 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative-based Airway and Vessel Morphology Quantification on Chest CT Images
Feb 13, 2020
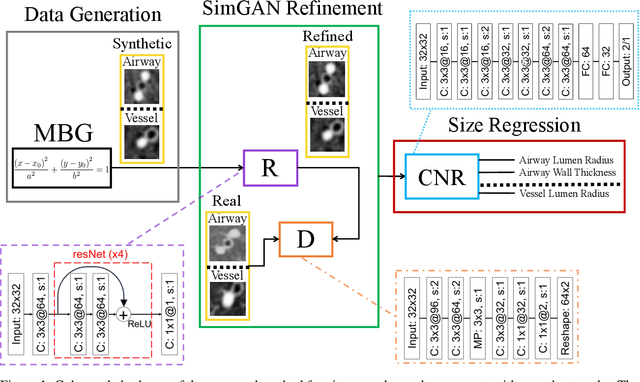

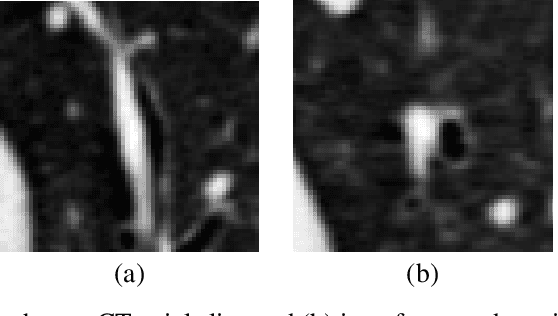
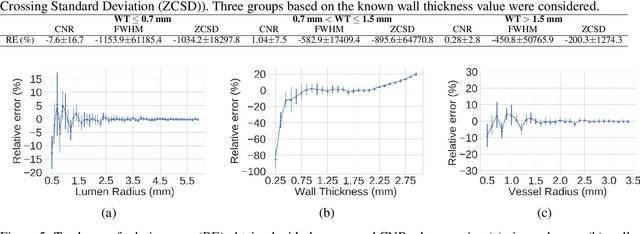
Accurately and precisely characterizing the morphology of small pulmonary structures from Computed Tomography (CT) images, such as airways and vessels, is becoming of great importance for diagnosis of pulmonary diseases. The smaller conducting airways are the major site of increased airflow resistance in chronic obstructive pulmonary disease (COPD), while accurately sizing vessels can help identify arterial and venous changes in lung regions that may determine future disorders. However, traditional methods are often limited due to image resolution and artifacts. We propose a Convolutional Neural Regressor (CNR) that provides cross-sectional measurement of airway lumen, airway wall thickness, and vessel radius. CNR is trained with data created by a generative model of synthetic structures which is used in combination with Simulated and Unsupervised Generative Adversarial Network (SimGAN) to create simulated and refined airways and vessels with known ground-truth. For validation, we first use synthetically generated airways and vessels produced by the proposed generative model to compute the relative error and directly evaluate the accuracy of CNR in comparison with traditional methods. Then, in-vivo validation is performed by analyzing the association between the percentage of the predicted forced expiratory volume in one second (FEV1\%) and the value of the Pi10 parameter, two well-known measures of lung function and airway disease, for airways. For vessels, we assess the correlation between our estimate of the small-vessel blood volume and the lungs' diffusing capacity for carbon monoxide (DLCO). The results demonstrate that Convolutional Neural Networks (CNNs) provide a promising direction for accurately measuring vessels and airways on chest CT images with physiological correlates.
Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders
Dec 05, 2018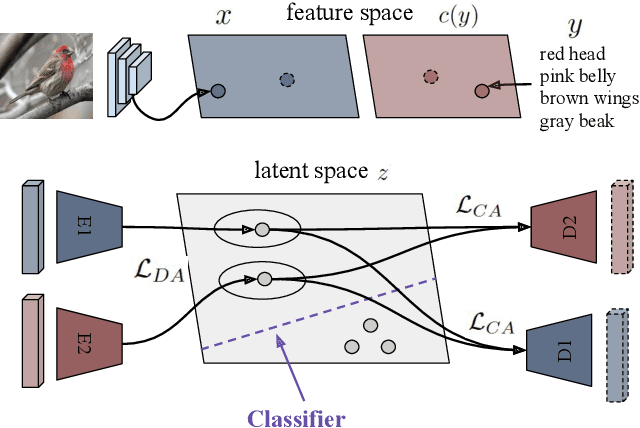

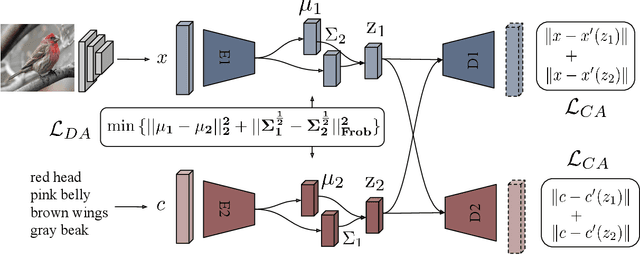
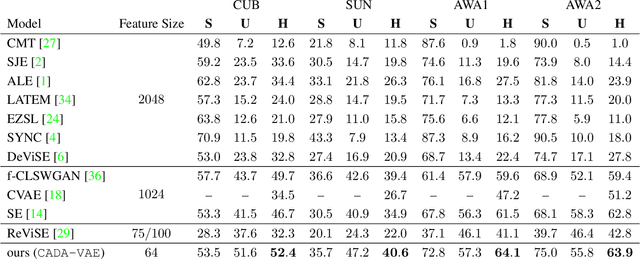
Many approaches in generalized zero-shot learning rely on cross-modal mapping between the image feature space and the class embedding space. As labeled images are rare, one direction is to augment the dataset by generating either images or image features. However, the former misses fine-grained details and the latter requires learning a mapping associated with class embeddings. In this work, we take feature generation one step further and propose a model where a shared latent space of image features and class embeddings is learned by modality-specific aligned variational autoencoders. This leaves us with the required discriminative information about the image and classes in the latent features, on which we train a softmax classifier. The key to our approach is that we align the distributions learned from images and from side-information to construct latent features that contain the essential multi-modal information associated with unseen classes. We evaluate our learned latent features on several benchmark datasets, i.e. CUB, SUN, AWA1 and AWA2, and establish a new state-of-the-art on generalized zero-shot as well as on few-shot learning. Moreover, our results on ImageNet with various zero-shot splits show that our latent features generalize well in large-scale settings.
Inception-Residual Block based Neural Network for Thermal Image Denoising
Oct 31, 2018
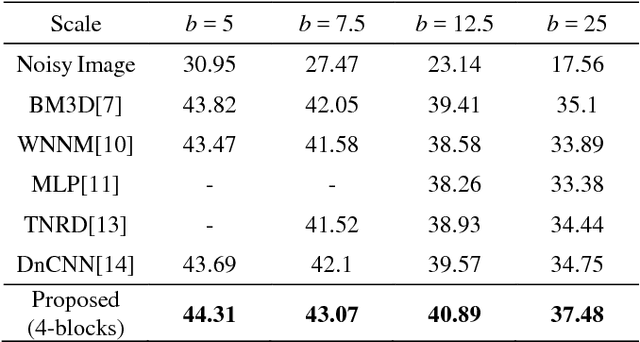

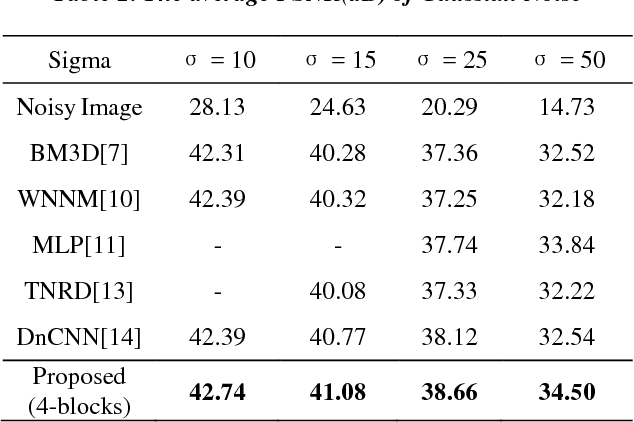
Thermal cameras shows noisy images due to their limited thermal resolution, especially for scenes of low temperature difference. In this paper, to deal with noise problem, we propose a novel neural network architecture with repeatable denoising inception residual blocks(DnIRB) for noise learning. Each DnIRB has two sub-blocks with difference receptive fields and one shortcut connection for preventing vanishing gradient problem. The proposed approach is tested for thermal images. The experimental results show that the proposed approach show the best SQNR performance and reasonable processing time compared with state-of-the-art denoising methods.
