 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Coverage Testing of Deep Learning Models using Dataset Characterization
Nov 17, 2019
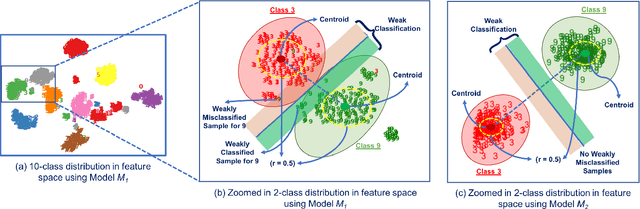
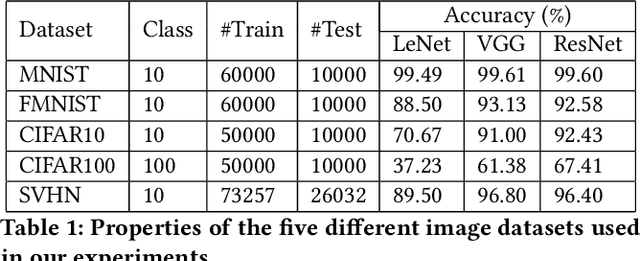
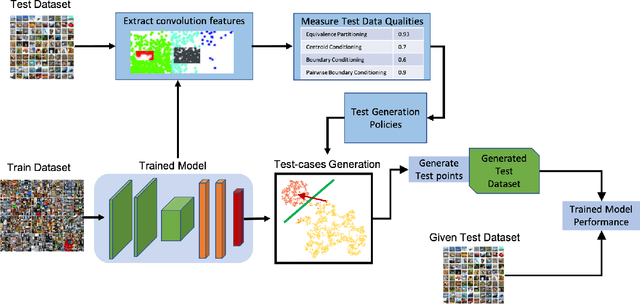
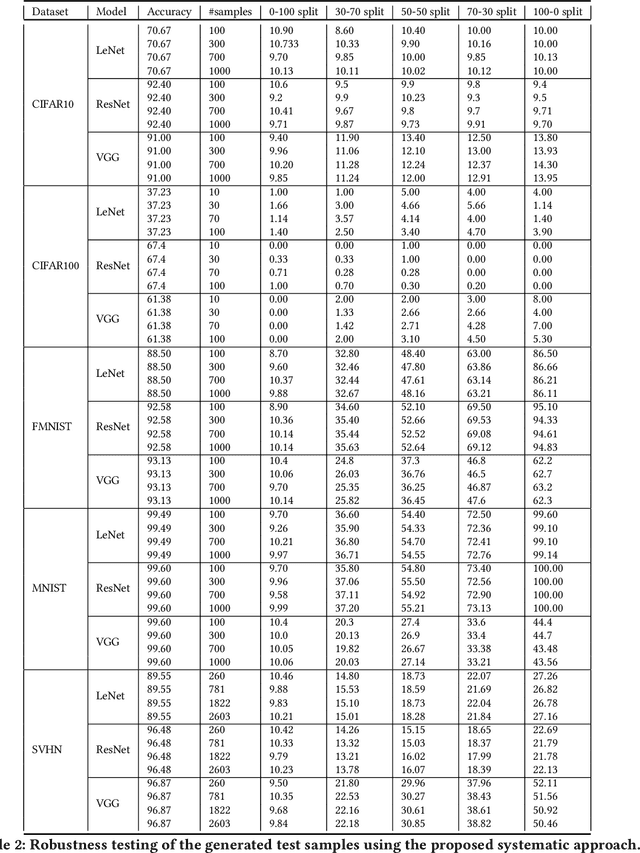
Deep Neural Networks (DNNs), with its promising performance, are being increasingly used in safety critical applications such as autonomous driving, cancer detection, and secure authentication. With growing importance in deep learning, there is a requirement for a more standardized framework to evaluate and test deep learning models. The primary challenge involved in automated generation of extensive test cases are: (i) neural networks are difficult to interpret and debug and (ii) availability of human annotators to generate specialized test points. In this research, we explain the necessity to measure the quality of a dataset and propose a test case generation system guided by the dataset properties. From a testing perspective, four different dataset quality dimensions are proposed: (i) equivalence partitioning, (ii) centroid positioning, (iii) boundary conditioning, and (iv) pair-wise boundary conditioning. The proposed system is evaluated on well known image classification datasets such as MNIST, Fashion-MNIST, CIFAR10, CIFAR100, and SVHN against popular deep learning models such as LeNet, ResNet-20, VGG-19. Further, we conduct various experiments to demonstrate the effectiveness of systematic test case generation system for evaluating deep learning models.
