 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
"Looking at the right stuff" -- Guided semantic-gaze for autonomous driving
Nov 24, 2019




In recent years, predicting driver's focus of attention has been a very active area of research in the autonomous driving community. Unfortunately, existing state-of-the-art techniques achieve this by relying only on human gaze information, thereby ignoring scene semantics. We propose a novel Semantics Augmented GazE (SAGE) detection approach that captures driving specific contextual information, in addition to the raw gaze. Such a combined attention mechanism serves as a powerful tool to focus on the relevant regions in an image frame in order to make driving both safe and efficient. Using this, we design a complete saliency prediction framework -- SAGE-Net, which modifies the initial prediction from SAGE by taking into account vital aspects such as distance to objects (depth), ego vehicle speed, and pedestrian crossing intent. Exhaustive experiments conducted through four popular saliency algorithms show that on 49/56 (87.5%) cases -- considering both the overall dataset and crucial driving scenarios, SAGE outperforms existing techniques without any additional computational overhead during the training process. The final paper will be accompanied by the release of our dataset and relevant code.
Deep Cytometry
Apr 09, 2019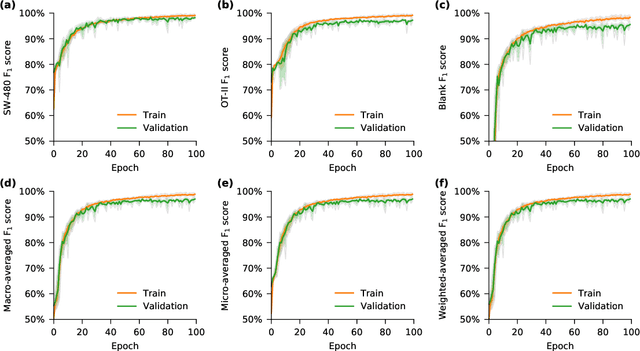
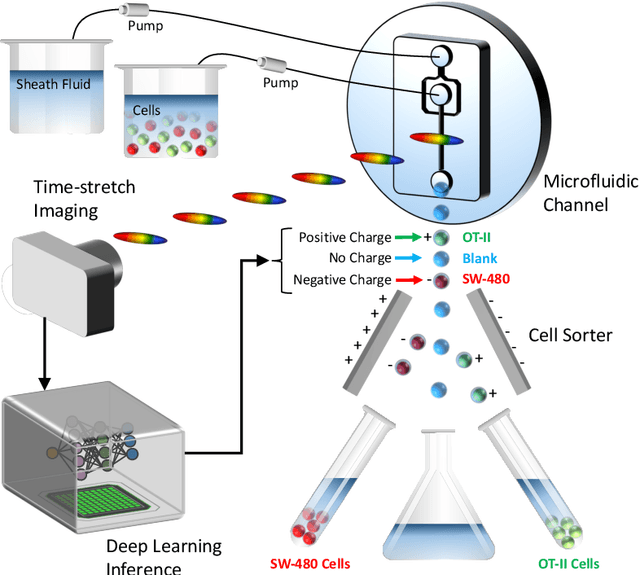
Deep learning has achieved spectacular performance in image and speech recognition and synthesis. It outperforms other machine learning algorithms in problems where large amounts of data are available. In the area of measurement technology, instruments based on the Photonic Time Stretch have established record real-time measurement throughput in spectroscopy, optical coherence tomography, and imaging flow cytometry. These extreme-throughput instruments generate approximately 1 Tbit/s of continuous measurement data and have led to the discovery of rare phenomena in nonlinear and complex systems as well as new types of biomedical instruments. Owing to the abundance of data they generate, time stretch instruments are a natural fit to deep learning classification. Previously we had shown that high-throughput label-free cell classification with high accuracy can be achieved through a combination of time stretch microscopy, image processing and feature extraction, followed by deep learning for finding cancer cells in the blood. Such a technology holds promise for early detection of primary cancer or metastasis. Here we describe a new implementation of deep learning which entirely avoids the computationally costly image processing and feature extraction pipeline. The improvement in computational efficiency makes this new technology suitable for cell sorting via deep learning. Our neural network takes less than a millisecond to classify the cells, fast enough to provide a decision to a cell sorter. We demonstrate the applicability of our new method in the classification of OT-II white blood cells and SW-480 epithelial cancer cells with more than 95\% accuracy in a label-free fashion.
