 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Localization Using Sparse Semantic 3D Map
Apr 08, 2019
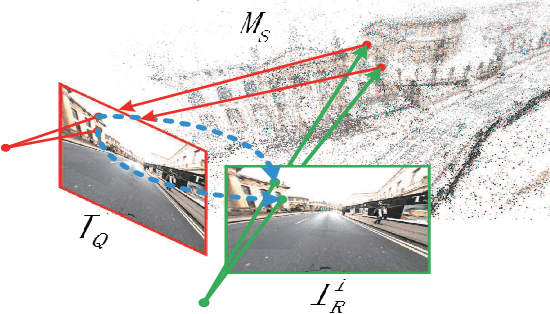

Accurate and robust visual localization under a wide range of viewing condition variations including season and illumination changes, as well as weather and day-night variations, is the key component for many computer vision and robotics applications. Under these conditions, most traditional methods would fail to locate the camera. In this paper we present a visual localization algorithm that combines structure-based method and image-based method with semantic information. Given semantic information about the query and database images, the retrieved images are scored according to the semantic consistency of the 3D model and the query image. Then the semantic matching score is used as weight for RANSAC's sampling and the pose is solved by a standard PnP solver. Experiments on the challenging long-term visual localization benchmark dataset demonstrate that our method has significant improvement compared with the state-of-the-arts.
3D BAT: A Semi-Automatic, Web-based 3D Annotation Toolbox for Full-Surround, Multi-Modal Data Streams
May 01, 2019
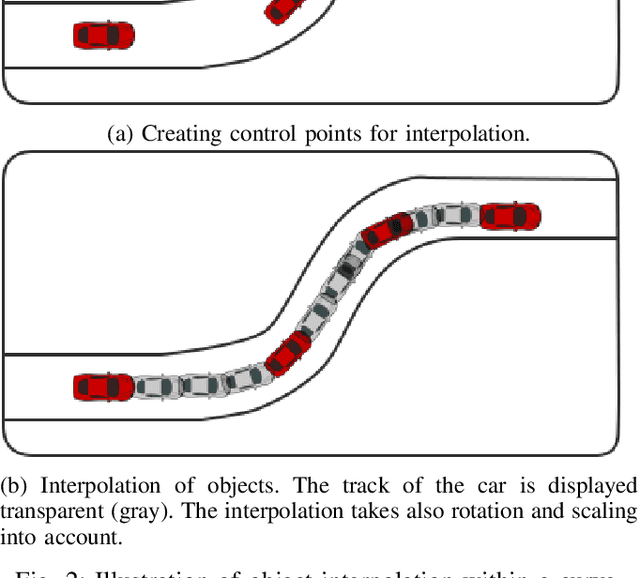
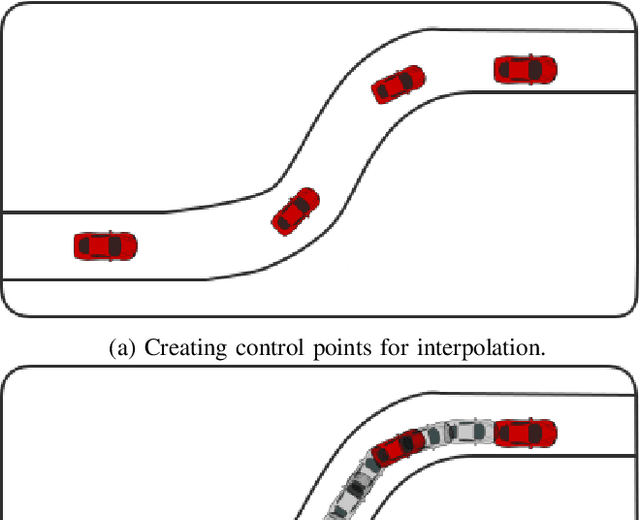

In this paper, we focus on obtaining 2D and 3D labels, as well as track IDs for objects on the road with the help of a novel 3D Bounding Box Annotation Toolbox (3D BAT). Our open source, web-based 3D BAT incorporates several smart features to improve usability and efficiency. For instance, this annotation toolbox supports semi-automatic labeling of tracks using interpolation, which is vital for downstream tasks like tracking, motion planning and motion prediction. Moreover, annotations for all camera images are automatically obtained by projecting annotations from 3D space into the image domain. In addition to the raw image and point cloud feeds, a Masterview consisting of the top view (bird's-eye-view), side view and front views is made available to observe objects of interest from different perspectives. Comparisons of our method with other publicly available annotation tools reveal that 3D annotations can be obtained faster and more efficiently by using our toolbox.
