 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enabling Hyper-Personalisation: Automated Ad Creative Generation and Ranking for Fashion e-Commerce
Aug 27, 2019
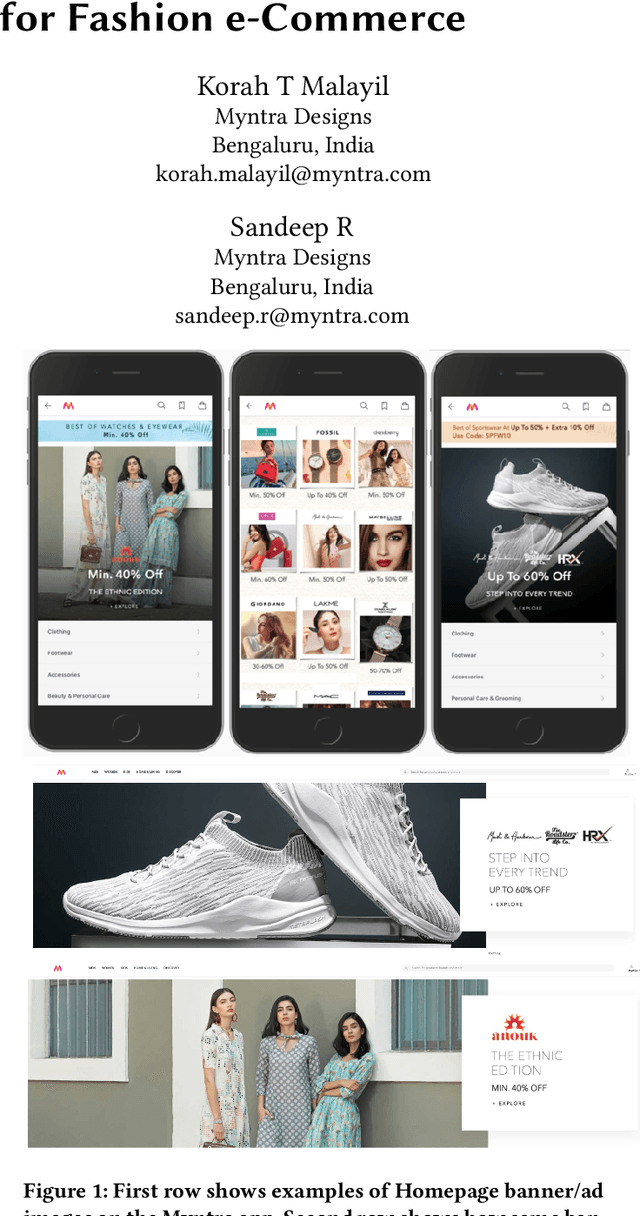
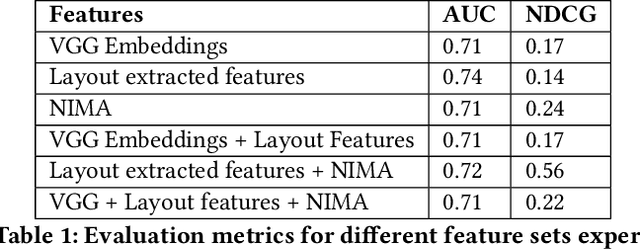
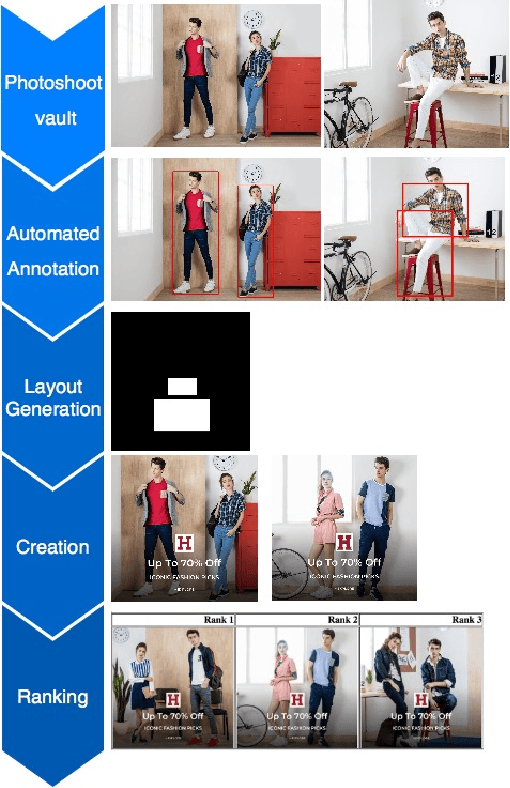
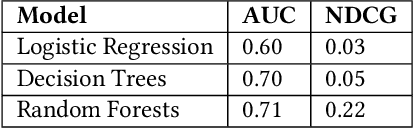
Homepage is the first touch point in the customer's journey and is one of the prominent channels of revenue for many e-commerce companies. A user's attention is mostly captured by homepage banner images (also called Ads/Creatives). The set of banners shown and their design, influence the customer's interest and plays a key role in optimizing the click through rates of the banners. Presently, massive and repetitive effort is put in, to manually create aesthetically pleasing banner images. Due to the large amount of time and effort involved in this process, only a small set of banners are made live at any point. This reduces the number of banners created as well as the degree of personalization that can be achieved. This paper thus presents a method to generate creatives automatically on a large scale in a short duration. The availability of diverse banners generated helps in improving personalization as they can cater to the taste of larger audience. The focus of our paper is on generating wide variety of homepage banners that can be made as an input for user level personalization engine. Following are the main contributions of this paper: 1) We introduce and explain the need for large scale banner generation for e-commerce 2) We present on how we utilize existing deep learning based detectors which can automatically annotate the required objects/tags from the image. 