 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Night Time Haze and Glow Removal using Deep Dilated Convolutional Network
Feb 03, 2019
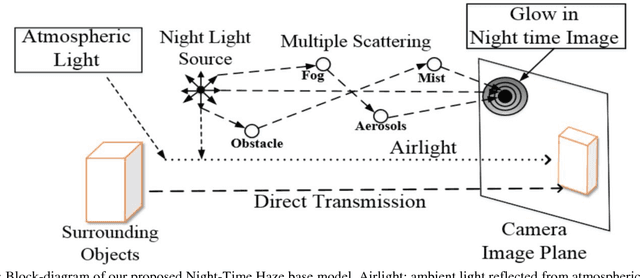
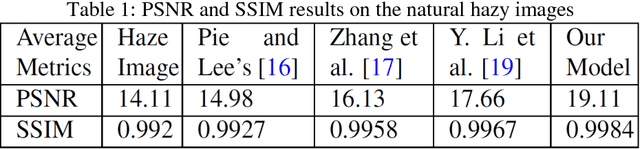
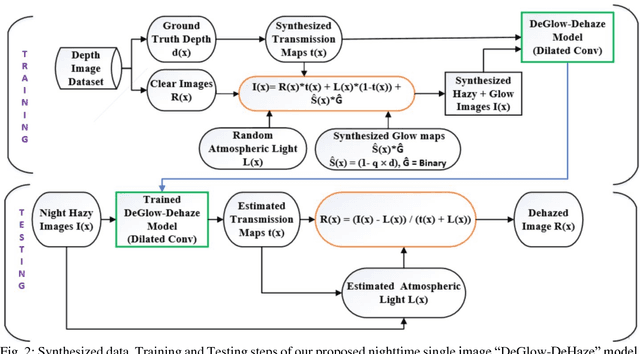
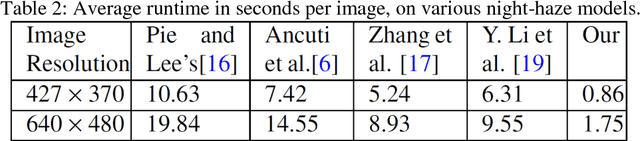
In this paper, we address the single image haze removal problem in a nighttime scene. The night haze removal is a severely ill-posed problem especially due to the presence of various visible light sources with varying colors and non-uniform illumination. These light sources are of different shapes and introduce noticeable glow in night scenes. To address these effects we introduce a deep learning based DeGlow-DeHaze iterative architecture which accounts for varying color illumination and glows. First, our convolution neural network (CNN) based DeGlow model is able to remove the glow effect significantly and on top of it a separate DeHaze network is included to remove the haze effect. For our recurrent network training, the hazy images and the corresponding transmission maps are synthesized from the NYU depth datasets and consequently restored a high-quality haze-free image. The experimental results demonstrate that our hybrid CNN model outperforms other state-of-the-art methods in terms of computation speed and image quality. We also show the effectiveness of our model on a number of real images and compare our results with the existing night haze heuristic models.