CNNTOP: a CNN-based Trajectory Owner Prediction Method
Jan 05, 2020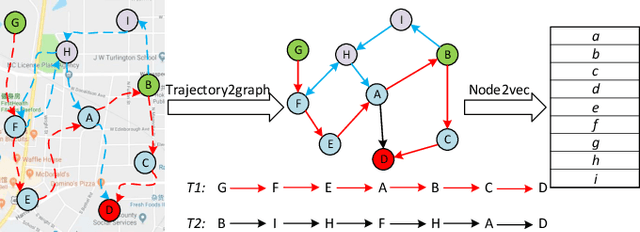
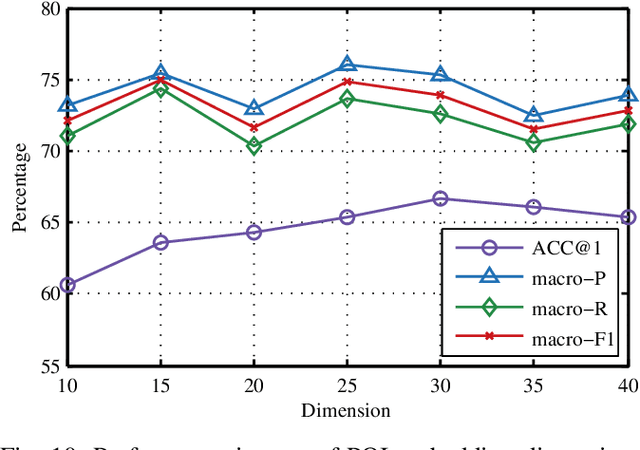
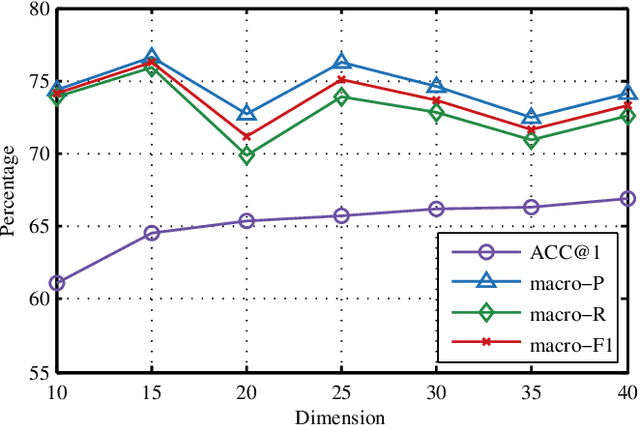
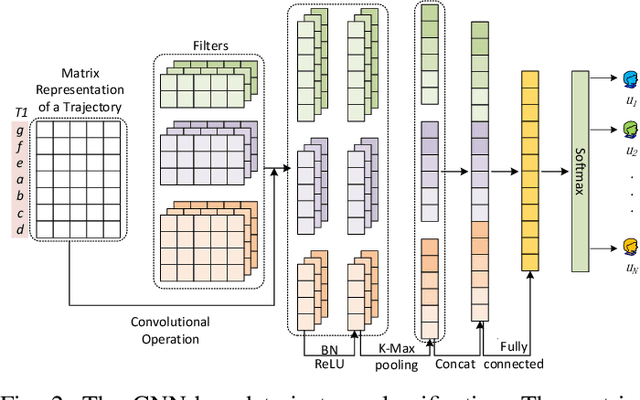
Trajectory owner prediction is the basis for many applications such as personalized recommendation, urban planning. Although much effort has been put on this topic, the results archived are still not good enough. Existing methods mainly employ RNNs to model trajectories semantically due to the inherent sequential attribute of trajectories. However, these approaches are weak at Point of Interest (POI) representation learning and trajectory feature detection. Thus, the performance of existing solutions is far from the requirements of practical applications. In this paper, we propose a novel CNN-based Trajectory Owner Prediction (CNNTOP) method. Firstly, we connect all POI according to trajectories from all users. The result is a connected graph that can be used to generate more informative POI sequences than other approaches. Secondly, we employ the Node2Vec algorithm to encode each POI into a low-dimensional real value vector. Then, we transform each trajectory into a fixed-dimensional matrix, which is similar to an image. Finally, a CNN is designed to detect features and predict the owner of a given trajectory. The CNN can extract informative features from the matrix representations of trajectories by convolutional operations, Batch normalization, and $K$-max pooling operations. Extensive experiments on real datasets demonstrate that CNNTOP substantially outperforms existing solutions in terms of macro-Precision, macro-Recall, macro-F1, and accuracy.
