 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FaultNet: Faulty Rail-Valves Detection using Deep Learning and Computer Vision
Nov 09, 2019


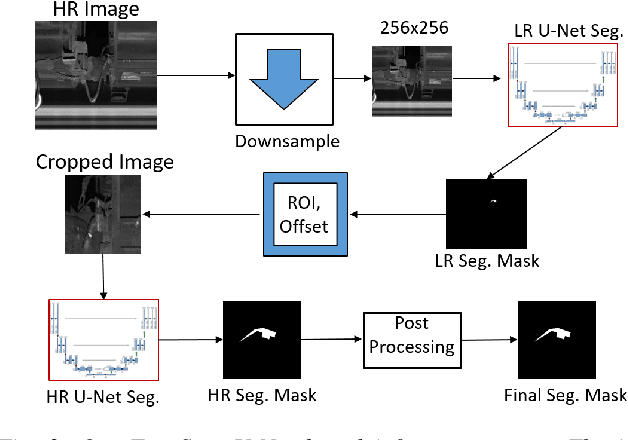
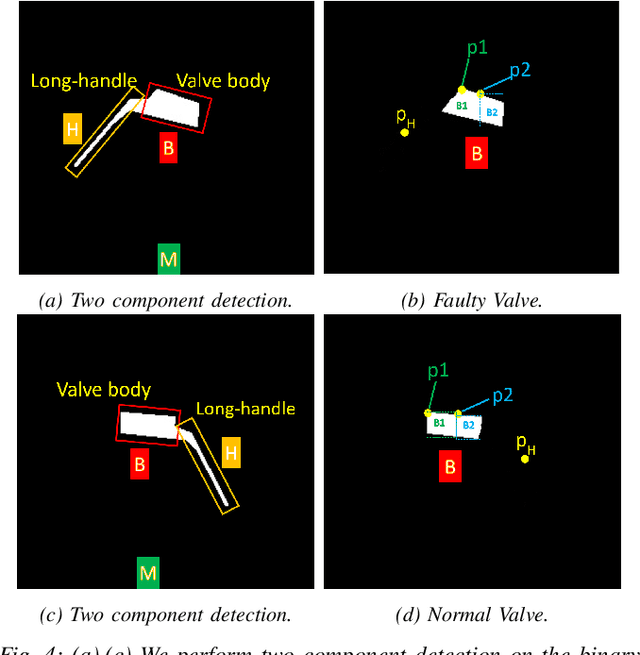
Regular inspection of rail valves and engines is an important task to ensure the safety and efficiency of railway networks around the globe. Over the past decade, computer vision and pattern recognition based techniques have gained traction for such inspection and defect detection tasks. An automated end-to-end trained system can potentially provide a low-cost, high throughput, and cheap alternative to manual visual inspection of these components. However, such systems require a huge amount of defective images for networks to understand complex defects. In this paper, a multi-phase deep learning based technique is proposed to perform accurate fault detection of rail-valves. Our approach uses a two-step method to perform high precision image segmentation of rail-valves resulting in pixel-wise accurate segmentation. Thereafter, a computer vision technique is used to identify faulty valves. We demonstrate that the proposed approach results in improved detection performance when compared to current state-of-theart techniques used in fault detection.
