 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cutting the Error by Half: Investigation of Very Deep CNN and Advanced Training Strategies for Document Image Classification
Apr 11, 2017


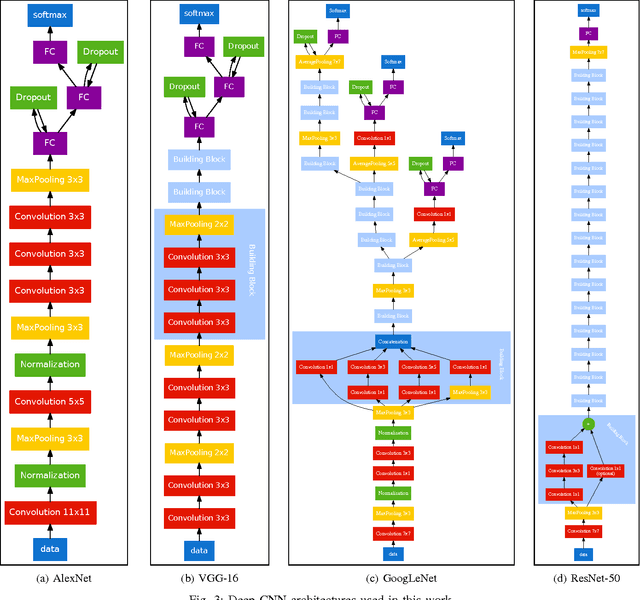
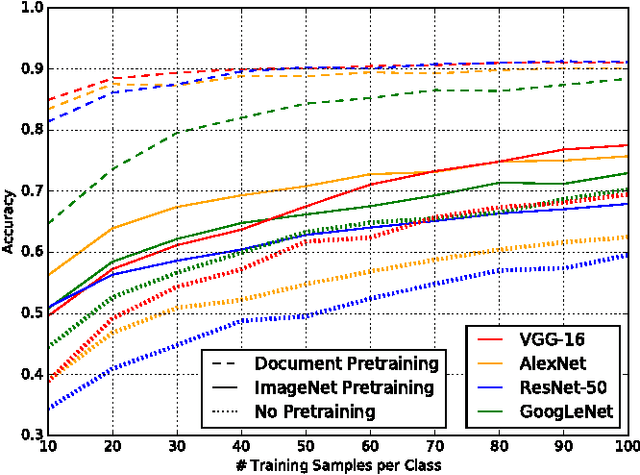
We present an exhaustive investigation of recent Deep Learning architectures, algorithms, and strategies for the task of document image classification to finally reduce the error by more than half. Existing approaches, such as the DeepDocClassifier, apply standard Convolutional Network architectures with transfer learning from the object recognition domain. The contribution of the paper is threefold: First, it investigates recently introduced very deep neural network architectures (GoogLeNet, VGG, ResNet) using transfer learning (from real images). Second, it proposes transfer learning from a huge set of document images, i.e. 400,000 documents. Third, it analyzes the impact of the amount of training data (document images) and other parameters to the classification abilities. We use two datasets, the Tobacco-3482 and the large-scale RVL-CDIP dataset. We achieve an accuracy of 91.13% for the Tobacco-3482 dataset while earlier approaches reach only 77.6%. Thus, a relative error reduction of more than 60% is achieved. For the large dataset RVL-CDIP, an accuracy of 90.97% is achieved, corresponding to a relative error reduction of 11.5%.
