 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multiple Light Source Dataset for Colour Research
Sep 16, 2019
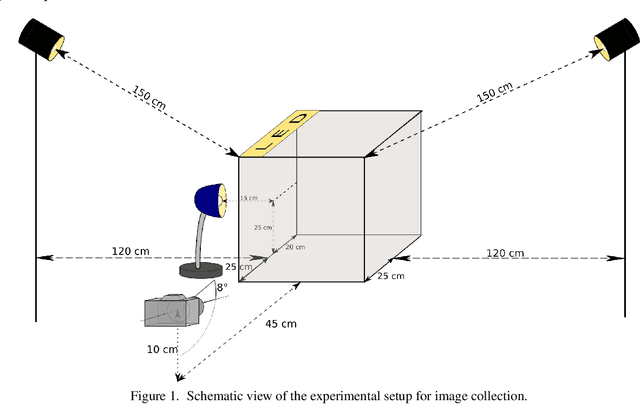


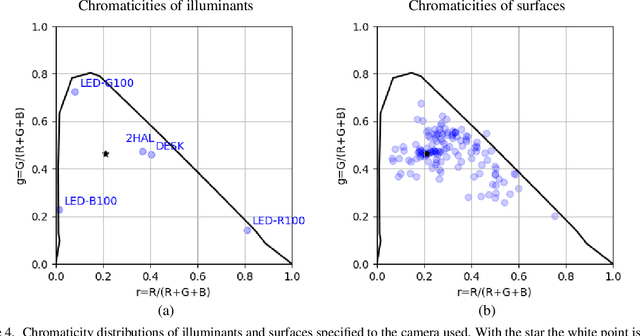
We present a collection of 24 multiple object scenes each recorded under 18 multiple light source illumination scenarios. The illuminants are varying in dominant spectral colours, intensity and distance from the scene. We mainly address the realistic scenarios for evaluation of computational colour constancy algorithms, but also have aimed to make the data as general as possible for computational colour science and computer vision. Along with the images of the scenes, we provide spectral characteristics of the camera, light sources and the objects and include pixel-by-pixel ground truth annotation of uniformly coloured object surfaces thus making this useful for benchmarking colour-based image segmentation algorithms. The dataset is freely available at https://github.com/visillect/mls-dataset.
VORNet: Spatio-temporally Consistent Video Inpainting for Object Removal
Apr 14, 2019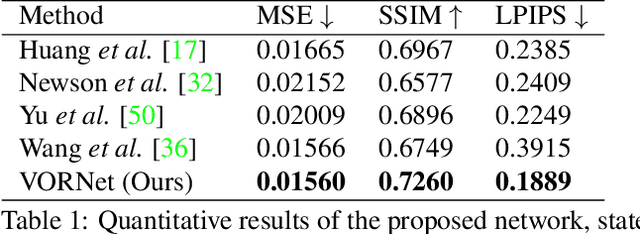
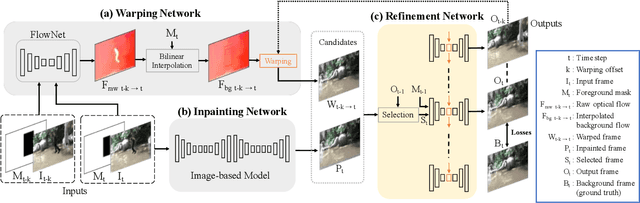
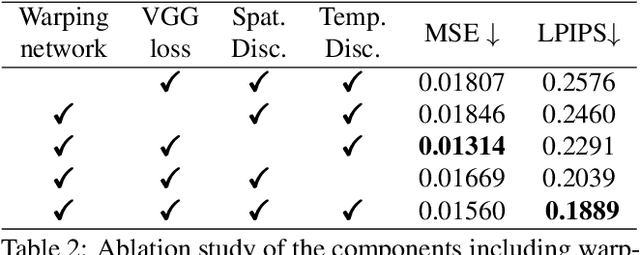
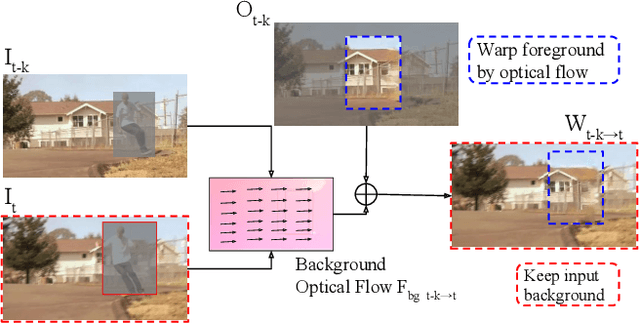
Video object removal is a challenging task in video processing that often requires massive human efforts. Given the mask of the foreground object in each frame, the goal is to complete (inpaint) the object region and generate a video without the target object. While recently deep learning based methods have achieved great success on the image inpainting task, they often lead to inconsistent results between frames when applied to videos. In this work, we propose a novel learning-based Video Object Removal Network (VORNet) to solve the video object removal task in a spatio-temporally consistent manner, by combining the optical flow warping and image-based inpainting model. Experiments are done on our Synthesized Video Object Removal (SVOR) dataset based on the YouTube-VOS video segmentation dataset, and both the objective and subjective evaluation demonstrate that our VORNet generates more spatially and temporally consistent videos compared with existing methods.
