 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detecting Out-of-Distribution Inputs in Deep Neural Networks Using an Early-Layer Output
Oct 23, 2019
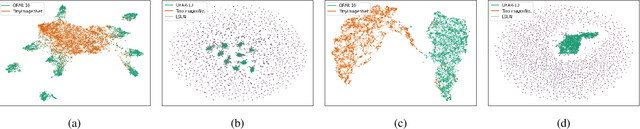

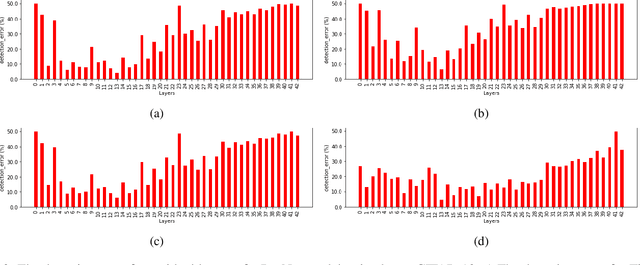
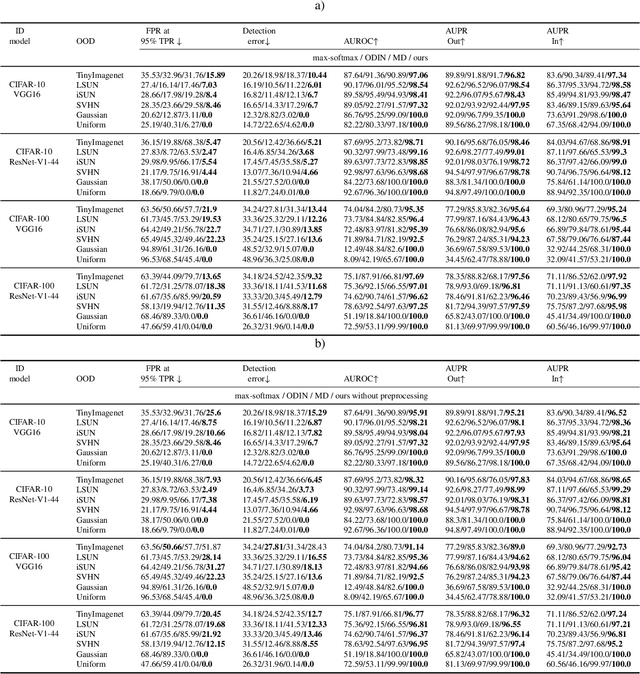
Deep neural networks achieve superior performance in challenging tasks such as image classification. However, deep classifiers tend to incorrectly classify out-of-distribution (OOD) inputs, which are inputs that do not belong to the classifier training distribution. Several approaches have been proposed to detect OOD inputs, but the detection task is still an ongoing challenge. In this paper, we propose a new OOD detection approach that can be easily applied to an existing classifier and does not need to have access to OOD samples. The detector is a one-class classifier trained on the output of an early layer of the original classifier fed with its original training set. We apply our approach to several low- and high-dimensional datasets and compare it to the state-of-the-art detection approaches. Our approach achieves substantially better results over multiple metrics.
DeepOtsu: Document Enhancement and Binarization using Iterative Deep Learning
Jan 18, 2019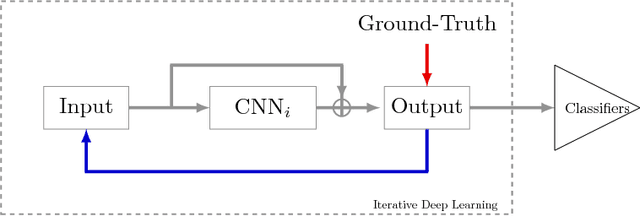
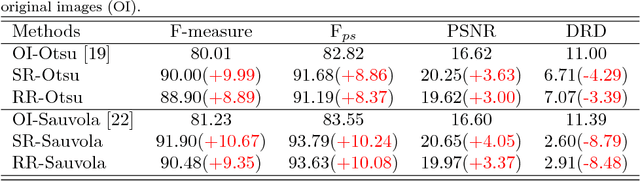


This paper presents a novel iterative deep learning framework and apply it for document enhancement and binarization. Unlike the traditional methods which predict the binary label of each pixel on the input image, we train the neural network to learn the degradations in document images and produce the uniform images of the degraded input images, which allows the network to refine the output iteratively. Two different iterative methods have been studied in this paper: recurrent refinement (RR) which uses the same trained neural network in each iteration for document enhancement and stacked refinement (SR) which uses a stack of different neural networks for iterative output refinement. Given the learned uniform and enhanced image, the binarization map can be easy to obtain by a global or local threshold. The experimental results on several public benchmark data sets show that our proposed methods provide a new clean version of the degraded image which is suitable for visualization and promising results of binarization using the global Otsu's threshold based on the enhanced images learned iteratively by the neural network.
