 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Parallel 3DPIFCM Algorithm for Noisy Brain MRI Images
Feb 05, 2020
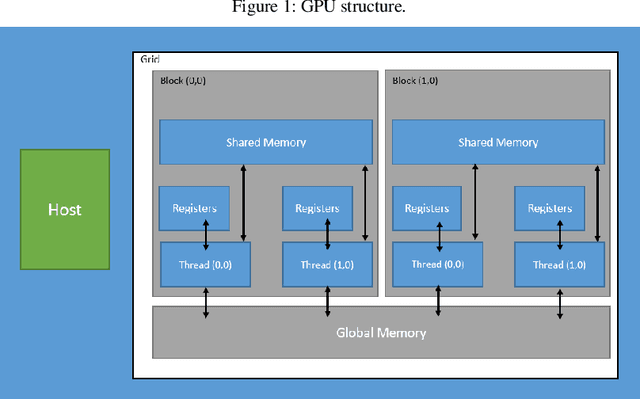
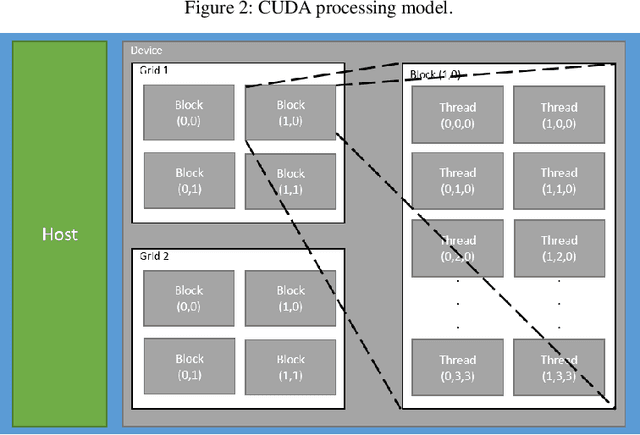
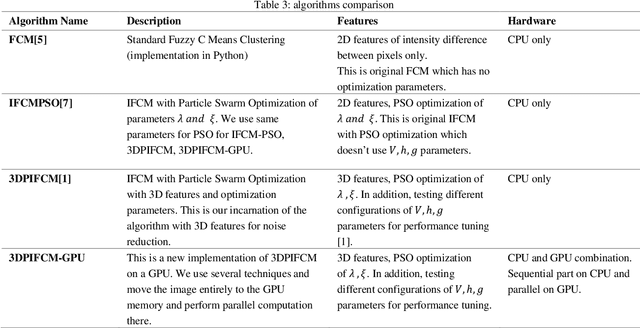
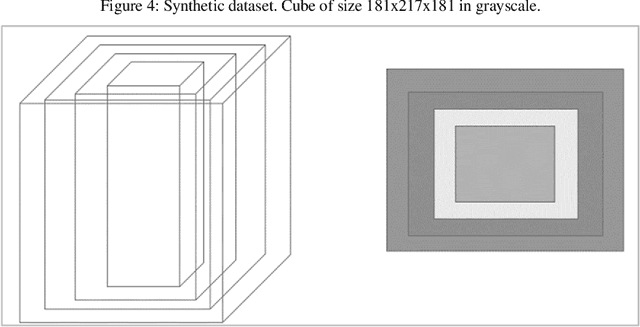
In this paper we implemented the algorithm we developed in [1] called 3DPIFCM in a parallel environment by using CUDA on a GPU. In our previous work we introduced 3DPIFCM which performs segmentation of images in noisy conditions and uses particle swarm optimization for finding the optimal algorithm parameters to account for noise. This algorithm achieved state of the art segmentation accuracy when compared to FCM (Fuzzy C-Means), IFCMPSO (Improved Fuzzy C-Means with Particle Swarm Optimization), GAIFCM (Genetic Algorithm Improved Fuzzy C-Means) on noisy MRI images of an adult Brain. When using a genetic algorithm or PSO (Particle Swarm Optimization) on a single machine for optimization we witnessed long execution times for practical clinical usage. Therefore, in the current paper our goal was to speed up the execution of 3DPIFCM by taking out parts of the algorithm and executing them as kernels on a GPU. The algorithm was implemented using the CUDA [13] framework from NVIDIA and experiments where performed on a server containing 64GB RAM , 8 cores and a TITAN X GPU with 3072 SP cores and 12GB of GPU memory. Our results show that the parallel version of the algorithm performs up to 27x faster than the original sequential version and 68x faster than GAIFCM algorithm. We show that the speedup of the parallel version increases as we increase the size of the image due to better utilization of cores in the GPU. Also, we show a speedup of up to 5x in our Brainweb experiment compared to other generic variants such as IFCMPSO and GAIFCM.