Calibration of Deep Probabilistic Models with Decoupled Bayesian Neural Networks
Sep 25, 2019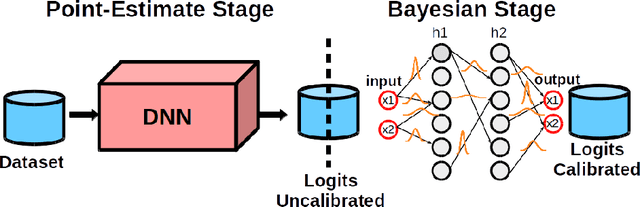
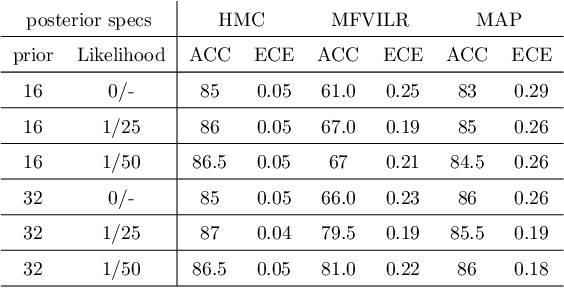
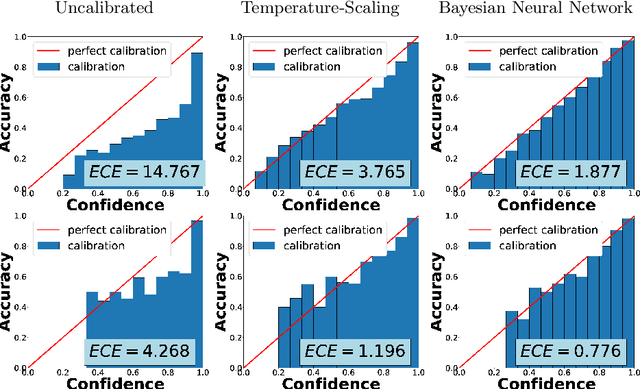
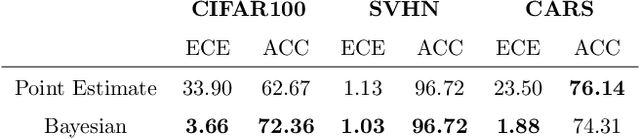
Deep Neural Networks (DNNs) have achieved state-of-the-art accuracy performance in many tasks. However, recent works have pointed out that the outputs provided by these models are not well-calibrated, seriously limiting their use in critical decision scenarios. In this work, we propose to use a decoupled Bayesian stage, implemented with a Bayesian Neural Network (BNN), to map the uncalibrated probabilities provided by a DNN to calibrated ones, consistently improving calibration. Our results evidence that incorporating uncertainty provides more reliable probabilistic models, a critical condition for achieving good calibration. We report a generous collection of experimental results using high-accuracy DNNs in standardized image classification benchmarks, showing the good performance, flexibility and robust behavior of our approach with respect to several state-of-the-art calibration methods. Code for reproducibility is provided.
