 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Can We Use Split Learning on 1D CNN Models for Privacy Preserving Training?
Mar 16, 2020
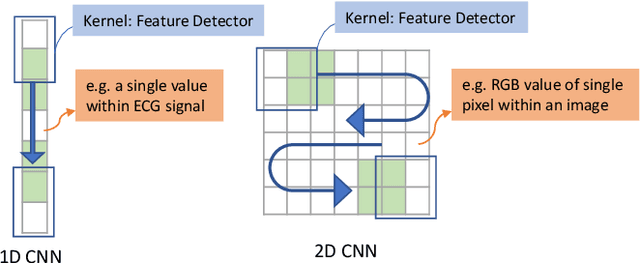
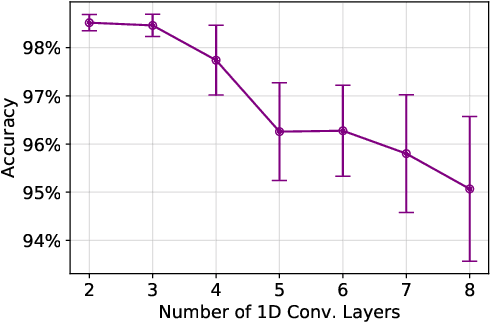
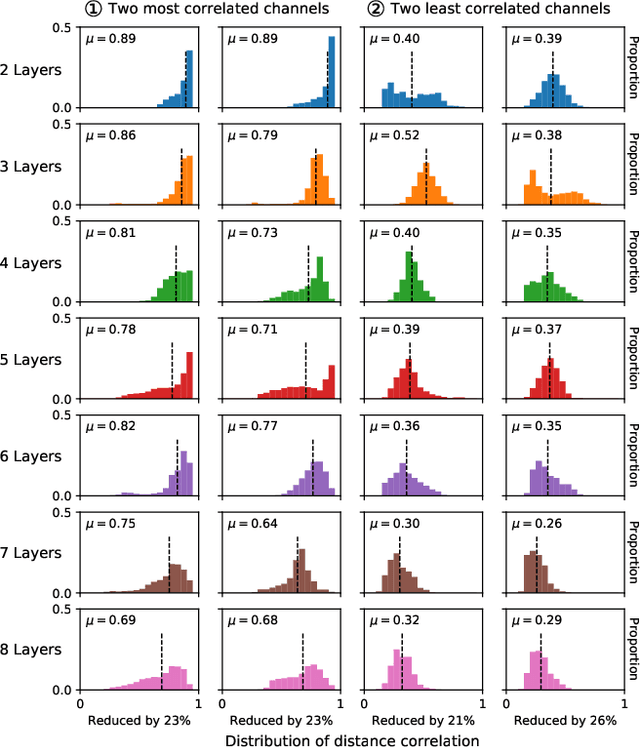
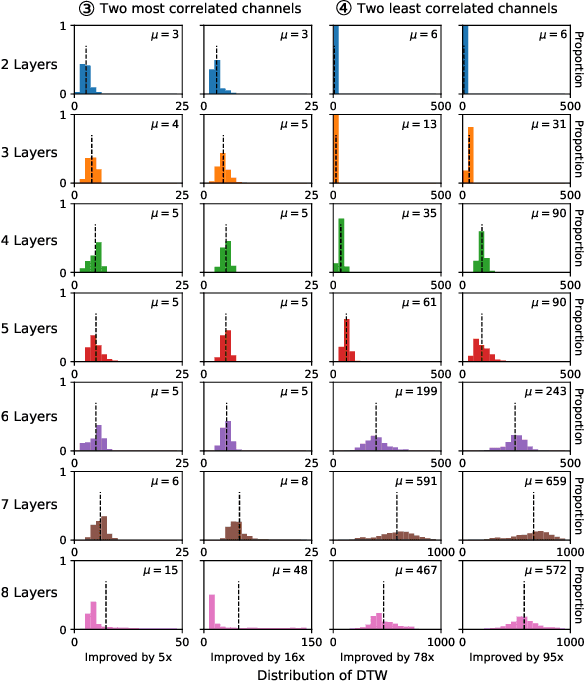
A new collaborative learning, called split learning, was recently introduced, aiming to protect user data privacy without revealing raw input data to a server. It collaboratively runs a deep neural network model where the model is split into two parts, one for the client and the other for the server. Therefore, the server has no direct access to raw data processed at the client. Until now, the split learning is believed to be a promising approach to protect the client's raw data; for example, the client's data was protected in healthcare image applications using 2D convolutional neural network (CNN) models. However, it is still unclear whether the split learning can be applied to other deep learning models, in particular, 1D CNN. In this paper, we examine whether split learning can be used to perform privacy-preserving training for 1D CNN models. To answer this, we first design and implement an 1D CNN model under split learning and validate its efficacy in detecting heart abnormalities using medical ECG data. We observed that the 1D CNN model under split learning can achieve the same accuracy of 98.9\% like the original (non-split) model. However, our evaluation demonstrates that split learning may fail to protect the raw data privacy on 1D CNN models. To address the observed