* 8 pages, 8 figures, ITSC 2019
Beyond Narrative Description: Generating Poetry from Images by Multi-Adversarial Training
Oct 10, 2018
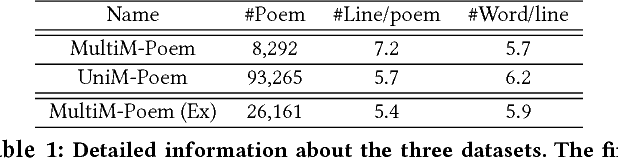
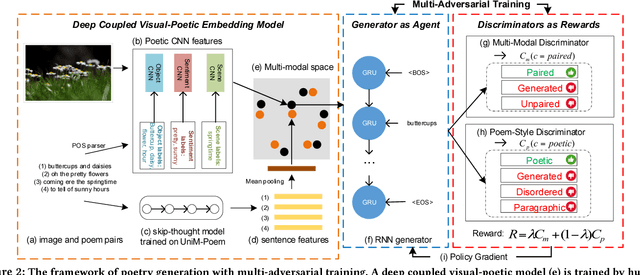

Automatic generation of natural language from images has attracted extensive attention. In this paper, we take one step further to investigate generation of poetic language (with multiple lines) to an image for automatic poetry creation. This task involves multiple challenges, including discovering poetic clues from the image (e.g., hope from green), and generating poems to satisfy both relevance to the image and poeticness in language level. To solve the above challenges, we formulate the task of poem generation into two correlated sub-tasks by multi-adversarial training via policy gradient, through which the cross-modal relevance and poetic language style can be ensured. To extract poetic clues from images, we propose to learn a deep coupled visual-poetic embedding, in which the poetic representation from objects, sentiments and scenes in an image can be jointly learned. Two discriminative networks are further introduced to guide the poem generation, including a multi-modal discriminator and a poem-style discriminator. To facilitate the research, we have released two poem datasets by human annotators with two distinct properties: 1) the first human annotated image-to-poem pair dataset (with 8,292 pairs in total), and 2) to-date the largest public English poem corpus dataset (with 92,265 different poems in total). Extensive experiments are conducted with 8K images, among which 1.5K image are randomly picked for evaluation. Both objective and subjective evaluations show the superior performances against the state-of-the-art methods for poem generation from images. Turing test carried out with over 500 human subjects, among which 30 evaluators are poetry experts, demonstrates the effectiveness of our approach.
Unified Visual-Semantic Embeddings: Bridging Vision and Language with Structured Meaning Representations
Apr 11, 2019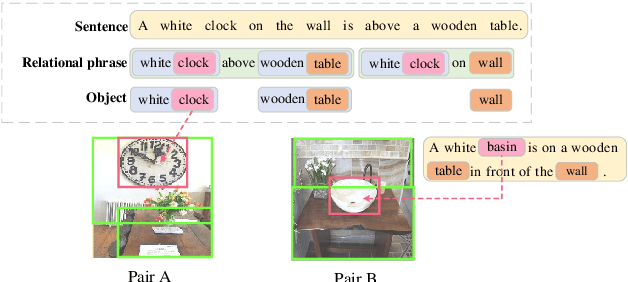

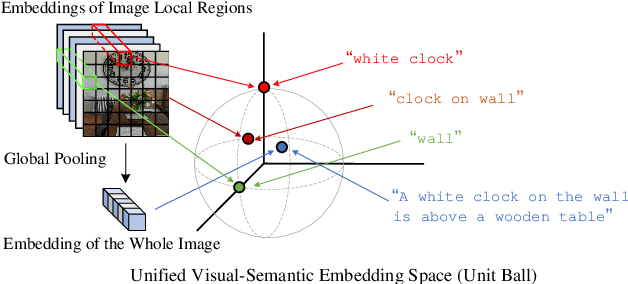

We propose the Unified Visual-Semantic Embeddings (Unified VSE) for learning a joint space of visual representation and textual semantics. The model unifies the embeddings of concepts at different levels: objects, attributes, relations, and full scenes. We view the sentential semantics as a combination of different semantic components such as objects and relations; their embeddings are aligned with different image regions. A contrastive learning approach is proposed for the effective learning of this fine-grained alignment from only image-caption pairs. We also present a simple yet effective approach that enforces the coverage of caption embeddings on the semantic components that appear in the sentence. We demonstrate that the Unified VSE outperforms baselines on cross-modal retrieval tasks; the enforcement of the semantic coverage improves the model's robustness in defending text-domain adversarial attacks. Moreover, our model empowers the use of visual cues to accurately resolve word dependencies in novel sentences.