Grounding Language Attributes to Objects using Bayesian Eigenobjects
May 30, 2019
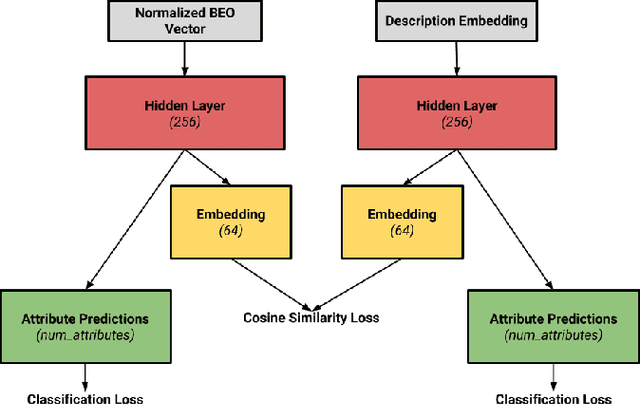
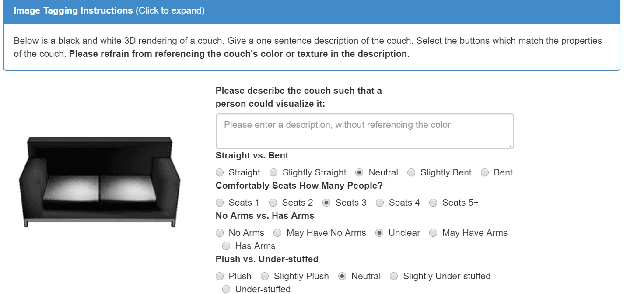
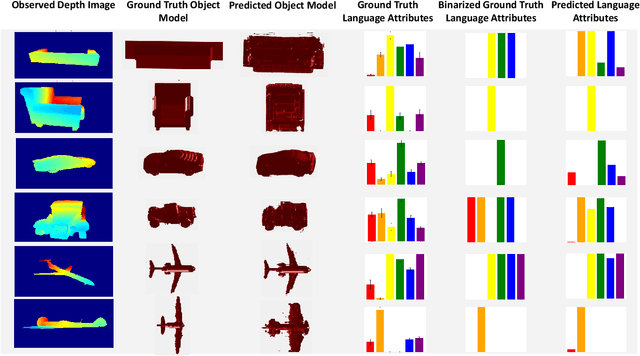
We develop a system to disambiguate objects based on simple physical descriptions. The system takes as input a natural language phrase and a depth image containing a segmented object and predicts how similar the observed object is to the described object. Our system is designed to learn from only a small amount of human-labeled language data and generalize to viewpoints not represented in the language-annotated depth-image training set. By decoupling 3D shape representation from language representation, our method is able to ground language to novel objects using a small amount of language-annotated depth-data and a larger corpus of unlabeled 3D object meshes, even when these objects are partially observed from unusual viewpoints. Our system is able to disambiguate between novel objects, observed via depth-images, based on natural language descriptions. Our method also enables view-point transfer; trained on human-annotated data on a small set of depth-images captured from frontal viewpoints, our system successfully predicted object attributes from rear views despite having no such depth images in its training set. Finally, we demonstrate our system on a Baxter robot, enabling it to pick specific objects based on human-provided natural language descriptions.
