 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning eating environments through scene clustering
Oct 24, 2019

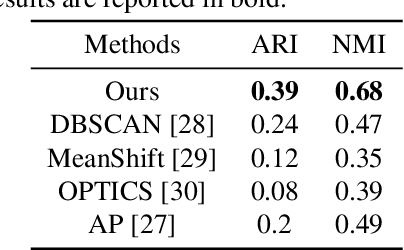
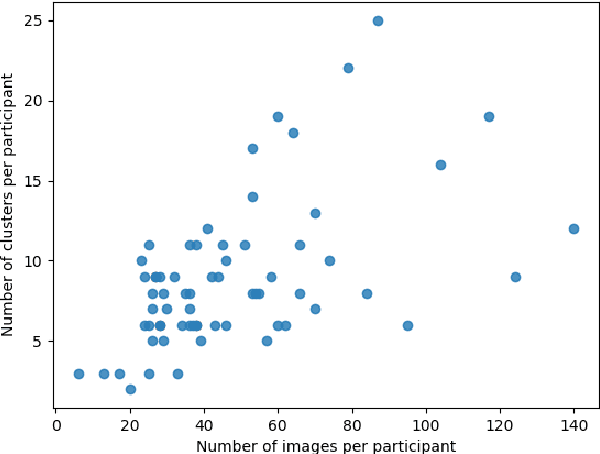
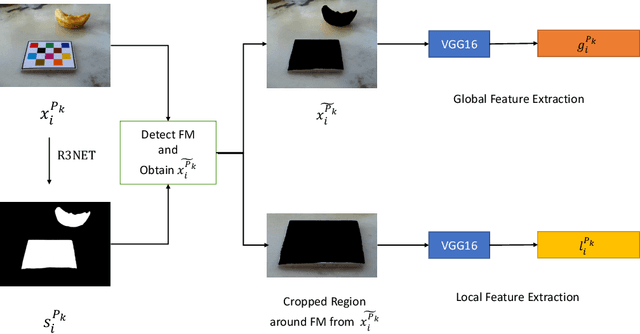
It is well known that dietary habits have a significant influence on health. While many studies have been conducted to understand this relationship, little is known about the relationship between eating environments and health. Yet researchers and health agencies around the world have recognized the eating environment as a promising context for improving diet and health. In this paper, we propose an image clustering method to automatically extract the eating environments from eating occasion images captured during a community dwelling dietary study. Specifically, we are interested in learning how many different environments an individual consumes food in. Our method clusters images by extracting features at both global and local scales using a deep neural network. The variation in the number of clusters and images captured by different individual makes this a very challenging problem. Experimental results show that our method performs significantly better compared to several existing clustering approaches.
Improving Super-Resolution Methods via Incremental Residual Learning
Aug 21, 2018
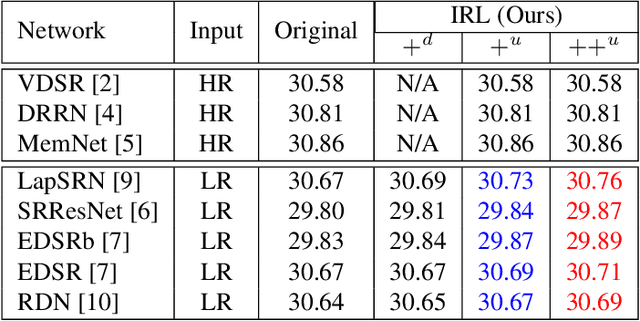
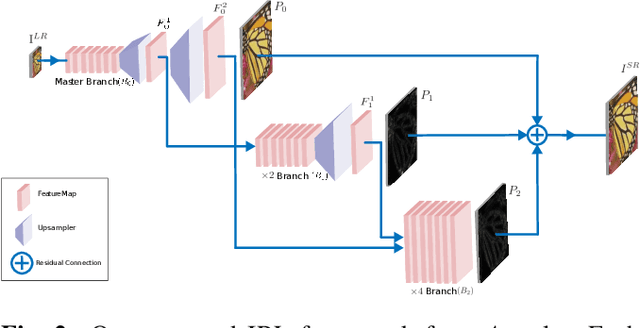
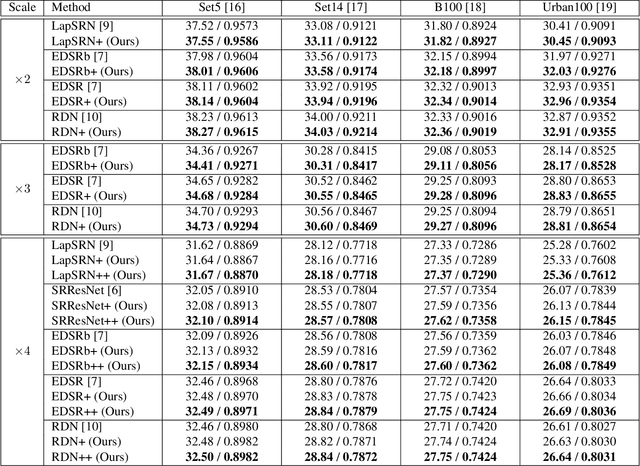
Recently, deep Convolutional Neural Networks (CNNs) have shown promising performance in accurate reconstruction of high resolution (HR) image, given its low resolution (LR) counter-part. However, recent state-of-the-art methods operate primarily on LR image for memory efficiency, but we show that it comes at the cost of performance. Furthermore, because spatial dimensions of input and output of such networks do not match, it's not possible to learn residuals in image space; we show that learning residuals in image space leads to performance enhancement. To this end, we propose a novel Incremental Residual Learning (IRL) framework to solve the above mentioned issues. In IRL, a set of branches i.e arbitrary image-to-image networks are trained sequentially where each branch takes spatially upsampled higher dimensional feature maps as input and predicts the residuals