Non-locally Encoder-Decoder Convolutional Network for Whole Brain QSM Inversion
Apr 11, 2019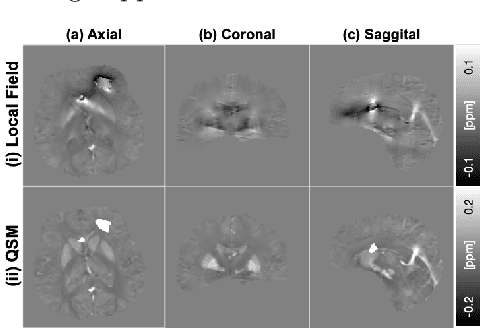

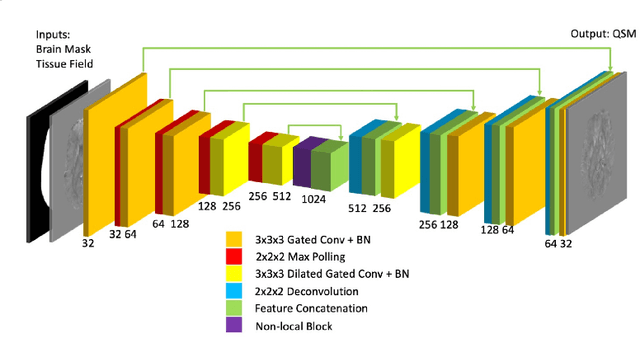
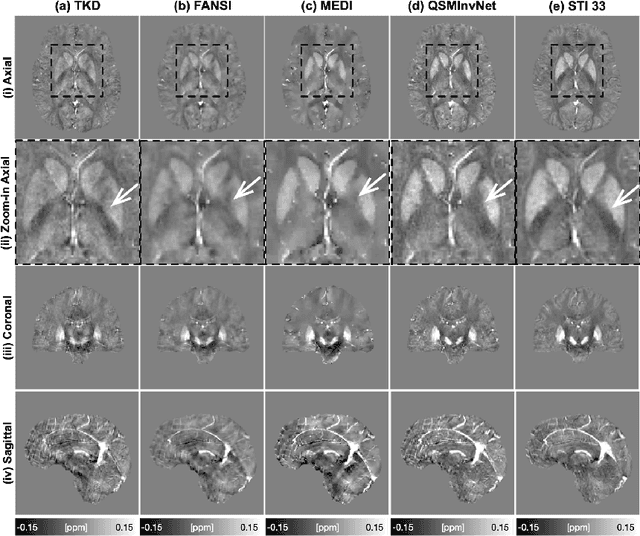
Quantitative Susceptibility Mapping (QSM) reconstruction is a challenging inverse problem driven by ill conditioning of its field-to -susceptibility transformation. State-of-art QSM reconstruction methods either suffer from image artifacts or long computation times, which limits QSM clinical translation efforts. To overcome these limitations, a non-locally encoder-decoder gated convolutional neural network is trained to infer whole brain susceptibility map, using the local field and brain mask as the inputs. The performance of the proposed method is evaluated relative to synthetic data, a publicly available challenge dataset, and clinical datasets. The proposed approach can outperform existing methods on quantitative metrics and visual assessment of image sharpness and streaking artifacts. The estimated susceptibility maps can preserve conspicuity of fine features and suppress streaking artifacts. The demonstrated methods have potential value in advancing QSM clinical research and aiding in the translation of QSM to clinical operations.
How well do U-Net-based segmentation trained on adult cardiac magnetic resonance imaging data generalise to rare congenital heart diseases for surgical planning?
