 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Co-occurrence Matrix and Fractal Dimension for Image Segmentation
Dec 06, 2011

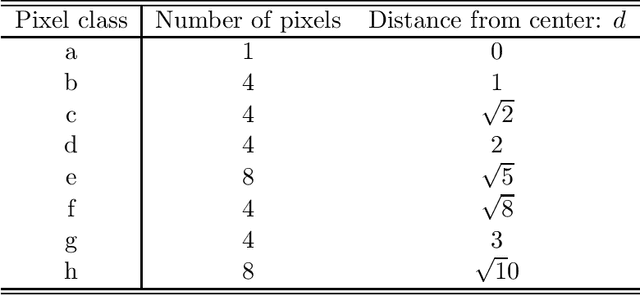


One of the most important tasks in image processing problem and machine vision is object recognition, and the success of many proposed methods relies on a suitable choice of algorithm for the segmentation of an image. This paper focuses on how to apply texture operators based on the concept of fractal dimension and cooccurence matrix, to the problem of object recognition and a new method based on fractal dimension is introduced. Several images, in which the result of the segmentation can be shown, are used to illustrate the use of each method and a comparative study of each operator is made.
A Novel Image Segmentation Enhancement Technique based on Active Contour and Topological Alignments
Jun 02, 2011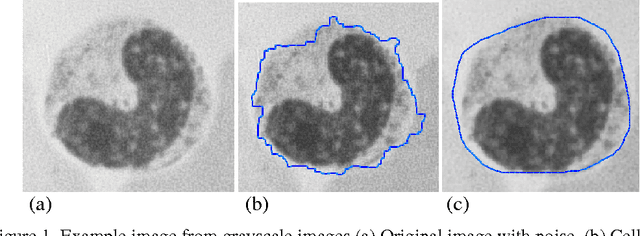
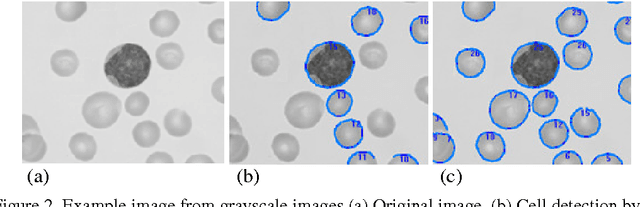

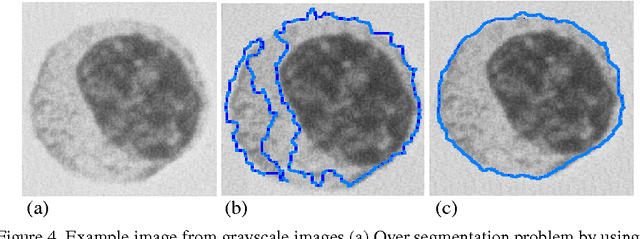
Topological alignments and snakes are used in image processing, particularly in locating object boundaries. Both of them have their own advantages and limitations. To improve the overall image boundary detection system, we focused on developing a novel algorithm for image processing. The algorithm we propose to develop will based on the active contour method in conjunction with topological alignments method to enhance the image detection approach. The algorithm presents novel technique to incorporate the advantages of both Topological Alignments and snakes. Where the initial segmentation by Topological Alignments is firstly transformed into the input of the snake model and begins its evolvement to the interested object boundary. The results show that the algorithm can deal with low contrast images and shape cells, demonstrate the segmentation accuracy under weak image boundaries, which responsible for lacking accuracy in image detecting techniques. We have achieved better segmentation and boundary detecting for the image, also the ability of the system to improve the low contrast and deal with over and under segmentation.
