 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From Open Set to Closed Set: Counting Objects by Spatial Divide-and-Conquer
Aug 15, 2019
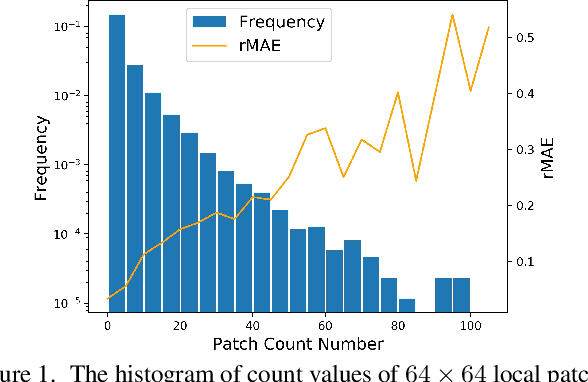

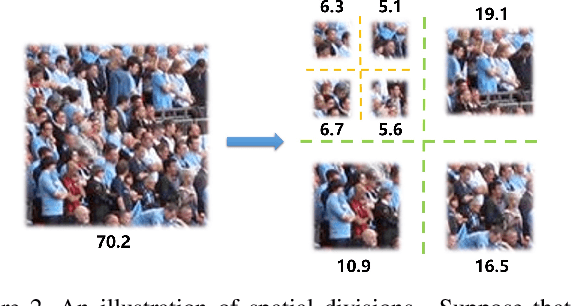

Visual counting, a task that predicts the number of objects from an image/video, is an open-set problem by nature, i.e., the number of population can vary in $[0,+\infty)$ in theory. However, the collected images and labeled count values are limited in reality, which means only a small closed set is observed. Existing methods typically model this task in a regression manner, while they are likely to suffer from an unseen scene with counts out of the scope of the closed set. In fact, counting is decomposable. A dense region can always be divided until sub-region counts are within the previously observed closed set. Inspired by this idea, we propose a simple but effective approach, Spatial Divide-and- Conquer Network (S-DCNet). S-DCNet only learns from a closed set but can generalize well to open-set scenarios via S-DC. S-DCNet is also efficient. To avoid repeatedly computing sub-region convolutional features, S-DC is executed on the feature map instead of on the input image. S-DCNet achieves the state-of-the-art performance on three crowd counting datasets (ShanghaiTech, UCF_CC_50 and UCF-QNRF), a vehicle counting dataset (TRANCOS) and a plant counting dataset (MTC). Compared to the previous best methods, S-DCNet brings a 20.2% relative improvement on the ShanghaiTech Part B, 20.9% on the UCF-QNRF, 22.5% on the TRANCOS and 15.1% on the MTC. Code has been made available at: https://github. com/xhp-hust-2018-2011/S-DCNet.
Revisit Lmser and its further development based on convolutional layers
Apr 12, 2019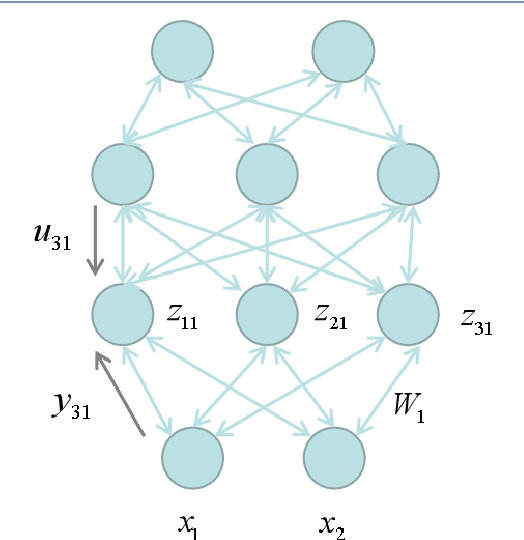
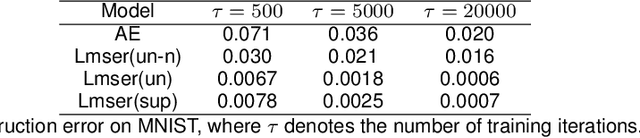

Proposed in 1991, Least Mean Square Error Reconstruction for self-organizing network, shortly Lmser, was a further development of the traditional auto-encoder (AE) by folding the architecture with respect to the central coding layer and thus leading to the features of symmetric weights and neurons, as well as jointly supervised and unsupervised learning. However, its advantages were only demonstrated in a one-hidden-layer implementation due to the lack of computing resources and big data at that time. In this paper, we revisit Lmser from the perspective of deep learning, develop Lmser network based on multiple convolutional layers, which is more suitable for image-related tasks, and confirm several Lmser functions with preliminary demonstrations on image recognition, reconstruction, association recall, and so on. Experiments demonstrate that Lmser indeed works as indicated in the original paper, and it has promising performance in various applications.