Bipartite Conditional Random Fields for Panoptic Segmentation
Dec 11, 2019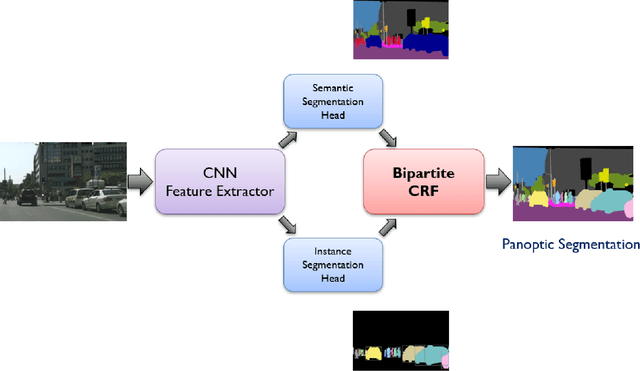
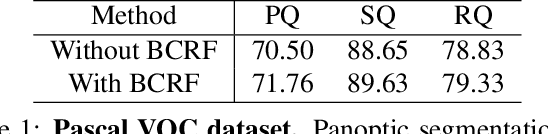
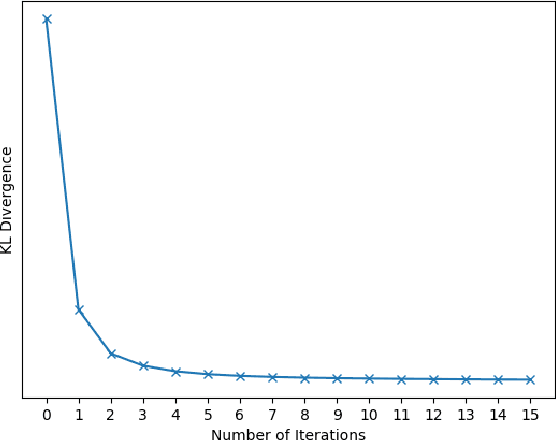

We tackle the panoptic segmentation problem with a conditional random field (CRF) model. Panoptic segmentation involves assigning a semantic label and an instance label to each pixel of a given image. At each pixel, the semantic label and the instance label should be compatible. Furthermore, a good panoptic segmentation should have a number of other desirable properties such as the spatial and color consistency of the labeling (similar looking neighboring pixels should have the same semantic label and the instance label). To tackle this problem, we propose a CRF model, named Bipartite CRF or BCRF, with two types of random variables for semantic and instance labels. In this formulation, various energies are defined within and across the two types of random variables to encourage a consistent panoptic segmentation. We propose a mean-field-based efficient inference algorithm for solving the CRF and empirically show its convergence properties. This algorithm is fully differentiable, and therefore, BCRF inference can be included as a trainable module in a deep network. In the experimental evaluation, we quantitatively and qualitatively show that the BCRF yields superior panoptic segmentation results in practice.
Learning to discover and localize visual objects with open vocabulary
Nov 25, 2018
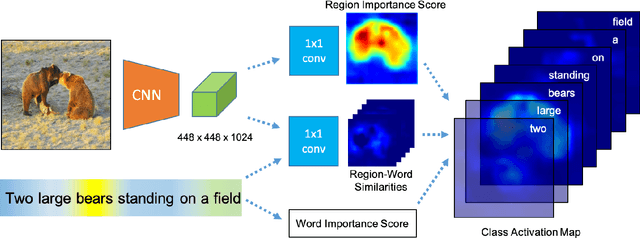

To alleviate the cost of obtaining accurate bounding boxes for training today's state-of-the-art object detection models, recent weakly supervised detection work has proposed techniques to learn from image-level labels. However, requiring discrete image-level labels is both restrictive and suboptimal. Real-world "supervision" usually consists of more unstructured text, such as captions. In this work we learn association maps between images and captions. We then use a novel objectness criterion to rank the resulting candidate boxes, such that high-ranking boxes have strong gradients along all edges. Thus, we can detect objects beyond a fixed object category vocabulary, if those objects are frequent and distinctive enough. We show that our objectness criterion improves the proposed bounding boxes in relation to prior weakly supervised detection methods. Further, we show encouraging results on object detection from image-level captions only.