* 7 pages
Numeric Solutions of Eigenvalue Problems for Generic Nonlinear Operators
Sep 12, 2019

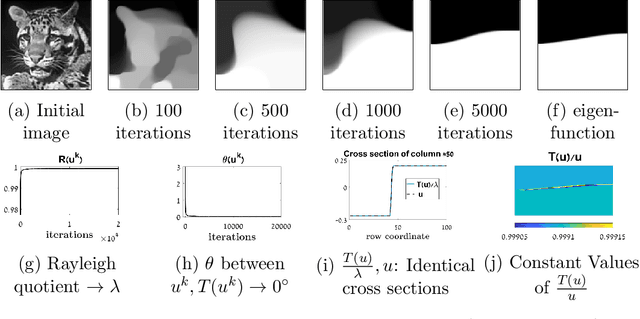
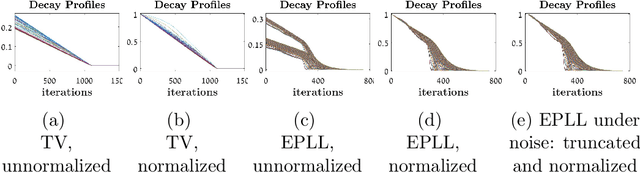
Numerical methods for solving linear eigenvalue problem are widely studiedand used in science and engineering. In this paper, we propose a generalizednumerical method for solving eigenproblems for generic, nonlinear opera-tors. This has potentially wide implications, since most image processingalgorithms (e.g. denoising) can be viewed as nonlinear operators, whoseeigenproblem analysis provides information on the most- and least-suitablefunctions as input. We solve the problem by a nonlinear adaptation of thepower method, a well known linear eigensolver. An analysis and valida-tion framework is proposed, as well as preliminary theory. We validate themethod using total-variation (TV) and demonstrate it on the EPLL denoiser(Zoran-Weiss). Finally, we suggest an encryption-decryption application.
Learning Semantic Correspondence Exploiting an Object-level Prior
Nov 29, 2019
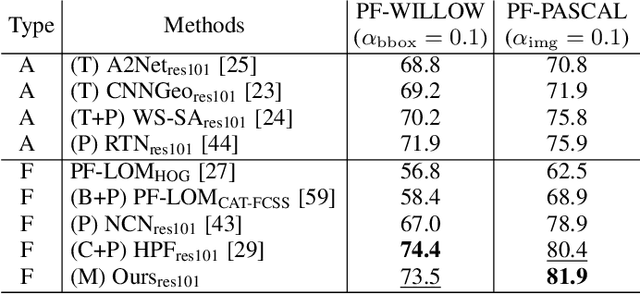
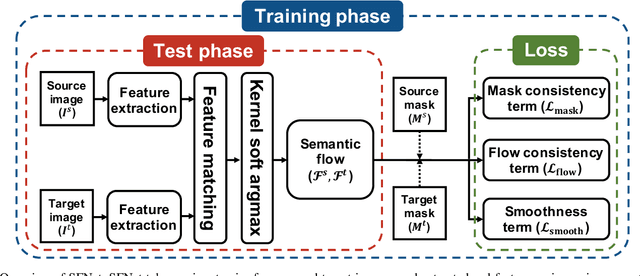

We address the problem of semantic correspondence, that is, establishing a dense flow field between images depicting different instances of the same object or scene category. We propose to use images annotated with binary foreground masks and subjected to synthetic geometric deformations to train a convolutional neural network (CNN) for this task. Using these masks as part of the supervisory signal provides an object-level prior for the semantic correspondence task and offers a good compromise between semantic flow methods, where the amount of training data is limited by the cost of manually selecting point correspondences, and semantic alignment ones, where the regression of a single global geometric transformation between images may be sensitive to image-specific details such as background clutter. We propose a new CNN architecture, dubbed SFNet, which implements this idea. It leverages a new and differentiable version of the argmax function for end-to-end training, with a loss that combines mask and flow consistency with smoothness terms. Experimental results demonstrate the effectiveness of our approach, which significantly outperforms the state of the art on standard benchmarks.