3) We also propose a Genetic Algorithm based method to generate an optimal banner layout for the given image content, input components and other design constraints. 4) Further, to aid the process of picking the right set of banners, we designed a ranking method and evaluated multiple models. All our experiments have been performed on data from Myntra (http://www.myntra.com), one of the top fashion e-commerce players in India.
Curriculum Self-Paced Learning for Cross-Domain Object Detection
Nov 15, 2019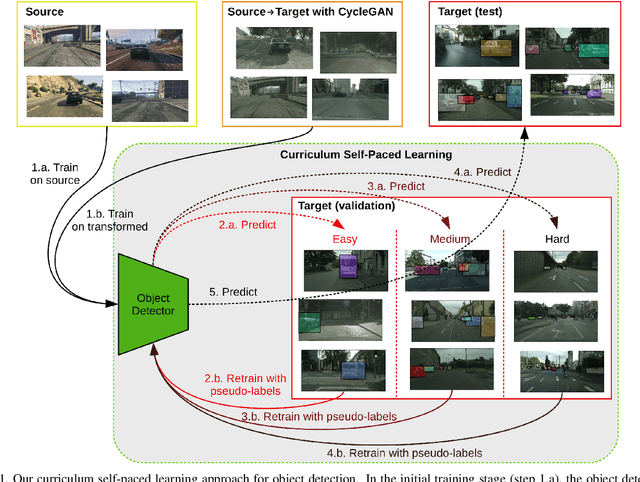
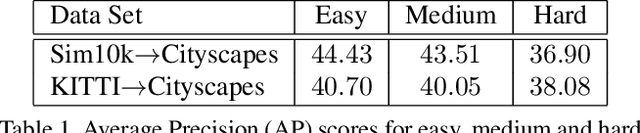
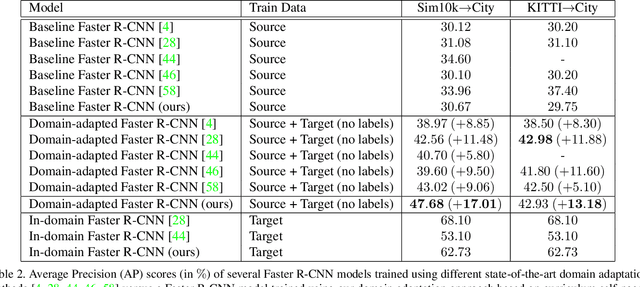

Training (source) domain bias affects state-of-the-art object detectors, such as Faster R-CNN, when applied to new (target) domains. To alleviate this problem, researchers proposed various domain adaptation methods to improve object detection results in the cross-domain setting, e.g. by translating images with ground-truth labels from the source domain to the target domain using Cycle-GAN or by applying self-paced learning. On top of combining Cycle-GAN transformations and self-paced learning, in this paper, we propose a novel self-paced algorithm that learns from easy to hard. To estimate the difficulty of each image, we use the number of detected objects divided by their average size. Our method is simple and effective, without any overhead during inference. It uses only pseudo-labels for samples taken from the target domain, i.e. the domain adaptation is unsupervised. We conduct experiments on two cross-domain benchmarks, showing better results than the state of the art. We also perform an ablation study demonstrating the utility of each component in our framework.