of all previous branches combined. We plug recent state of the art methods as base networks in IRL framework and demonstrate the consistent performance enhancement through extensive experiments on public benchmark datasets to set a new state of the art for super-resolution. Compared to the base networks our method incurs no extra memory overhead as only one branch is trained at a time. Furthermore, as our method is trained to learned residuals, complete set of branches are trained in only 20% of time relative to base network.
Single-bit-per-weight deep convolutional neural networks without batch-normalization layers for embedded systems
Jul 22, 2019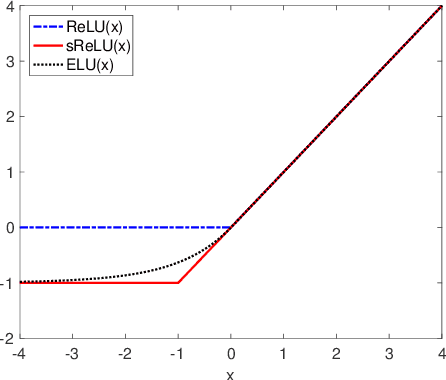
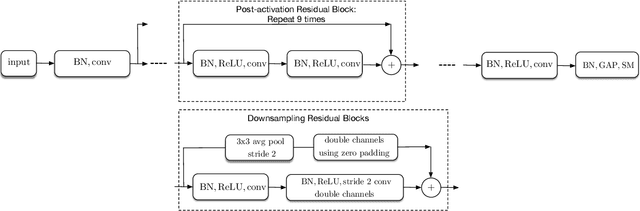
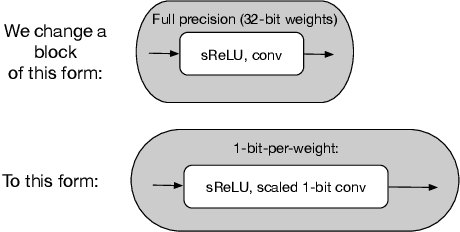
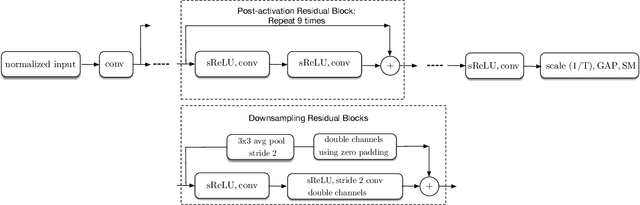
Batch-normalization (BN) layers are thought to be an integrally important layer type in today's state-of-the-art deep convolutional neural networks for computer vision tasks such as classification and detection. However, BN layers introduce complexity and computational overheads that are highly undesirable for training and/or inference on low-power custom hardware implementations of real-time embedded vision systems such as UAVs, robots and Internet of Things (IoT) devices. They are also problematic when batch sizes need to be very small during training, and innovations such as residual connections introduced more recently than BN layers could potentially have lessened their impact. In this paper we aim to quantify the benefits BN layers offer in image classification networks, in comparison with alternative choices. In particular, we study networks that use shifted-ReLU layers instead of BN layers. We found, following experiments with wide residual networks applied to the ImageNet, CIFAR 10 and CIFAR 100 image classification datasets, that BN layers do not consistently offer a significant advantage. We found that the accuracy margin offered by BN layers depends on the data set, the network size, and the bit-depth of weights. We conclude that in situations where BN layers are undesirable due to speed, memory or complexity costs, that using shifted-ReLU layers instead should be considered; we found they can offer advantages in all these areas, and often do not impose a significant accuracy cost.
