 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Accurate Nuclear Segmentation with Center Vector Encoding
Jul 10, 2019
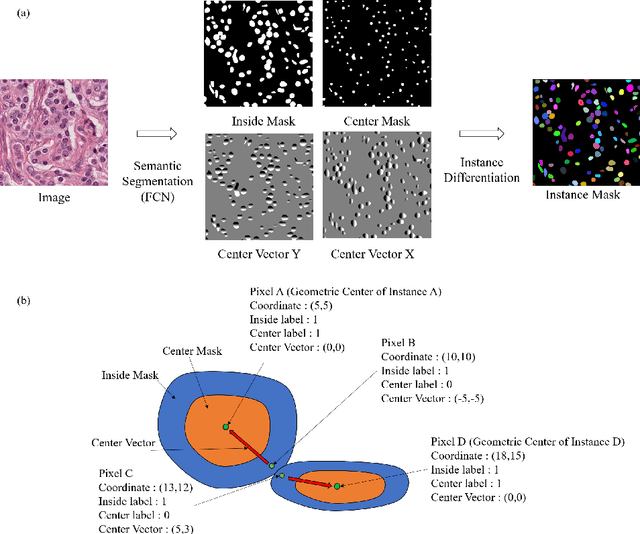
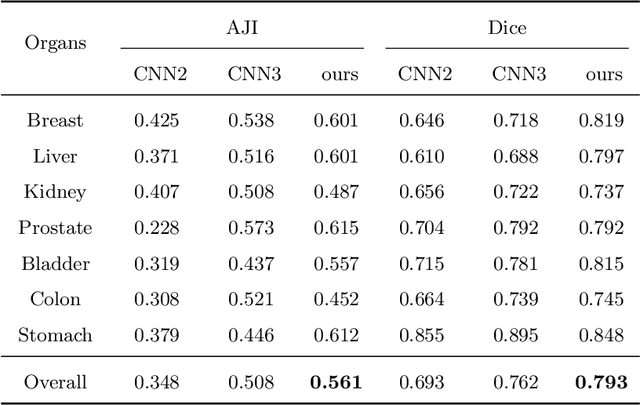
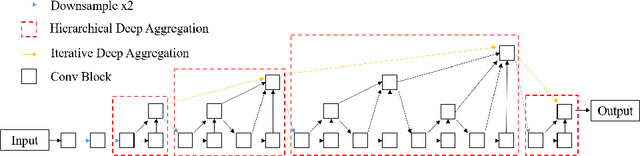
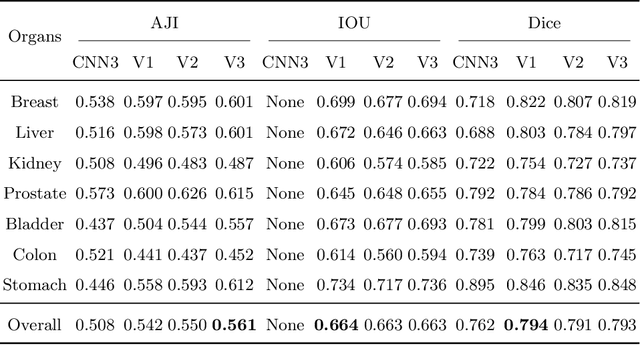
Nuclear segmentation is important and frequently demanded for pathology image analysis, yet is also challenging due to nuclear crowdedness and possible occlusion. In this paper, we present a novel bottom-up method for nuclear segmentation. The concepts of Center Mask and Center Vector are introduced to better depict the relationship between pixels and nuclear instances. The instance differentiation process are thus largely simplified and easier to understand. Experiments demonstrate the effectiveness of Center Vector Encoding, where our method outperforms state-of-the-arts by a clear margin.