KoPA: Automated Kronecker Product Approximation
Dec 05, 2019
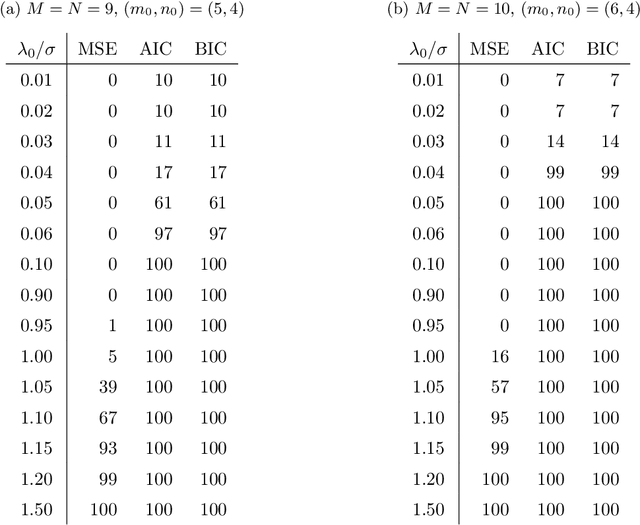
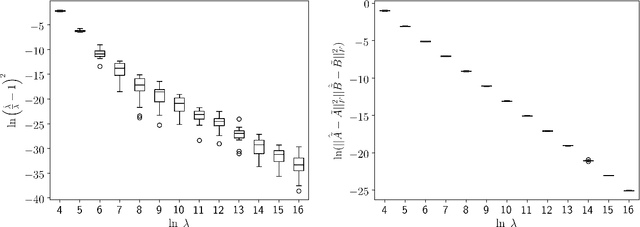
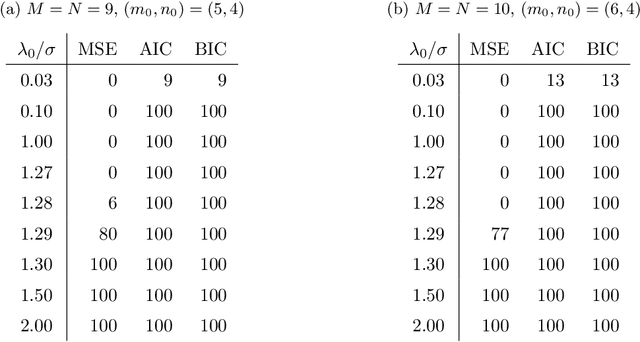
We consider matrix approximation induced by the Kronecker product decomposition. Similar as the low rank approximations, which seeks to approximate a given matrix by the sum of a few rank-1 matrices, we propose to use the approximation by the sum of a few Kronecker products, which we refer to as the Kronecker product approximation (KoPA). Although it can be transformed into an SVD problem, KoPA offers a greater flexibility over low rank approximation, since it allows the user to choose the configuration of the Kronecker product. On the other hand, the configuration (the dimensions of the two smaller matrices forming the Kronecker product) to be used is usually unknown, and has to be determined from the data in order to obtain optimal balance between accuracy and complexity. We propose to use an extended information criterion to select the configuration. Under the paradigm of high dimensionality, we show that the proposed procedure is able to select the true configuration with probability tending to one, under suitable conditions on the signal-to-noise ratio. We demonstrate the performance and superiority of KoPA over the low rank approximations thought numerical studies, and a real example in image analysis.