QANet - Quality Assurance Network for Microscopy Cell Segmentation
Apr 23, 2019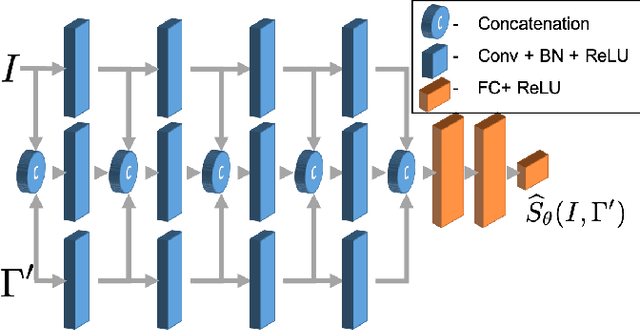
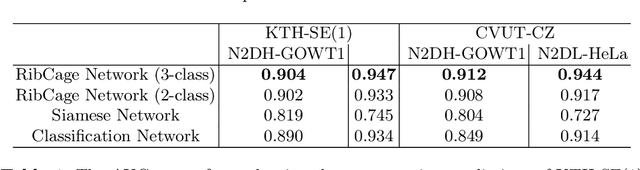
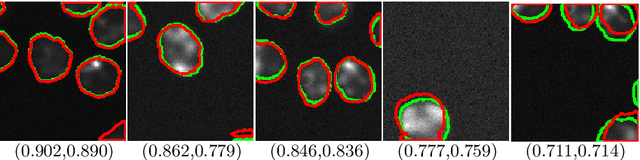

Tools and methods for automatic image segmentation are rapidly developing, each with its own strengths and weaknesses. While these methods are designed to be as general as possible, there are no guarantees for their performance on new data. The choice between methods is usually based on benchmark performance whereas the data in the benchmark can be significantly different than that of the user. We introduce a novel Deep Learning method which, given an image and a proposed corresponding segmentation, estimates the Intersection over Union measure (IoU) with respect to the unknown ground truth. We refer to this method as a Quality Assurance Network - QANet. The QANet is designed to give the user an estimate of the segmentation quality on the users own, private, data without the need for human inspection or labelling. It is based on the RibCage Network architecture, originally proposed as a discriminator in an adversarial network framework. Promising IoU prediction results are demonstrated based on the Cell Segmentation Benchmark.
Increasing Expressivity of a Hyperspherical VAE
Oct 07, 2019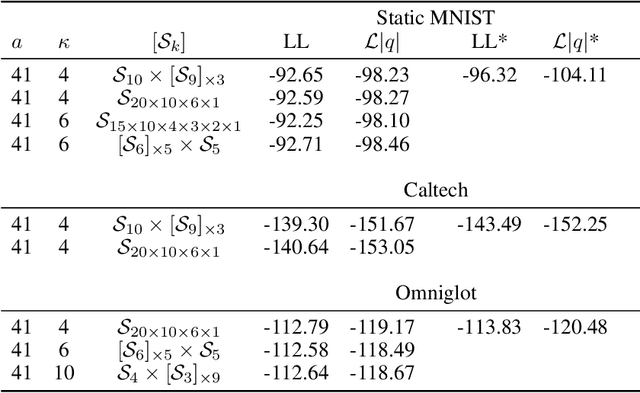
Learning suitable latent representations for observed, high-dimensional data is an important research topic underlying many recent advances in machine learning. While traditionally the Gaussian normal distribution has been the go-to latent parameterization, recently a variety of works have successfully proposed the use of manifold-valued latents. In one such work (Davidson et al., 2018), the authors empirically show the potential benefits of using a hyperspherical von Mises-Fisher (vMF) distribution in low dimensionality. However, due to the unique distributional form of the vMF, expressivity in higher dimensional space is limited as a result of its scalar concentration parameter leading to a 'hyperspherical bottleneck'. In this work we propose to extend the usability of hyperspherical parameterizations to higher dimensions using a product-space instead, showing improved results on a selection of image datasets.