privacy leakage in split learning, we adopt two privacy leakage mitigation techniques: 1) adding more hidden layers to the client side and 2) applying differential privacy. Although those mitigation techniques are helpful in reducing privacy leakage, they have a significant impact on model accuracy. Hence, based on those results, we conclude that split learning alone would not be sufficient to maintain the confidentiality of raw sequential data in 1D CNN models.
Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey
Feb 16, 2019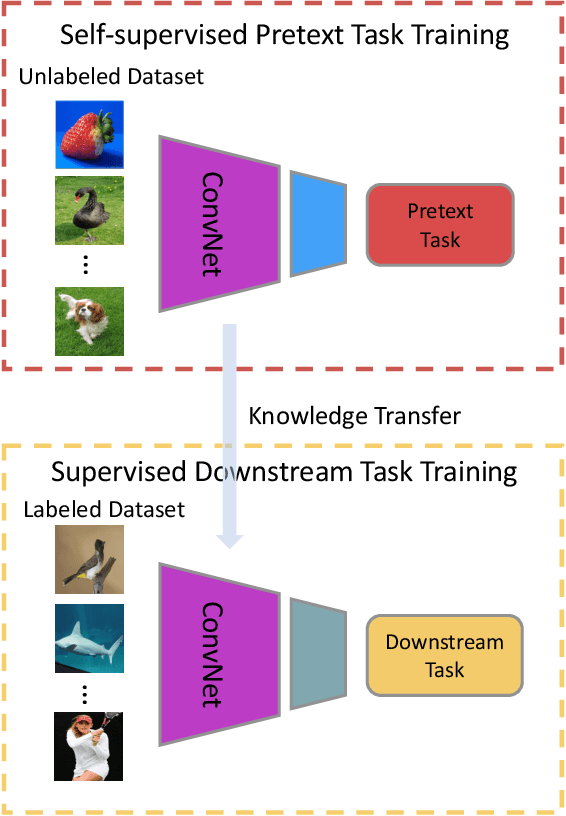
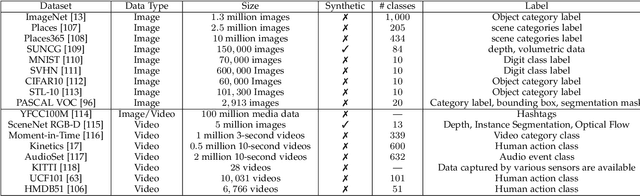
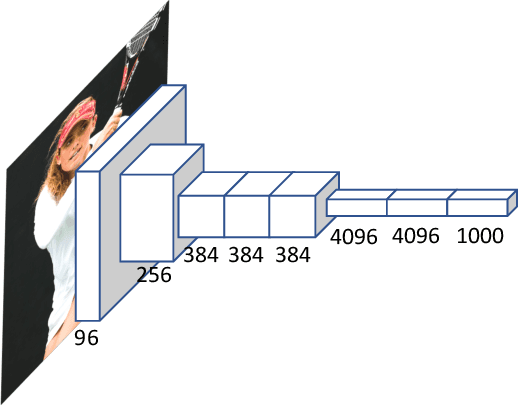
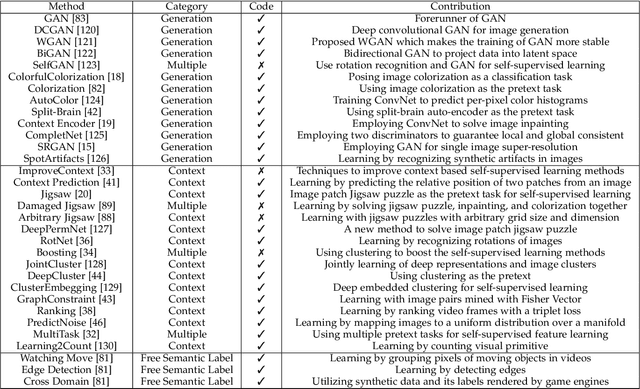
Large-scale labeled data are generally required to train deep neural networks in order to obtain better performance in visual feature learning from images or videos for computer vision applications. To avoid extensive cost of collecting and annotating large-scale datasets, as a subset of unsupervised learning methods, self-supervised learning methods are proposed to learn general image and video features from large-scale unlabeled data without using any human-annotated labels. This paper provides an extensive review of deep learning-based self-supervised general visual feature learning methods from images or videos. First, the motivation, general pipeline, and terminologies of this field are described. Then the common deep neural network architectures that used for self-supervised learning are summarized. Next, the main components and evaluation metrics of self-supervised learning methods are