Improved Embeddings with Easy Positive Triplet Mining
Apr 08, 2019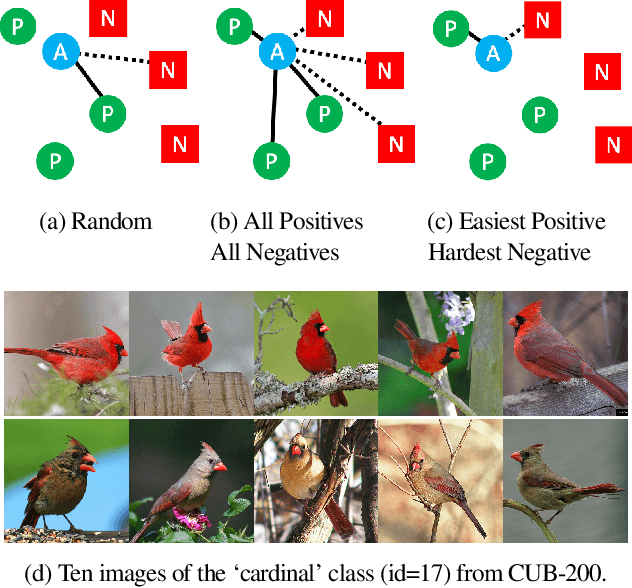
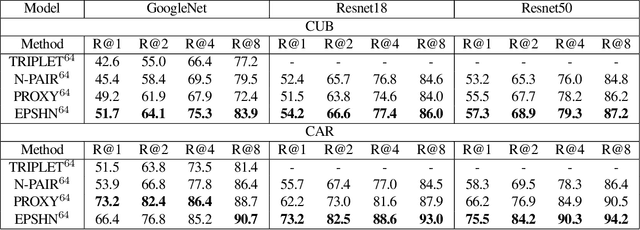
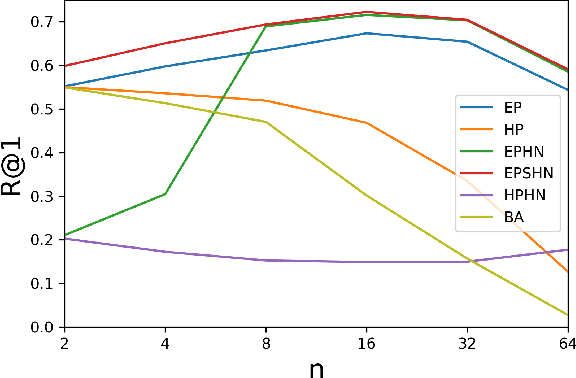
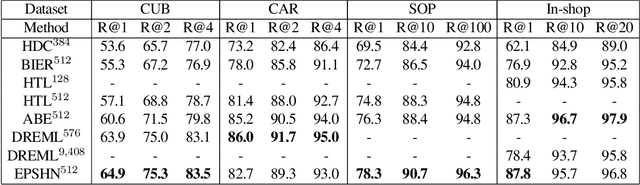
Deep metric learning seeks to define an embedding where semantically similar images are embedded to nearby locations, and semantically dissimilar images are embedded to distant locations. Substantial work has focused on loss functions and strategies to learn these embeddings by pushing images from the same class as close together in the embedding space as possible. In this paper, we propose an alternative, loosened embedding strategy that requires the embedding function only map each training image to the most similar examples from the same class, an approach we call "Easy Positive" mining. We provide a collection of experiments and visualizations that highlight that this Easy Positive mining leads to embeddings that are more flexible and generalize better to new unseen data. This simple mining strategy yields recall performance that exceeds state of the art approaches (including those with complicated loss functions and ensemble methods) on image retrieval datasets including CUB, Stanford Online Products, In-Shop Clothes and Hotels-50K.