Feb 10, 2020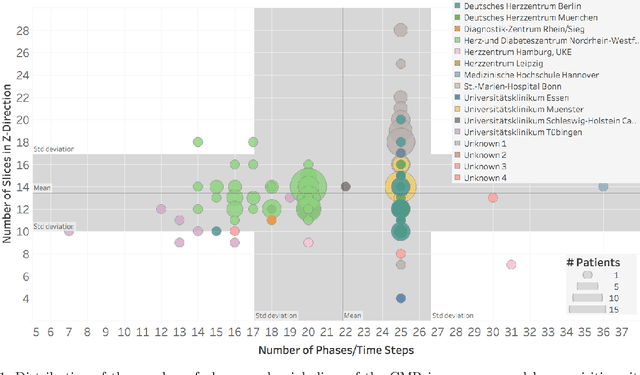
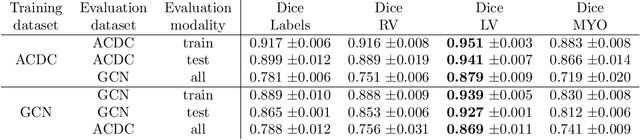
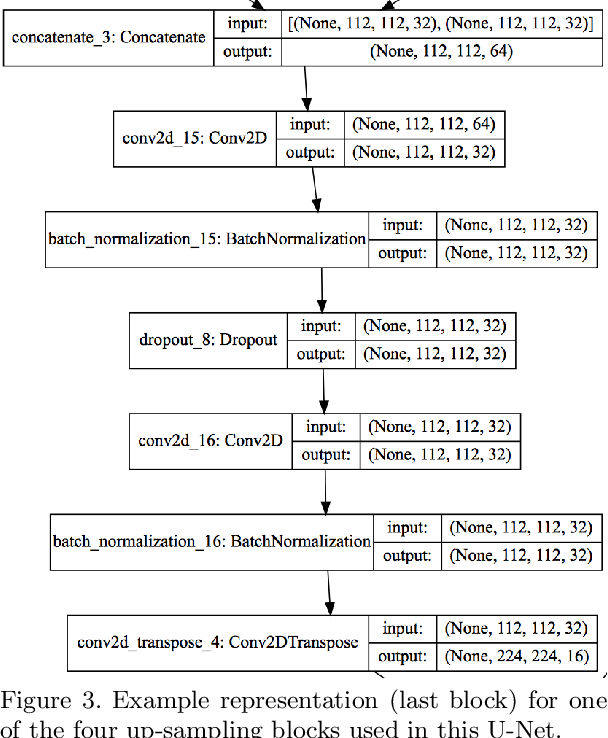
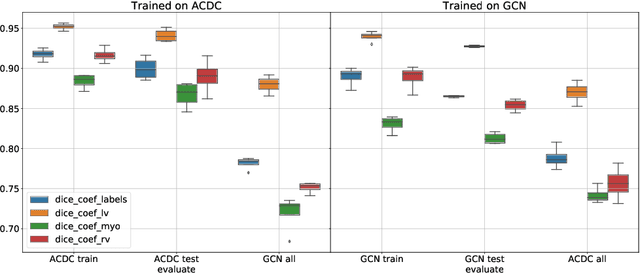
Planning the optimal time of intervention for pulmonary valve replacement surgery in patients with the congenital heart disease Tetralogy of Fallot (TOF) is mainly based on ventricular volume and function according to current guidelines. Both of these two biomarkers are most reliably assessed by segmentation of 3D cardiac magnetic resonance (CMR) images. In several grand challenges in the last years, U-Net architectures have shown impressive results on the provided data. However, in clinical practice, data sets are more diverse considering individual pathologies and image properties derived from different scanner properties. Additionally, specific training data for complex rare diseases like TOF is scarce. For this work, 1) we assessed the accuracy gap when using a publicly available labelled data set (the Automatic Cardiac Diagnosis Challenge (ACDC) data set) for training and subsequent applying it to CMR data of TOF patients and vice versa and 2) whether we can achieve similar results when applying the model to a more heterogeneous data base. Multiple deep learning models were trained with four-fold cross validation. Afterwards they were evaluated on the respective unseen CMR images from the other collection. Our results confirm that current deep learning models can achieve excellent results (left ventricle dice of $0.951\pm{0.003}$/$0.941\pm{0.007}$ train/validation) within a single data collection. But once they are applied to other pathologies, it becomes apparent how much they overfit to the training pathologies (dice score drops between $0.072\pm{0.001}$ for the left and $0.165\pm{0.001}$ for the right ventricle).