Iterative multi-path tracking for video and volume segmentation with sparse point supervision
Aug 27, 2018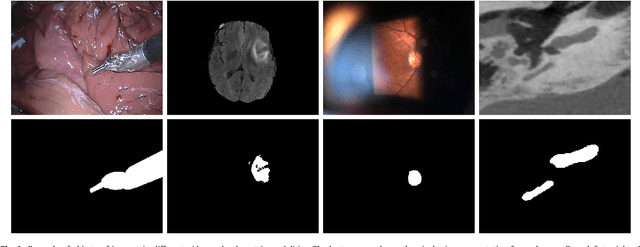

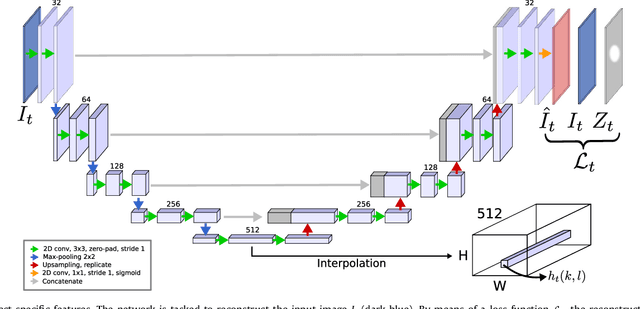

Recent machine learning strategies for segmentation tasks have shown great ability when trained on large pixel-wise annotated image datasets. It remains a major challenge however to aggregate such datasets, as the time and monetary cost associated with collecting extensive annotations is extremely high. This is particularly the case for generating precise pixel-wise annotations in video and volumetric image data. To this end, this work presents a novel framework to produce pixel-wise segmentations using minimal supervision. Our method relies on 2D point supervision, whereby a single 2D location within an object of interest is provided on each image of the data. Our method then estimates the object appearance in a semi-supervised fashion by learning object-image-specific features and by using these in a semi-supervised learning framework. Our object model is then used in a graph-based optimization problem that takes into account all provided locations and the image data in order to infer the complete pixel-wise segmentation. In practice, we solve this optimally as a tracking problem using a K-shortest path approach. Both the object model and segmentation are then refined iteratively to further improve the final segmentation. We show that by collecting 2D locations using a gaze tracker, our approach can provide state-of-the-art segmentations on a range of objects and image modalities (video and 3D volumes), and that these can then be used to train supervised machine learning classifiers.
Tensor Recovery from Noisy and Multi-Level Quantized Measurements
Dec 05, 2019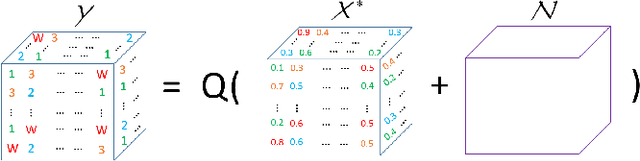
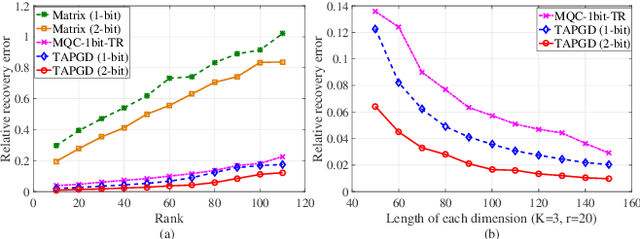
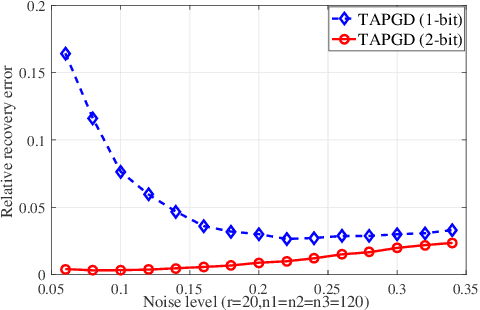
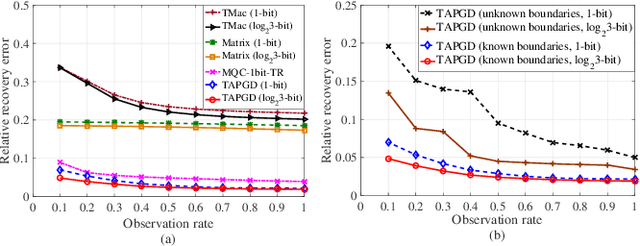
Higher-order tensors can represent scores in a rating system, frames in a video, and images of the same subject. In practice, the measurements are often highly quantized due to the sampling strategies or the quality of devices. Existing works on tensor recovery have focused on data losses and random noises. Only a few works consider tensor recovery from quantized measurements but are restricted to binary measurements. This paper, for the first time, addresses the problem of tensor recovery from multi-level quantized measurements. Leveraging the low-rank property of the tensor, this paper proposes a nonconvex optimization problem for tensor recovery. We provide a theoretical upper bound of the recovery error, which diminishes to zero when the sizes of dimensions increase to infinity. Our error bound significantly improves over the existing results in one-bit tensor recovery and quantized matrix recovery. A tensor-based alternating proximal gradient descent algorithm with a convergence guarantee is proposed to solve the nonconvex problem. Our recovery method can handle data losses and do not need the information of the quantization rule. The method is validated on synthetic data, image datasets, and music recommender datasets.
