 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Assisting Blind People Using Object Detection with Vocal Feedback
Dec 18, 2023
For visually impaired people, it is highly difficult to make independent movement and safely move in both indoors and outdoors environment. Furthermore, these physically and visually challenges prevent them from in day-today live activities. Similarly, they have problem perceiving objects of surrounding environment that may pose a risk to them. The proposed approach suggests detection of objects in real-time video by using a web camera, for the object identification, process. You Look Only Once (YOLO) model is utilized which is CNN-based real-time object detection technique. Additionally, The OpenCV libraries of Python is used to implement the software program as well as deep learning process is performed. Image recognition results are transferred to the visually impaired users in audible form by means of Google text-to-speech library and determine object location relative to its position in the screen. The obtaining result was evaluated by using the mean Average Precision (mAP), and it was found that the proposed approach achieves excellent results when it compared to previous approaches.
Cross-Age Contrastive Learning for Age-Invariant Face Recognition
Dec 18, 2023Cross-age facial images are typically challenging and expensive to collect, making noise-free age-oriented datasets relatively small compared to widely-used large-scale facial datasets. Additionally, in real scenarios, images of the same subject at different ages are usually hard or even impossible to obtain. Both of these factors lead to a lack of supervised data, which limits the versatility of supervised methods for age-invariant face recognition, a critical task in applications such as security and biometrics. To address this issue, we propose a novel semi-supervised learning approach named Cross-Age Contrastive Learning (CACon). Thanks to the identity-preserving power of recent face synthesis models, CACon introduces a new contrastive learning method that leverages an additional synthesized sample from the input image. We also propose a new loss function in association with CACon to perform contrastive learning on a triplet of samples. We demonstrate that our method not only achieves state-of-the-art performance in homogeneous-dataset experiments on several age-invariant face recognition benchmarks but also outperforms other methods by a large margin in cross-dataset experiments.
RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation
Dec 19, 20233D occupancy prediction is an emerging task that aims to estimate the occupancy states and semantics of 3D scenes using multi-view images. However, image-based scene perception encounters significant challenges in achieving accurate prediction due to the absence of geometric priors. In this paper, we address this issue by exploring cross-modal knowledge distillation in this task, i.e., we leverage a stronger multi-modal model to guide the visual model during training. In practice, we observe that directly applying features or logits alignment, proposed and widely used in bird's-eyeview (BEV) perception, does not yield satisfactory results. To overcome this problem, we introduce RadOcc, a Rendering assisted distillation paradigm for 3D Occupancy prediction. By employing differentiable volume rendering, we generate depth and semantic maps in perspective views and propose two novel consistency criteria between the rendered outputs of teacher and student models. Specifically, the depth consistency loss aligns the termination distributions of the rendered rays, while the semantic consistency loss mimics the intra-segment similarity guided by vision foundation models (VLMs). Experimental results on the nuScenes dataset demonstrate the effectiveness of our proposed method in improving various 3D occupancy prediction approaches, e.g., our proposed methodology enhances our baseline by 2.2% in the metric of mIoU and achieves 50% in Occ3D benchmark.
Multi-View Unsupervised Image Generation with Cross Attention Guidance
Dec 07, 2023The growing interest in novel view synthesis, driven by Neural Radiance Field (NeRF) models, is hindered by scalability issues due to their reliance on precisely annotated multi-view images. Recent models address this by fine-tuning large text2image diffusion models on synthetic multi-view data. Despite robust zero-shot generalization, they may need post-processing and can face quality issues due to the synthetic-real domain gap. This paper introduces a novel pipeline for unsupervised training of a pose-conditioned diffusion model on single-category datasets. With the help of pretrained self-supervised Vision Transformers (DINOv2), we identify object poses by clustering the dataset through comparing visibility and locations of specific object parts. The pose-conditioned diffusion model, trained on pose labels, and equipped with cross-frame attention at inference time ensures cross-view consistency, that is further aided by our novel hard-attention guidance. Our model, MIRAGE, surpasses prior work in novel view synthesis on real images. Furthermore, MIRAGE is robust to diverse textures and geometries, as demonstrated with our experiments on synthetic images generated with pretrained Stable Diffusion.