Less Is Better: Unweighted Data Subsampling via Influence Function
Dec 03, 2019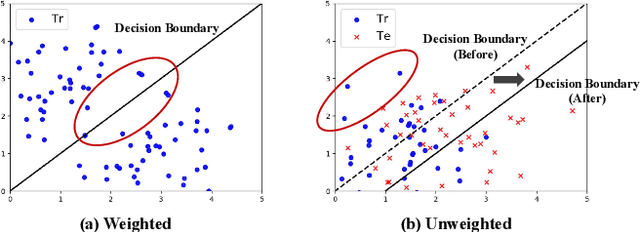
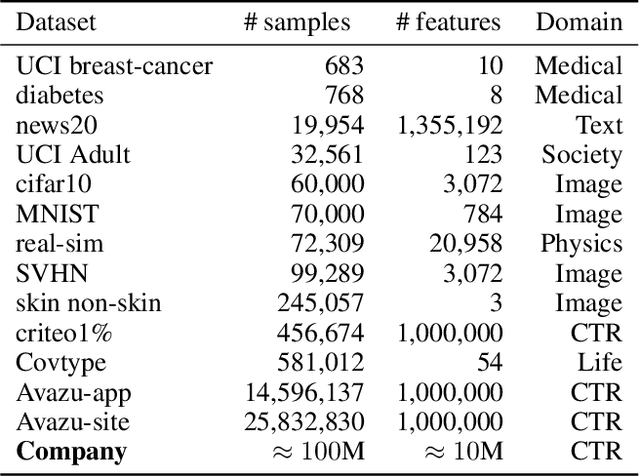
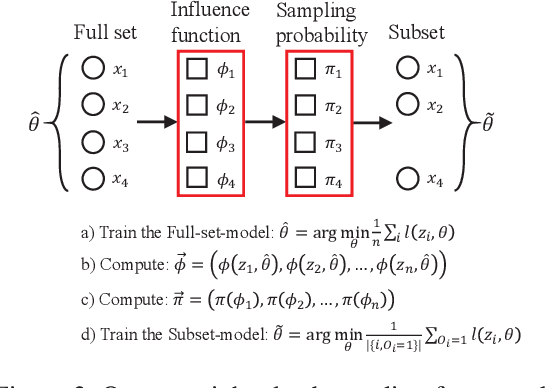
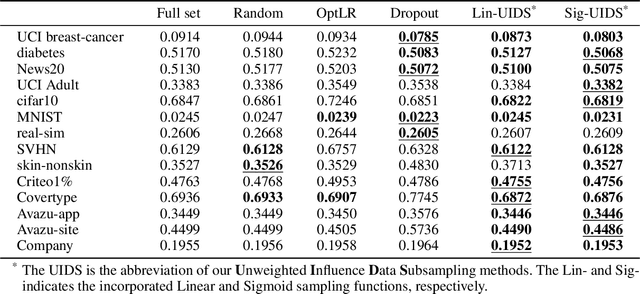
In the time of \emph{Big Data}, training complex models on large-scale data sets is challenging, making it appealing to reduce data volume for saving computation resources by subsampling. Most previous works in subsampling are weighted methods designed to help the performance of subset-model approach the full-set-model, hence the weighted methods have no chance to acquire a subset-model that is better than the full-set-model. However, we question that \emph{how can we achieve better model with less data?} In this work, we propose a novel Unweighted Influence Data Subsampling (UIDS) method, and prove that the subset-model acquired through our method can outperform the full-set-model. Besides, we show that overly confident on a given test set for sampling is common in Influence-based subsampling methods, which can eventually cause our subset-model's failure in out-of-sample test. To mitigate it, we develop a probabilistic sampling scheme to control the \emph{worst-case risk} over all distributions close to the empirical distribution. The experiment results demonstrate our methods superiority over existed subsampling methods in diverse tasks, such as text classification, image classification, click-through prediction, etc.