Modular Meta-Learning with Shrinkage
Sep 12, 2019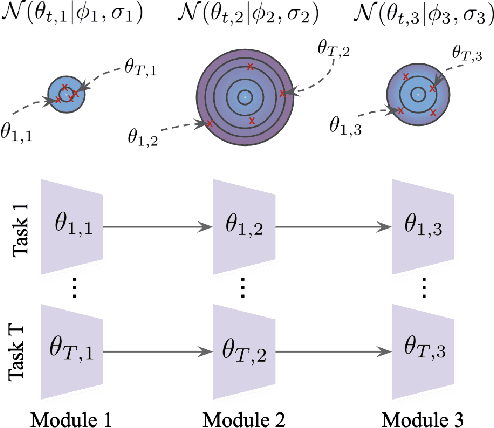
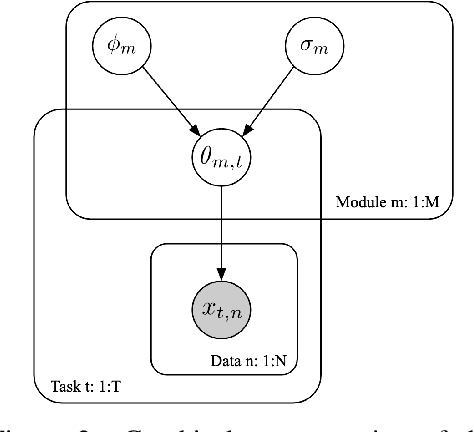
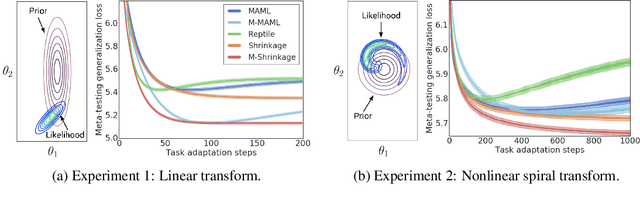
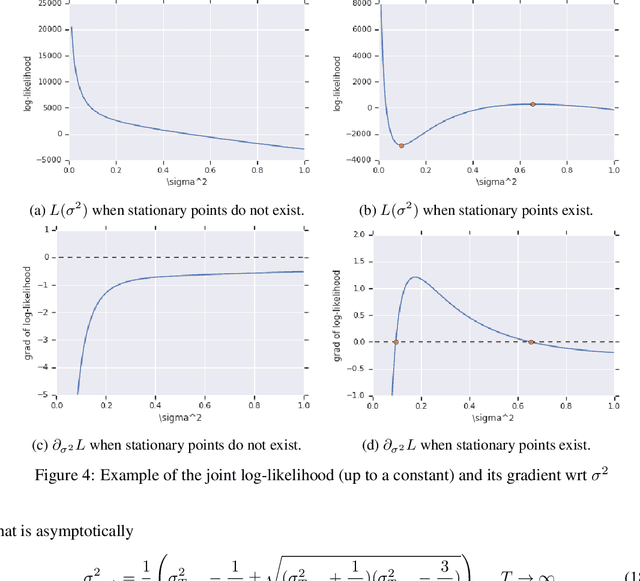
Most gradient-based approaches to meta-learning do not explicitly account for the fact that different parts of the underlying model adapt by different amounts when applied to a new task. For example, the input layers of an image classification convnet typically adapt very little, while the output layers can change significantly. This can cause parts of the model to begin to overfit while others underfit. To address this, we introduce a hierarchical Bayesian model with per-module shrinkage parameters, which we propose to learn by maximizing an approximation of the predictive likelihood using implicit differentiation. Our algorithm subsumes Reptile and outperforms variants of MAML on two synthetic few-shot meta-learning problems.
