 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Very Deep Convolutional Networks for Large-Scale Image Recognition
Apr 10, 2015
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalise well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
Unsupervised Automated Event Detection using an Iterative Clustering based Segmentation Approach
Jan 22, 2019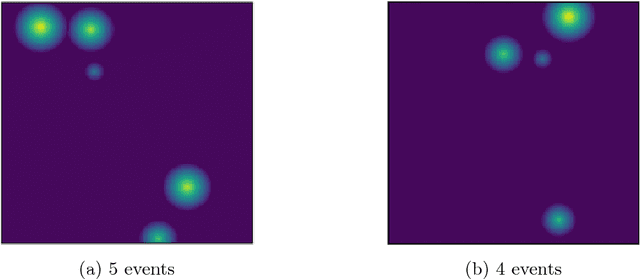
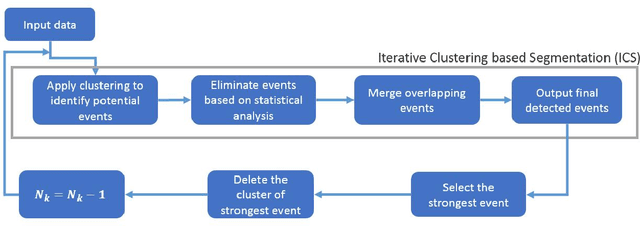
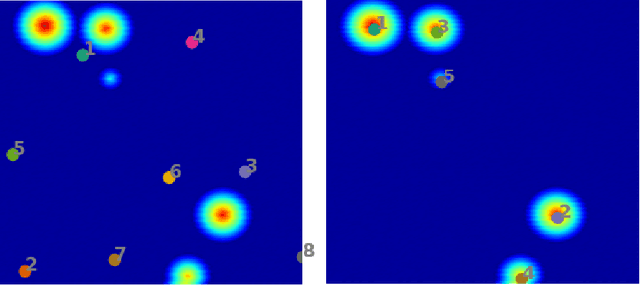
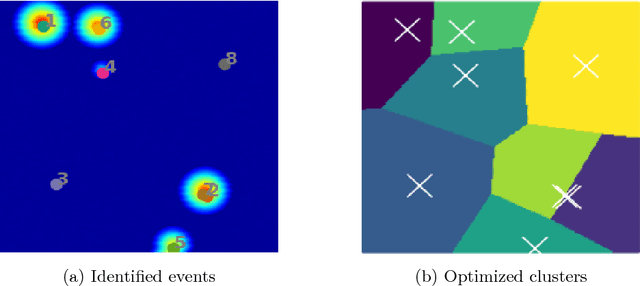
A class of vision problems, less commonly studied, consists of detecting objects in imagery obtained from physics-based experiments. These objects can span in 4D (x, y, z, t) and are visible as disturbances (caused due to physical phenomena) in the image with background distribution being approximately uniform. Such objects, occasionally referred to as `events', can be considered as high energy blobs in the image. Unlike the images analyzed in conventional vision problems, very limited features are associated with such events, and their shape, size and count can vary significantly. This poses a challenge on the use of pre-trained models obtained from supervised approaches. In this paper, we propose an unsupervised approach involving iterative clustering based segmentation (ICS) which can detect target objects (events) in real-time. In this approach, a test image is analyzed over several cycles, and one event is identified per cycle. Each cycle consists of the following steps: (1) image segmentation using a modified k-means clustering method, (2) elimination of empty (with no events) segments based on statistical analysis of each segment, (3) merging segments that overlap (correspond to same event), and (4) selecting the strongest event. These four steps are repeated until all the events have been identified. The ICS approach consists of a few hyper-parameters that have been chosen based on statistical study performed over a set of test images. The applicability of ICS method is demonstrated on several 2D and 3D test examples.
