 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generalization Bounds for Convolutional Neural Networks
Oct 03, 2019

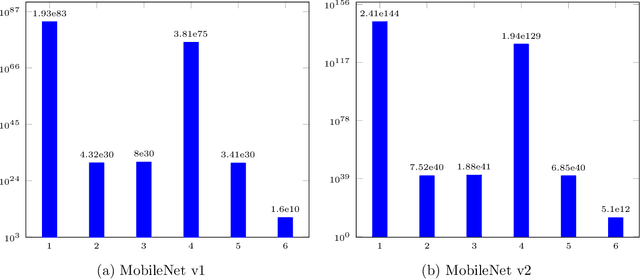
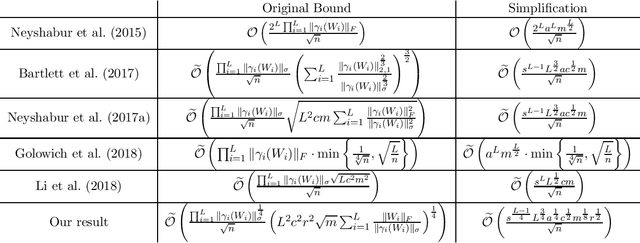
Convolutional neural networks (CNNs) have achieved breakthrough performances in a wide range of applications including image classification, semantic segmentation, and object detection. Previous research on characterizing the generalization ability of neural networks mostly focuses on fully connected neural networks (FNNs), regarding CNNs as a special case of FNNs without taking into account the special structure of convolutional layers. In this work, we propose a tighter generalization bound for CNNs by exploiting the sparse and permutation structure of its weight matrices. As the generalization bound relies on the spectral norm of weight matrices, we further study spectral norms of three commonly used convolution operations including standard convolution, depthwise convolution, and pointwise convolution. Theoretical and experimental results both demonstrate that our bounds for CNNs are tighter than existing bounds.
Unsupervised Learning Methods for Visual Place Recognition in Discretely and Continuously Changing Environments
Jan 24, 2020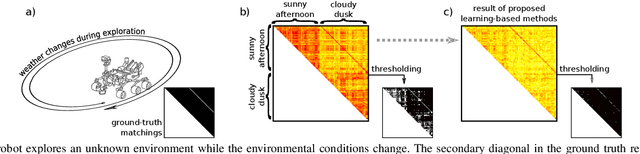
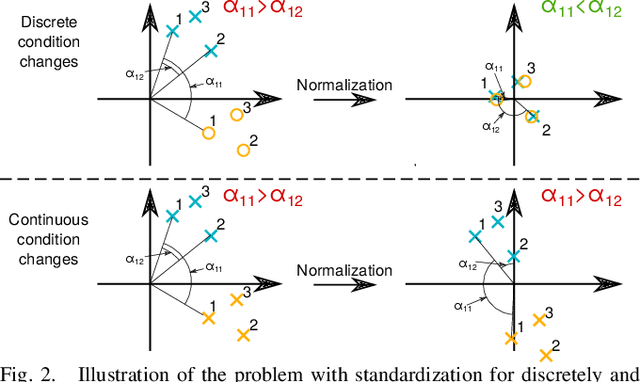
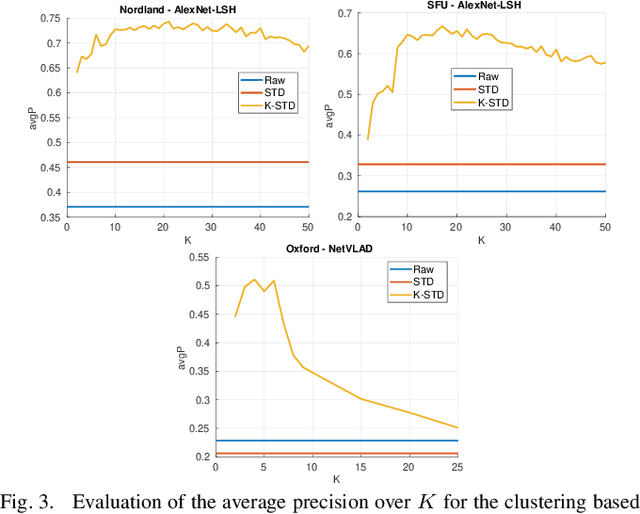
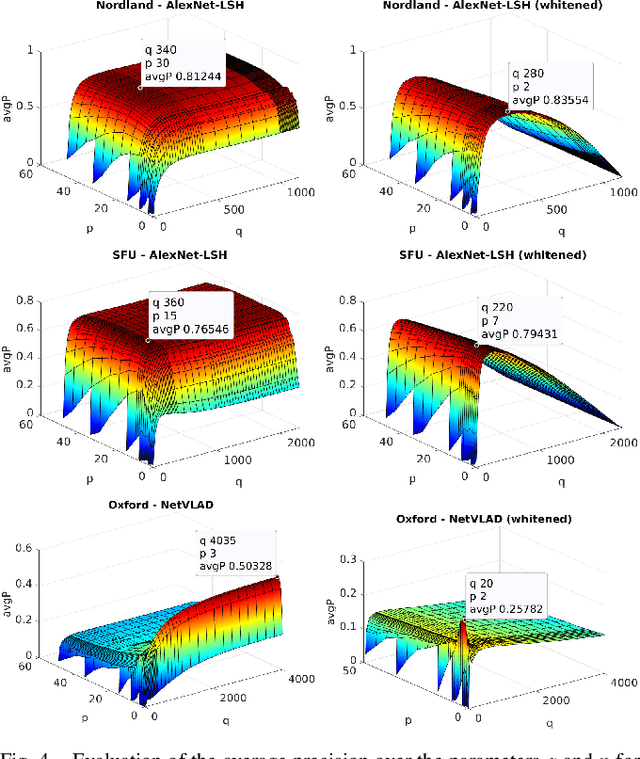
Visual place recognition in changing environments is the problem of finding matchings between two sets of observations, a query set and a reference set, despite severe appearance changes. Recently, image comparison using CNN-based descriptors showed very promising results. However, existing experiments from the literature typically assume a single distinctive condition within each set (e.g., reference: day, query: night). We demonstrate that as soon as the conditions change within one set (e.g., reference: day, query: traversal daytime-dusk-night-dawn), different places under the same condition can suddenly look more similar than same places under different conditions and state-of-the-art approaches like CNN-based descriptors fail. This paper discusses this practically very important problem of in-sequence condition changes and defines a hierarchy of problem setups from (1) no in-sequence changes, (2) discrete in-sequence changes, to (3) continuous in-sequence