DeepDistance: A Multi-task Deep Regression Model for Cell Detection in Inverted Microscopy Images
Aug 29, 2019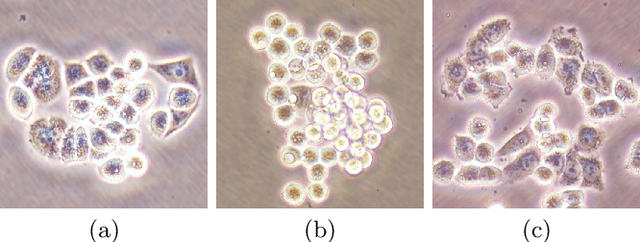
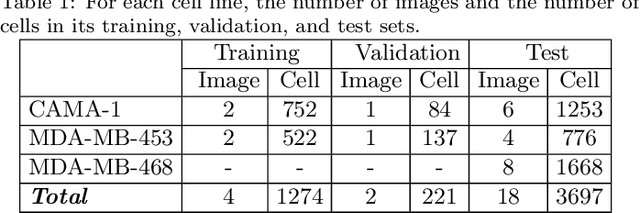

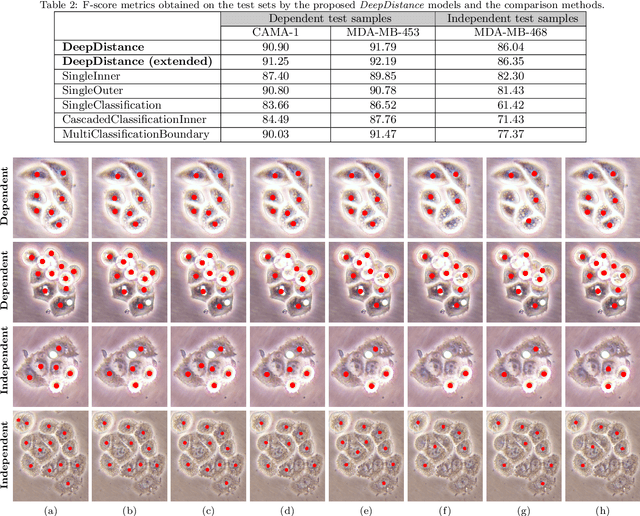
This paper presents a new deep regression model, which we call DeepDistance, for cell detection in images acquired with inverted microscopy. This model considers cell detection as a task of finding most probable locations that suggest cell centers in an image. It represents this main task with a regression task of learning an inner distance metric. However, different than the previously reported regression based methods, the DeepDistance model proposes to approach its learning as a multi-task regression problem where multiple tasks are learned by using shared feature representations. To this end, it defines a secondary metric, normalized outer distance, to represent a different aspect of the problem and proposes to define its learning as complementary to the main cell detection task. In order to learn these two complementary tasks more effectively, the DeepDistance model designs a fully convolutional network (FCN) with a shared encoder path and end-to-end trains this FCN to concurrently learn the tasks in parallel. DeepDistance uses the inner distances estimated by this FCN in a detection algorithm to locate individual cells in a given image. For further performance improvement on the main task, this paper also presents an extended version of the DeepDistance model. This extended model includes an auxiliary classification task and learns it in parallel to the two regression tasks by sharing feature representations with them. Our experiments on three different human cell lines reveal that the proposed multi-task learning models, the DeepDistance model and its extended version, successfully identify cell locations, even for the cell line that was not used in training, and improve the results of the previous deep learning methods.
Generative-based Airway and Vessel Morphology Quantification on Chest CT Images
Feb 13, 2020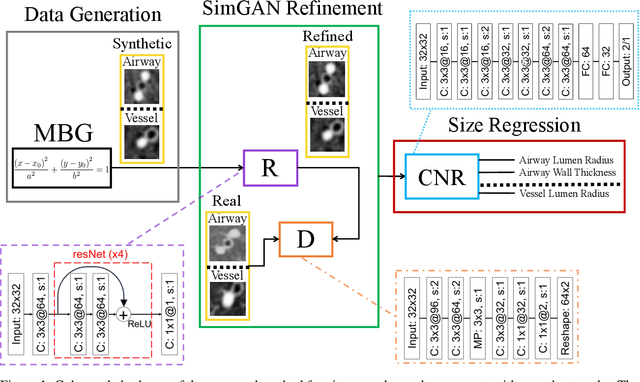

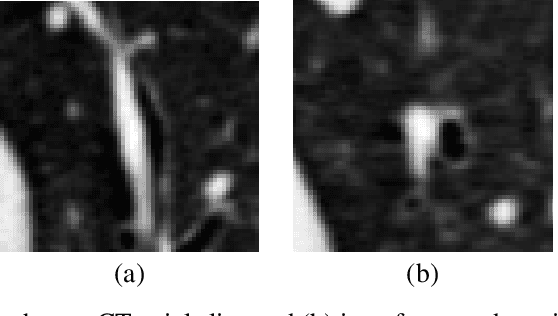
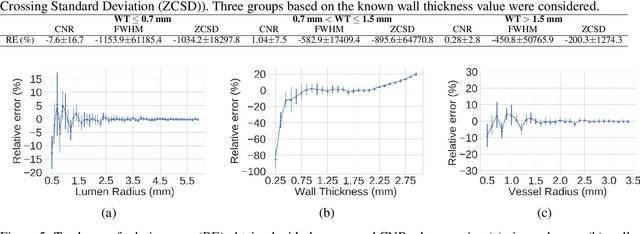
Accurately and precisely characterizing the morphology of small pulmonary structures from Computed Tomography (CT) images, such as airways and vessels, is becoming of great importance for diagnosis of pulmonary diseases. The smaller conducting airways are the major site of increased airflow resistance in chronic obstructive pulmonary disease (COPD), while accurately sizing vessels can help identify arterial