reviewed followed by the commonly used image and video datasets and the existing self-supervised visual feature learning methods. Finally, quantitative performance comparisons of the reviewed methods on benchmark datasets are summarized and discussed for both image and video feature learning. At last, this paper is concluded and lists a set of promising future directions for self-supervised visual feature learning.
PVN3D: A Deep Point-wise 3D Keypoints Voting Network for 6DoF Pose Estimation
Nov 11, 2019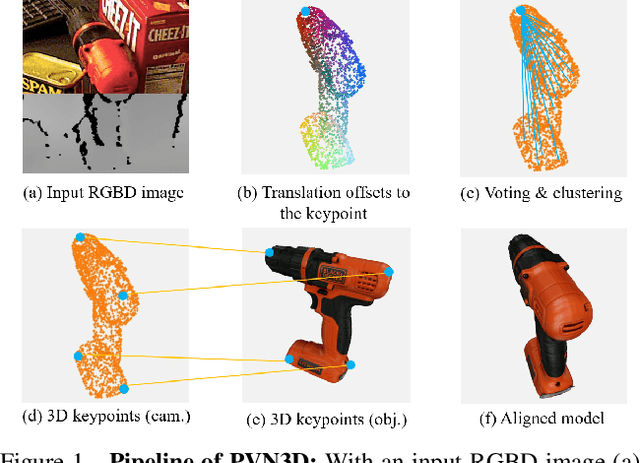
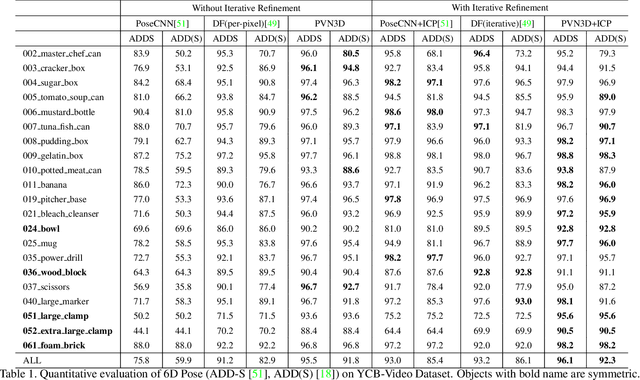
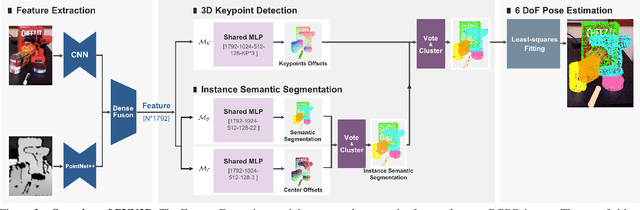
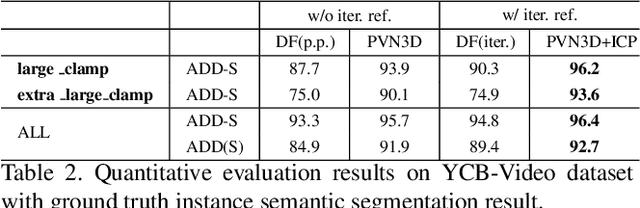
In this work, we present a novel data-driven method for robust 6DoF object pose estimation from a single RGBD image. Unlike previous methods that directly regressing pose parameters, we tackle this challenging task with a keypoint-based approach. Specifically, we propose a deep Hough voting network to detect 3D keypoints of objects and then estimate the 6D pose parameters within a least-squares fitting manner. Our method is a natural extension of 2D-keypoint approaches that successfully work on RGB based 6DoF estimation. It allows us to fully utilize the geometric constraint of rigid objects with the extra depth information and is easy for a network to learn and optimize. Extensive experiments were conducted to demonstrate the effectiveness of 3D-keypoint detection in the 6D pose estimation task. Experimental results also show our method outperforms the state-of-the-art methods by large margins on several benchmarks.