SoDeep: a Sorting Deep net to learn ranking loss surrogates
Apr 08, 2019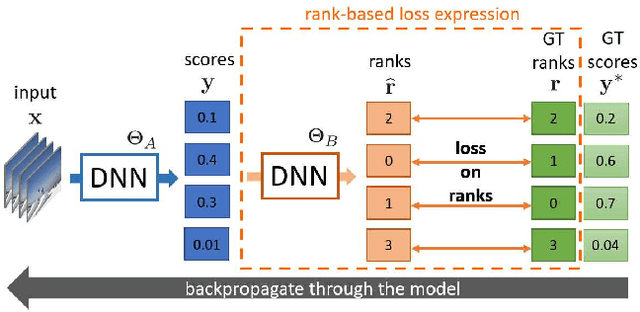

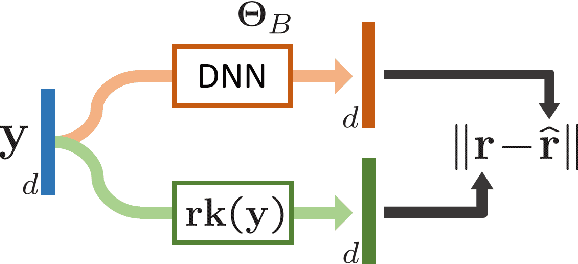

Several tasks in machine learning are evaluated using non-differentiable metrics such as mean average precision or Spearman correlation. However, their non-differentiability prevents from using them as objective functions in a learning framework. Surrogate and relaxation methods exist but tend to be specific to a given metric. In the present work, we introduce a new method to learn approximations of such non-differentiable objective functions. Our approach is based on a deep architecture that approximates the sorting of arbitrary sets of scores. It is trained virtually for free using synthetic data. This sorting deep (SoDeep) net can then be combined in a plug-and-play manner with existing deep architectures. We demonstrate the interest of our approach in three different tasks that require ranking: Cross-modal text-image retrieval, multi-label image classification and visual memorability ranking. Our approach yields very competitive results on these three tasks, which validates the merit and the flexibility of SoDeep as a proxy for sorting operation in ranking-based losses.
Approximate Bayesian Computation with the Sliced-Wasserstein Distance
Oct 28, 2019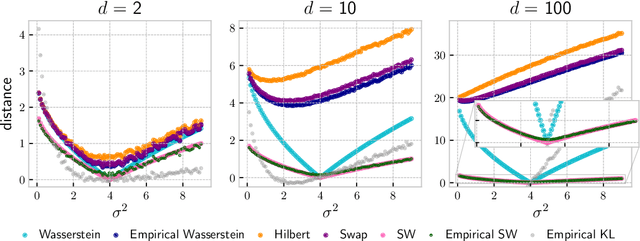
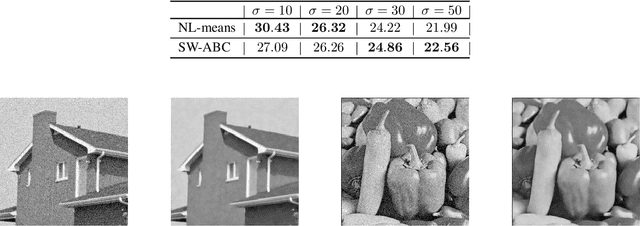
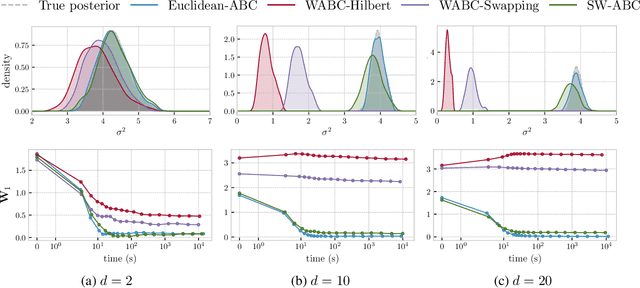
Approximate Bayesian Computation (ABC) is a popular method for approximate inference in generative models with intractable but easy-to-sample likelihood. It constructs an approximate posterior distribution by finding parameters for which the simulated data are close to the observations in terms of summary statistics. These statistics are defined beforehand and might induce a loss of information, which has been shown to deteriorate the quality of the approximation. To overcome this problem, Wasserstein-ABC has been recently proposed, and compares the datasets via the Wasserstein distance between their empirical distributions, but does not scale well to the dimension or the number of samples. We propose a new ABC technique, called Sliced-Wasserstein ABC and based on the Sliced-Wasserstein distance, which has better computational and statistical properties. We derive two theoretical results showing the asymptotical consistency of our approach, and we illustrate its advantages on synthetic data and an image denoising task.