changes. We will experimentally evaluate the effect of these changes on two state-of-the-art CNN-descriptors. Our experiments emphasize the importance of statistical standardization of descriptors and shows its limitations in case of continuous changes. To address this practically most relevant setup, we investigate and experimentally evaluate the application of unsupervised learning methods using two available PCA-based approaches and propose a novel clustering-based extension of the statistical normalization.
Learning a Unified Embedding for Visual Search at Pinterest
Aug 05, 2019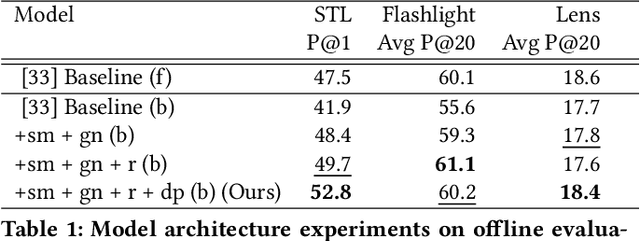

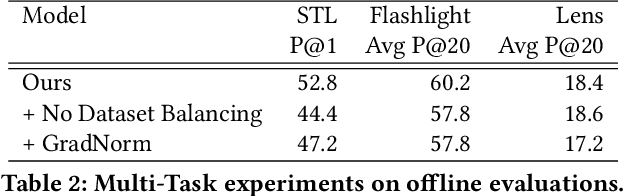
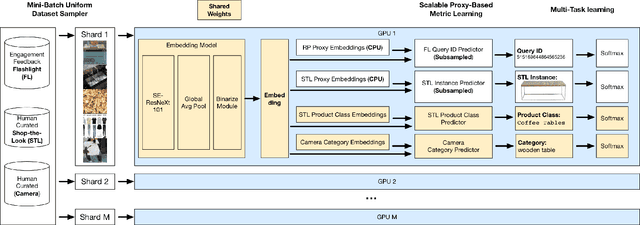
At Pinterest, we utilize image embeddings throughout our search and recommendation systems to help our users navigate through visual content by powering experiences like browsing of related content and searching for exact products for shopping. In this work we describe a multi-task deep metric learning system to learn a single unified image embedding which can be used to power our multiple visual search products. The solution we present not only allows us to train for multiple application objectives in a single deep neural network architecture, but takes advantage of correlated information in the combination of all training data from each application to generate a unified embedding that outperforms all specialized embeddings previously deployed for each product. We discuss the challenges of handling images from different domains such as camera photos, high quality web images, and clean product catalog images. We also detail how to jointly train for multiple product objectives and how to leverage both engagement data and human labeled data. In addition, our trained embeddings can also be binarized for efficient storage and retrieval without compromising precision and recall. Through comprehensive evaluations on offline metrics, user studies, and online A/B experiments, we demonstrate that our proposed unified embedding improves both relevance and engagement of our visual search products for both browsing and searching purposes when compared to existing specialized embeddings. Finally, the deployment of the unified embedding at Pinterest has drastically reduced the operation and engineering cost of maintaining multiple embeddings while improving quality.