Towards Building a Real Time Mobile Device Bird Counting System Through Synthetic Data Training and Model Compression
Dec 15, 2019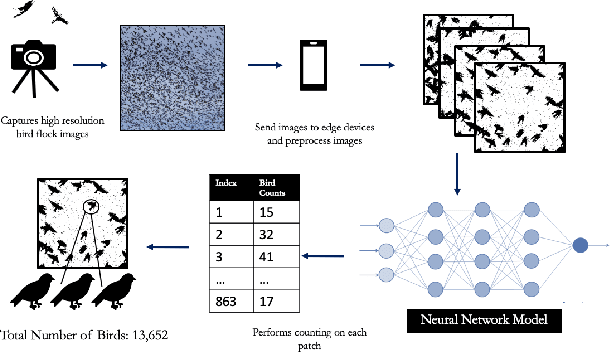

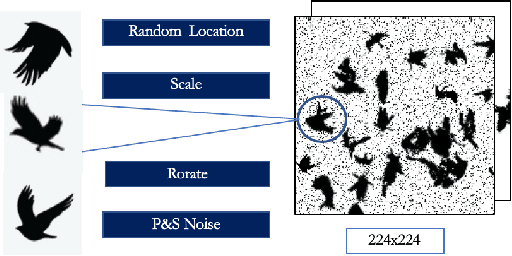
Counting the number of birds in an open sky setting has been an challenging problem due to the large number of bird flocks and the birds can overlap. Another difficulty is the lack of accurate training samples since the cost of labeling images of bird flocks can be extremely high and each sample picture can contain thousands of birds in a high resolution image. Inspired by recent work on training with synthetic data to perform crowd counting, we design a mechanism to generate synthetic bird dataset with precise bird count and the corresponding density maps. We then train a Unet model on the synthetic dataset to perform density map estimation that produces the count for each input. Our method is able to achieve MSE of approximately 12.4 on real dataset. In order to build a scalable system for fast bird counting under storage and computational constraints, we use model compression techniques and efficient model structures to increase the inference speed and save storage cost. We are able to reduce storage cost from 55MB to less than 5MB for the model with minimum loss of accuracy. This paper describes the pipelines of building an efficient bird counting system.
Grasping and Manipulation with a Multi-Fingered Hand
Mar 03, 2020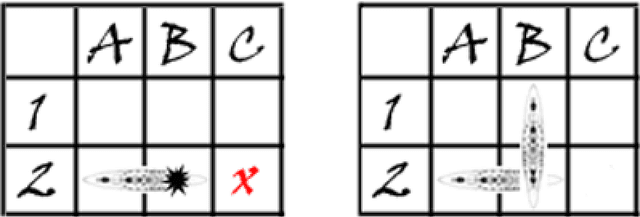
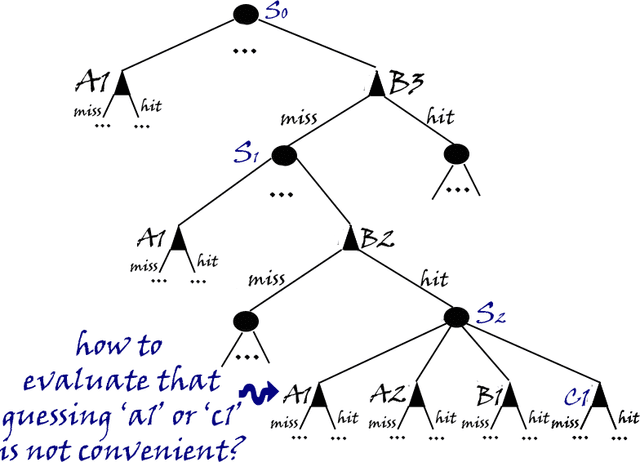
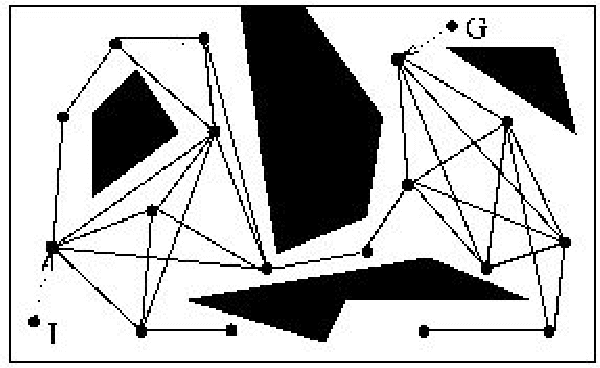
This thesis is concerned with deriving planning algorithms for robot manipulators. Manipulation has two effects, the robot has a physical effect on the object, and it also acquires information about the object. This thesis presents algorithms that treat both problems. First, I present an extension of the well-known piano mover's problem where a robot pushing an object must plan its movements as well as those of the object. This requires simultaneous planning in the joint space of the robot and the configuration space of the object, in contrast to the original problem which only requires planning in the latter space. The effects of a robot action on the object configuration are determined by the non-invertible rigid body mechanics. Second, I