Representing pictures with emotions
Dec 07, 2018
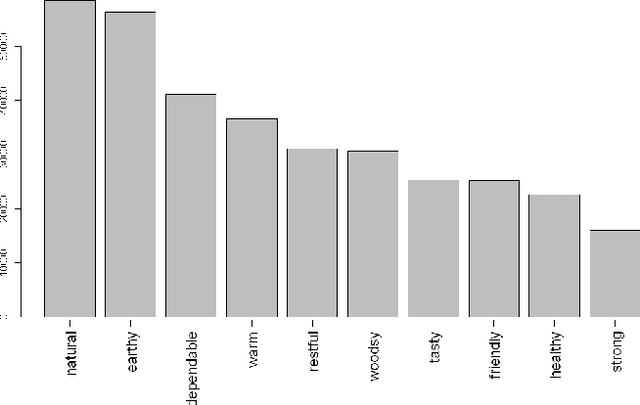
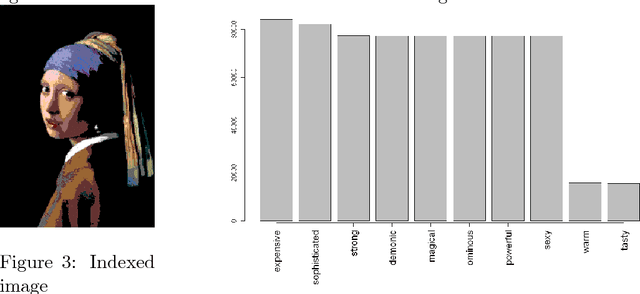
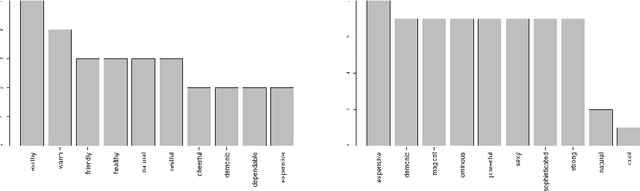
Modern research in content-based image retrieval systems (CIBR) has become progressively more focused on the richness of human semantics. Several approaches may be used to reduced the 'semantic gap' between the high-level human experience and the low level visual features of pictures. Object ontology, among others, is one of the methods. In this paper we investigate the use of a codified emotion ontology over global color features of images to annotate the images at a high semantic level. In order to speed up the annotation process the images are sampled so that each digital image is represented by a random subset of its content. We test within controlled conditions how this random subset may represent the adequate high level emotional concept presented in the image. We monitor this information reducing process with entropy measures, showing that controlled random sampling can capture with significant relevance high level concepts for picture representation.
Convolutional Neural Networks: A Binocular Vision Perspective
Dec 21, 2019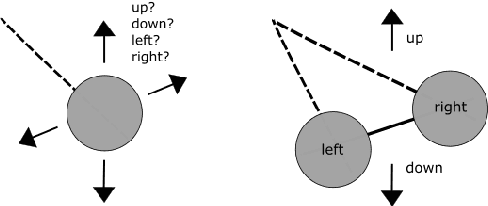
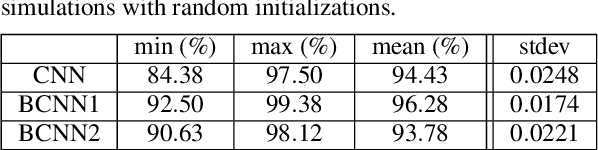
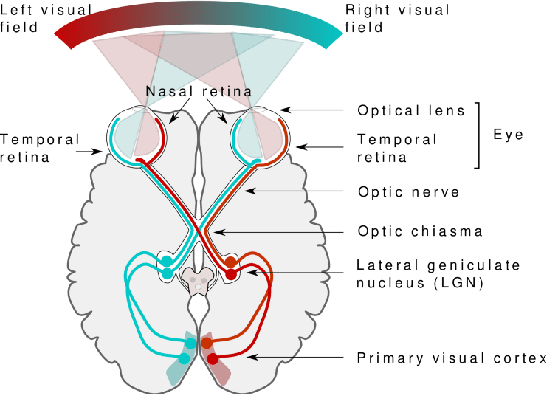

It is arguable that whether the single camera captured (monocular) image datasets are sufficient enough to train and test convolutional neural networks (CNNs) for imitating the biological neural network structures of the human brain. As human visual system works in binocular, the collaboration of the eyes with the two brain lobes needs more investigation for improvements in such CNN-based visual imagery analysis applications. It is indeed questionable that if respective visual fields of each eye and the associated brain lobes are responsible for different learning abilities of the same scene. There are such open questions in this field of research which need rigorous investigation in order to further understand the nature of the human visual system, hence improve the currently available deep learning applications. This position paper analyses a binocular CNNs architecture that is more analogous to the biological structure of the human visual system than the conventional deep learning techniques. While taking a structure called optic chiasma into account, this architecture consists of basically two parallel CNN structures associated with each visual field and the brain lobe, fully connected later possibly as in the primary visual cortex (V1). Experimental results demonstrate that binocular learning of two different visual fields leads to better classification rates on average, when compared to classical CNN architectures.