Generating and Exploiting Probabilistic Monocular Depth Estimates
Jun 13, 2019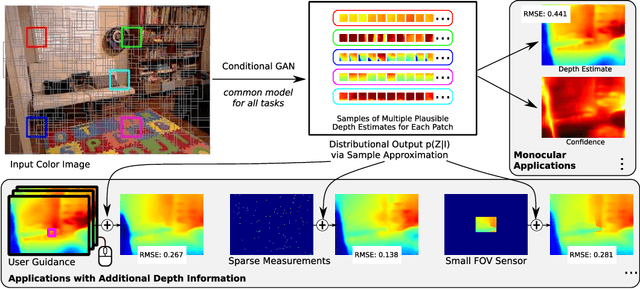
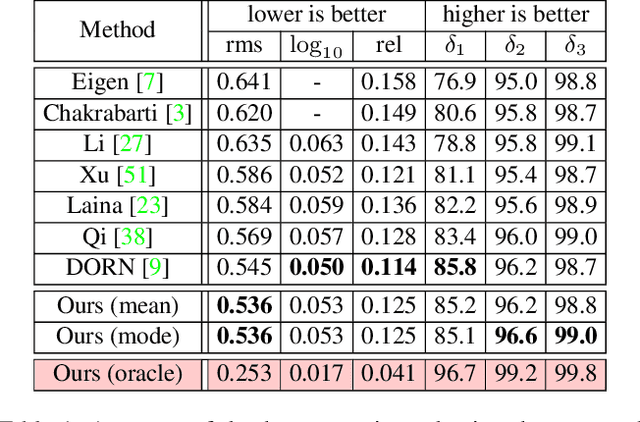
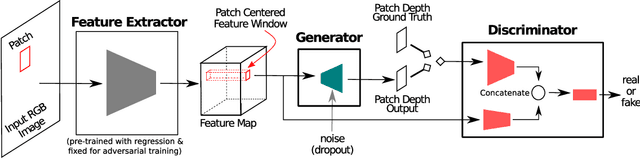
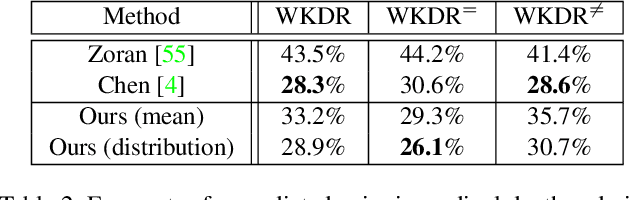
Despite the remarkable success of modern monocular depth estimation methods, the accuracy achievable from a single image is limited, making it is practically useful to incorporate other sources of depth information. Currently, depth estimation from different combinations of sources are treated as different applications, and solved via separate networks trained to use the set of available sources as input for each application. In this paper, we propose a common versatile model that outputs a probability distribution over scene depth given an input color image, as a sample approximation using outputs from a conditional GAN. This distributional output is useful even in the monocular setting, and can be used to estimate depth, pairwise ordering, etc. More importantly, these outputs can be combined with a variety of other depth cues---such as user guidance and partial measurements---for use in different application settings, without retraining. We demonstrate the efficacy of our approach through experiments on the NYUv2 dataset for a number of tasks, and find that our results from a common model, trained only once, are comparable to those from state-of-the-art methods with separate task-specific models.