Image Deblurring and Super-resolution by Adaptive Sparse Domain Selection and Adaptive Regularization
Dec 06, 2010
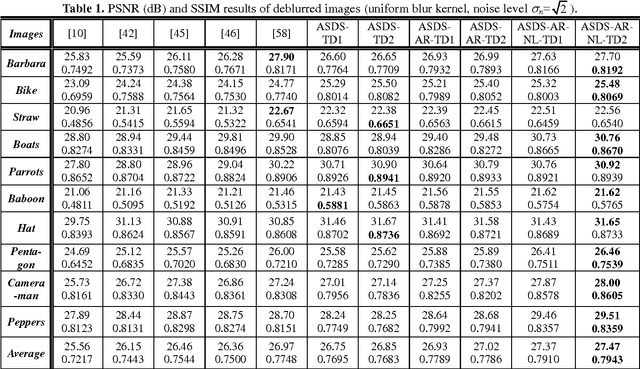

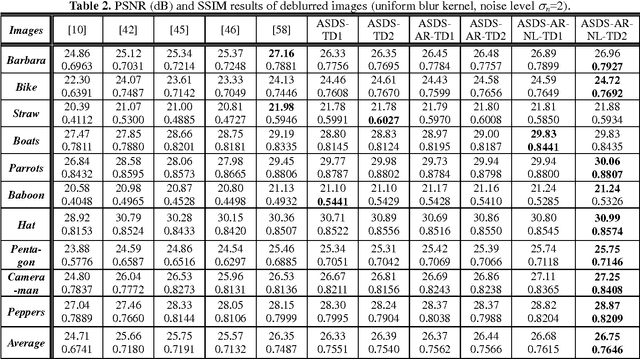
As a powerful statistical image modeling technique, sparse representation has been successfully used in various image restoration applications. The success of sparse representation owes to the development of l1-norm optimization techniques, and the fact that natural images are intrinsically sparse in some domain. The image restoration quality largely depends on whether the employed sparse domain can represent well the underlying image. Considering that the contents can vary significantly across different images or different patches in a single image, we propose to learn various sets of bases from a pre-collected dataset of example image patches, and then for a given patch to be processed, one set of bases are adaptively selected to characterize the local sparse domain. We further introduce two adaptive regularization terms into the sparse representation framework. First, a set of autoregressive (AR) models are learned from the dataset of example image patches. The best fitted AR models to a given patch are adaptively selected to regularize the image local structures. Second, the image non-local self-similarity is introduced as another regularization term. In addition, the sparsity regularization parameter is adaptively estimated for better image restoration performance. Extensive experiments on image deblurring and super-resolution validate that by using adaptive sparse domain selection and adaptive regularization, the proposed method achieves much better results than many state-of-the-art algorithms in terms of both PSNR and visual perception.