Multiview Cross-supervision for Semantic Segmentation
Dec 04, 2018

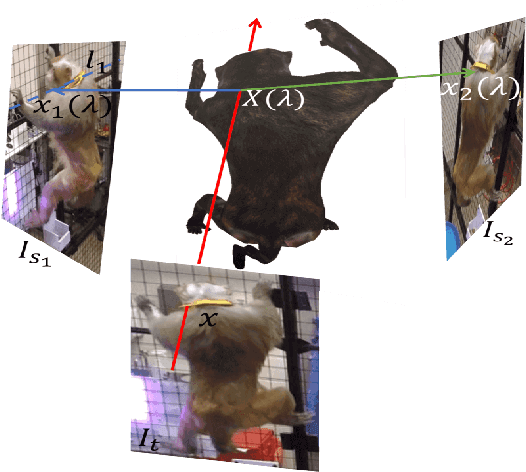
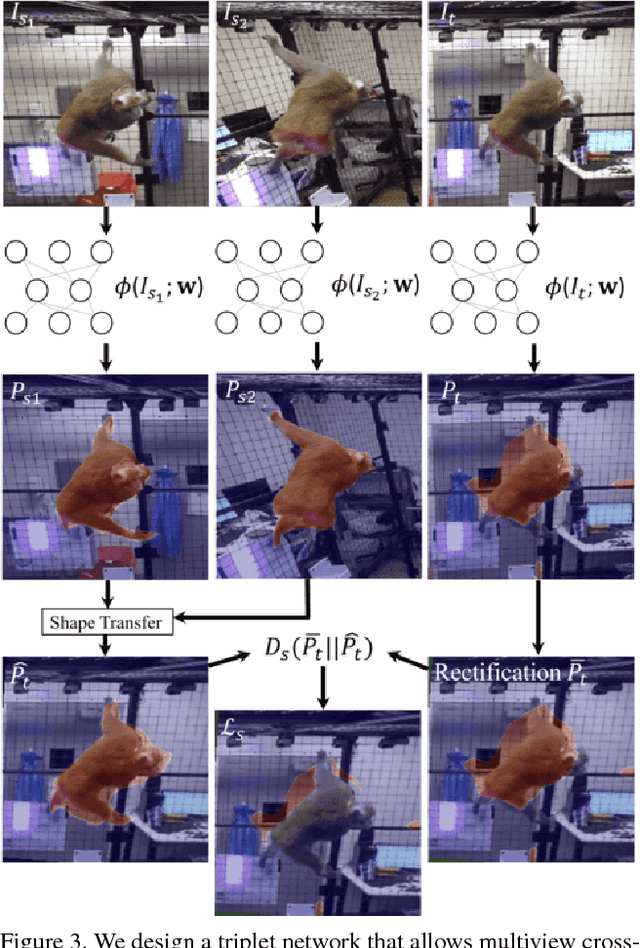
This paper presents a semi-supervised learning framework for a customized semantic segmentation task using multiview image streams. A key challenge of the customized task lies in the limited accessibility of the labeled data due to the requirement of prohibitive manual annotation effort. We hypothesize that it is possible to leverage multiview image streams that are linked through the underlying 3D geometry, which can provide an additional supervisionary signal to train a segmentation model. We formulate a new cross-supervision method using a shape belief transfer---the segmentation belief in one image is used to predict that of the other image through epipolar geometry analogous to shape-from-silhouette. The shape belief transfer provides the upper and lower bounds of the segmentation for the unlabeled data where its gap approaches asymptotically to zero as the number of the labeled views increases. We integrate this theory to design a novel network that is agnostic to camera calibration, network model, and semantic category and bypasses the intermediate process of suboptimal 3D reconstruction. We validate this network by recognizing a customized semantic category per pixel from realworld visual data including non-human species and a subject of interest in social videos where attaining large-scale annotation data is infeasible.