and venous changes in lung regions that may determine future disorders. However, traditional methods are often limited due to image resolution and artifacts. We propose a Convolutional Neural Regressor (CNR) that provides cross-sectional measurement of airway lumen, airway wall thickness, and vessel radius. CNR is trained with data created by a generative model of synthetic structures which is used in combination with Simulated and Unsupervised Generative Adversarial Network (SimGAN) to create simulated and refined airways and vessels with known ground-truth. For validation, we first use synthetically generated airways and vessels produced by the proposed generative model to compute the relative error and directly evaluate the accuracy of CNR in comparison with traditional methods. Then, in-vivo validation is performed by analyzing the association between the percentage of the predicted forced expiratory volume in one second (FEV1\%) and the value of the Pi10 parameter, two well-known measures of lung function and airway disease, for airways. For vessels, we assess the correlation between our estimate of the small-vessel blood volume and the lungs' diffusing capacity for carbon monoxide (DLCO). The results demonstrate that Convolutional Neural Networks (CNNs) provide a promising direction for accurately measuring vessels and airways on chest CT images with physiological correlates.
Max-Sliced Wasserstein Distance and its use for GANs
Apr 11, 2019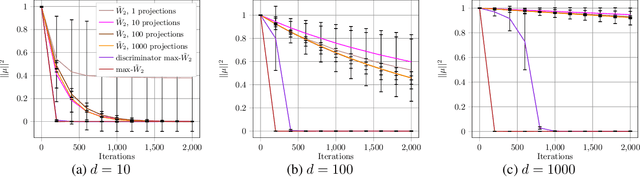

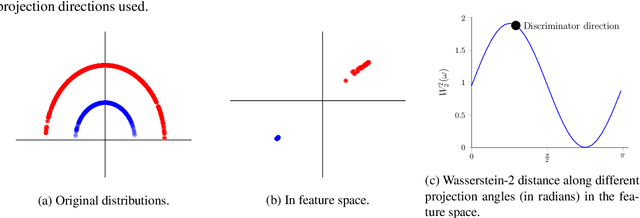

Generative adversarial nets (GANs) and variational auto-encoders have significantly improved our distribution modeling capabilities, showing promise for dataset augmentation, image-to-image translation and feature learning. However, to model high-dimensional distributions, sequential training and stacked architectures are common, increasing the number of tunable hyper-parameters as well as the training time. Nonetheless, the sample complexity of the distance metrics remains one of the factors affecting GAN training. We first show that the recently proposed sliced Wasserstein distance has compelling sample complexity properties when compared to the Wasserstein distance. To further improve the sliced Wasserstein distance we then analyze its `projection complexity' and develop the max-sliced Wasserstein distance which enjoys compelling sample complexity while reducing projection complexity, albeit necessitating a max estimation. We finally illustrate that the proposed distance trains GANs on high-dimensional images up to a resolution of 256x256 easily.