Learning Priors in High-frequency Domain for Inverse Imaging Reconstruction
Oct 23, 2019
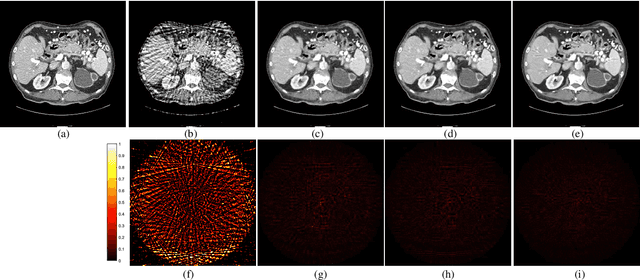
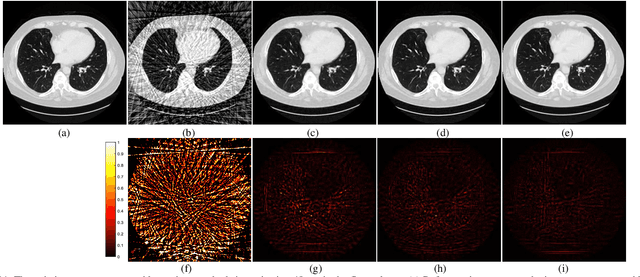
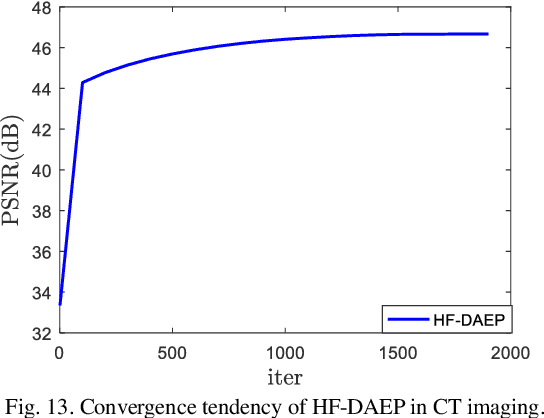
Ill-posed inverse problems in imaging remain an active research topic in several decades, with new approaches constantly emerging. Recognizing that the popular dictionary learning and convolutional sparse coding are both essentially modeling the high-frequency component of an image, which convey most of the semantic information such as texture details, in this work we propose a novel multi-profile high-frequency transform-guided denoising autoencoder as prior (HF-DAEP). To achieve this goal, we first extract a set of multi-profile high-frequency components via a specific transformation and add the artificial Gaussian noise to these high-frequency components as training samples. Then, as the high-frequency prior information is learned, we incorporate it into classical iterative reconstruction process by proximal gradient descent technique. Preliminary results on highly under-sampled magnetic resonance imaging and sparse-view computed tomography reconstruction demonstrate that the proposed method can efficiently reconstruct feature details and present advantages over state-of-the-arts.
Real-Time Referring Expression Comprehension by Single-Stage Grounding Network
Dec 09, 2018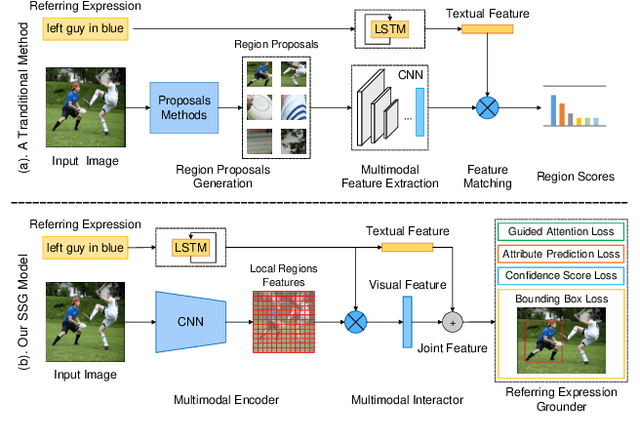
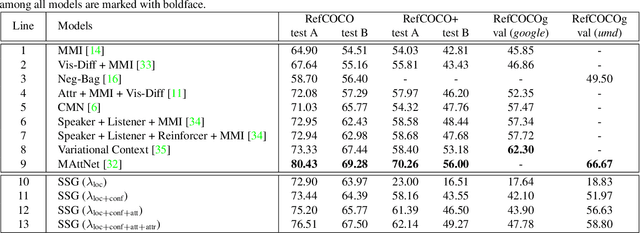
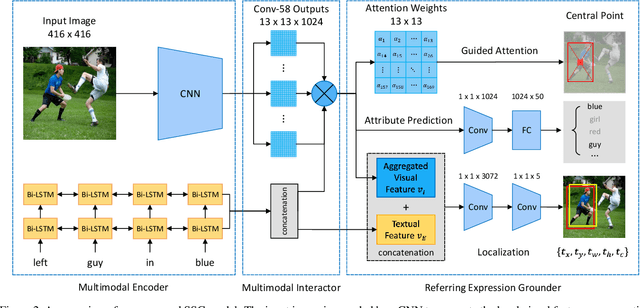
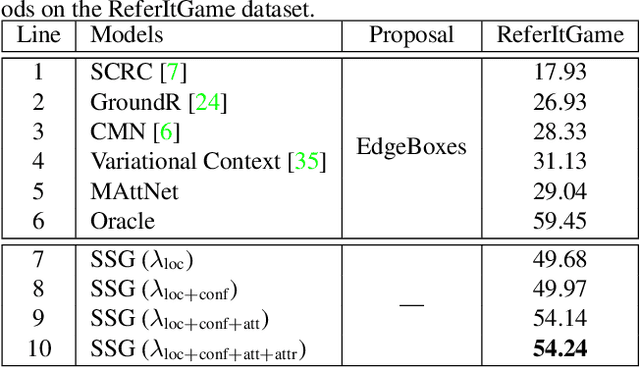
In this paper, we propose a novel end-to-end model, namely Single-Stage Grounding network (SSG), to localize the referent given a referring expression within an image. Different from previous multi-stage models which rely on object proposals or detected regions, our proposed model aims to comprehend a referring expression through one single stage without resorting to region proposals as well as the subsequent region-wise feature extraction. Specifically, a multimodal interactor is proposed to summarize the local region features regarding the referring expression attentively. Subsequently, a grounder is proposed to localize the referring expression within the given image directly. For further improving the localization accuracy, a