Assessing four Neural Networks on Handwritten Digit Recognition Dataset (MNIST)
Nov 16, 2018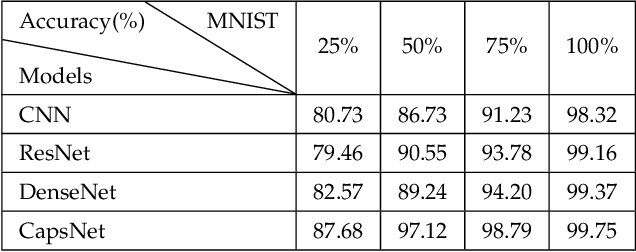
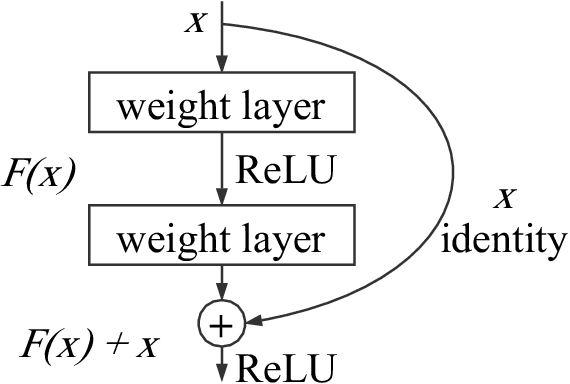
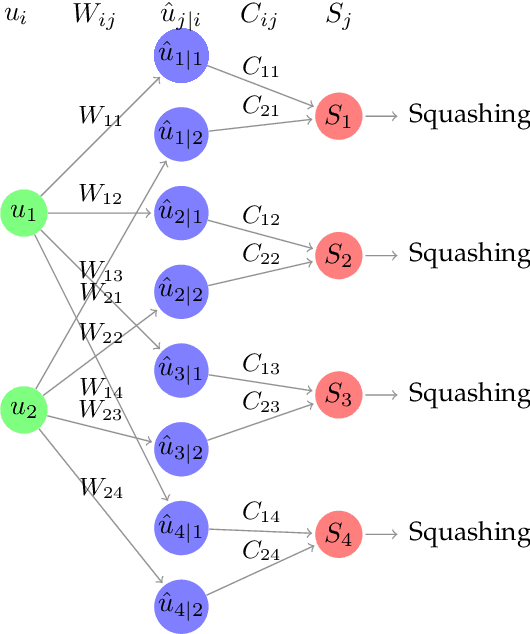
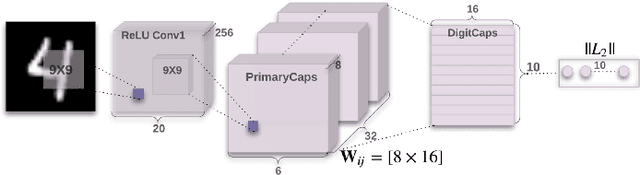
Although the image recognition has been a research topic for many years, many researchers still have a keen interest in it. In some papers, however, there is a tendency to compare models only on one or two datasets, either because of time restraints or because the model is tailored to a specific task. Accordingly, it is hard to understand how well a certain model generalizes across image recognition field. In this paper, we compare four neural networks on MNIST dataset with different division. Among of them, three are Convolutional Neural Networks (CNN), Deep Residual Network (ResNet) and Dense Convolutional Network (DenseNet) respectively, and the other is our improvement on CNN baseline through introducing Capsule Network (CapsNet) to image recognition area. We show that the previous models despite do a quite good job in this area, our retrofitting can be applied to get a better performance. The result obtained by CapsNet is an accuracy rate of 99.75\%, and it is the best result published so far. Another inspiring result is that CapsNet only needs a small amount of data to get the excellent performance. Finally, we will apply CapsNet's ability to generalize in other image recognition field in the future.