Parallel 3DPIFCM Algorithm for Noisy Brain MRI Images
Feb 05, 2020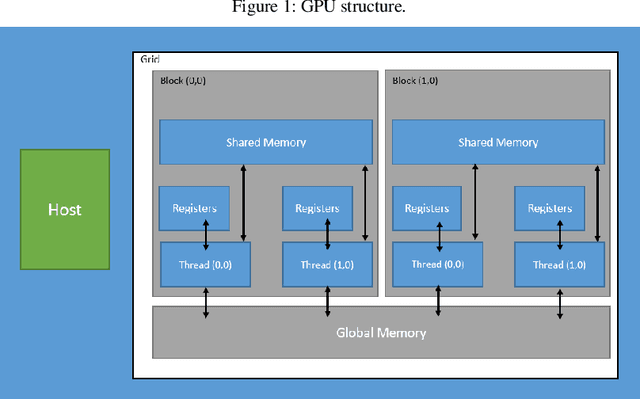
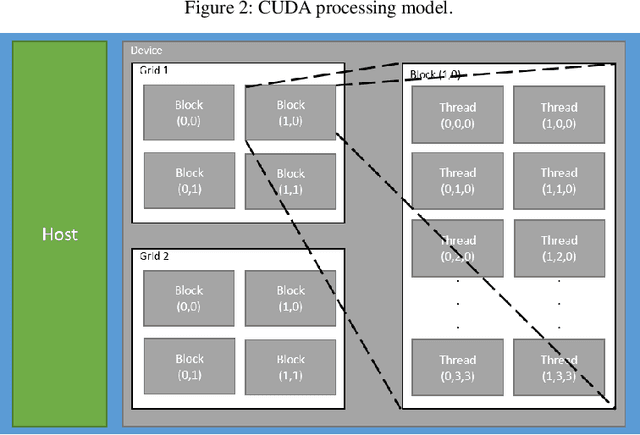
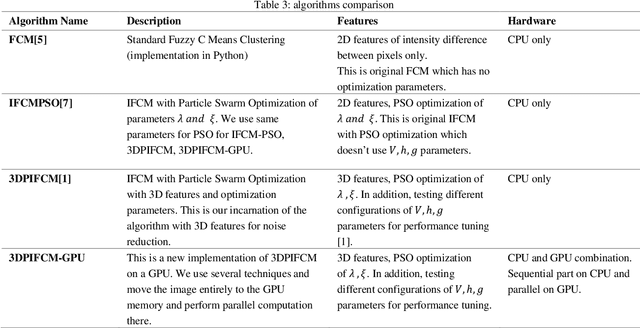
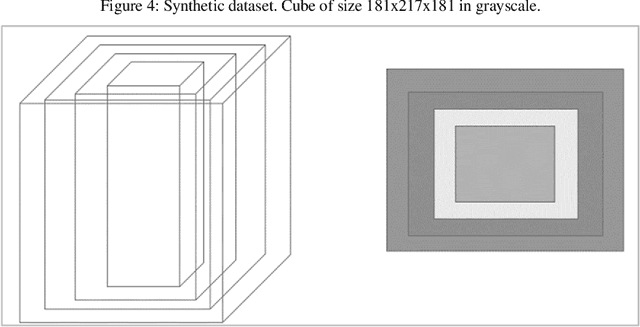
In this paper we implemented the algorithm we developed in [1] called 3DPIFCM in a parallel environment by using CUDA on a GPU. In our previous work we introduced 3DPIFCM which performs segmentation of images in noisy conditions and uses particle swarm optimization for finding the optimal algorithm parameters to account for noise. This algorithm achieved state of the art segmentation accuracy when compared to FCM (Fuzzy C-Means), IFCMPSO (Improved Fuzzy C-Means with Particle Swarm Optimization), GAIFCM (Genetic Algorithm Improved Fuzzy C-Means) on noisy MRI images of an adult Brain. When using a genetic algorithm or PSO (Particle Swarm Optimization) on a single machine for optimization we witnessed long execution times for practical clinical usage. Therefore, in the current paper our goal was to speed up the execution of 3DPIFCM by taking out parts of the algorithm and executing them as kernels on a GPU. The algorithm was implemented using the CUDA [13] framework from NVIDIA and experiments where performed on a server containing 64GB RAM , 8 cores and a TITAN X GPU with 3072 SP cores and 12GB of GPU memory. Our results show that the parallel version of the algorithm performs up to 27x faster than the original sequential version and 68x faster than GAIFCM algorithm. We show that the speedup of the parallel version increases as we increase the size of the image due to better utilization of cores in the GPU. Also, we show a speedup of up to 5x in our Brainweb experiment compared to other generic variants such as IFCMPSO and GAIFCM.