FDSNet: Finger dorsal image spoof detection network using light field camera
Dec 18, 2018
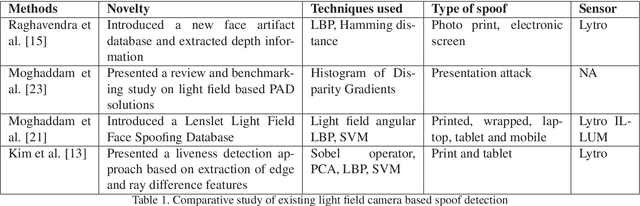
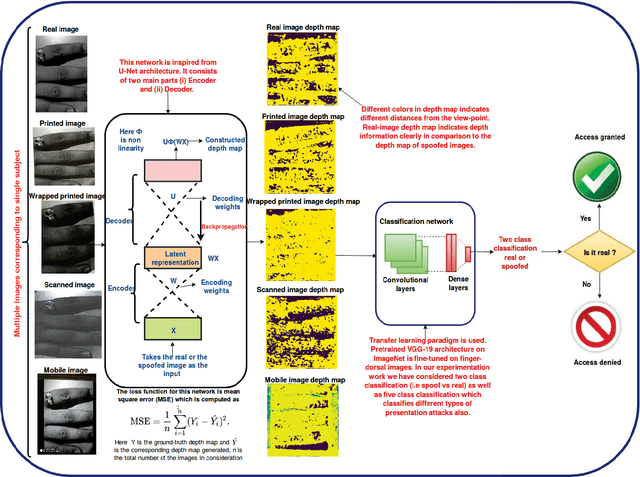
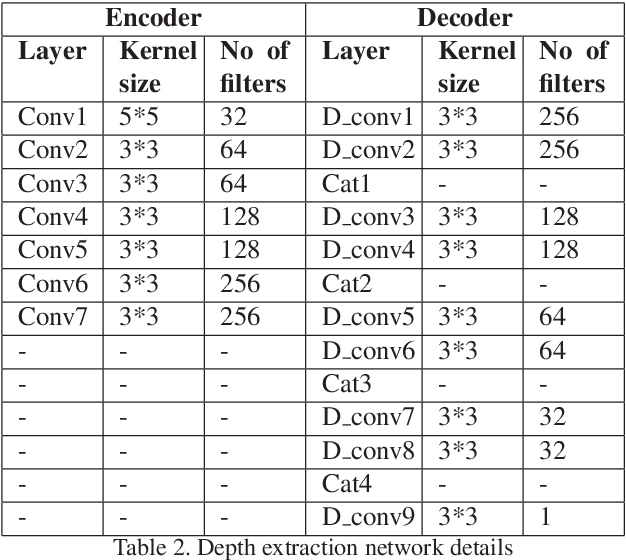
At present spoofing attacks via which biometric system is potentially vulnerable against a fake biometric characteristic, introduces a great challenge to recognition performance. Despite the availability of a broad range of presentation attack detection (PAD) or liveness detection algorithms, fingerprint sensors are vulnerable to spoofing via fake fingers. In such situations, finger dorsal images can be thought of as an alternative which can be captured without much user cooperation and are more appropriate for outdoor security applications. In this paper, we present a first feasibility study of spoofing attack scenarios on finger dorsal authentication system, which include four types of presentation attacks such as printed paper, wrapped printed paper, scan and mobile. This study also presents a CNN based spoofing attack detection method which employ state-of-the-art deep learning techniques along with transfer learning mechanism. We have collected 196 finger dorsal real images from 33 subjects, captured with a Lytro camera and also created a set of 784 finger dorsal spoofing images. Extensive experimental results have been performed that demonstrates the superiority of the proposed approach for various spoofing attacks.
