 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Liver segmentation and metastases detection in MR images using convolutional neural networks
Oct 15, 2019

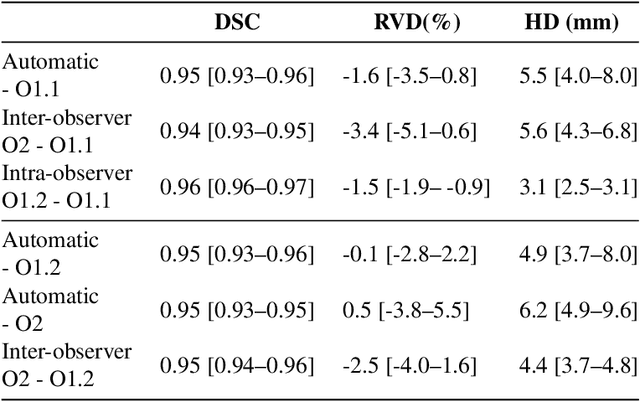
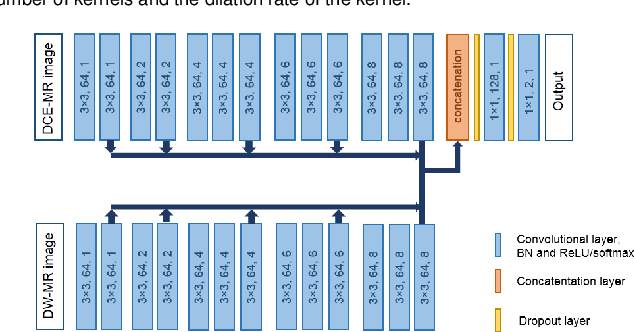
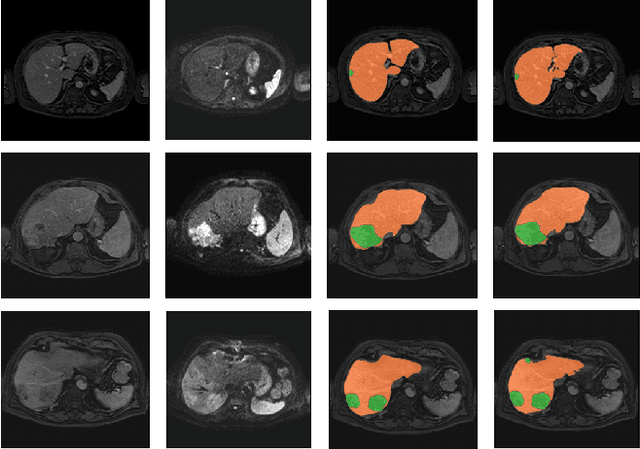
Primary tumors have a high likelihood of developing metastases in the liver and early detection of these metastases is crucial for patient outcome. We propose a method based on convolutional neural networks (CNN) to detect liver metastases. First, the liver was automatically segmented using the six phases of abdominal dynamic contrast enhanced (DCE) MR images. Next, DCE-MR and diffusion weighted (DW) MR images are used for metastases detection within the liver mask. The liver segmentations have a median Dice similarity coefficient of 0.95 compared with manual annotations. The metastases detection method has a sensitivity of 99.8% with a median of 2 false positives per image. The combination of the two MR sequences in a dual pathway network is proven valuable for the detection of liver metastases. In conclusion, a high quality liver segmentation can be obtained in which we can successfully detect liver metastases.