Encoding High-Level Visual Attributes in Capsules for Explainable Medical Diagnoses
Sep 12, 2019
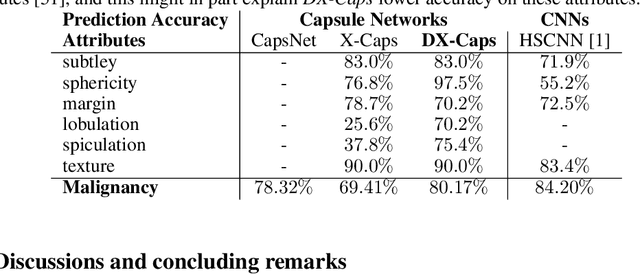
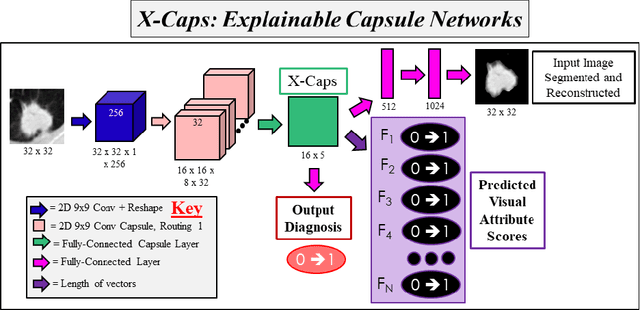
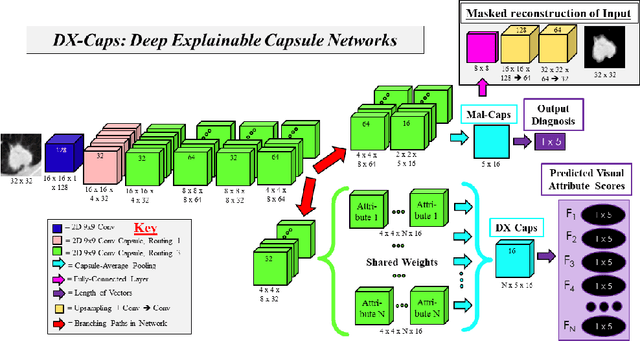
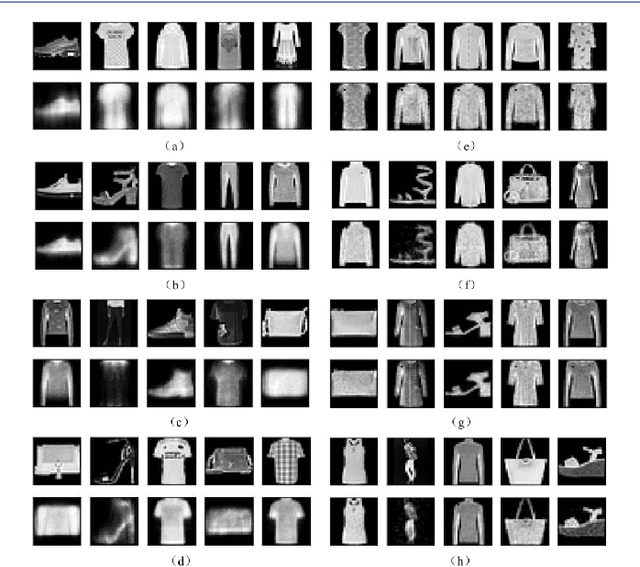
Deep neural networks are often called black-boxes due to their difficult-to-interpret decisions. This is characteristic of a deeper trend in machine learning, where predictive performance typically comes at the cost of interpretability. In some domains, such as image-based diagnostic tasks, understanding the reasons behind machine generated predictions is vital in assessing trust. In this study, we introduce novel designs of capsule networks to provide explainable diagnoses. Our proposed deep explainable capsule architecture, called DX-Caps, can encode high-level visual attributes within the vectors of capsules in order to simultaneously produce malignancy predictions for lung cancer as well as approximations of six visually-interpretable attributes, used by radiologists to explain their predictions. To reduce parameter and memory burden of this deeper network, we introduce a new capsule-average pooling function. With this simple, but fundamental addition, capsule networks can be designed in a deeper fashion than was possible before. Our overall approach can be characterized as multi-task learning; we learn to approximate the six high-level visual attributes of a lung nodule within the vectors of our uniquely constructed deep