AdvPC: Transferable Adversarial Perturbations on 3D Point Clouds
Dec 01, 2019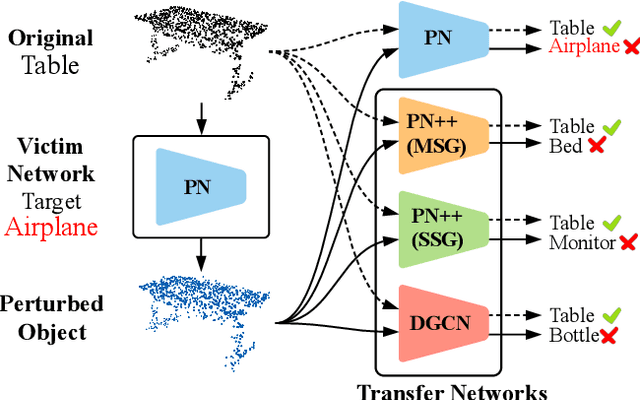
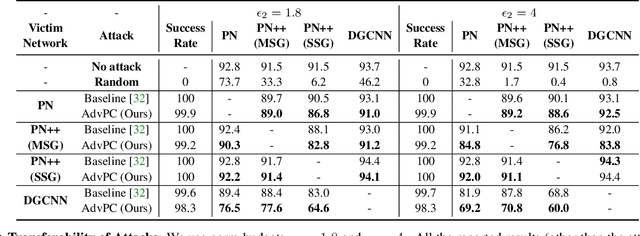
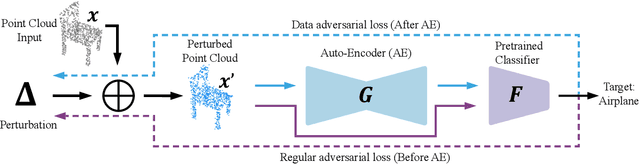
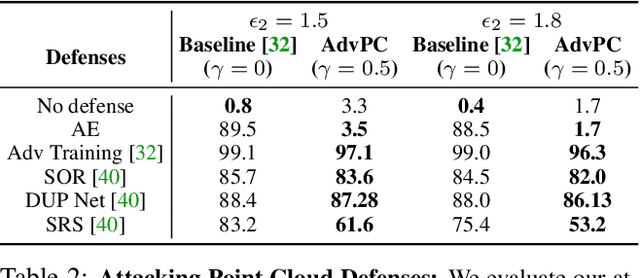
Deep neural networks are vulnerable to adversarial attacks, in which imperceptible perturbations to their input lead to erroneous network predictions. This phenomenon has been extensively studied in the image domain, and only recently extended to 3D point clouds. In this work, we present novel data-driven adversarial attacks against 3D point cloud networks. We aim to address the following problems in current 3D point cloud adversarial attacks: they do not transfer well between different networks, and they are easy to defend against simple statistical methods. To this extent, we develop new point cloud attacks (we dub AdvPC) that exploit input data distributions. These attacks lead to perturbations that are resilient against current defenses while remaining highly transferable compared to state-of-the-art attacks. We test our attacks using four popular point cloud networks: PointNet, PointNet++ (MSG and SSG), and DGCNN. Our proposed attack enables an increase in the transferability of up to 20 points for some networks. It also increases the ability to break defenses of up to 23 points on ModelNet40 data.
Multi-task Image Classification via Collaborative, Hierarchical Spike-and-Slab Priors
Jan 30, 2015

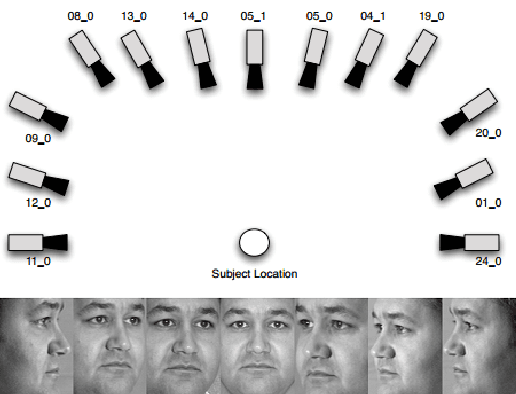
Promising results have been achieved in image classification problems by exploiting the discriminative power of sparse representations for classification (SRC). Recently, it has been shown that the use of \emph{class-specific} spike-and-slab priors in conjunction with the class-specific dictionaries from SRC is particularly effective in low training scenarios. As a logical extension, we build on this framework for multitask scenarios, wherein multiple representations of the same physical phenomena are available. We experimentally demonstrate the benefits of mining joint information from different camera views for multi-view face recognition.