Post-training Quantization with Progressive Calibration and Activation Relaxing for Text-to-Image Diffusion Models
Nov 18, 2023Diffusion models have achieved great success due to their remarkable generation ability. However, their high computational overhead is still a troublesome problem. Recent studies have leveraged post-training quantization (PTQ) to compress diffusion models. However, most of them only focus on unconditional models, leaving the quantization of widely used large pretrained text-to-image models, e.g., Stable Diffusion, largely unexplored. In this paper, we propose a novel post-training quantization method PCR (Progressive Calibration and Relaxing) for text-to-image diffusion models, which consists of a progressive calibration strategy that considers the accumulated quantization error across timesteps, and an activation relaxing strategy that improves the performance with negligible cost. Additionally, we demonstrate the previous metrics for text-to-image diffusion model quantization are not accurate due to the distribution gap. To tackle the problem, we propose a novel QDiffBench benchmark, which utilizes data in the same domain for more accurate evaluation. Besides, QDiffBench also considers the generalization performance of the quantized model outside the calibration dataset. Extensive experiments on Stable Diffusion and Stable Diffusion XL demonstrate the superiority of our method and benchmark. Moreover, we are the first to achieve quantization for Stable Diffusion XL while maintaining the performance.
Towards Robust and Expressive Whole-body Human Pose and Shape Estimation
Dec 14, 2023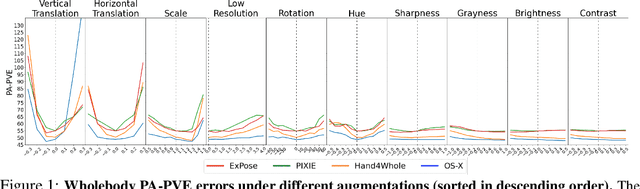


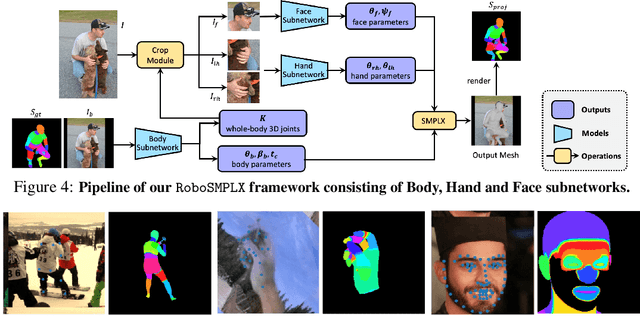
Whole-body pose and shape estimation aims to jointly predict different behaviors (e.g., pose, hand gesture, facial expression) of the entire human body from a monocular image. Existing methods often exhibit degraded performance under the complexity of in-the-wild scenarios. We argue that the accuracy and reliability of these models are significantly affected by the quality of the predicted \textit{bounding box}, e.g., the scale and alignment of body parts. The natural discrepancy between the ideal bounding box annotations and model detection results is particularly detrimental to the performance of whole-body pose and shape estimation. In this paper, we propose a novel framework to enhance the robustness of whole-body pose and shape estimation. Our framework incorporates three new modules to address the above challenges from three perspectives: \textbf{1) Localization Module} enhances the model's awareness of the subject's location and semantics within the image space. \textbf{2) Contrastive Feature Extraction Module} encourages the model to be invariant to robust augmentations by incorporating contrastive loss with dedicated positive samples. \textbf{3) Pixel Alignment Module} ensures the reprojected mesh from the predicted camera and body model parameters are accurate and pixel-aligned. We perform comprehensive experiments to demonstrate the effectiveness of our proposed framework on body, hands, face and whole-body benchmarks. Codebase is available at \url{https://github.com/robosmplx/robosmplx}.
Factorization Vision Transformer: Modeling Long Range Dependency with Local Window Cost
Dec 14, 2023Transformers have astounding representational power but typically consume considerable computation which is quadratic with image resolution. The prevailing Swin transformer reduces computational costs through a local window strategy. However, this strategy inevitably causes two drawbacks: (1) the local window-based self-attention hinders global dependency modeling capability; (2) recent studies point out that local windows impair robustness. To overcome these challenges, we pursue a preferable trade-off between computational cost and performance. Accordingly, we propose a novel factorization self-attention mechanism (FaSA) that enjoys both the advantages of local window cost and long-range dependency modeling capability. By factorizing the conventional attention matrix into sparse sub-attention matrices, FaSA captures long-range dependencies while aggregating mixed-grained information at a computational cost equivalent to the local window-based self-attention. Leveraging FaSA, we present the factorization vision transformer (FaViT) with a hierarchical structure. FaViT achieves high performance and robustness, with linear computational complexity concerning input image spatial resolution. Extensive experiments have shown FaViT's advanced performance in classification and downstream tasks. Furthermore, it also exhibits strong model robustness to corrupted and biased data and hence demonstrates benefits in favor of practical applications. In comparison to the baseline model Swin-T, our FaViT-B2 significantly improves classification accuracy by 1% and robustness by 7%, while reducing model parameters by 14%. Our code will soon be publicly available at https://github.com/q2479036243/FaViT.
