 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Collective Learning
Dec 05, 2019
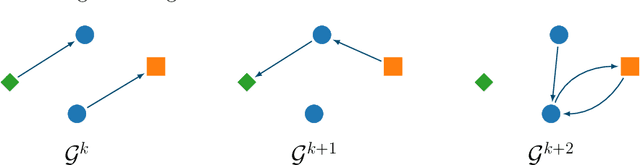
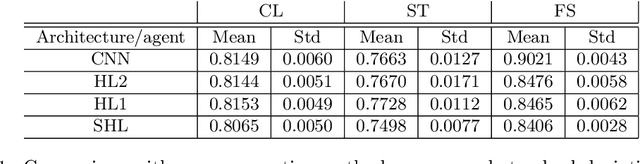
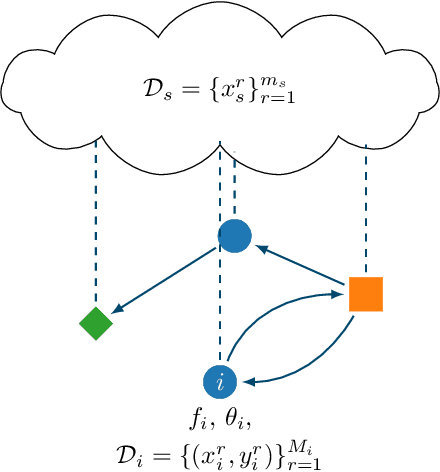
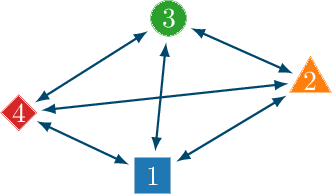
In this paper, we introduce the concept of collective learning (CL) which exploits the notion of collective intelligence in the field of distributed semi-supervised learning. The proposed framework draws inspiration from the learning behavior of human beings, who alternate phases involving collaboration, confrontation and exchange of views with other consisting of studying and learning on their own. On this regard, CL comprises two main phases: a self-training phase in which learning is performed on local private (labeled) data only and a collective training phase in which proxy-labels are assigned to shared (unlabeled) data by means of a consensus-based algorithm. In the considered framework, heterogeneous systems can be connected over the same network, each with different computational capabilities and resources and everyone in the network may take advantage of the cooperation and will eventually reach higher performance with respect to those it can reach on its own. An extensive experimental campaign on an image classification problem emphasizes the properties of CL by analyzing the performance achieved by the cooperating agents.
Weakly Supervised Visual Semantic Parsing
Jan 08, 2020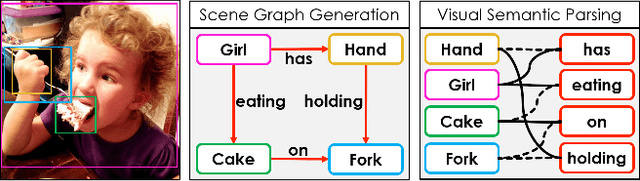
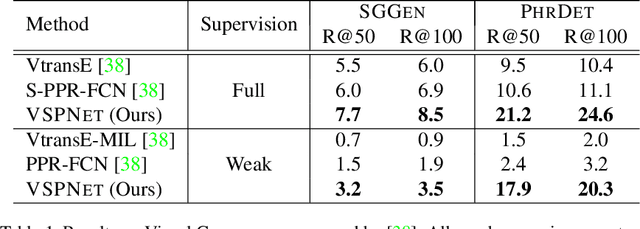
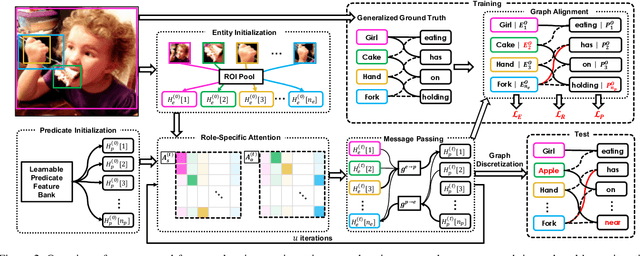
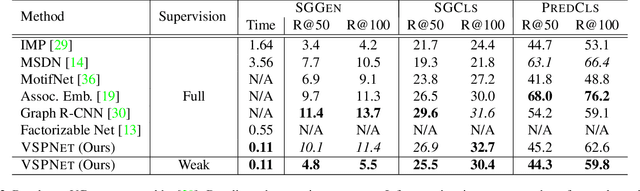
Scene Graph Generation (SGG) aims to extract entities, predicates and their intrinsic structure from images, leading to a deep understanding of visual content, with many potential applications such as visual reasoning and image retrieval. Nevertheless, computer vision is still far from a practical solution for this task. Existing SGG methods require millions of manually annotated bounding boxes for scene graph entities in a large set of images. Moreover, they are computationally inefficient, as they exhaustively process all pairs of object proposals to predict their relationships. In this paper, we address those two limitations by first proposing a generalized formulation of SGG, namely Visual Semantic Parsing, which disentangles entity and predicate prediction, and enables sub-quadratic performance. Then we