guided attention mechanism is proposed to enforce the grounder to focus on the central region of the referent. Moreover, by exploiting and predicting visual attribute information, the grounder can further distinguish the referent objects within an image and thereby improve the model performance. Experiments on RefCOCO, RefCOCO+, and RefCOCOg datasets demonstrate that our proposed SSG without relying on any region proposals can achieve comparable performance with other advanced models. Furthermore, our SSG outperforms the previous models and achieves the state-of-art performance on the ReferItGame dataset. More importantly, our SSG is time efficient and can ground a referring expression in a 416*416 image from the RefCOCO dataset in 25ms (40 referents per second) on average with a Nvidia Tesla P40, accomplishing more than 9* speedups over the existing multi-stage models.
Data-Driven Microstructure Property Relations
Apr 01, 2019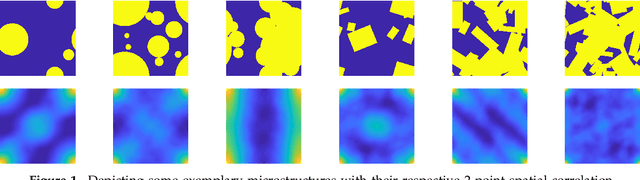
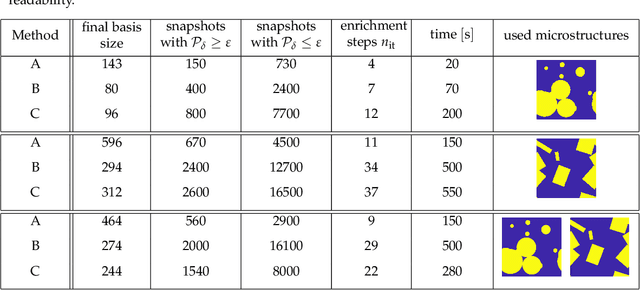
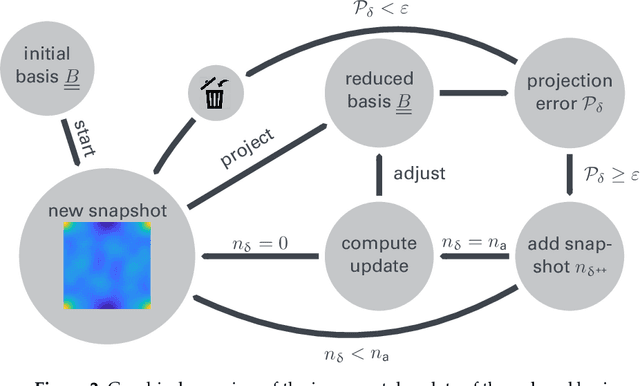
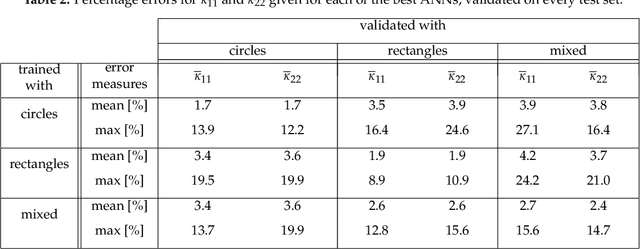
An image based prediction of the effective heat conductivity for highly heterogeneous microstructured materials is presented. The synthetic materials under consideration show different inclusion morphology, orientation, volume fraction and topology. The prediction of the effective property is made exclusively based on image data with the main emphasis being put on the 2-point spatial correlation function. This task is implemented using both unsupervised and supervised machine learning methods. First, a snapshot proper orthogonal decomposition (POD) is used to analyze big sets of random microstructures and thereafter compress significant characteristics of the microstructure into a low-dimensional feature vector. In order to manage the related amount of data and computations, three different incremental snapshot POD methods are proposed. In the second step, the obtained feature vector is used to predict the effective material property by using feed forward neural networks. Numerical examples regarding the incremental basis identification and the prediction accuracy of the approach are presented. A Python code illustrating the application of the surrogate is freely available.