capsule network, while simultaneously segmenting the nodule and predicting its malignancy potential (diagnosis). Tested on over 1000 CT scans, our experimental results show that our proposed algorithm can approximate the visual attributes of lung nodules far better than a deep multi-path dense 3D CNN. The proposed network also achieves higher diagnostic accuracy than a baseline explainable capsule network X-Caps and CapsNet when applied to this task for the first time as well. To the best of our knowledge, this is the first study to investigate capsule networks for visual attribute prediction in general, and explainable medical image diagnosis in particular.
TunaGAN: Interpretable GAN for Smart Editing
Aug 16, 2019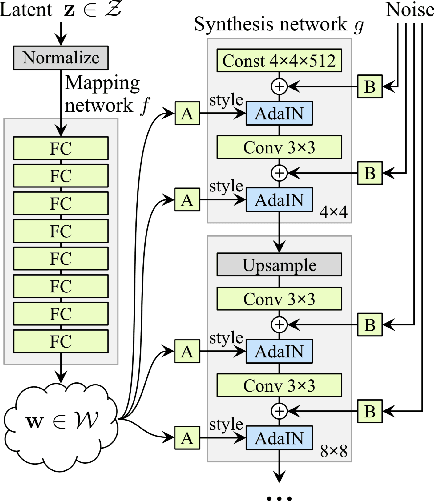
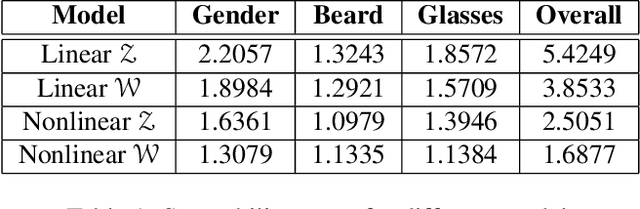
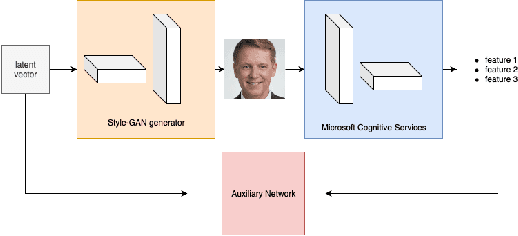

In this paper, we introduce a tunable generative adversary network (TunaGAN) that uses an auxiliary network on top of existing generator networks (Style-GAN) to modify high-resolution face images according to user's high-level instructions, with good qualitative and quantitative performance. To optimize for feature disentanglement, we also investigate two different latent space that could be traversed for modification. The problem of mode collapse is characterized in detail for model robustness. This work could be easily extended to content-aware image editor based on other GANs and provide insight on mode collapse problems in more general settings.