Compression of convolutional neural networks for high performance imagematching tasks on mobile devices
Jan 09, 2020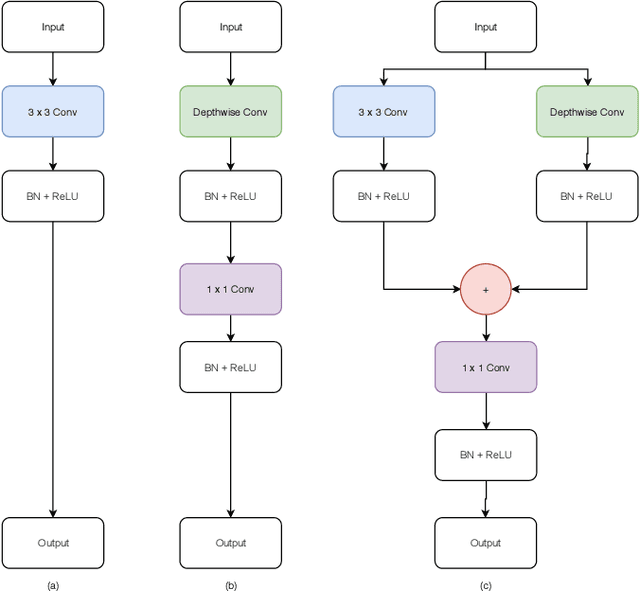
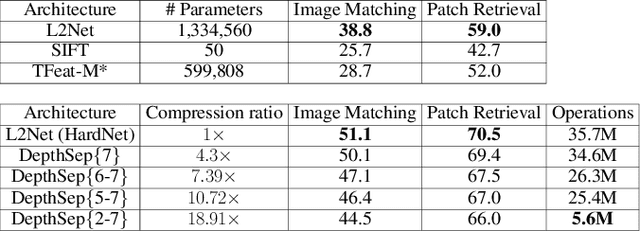
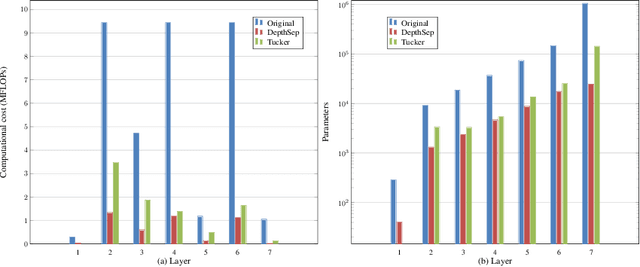
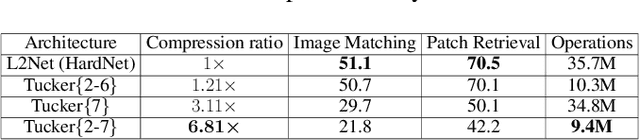
Deep neural networks have demonstrated state-of-the-art performance for feature-based image matching through the advent of new large and diverse datasets. However, there has been little work on evaluating the computational cost, model size, and matching accuracy tradeoffs for these models. This paper explicitly addresses these practical constraints by considering state-of-the-art L2Net architecture. We observe a significant redundancy in the L2Net architecture, which we exploit through the use of depthwise separable layers and an efficient Tucker decomposition. We demonstrate that a combination of these methods is more effective, but still sacrifices the top-end accuracy. We therefore propose the Convolution-Depthwise-Pointwise (CDP) layer, which provides a means of interpolating between the standard and depthwise separable convolutions. With this proposed layer, we are able to achieve up to 8 times reduction in the number of parameters on the L2Net architecture, 13 times reduction in the computational complexity, while sacrificing less than 1% on the overall accuracy across the HPatches benchmarks. To further demonstrate the generalisation of this approach, we apply it to the SuperPoint model. We show that CDP layers improve upon the accuracy while using significantly less parameters and floating-point operations for inference.