Inverse Cooking: Recipe Generation from Food Images
Dec 14, 2018



People enjoy food photography because they appreciate food. Behind each meal there is a story described in a complex recipe and, unfortunately, by simply looking at a food image we do not have access to its preparation process. Therefore, in this paper we introduce an inverse cooking system that recreates cooking recipes given food images. Our system predicts ingredients as sets by means of a novel architecture, modeling their dependencies without imposing any order, and then generates cooking instructions by attending to both image and its inferred ingredients simultaneously. We extensively evaluate the whole system on the large-scale Recipe1M dataset and show that (1) we improve performance w.r.t. previous baselines for ingredient prediction; (2) we are able to obtain high quality recipes by leveraging both image and ingredients; (3) our system is able to produce more compelling recipes than retrieval-based approaches according to human judgment.
Chart Auto-Encoders for Manifold Structured Data
Dec 20, 2019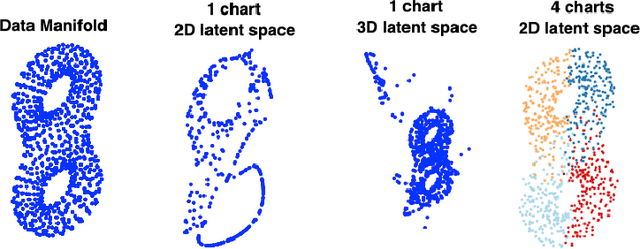
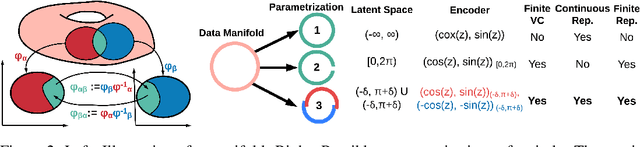
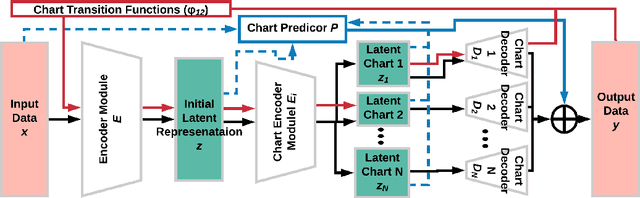
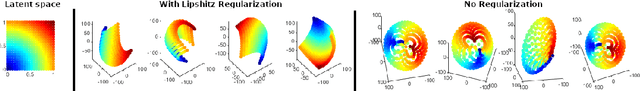
Auto-encoding and generative models have made tremendous successes in image and signal representation learning and generation. These models, however, generally employ the full Euclidean space or a bounded subset (such as $[0,1]^l$) as the latent space, whose flat geometry is often too simplistic to meaningfully reflect the topological structure of the data. This paper aims at exploring a universal geometric structure of the latent space for better data representation. Inspired by differential geometry, we propose a Chart Auto-Encoder (CAE), which captures the manifold structure of the data with multiple charts and transition functions among them. CAE translates the mathematical definition of manifold through parameterizing the entire data set as a collection of overlapping charts, creating local latent representations. These representations are an enhancement of the single-charted latent space commonly employed in auto-encoding models, as they reflect the intrinsic structure of the manifold. Therefore, CAE achieves a more accurate approximation of data and generates realistic synthetic examples. We demonstrate the efficacy of CAEs through a series experiments with synthetic and real-life data which illustrate that CAEs can out-preform variational auto-encoders on reconstruction tasks while using much smaller latent spaces.