Generative-based Airway and Vessel Morphology Quantification on Chest CT Images
Feb 13, 2020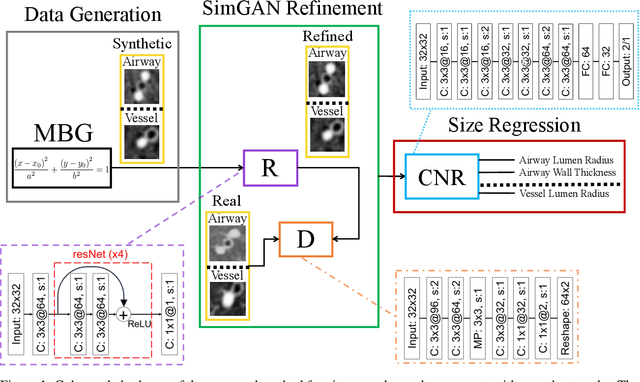

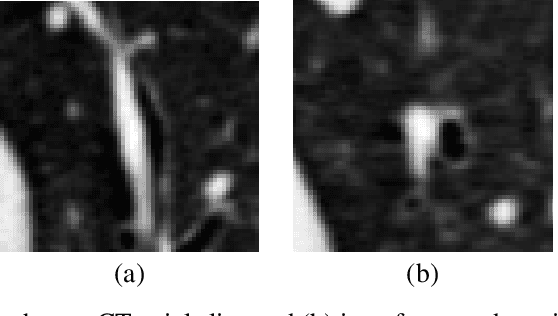
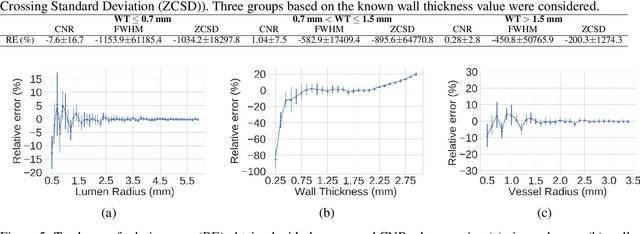
Accurately and precisely characterizing the morphology of small pulmonary structures from Computed Tomography (CT) images, such as airways and vessels, is becoming of great importance for diagnosis of pulmonary diseases. The smaller conducting airways are the major site of increased airflow resistance in chronic obstructive pulmonary disease (COPD), while accurately sizing vessels can help identify arterial and venous changes in lung regions that may determine future disorders. However, traditional methods are often limited due to image resolution and artifacts. We propose a Convolutional Neural Regressor (CNR) that provides cross-sectional measurement of airway lumen, airway wall thickness, and vessel radius. CNR is trained with data created by a generative model of synthetic structures which is used in combination with Simulated and Unsupervised Generative Adversarial Network (SimGAN) to create simulated and refined airways and vessels with known ground-truth. For validation, we first use synthetically generated airways and vessels produced by the proposed generative model to compute the relative error and directly evaluate the accuracy of CNR in comparison with traditional methods. Then, in-vivo validation is performed by analyzing the association between the percentage of the predicted forced expiratory volume in one second (FEV1\%) and the value of the Pi10 parameter, two well-known measures of lung function and airway disease, for airways. For vessels, we assess the correlation between our estimate of the small-vessel blood volume and the lungs' diffusing capacity for carbon monoxide (DLCO). The results demonstrate that Convolutional Neural Networks (CNNs) provide a promising direction for accurately measuring vessels and airways on chest CT images with physiological correlates.