Automatic Discovery of Political Meme Genres with Diverse Appearances
Jan 17, 2020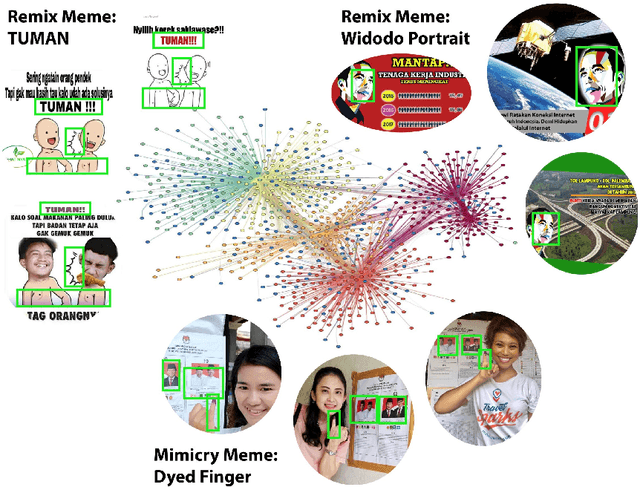
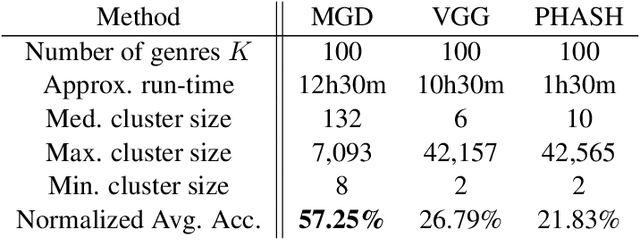
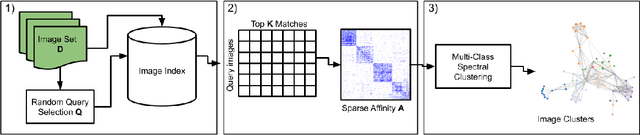

Forms of human communication are not static --- we expect some evolution in the way information is conveyed over time because of advances in technology. One example of this phenomenon is the image-based meme, which has emerged as a dominant form of political messaging in the past decade. While originally used to spread jokes on social media, memes are now having an outsized impact on public perception of world events. A significant challenge in automatic meme analysis has been the development of a strategy to match memes from within a single genre when the appearances of the images vary. Such variation is especially common in memes exhibiting mimicry. For example, when voters perform a common hand gesture to signal their support for a candidate. In this paper we introduce a scalable automated visual recognition pipeline for discovering political meme genres of diverse appearance. This pipeline can ingest meme images from a social network, apply computer vision-based techniques to extract local features and index new images into a database, and then organize the memes into related genres. To validate this approach, we perform a large case study on the 2019 Indonesian Presidential Election using a new dataset of over two million images collected from Twitter and Instagram. Results show that this approach can discover new meme genres with visually diverse images that share common stylistic elements, paving the way forward for further work in semantic analysis and content attribution.
Bounded Manifold Completion
Dec 19, 2019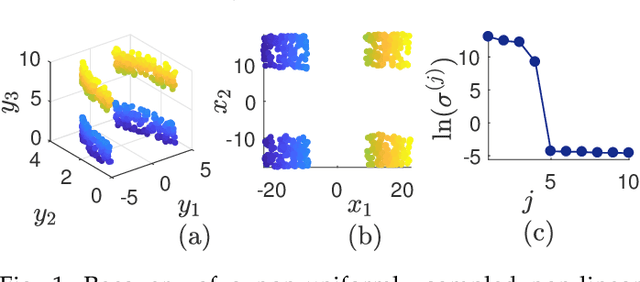

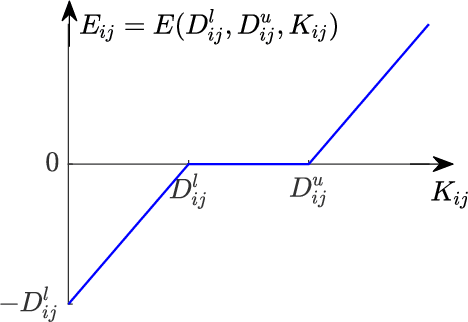
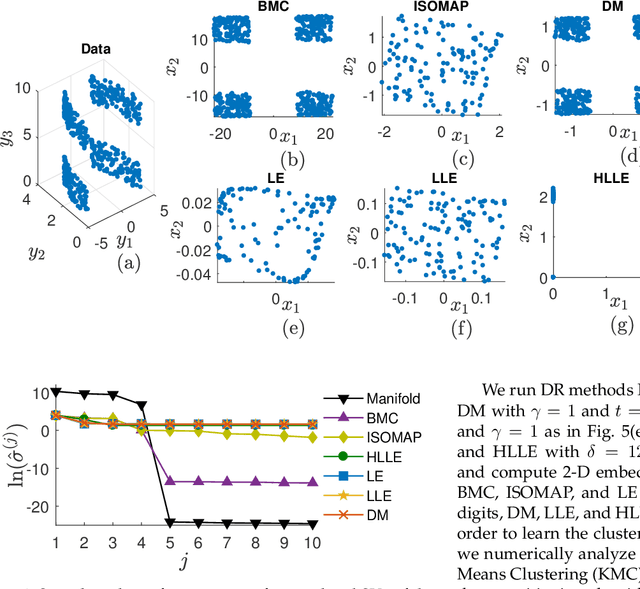