A Unified Neural Architecture for Instrumental Audio Tasks
Mar 01, 2019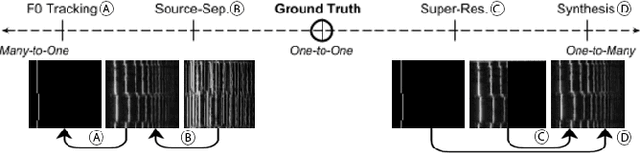
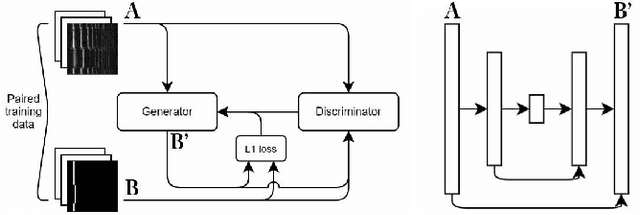
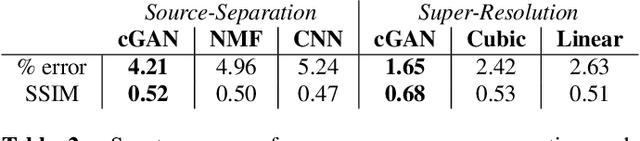
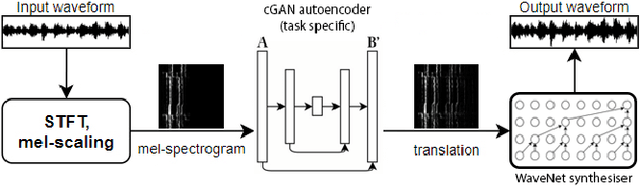
Within Music Information Retrieval (MIR), prominent tasks -- including pitch-tracking, source-separation, super-resolution, and synthesis -- typically call for specialised methods, despite their similarities. Conditional Generative Adversarial Networks (cGANs) have been shown to be highly versatile in learning general image-to-image translations, but have not yet been adapted across MIR. In this work, we present an end-to-end supervisable architecture to perform all aforementioned audio tasks, consisting of a WaveNet synthesiser conditioned on the output of a jointly-trained cGAN spectrogram translator. In doing so, we demonstrate the potential of such flexible techniques to unify MIR tasks, promote efficient transfer learning, and converge research to the improvement of powerful, general methods. Finally, to the best of our knowledge, we present the first application of GANs to guided instrument synthesis.