Facial Expression Restoration Based on Improved Graph Convolutional Networks
Oct 23, 2019
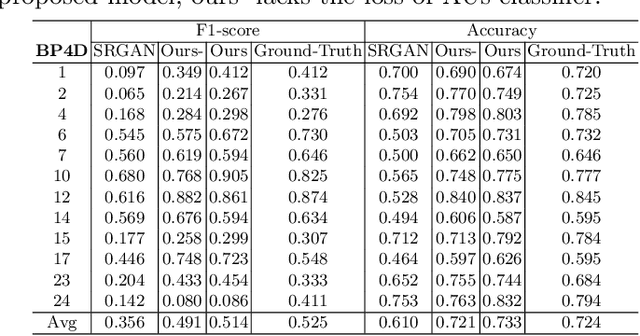
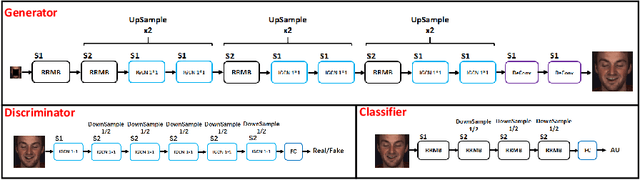
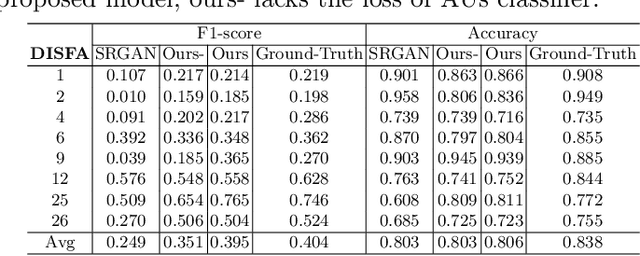
Facial expression analysis in the wild is challenging when the facial image is with low resolution or partial occlusion. Considering the correlations among different facial local regions under different facial expressions, this paper proposes a novel facial expression restoration method based on generative adversarial network by integrating an improved graph convolutional network (IGCN) and region relation modeling block (RRMB). Unlike conventional graph convolutional networks taking vectors as input features, IGCN can use tensors of face patches as inputs. It is better to retain the structure information of face patches. The proposed RRMB is designed to address facial generative tasks including inpainting and super-resolution with facial action units detection, which aims to restore facial expression as the ground-truth. Extensive experiments conducted on BP4D and DISFA benchmarks demonstrate the effectiveness of our proposed method through quantitative and qualitative evaluations.
No Surprises: Training Robust Lung Nodule Detection for Low-Dose CT Scans by Augmenting with Adversarial Attacks
Mar 08, 2020

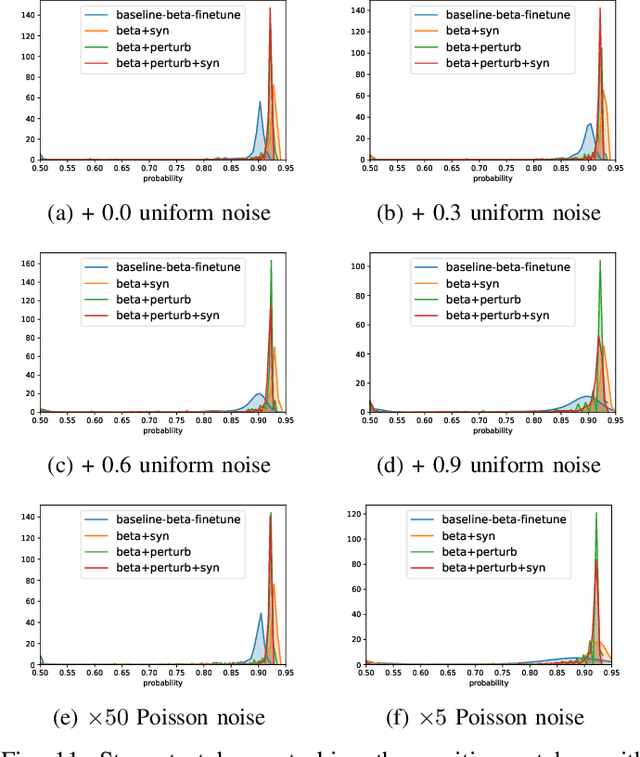
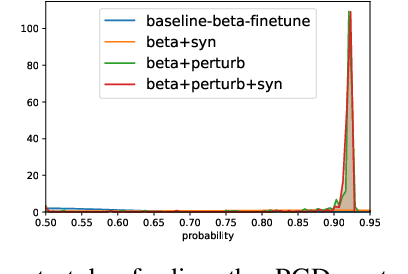
Detecting malignant pulmonary nodules at an early stage can allow medical interventions which increases the survival rate of lung cancer patients. Using computer vision techniques to detect nodules can improve the sensitivity and the speed of interpreting chest CT for lung cancer screening. Many studies have used CNNs to detect nodule candidates. Though such approaches have been shown to outperform the conventional image processing based methods regarding the detection accuracy, CNNs are also known to be limited to generalize on under-represented samples in the training set and prone to imperceptible noise perturbations. Such limitations can not be easily addressed by scaling up the dataset or the models. In this work, we propose to add adversarial synthetic nodules and adversarial attack samples to the training data to improve the generalization and the robustness of the lung nodule detection systems. In order to generate hard examples of nodules from a differentiable nodule synthesizer, we use projected gradient descent (PGD) to search the latent code within a bounded neighbourhood that would generate nodules to decrease the detector response. To make the network more robust to unanticipated noise perturbations, we use PGD to search for noise patterns that can trigger the network to give over-confident mistakes. By evaluating on two different benchmark datasets containing consensus annotations from three radiologists, we show that the proposed techniques can improve the detection performance on real CT data. To understand the limitations of both the conventional networks and the proposed augmented networks, we also perform stress-tests on the false positive reduction networks by feeding different types of artificially produced patches. We show that the augmented networks are more robust to both under-represented nodules as well as resistant to noise perturbations.