Conditional GANs for Multi-Illuminant Color Constancy: Revolution or Yet Another Approach?
Nov 15, 2018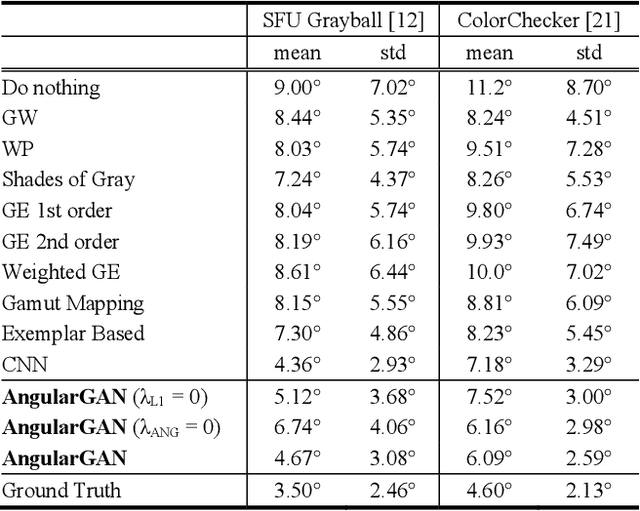
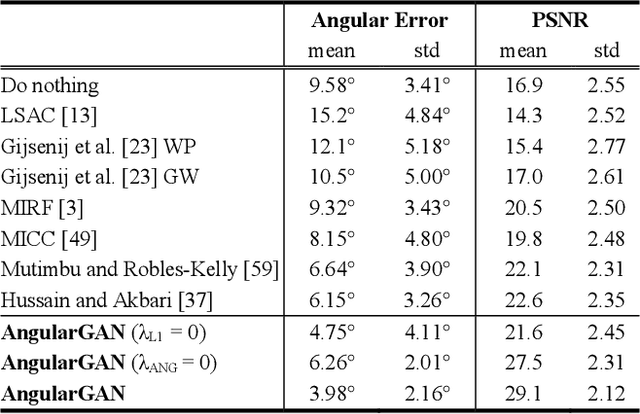
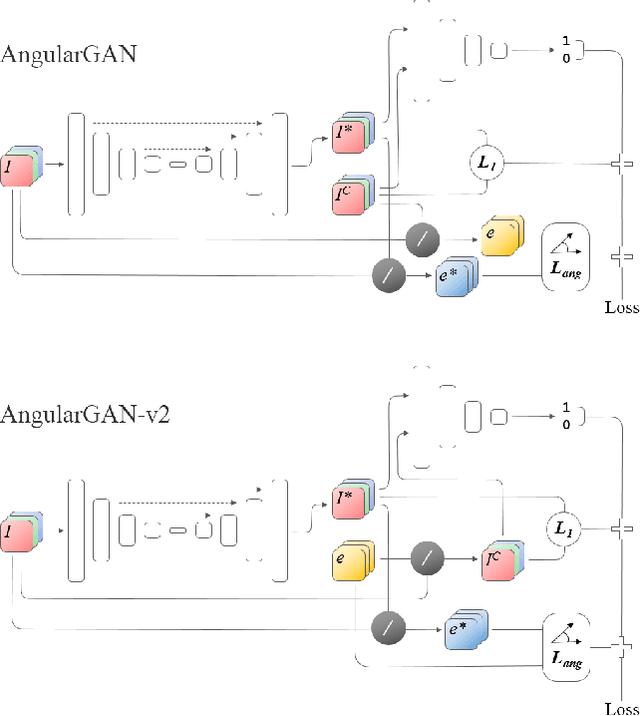

Non-uniform and multi-illuminant color constancy are important tasks, the solution of which will allow to discard information about lighting conditions in the image. Non-uniform illumination and shadows distort colors of real-world objects and mostly do not contain valuable information. Thus, many computer vision and image processing techniques would benefit from automatic discarding of this information at the pre-processing step. In this work we propose novel view on this classical problem via generative end-to-end algorithm, namely image conditioned Generative Adversarial Network. We also demonstrate the potential of the given approach for joint shadow detection and removal. Forced by the lack of training data, we render the largest existing shadow removal dataset and make it publicly available. It consists of approximately 6,000 pairs of wide field of view synthetic images with and without shadows.