Improving Robustness of time series classifier with Neural ODE guided gradient based data augmentation
Oct 15, 2019
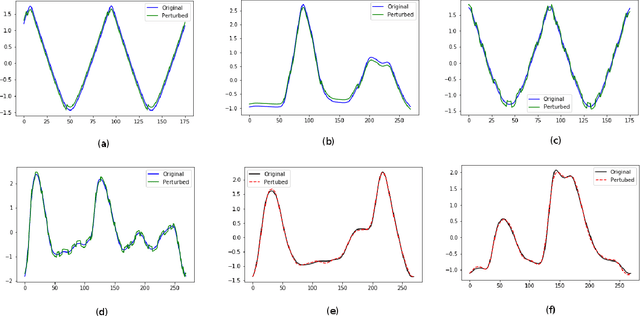
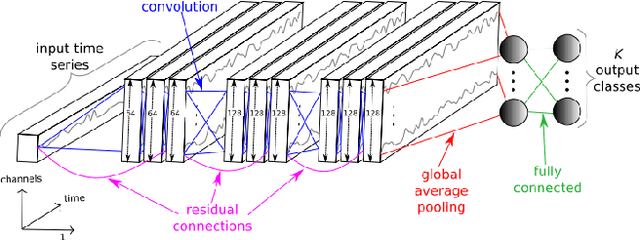
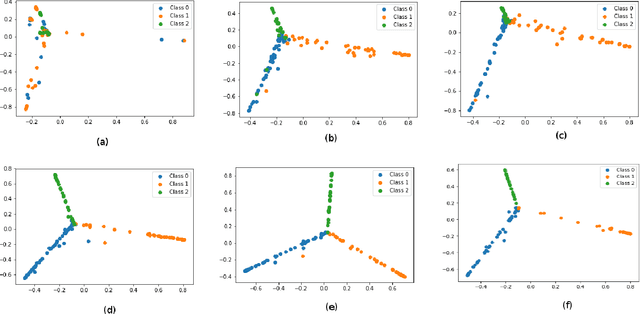
Exploring adversarial attack vectors and studying their effects on machine learning algorithms has been of interest to researchers. Deep neural networks working with time series data have received lesser interest compared to their image counterparts in this context. In a recent finding, it has been revealed that current state-of-the-art deep learning time series classifiers are vulnerable to adversarial attacks. In this paper, we introduce two local gradient based and one spectral density based time series data augmentation techniques. We show that a model trained with data obtained using our techniques obtains state-of-the-art classification accuracy on various time series benchmarks. In addition, it improves the robustness of the model against some of the most common corruption techniques,such as Fast Gradient Sign Method (FGSM) and Basic Iterative Method (BIM).
Real-Time Semantic Segmentation via Multiply Spatial Fusion Network
Nov 17, 2019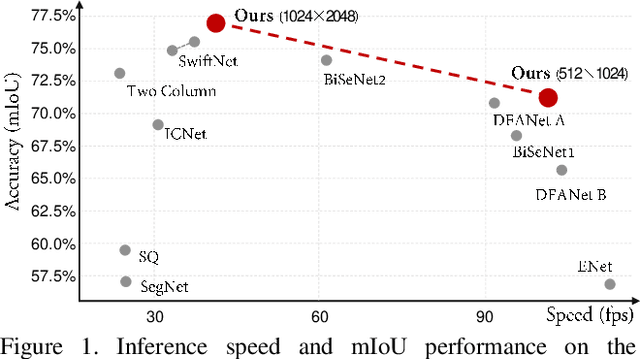
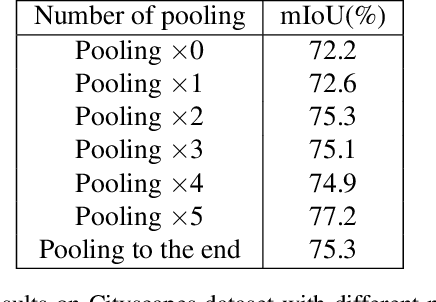
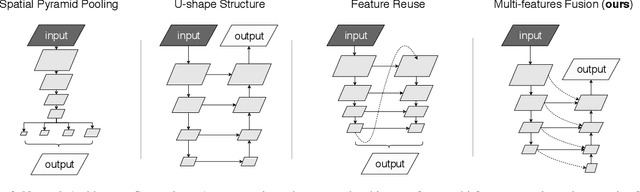

Real-time semantic segmentation plays a significant role in industry applications, such as autonomous driving, robotics and so on. It is a challenging task as both efficiency and performance need to be considered simultaneously. To address such a complex task, this paper proposes an efficient CNN called Multiply Spatial Fusion Network (MSFNet) to achieve fast and accurate perception. The proposed MSFNet uses Class Boundary Supervision to process the relevant boundary information based on our proposed Multi-features Fusion Module which can obtain spatial information and enlarge receptive field. Therefore, the final upsampling of the feature maps of 1/8 original image size can achieve impressive results while maintaining a high speed. Experiments on Cityscapes and Camvid datasets show an obvious advantage of the proposed approach compared with the existing approaches. Specifically, it achieves 77.1% Mean IOU on the Cityscapes test dataset with the speed of 41 FPS for a 1024*2048 input, and 75.4% Mean IOU with the speed of 91 FPS on the Camvid test dataset.