Learn Stereo, Infer Mono: Siamese Networks for Self-Supervised, Monocular, Depth Estimation
May 01, 2019
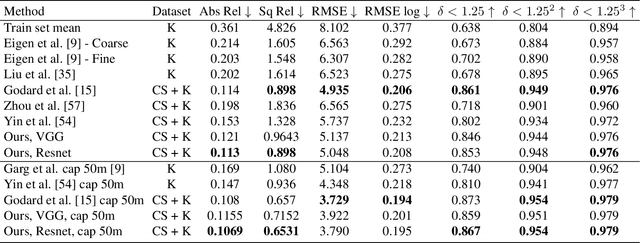
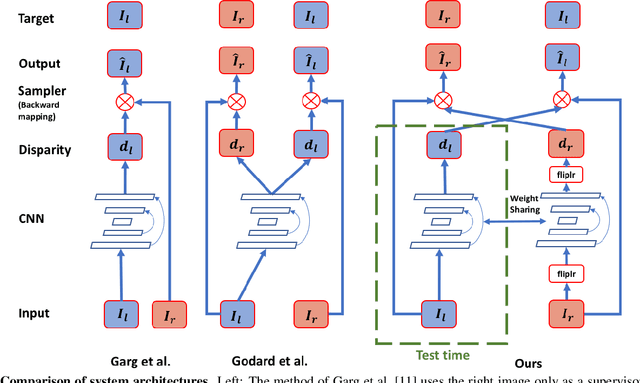
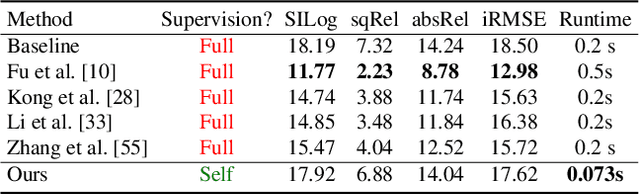
The field of self-supervised monocular depth estimation has seen huge advancements in recent years. Most methods assume stereo data is available during training but usually under-utilize it and only treat it as a reference signal. We propose a novel self-supervised approach which uses both left and right images equally during training, but can still be used with a single input image at test time, for monocular depth estimation. Our Siamese network architecture consists of two, twin networks, each learns to predict a disparity map from a single image. At test time, however, only one of these networks is used in order to infer depth. We show state-of-the-art results on the standard KITTI Eigen split benchmark as well as being the highest scoring self-supervised method on the new KITTI single view benchmark. To demonstrate the ability of our method to generalize to new data sets, we further provide results on the Make3D benchmark, which was not used during training.
MVP: Unified Motion and Visual Self-Supervised Learning for Large-Scale Robotic Navigation
Mar 02, 2020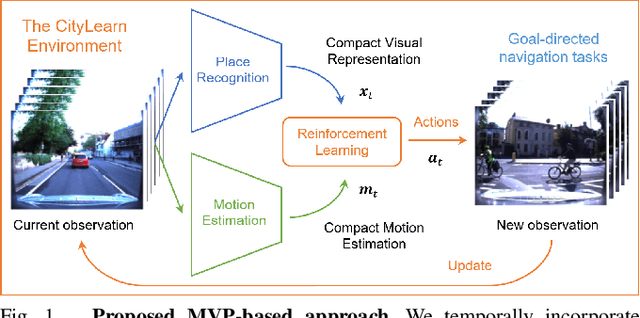
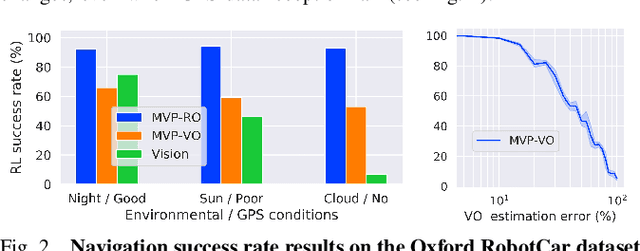

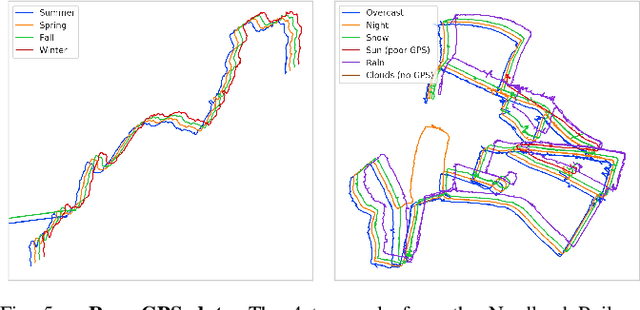