Highlighting Bias with Explainable Neural-Symbolic Visual Reasoning
Sep 19, 2019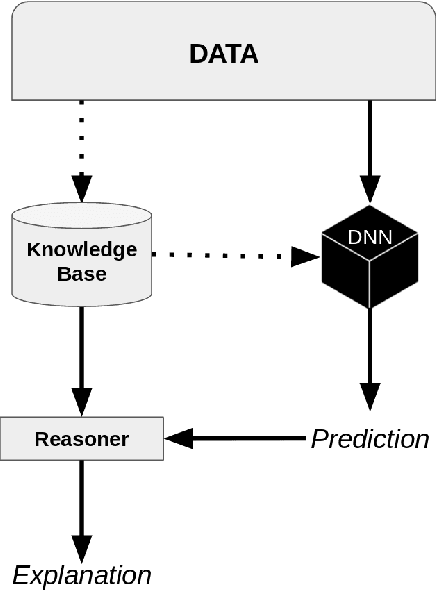

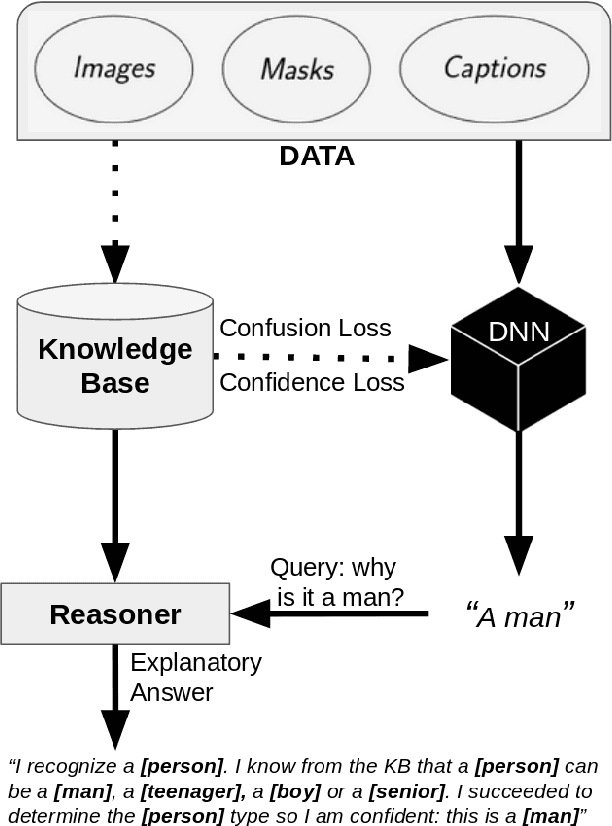
Many high-performance models suffer from a lack of interpretability. There has been an increasing influx of work on explainable artificial intelligence (XAI) in order to disentangle what is meant and expected by XAI. Nevertheless, there is no general consensus on how to produce and judge explanations. In this paper, we discuss why techniques integrating connectionist and symbolic paradigms are the most efficient solutions to produce explanations for non-technical users and we propose a reasoning model, based on definitions by Doran et al. [2017] (arXiv:1710.00794) to explain a neural network's decision. We use this explanation in order to correct bias in the network's decision rationale. We accompany this model with an example of its potential use, based on the image captioning method in Burns et al. [2018] (arXiv:1803.09797).