Rosetta: Large scale system for text detection and recognition in images
Oct 11, 2019
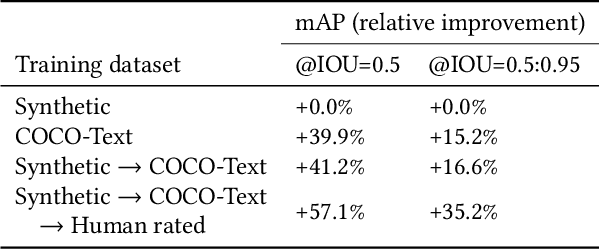
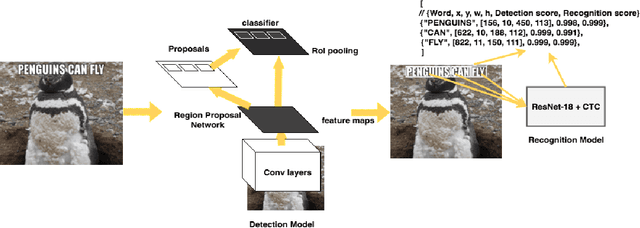

In this paper we present a deployed, scalable optical character recognition (OCR) system, which we call Rosetta, designed to process images uploaded daily at Facebook scale. Sharing of image content has become one of the primary ways to communicate information among internet users within social networks such as Facebook and Instagram, and the understanding of such media, including its textual information, is of paramount importance to facilitate search and recommendation applications. We present modeling techniques for efficient detection and recognition of text in images and describe Rosetta's system architecture. We perform extensive evaluation of presented technologies, explain useful practical approaches to build an OCR system at scale, and provide insightful intuitions as to why and how certain components work based on the lessons learnt during the development and deployment of the system.
Curiosity-driven Reinforcement Learning for Diverse Visual Paragraph Generation
Aug 01, 2019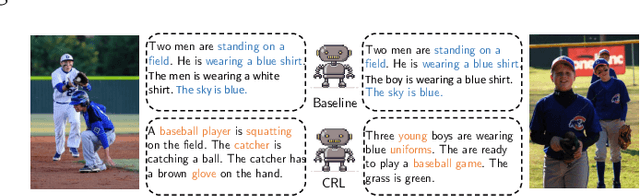
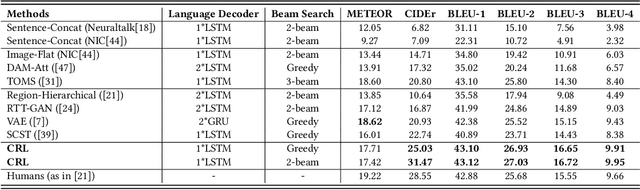
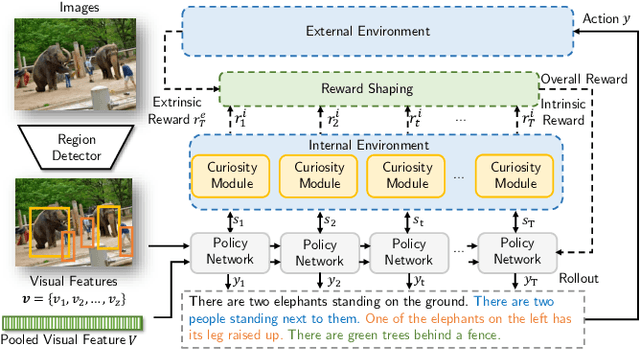
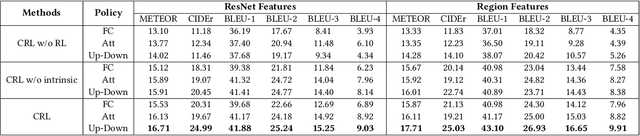
Visual paragraph generation aims to automatically describe a given image from different perspectives and organize sentences in a coherent way. In this paper, we address three critical challenges for this task in a reinforcement learning setting: the mode collapse, the delayed feedback, and the time-consuming warm-up for policy networks. Generally, we propose a novel Curiosity-driven Reinforcement Learning (CRL) framework to jointly enhance the diversity and accuracy of the generated paragraphs. First, by modeling the paragraph captioning as a long-term decision-making process and measuring the