Visually Guided Self Supervised Learning of Speech Representations
Jan 13, 2020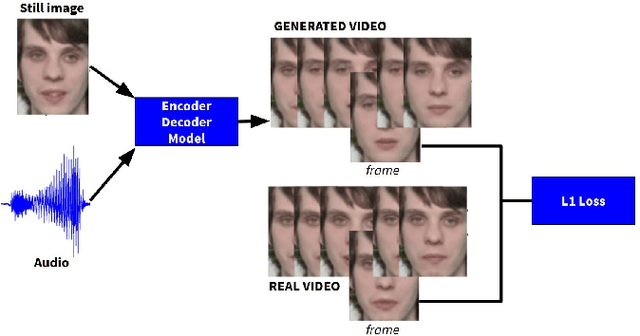
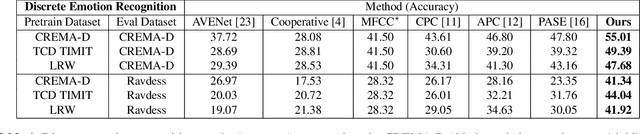
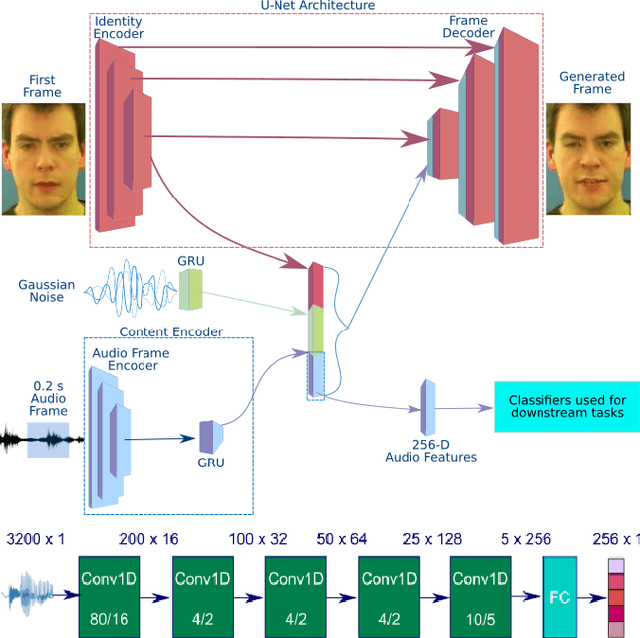
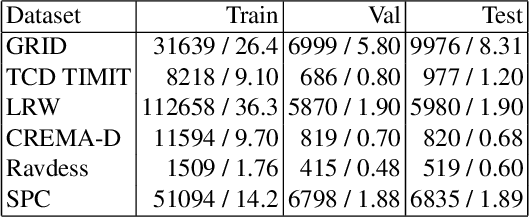
Self supervised representation learning has recently attracted a lot of research interest for both the audio and visual modalities. However, most works typically focus on a particular modality or feature alone and there has been very limited work that studies the interaction between the two modalities for learning self supervised representations. We propose a framework for learning audio representations guided by the visual modality in the context of audiovisual speech. We employ a generative audio-to-video training scheme in which we animate a still image corresponding to a given audio clip and optimize the generated video to be as close as possible to the real video of the speech segment. Through this process, the audio encoder network learns useful speech representations that we evaluate on emotion recognition and speech recognition. We achieve state of the art results for emotion recognition and competitive results for speech recognition. This demonstrates the potential of visual supervision for learning audio representations as a novel way for self-supervised learning which has not been explored in the past. The proposed unsupervised audio features can leverage a virtually unlimited amount of training data of unlabelled audiovisual speech and have a large number of potentially promising applications.