Max-Sliced Wasserstein Distance and its use for GANs
Apr 11, 2019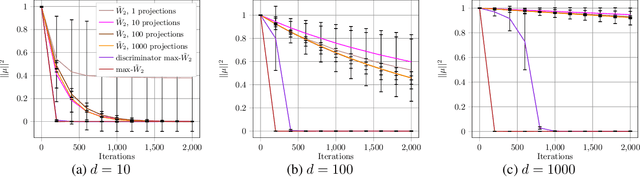

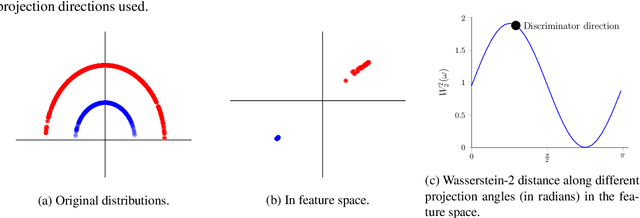

Generative adversarial nets (GANs) and variational auto-encoders have significantly improved our distribution modeling capabilities, showing promise for dataset augmentation, image-to-image translation and feature learning. However, to model high-dimensional distributions, sequential training and stacked architectures are common, increasing the number of tunable hyper-parameters as well as the training time. Nonetheless, the sample complexity of the distance metrics remains one of the factors affecting GAN training. We first show that the recently proposed sliced Wasserstein distance has compelling sample complexity properties when compared to the Wasserstein distance. To further improve the sliced Wasserstein distance we then analyze its `projection complexity' and develop the max-sliced Wasserstein distance which enjoys compelling sample complexity while reducing projection complexity, albeit necessitating a max estimation. We finally illustrate that the proposed distance trains GANs on high-dimensional images up to a resolution of 256x256 easily.
Outlier Guided Optimization of Abdominal Segmentation
Feb 10, 2020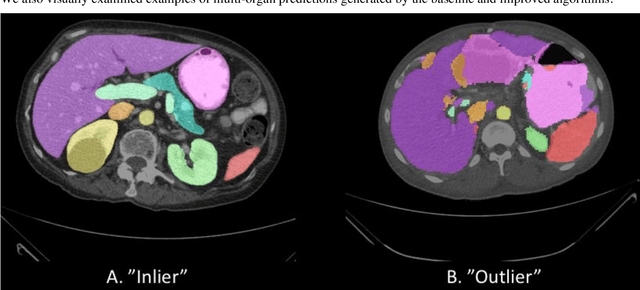
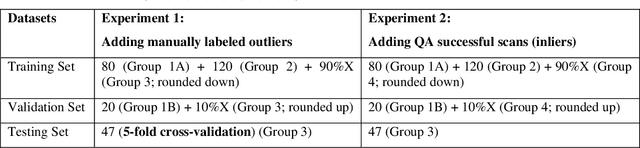
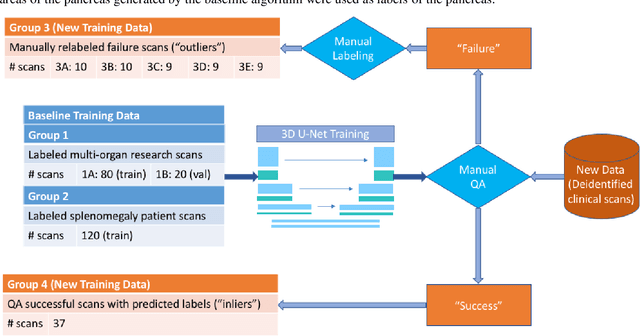
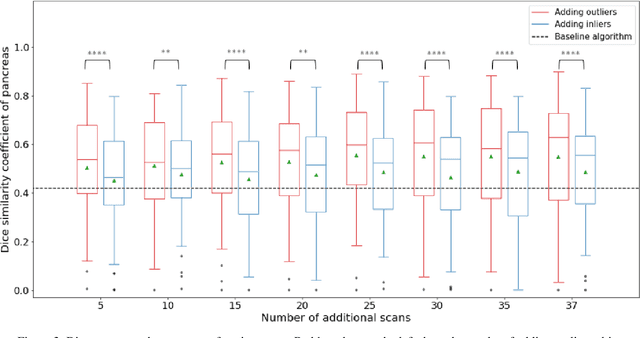
Abdominal multi-organ segmentation of computed tomography (CT) images has been the subject of extensive research interest. It presents a substantial challenge in medical image processing, as the shape and distribution of abdominal organs can vary greatly among the population and within an individual over time. While continuous integration of novel datasets into the training set provides potential for better segmentation performance, collection of data at scale is not only costly, but also impractical in some contexts. Moreover, it remains unclear what marginal value additional data have to offer. Herein, we propose a single-pass active learning method through human quality assurance (QA). We built on a pre-trained 3D U-Net model for abdominal multi-organ segmentation and augmented the dataset either with outlier data (e.g., exemplars for which the baseline algorithm failed) or inliers (e.g., exemplars for which the baseline algorithm worked). The new models were trained using the augmented datasets with 5-fold cross-validation (for outlier data) and withheld outlier samples (for inlier data). Manual labeling of outliers increased Dice scores with outliers by 0.130, compared to an increase of 0.067 with inliers (p<0.001, two-tailed paired t-test). By adding 5 to 37 inliers or outliers to training, we find that the marginal value of adding outliers is higher than that of adding inliers. In summary, improvement on single-organ performance was obtained without diminishing multi-organ performance or significantly increasing training time. Hence, identification and correction of baseline failure cases present an effective and efficient method of selecting training data to improve algorithm performance.