prediction uncertainty of state transitions as intrinsic rewards, the model is incentivized to memorize precise but rarely spotted descriptions to context, rather than being biased towards frequent fragments and generic patterns. Second, since the extrinsic reward from evaluation is only available until the complete paragraph is generated, we estimate its expected value at each time step with temporal-difference learning, by considering the correlations between successive actions. Then the estimated extrinsic rewards are complemented by dense intrinsic rewards produced from the derived curiosity module, in order to encourage the policy to fully explore action space and find a global optimum. Third, discounted imitation learning is integrated for learning from human demonstrations, without separately performing the time-consuming warm-up in advance. Extensive experiments conducted on the Standford image-paragraph dataset demonstrate the effectiveness and efficiency of the proposed method, improving the performance by 38.4% compared with state-of-the-art.
Learning to Map Nearly Anything
Sep 16, 2019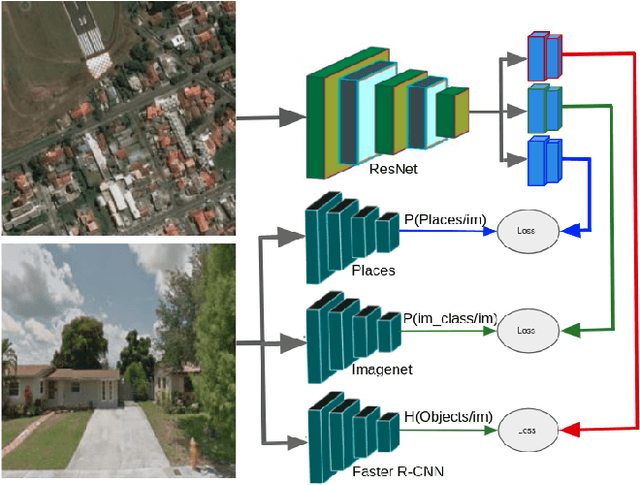


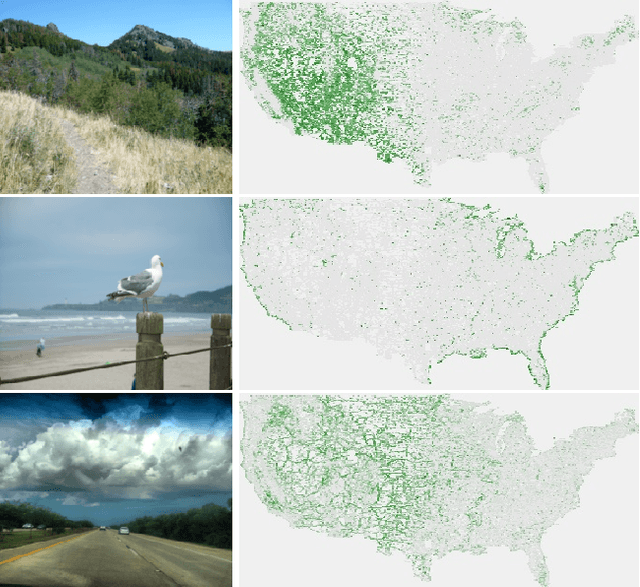
Looking at the world from above, it is possible to estimate many properties of a given location, including the type of land cover and the expected land use. Historically, such tasks have relied on relatively coarse-grained categories due to the difficulty of obtaining fine-grained annotations. In this work, we propose an easily extensible approach that makes it possible to estimate fine-grained properties from overhead imagery. In particular, we propose a cross-modal distillation strategy to learn to predict the distribution of fine-grained properties from overhead imagery, without requiring any manual annotation of overhead imagery. We show that our learned models can be used directly for applications in mapping and image localization.