Style Mixer: Semantic-aware Multi-Style Transfer Network
Oct 29, 2019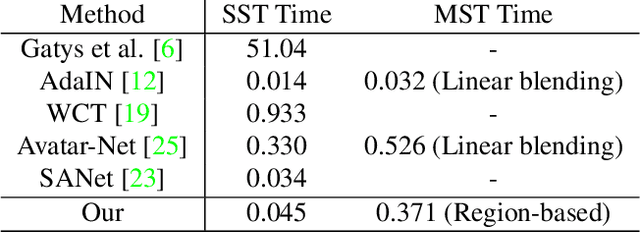
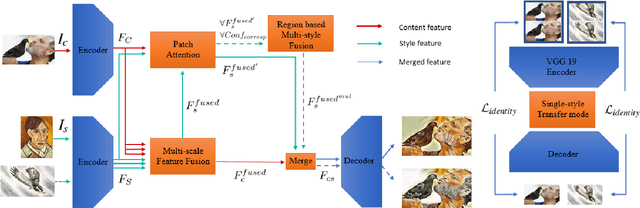
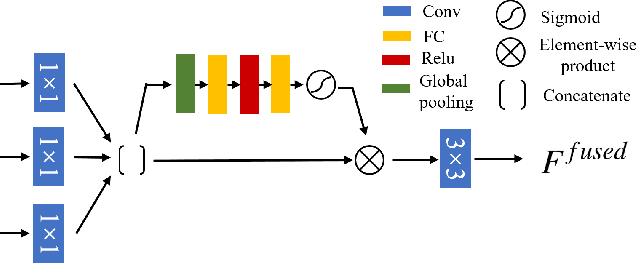

Recent neural style transfer frameworks have obtained astonishing visual quality and flexibility in Single-style Transfer (SST), but little attention has been paid to Multi-style Transfer (MST) which refers to simultaneously transferring multiple styles to the same image. Compared to SST, MST has the potential to create more diverse and visually pleasing stylization results. In this paper, we propose the first MST framework to automatically incorporate multiple styles into one result based on regional semantics. We first improve the existing SST backbone network by introducing a novel multi-level feature fusion module and a patch attention module to achieve better semantic correspondences and preserve richer style details. For MST, we designed a conceptually simple yet effective region-based style fusion module to insert into the backbone. It assigns corresponding styles to content regions based on semantic matching, and then seamlessly combines multiple styles together. Comprehensive evaluations demonstrate that our framework outperforms existing works of SST and MST.