DeepDistance: A Multi-task Deep Regression Model for Cell Detection in Inverted Microscopy Images
Aug 29, 2019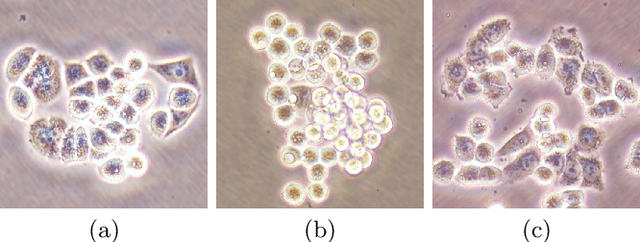
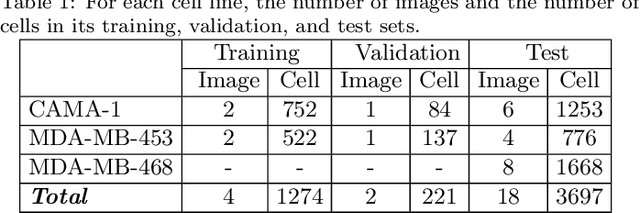

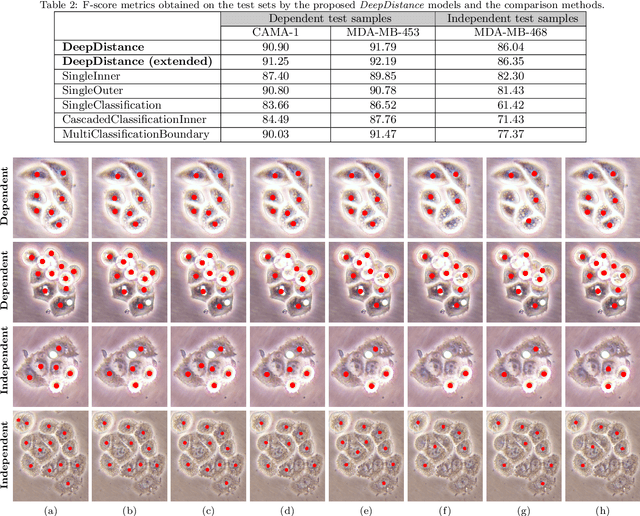
This paper presents a new deep regression model, which we call DeepDistance, for cell detection in images acquired with inverted microscopy. This model considers cell detection as a task of finding most probable locations that suggest cell centers in an image. It represents this main task with a regression task of learning an inner distance metric. However, different than the previously reported regression based methods, the DeepDistance model proposes to approach its learning as a multi-task regression problem where multiple tasks are learned by using shared feature representations. To this end, it defines a secondary metric, normalized outer distance, to represent a different aspect of the problem and proposes to define its learning as complementary to the main cell detection task. In order to learn these two complementary tasks more effectively, the DeepDistance model designs a fully convolutional network (FCN) with a shared encoder path and end-to-end trains this FCN to concurrently learn the tasks in parallel. DeepDistance uses the inner distances estimated by this FCN in a detection algorithm to locate individual cells in a given image. For further performance improvement on the main task, this paper also presents an extended version of the DeepDistance model. This extended model includes an auxiliary classification task and learns it in parallel to the two regression tasks by sharing feature representations with them. Our experiments on three different human cell lines reveal that the proposed multi-task learning models, the DeepDistance model and its extended version, successfully identify cell locations, even for the cell line that was not used in training, and improve the results of the previous deep learning methods.