consider planning under uncertainty and in particular planning for information effects. I consider the case where a robot has to reach and grasp an object under pose uncertainty caused by shape incompleteness. The approach presented in this report is to study and possibly extend a new approach to artificial intelligence (A.I.) which has emerged in the last years in response to the necessity of building intelligent controllers for agents operating in unstructured stochastic environments. Such agents require the ability to learn by interaction with its environment an optimal action-selection behaviour. The main issue is that real-world problems are usually dynamic and unpredictable. Thus, the agent needs to update constantly its current image of the world using its sensors, which provide only a noisy description of the surrounding environment. Although there are different schools of thinking, with their own set of techniques, a brand new direction which unifies many A.I. researches is to formalise such agent/environment interactions as embedded systems with stochastic dynamics.
Normalized Diversification
Apr 10, 2019
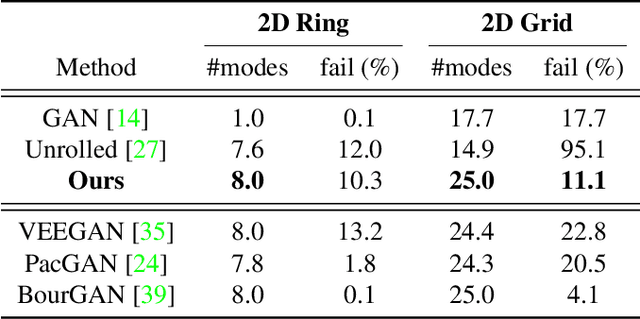
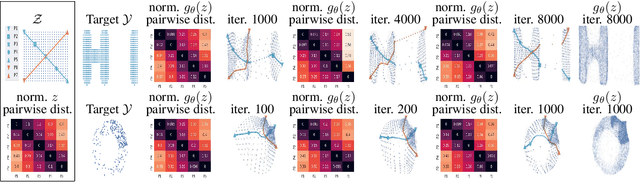
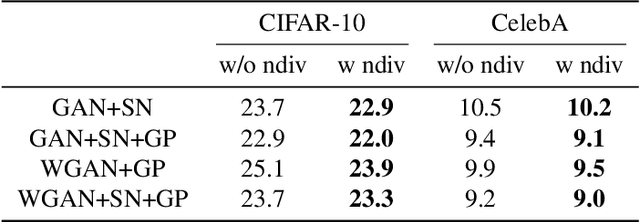
Generating diverse yet specific data is the goal of the generative adversarial network (GAN), but it suffers from the problem of mode collapse. We introduce the concept of normalized diversity which force the model to preserve the normalized pairwise distance between the sparse samples from a latent parametric distribution and their corresponding high-dimensional outputs. The normalized diversification aims to unfold the manifold of unknown topology and non-uniform distribution, which leads to safe interpolation between valid latent variables. By alternating the maximization over the pairwise distance and updating the total distance (normalizer), we encourage the model to actively explore in the high-dimensional output space. We demonstrate that by combining the normalized diversity loss and the adversarial loss, we generate diverse data without suffering from mode collapsing. Experimental results show that our method achieves consistent improvement on unsupervised image generation, conditional image generation and hand pose estimation over strong baselines.