Autonomous navigation emerges from both motion and local visual perception in real-world environments. However, most successful robotic motion estimation methods (e.g. VO, SLAM, SfM) and vision systems (e.g. CNN, visual place recognition-VPR) are often separately used for mapping and localization tasks. Conversely, recent reinforcement learning (RL) based methods for visual navigation rely on the quality of GPS data reception, which may not be reliable when directly using it as ground truth across multiple, month-spaced traversals in large environments. In this paper, we propose a novel motion and visual perception approach, dubbed MVP, that unifies these two sensor modalities for large-scale, target-driven navigation tasks. Our MVP-based method can learn faster, and is more accurate and robust to both extreme environmental changes and poor GPS data than corresponding vision-only navigation methods. MVP temporally incorporates compact image representations, obtained using VPR, with optimized motion estimation data, including but not limited to those from VO or optimized radar odometry (RO), to efficiently learn self-supervised navigation policies via RL. We evaluate our method on two large real-world datasets, Oxford Robotcar and Nordland Railway, over a range of weather (e.g. overcast, night, snow, sun, rain, clouds) and seasonal (e.g. winter, spring, fall, summer) conditions using the new CityLearn framework; an interactive environment for efficiently training navigation agents. Our experimental results, on traversals of the Oxford RobotCar dataset with no GPS data, show that MVP can achieve 53% and 93% navigation success rate using VO and RO, respectively, compared to 7% for a vision-only method. We additionally report a trade-off between the RL success rate and the motion estimation precision.