Bridging adversarial samples and adversarial networks
Dec 20, 2019
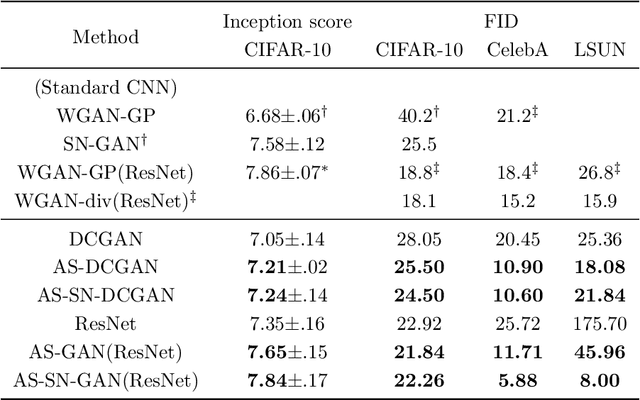


Generative adversarial networks have achieved remarkable performance on various tasks but suffer from training instability. In this paper, we investigate this problem from the perspective of adversarial samples. We find that adversarial training on fake samples has been implemented in vanilla GAN but that on real samples does not exist, which makes adversarial training unsymmetric. Consequently, discriminator is vulnerable to adversarial perturbation and the gradient given by discriminator contains uninformative adversarial noise. Adversarial noise can not improve the fidelity of generated samples but can drastically change the prediction of discriminator, which can hinder generator from catching the pattern of real samples and cause instability in training. To this end, we further incorporate adversarial training of discriminator on real samples into vanilla GANs. This scheme can make adversarial training symmetric and make discriminator more robust. Robust discriminator can give more informative gradient with less adversarial noise, which can stabilize training and accelerate convergence. We validate the proposed method on image generation on CIFAR-10 , CelebA, and LSUN with varied network architectures. Experiments show that training is stabilized and FID scores of generated samples are improved by $10\% \sim 50\%$ relative to the baseline with additional $25\%$ computation cost.
Self-labelling via simultaneous clustering and representation learning
Nov 13, 2019
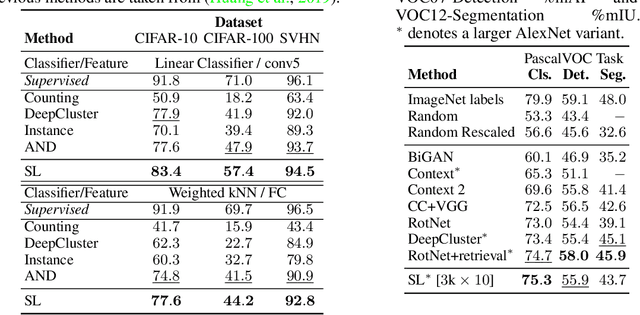
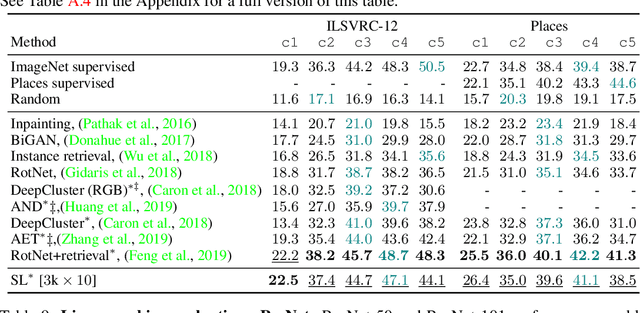
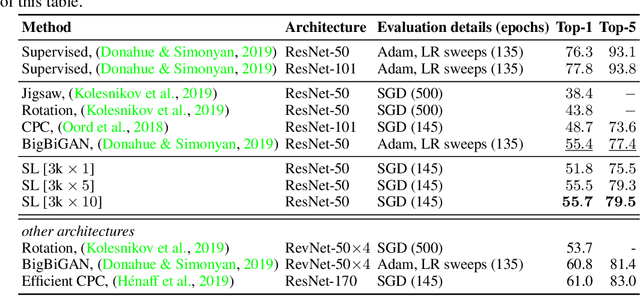
Combining clustering and representation learning is one of the most promising approaches for unsupervised learning of deep neural networks. However, doing so naively leads to ill posed learning problems with degenerate solutions. In this paper, we propose a novel and principled learning formulation that addresses these issues. The method is obtained by maximizing the information between labels and input data indices. We show that this criterion extends standard cross-entropy minimization to an optimal transport problem, which we solve efficiently for millions of input images and thousands of labels using a fast variant of the Sinkhorn-Knopp algorithm. The resulting method is able to self-label visual data so as to train highly competitive image representations without manual labels. Compared to the best previous method in this class, namely DeepCluster, our formulation minimizes a single objective function for both representation learning and clustering; it also significantly outperforms DeepCluster in standard benchmarks and reaches state of the art for learning a ResNet-50 self-supervisedly.