Neural Network Interpretation via Fine Grained Textual Summarization
Sep 06, 2018
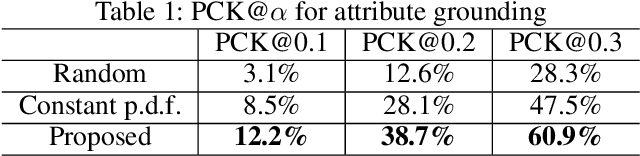
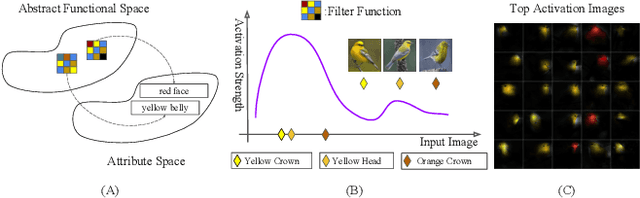

Current visualization based network interpretation methodssuffer from lacking semantic-level information. In this paper, we introduce the novel task of interpreting classification models using fine grained textual summarization. Along with the label prediction, the network will generate a sentence explaining its decision. Constructing a fully annotated dataset of filter|text pairs is unrealistic because of image to filter response function complexity. We instead propose a weakly-supervised learning algorithm leveraging off-the-shelf image caption annotations. Central to our algorithm is the filter-level attribute probability density function (p.d.f.), learned as a conditional probability through Bayesian inference with the input image and its feature map as latent variables. We show our algorithm faithfully reflects the features learned by the model using rigorous applications like attribute based image retrieval and unsupervised text grounding. We further show that the textual summarization process can help in understanding network failure patterns and can provide clues for further improvements.
Unsupervised Multi-modal Neural Machine Translation
Nov 28, 2018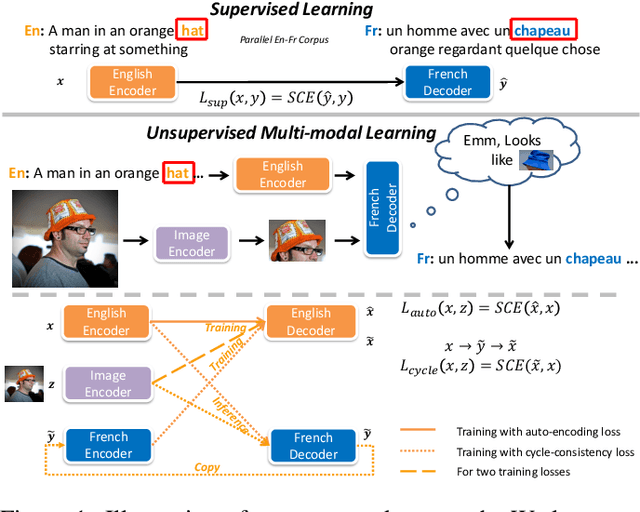
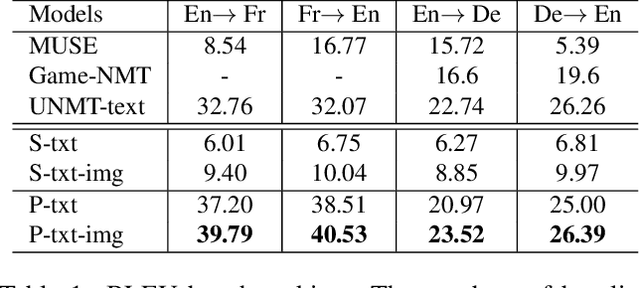
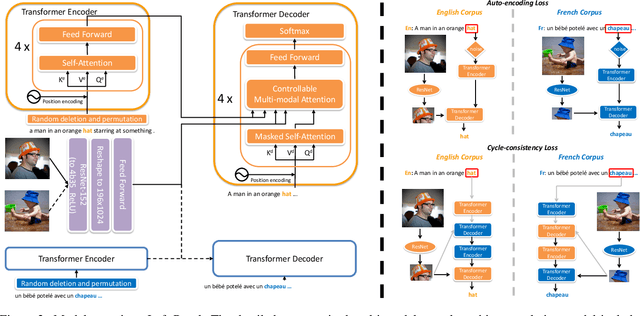

Unsupervised neural machine translation (UNMT) has recently achieved remarkable results with only large monolingual corpora in each language. However, the uncertainty of associating target with source sentences makes UNMT theoretically an ill-posed problem. This work investigates the possibility of utilizing images for disambiguation to improve the performance of UNMT. Our assumption is intuitively based on the invariant property of image, i.e., the description of the same visual content by different languages should be approximately similar. We propose an unsupervised multi-modal machine translation (UMNMT) framework based on the language translation cycle consistency loss conditional on the image, targeting to learn the bidirectional multi-modal translation simultaneously. Through an alternate training between multi-modal and uni-modal, our inference model can translate with or without the image. On the widely used Multi30K dataset, the experimental results of our approach are significantly better than those of the text-only UNMT on the 2016 test dataset.