An Improving Framework of regularization for Network Compression
Dec 11, 2019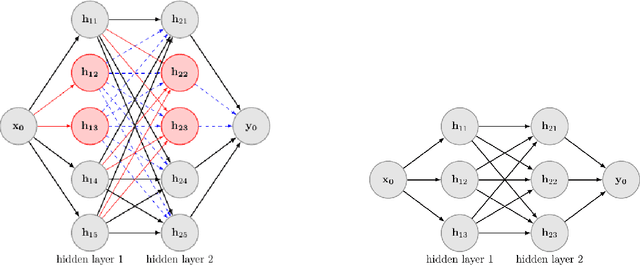
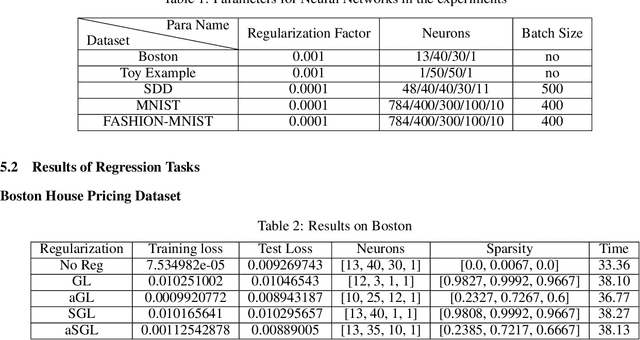
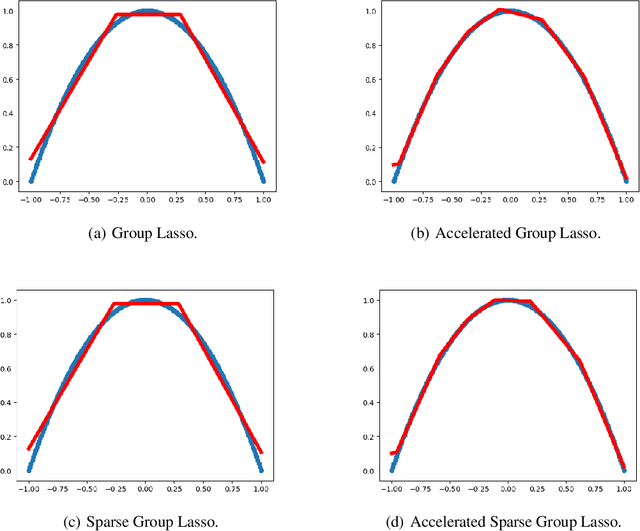

Deep Neural Networks have achieved remarkable success relying on the developing high computation capability of GPUs and large-scale datasets with increasing network depth and width in image recognition, object detection and many other applications. However, due to the expensive computation and intensive memory, researchers have concentrated on designing compression methods in recent years. In this paper, we briefly summarize the existing advanced techniques that are useful in model compression at first. After that, we give a detailed description on group lasso regularization and its variants. More importantly, we propose an improving framework of partial regularization based on the relationship between neurons and connections of adjacent layers. It is reasonable and feasible with the help of permutation property of neural network . Experiment results show that partial regularization methods brings improvements such as higher classification accuracy in both training and testing stages on multiple datasets. Since our regularizers contain the computation of less parameters, it shows competitive performances in terms of the total running time of experiments. Finally, we analysed the results and draw a conclusion that the optimal network structure must exist and depend on the input data.
