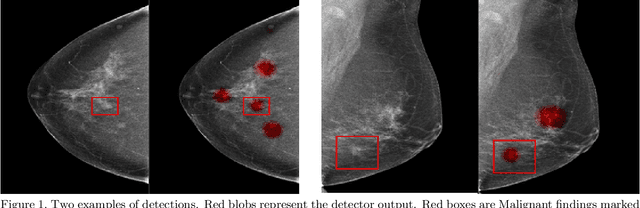
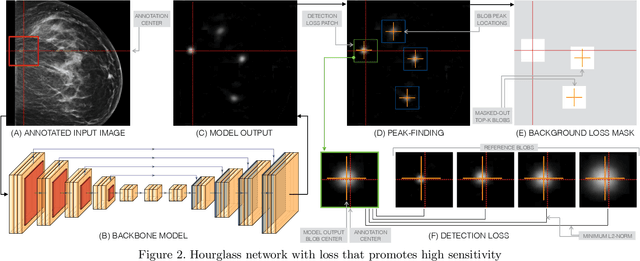
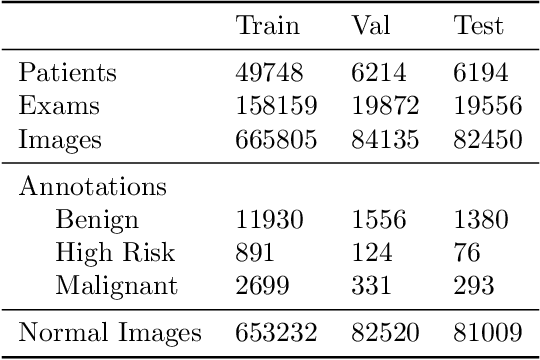
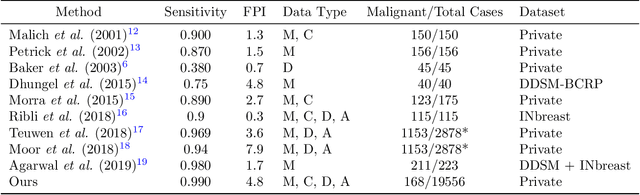
Early detection of breast cancer through screening mammography yields a 20-35% increase in survival rate; however, there are not enough radiologists to serve the growing population of women seeking screening mammography. Although commercial computer aided detection (CADe) software has been available to radiologists for decades, it has failed to improve the interpretation of full-field digital mammography (FFDM) images due to its low sensitivity over the spectrum of findings. In this work, we leverage a large set of FFDM images with loose bounding boxes of mammographically significant findings to train a deep learning detector with extreme sensitivity. Building upon work from the Hourglass architecture, we train a model that produces segmentation-like images with high spatial resolution, with the aim of producing 2D Gaussian blobs centered on ground-truth boxes. We replace the pixel-wise $L_2$ norm with a weak-supervision loss designed to achieve high sensitivity, asymmetrically penalizing false positives and false negatives while softening the noise of the loose bounding boxes by permitting a tolerance in misaligned predictions. The resulting system achieves a sensitivity for malignant findings of 0.99 with only 4.8 false positive markers per image. When utilized in a CADe system, this model could enable a novel workflow where radiologists can focus their attention with trust on only the locations proposed by the model, expediting the interpretation process and bringing attention to potential findings that could otherwise have been missed. Due to its nearly perfect sensitivity, the proposed detector can also be used as a high-performance proposal generator in two-stage detection systems.