High Fidelity Face Manipulation with Extreme Pose and Expression
Mar 28, 2019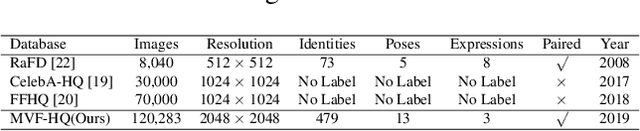
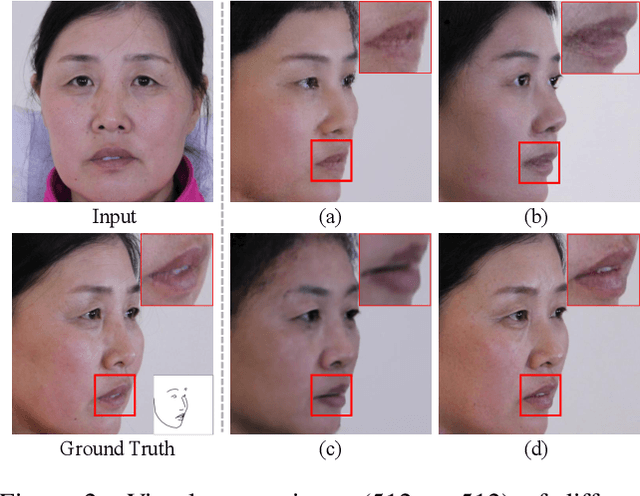
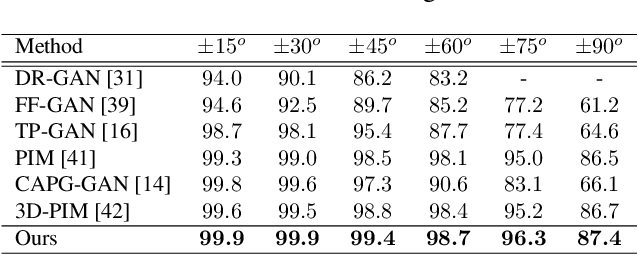
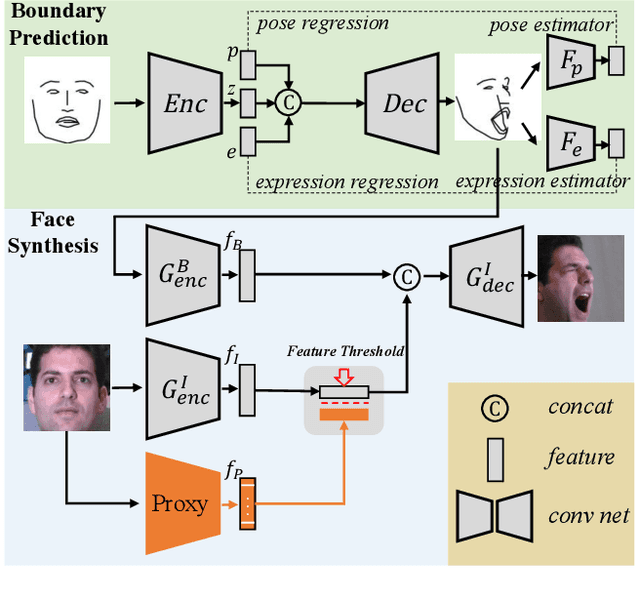
Face manipulation has shown remarkable advances with the flourish of Generative Adversarial Networks. However, due to the difficulties of controlling the structure and texture in high-resolution, it is challenging to simultaneously model pose and expression during manipulation. In this paper, we propose a novel framework that simplifies face manipulation with extreme pose and expression into two correlated stages: a boundary prediction stage and a disentangled face synthesis stage. In the first stage, we propose to use a boundary image for joint pose and expression modeling. An encoder-decoder network is employed to predict the boundary image of the target face in a semi-supervised way. Pose and expression estimators are used to improve the prediction accuracy. In the second stage, the predicted boundary image and the original face are encoded into the structure and texture latent space by two encoder networks respectively. A proxy network and a feature threshold loss are further imposed as constraints to disentangle the latent space. In addition, we build up a new high quality Multi-View Face (MVF-HQ) database that contains 120K high-resolution face images of 479 identities with pose and expression variations, which will be released soon. Qualitative and quantitative experiments on four databases show that our method pushes forward the advance of extreme face manipulation from 128 $\times$ 128 resolution to 1024 $\times$ 1024 resolution, and significantly improves the face recognition performance under large poses.
DeepSperm: A robust and real-time bull sperm-cell detection in densely populated semen videos
Mar 03, 2020