Coverage Testing of Deep Learning Models using Dataset Characterization
Nov 17, 2019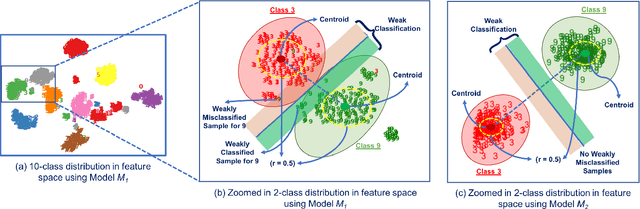
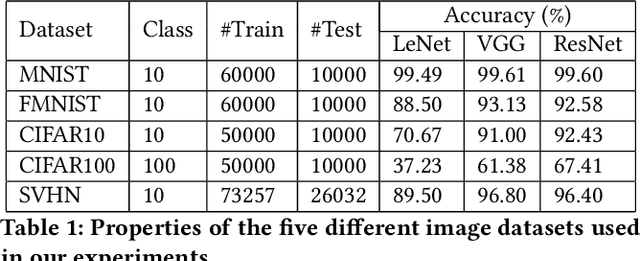
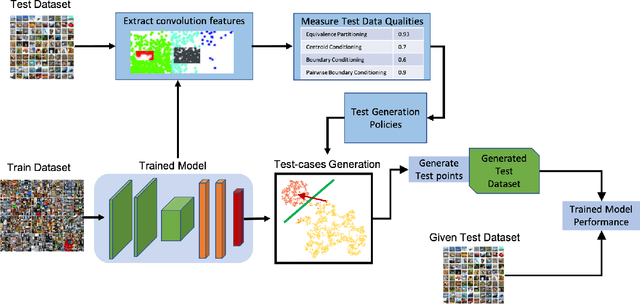
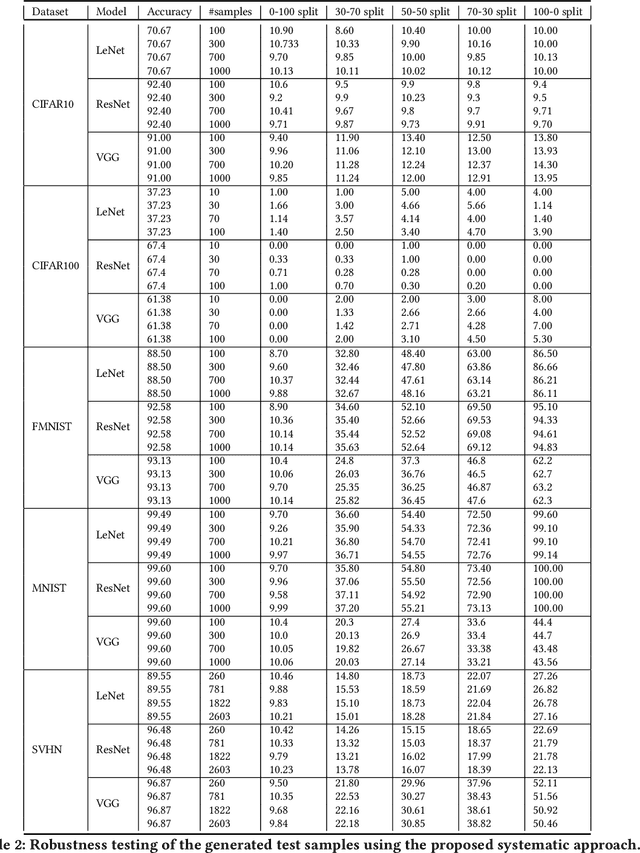
Deep Neural Networks (DNNs), with its promising performance, are being increasingly used in safety critical applications such as autonomous driving, cancer detection, and secure authentication. With growing importance in deep learning, there is a requirement for a more standardized framework to evaluate and test deep learning models. The primary challenge involved in automated generation of extensive test cases are: (i) neural networks are difficult to interpret and debug and (ii) availability of human annotators to generate specialized test points. In this research, we explain the necessity to measure the quality of a dataset and propose a test case generation system guided by the dataset properties. From a testing perspective, four different dataset quality dimensions are proposed: (i) equivalence partitioning, (ii) centroid positioning, (iii) boundary conditioning, and (iv) pair-wise boundary conditioning. The proposed system is evaluated on well known image classification datasets such as MNIST, Fashion-MNIST, CIFAR10, CIFAR100, and SVHN against popular deep learning models such as LeNet, ResNet-20, VGG-19. Further, we conduct various experiments to demonstrate the effectiveness of systematic test case generation system for evaluating deep learning models.