Model Extraction Attacks against Recurrent Neural Networks
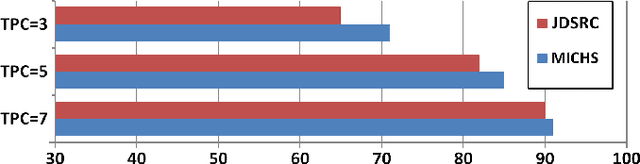
Feb 01, 2020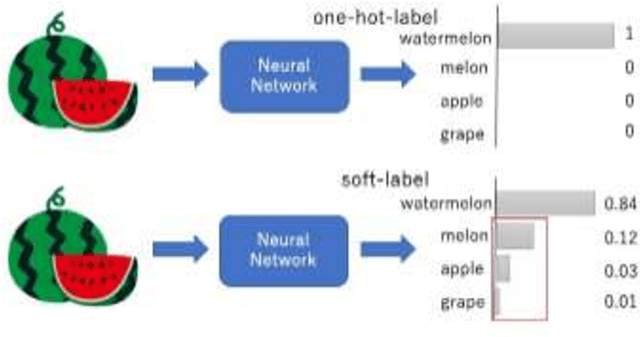
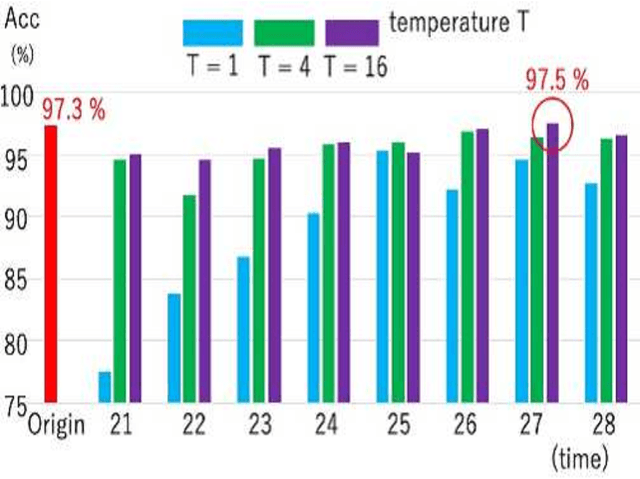
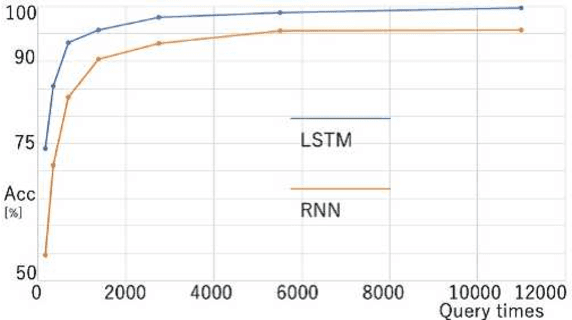
Model extraction attacks are a kind of attacks in which an adversary obtains a new model, whose performance is equivalent to that of a target model, via query access to the target model efficiently, i.e., fewer datasets and computational resources than those of the target model. Existing works have dealt with only simple deep neural networks (DNNs), e.g., only three layers, as targets of model extraction attacks, and hence are not aware of the effectiveness of recurrent neural networks (RNNs) in dealing with time-series data. In this work, we shed light on the threats of model extraction attacks against RNNs. We discuss whether a model with a higher accuracy can be extracted with a simple RNN from a long short-term memory (LSTM), which is a more complicated and powerful RNN. Specifically, we tackle the following problems. First, in a case of a classification problem, such as image recognition, extraction of an RNN model without final outputs from an LSTM model is presented by utilizing outputs halfway through the sequence. Next, in a case of a regression problem. such as in weather forecasting, a new attack by newly configuring a loss function is presented. We conduct experiments on our model extraction attacks against an RNN and an LSTM trained with publicly available academic datasets. We then show that a model with a higher accuracy can be extracted efficiently, especially through configuring a loss function and a more complex architecture different from the target model.