Curved Gabor Filters for Fingerprint Image Enhancement
Jul 25, 2014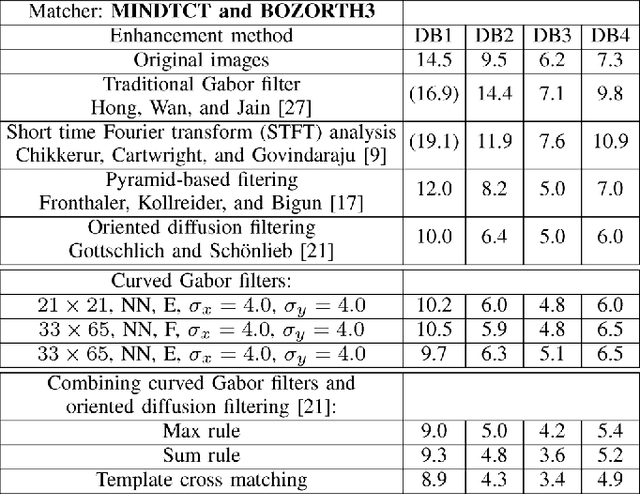
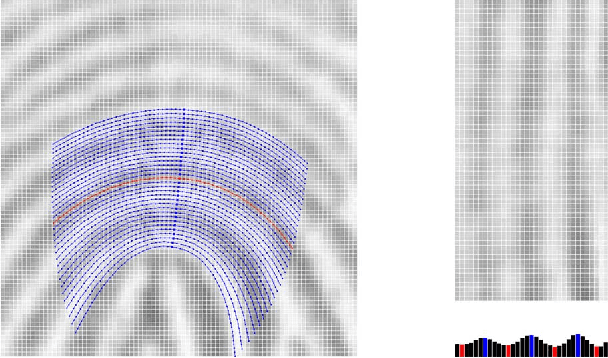
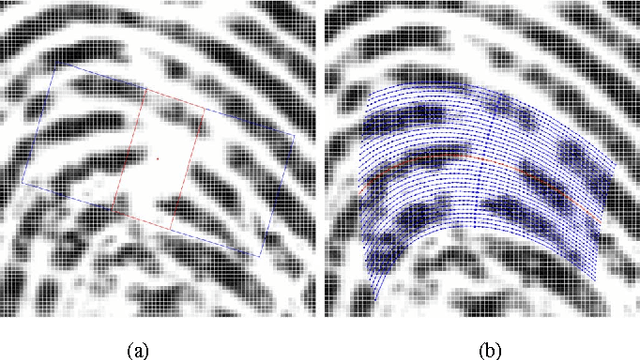

Gabor filters play an important role in many application areas for the enhancement of various types of images and the extraction of Gabor features. For the purpose of enhancing curved structures in noisy images, we introduce curved Gabor filters which locally adapt their shape to the direction of flow. These curved Gabor filters enable the choice of filter parameters which increase the smoothing power without creating artifacts in the enhanced image. In this paper, curved Gabor filters are applied to the curved ridge and valley structure of low-quality fingerprint images. First, we combine two orientation field estimation methods in order to obtain a more robust estimation for very noisy images. Next, curved regions are constructed by following the respective local orientation and they are used for estimating the local ridge frequency. Lastly, curved Gabor filters are defined based on curved regions and they are applied for the enhancement of low-quality fingerprint images. Experimental results on the FVC2004 databases show improvements of this approach in comparison to state-of-the-art enhancement methods.
Place-specific Background Modeling Using Recursive Autoencoders
Apr 07, 2019

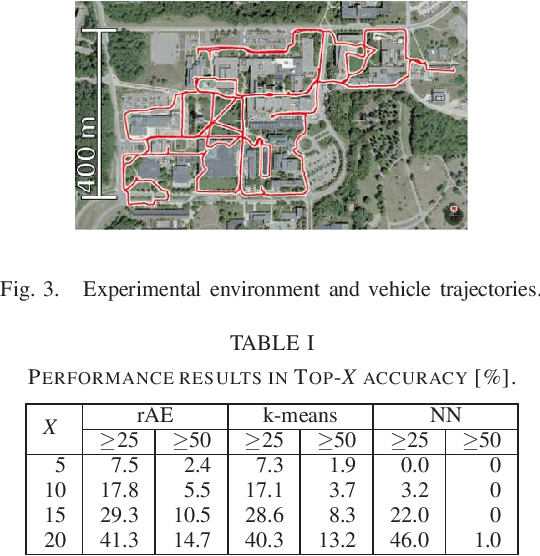
Image change detection (ICD) to detect changed objects in front of a vehicle with respect to a place-specific background model using an on-board monocular vision system is a fundamental problem in intelligent vehicle (IV). From the perspective of recent large-scale IV applications, it can be impractical in terms of space/time efficiency to train place-specific background models for every possible place. To address these issues, we introduce a new autoencoder (AE) based efficient ICD framework that combines the advantages of AE-based anomaly detection (AD) and AE-based image compression (IC). We propose a method that uses AE reconstruction errors as a single unified measure for training a minimal set of place-specific AEs and maintains detection accuracy. We introduce an efficient incremental recursive AE (rAE) training framework that recursively summarizes a large collection of background images into the AE set. The results of experiments on challenging cross-season ICD tasks validate the efficacy of the proposed approach.