Weakly Supervised Learning of Instance Segmentation with Inter-pixel Relations
May 10, 2019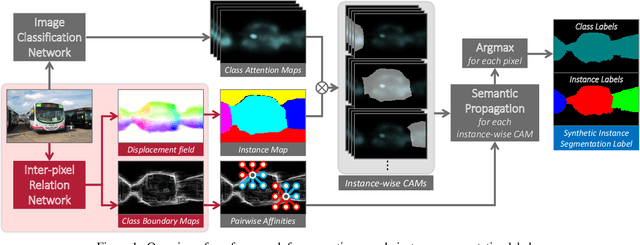

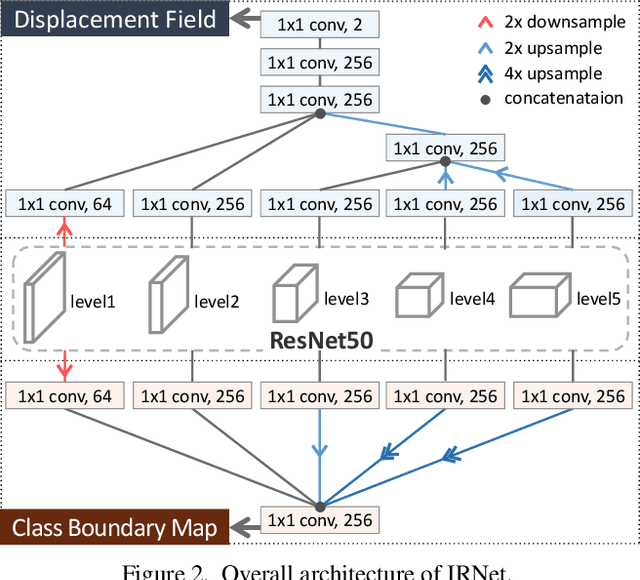

This paper presents a novel approach for learning instance segmentation with image-level class labels as supervision. Our approach generates pseudo instance segmentation labels of training images, which are used to train a fully supervised model. For generating the pseudo labels, we first identify confident seed areas of object classes from attention maps of an image classification model, and propagate them to discover the entire instance areas with accurate boundaries. To this end, we propose IRNet, which estimates rough areas of individual instances and detects boundaries between different object classes. It thus enables to assign instance labels to the seeds and to propagate them within the boundaries so that the entire areas of instances can be estimated accurately. Furthermore, IRNet is trained with inter-pixel relations on the attention maps, thus no extra supervision is required. Our method with IRNet achieves an outstanding performance on the PASCAL VOC 2012 dataset, surpassing not only previous state-of-the-art trained with the same level of supervision, but also some of previous models relying on stronger supervision.
HistoNet: Predicting size histograms of object instances
Dec 11, 2019
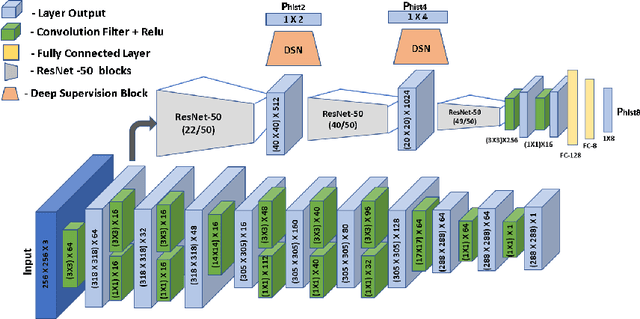


We propose to predict histograms of object sizes in crowded scenes directly without any explicit object instance segmentation. What makes this task challenging is the high density of objects (of the same category), which makes instance identification hard. Instead of explicitly segmenting object instances, we show that directly learning histograms of object sizes improves accuracy while using drastically less parameters. This is very useful for application scenarios where explicit, pixel-accurate instance segmentation is not needed, but there lies interest in the overall distribution of instance sizes. Our core applications are in biology, where we estimate the size distribution of soldier fly larvae, and medicine, where we estimate the size distribution of cancer cells as an intermediate step to calculate the tumor cellularity score. Given an image with hundreds of small object instances, we output the total count and the size histogram. We also provide a new data set for this task, the FlyLarvae data set, which consists of 11,000 larvae instances labeled pixel-wise. Our method results in an overall improvement in the count and size distribution prediction as compared to state-of-the-art instance segmentation method Mask R-CNN.