Scalability in Perception for Autonomous Driving: An Open Dataset Benchmark
Dec 10, 2019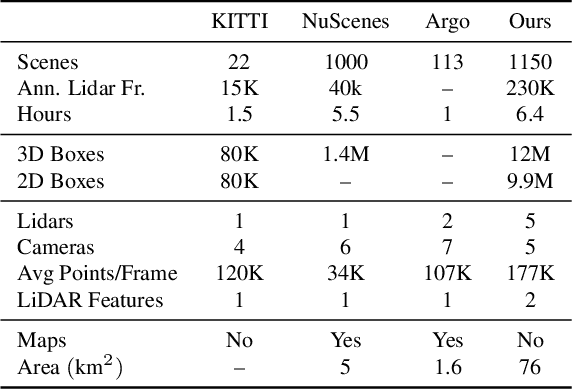
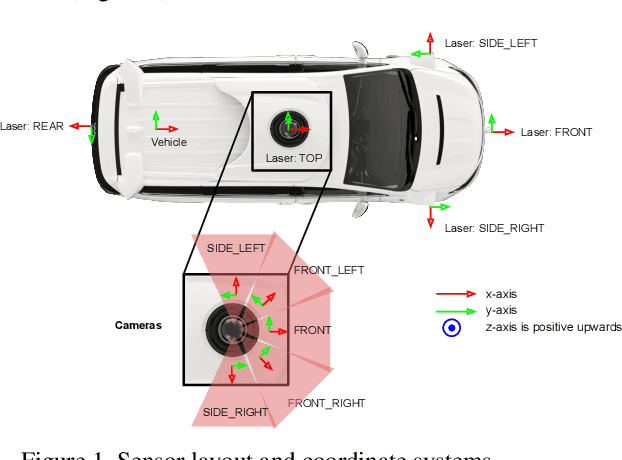

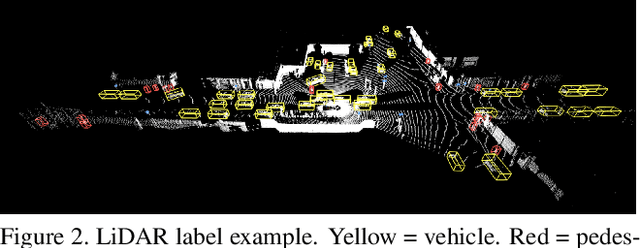
The research community has increasing interest in autonomous driving research, despite the resource intensity of obtaining representative real world data. Existing self-driving datasets are limited in the scale and variation of the environments they capture, even though generalization within and between operating regions is crucial to the overall viability of the technology. In an effort to help align the research community's contributions with real-world self-driving problems, we introduce a new large scale, high quality, diverse dataset. Our new dataset consists of 1150 scenes that each span 20 seconds, consisting of well synchronized and calibrated high quality LiDAR and camera data captured across a range of urban and suburban geographies. It is 15x more diverse than the largest camera+LiDAR dataset available based on our proposed diversity metric. We exhaustively annotated this data with 2D (camera image) and 3D (LiDAR) bounding boxes, with consistent identifiers across frames. Finally, we provide strong baselines for 2D as well as 3D detection and tracking tasks. We further study the effects of dataset size and generalization across geographies on 3D detection methods. Find data, code and more up-to-date information at http://www.waymo.com/open.