QANet - Quality Assurance Network for Microscopy Cell Segmentation
Apr 23, 2019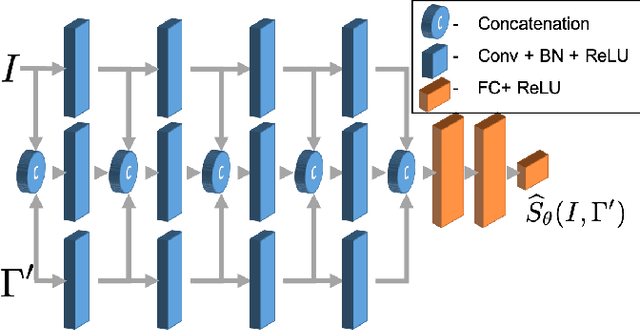
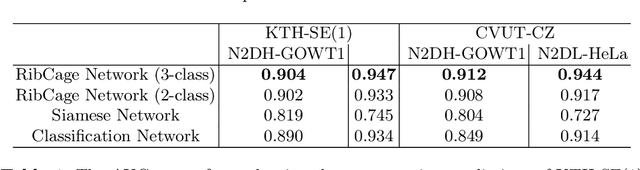
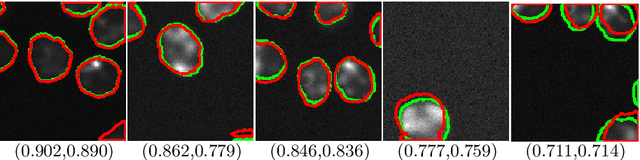

Tools and methods for automatic image segmentation are rapidly developing, each with its own strengths and weaknesses. While these methods are designed to be as general as possible, there are no guarantees for their performance on new data. The choice between methods is usually based on benchmark performance whereas the data in the benchmark can be significantly different than that of the user. We introduce a novel Deep Learning method which, given an image and a proposed corresponding segmentation, estimates the Intersection over Union measure (IoU) with respect to the unknown ground truth. We refer to this method as a Quality Assurance Network - QANet. The QANet is designed to give the user an estimate of the segmentation quality on the users own, private, data without the need for human inspection or labelling. It is based on the RibCage Network architecture, originally proposed as a discriminator in an adversarial network framework. Promising IoU prediction results are demonstrated based on the Cell Segmentation Benchmark.
Centroid-Based Scene Classification (CBSC): Using Deep Features and Clustering for RGB-D Indoor Scene Classification
Nov 01, 2019
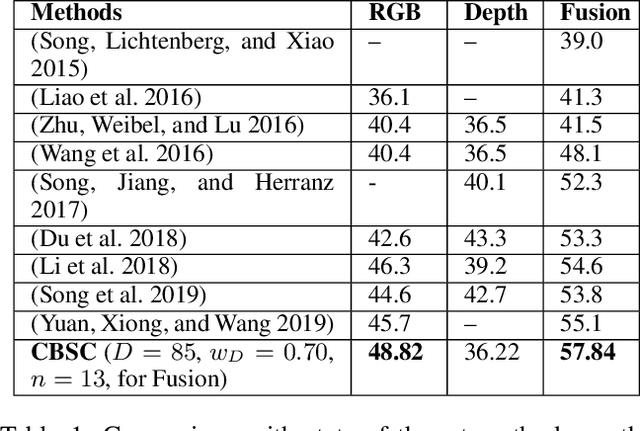
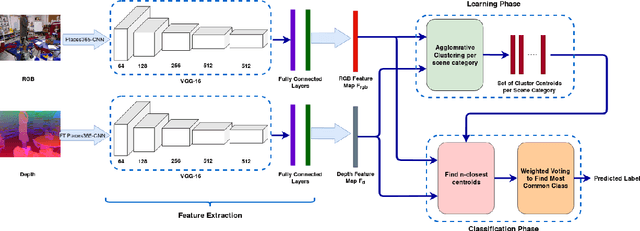

This paper contributes a novel method for RGB-D indoor scene classification. Recent approaches to this problem focus on developing increasingly complex pipelines that learn correlated features across the RGB and depth modalities. In contrast, this paper presents a simple method that first extracts features for the RGB and depth modalities using Places365-CNN and fine-tuned Places365-CNN on depth data, respectively and then clusters these features to generate a set of centroids representing each scene category from the training data. For classification a scene image is converted to CNN features and the distance of these features to the n closest learned centroids is used to predict the image's category. We evaluate our method on two standard RGB-D indoor scene classification benchmarks: SUNRGB-D and NYU Depth V2 and demonstrate that our proposed classification approach achieves superior performance over the state-of-the-art methods on both datasets.