Adaptive Leader-Follower Formation Control and Obstacle Avoidance via Deep Reinforcement Learning
Nov 15, 2019
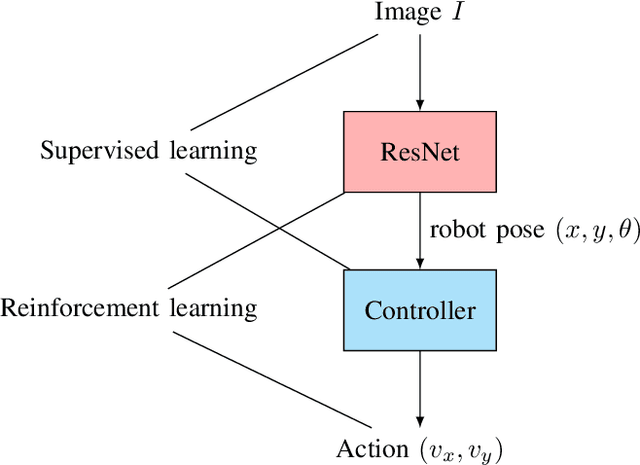
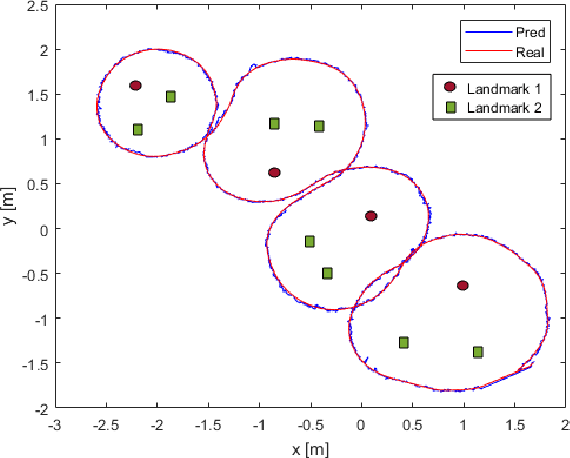
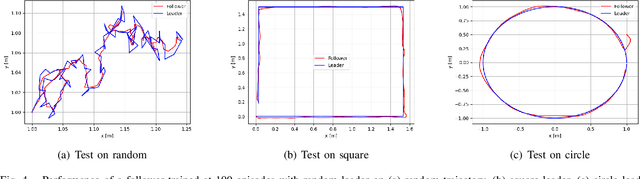
We propose a deep reinforcement learning (DRL) methodology for the tracking, obstacle avoidance, and formation control of nonholonomic robots. By separating vision-based control into a perception module and a controller module, we can train a DRL agent without sophisticated physics or 3D modeling. In addition, the modular framework averts daunting retrains of an image-to-action end-to-end neural network, and provides flexibility in transferring the controller to different robots. First, we train a convolutional neural network (CNN) to accurately localize in an indoor setting with dynamic foreground/background. Then, we design a new DRL algorithm named Momentum Policy Gradient (MPG) for continuous control tasks and prove its convergence. We also show that MPG is robust at tracking varying leader movements and can naturally be extended to problems of formation control. Leveraging reward shaping, features such as collision and obstacle avoidance can be easily integrated into a DRL controller.