Enhancing Cross-task Black-Box Transferability of Adversarial Examples with Dispersion Reduction
Nov 22, 2019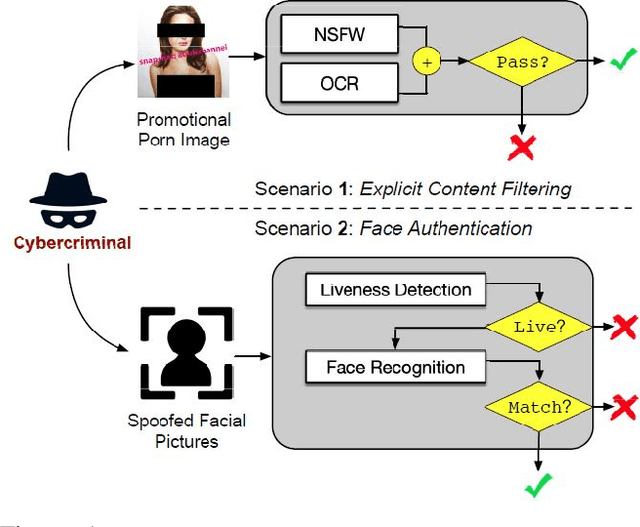
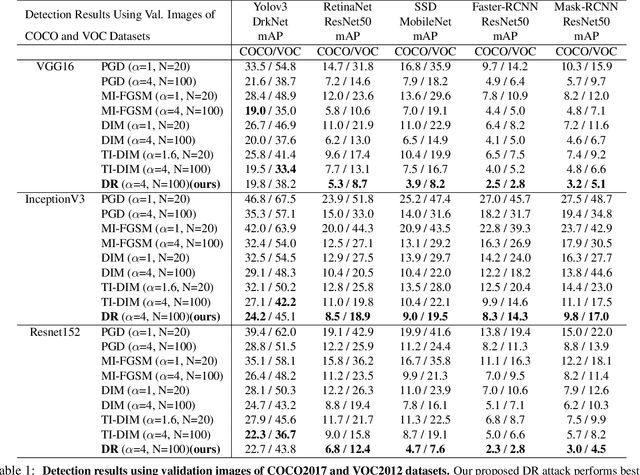
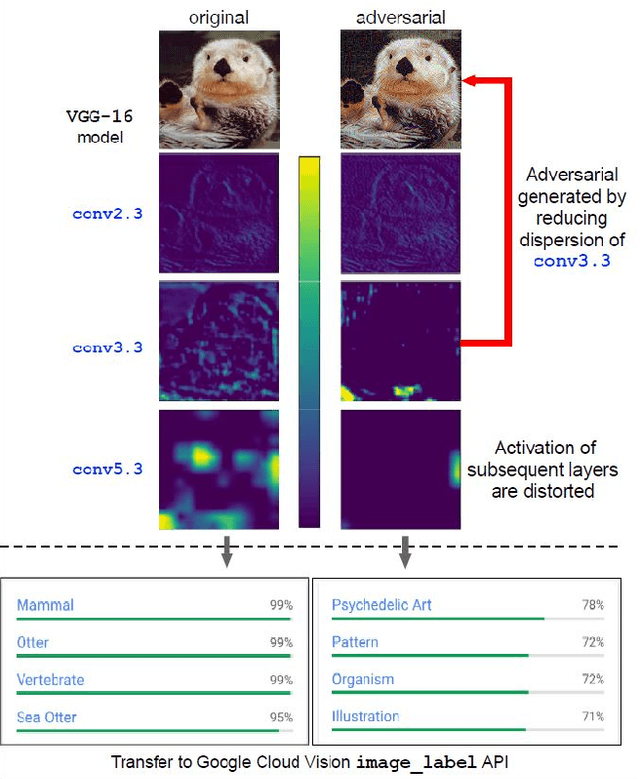
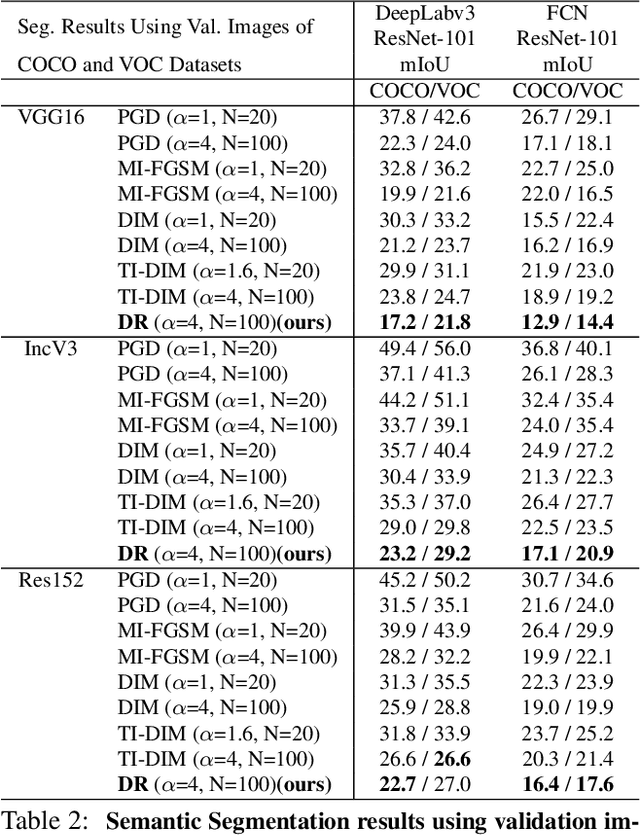
Neural networks are known to be vulnerable to carefully crafted adversarial examples, and these malicious samples often transfer, i.e., they remain adversarial even against other models. Although great efforts have been delved into the transferability across models, surprisingly, less attention has been paid to the cross-task transferability, which represents the real-world cybercriminal's situation, where an ensemble of different defense/detection mechanisms need to be evaded all at once. In this paper, we investigate the transferability of adversarial examples across a wide range of real-world computer vision tasks, including image classification, object detection, semantic segmentation, explicit content detection, and text detection. Our proposed attack minimizes the ``dispersion'' of the internal feature map, which overcomes existing attacks' limitation of requiring task-specific loss functions and/or probing a target model. We conduct evaluation on open source detection and segmentation models as well as four different computer vision tasks provided by Google Cloud Vision (GCV) APIs, to show how our approach outperforms existing attacks by degrading performance of multiple CV tasks by a large margin with only modest perturbations linf=16.