Simple iterative method for generating targeted universal adversarial perturbations
Nov 18, 2019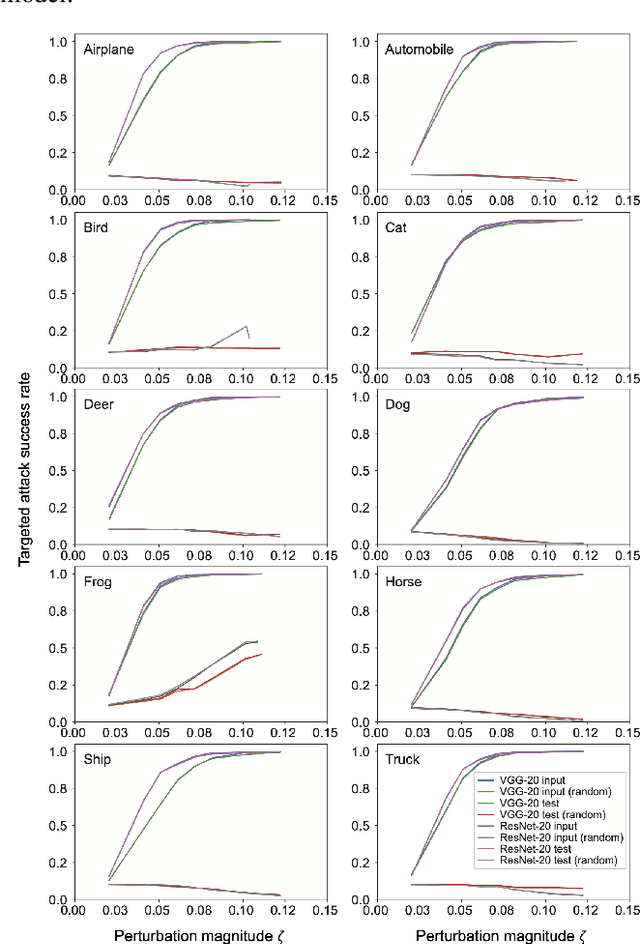
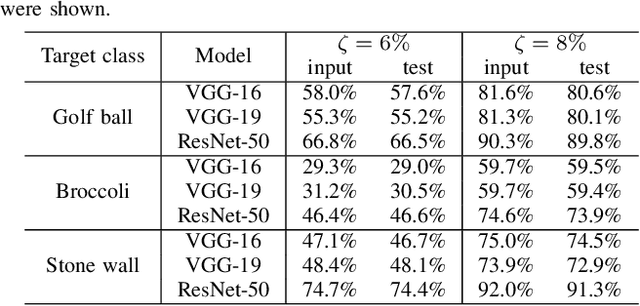
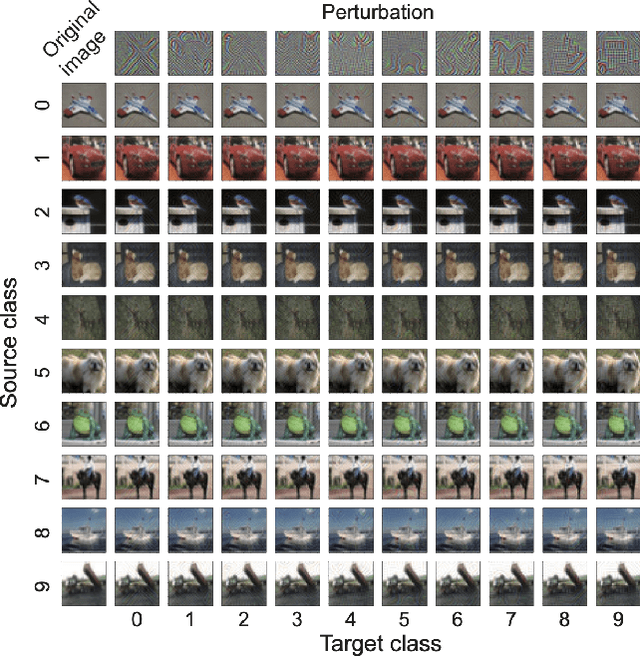
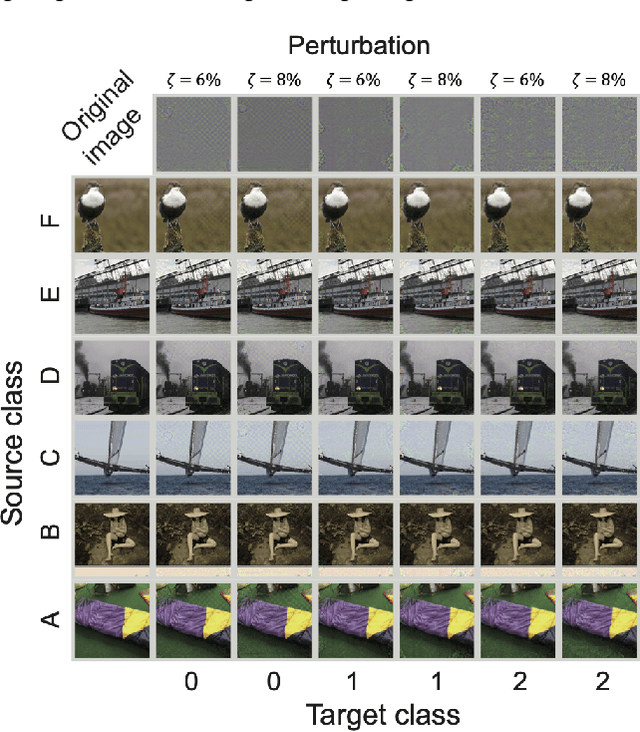
Deep neural networks (DNNs) are vulnerable to adversarial attacks. In particular, a single perturbation known as the universal adversarial perturbation (UAP) can foil most classification tasks conducted by DNNs. Thus, different methods for generating UAPs are required to fully evaluate the vulnerability of DNNs. A realistic evaluation would be with cases that consider targeted attacks; wherein the generated UAP causes DNN to classify an input into a specific class. However, the development of UAPs for targeted attacks has largely fallen behind that of UAPs for non-targeted attacks. Therefore, we propose a simple iterative method to generate UAPs for targeted attacks. Our method combines the simple iterative method for generating non-targeted UAPs and the fast gradient sign method for generating a targeted adversarial perturbation for an input. We applied the proposed method to state-of-the-art DNN models for image classification and proved the existence of almost imperceptible UAPs for targeted attacks; further, we demonstrated that such UAPs are easily generatable.