propose the Visual Semantic Parsing Network, \textsc{VSPNet}, based on a novel three-stage message propagation network, as well as a role-driven attention mechanism to route messages efficiently without a quadratic cost. Finally, we propose the first graph-based weakly supervised learning framework based on a novel graph alignment algorithm, which enables training without bounding box annotations. Through extensive experiments on the Visual Genome dataset, we show \textsc{VSPNet} outperforms weakly supervised baselines significantly and approaches fully supervised performance, while being five times faster.
Training Generative Networks with general Optimal Transport distances
Oct 01, 2019
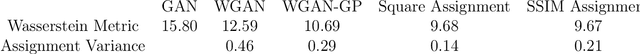
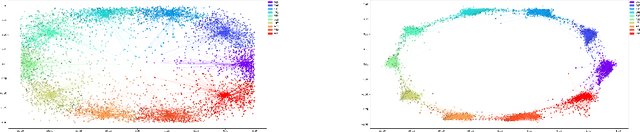
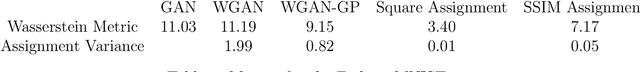
We propose a new algorithm that uses an auxiliary Neural Network to calculate the transport distance between two data distributions and export an optimal transport map. In the sequel we use the aforementioned map to train Generative Networks. Unlike WGANs, where the Euclidean distance is implicitly used, this new method allows to use any transportation cost function that can be chosen to match the problem at hand. More specifically, it allows to use the squared distance as a transportation cost function, giving rise to the Wasserstein-2 metric for probability distributions, which has rich geometric properties that result in fast and stable gradients descends. It also allows to use image centered distances, like the Structure Similarity index, with notable differences in the results.
Multi-task Image Classification via Collaborative, Hierarchical Spike-and-Slab Priors
Jan 30, 2015

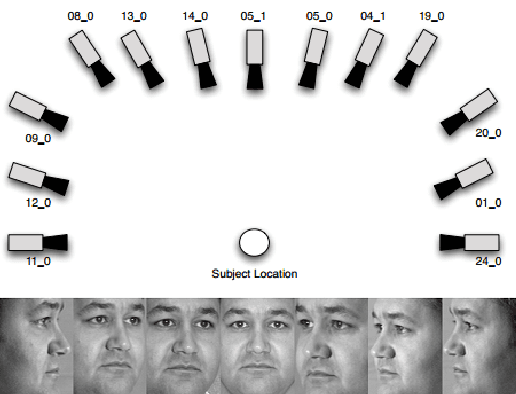
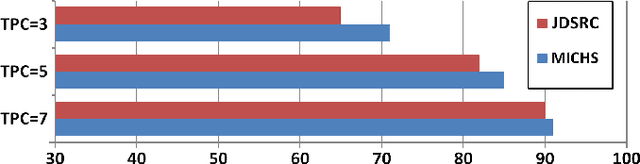
Promising results have been achieved in image classification problems by exploiting the discriminative power of sparse representations for classification (SRC). Recently, it has been shown that the use of \emph{class-specific} spike-and-slab priors in conjunction with the class-specific dictionaries from SRC is particularly effective in low training scenarios. As a logical extension, we build on this framework for multitask scenarios, wherein multiple representations of the same physical phenomena are available. We experimentally demonstrate the benefits of mining joint information from different camera views for multi-view face recognition.