Image Data Compression for Covariance and Histogram Descriptors
May 23, 2015
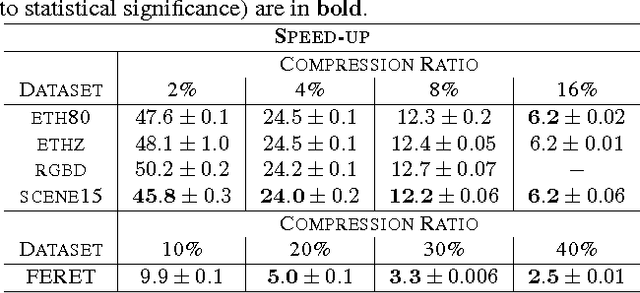
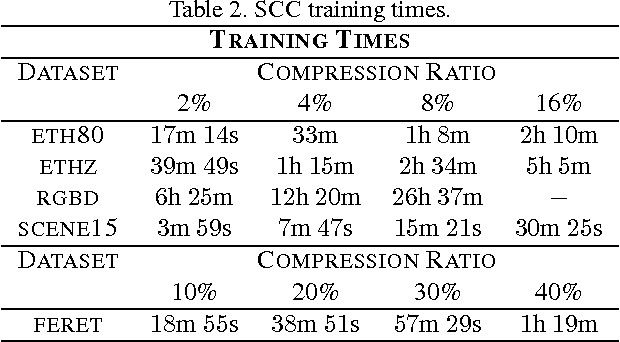
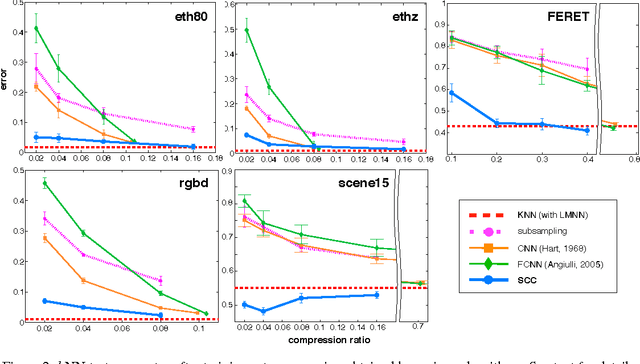
Covariance and histogram image descriptors provide an effective way to capture information about images. Both excel when used in combination with special purpose distance metrics. For covariance descriptors these metrics measure the distance along the non-Euclidean Riemannian manifold of symmetric positive definite matrices. For histogram descriptors the Earth Mover's distance measures the optimal transport between two histograms. Although more precise, these distance metrics are very expensive to compute, making them impractical in many applications, even for data sets of only a few thousand examples. In this paper we present two methods to compress the size of covariance and histogram datasets with only marginal increases in test error for k-nearest neighbor classification. Specifically, we show that we can reduce data sets to 16% and in some cases as little as 2% of their original size, while approximately matching the test error of kNN classification on the full training set. In fact, because the compressed set is learned in a supervised fashion, it sometimes even outperforms the full data set, while requiring only a fraction of the space and drastically reducing test-time computation.