ResNetX: a more disordered and deeper network architecture
Dec 18, 2019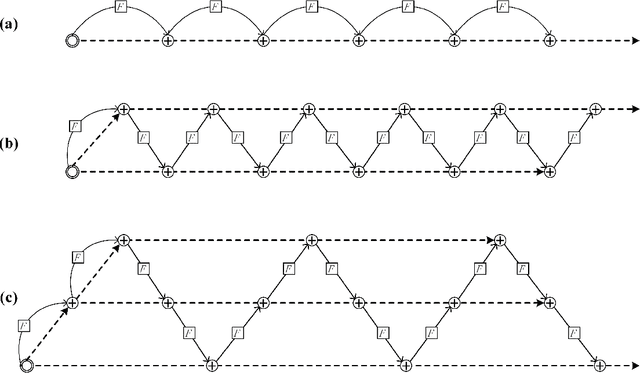
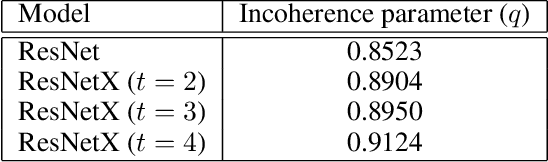
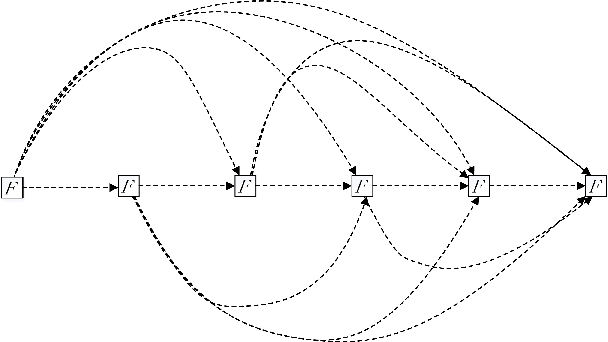
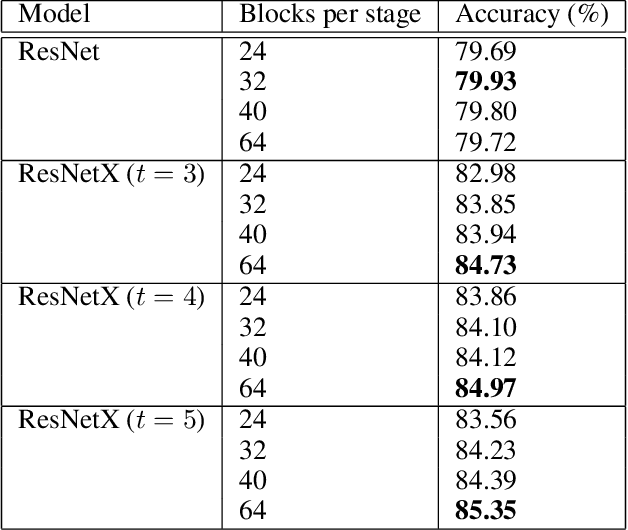
Designing efficient network structures has always been the core content of neural network research. ResNet and its variants have proved to be efficient in architecture. However, how to theoretically character the influence of network structure on performance is still vague. With the help of techniques in complex networks, We here provide a natural yet efficient extension to ResNet by folding its backbone chain. Our architecture has two structural features when being mapped to directed acyclic graphs: First is a higher degree of the disorder compared with ResNet, which let ResNetX explore a larger number of feature maps with different sizes of receptive fields. Second is a larger proportion of shorter paths compared to ResNet, which improves the direct flow of information through the entire network. Our architecture exposes a new dimension, namely "fold depth", in addition to existing dimensions of depth, width, and cardinality. Our architecture is a natural extension to ResNet, and can be integrated with existing state-of-the-art methods with little effort. Image classification results on CIFAR-10 and CIFAR-100 benchmarks suggested that our new network architecture performs better than ResNet.