Cross-domain Image Retrieval with a Dual Attribute-aware Ranking Network
May 29, 2015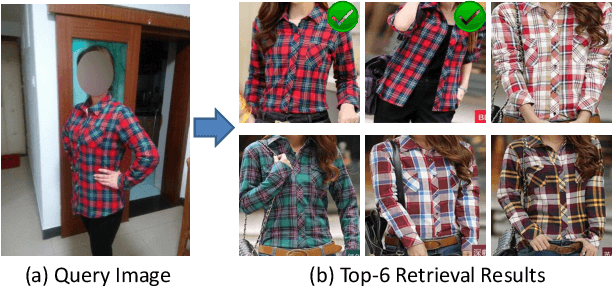
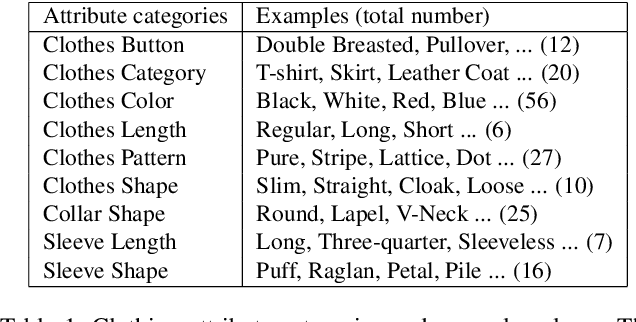

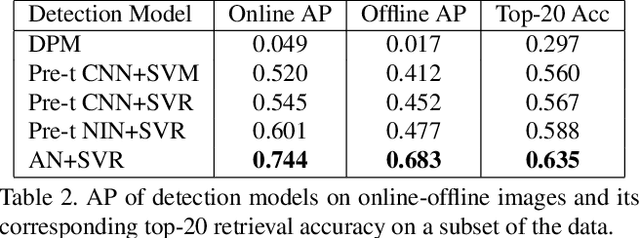
We address the problem of cross-domain image retrieval, considering the following practical application: given a user photo depicting a clothing image, our goal is to retrieve the same or attribute-similar clothing items from online shopping stores. This is a challenging problem due to the large discrepancy between online shopping images, usually taken in ideal lighting/pose/background conditions, and user photos captured in uncontrolled conditions. To address this problem, we propose a Dual Attribute-aware Ranking Network (DARN) for retrieval feature learning. More specifically, DARN consists of two sub-networks, one for each domain, whose retrieval feature representations are driven by semantic attribute learning. We show that this attribute-guided learning is a key factor for retrieval accuracy improvement. In addition, to further align with the nature of the retrieval problem, we impose a triplet visual similarity constraint for learning to rank across the two sub-networks. Another contribution of our work is a large-scale dataset which makes the network learning feasible. We exploit customer review websites to crawl a large set of online shopping images and corresponding offline user photos with fine-grained clothing attributes, i.e., around 450,000 online shopping images and about 90,000 exact offline counterpart images of those online ones. All these images are collected from real-world consumer websites reflecting the diversity of the data modality, which makes this dataset unique and rare in the academic community. We extensively evaluate the retrieval performance of networks in different configurations. The top-20 retrieval accuracy is doubled when using the proposed DARN other than the current popular solution using pre-trained CNN features only (0.570 vs. 0.268).