Large Scale Open-Set Deep Logo Detection
Nov 18, 2019
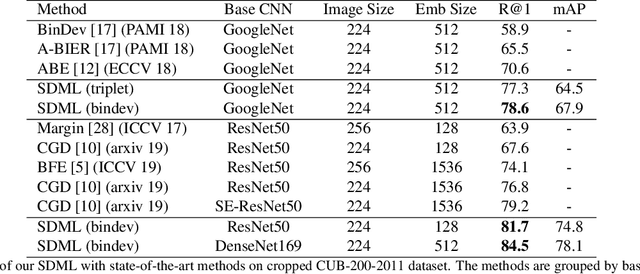

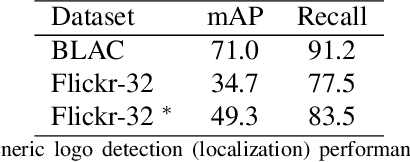
We present an open-set logo detection (OSLD) system, which can detect (localize and recognize) any number of unseen logo classes without re-training; it only requires a small set of canonical logo images for each logo class. We achieve this using a two-stage approach: (1) Generic logo detection to detect candidate logo regions in an image. (2) Logo matching for matching the detected logo regions to a set of canonical logo images to recognize them. We also introduce a 'simple deep metric learning' (SDML) framework that outperformed more complicated ensemble and attention models and boosted the logo matching accuracy. Furthermore, we constructed a new open-set logo detection dataset with thousands of logo classes, and will release it for research purposes. We demonstrate the effectiveness of OSLD on our dataset and on the standard Flickr-32 logo dataset, outperforming the state-of-the-art open-set and closed-set logo detection methods by a large margin.
Illuminant Chromaticity Estimation from Interreflections
Jun 13, 2019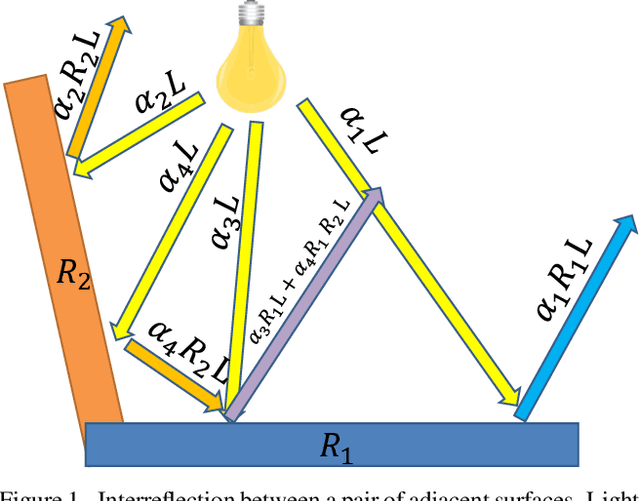
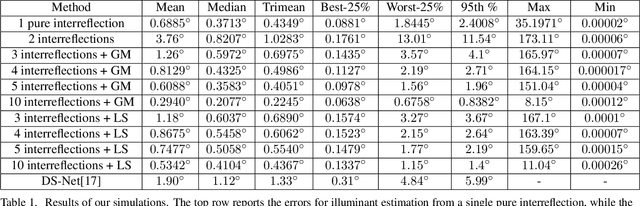
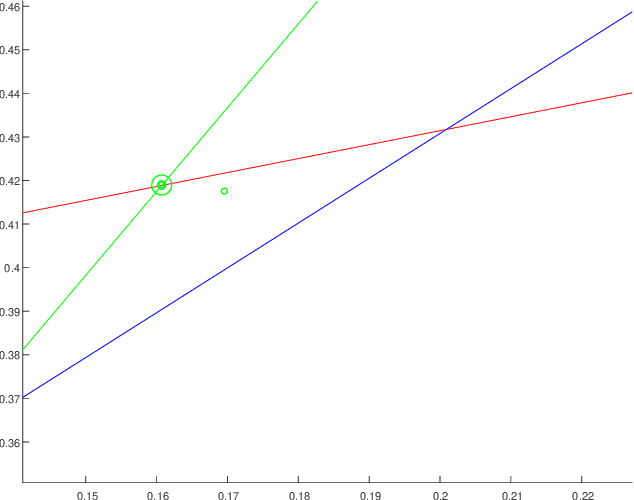
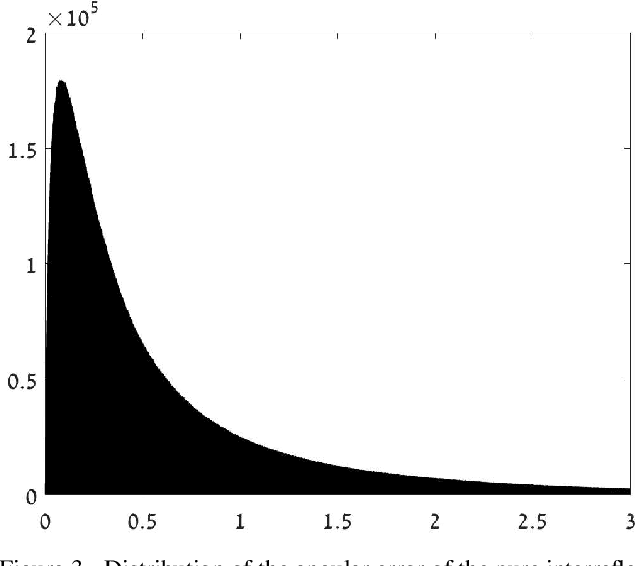
Reliable estimation of illuminant chromaticity is crucial for simulating color constancy and for white balancing digital images. However, estimating illuminant chromaticity from a single image is an ill-posed task, in general, and existing solutions typically employ a variety of assumptions and heuristics. In this paper, we present a new, physically-based, approach for estimating illuminant chromaticity from interreflections of light between diffuse surfaces. Our approach assumes that all of the direct illumination in the scene has the same chromaticity, and that at least two areas where interreflections between Lambertian surfaces occur may be detected in the image. No further assumptions or restrictions on the illuminant chromaticty or the shading in the scene are necessary. Our approach is based on representing interreflections as lines in a special 2D color space, and the chromaticity of the illuminant is