* Accepted IROS 2019 paper with minor revisions
Automatic classification of geologic units in seismic images using partially interpreted examples
Jan 12, 2019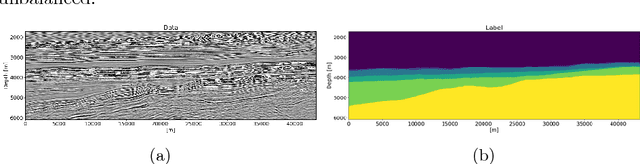
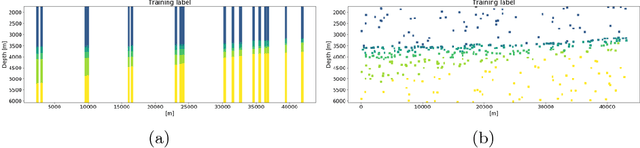
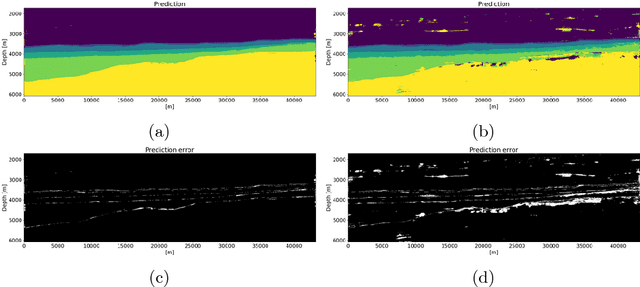
Geologic interpretation of large seismic stacked or migrated seismic images can be a time-consuming task for seismic interpreters. Neural network based semantic segmentation provides fast and automatic interpretations, provided a sufficient number of example interpretations are available. Networks that map from image-to-image emerged recently as powerful tools for automatic segmentation, but standard implementations require fully interpreted examples. Generating training labels for large images manually is time consuming. We introduce a partial loss-function and labeling strategies such that networks can learn from partially interpreted seismic images. This strategy requires only a small number of annotated pixels per seismic image. Tests on seismic images and interpretation information from the Sea of Ireland show that we obtain high-quality predicted interpretations from a small number of large seismic images. The combination of a partial-loss function, a multi-resolution network that explicitly takes small and large-scale geological features into account, and new labeling strategies make neural networks a more practical tool for automatic seismic interpretation.
MMGAN: Generative Adversarial Networks for Multi-Modal Distributions