Deep Learning for Power System Security Assessment
Mar 31, 2019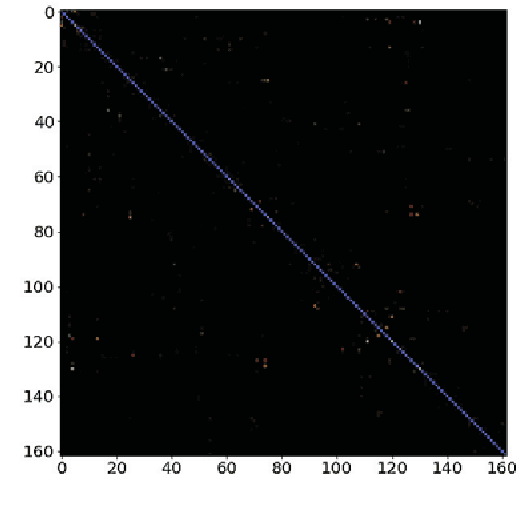
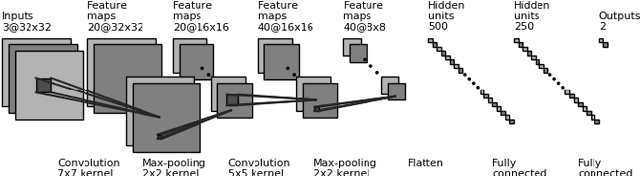
Security assessment is among the most fundamental functions of power system operator. The sheer complexity of power systems exceeding a few buses, however, makes it an extremely computationally demanding task. The emergence of deep learning methods that are able to handle immense amounts of data, and infer valuable information appears as a promising alternative. This paper has two main contributions. First, inspired by the remarkable performance of convolutional neural networks for image processing, we represent for the first time power system snapshots as 2-dimensional images, thus taking advantage of the wide range of deep learning methods available for image processing. Second, we train deep neural networks on a large database for the NESTA 162-bus system to assess both N-1 security and small-signal stability. We find that our approach is over 255 times faster than a standard small-signal stability assessment, and it can correctly determine unsafe points with over 99% accuracy.
Learning to Synthesize Motion Blur
Nov 27, 2018
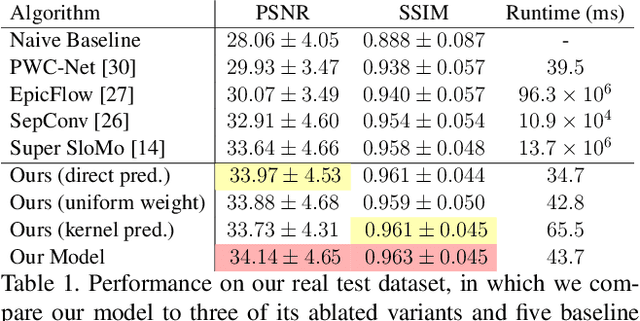


We present a technique for synthesizing a motion blurred image from a pair of unblurred images captured in succession. To build this system we motivate and design a differentiable "line prediction" layer to be used as part of a neural network architecture, with which we can learn a system to regress from image pairs to motion blurred images that span the capture time of the input image pair. Training this model requires an abundance of data, and so we design and execute a strategy for using frame interpolation techniques to generate a large-scale synthetic dataset of motion blurred images and their respective inputs. We additionally capture a high quality test set of real motion blurred images, synthesized from slow motion videos, with which we evaluate our model against several baseline techniques that can be used to synthesize motion blur. Our model produces higher accuracy output than our baselines, and is several orders of magnitude faster than those baselines with competitive accuracy.