estimated from the approximate intersection between two or more such lines. Experimental results are reported on a dataset of illumination and surface reflectance spectra, as well as on real images we captured. The results indicate that our approach can yield state-of-the-art results when the interreflections are significant enough to be captured by the camera.
Optimal HDR and Depth from Dual Cameras
Mar 12, 2020
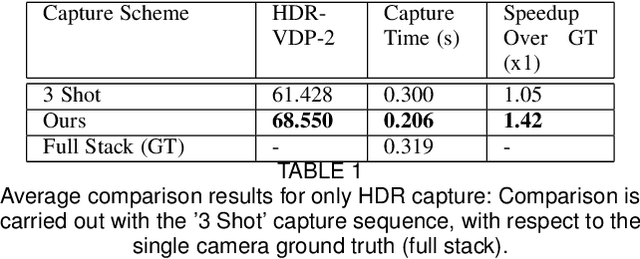
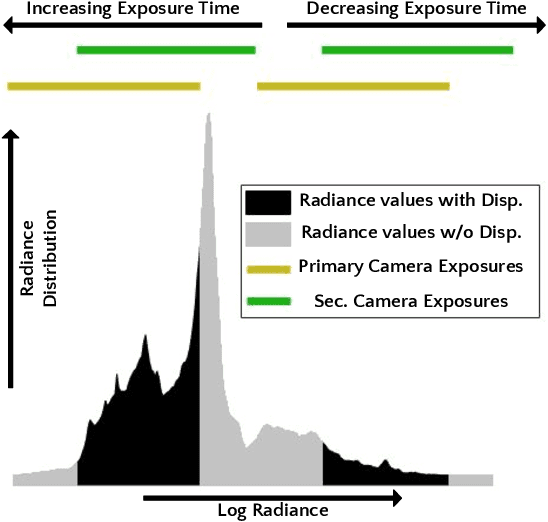
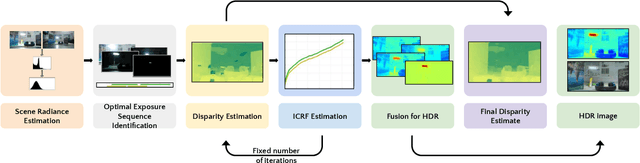
Dual camera systems have assisted in the proliferation of various applications, such as optical zoom, low-light imaging and High Dynamic Range (HDR) imaging. In this work, we explore an optimal method for capturing the scene HDR and disparity map using dual camera setups. Hasinoff et al. (2010) have developed a noise optimal framework for HDR capture from a single camera. We generalize this to the dual camera set-up for estimating both HDR and disparity map. It may seem that dual camera systems can capture HDR in a shorter time. However, disparity estimation is a necessary step, which requires overlap among the images captured by the two cameras. This may lead to an increase in the capture time. To address this conflicting requirement, we propose a novel framework to find the optimal exposure and ISO sequence by minimizing the capture time under the constraints of an upper bound on the disparity error and a lower bound on the per-exposure SNR. We show that the resulting optimization problem is non-convex in general and propose an appropriate initialization technique. To obtain the HDR and disparity map from the optimal capture sequence, we propose a pipeline which alternates between estimating the camera ICRFs and the scene disparity map. We demonstrate that our optimal capture sequence leads to better results than other possible capture sequences. Our results are also close to those obtained by capturing the full stereo stack spanning the entire dynamic range. Finally, we present for the first time a stereo HDR dataset consisting of dense ISO and exposure stack captured from a smartphone dual camera. The dataset consists of 6 scenes, with an average of 142 exposure-ISO image sequence per scene.