Nonlinear dimensionality reduction or, equivalently, the approximation of high-dimensional data using a low-dimensional nonlinear manifold is an active area of research. In this paper, we will present a thematically different approach to detect the existence of a low-dimensional manifold of a given dimension that lies within a set of bounds derived from a given point cloud. A matrix representing the appropriately defined distances on a low-dimensional manifold is low-rank, and our method is based on current techniques for recovering a partially observed matrix from a small set of fully observed entries that can be implemented as a low-rank Matrix Completion (MC) problem. MC methods are currently used to solve challenging real-world problems, such as image inpainting and recommender systems, and we leverage extent efficient optimization techniques that use a nuclear norm convex relaxation as a surrogate for non-convex and discontinuous rank minimization. Our proposed method provides several advantages over current nonlinear dimensionality reduction techniques, with the two most important being theoretical guarantees on the detection of low-dimensional embeddings and robustness to non-uniformity in the sampling of the manifold. We validate the performance of this approach using both a theoretical analysis as well as synthetic and real-world benchmark datasets.
Multiple Linear Regression Haze-removal Model Based on Dark Channel Prior
Apr 25, 2019



Dark Channel Prior (DCP) is a widely recognized traditional dehazing algorithm. However, it may fail in bright region and the brightness of the restored image is darker than hazy image. In this paper, we propose an effective method to optimize DCP. We build a multiple linear regression haze-removal model based on DCP atmospheric scattering model and train this model with RESIDE dataset, which aims to reduce the unexpected errors caused by the rough estimations of transmission map t(x) and atmospheric light A. The RESIDE dataset provides enough synthetic hazy images and their corresponding