FotonNet: A HW-Efficient Object Detection System Using 3D-Depth Segmentation and 2D-DNN Classifier
Nov 19, 2018
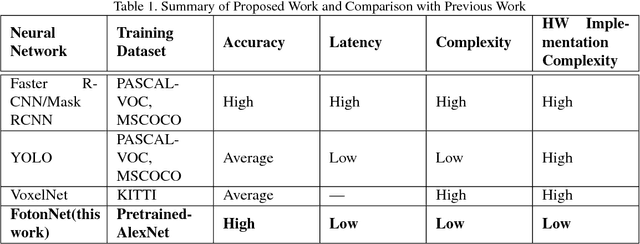
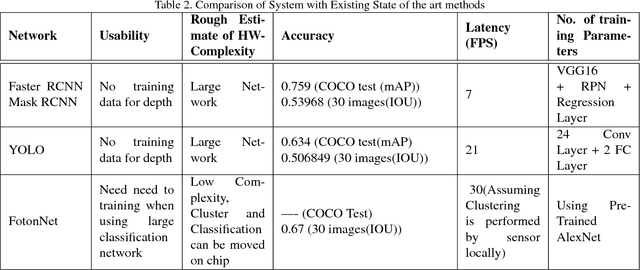
Object detection and classification is one of the most important computer vision problems. Ever since the introduction of deep learning \cite{krizhevsky2012imagenet}, we have witnessed a dramatic increase in the accuracy of this object detection problem. However, most of these improvements have occurred using conventional 2D image processing. Recently, low-cost 3D-image sensors, such as the Microsoft Kinect (Time-of-Flight) or the Apple FaceID (Structured-Light), can provide 3D-depth or point cloud data that can be added to a convolutional neural network, acting as an extra set of dimensions. In our proposed approach, we introduce a new 2D + 3D system that takes the 3D-data to determine the object region followed by any conventional 2D-DNN, such as AlexNet. In this method, our approach can easily dissociate the information collection from the Point Cloud and 2D-Image data and combine both operations later. Hence, our system can use any existing trained 2D network on a large image dataset, and does not require a large 3D-depth dataset for new training. Experimental object detection results across 30 images show an accuracy of 0.67, versus 0.54 and 0.51 for RCNN and YOLO, respectively.
Image Based Fashion Product Recommendation with Deep Learning
Jul 17, 2018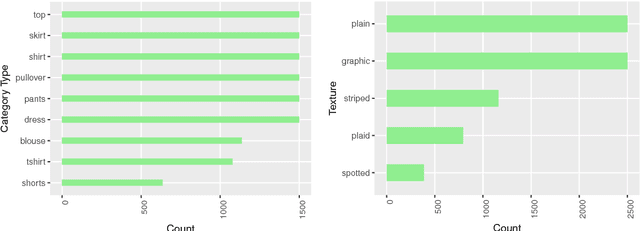
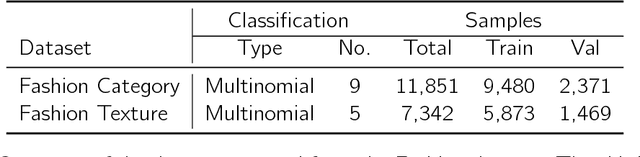
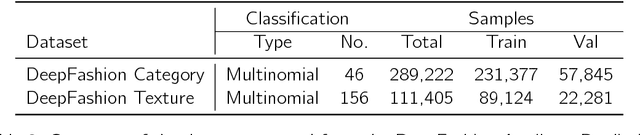
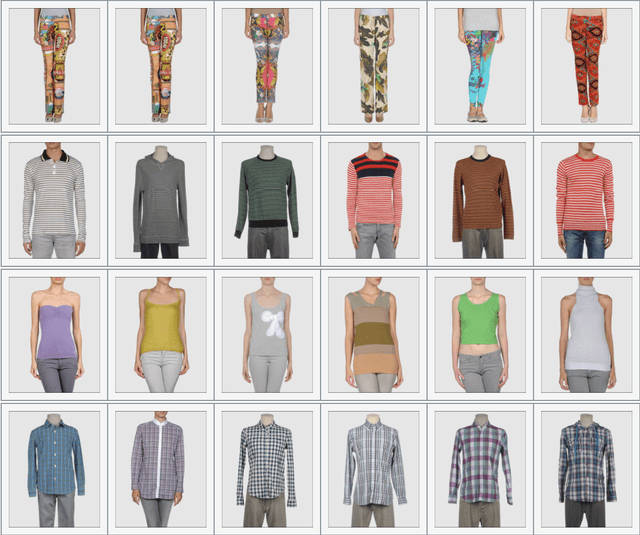
We develop a two-stage deep learning framework that recommends fashion images based on other input images of similar style. For that purpose, a neural network classifier is used as a data-driven, visually-aware feature extractor. The latter then serves as input for similarity-based recommendations using a ranking algorithm. Our approach is tested on the publicly available Fashion dataset. Initialization strategies using transfer learning from larger product databases are presented. Combined with more traditional content-based recommendation systems, our framework can help to increase robustness and performance, for example, by better matching a particular customer style.