Learning Multi-Human Optical Flow
Oct 24, 2019
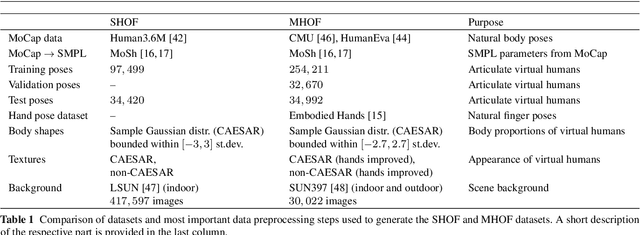
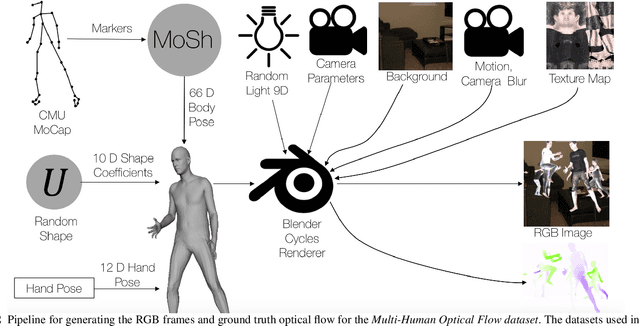
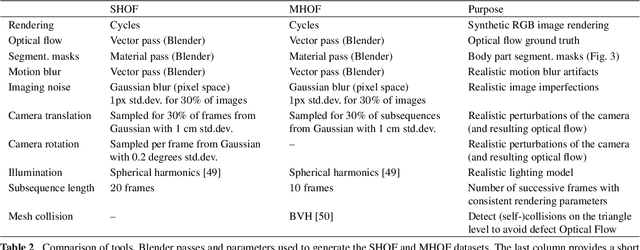
The optical flow of humans is well known to be useful for the analysis of human action. Recent optical flow methods focus on training deep networks to approach the problem. However, the training data used by them does not cover the domain of human motion. Therefore, we develop a dataset of multi-human optical flow and train optical flow networks on this dataset. We use a 3D model of the human body and motion capture data to synthesize realistic flow fields in both single- and multi-person images. We then train optical flow networks to estimate human flow fields from pairs of images. We demonstrate that our trained networks are more accurate than a wide range of top methods on held-out test data and that they can generalize well to real image sequences. The code, trained models and the dataset are available for research.