groundtruth images to train and test. We compare the performances of different dehazing algorithms in terms of two important full-reference metrics, the peak-signal-to-noise ratio (PSNR) as well as the structural similarity index measure (SSIM). The experiment results show that our model gets highest SSIM value and its PSNR value is also higher than most of state-of-the-art dehazing algorithms. Our results also overcome the weakness of DCP on real-world hazy images
Making Convolutional Networks Shift-Invariant Again
Apr 25, 2019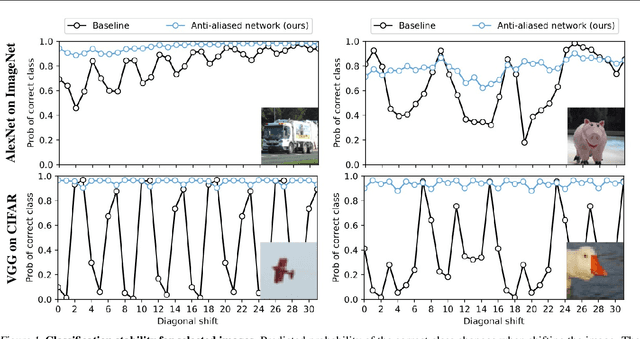
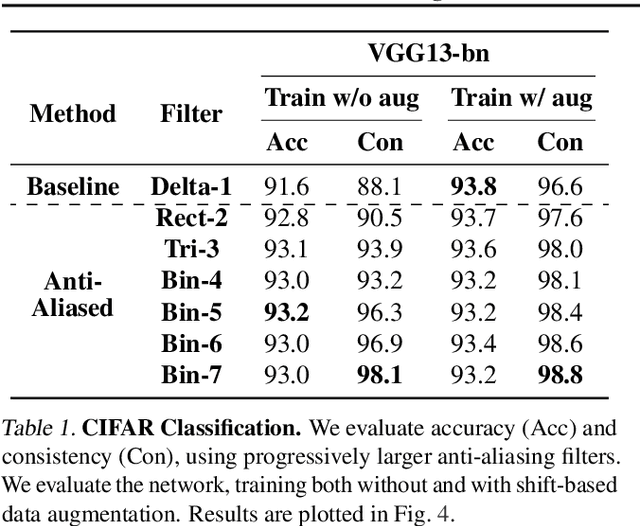
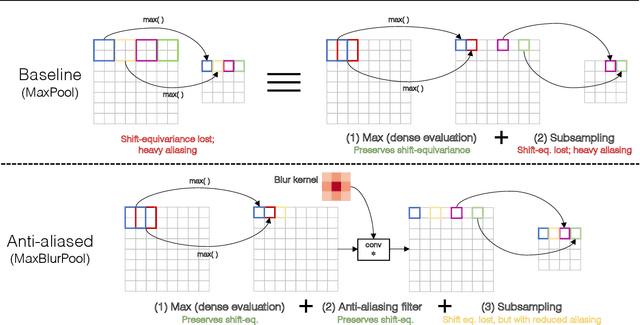
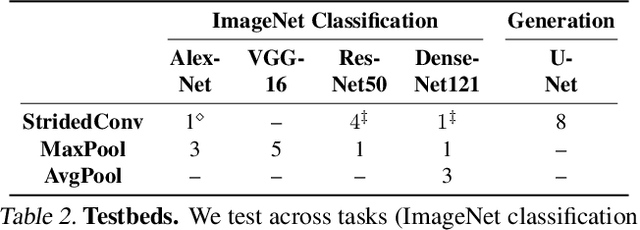
Modern convolutional networks are not shift-invariant, as small input shifts or translations can cause drastic changes in the output. Commonly used downsampling methods, such as max-pooling, strided-convolution, and average-pooling, ignore the sampling theorem. The well-known signal processing fix is anti-aliasing by low-pass filtering before downsampling. However, simply inserting this module into deep networks leads to performance degradation; as a result, it is seldomly used today. We show that when integrated correctly, it is compatible with existing architectural components, such as max-pooling. The technique is general and can be incorporated across layer types and applications, such as image classification and conditional image generation. In addition to increased shift-invariance, we also observe, surprisingly, that anti-aliasing boosts accuracy in ImageNet classification, across several commonly-used architectures. This indicates that anti-aliasing serves as effective regularization. Our results demonstrate that this classical signal processing technique has been undeservingly overlooked in modern deep networks. Code and anti-aliased versions of popular networks will be made available at \url{https://richzhang.github.io/antialiased-cnns/} .