Automatic Discovery of Political Meme Genres with Diverse Appearances
Jan 17, 2020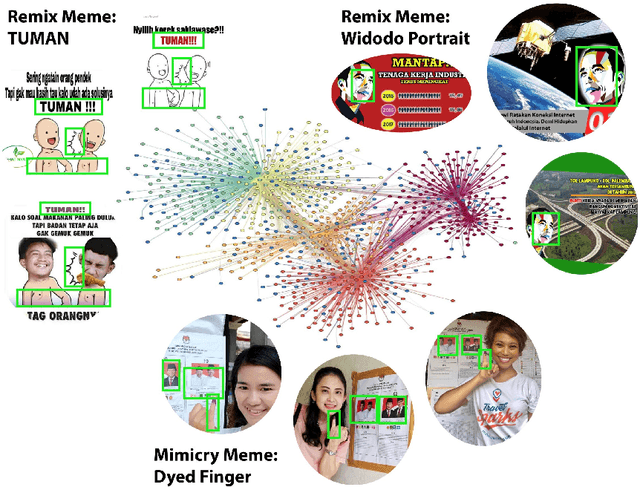
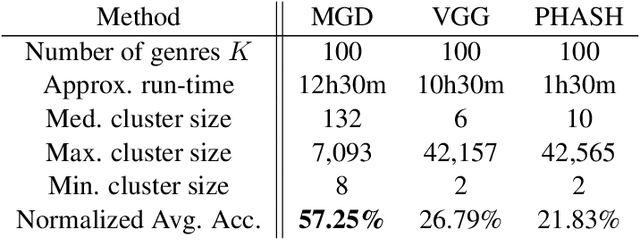
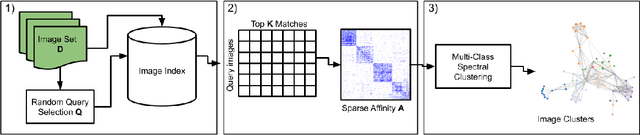

Forms of human communication are not static --- we expect some evolution in the way information is conveyed over time because of advances in technology. One example of this phenomenon is the image-based meme, which has emerged as a dominant form of political messaging in the past decade. While originally used to spread jokes on social media, memes are now having an outsized impact on public perception of world events. A significant challenge in automatic meme analysis has been the development of a strategy to match memes from within a single genre when the appearances of the images vary. Such variation is especially common in memes exhibiting mimicry. For example, when voters perform a common hand gesture to signal their support for a candidate. In this paper we introduce a scalable automated visual recognition pipeline for discovering political meme genres of diverse appearance. This pipeline can ingest meme images from a social network, apply computer vision-based techniques to extract local features and index new images into a database, and then organize the memes into related genres. To validate this approach, we perform a large case study on the 2019 Indonesian Presidential Election using a new dataset of over two million images collected from Twitter and Instagram. Results show that this approach can discover new meme genres with visually diverse images that share common stylistic elements, paving the way forward for further work in semantic analysis and content attribution.