Image Parsing with a Wide Range of Classes and Scene-Level Context
Oct 24, 2015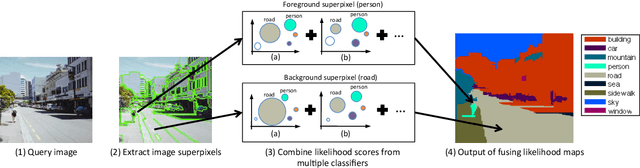
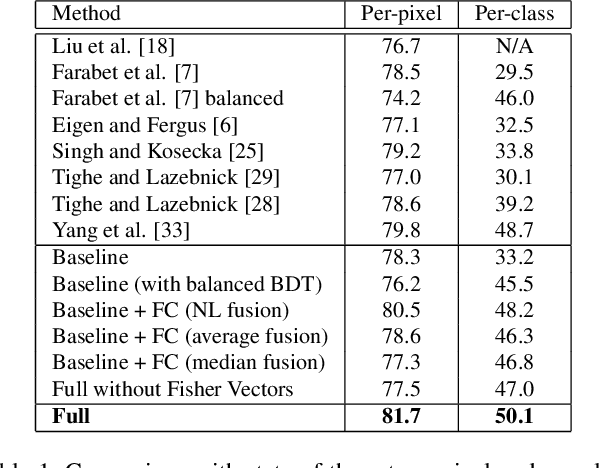
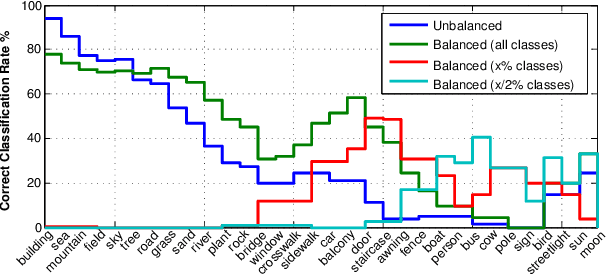
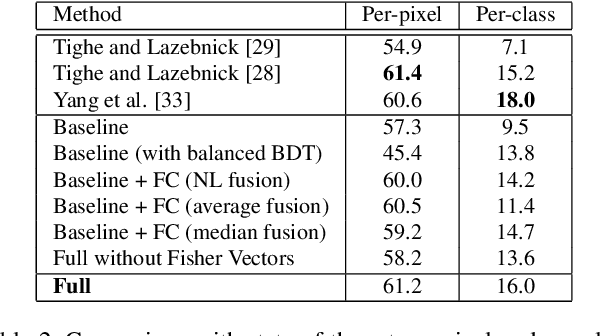
This paper presents a nonparametric scene parsing approach that improves the overall accuracy, as well as the coverage of foreground classes in scene images. We first improve the label likelihood estimates at superpixels by merging likelihood scores from different probabilistic classifiers. This boosts the classification performance and enriches the representation of less-represented classes. Our second contribution consists of incorporating semantic context in the parsing process through global label costs. Our method does not rely on image retrieval sets but rather assigns a global likelihood estimate to each label, which is plugged into the overall energy function. We evaluate our system on two large-scale datasets, SIFTflow and LMSun. We achieve state-of-the-art performance on the SIFTflow dataset and near-record results on LMSun.
Scalability in Perception for Autonomous Driving: An Open Dataset Benchmark
Dec 10, 2019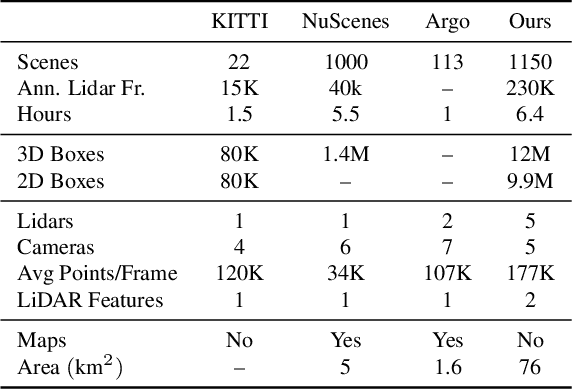
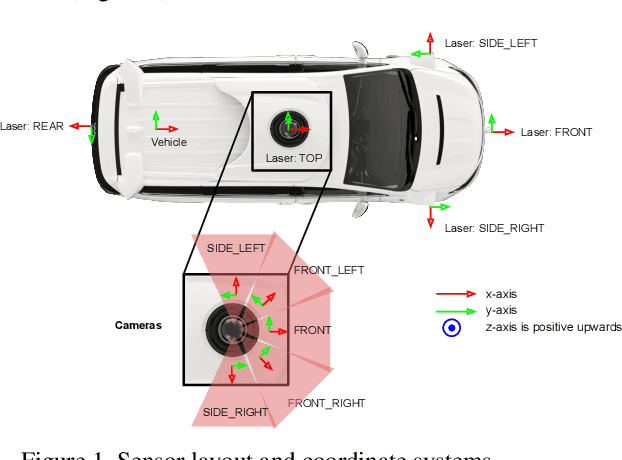

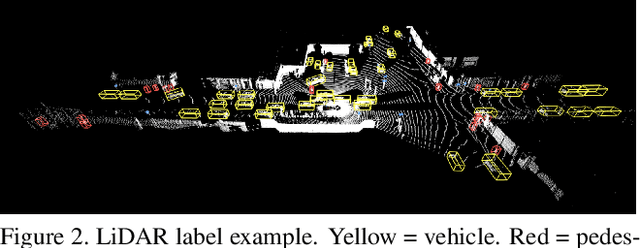
The research community has increasing interest in autonomous driving research, despite the resource intensity of obtaining representative real world data. Existing self-driving datasets are limited in the scale and variation of the environments they capture, even though generalization within and between operating regions is crucial to the overall viability of the technology. In an effort to help align the research community's contributions with real-world self-driving problems, we introduce a new