DISA at ImageCLEF 2014 Revised: Search-based Image Annotation with DeCAF Features
Sep 16, 2014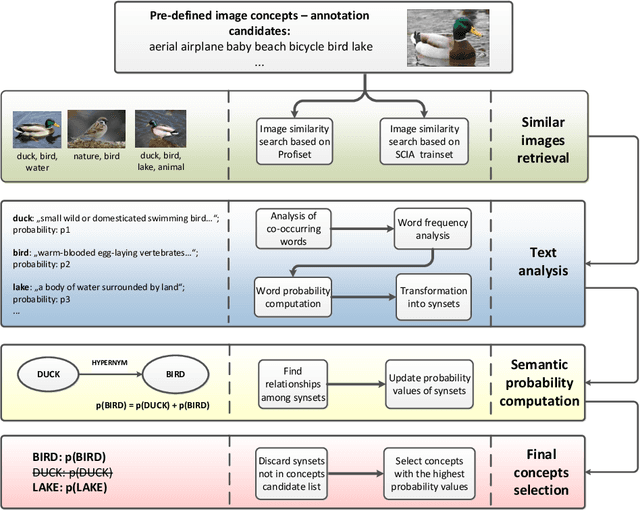
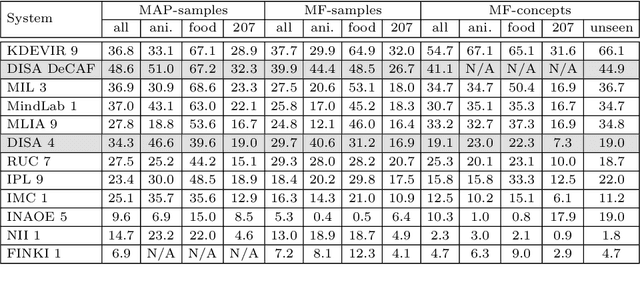
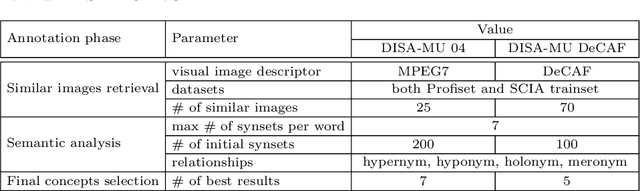
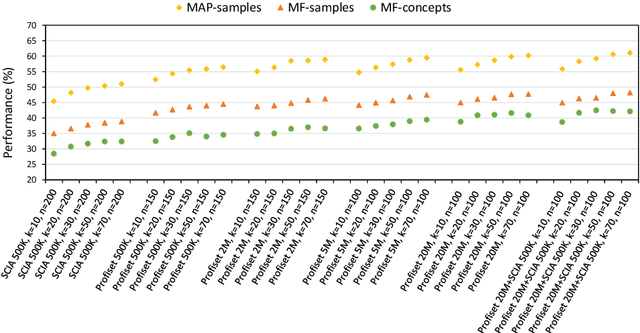
This paper constitutes an extension to the report on DISA-MU team participation in the ImageCLEF 2014 Scalable Concept Image Annotation Task as published in [3]. Specifically, we introduce a new similarity search component that was implemented into the system, report on the results achieved by utilizing this component, and analyze the influence of different similarity search parameters on the annotation quality.
Learning Linear Transformations for Fast Arbitrary Style Transfer
Aug 14, 2018
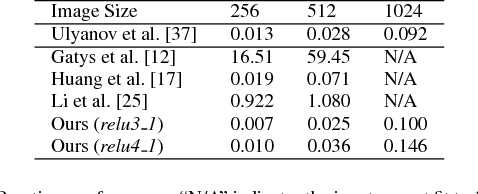
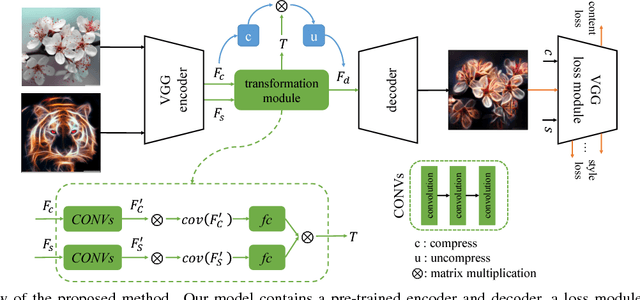
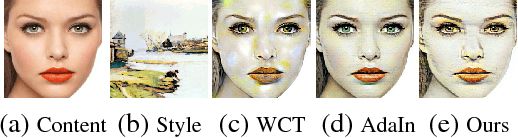
Given a random pair of images, an arbitrary style transfer method extracts the feel from the reference image to synthesize an output based on the look of the other content image. Recent arbitrary style transfer methods transfer second order statistics from reference image onto content image via a multiplication between content image features and a transformation matrix, which is computed from features with a pre-determined algorithm. These algorithms either require computationally expensive operations, or fail to model the feature covariance and produce artifacts in synthesized images. Generalized from these methods, in this work, we derive the form of transformation matrix theoretically and present an arbitrary style transfer approach that learns the transformation matrix with a feed-forward network. Our algorithm is highly efficient yet allows a flexible combination of multi-level styles while preserving content affinity during style transfer process. We demonstrate the effectiveness of our approach on four tasks: artistic style transfer, video and photo-realistic style transfer as well as domain adaptation, including comparisons with the state-of-the-art methods.