3D-LaneNet: end-to-end 3D multiple lane detection
Nov 27, 2018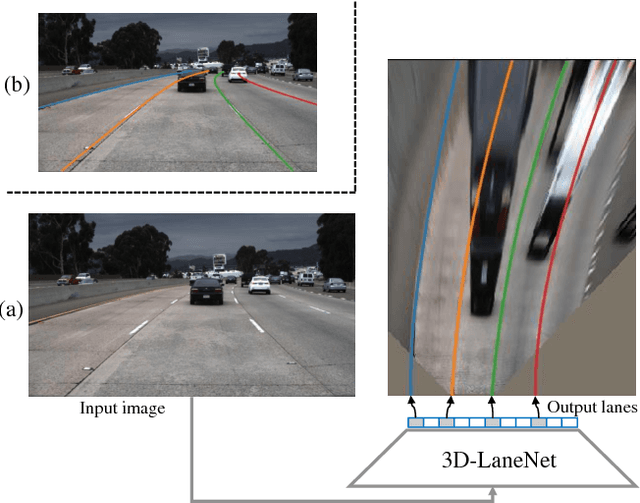
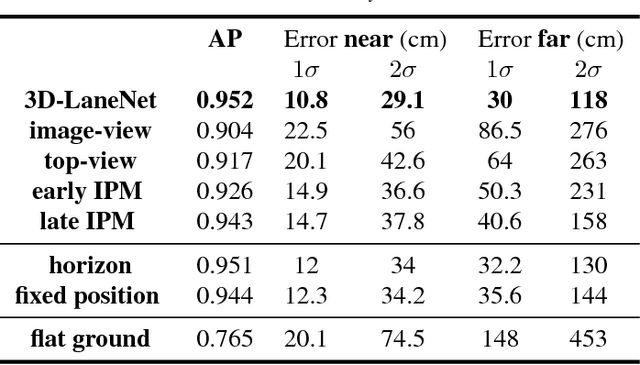
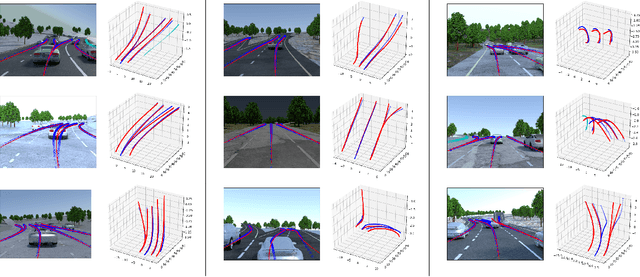

We introduce a network that directly predicts the 3D layout of lanes in a road scene from a single image. This work marks a first attempt to address this task with on-board sensing instead of relying on pre-mapped environments. Our network architecture, 3D-LaneNet, applies two new concepts: intra-network inverse-perspective mapping (IPM) and anchor-based lane representation. The intra-network IPM projection facilitates a dual-representation information flow in both regular image-view and top-view. An anchor-per-column output representation enables our end-to-end approach replacing common heuristics such as clustering and outlier rejection. In addition, our approach explicitly handles complex situations such as lane merges and splits. Promising results are shown on a new 3D lane synthetic dataset. For comparison with existing methods, we verify our approach on the image-only tuSimple lane detection benchmark and reach competitive performance.