Convolutional Neural Network on Semi-Regular Triangulated Meshes and its Application to Brain Image Data
Apr 15, 2019
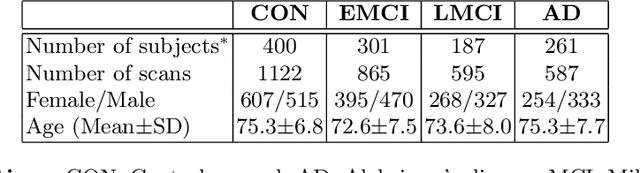
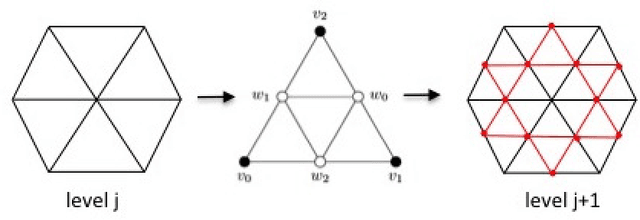
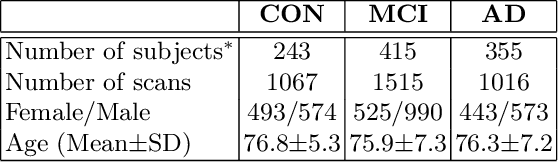
We developed a convolution neural network (CNN) on semi-regular triangulated meshes whose vertices have 6 neighbours. The key blocks of the proposed CNN, including convolution and down-sampling, are directly defined in a vertex domain. By exploiting the ordering property of semi-regular meshes, the convolution is defined on a vertex domain with strong motivation from the spatial definition of classic convolution. Moreover, the down-sampling of a semi-regular mesh embedded in a 3D Euclidean space can achieve a down-sampling rate of 4, 16, 64, etc. We demonstrated the use of this vertex-based graph CNN for the classification of mild cognitive impairment (MCI) and Alzheimer's disease (AD) based on 3169 MRI scans of the Alzheimer's Disease Neuroimaging Initiative (ADNI). We compared the performance of the vertex-based graph CNN with that of the spectral graph CNN.
LPRNet: Lightweight Deep Network by Low-rank Pointwise Residual Convolution
Oct 25, 2019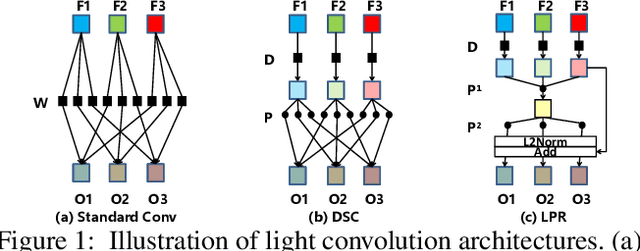

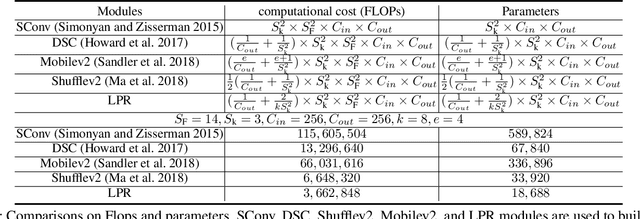
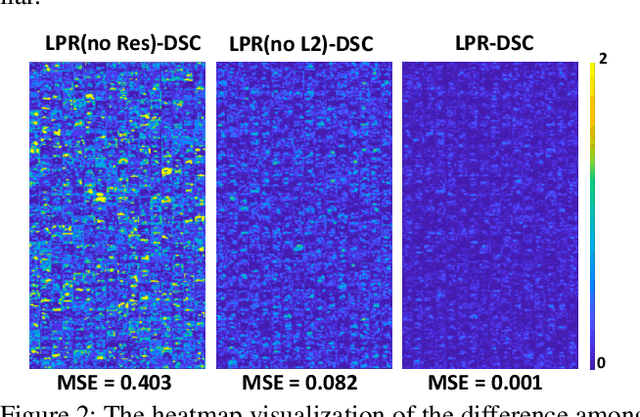
Deep learning has become popular in recent years primarily due to the powerful computing device such as GPUs. However, deploying these deep models to end-user devices, smart phones, or embedded systems with limited resources is challenging. To reduce the computation and memory costs, we propose a novel lightweight deep learning module by low-rank pointwise residual (LPR) convolution, called LPRNet. Essentially, LPR aims at using low-rank approximation in pointwise convolution to further reduce the module size, while keeping depthwise convolutions as the residual module to rectify the LPR module. This is critical when the low-rankness undermines the convolution process. We embody our design by replacing modules of identical input-output dimension in MobileNet and ShuffleNetv2. Experiments on visual recognition tasks including image classification and face alignment on popular benchmarks show that our LPRNet achieves competitive performance but with significant reduction of Flops and memory cost compared to the state-of-the-art deep models focusing on model compression.