Robust real time face recognition and tracking on gpu using fusion of rgb and depth image
Apr 08, 2015This paper presents a real-time face recognition system using kinect sensor. The algorithm is implemented on GPU using opencl and significant speed improvements are observed. We use kinect depth image to increase the robustness and reduce computational cost of conventional LBP based face recognition. The main objective of this paper was to perform robust, high speed fusion based face recognition and tracking. The algorithm is mainly composed of three steps. First step is to detect all faces in the video using viola jones algorithm. The second step is online database generation using a tracking window on the face. A modified LBP feature vector is calculated using fusion information from depth and greyscale image on GPU. This feature vector is used to train a svm classifier. Third step involves recognition of multiple faces based on our modified feature vector.
PointPainting: Sequential Fusion for 3D Object Detection
Nov 22, 2019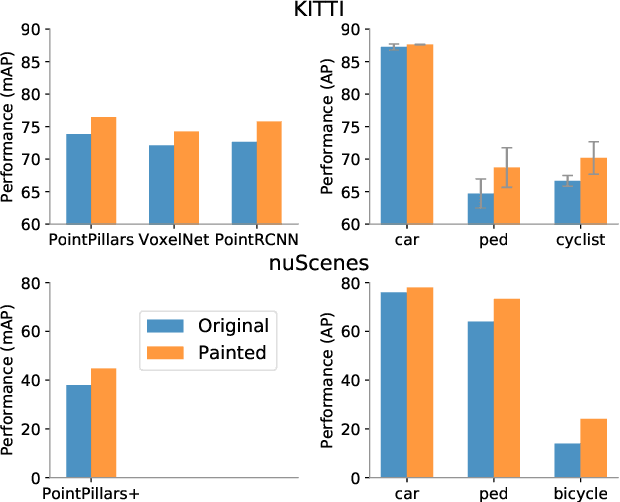
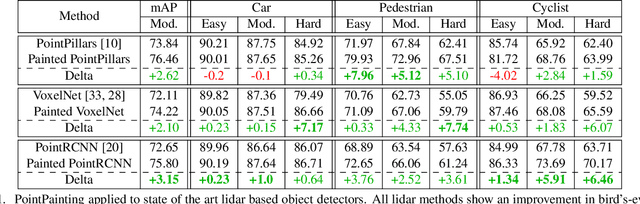
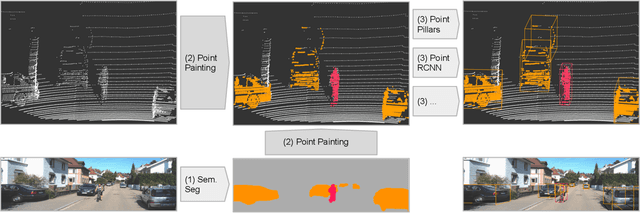
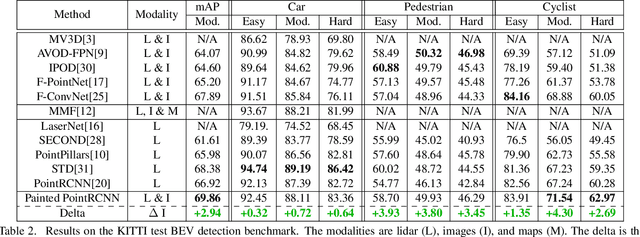
Camera and lidar are important sensor modalities for robotics in general and self-driving cars in particular. The sensors provide complementary information offering an opportunity for tight sensor-fusion. Surprisingly, lidar-only methods outperform fusion methods on the main benchmark datasets, suggesting a gap in the literature. In this work, we propose PointPainting: a sequential fusion method to fill this gap. PointPainting works by projecting lidar points into the output of an image-only semantic segmentation network and appending the class scores to each point. The appended (painted) point cloud can then be fed to any lidar-only method. Experiments show large improvements on three different state-of-the art methods, Point-RCNN, VoxelNet and PointPillars on the KITTI and nuScenes datasets. The painted version of PointRCNN represents a new state of the art on the KITTI leaderboard for the bird's-eye view detection task. In ablation, we study how the effects of Painting depends on the quality and format of the semantic segmentation output, and demonstrate how latency can be minimized through pipelining.