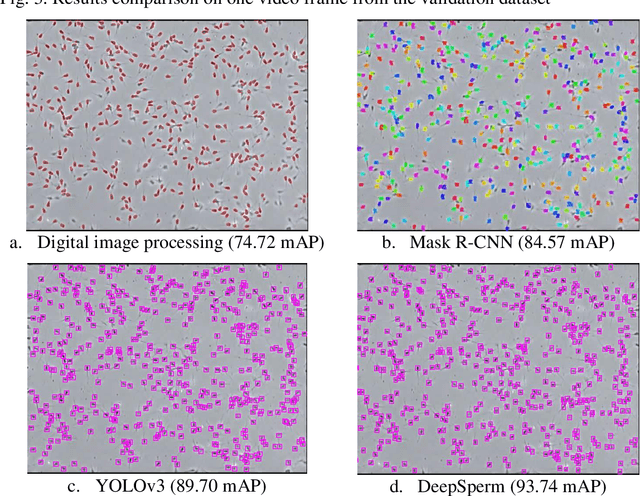
Background and Objective: Object detection is a primary research interest in computer vision. Sperm-cell detection in a densely populated bull semen microscopic observation video presents challenges such as partial occlusion, vast number of objects in a single video frame, tiny size of the object, artifacts, low contrast, and blurry objects because of the rapid movement of the sperm cells. This study proposes an architecture, called DeepSperm, that solves the aforementioned challenges and is more accurate and faster than state-of-the-art architectures. Methods: In the proposed architecture, we use only one detection layer, which is specific for small object detection. For handling overfitting and increasing accuracy, we set a higher network resolution, use a dropout layer, and perform data augmentation on hue, saturation, and exposure. Several hyper-parameters are tuned to achieve better performance. We compare our proposed method with those of a conventional image processing-based object-detection method, you only look once (YOLOv3), and mask region-based convolutional neural network (Mask R-CNN). Results: In our experiment, we achieve 86.91 mAP on the test dataset and a processing speed of 50.3 fps. In comparison with YOLOv3, we achieve an increase of 16.66 mAP point, 3.26 x faster on testing, and 1.4 x faster on training with a small training dataset, which contains 40 video frames. The weights file size was also reduced significantly, with 16.94 x smaller than that of YOLOv3. Moreover, it requires 1.3 x less graphical processing unit (GPU) memory than YOLOv3. Conclusions: This study proposes DeepSperm, which is a simple, effective, and efficient architecture with its hyper-parameters and configuration to detect bull sperm cells robustly in real time. In our experiment, we surpass the state of the art in terms of accuracy, speed, and resource needs.