Audio-Conditioned U-Net for Position Estimation in Full Sheet Images
Oct 16, 2019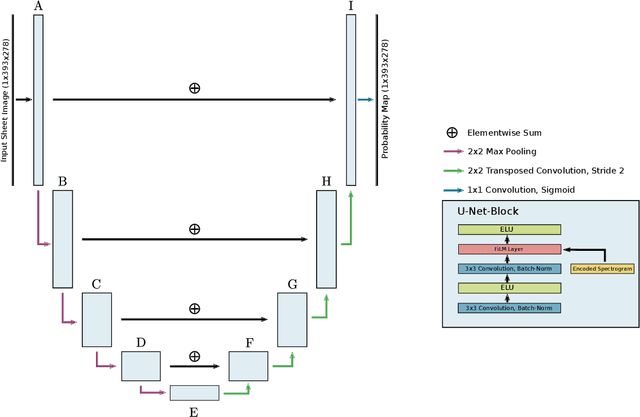


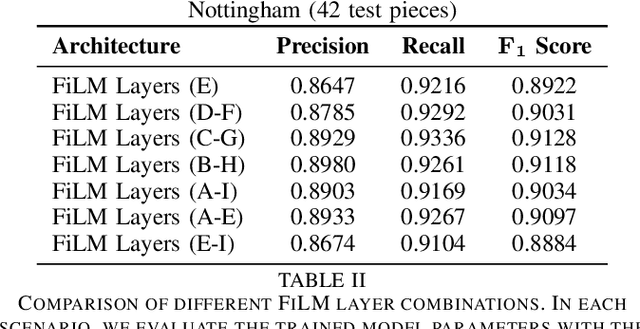
The goal of score following is to track a musical performance, usually in the form of audio, in a corresponding score representation. Established methods mainly rely on computer-readable scores in the form of MIDI or MusicXML and achieve robust and reliable tracking results. Recently, multimodal deep learning methods have been used to follow along musical performances in raw sheet images. Among the current limits of these systems is that they require a non trivial amount of preprocessing steps that unravel the raw sheet image into a single long system of staves. The current work is an attempt at removing this particular limitation. We propose an architecture capable of estimating matching score positions directly within entire unprocessed sheet images. We argue that this is a necessary first step towards a fully integrated score following system that does not rely on any preprocessing steps such as optical music recognition.
Robust Invisible Hyperlinks in Physical Photographs Based on 3D Rendering Attacks
Dec 03, 2019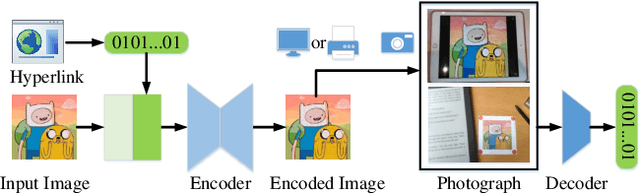
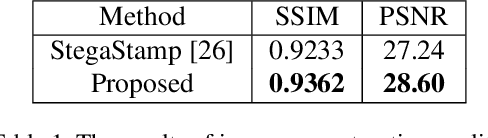
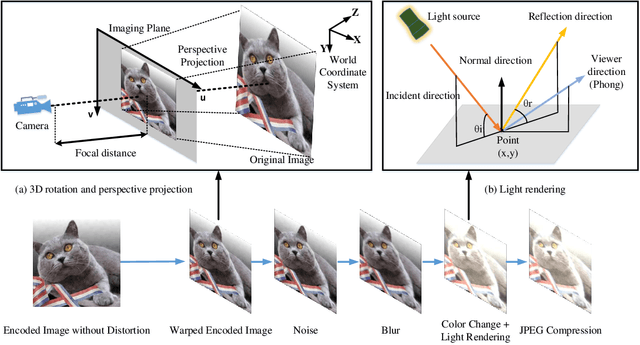
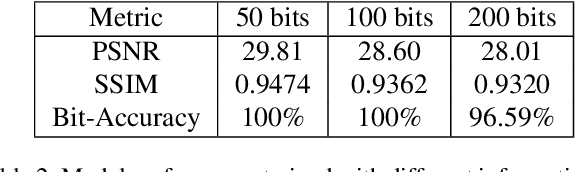
In the era of multimedia and Internet, people are eager to obtain information from offline to online. Quick Response (QR) codes and digital watermarks help us access information quickly. However, QR codes look ugly and invisible watermarks can be easily broken in physical photographs. Therefore, this paper proposes a novel method to embed hyperlinks into natural images, making the hyperlinks invisible for human eyes but detectable for mobile devices. Our method is an end-to-end neural network with an encoder to hide information and a decoder to recover information. From original images to physical photographs, camera imaging process will introduce a series of distortion such as noise, blur, and light. To train a robust decoder against the physical distortion from the real world, a distortion network based on 3D rendering is inserted between the encoder and the decoder to simulate the camera imaging process. Besides, in order to maintain the visual attraction of the image with hyperlinks, we propose a loss function based on just noticeable difference (JND) to supervise the training of encoder. Experimental results show that our approach outperforms the previous method in both simulated and real situations.