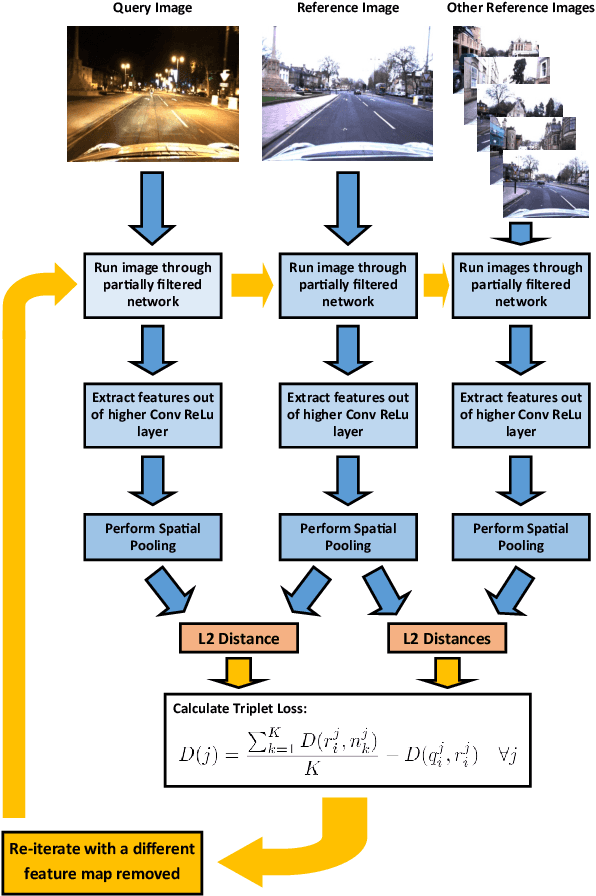
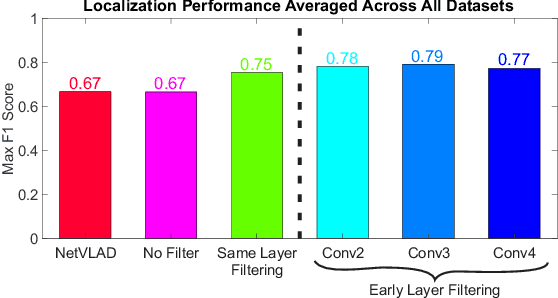
Filter Early, Match Late: Improving Network-Based Visual Place Recognition
Jun 21, 2019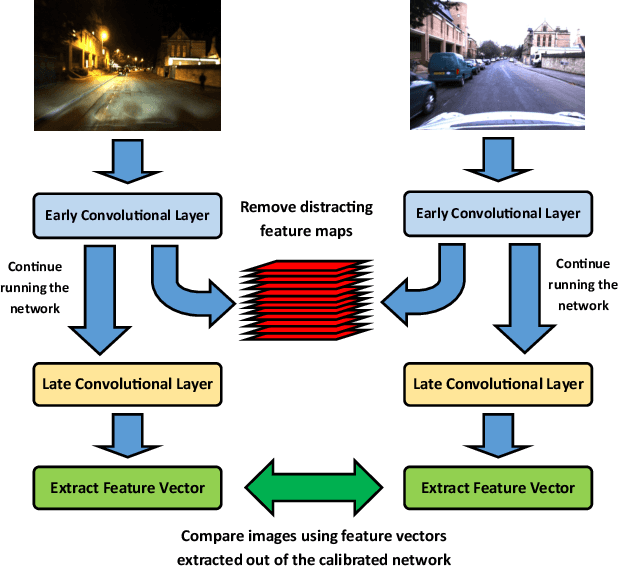

CNNs have excelled at performing place recognition over time, particularly when the neural network is optimized for localization in the current environmental conditions. In this paper we investigate the concept of feature map filtering, where, rather than using all the activations within a convolutional tensor, only the most useful activations are used. Since specific feature maps encode different visual features, the objective is to remove feature maps that are detract from the ability to recognize a location across appearance changes. Our key innovation is to filter the feature maps in an early convolutional layer, but then continue to run the network and extract a feature vector using a later layer in the same network. By filtering early visual features and extracting a feature vector from a higher, more viewpoint invariant later layer, we demonstrate improved condition and viewpoint invariance. Our approach requires image pairs for training from the deployment environment, but we show that state-of-the-art performance can regularly be achieved with as little as a single training image pair. An exhaustive experimental analysis is performed to determine the full scope of causality between early layer filtering and late layer extraction. For validity, we use three datasets: Oxford RobotCar, Nordland, and Gardens Point, achieving overall superior performance to NetVLAD. The work provides a number of new avenues for exploring CNN optimizations, without full re-training.