Synthesizing Black-box Anti-forensics DeepFakes with High Visual Quality
Dec 17, 2023DeepFake, an AI technology for creating facial forgeries, has garnered global attention. Amid such circumstances, forensics researchers focus on developing defensive algorithms to counter these threats. In contrast, there are techniques developed for enhancing the aggressiveness of DeepFake, e.g., through anti-forensics attacks, to disrupt forensic detectors. However, such attacks often sacrifice image visual quality for improved undetectability. To address this issue, we propose a method to generate novel adversarial sharpening masks for launching black-box anti-forensics attacks. Unlike many existing arts, with such perturbations injected, DeepFakes could achieve high anti-forensics performance while exhibiting pleasant sharpening visual effects. After experimental evaluations, we prove that the proposed method could successfully disrupt the state-of-the-art DeepFake detectors. Besides, compared with the images processed by existing DeepFake anti-forensics methods, the visual qualities of anti-forensics DeepFakes rendered by the proposed method are significantly refined.
Rethinking Multiple Instance Learning for Whole Slide Image Classification: A Bag-Level Classifier is a Good Instance-Level Teacher
Dec 02, 2023Multiple Instance Learning (MIL) has demonstrated promise in Whole Slide Image (WSI) classification. However, a major challenge persists due to the high computational cost associated with processing these gigapixel images. Existing methods generally adopt a two-stage approach, comprising a non-learnable feature embedding stage and a classifier training stage. Though it can greatly reduce the memory consumption by using a fixed feature embedder pre-trained on other domains, such scheme also results in a disparity between the two stages, leading to suboptimal classification accuracy. To address this issue, we propose that a bag-level classifier can be a good instance-level teacher. Based on this idea, we design Iteratively Coupled Multiple Instance Learning (ICMIL) to couple the embedder and the bag classifier at a low cost. ICMIL initially fix the patch embedder to train the bag classifier, followed by fixing the bag classifier to fine-tune the patch embedder. The refined embedder can then generate better representations in return, leading to a more accurate classifier for the next iteration. To realize more flexible and more effective embedder fine-tuning, we also introduce a teacher-student framework to efficiently distill the category knowledge in the bag classifier to help the instance-level embedder fine-tuning. Thorough experiments were conducted on four distinct datasets to validate the effectiveness of ICMIL. The experimental results consistently demonstrate that our method significantly improves the performance of existing MIL backbones, achieving state-of-the-art results. The code is available at: https://github.com/Dootmaan/ICMIL/tree/confidence_based
Stable diffusion for Data Augmentation in COCO and Weed Datasets
Dec 07, 2023Generative models have increasingly impacted relative tasks ranging from image revision and object detection in computer vision to interior design and idea illustration in more general fields. Stable diffusion is an outstanding model series that paves the way for producing high-resolution images with thorough details from text prompts or reference images. It will be an interesting topic about how to leverage the capability of stable diffusion to elevate the image variations of certain categories (e.g., vehicles, humans, and daily objects); particularly, it has the potential to gain improvements for small datasets with image-sparse categories. This study utilized seven categories in the popular COCO dataset and three widespread weed species in Michigan to evaluate the efficiency of a recent version of stable diffusion. In detail, Stable diffusion was used to generate synthetic images belonging to these classes; then, YOLOv8 models were trained based on these synthetic images, whose performance was compared to the models trained on original images. In addition, several techniques (e.g., Image-to-image translation, Dreambooth, ControlNet) of Stable diffusion were leveraged for image generation with different focuses. In spite of the overall results being disappointing, promising results have been achieved in some classes, illustrating the potential of stable diffusion models to improve the performance of detection models, which represent more helpful information being conveyed into the models by the generated images. This seminal study may expedite the adaption of stable diffusion models to classification and detection tasks in different fields.