large scale, high quality, diverse dataset. Our new dataset consists of 1150 scenes that each span 20 seconds, consisting of well synchronized and calibrated high quality LiDAR and camera data captured across a range of urban and suburban geographies. It is 15x more diverse than the largest camera+LiDAR dataset available based on our proposed diversity metric. We exhaustively annotated this data with 2D (camera image) and 3D (LiDAR) bounding boxes, with consistent identifiers across frames. Finally, we provide strong baselines for 2D as well as 3D detection and tracking tasks. We further study the effects of dataset size and generalization across geographies on 3D detection methods. Find data, code and more up-to-date information at http://www.waymo.com/open.
Variational Disparity Estimation Framework for Plenoptic Image
Apr 18, 2018
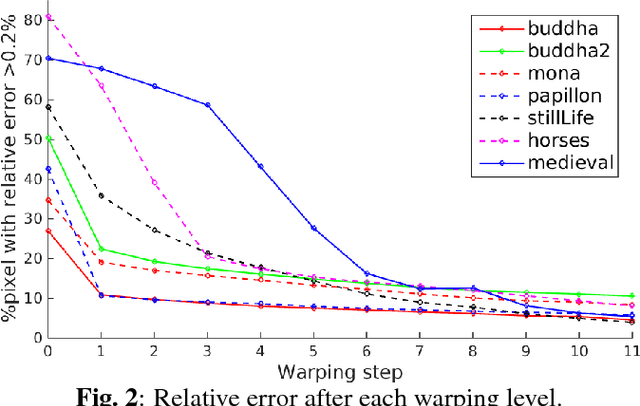
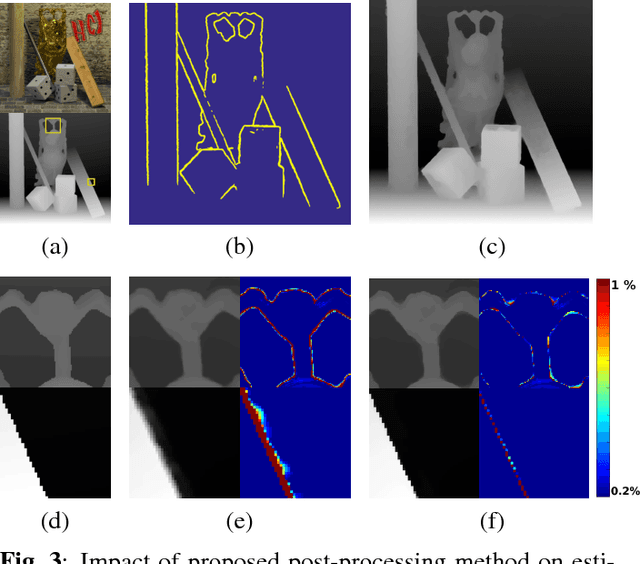
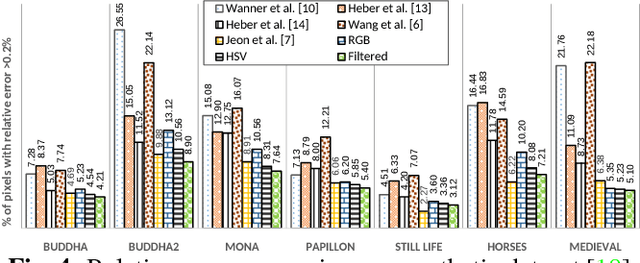
This paper presents a computational framework for accurately estimating the disparity map of plenoptic images. The proposed framework is based on the variational principle and provides intrinsic sub-pixel precision. The light-field motion tensor introduced in the framework allows us to combine advanced robust data terms as well as provides explicit treatments for different color channels. A warping strategy is embedded in our framework for tackling the large displacement problem. We also show that by applying a simple regularization term and a guided median filtering, the accuracy of displacement field at occluded area could be greatly enhanced. We demonstrate the excellent performance of the proposed framework by intensive comparisons with the Lytro software and contemporary approaches on both synthetic and real-world datasets.