Study of Efficient Technique Based On 2D Tsallis Entropy For Image Thresholding
Jan 20, 2014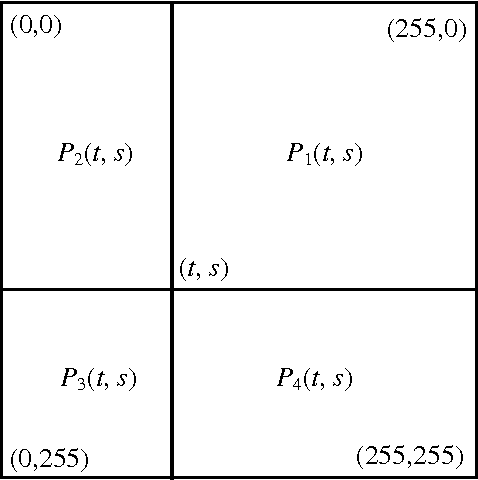
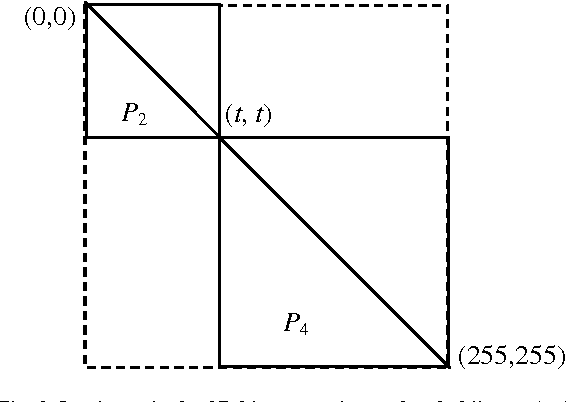
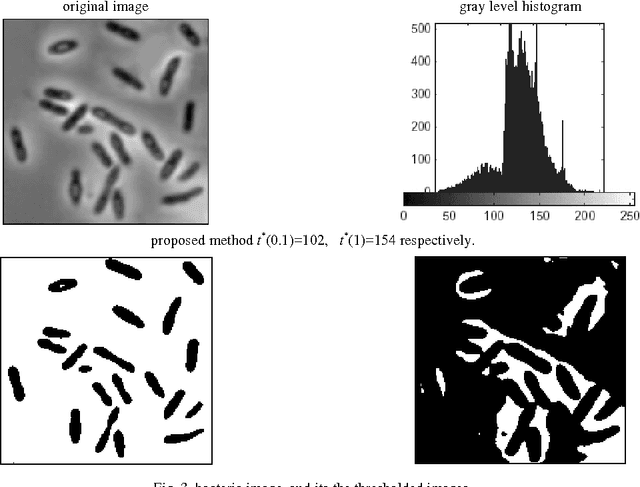
Thresholding is an important task in image processing. It is a main tool in pattern recognition, image segmentation, edge detection and scene analysis. In this paper, we present a new thresholding technique based on two-dimensional Tsallis entropy. The two-dimensional Tsallis entropy was obtained from the twodimensional histogram which was determined by using the gray value of the pixels and the local average gray value of the pixels, the work it was applied a generalized entropy formalism that represents a recent development in statistical mechanics. The effectiveness of the proposed method is demonstrated by using examples from the real-world and synthetic images. The performance evaluation of the proposed technique in terms of the quality of the thresholded images are presented. Experimental results demonstrate that the proposed method achieve better result than the Shannon method.