Nov 15, 2019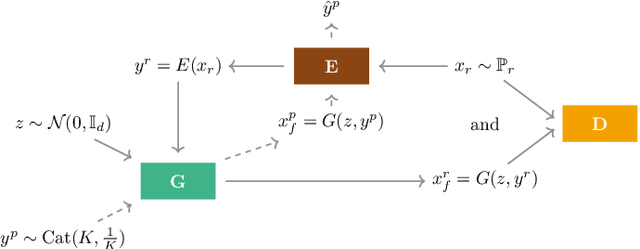
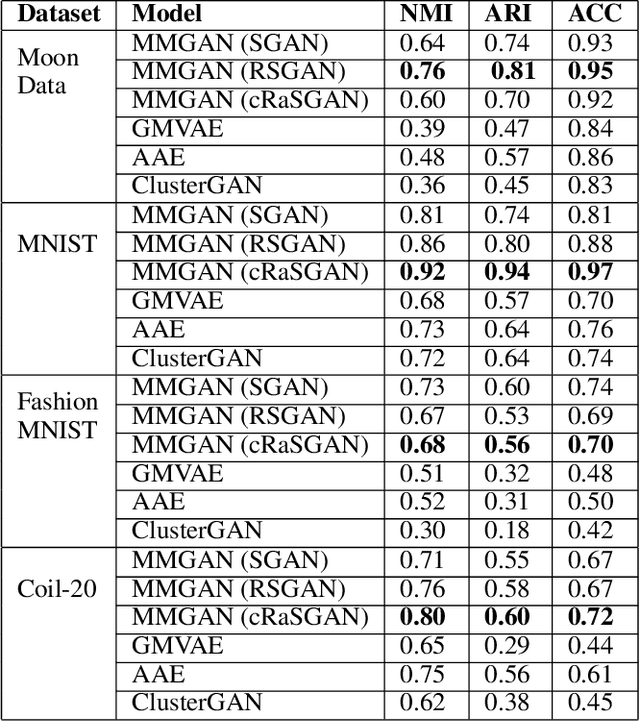
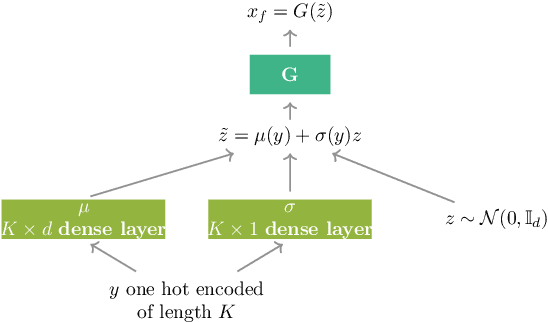
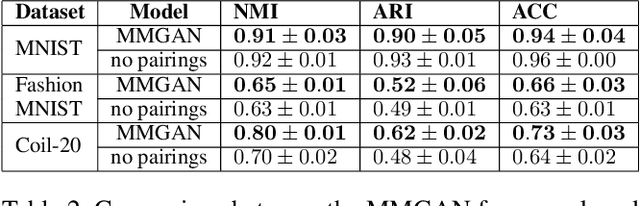
Over the past years, Generative Adversarial Networks (GANs) have shown a remarkable generation performance especially in image synthesis. Unfortunately, they are also known for having an unstable training process and might loose parts of the data distribution for heterogeneous input data. In this paper, we propose a novel GAN extension for multi-modal distribution learning (MMGAN). In our approach, we model the latent space as a Gaussian mixture model with a number of clusters referring to the number of disconnected data manifolds in the observation space, and include a clustering network, which relates each data manifold to one Gaussian cluster. Thus, the training gets more stable. Moreover, MMGAN allows for clustering real data according to the learned data manifold in the latent space. By a series of benchmark experiments, we illustrate that MMGAN outperforms competitive state-of-the-art models in terms of clustering performance.
Liver Segmentation in Abdominal CT Images via Auto-Context Neural Network and Self-Supervised Contour Attention
Feb 14, 2020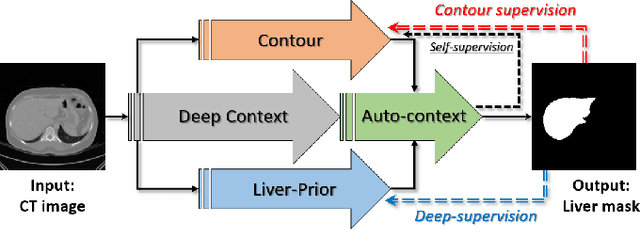
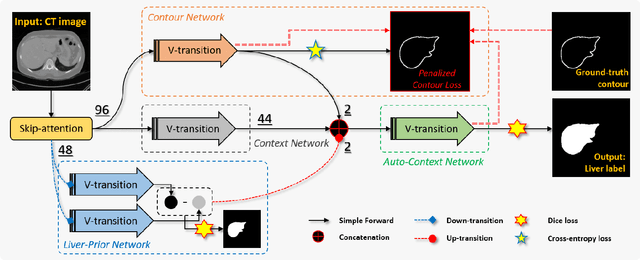
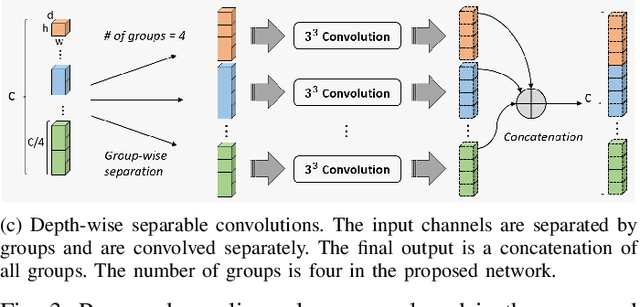
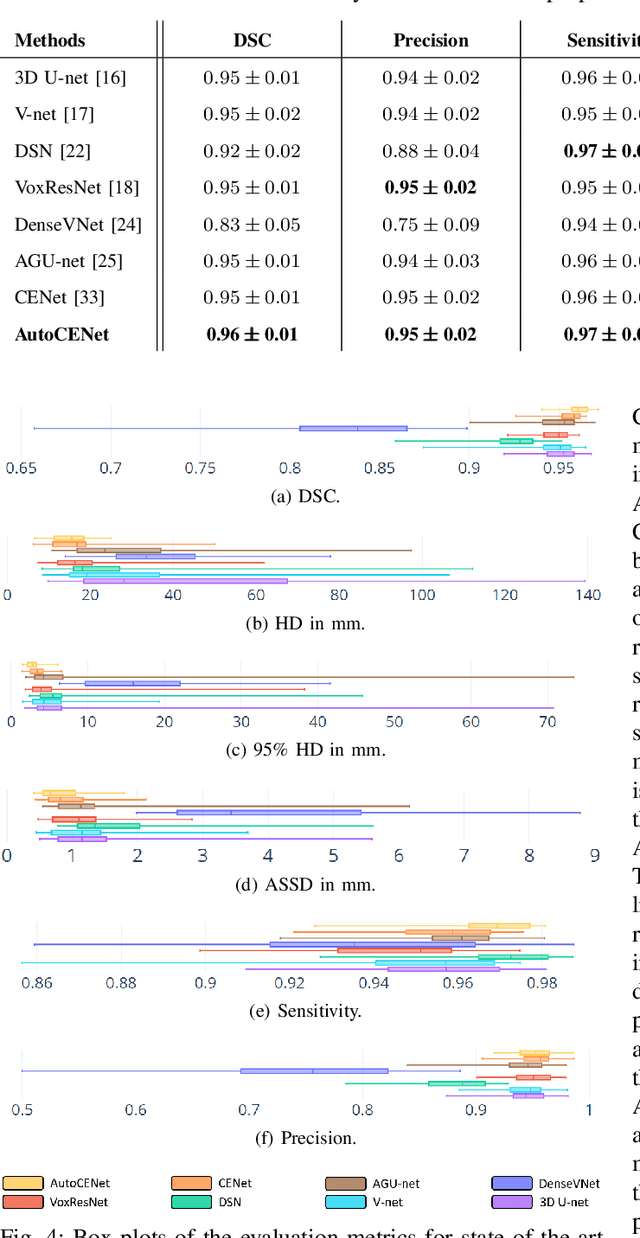
Accurate image segmentation of the liver is a challenging problem owing to its large shape variability and unclear boundaries. Although the applications of fully convolutional neural networks (CNNs) have shown groundbreaking results, limited studies have focused on the performance of generalization. In this study, we introduce a CNN for liver segmentation on abdominal computed tomography (CT) images that shows high generalization performance and accuracy. To improve the generalization performance, we initially propose an auto-context algorithm in a single CNN. The proposed auto-context neural network exploits an effective high-level residual estimation to obtain the shape prior. Identical dual paths are effectively trained to represent mutual complementary features for an accurate posterior analysis of a liver. Further, we extend our network by employing a self-supervised contour scheme. We trained sparse contour features by penalizing the ground-truth contour to focus more contour attentions on the failures. The experimental results show that the proposed network results in better accuracy when compared to the state-of-the-art networks by reducing 10.31% of the Hausdorff distance. We used 180 abdominal CT images for training and validation. Two-fold cross-validation is presented for a comparison with the state-of-the-art neural networks. Novel multiple N-fold cross-validations are conducted to verify the performance of generalization. The proposed network showed the best generalization performance among the networks. Additionally, we present a series of ablation experiments that comprehensively support the importance of the underlying concepts.