Contextualize, Show and Tell: A Neural Visual Storyteller
Jun 03, 2018
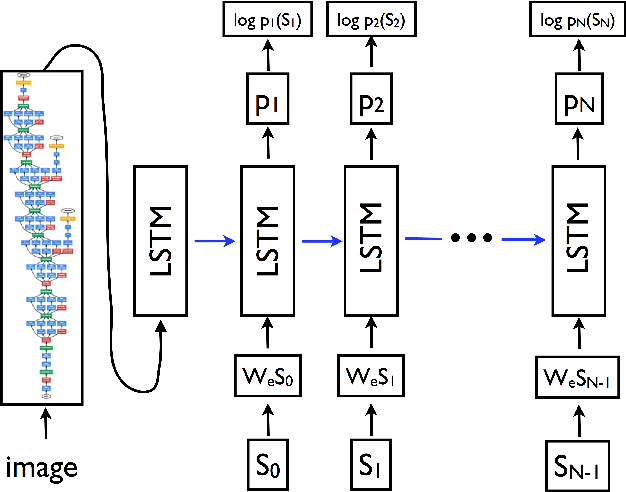

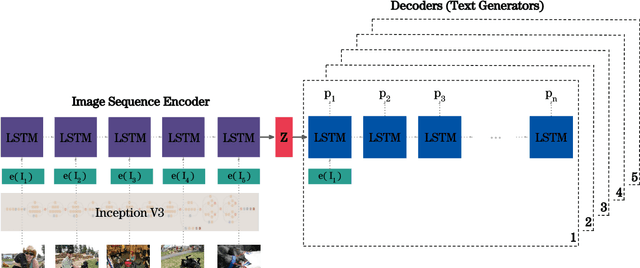
We present a neural model for generating short stories from image sequences, which extends the image description model by Vinyals et al. (Vinyals et al., 2015). This extension relies on an encoder LSTM to compute a context vector of each story from the image sequence. This context vector is used as the first state of multiple independent decoder LSTMs, each of which generates the portion of the story corresponding to each image in the sequence by taking the image embedding as the first input. Our model showed competitive results with the METEOR metric and human ratings in the internal track of the Visual Storytelling Challenge 2018.
Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond
Nov 06, 2018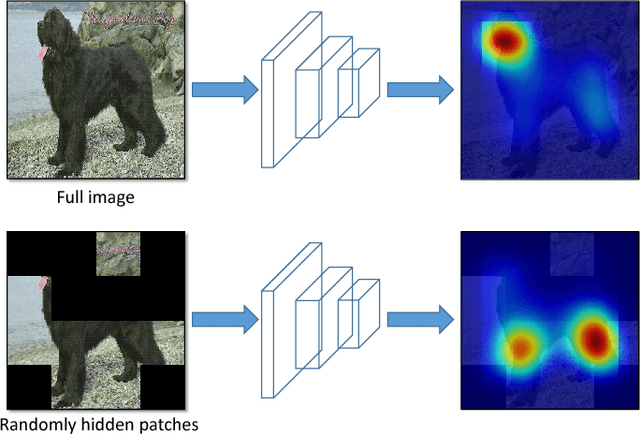
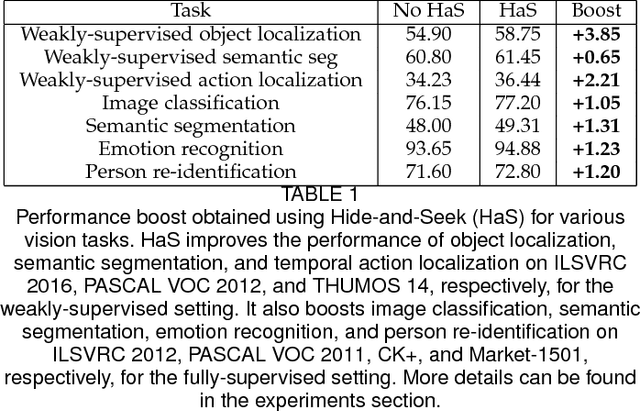
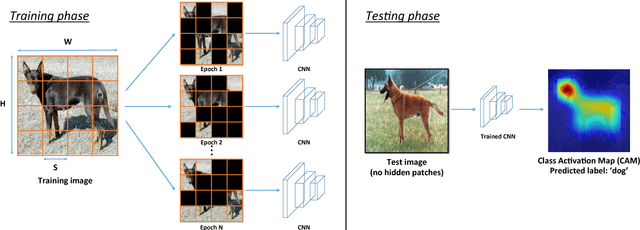
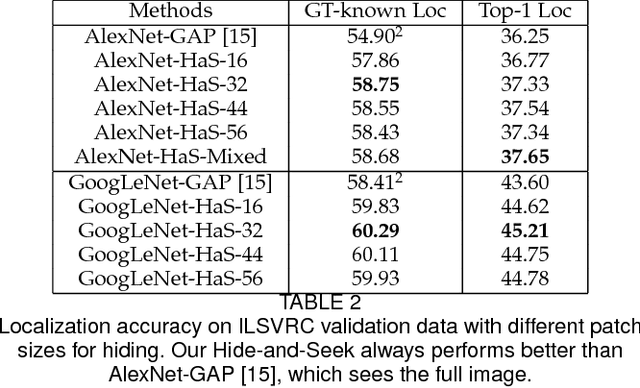
We propose 'Hide-and-Seek' a general purpose data augmentation technique, which is complementary to existing data augmentation techniques and is beneficial for various visual recognition tasks. The key idea is to hide patches in a training image randomly, in order to force the network to seek other relevant content when the most discriminative content is hidden. Our approach only needs to modify the input image and can work with any network to improve its performance. During testing, it does not need to hide any patches. The main advantage of Hide-and-Seek over existing data augmentation techniques is its ability to improve object localization accuracy in the weakly-supervised setting, and we therefore use this task to motivate the approach. However, Hide-and-Seek is not tied only to the image localization task, and can generalize to other forms of visual input like videos, as well as other recognition tasks like image classification, temporal action localization, semantic segmentation, emotion recognition, age/gender estimation, and person re-identification. We perform extensive experiments to showcase the advantage of Hide-and-Seek on these various visual recognition problems.