Activity Driven Weakly Supervised Object Detection
Apr 02, 2019
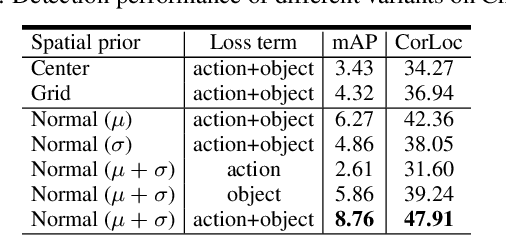
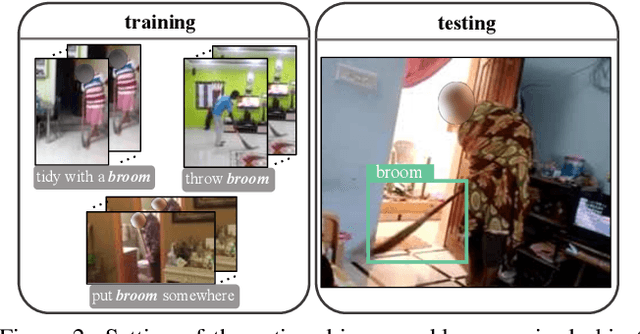
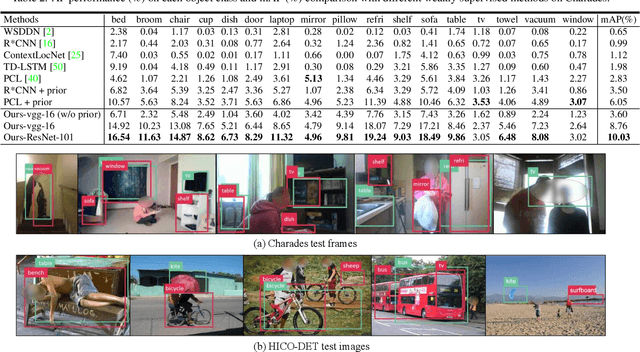
Weakly supervised object detection aims at reducing the amount of supervision required to train detection models. Such models are traditionally learned from images/videos labelled only with the object class and not the object bounding box. In our work, we try to leverage not only the object class labels but also the action labels associated with the data. We show that the action depicted in the image/video can provide strong cues about the location of the associated object. We learn a spatial prior for the object dependent on the action (e.g. "ball" is closer to "leg of the person" in "kicking ball"), and incorporate this prior to simultaneously train a joint object detection and action classification model. We conducted experiments on both video datasets and image datasets to evaluate the performance of our weakly supervised object detection model. Our approach outperformed the current state-of-the-art (SOTA) method by more than 6% in mAP on the Charades video dataset.
Hierarchical LSTMs with Adaptive Attention for Visual Captioning
Dec 26, 2018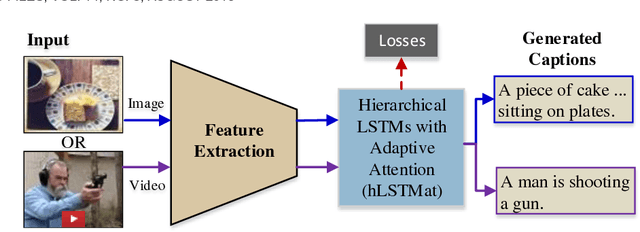

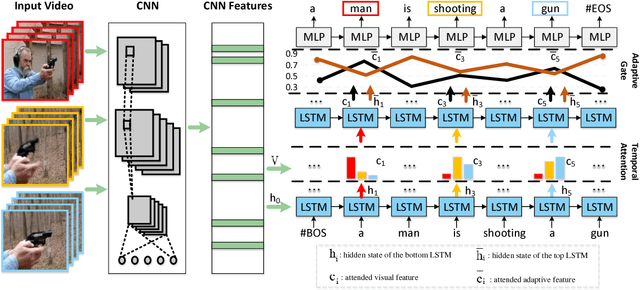
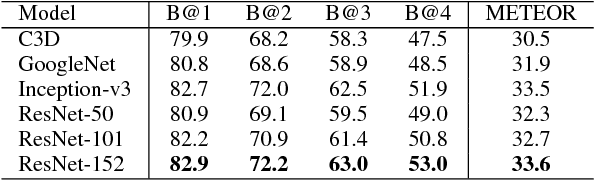
Recent progress has been made in using attention based encoder-decoder framework for image and video captioning. Most existing decoders apply the attention mechanism to every generated word including both visual words (e.g., "gun" and "shooting") and non-visual words (e.g. "the", "a"). However, these non-visual words can be easily predicted using natural language model without considering visual signals or attention. Imposing attention mechanism on non-visual words could mislead and decrease the overall performance of visual captioning. Furthermore, the hierarchy of LSTMs enables more complex representation of