Model Extraction Attacks against Recurrent Neural Networks
Feb 01, 2020
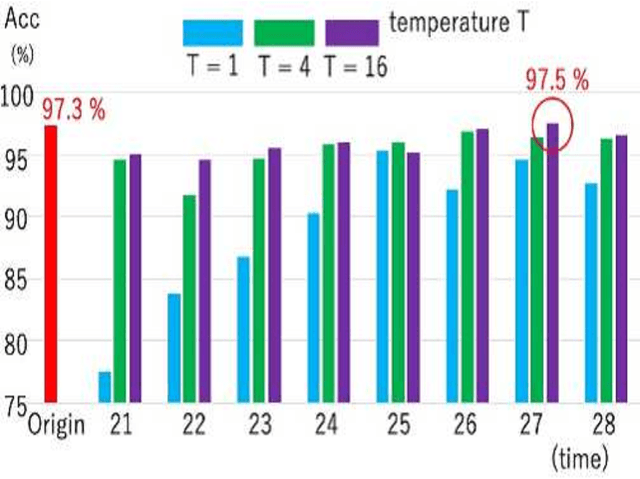
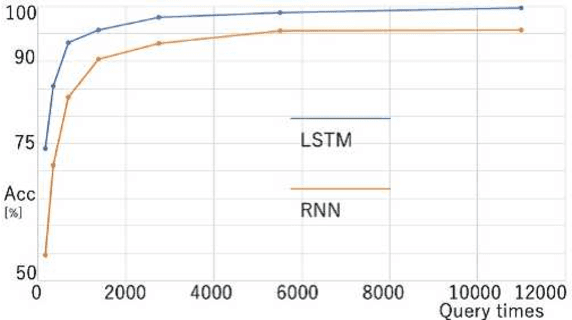
Model extraction attacks are a kind of attacks in which an adversary obtains a new model, whose performance is equivalent to that of a target model, via query access to the target model efficiently, i.e., fewer datasets and computational resources than those of the target model. Existing works have dealt with only simple deep neural networks (DNNs), e.g., only three layers, as targets of model extraction attacks, and hence are not aware of the effectiveness of recurrent neural networks (RNNs) in dealing with time-series data. In this work, we shed light on the threats of model extraction attacks against RNNs. We discuss whether a model with a higher accuracy can be extracted with a simple RNN from a long short-term memory (LSTM), which is a more complicated and powerful RNN. Specifically, we tackle the following problems. First, in a case of a classification problem, such as image recognition, extraction of an RNN model without final outputs from an LSTM model is presented by utilizing outputs halfway through the sequence. Next, in a case of a regression problem. such as in weather forecasting, a new attack by newly configuring a loss function is presented. We conduct experiments on our model extraction attacks against an RNN and an LSTM trained with publicly available academic datasets. We then show that a model with a higher accuracy can be extracted efficiently, especially through configuring a loss function and a more complex architecture different from the target model.