HOG feature extraction from encrypted images for privacy-preserving machine learning
Apr 29, 2019
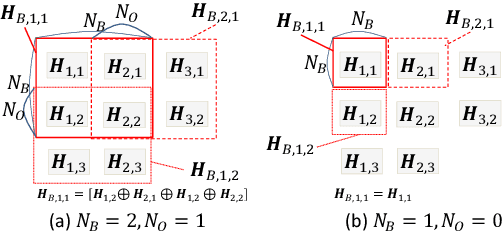

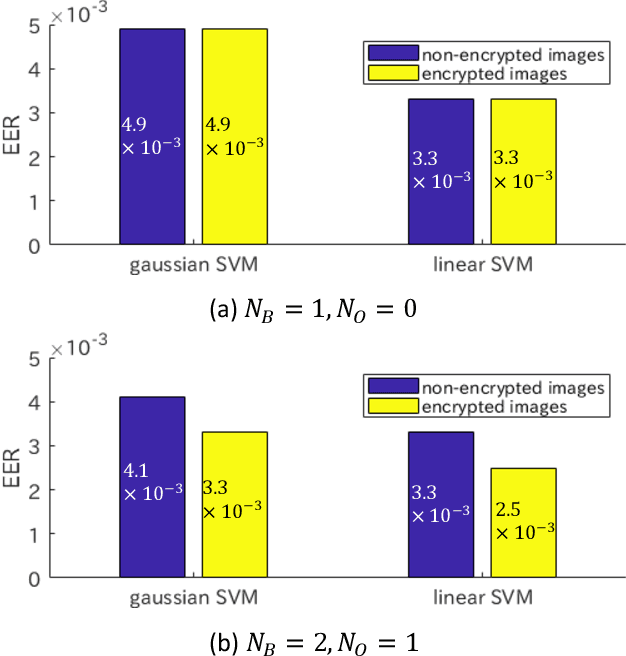
In this paper, we propose an extraction method of HOG (histograms-of-oriented-gradients) features from encryption-then-compression (EtC) images for privacy-preserving machine learning, where EtC images are images encrypted by a block-based encryption method proposed for EtC systems with JPEG compression, and HOG is a feature descriptor used in computer vision for the purpose of object detection and image classification. Recently, cloud computing and machine learning have been spreading in many fields. However, the cloud computing has serious privacy issues for end users, due to unreliability of providers and some accidents. Accordingly, we propose a novel block-based extraction method of HOG features, and the proposed method enables us to carry out any machine learning algorithms without any influence, under some conditions. In an experiment, the proposed method is applied to a face image recognition problem under the use of two kinds of classifiers: linear support vector machine (SVM), gaussian SVM, to demonstrate the effectiveness.