Use of Ghost Cytometry to Differentiate Cells with Similar Gross Morphologic Characteristics
Mar 22, 2019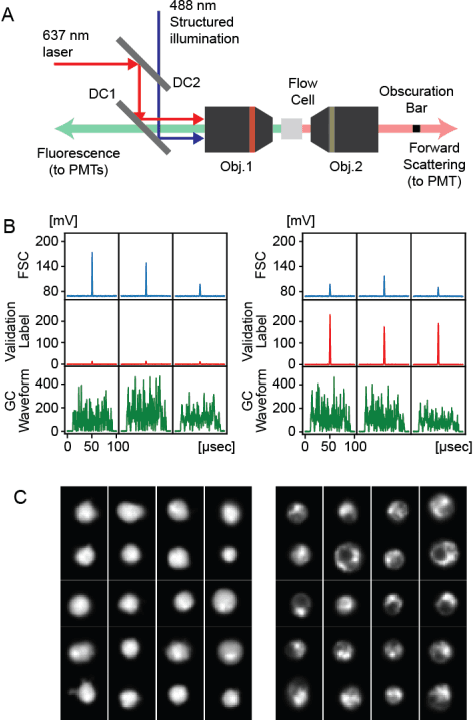
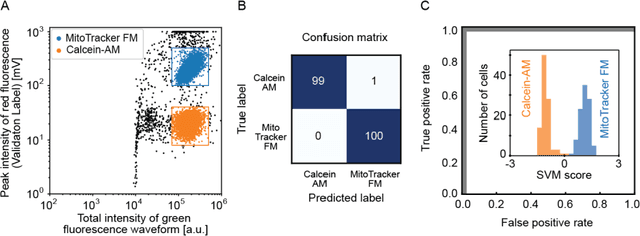
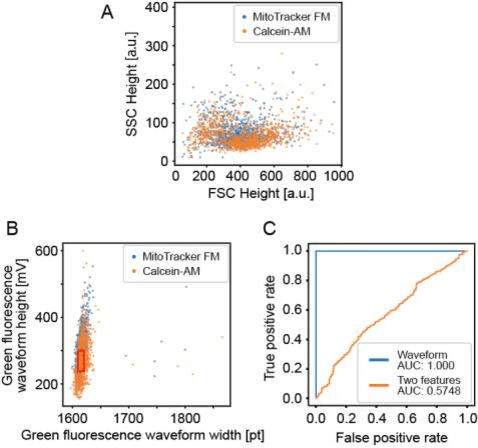
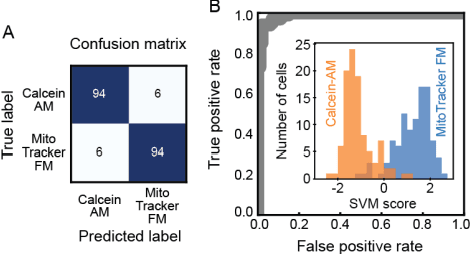
Imaging flow cytometry shows significant potential for increasing our understanding of heterogeneous and complex life systems and is useful for biomedical applications. Ghost cytometry is a recently proposed approach for directly analyzing compressively measured signals, thereby relieving the computational bottleneck observed in high-throughput cytometry based on morphological information. While this image-free approach could distinguish different cell types using the same fluorescence staining method, further strict controls are sometimes required to clearly demonstrate that the classification is based on detailed morphologic analysis. In this study, we show that ghost cytometry can be used to classify cell populations of the same type but with different fluorescence distributions in space, supporting the strength of our image-free approach for morphologic cell analysis.