Adversarial reconstruction for Multi-modal Machine Translation
Oct 07, 2019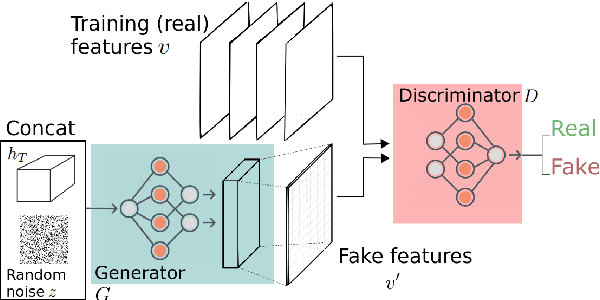
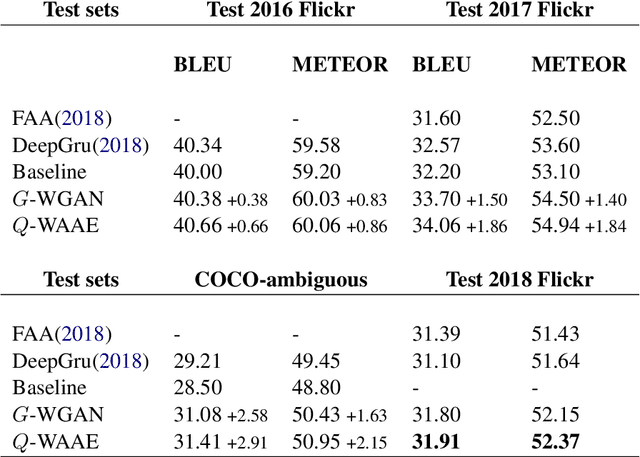
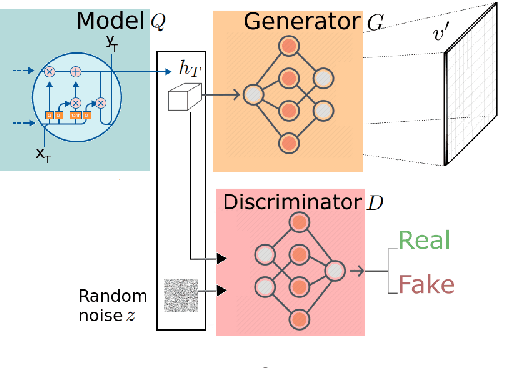
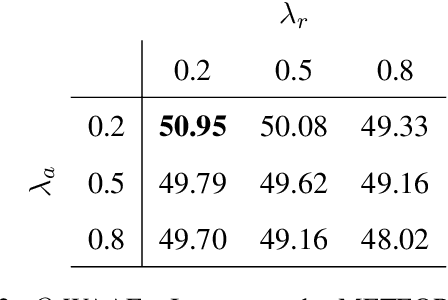
Even with the growing interest in problems at the intersection of Computer Vision and Natural Language, grounding (i.e. identifying) the components of a structured description in an image still remains a challenging task. This contribution aims to propose a model which learns grounding by reconstructing the visual features for the Multi-modal translation task. Previous works have partially investigated standard approaches such as regression methods to approximate the reconstruction of a visual input. In this paper, we propose a different and novel approach which learns grounding by adversarial feedback. To do so, we modulate our network following the recent promising adversarial architectures and evaluate how the adversarial response from a visual reconstruction as an auxiliary task helps the model in its learning. We report the highest scores in term of BLEU and METEOR metrics on the different datasets.
A framework for the extraction of Deep Neural Networks by leveraging public data
May 22, 2019


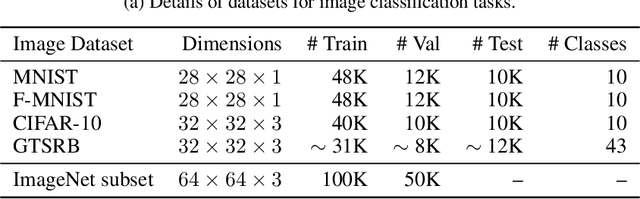
Machine learning models trained on confidential datasets are increasingly being deployed for profit. Machine Learning as a Service (MLaaS) has made such models easily accessible to end-users. Prior work has developed model extraction attacks, in which an adversary extracts an approximation of MLaaS models by making black-box queries to it. However, none of these works is able to satisfy all the three essential criteria for practical model extraction: (1) the ability to work on deep learning models, (2) the non-requirement of domain knowledge and (3) the ability to work with a limited query budget. We design a model extraction framework that makes use of active learning and large public datasets to satisfy them. We demonstrate that it is possible to use this framework to steal deep classifiers trained on a variety of datasets from image and text domains. By querying a model via black-box access for its top prediction, our framework improves performance on an average over a uniform noise baseline by 4.70x for image tasks and 2.11x for text tasks respectively, while using only 30% (30,000 samples) of the public dataset at its disposal.