Robust Re-identification of Manta Rays from Natural Markings by Learning Pose Invariant Embeddings
Feb 28, 2019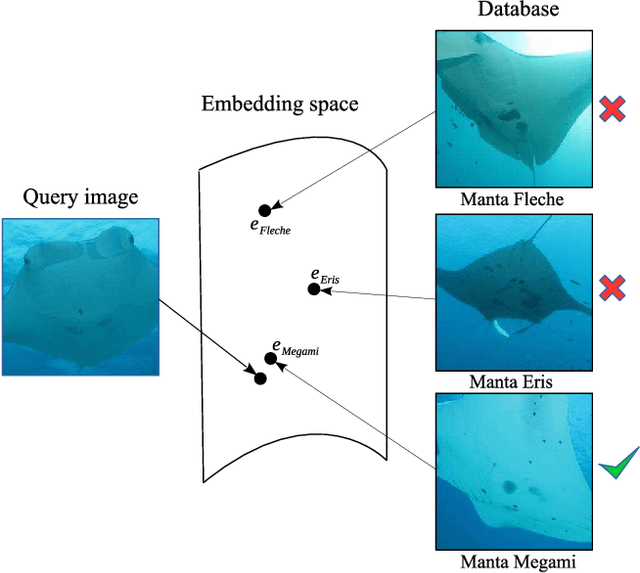
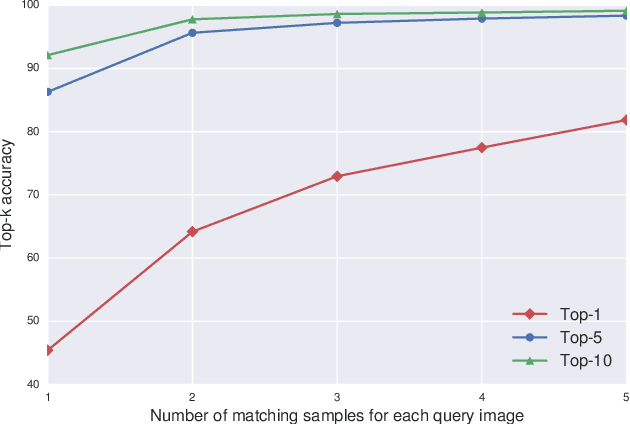


Visual identification of individual animals that bear unique natural body markings is an important task in wildlife conservation. The photo databases of animal markings grow larger and each new observation has to be matched against thousands of images. Existing photo-identification solutions have constraints on image quality and appearance of the pattern of interest in the image. These constraints limit the use of photos from citizen scientists. We present a novel system for visual re-identification based on unique natural markings that is robust to occlusions, viewpoint and illumination changes. We adapt methods developed for face re-identification and implement a deep convolutional neural network (CNN) to learn embeddings for images of natural markings. The distance between the learned embedding points provides a dissimilarity measure between the corresponding input images. The network is optimized using the triplet loss function and the online semi-hard triplet mining strategy. The proposed re-identification method is generic and not species specific. We evaluate the proposed system on image databases of manta ray belly patterns and humpback whale flukes. To be of practical value and adopted by marine biologists, a re-identification system needs to have a top-10 accuracy of at least 95%. The proposed system achieves this performance standard.
Color Constancy by GANs: An Experimental Survey
Dec 07, 2018
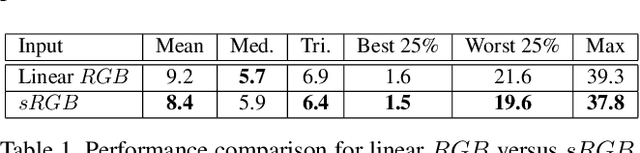
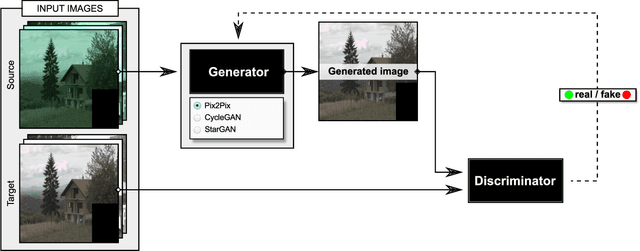
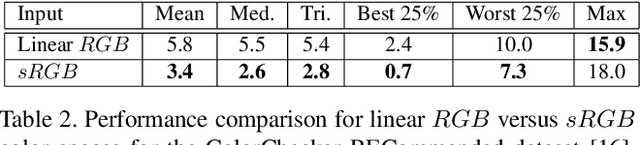
In this paper, we formulate the color constancy task as an image-to-image translation problem using GANs. By conducting a large set of experiments on different datasets, an experimental survey is provided on the use of different types of GANs to solve for color constancy i.e. CC-GANs (Color Constancy GANs). Based on the experimental review, recommendations are given for the design of CC-GAN architectures based on different criteria, circumstances and datasets.