Fractional Multiscale Fusion-based De-hazing
Aug 29, 2018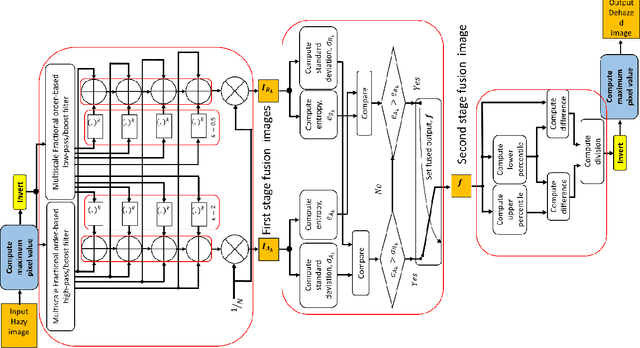
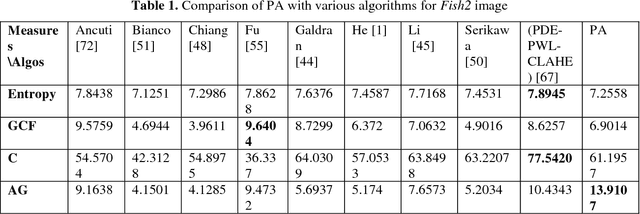

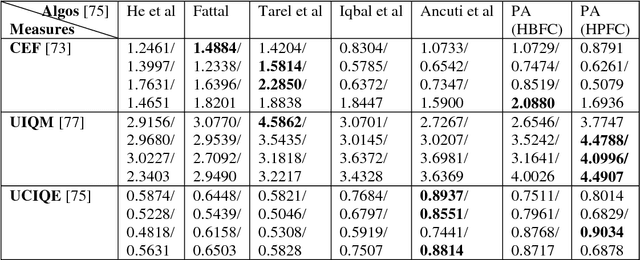
This report presents the results of a proposed multi-scale fusion-based single image de-hazing algorithm, which can also be used for underwater image enhancement. Furthermore, the algorithm was designed for very fast operation and minimal run-time. The proposed scheme is the faster than existing algorithms for both de-hazing and underwater image enhancement and amenable to digital hardware implementation. Results indicate mostly consistent and good results for both categories of images when compared with other algorithms from the literature.
Model Extraction Attacks against Recurrent Neural Networks
Feb 01, 2020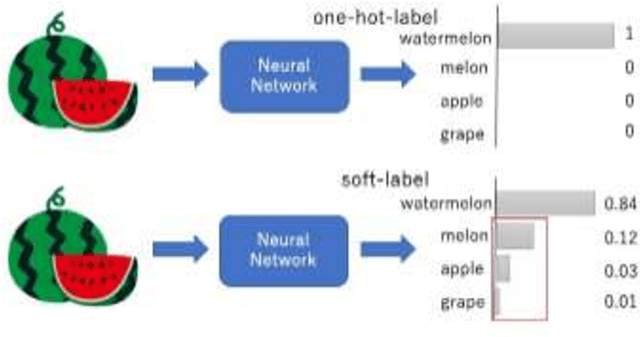
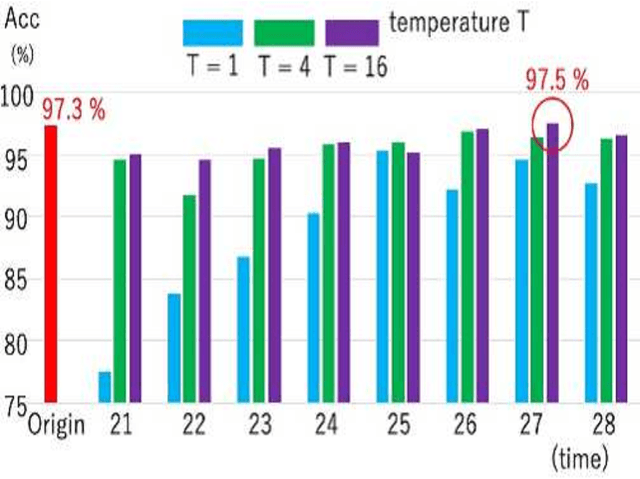
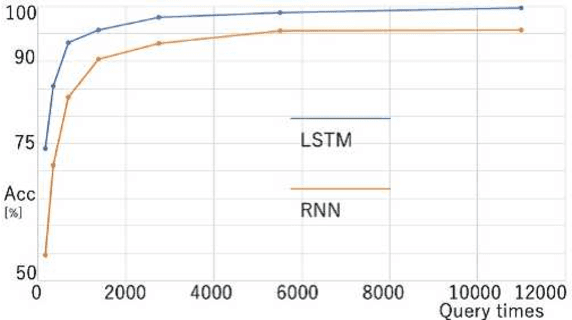
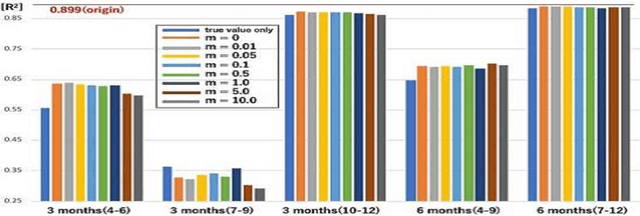
Model extraction attacks are a kind of attacks in which an adversary obtains a new model, whose performance is equivalent to that of a target model, via query access to the target model efficiently, i.e., fewer datasets and computational resources than those of the target model. Existing works have dealt with only simple deep neural networks (DNNs), e.g., only three layers, as targets of model extraction attacks, and hence are not aware of the effectiveness of recurrent neural networks (RNNs) in dealing with time-series data. In this work, we shed light on the threats of model extraction attacks against RNNs. We discuss whether a model with a higher accuracy can be extracted with a simple RNN from a long short-term memory (LSTM), which is a more complicated and powerful RNN. Specifically, we tackle the following problems. First, in a case of a classification problem, such as image recognition, extraction of an RNN model without final outputs from an LSTM model is presented by utilizing outputs halfway through the sequence. Next, in a case of a regression problem. such as in weather forecasting, a new attack by newly configuring a loss function is presented. We conduct experiments on our model extraction attacks against an RNN and an LSTM trained with publicly available academic datasets. We then show that a model with a higher accuracy can be extracted efficiently, especially through configuring a loss function and a more complex architecture different from the target model.
ResNetX: a more disordered and deeper network architecture
Dec 18, 2019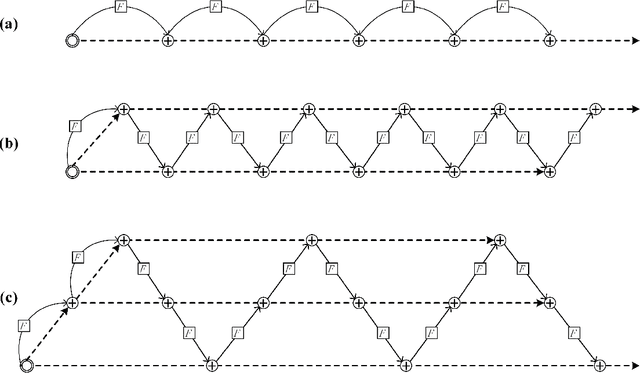
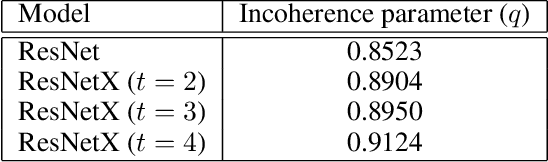
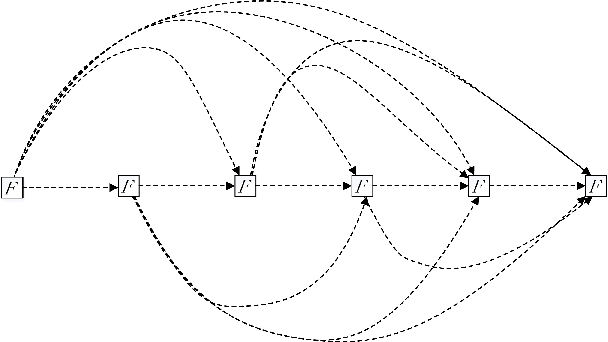
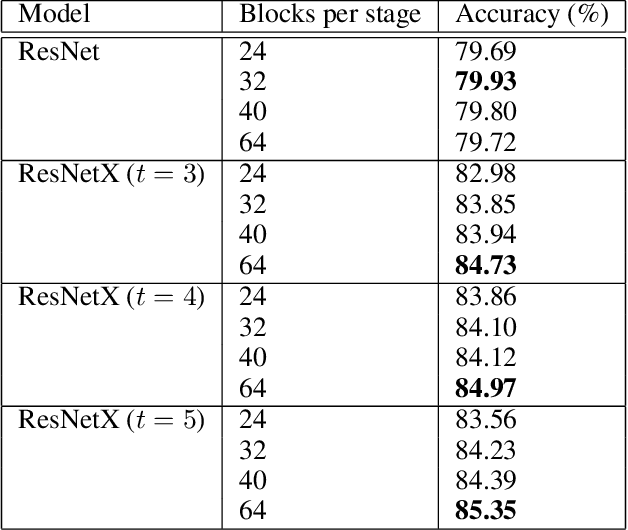
Designing efficient network structures has always been the core content of neural network research. ResNet and its variants have proved to be efficient in architecture. However, how to theoretically character the influence of network structure on performance is still vague. With the help of techniques in complex networks, We here provide a natural yet efficient extension to ResNet by folding its backbone chain. Our architecture has two structural features when being mapped to directed acyclic graphs: First is a higher degree of the disorder compared with ResNet, which let ResNetX explore a larger number of feature maps with different sizes of receptive fields. Second is a larger