SpatialFlow: Bridging All Tasks for Panoptic Segmentation
Dec 02, 2019
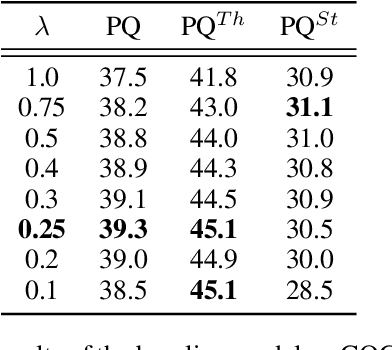
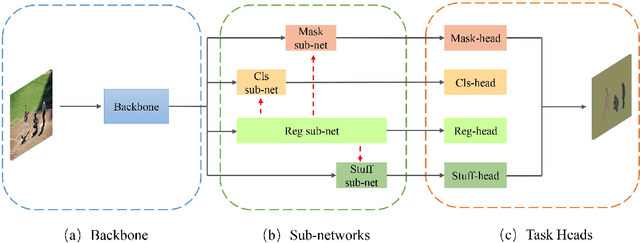
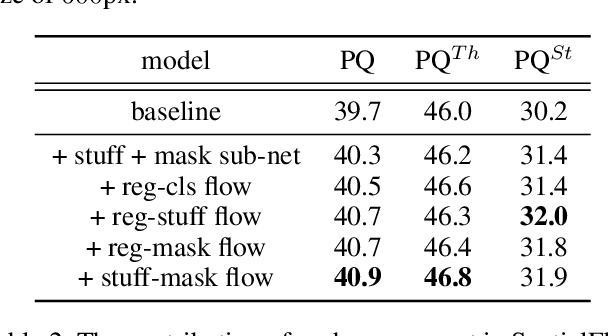
Object location is fundamental to panoptic segmentation as it is related to all things and stuff. How to integrate object location in both thing and stuff segmentation is a crucial problem. In this paper, we propose object spatial information flows to achieve this objective. More importantly, we design four parallel sub-networks for sub-tasks in panoptic segmentation, which leads to the preferable adaptation of object spatial information. With sub-networks, the flows can bridge all tasks together by delivering the object's spatial context from the box regression task to others. They can also provide clues for segmenting both things and stuff, which helps the network better understand the whole image. Upon the sub-networks and the flows, we present a location-aware and unified framework for panoptic segmentation, denoted as SpatialFlow. We perform a detailed ablation study on each component and conduct extensive experiments to prove the effectiveness of Our SpatialFlow. Furthermore, we achieve state-of-the-art results, which are $47.3$ PQ and $62.5$ PQ respectively on MS-COCO and Cityscapes panoptic benchmarks.