Rethinking Normalization and Elimination Singularity in Neural Networks
Nov 21, 2019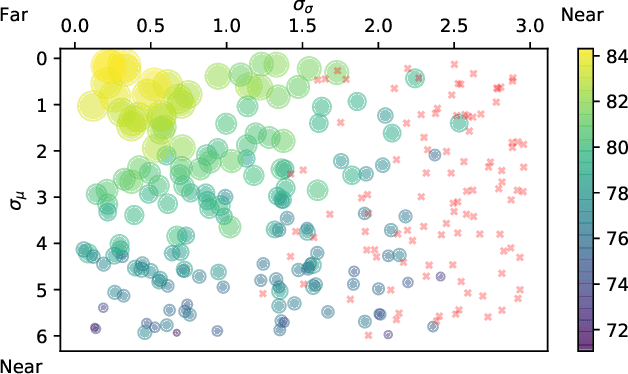
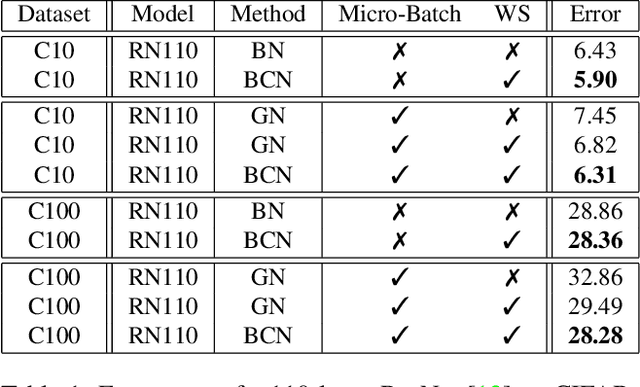
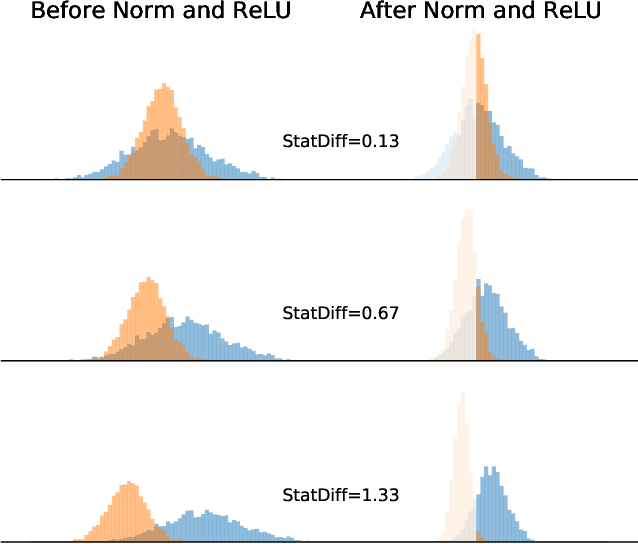
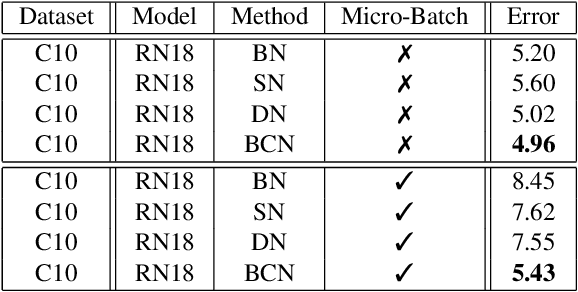
In this paper, we study normalization methods for neural networks from the perspective of elimination singularity. Elimination singularities correspond to the points on the training trajectory where neurons become consistently deactivated. They cause degenerate manifolds in the loss landscape which will slow down training and harm model performances. We show that channel-based normalizations (e.g. Layer Normalization and Group Normalization) are unable to guarantee a far distance from elimination singularities, in contrast with Batch Normalization which by design avoids models from getting too close to them. To address this issue, we propose BatchChannel Normalization (BCN), which uses batch knowledge to avoid the elimination singularities in the training of channel-normalized models. Unlike Batch Normalization, BCN is able to run in both large-batch and micro-batch training settings. The effectiveness of BCN is verified on many tasks, including image classification, object detection, instance segmentation, and semantic segmentation. The code is here: https://github.com/joe-siyuan-qiao/Batch-Channel-Normalization.