visual data, capturing information at different scales. To address these issues, we propose a hierarchical LSTM with adaptive attention (hLSTMat) approach for image and video captioning. Specifically, the proposed framework utilizes the spatial or temporal attention for selecting specific regions or frames to predict the related words, while the adaptive attention is for deciding whether to depend on the visual information or the language context information. Also, a hierarchical LSTMs is designed to simultaneously consider both low-level visual information and high-level language context information to support the caption generation. We initially design our hLSTMat for video captioning task. Then, we further refine it and apply it to image captioning task. To demonstrate the effectiveness of our proposed framework, we test our method on both video and image captioning tasks. Experimental results show that our approach achieves the state-of-the-art performance for most of the evaluation metrics on both tasks. The effect of important components is also well exploited in the ablation study.
Image Processing based Systems and Techniques for the Recognition of Ancient and Modern Coins
Dec 23, 2013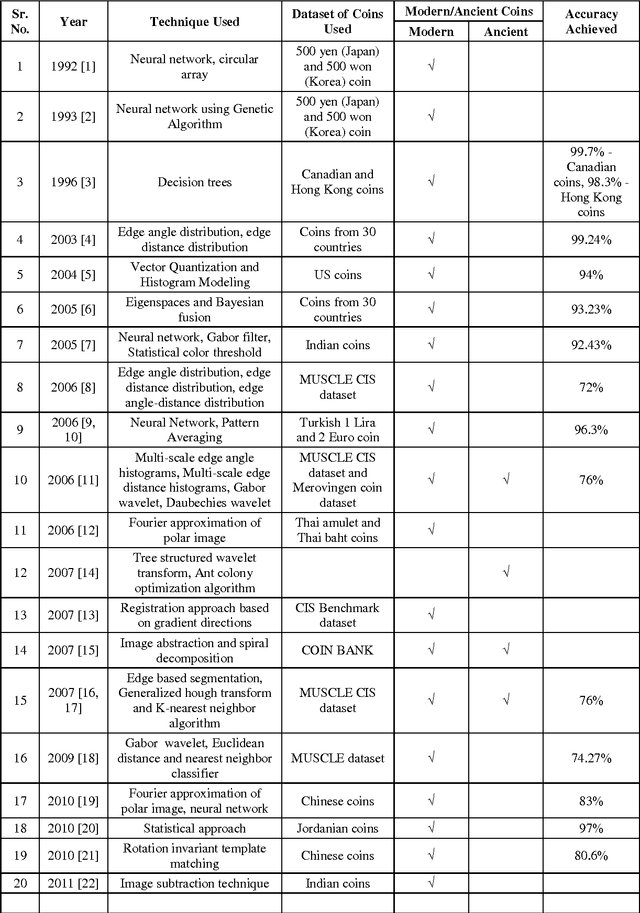
Coins are frequently used in everyday life at various places like in banks, grocery stores, supermarkets, automated weighing machines, vending machines etc. So, there is a basic need to automate the counting and sorting of coins. For this machines need to recognize the coins very fast and accurately, as further transaction processing depends on this recognition. Three types of systems are available in the market: Mechanical method based systems, Electromagnetic method based systems and Image processing based systems. This paper presents an overview of available systems and techniques based on image processing to recognize ancient and modern coins.
* 5 pages, 1 table, Published with International Journal of Computer Applications (IJCA)