A Deep Neural Networks Approach for Pixel-Level Runway Pavement Crack Segmentation Using Drone-Captured Images
Jan 09, 2020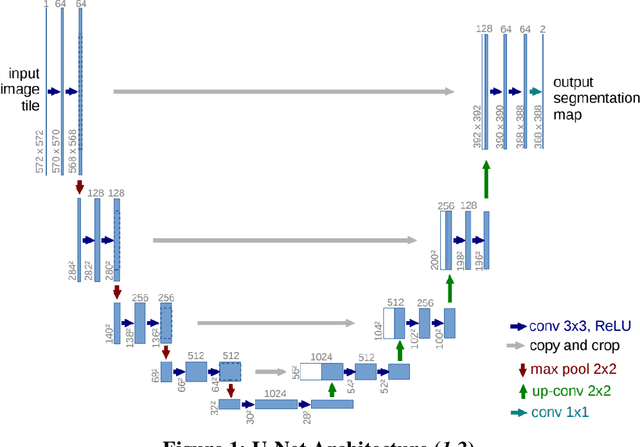

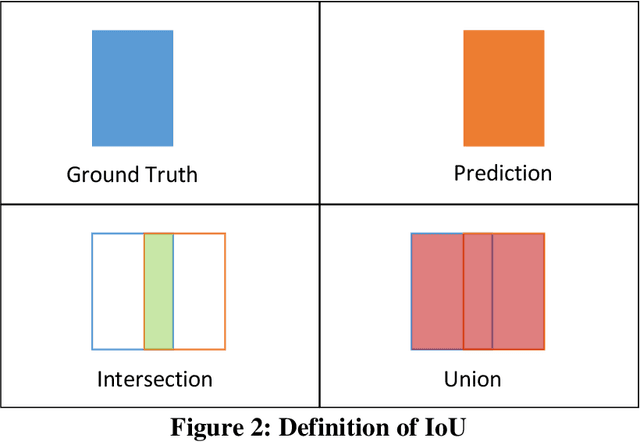

Pavement conditions are a critical aspect of asset management and directly affect safety. This study introduces a deep neural network method called U-Net for pavement crack segmentation based on drone-captured images to reduce the cost and time needed for airport runway inspection. The proposed approach can also be used for highway pavement conditions assessment during off-peak periods when there are few vehicles on the road. In this study, runway pavement images are collected using drone at various heights from the Fitchburg Municipal Airport (FMA) in Massachusetts to evaluate their quality and applicability for crack segmentation, from which an optimal height is determined. Drone images captured at the optimal height are then used to evaluate the crack segmentation performance of the U-Net model. Deep learning methods typically require a huge set of annotated training datasets for model development, which can be a major obstacle for their applications. An online annotated pavement image dataset is used together with the FMA data to train the U-Net model. The results show that U-Net performs well on the FMA testing data even with limited FMA training images, suggesting that it has good generalization ability and great potential to be used for both airport runways and highway pavements.