An Infinite Parade of Giraffes: Expressive Augmentation and Complexity Layers for Cartoon Drawing
Nov 08, 2018
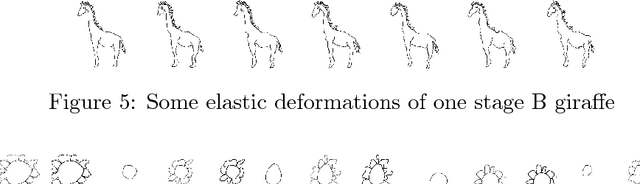
In this paper, we explore creative image generation constrained by small data. To partially automate the creation of cartoon sketches consistent with a specific designer's style, where acquiring a very large original image set is impossible or cost prohibitive, we exploit domain specific knowledge for a huge reduction in original image requirements, creating an effectively infinite number of cartoon giraffes from just nine original drawings. We introduce "expressive augmentations" for cartoon sketches, mathematical transformations that create broad domain appropriate variation, far beyond the usual affine transformations, and we show that chained GANs models trained on the temporal stages of drawing or "complexity layers" can effectively add character appropriate details and finish new drawings in the designer's style. We discuss the application of these tools in design processes for textiles, graphics, architectural elements and interior design.
Sample-specific repetitive learning for photo aesthetic assessment and highlight region extraction
Sep 18, 2019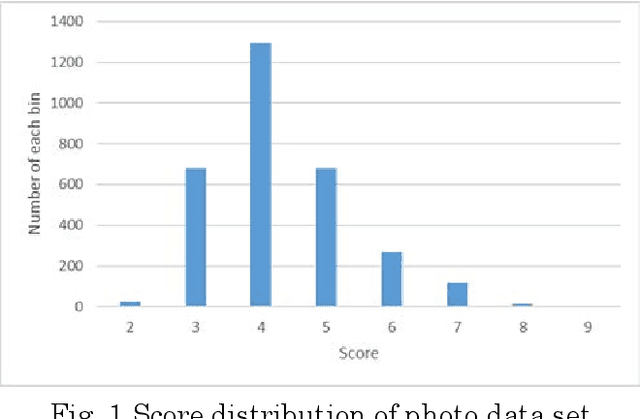
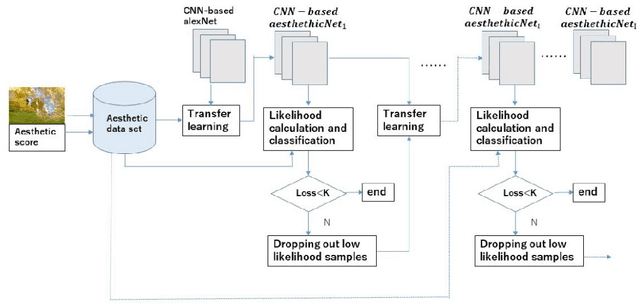

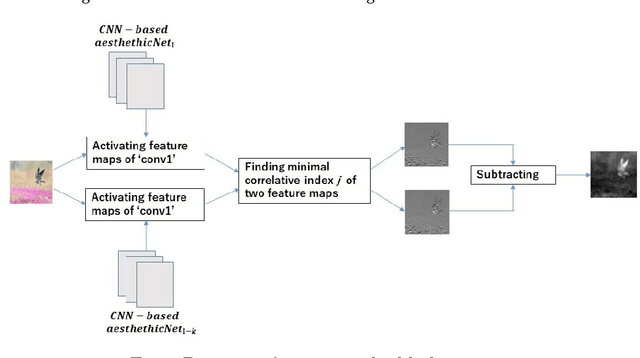
Aesthetic assessment is subjective, and the distribution of the aesthetic levels is imbalanced. In order to realize the auto-assessment of photo aesthetics, we focus on retraining the CNN-based aesthetic assessment model by dropping out the unavailable samples in the middle levels from the training data set repetitively to overcome the effect of imbalanced aesthetic data on classification. Further, the method of extracting aesthetics highlight region of the photo image by using the two repetitively trained models is presented. Therefore, the correlation of the extracted region with the aesthetic levels is analyzed to illustrate what aesthetics features influence the aesthetic quality of the photo. Moreover, the testing data set is from the different data source called 500px. Experimental results show that the proposed method is effective.