Recovering Faces from Portraits with Auxiliary Facial Attributes
Apr 07, 2019
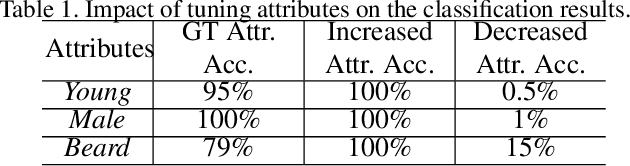
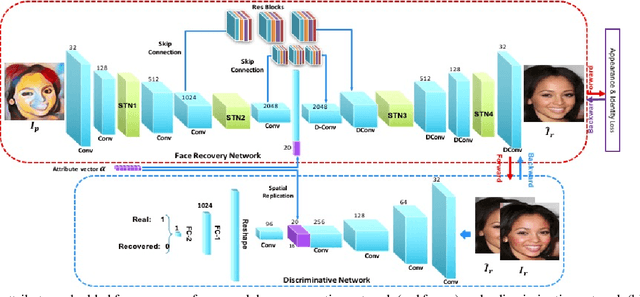
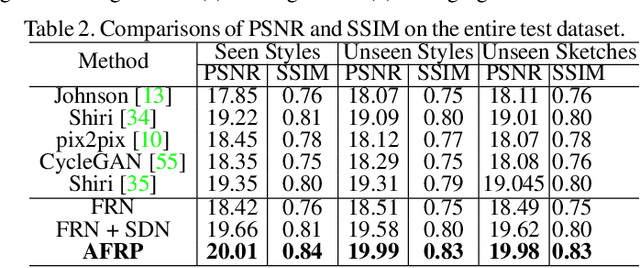
Recovering a photorealistic face from an artistic portrait is a challenging task since crucial facial details are often distorted or completely lost in artistic compositions. To handle this loss, we propose an Attribute-guided Face Recovery from Portraits (AFRP) that utilizes a Face Recovery Network (FRN) and a Discriminative Network (DN). FRN consists of an autoencoder with residual block-embedded skip-connections and incorporates facial attribute vectors into the feature maps of input portraits at the bottleneck of the autoencoder. DN has multiple convolutional and fully-connected layers, and its role is to enforce FRN to generate authentic face images with corresponding facial attributes dictated by the input attribute vectors. %Leveraging on the spatial transformer networks, FRN automatically compensates for misalignments of portraits. % and generates aligned face images. For the preservation of identities, we impose the recovered and ground-truth faces to share similar visual features. Specifically, DN determines whether the recovered image looks like a real face and checks if the facial attributes extracted from the recovered image are consistent with given attributes. %Our method can recover high-quality photorealistic faces from unaligned portraits while preserving the identity of the face images as well as it can reconstruct a photorealistic face image with a desired set of attributes. Our method can recover photorealistic identity-preserving faces with desired attributes from unseen stylized portraits, artistic paintings, and hand-drawn sketches. On large-scale synthesized and sketch datasets, we demonstrate that our face recovery method achieves state-of-the-art results.