What is not where: the challenge of integrating spatial representations into deep learning architectures
Jul 21, 2018
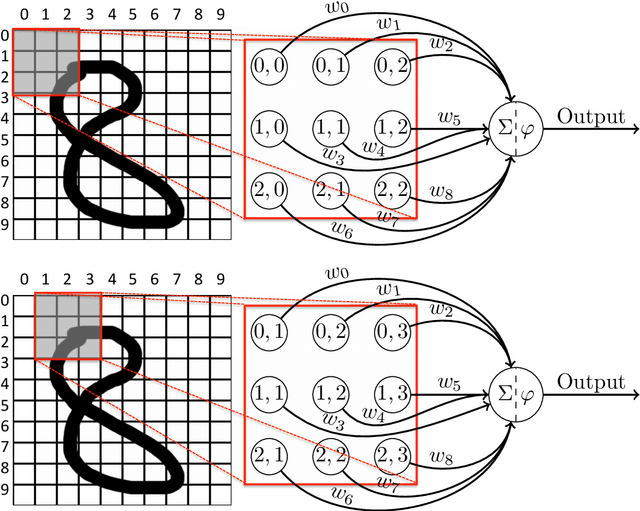
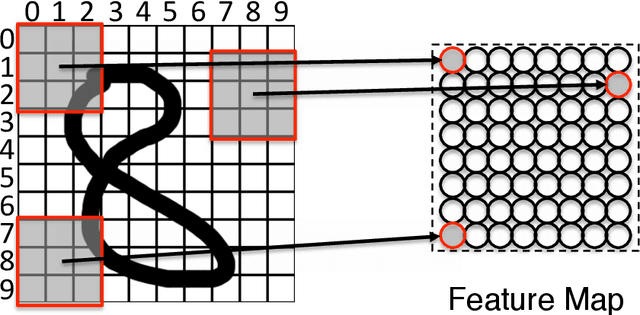
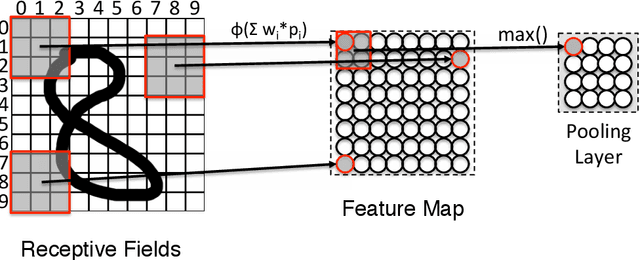
This paper examines to what degree current deep learning architectures for image caption generation capture spatial language. On the basis of the evaluation of examples of generated captions from the literature we argue that systems capture what objects are in the image data but not where these objects are located: the captions generated by these systems are the output of a language model conditioned on the output of an object detector that cannot capture fine-grained location information. Although language models provide useful knowledge for image captions, we argue that deep learning image captioning architectures should also model geometric relations between objects.
Learning to Map Nearly Anything
Sep 16, 2019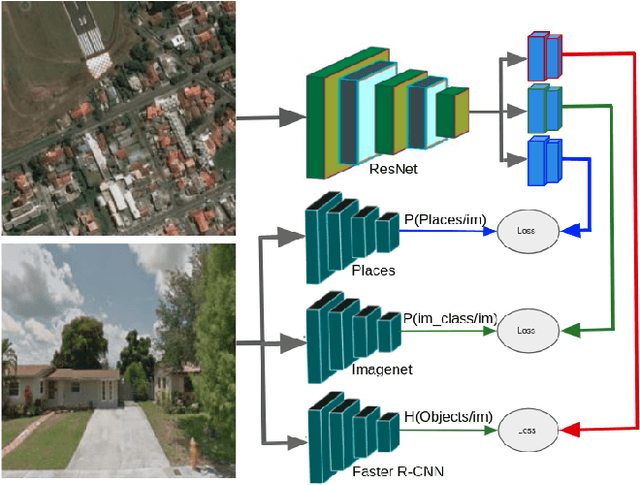


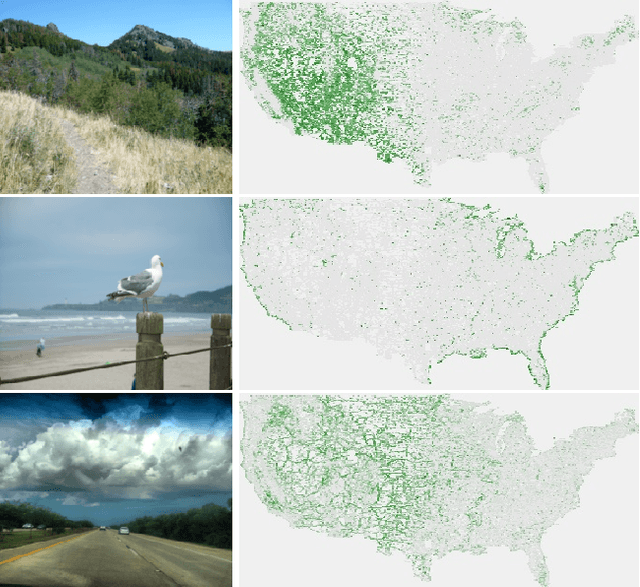
Looking at the world from above, it is possible to estimate many properties of a given location, including the type of land cover and the expected land use. Historically, such tasks have relied on relatively coarse-grained categories due to the difficulty of obtaining fine-grained annotations. In this work, we propose an easily extensible approach that makes it possible to estimate fine-grained properties from overhead imagery. In particular, we propose a cross-modal distillation strategy to learn to predict the distribution of fine-grained properties from overhead imagery, without requiring any manual annotation of overhead imagery. We show that our learned models can be used directly for applications in mapping and image localization.