Quality analysis of DCGAN-generated mammography lesions
Nov 28, 2019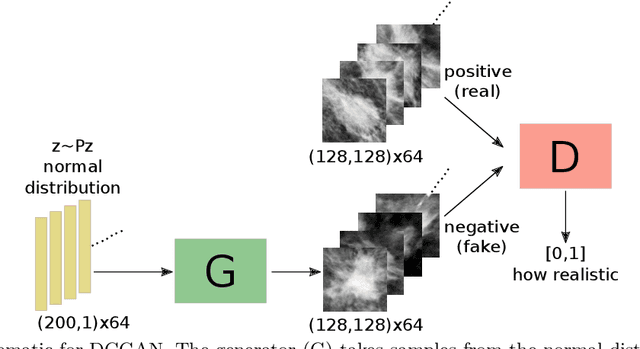
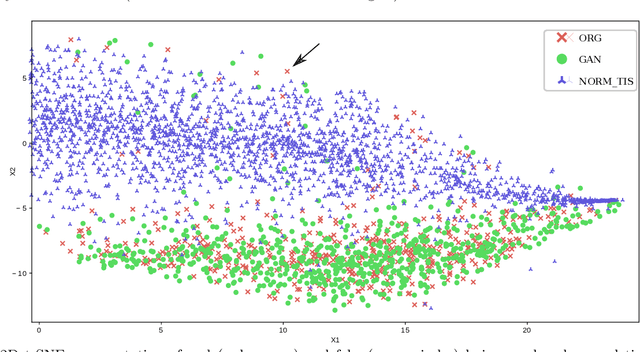
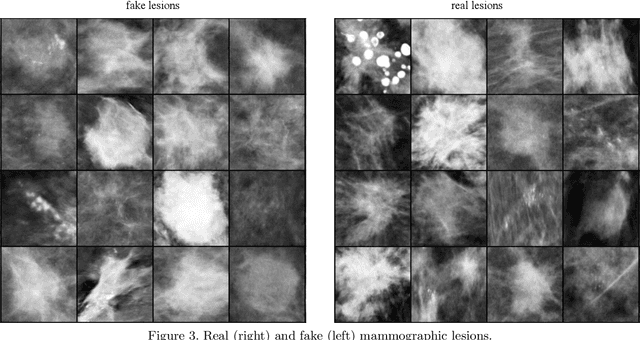
Medical image synthesis has gained a great focus recently, especially after the introduction of Generative Adversarial Networks (GANs). GANs have been used widely to provide anatomically-plausible and diverse samples for augmentation and other applications, including segmentation and super resolution. In our previous work, Deep Convolutional GANs were used to generate synthetic mammogram lesions, masses mainly, that could enhance the classification performance in imbalanced datasets. In this new work, a deeper investigation was carried out to explore other aspects of the generated images evaluation, i.e., realism, feature space distribution, and observers studies. t-Stochastic Neighbor Embedding (t-SNE) was used to reduce the dimensionality of real and fake images to enable 2D visualisations. Additionally, two expert radiologists performed a realism-evaluation study. Visualisations showed that the generated images have a similar feature distribution of the real ones, avoiding outliers. Moreover, Receiver Operating Characteristic (ROC) curve showed that the radiologists could not, in many cases, distinguish between synthetic and real lesions, giving 48% and 61% accuracies in a balanced sample set.