Unsupervised Change Detection in Multi-temporal VHR Images Based on Deep Kernel PCA Convolutional Mapping Network
Dec 18, 2019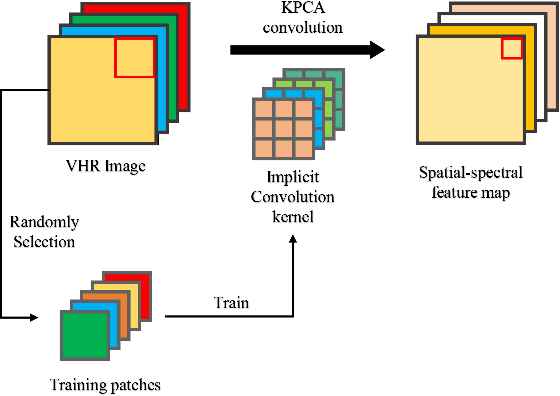


With the development of Earth observation technology, very-high-resolution (VHR) image has become an important data source of change detection. Nowadays, deep learning methods have achieved conspicuous performance in the change detection of VHR images. Nonetheless, most of the existing change detection models based on deep learning require annotated training samples. In this paper, a novel unsupervised model called kernel principal component analysis (KPCA) convolution is proposed for extracting representative features from multi-temporal VHR images. Based on the KPCA convolution, an unsupervised deep siamese KPCA convolutional mapping network (KPCA-MNet) is designed for binary and multi-class change detection. In the KPCA-MNet, the high-level spatial-spectral feature maps are extracted by a deep siamese network consisting of weight-shared PCA convolution layers. Then, the change information in the feature difference map is mapped into a 2-D polar domain. Finally, the change detection results are generated by threshold segmentation and clustering algorithms. All procedures of KPCA-MNet does not require labeled data. The theoretical analysis and experimental results demonstrate the validity, robustness, and potential of the proposed method in two binary change detection data sets and one multi-class change detection data set.
Front2Back: Single View 3D Shape Reconstruction via Front to Back Prediction
Jan 31, 2020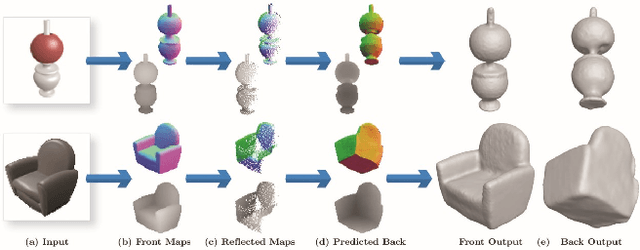



Reconstruction of a 3D shape from a single 2D image is a classical computer vision problem, whose difficulty stems from the inherent ambiguity of recovering occluded or only partially observed surfaces. Recent methods address this challenge through the use of largely unstructured neural networks that effectively distill conditional mapping and priors over 3D shape. In this work, we induce structure and geometric constraints by leveraging three core observations: (1) the surface of most everyday objects is often almost entirely exposed from pairs of typical opposite views; (2) everyday objects often exhibit global reflective symmetries which can be accurately predicted from single views; (3) opposite orthographic views of a 3D shape share consistent silhouettes. Following these observations, we first predict orthographic 2.5D visible surface maps (depth, normal and silhouette) from perspective 2D images, and detect global reflective symmetries in this data; second, we predict the back facing depth and normal maps using as input the front maps and, when available, the symmetric reflections of these maps; and finally, we reconstruct a 3D mesh from the union of these maps using a surface reconstruction method best suited for this data. Our experiments demonstrate that our framework outperforms state-of-the art approaches for 3D shape reconstructions from 2D and 2.5D data in terms of input fidelity and details preservation. Specifically, we achieve 12% better performance on average in ShapeNet benchmark dataset, and up to 19% for certain classes of objects (e.g., chairs and vessels).