Improving singing voice separation with the Wave-U-Net using Minimum Hyperspherical Energy
Oct 22, 2019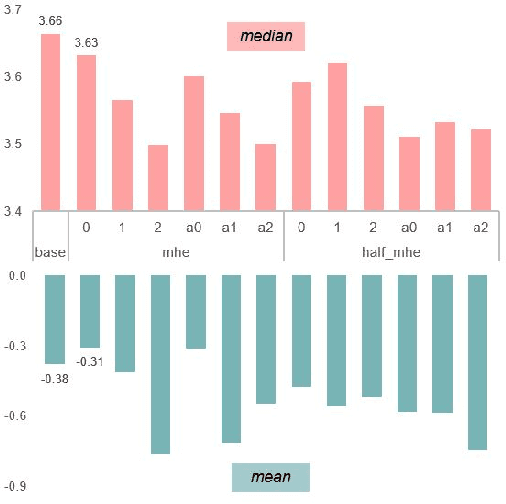
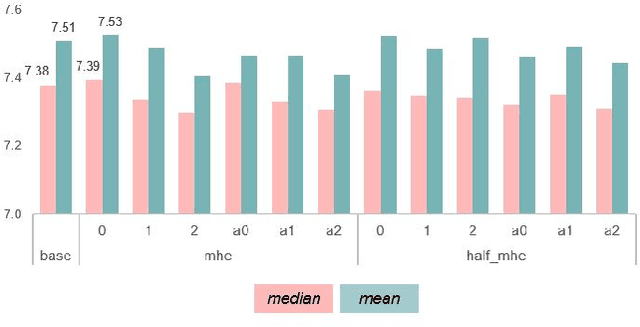
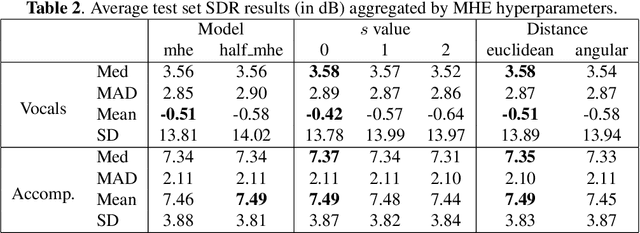

In recent years, deep learning has surpassed traditional approaches to the problem of singing voice separation. The Wave-U-Net is a recent deep network architecture that operates directly on the time domain. The standard Wave-U-Net is trained with data augmentation and early stopping to prevent overfitting. Minimum hyperspherical energy (MHE) regularization has recently proven to increase generalization in image classification problems by encouraging a diversified filter configuration. In this work, we apply MHE regularization to the 1D filters of the Wave-U-Net. We evaluated this approach for separating the vocal part from mixed music audio recordings on the MUSDB18 dataset. We found that adding MHE regularization to the loss function consistently improves singing voice separation, as measured in the Signal to Distortion Ratio on test recordings, leading to the current best time-domain system for singing voice extraction.