Intracranial Hemorrhage Segmentation Using Deep Convolutional Model
Nov 15, 2019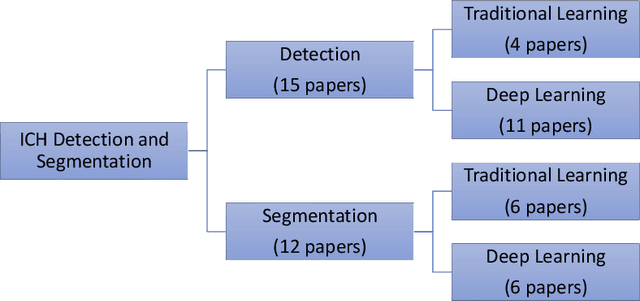
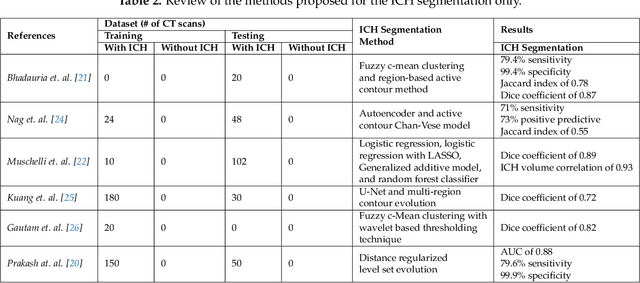
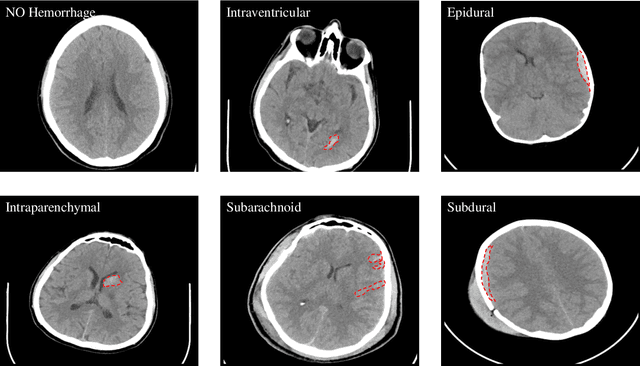
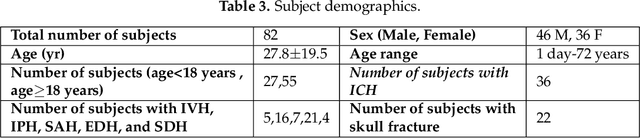
Traumatic brain injuries could cause intracranial hemorrhage (ICH). ICH could lead to disability or death if it is not accurately diagnosed and treated in a time-sensitive procedure. The current clinical protocol to diagnose ICH is examining Computerized Tomography (CT) scans by radiologists to detect ICH and localize its regions. However, this process relies heavily on the availability of an experienced radiologist. In this paper, we designed a study protocol to collect a dataset of 82 CT scans of subjects with traumatic brain injury. Later, the ICH regions were manually delineated in each slice by a consensus decision of two radiologists. Recently, fully convolutional networks (FCN) have shown to be successful in medical image segmentation. We developed a deep FCN, called U-Net, to segment the ICH regions from the CT scans in a fully automated manner. The method achieved a Dice coefficient of 0.31 for the ICH segmentation based on 5-fold cross-validation. The dataset is publicly available online at PhysioNet repository for future analysis and comparison.