Technical Report: Co-learning of geometry and semantics for online 3D mapping
Nov 04, 2019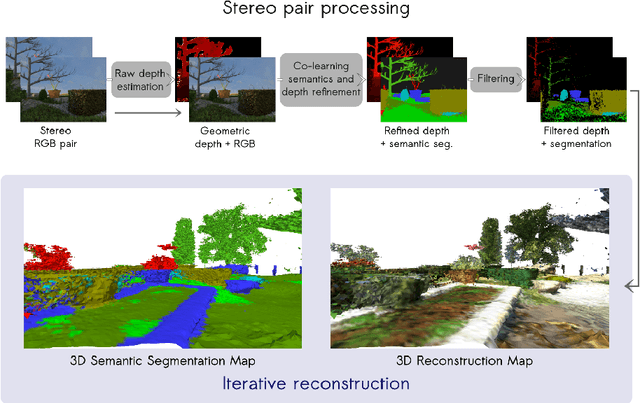

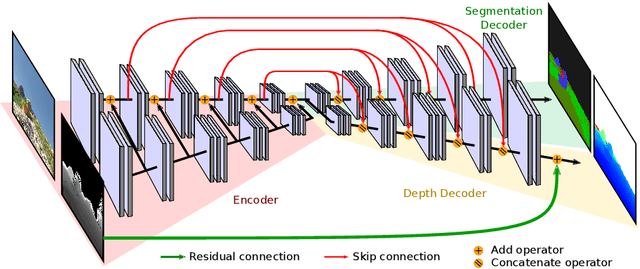
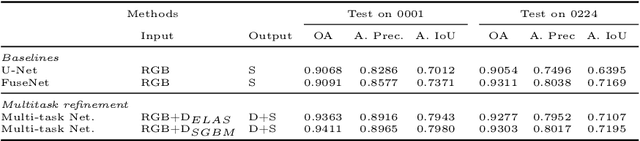
This paper is a technical report about our submission for the ECCV 2018 3DRMS Workshop Challenge on Semantic 3D Reconstruction \cite{Tylecek2018rms}. In this paper, we address 3D semantic reconstruction for autonomous navigation using co-learning of depth map and semantic segmentation. The core of our pipeline is a deep multi-task neural network which tightly refines depth and also produces accurate semantic segmentation maps. Its inputs are an image and a raw depth map produced from a pair of images by standard stereo vision. The resulting semantic 3D point clouds are then merged in order to create a consistent 3D mesh, in turn used to produce dense semantic 3D reconstruction maps. The performances of each step of the proposed method are evaluated on the dataset and multiple tasks of the 3DRMS Challenge, and repeatedly surpass state-of-the-art approaches.
Unsupervised Event-based Learning of Optical Flow, Depth, and Egomotion
Dec 19, 2018
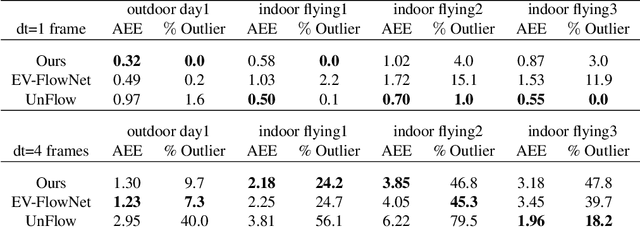
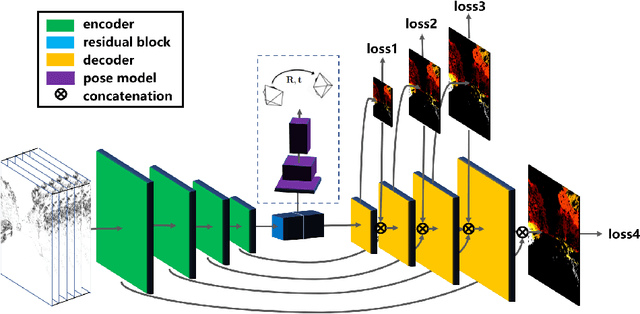
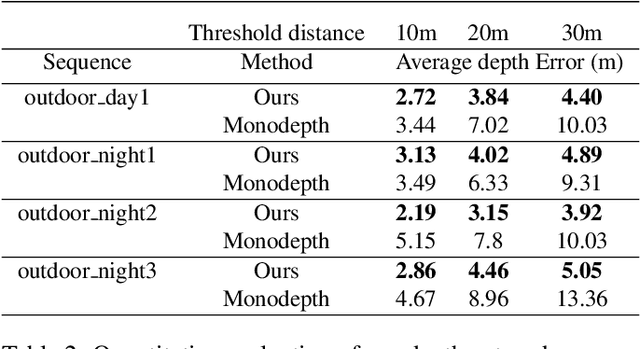
In this work, we propose a novel framework for unsupervised learning for event cameras that learns motion information from only the event stream. In particular, we propose an input representation of the events in the form of a discretized volume that maintains the temporal distribution of the events, which we pass through a neural network to predict the motion of the events. This motion is used to attempt to remove any motion blur in the event image. We then propose a loss function applied to the motion compensated event image that measures the motion blur in this image. We train two networks with this framework, one to predict optical flow, and one to predict egomotion and depths, and evaluate these networks on the Multi Vehicle Stereo Event Camera dataset, along with qualitative results from a variety of different scenes.