Gated-GAN: Adversarial Gated Networks for Multi-Collection Style Transfer
Apr 04, 2019
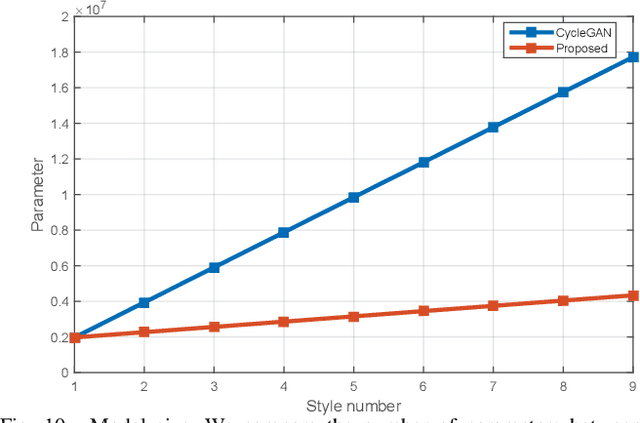


Style transfer describes the rendering of an image semantic content as different artistic styles. Recently, generative adversarial networks (GANs) have emerged as an effective approach in style transfer by adversarially training the generator to synthesize convincing counterfeits. However, traditional GAN suffers from the mode collapse issue, resulting in unstable training and making style transfer quality difficult to guarantee. In addition, the GAN generator is only compatible with one style, so a series of GANs must be trained to provide users with choices to transfer more than one kind of style. In this paper, we focus on tackling these challenges and limitations to improve style transfer. We propose adversarial gated networks (Gated GAN) to transfer multiple styles in a single model. The generative networks have three modules: an encoder, a gated transformer, and a decoder. Different styles can be achieved by passing input images through different branches of the gated transformer. To stabilize training, the encoder and decoder are combined as an autoencoder to reconstruct the input images. The discriminative networks are used to distinguish whether the input image is a stylized or genuine image. An auxiliary classifier is used to recognize the style categories of transferred images, thereby helping the generative networks generate images in multiple styles. In addition, Gated GAN makes it possible to explore a new style by investigating styles learned from artists or genres. Our extensive experiments demonstrate the stability and effectiveness of the proposed model for multistyle transfer.
Improved Exploration through Latent Trajectory Optimization in Deep Deterministic Policy Gradient
Nov 15, 2019

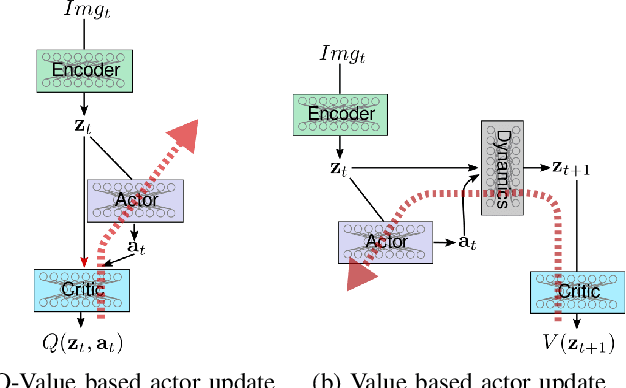
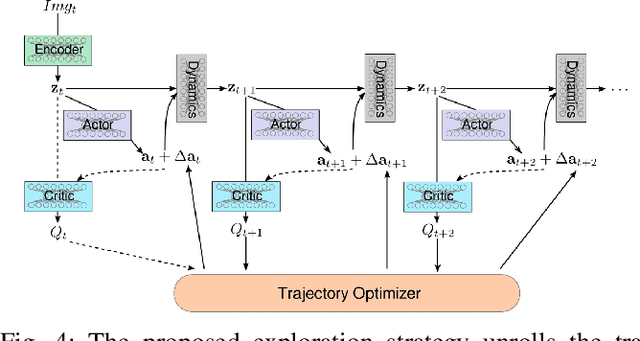
Model-free reinforcement learning algorithms such as Deep Deterministic Policy Gradient (DDPG) often require additional exploration strategies, especially if the actor is of deterministic nature. This work evaluates the use of model-based trajectory optimization methods used for exploration in Deep Deterministic Policy Gradient when trained on a latent image embedding. In addition, an extension of DDPG is derived using a value function as critic, making use of a learned deep dynamics model to compute the policy gradient. This approach leads to a symbiotic relationship between the deep reinforcement learning algorithm and the latent trajectory optimizer. The trajectory optimizer benefits from the critic learned by the RL algorithm and the latter from the enhanced exploration generated by the planner. The developed methods are evaluated on two continuous control tasks, one in simulation and one in the real world. In particular, a Baxter robot is trained to perform an insertion task, while only receiving sparse rewards and images as observations from the environment.