Effortless Deep Training for Traffic Sign Detection Using Templates and Arbitrary Natural Images
Jul 23, 2019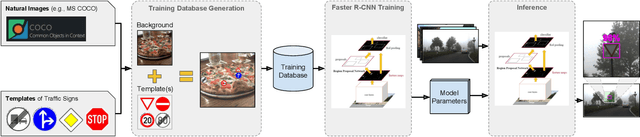



Deep learning has been successfully applied to several problems related to autonomous driving. Often, these solutions rely on large networks that require databases of real image samples of the problem (i.e., real world) for proper training. The acquisition of such real-world data sets is not always possible in the autonomous driving context, and sometimes their annotation is not feasible (e.g., takes too long or is too expensive). Moreover, in many tasks, there is an intrinsic data imbalance that most learning-based methods struggle to cope with. It turns out that traffic sign detection is a problem in which these three issues are seen altogether. In this work, we propose a novel database generation method that requires only (i) arbitrary natural images, i.e., requires no real image from the domain of interest, and (ii) templates of the traffic signs, i.e., templates synthetically created to illustrate the appearance of the category of a traffic sign. The effortlessly generated training database is shown to be effective for the training of a deep detector (such as Faster R-CNN) on German traffic signs, achieving 95.66% of mAP on average. In addition, the proposed method is able to detect traffic signs with an average precision, recall and F1-score of about 94%, 91% and 93%, respectively. The experiments surprisingly show that detectors can be trained with simple data generation methods and without problem domain data for the background, which is in the opposite direction of the common sense for deep learning.