proportion of shorter paths compared to ResNet, which improves the direct flow of information through the entire network. Our architecture exposes a new dimension, namely "fold depth", in addition to existing dimensions of depth, width, and cardinality. Our architecture is a natural extension to ResNet, and can be integrated with existing state-of-the-art methods with little effort. Image classification results on CIFAR-10 and CIFAR-100 benchmarks suggested that our new network architecture performs better than ResNet.
Centroid-Based Scene Classification (CBSC): Using Deep Features and Clustering for RGB-D Indoor Scene Classification
Nov 01, 2019
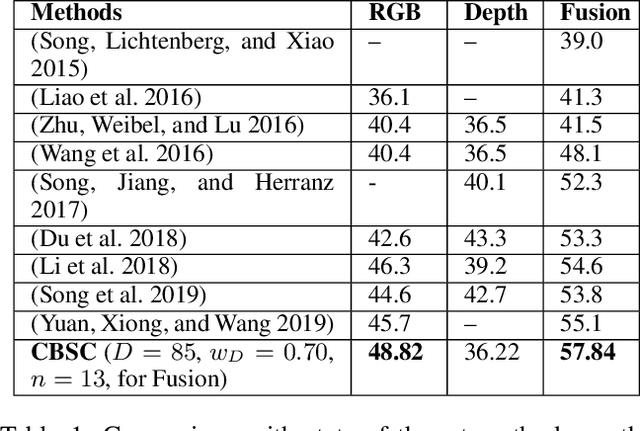
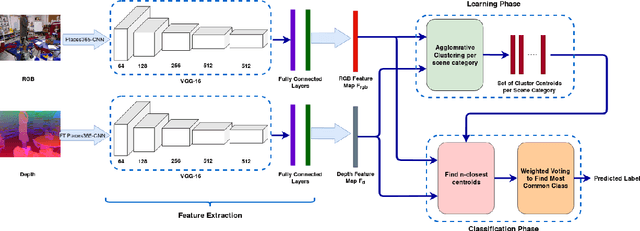

This paper contributes a novel method for RGB-D indoor scene classification. Recent approaches to this problem focus on developing increasingly complex pipelines that learn correlated features across the RGB and depth modalities. In contrast, this paper presents a simple method that first extracts features for the RGB and depth modalities using Places365-CNN and fine-tuned Places365-CNN on depth data, respectively and then clusters these features to generate a set of centroids representing each scene category from the training data. For classification a scene image is converted to CNN features and the distance of these features to the n closest learned centroids is used to predict the image's category. We evaluate our method on two standard RGB-D indoor scene classification benchmarks: SUNRGB-D and NYU Depth V2 and demonstrate that our proposed classification approach achieves superior performance over the state-of-the-art methods on both datasets.