Efficient Computation of Hessian Matrices in TensorFlow
May 14, 2019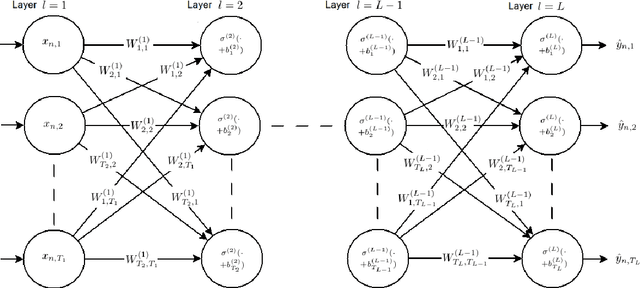
The Hessian matrix has a number of important applications in a variety of different fields, such as optimzation, image processing and statistics. In this paper we focus on the practical aspects of efficiently computing Hessian matrices in the context of deep learning using the Python scripting language and the TensorFlow library.
Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network
Sep 11, 2019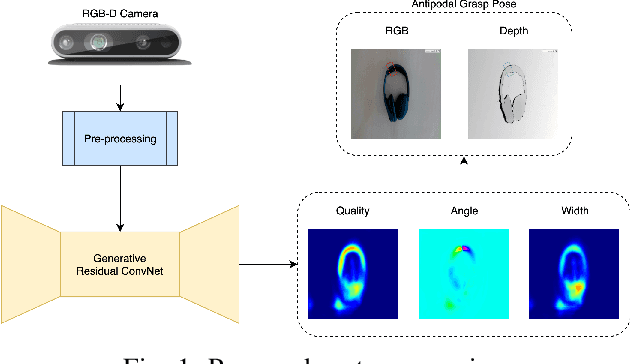
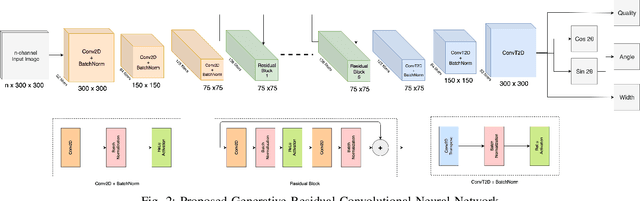

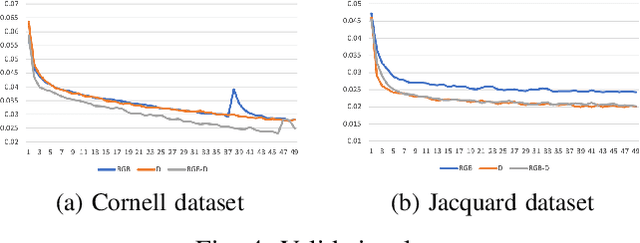
In this paper, we tackle the problem of generating antipodal robotic grasps for unknown objects from n-channel image of the scene. We propose a novel Generative Residual Convolutional Neural Network (GR-ConvNet) model that can generate robust antipodal grasps from n-channel input at realtime speeds (~20ms). We evaluate the proposed model architecture on standard datasets and previously unseen household objects. We achieved state-of-the-art accuracy of 97.7% and 94.6% on Cornell and Jacquard grasping datasets respectively. We also demonstrate a 93.5% grasp success rate on previously unseen real-world objects. Our open-source implementation of GR-ConvNet can be found at github.com/skumra/robotic-grasping.