CNNTOP: a CNN-based Trajectory Owner Prediction Method
Jan 05, 2020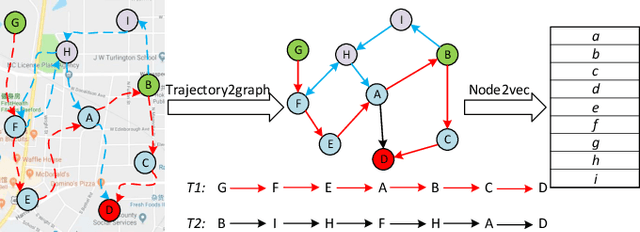
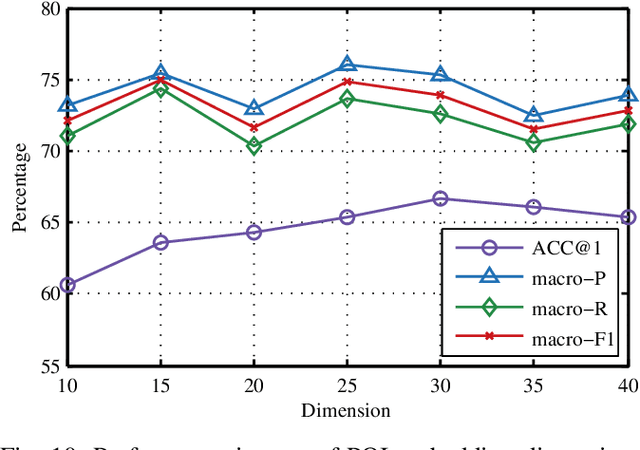
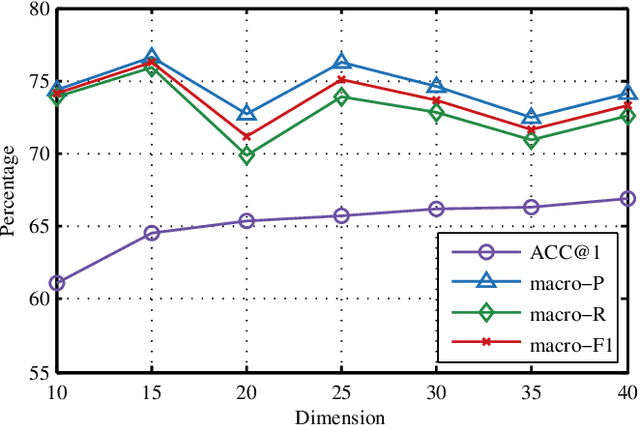
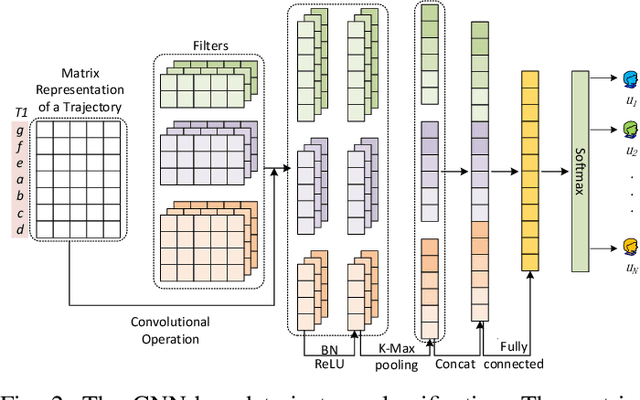
Trajectory owner prediction is the basis for many applications such as personalized recommendation, urban planning. Although much effort has been put on this topic, the results archived are still not good enough. Existing methods mainly employ RNNs to model trajectories semantically due to the inherent sequential attribute of trajectories. However, these approaches are weak at Point of Interest (POI) representation learning and trajectory feature detection. Thus, the performance of existing solutions is far from the requirements of practical applications. In this paper, we propose a novel CNN-based Trajectory Owner Prediction (CNNTOP) method. Firstly, we connect all POI according to trajectories from all users. The result is a connected graph that can be used to generate more informative POI sequences than other approaches. Secondly, we employ the Node2Vec algorithm to encode each POI into a low-dimensional real value vector. Then, we transform each trajectory into a fixed-dimensional matrix, which is similar to an image. Finally, a CNN is designed to detect features and predict the owner of a given trajectory. The CNN can extract informative features from the matrix representations of trajectories by convolutional operations, Batch normalization, and $K$-max pooling operations. Extensive experiments on real datasets demonstrate that CNNTOP substantially outperforms existing solutions in terms of macro-Precision, macro-Recall, macro-F1, and accuracy.