Curiosity-driven Reinforcement Learning for Diverse Visual Paragraph Generation
Aug 01, 2019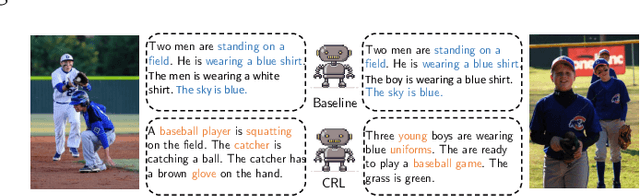
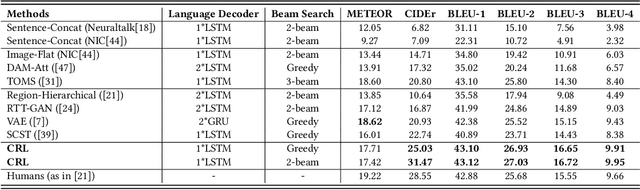
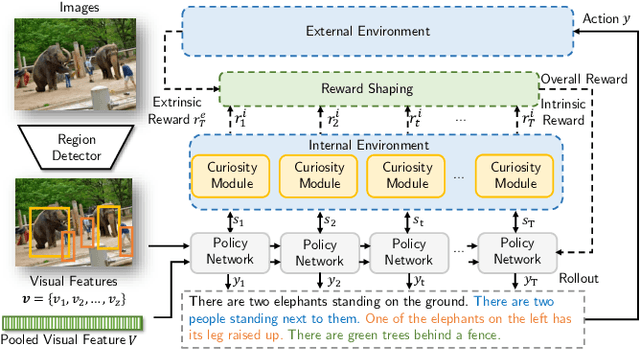
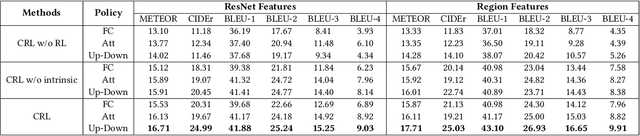
Visual paragraph generation aims to automatically describe a given image from different perspectives and organize sentences in a coherent way. In this paper, we address three critical challenges for this task in a reinforcement learning setting: the mode collapse, the delayed feedback, and the time-consuming warm-up for policy networks. Generally, we propose a novel Curiosity-driven Reinforcement Learning (CRL) framework to jointly enhance the diversity and accuracy of the generated paragraphs. First, by modeling the paragraph captioning as a long-term decision-making process and measuring the prediction uncertainty of state transitions as intrinsic rewards, the model is incentivized to memorize precise but rarely spotted descriptions to context, rather than being biased towards frequent fragments and generic patterns. Second, since the extrinsic reward from evaluation is only available until the complete paragraph is generated, we estimate its expected value at each time step with temporal-difference learning, by considering the correlations between successive actions. Then the estimated extrinsic rewards are complemented by dense intrinsic rewards produced from the derived curiosity module, in order to encourage the policy to fully explore action space and find a global optimum. Third, discounted imitation learning is integrated for learning from human demonstrations, without separately performing the time-consuming warm-up in advance. Extensive experiments conducted on the Standford image-paragraph dataset demonstrate the effectiveness and efficiency of the proposed method, improving the performance by 38.4% compared with state-of-the-art.
Smart Home Appliances: Chat with Your Fridge
Dec 19, 2019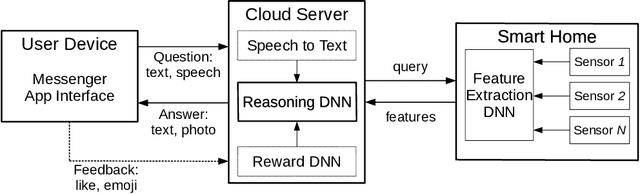
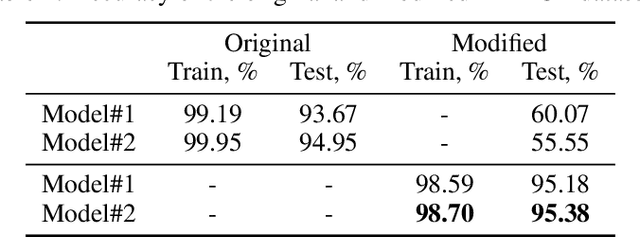

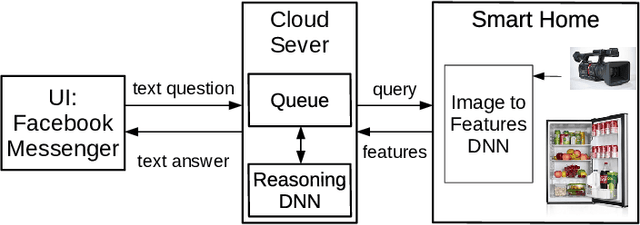
Current home appliances are capable to execute a limited number of voice commands such as turning devices on or off, adjusting music volume or light conditions. Recent progress in machine reasoning gives an opportunity to develop new types of conversational user interfaces for home appliances. In this paper, we apply state-of-the-art visual reasoning model and demonstrate that it is feasible to ask a smart fridge about its contents and various properties of the food with close-to-natural conversation experience. Our visual reasoning model answers user questions about existence, count, category and freshness of each product by analyzing photos made by the image sensor inside the smart fridge. Users may chat with their fridge using off-the-shelf phone messenger while being away from home, for example, when shopping in the supermarket. We generate a visually realistic synthetic dataset to train machine learning reasoning model that achieves 95% answer accuracy on test data. We present the results of initial user tests and discuss how we modify distribution of generated questions for model training based on human-in-the-loop guidance. We open source code for the whole system including dataset generation, reasoning model and demonstration scripts.