LatentFusion: End-to-End Differentiable Reconstruction and Rendering for Unseen Object Pose Estimation
Dec 01, 2019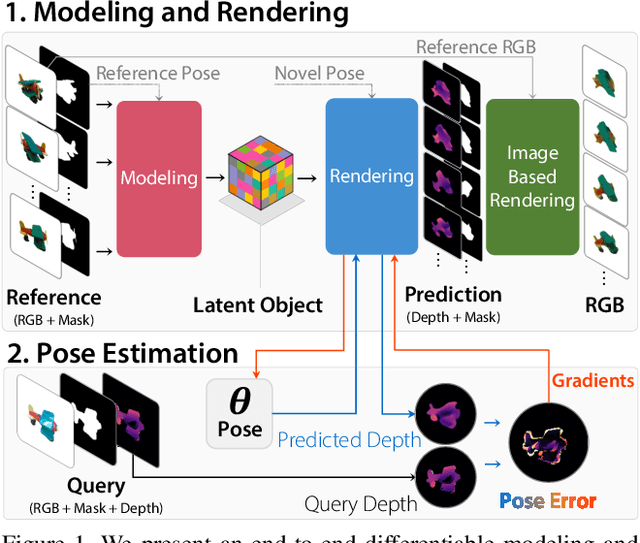
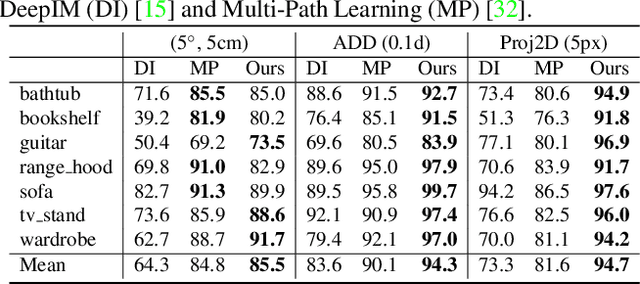
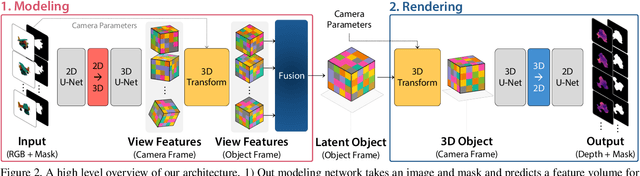
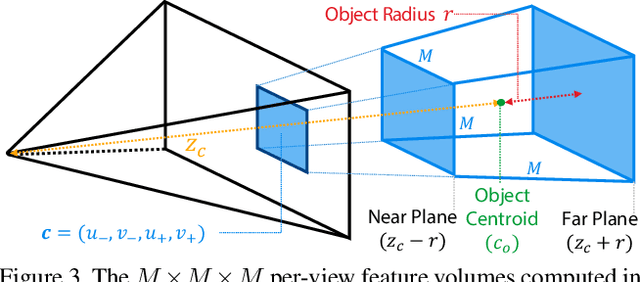
Current 6D object pose estimation methods usually require a 3D model for each object. These methods also require additional training in order to incorporate new objects. As a result, they are difficult to scale to a large number of objects and cannot be directly applied to unseen objects. In this work, we propose a novel framework for 6D pose estimation of unseen objects. We design an end-to-end neural network that reconstructs a latent 3D representation of an object using a small number of reference views of the object. Using the learned 3D representation, the network is able to render the object from arbitrary views. Using this neural renderer, we directly optimize for pose given an input image. By training our network with a large number of 3D shapes for reconstruction and rendering, our network generalizes well to unseen objects. We present a new dataset for unseen object pose estimation--MOPED. We evaluate the performance of our method for unseen object pose estimation on MOPED as well as the ModelNet dataset.
DeepOtsu: Document Enhancement and Binarization using Iterative Deep Learning
Jan 18, 2019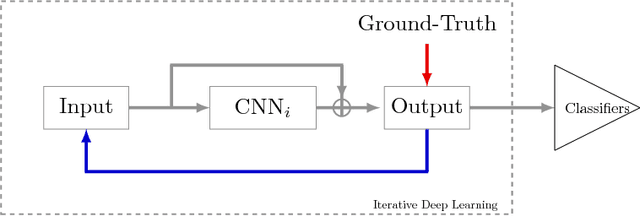
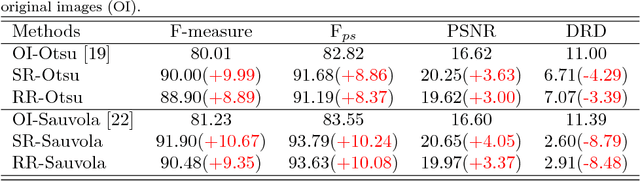


This paper presents a novel iterative deep learning framework and apply it for document enhancement and binarization. Unlike the traditional methods which predict the binary label of each pixel on the input image, we train the neural network to learn the degradations in document images and produce the uniform images of the degraded input images, which allows the network to refine the output iteratively. Two different iterative methods have been studied in this paper: recurrent refinement (RR) which uses the same trained neural network in each iteration for document enhancement and stacked refinement (SR) which uses a stack of different neural networks for iterative output refinement. Given the learned uniform and enhanced image, the binarization map can be easy to obtain by a global or local threshold. The experimental results on several public benchmark data sets show that our proposed methods provide a new clean version of the degraded image which is suitable for visualization and promising results of binarization using the global Otsu's threshold based on the enhanced images learned iteratively by the neural network.