On-the-fly Prediction of Protein Hydration Densities and Free Energies using Deep Learning
Jan 07, 2020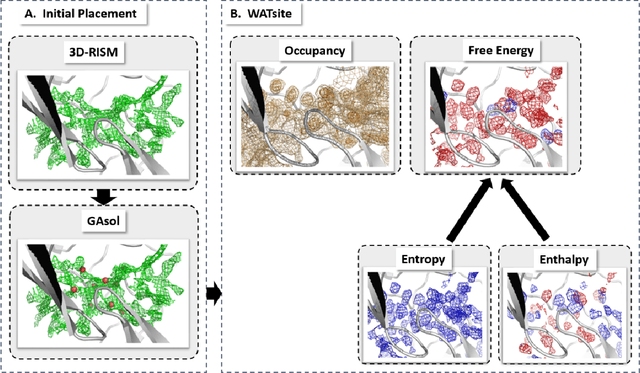
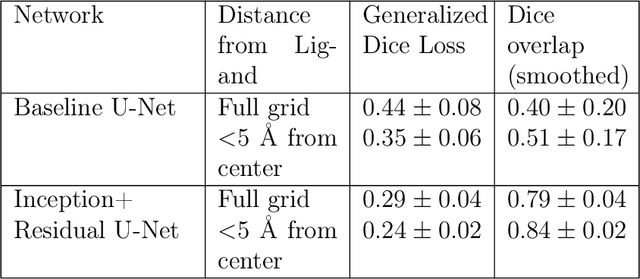
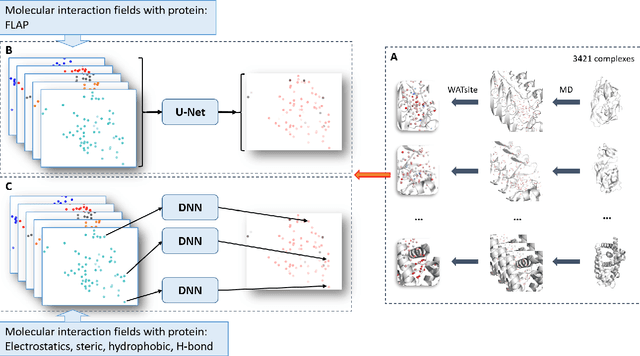
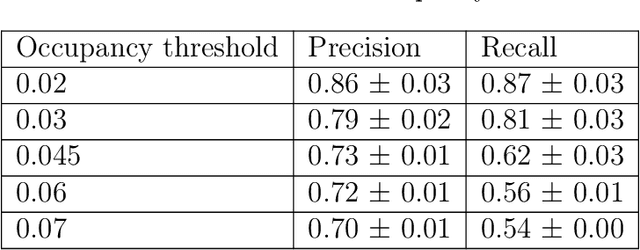
The calculation of thermodynamic properties of biochemical systems typically requires the use of resource-intensive molecular simulation methods. One example thereof is the thermodynamic profiling of hydration sites, i.e. high-probability locations for water molecules on the protein surface, which play an essential role in protein-ligand associations and must therefore be incorporated in the prediction of binding poses and affinities. To replace time-consuming simulations in hydration site predictions, we developed two different types of deep neural-network models aiming to predict hydration site data. In the first approach, meshed 3D images are generated representing the interactions between certain molecular probes placed on regular 3D grids, encompassing the binding pocket, with the static protein. These molecular interaction fields are mapped to the corresponding 3D image of hydration occupancy using a neural network based on an U-Net architecture. In a second approach, hydration occupancy and thermodynamics were predicted point-wise using a neural network based on fully-connected layers. In addition to direct protein interaction fields, the environment of each grid point was represented using moments of a spherical harmonics expansion of the interaction properties of nearby grid points. Application to structure-activity relationship analysis and protein-ligand pose scoring demonstrates the utility of the predicted hydration information.