A Unified Learning Based Framework for Light Field Reconstruction from Coded Projections
Dec 26, 2018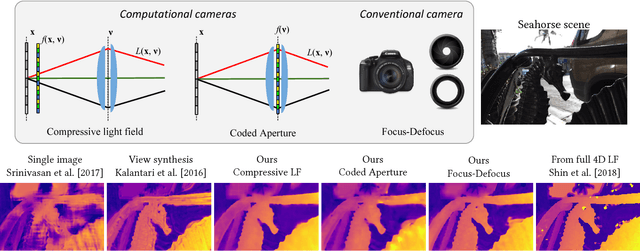
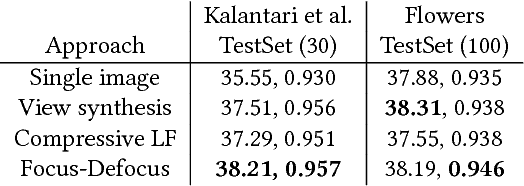
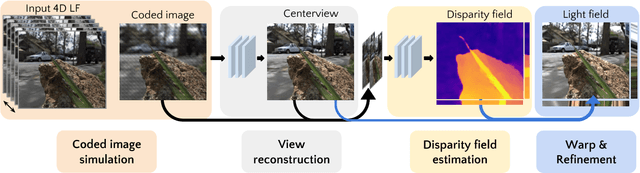
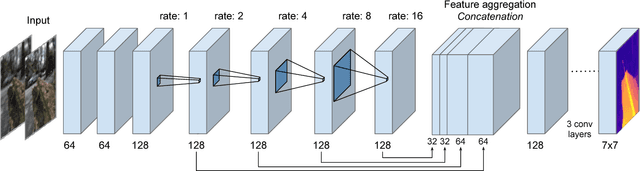
Light field presents a rich way to represent the 3D world by capturing the spatio-angular dimensions of the visual signal. However, the popular way of capturing light field (LF) via a plenoptic camera presents spatio-angular resolution trade-off. Computational imaging techniques such as compressive light field and programmable coded aperture reconstruct full sensor resolution LF from coded projections obtained by multiplexing the incoming spatio-angular light field. Here, we present a unified learning framework that can reconstruct LF from a variety of multiplexing schemes with minimal number of coded images as input. We consider three light field capture schemes: heterodyne capture scheme with code placed near the sensor, coded aperture scheme with code at the camera aperture and finally the dual exposure scheme of capturing a focus-defocus pair where there is no explicit coding. Our algorithm consists of three stages 1) we recover the all-in-focus image from the coded image 2) we estimate the disparity maps for all the LF views from the coded image and the all-in-focus image, 3) we then render the LF by warping the all-in-focus image using disparity maps and refine it. For these three stages we propose three deep neural networks - ViewNet, DispairtyNet and RefineNet. Our reconstructions show that our learning algorithm achieves state-of-the-art results for all the three multiplexing schemes. Especially, our LF reconstructions from focus-defocus pair is comparable to other learning-based view synthesis approaches from multiple images. Thus, our work paves the way for capturing high-resolution LF (~ a megapixel) using conventional cameras such as DSLRs. Please check our supplementary materials $\href{https://docs.google.com/presentation/d/1Vr-F8ZskrSd63tvnLfJ2xmEXY6OBc1Rll3XeOAtc11I/}{online}$ to better appreciate the reconstructed light fields.
Shape Evasion: Preventing Body Shape Inference of Multi-Stage Approaches
May 27, 2019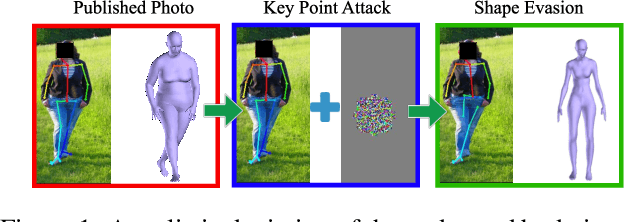



Modern approaches to pose and body shape estimation have recently achieved strong performance even under challenging real-world conditions. Even from a single image of a clothed person, a realistic looking body shape can be inferred that captures a users' weight group and body shape type well. This opens up a whole spectrum of applications -- in particular in fashion -- where virtual try-on and recommendation systems can make use of these new and automatized cues. However, a realistic depiction of the undressed body is regarded highly private and therefore might not be consented by most people. Hence, we ask if the automatic extraction of such information can be effectively evaded. While adversarial perturbations have been shown to be effective for manipulating the output of machine learning models -- in particular, end-to-end deep learning approaches -- state of the art shape estimation methods are composed of multiple stages. We perform the first investigation of different strategies that can be used to effectively manipulate the automatic shape estimation while preserving the overall appearance of the original image.