Advanced Capsule Networks via Context Awareness
Apr 02, 2019
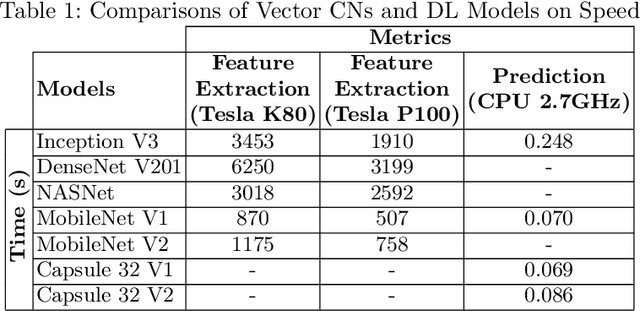
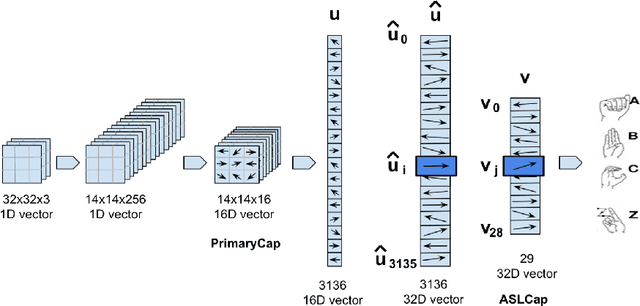
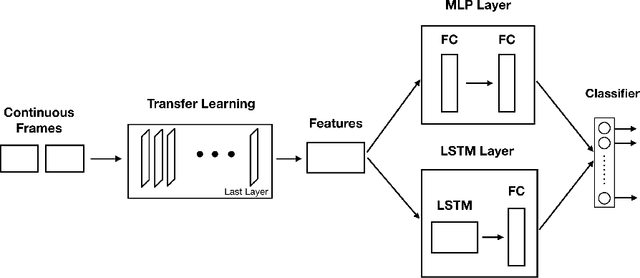
Capsule Networks (CN) offer new architectures for Deep Learning (DL) community. Though its effectiveness has been demonstrated in MNIST and smallNORB datasets, the networks still face challenges in other datasets for images with distinct contexts. In this research, we improve the design of CN (Vector version) namely we expand more Pooling layers to filter image backgrounds and increase Reconstruction layers to make better image restoration. Additionally, we perform experiments to compare accuracy and speed of CN versus DL models. In DL models, we utilize Inception V3 and DenseNet V201 for powerful computers besides NASNet, MobileNet V1 and MobileNet V2 for small and embedded devices. We evaluate our models on a fingerspelling alphabet dataset from American Sign Language (ASL). The results show that CNs perform comparably to DL models while dramatically reducing training time. We also make a demonstration and give a link for the purpose of illustration.