FakeSpotter: A Simple Baseline for Spotting AI-Synthesized Fake Faces
Sep 13, 2019
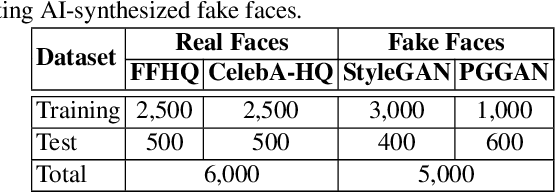
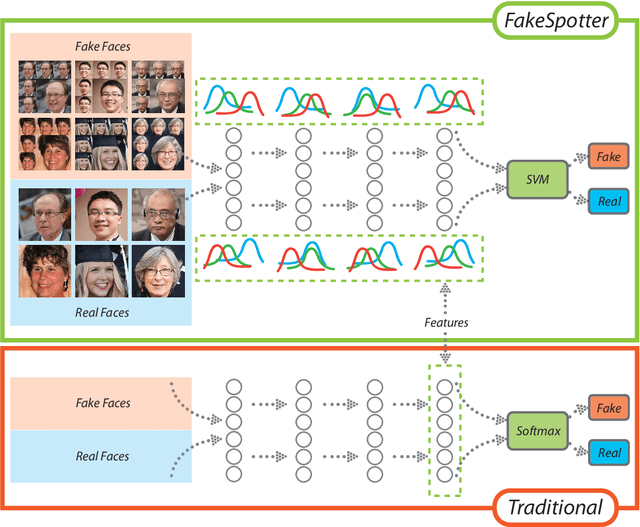
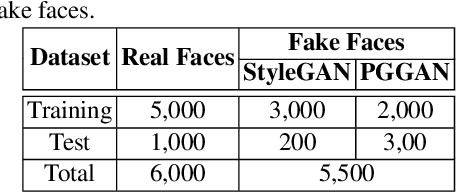
In recent years, we have witnessed the unprecedented success of generative adversarial networks (GANs) and its variants in image synthesis. These techniques are widely adopted in synthesizing fake faces which poses a serious challenge to existing face recognition (FR) systems and brings potential security threats to social networks and media as the fakes spread and fuel the misinformation. Unfortunately, robust detectors of these AI-synthesized fake faces are still in their infancy and are not ready to fully tackle this emerging challenge. Currently, image forensic-based and learning-based approaches are the two major categories of strategies in detecting fake faces. In this work, we propose an alternative category of approaches based on monitoring neuron behavior. The studies on neuron coverage and interactions have successfully shown that they can be served as testing criteria for deep learning systems, especially under the settings of being exposed to adversarial attacks. Here, we conjecture that monitoring neuron behavior can also serve as an asset in detecting fake faces since layer-by-layer neuron activation patterns may capture more subtle features that are important for the fake detector. Empirically, we have shown that the proposed FakeSpotter, based on neuron coverage behavior, in tandem with a simple linear classifier can greatly outperform deeply trained convolutional neural networks (CNNs) for spotting AI-synthesized fake faces. Extensive experiments carried out on three deep learning (DL) based FR systems, with two GAN variants for synthesizing fake faces, and on two public high-resolution face datasets have demonstrated the potential of the FakeSpotter serving as a simple, yet robust baseline for fake face detection in the wild.