 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Re-identification of Manta Rays from Natural Markings by Learning Pose Invariant Embeddings
Feb 28, 2019
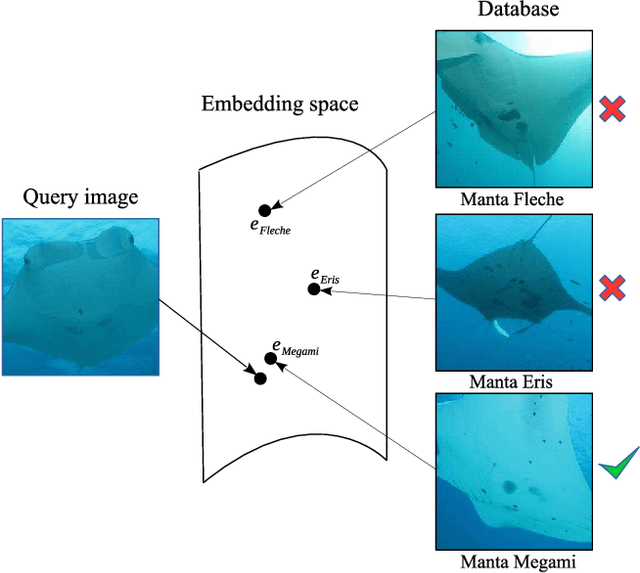
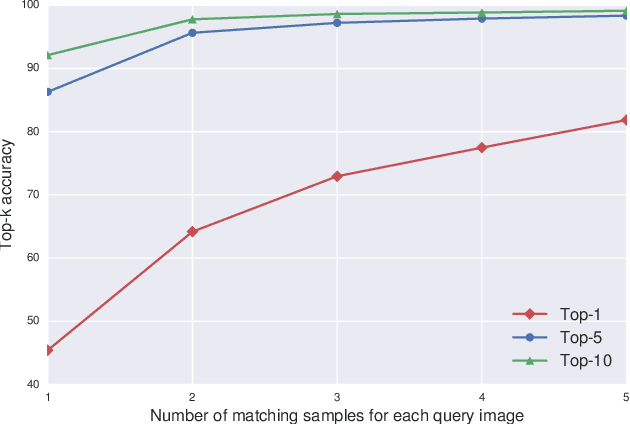


Visual identification of individual animals that bear unique natural body markings is an important task in wildlife conservation. The photo databases of animal markings grow larger and each new observation has to be matched against thousands of images. Existing photo-identification solutions have constraints on image quality and appearance of the pattern of interest in the image. These constraints limit the use of photos from citizen scientists. We present a novel system for visual re-identification based on unique natural markings that is robust to occlusions, viewpoint and illumination changes. We adapt methods developed for face re-identification and implement a deep convolutional neural network (CNN) to learn embeddings for images of natural markings. The distance between the learned embedding points provides a dissimilarity measure between the corresponding input images. The network is optimized using the triplet loss function and the online semi-hard triplet mining strategy. The proposed re-identification method is generic and not species specific. We evaluate the proposed system on image databases of manta ray belly patterns and humpback whale flukes. To be of practical value and adopted by marine biologists, a re-identification system needs to have a top-10 accuracy of at least 95%. The proposed system achieves this performance standard.
UWGAN: Underwater GAN for Real-world Underwater Color Restoration and Dehazing
Dec 21, 2019In real-world underwater environment, exploration of seabed resources, underwater archaeology, and underwater fishing rely on a variety of sensors, vision sensor is the most important one due to its high information content, non-intrusive, and passive nature. However, wavelength-dependent light attenuation and back-scattering result in color distortion and haze effect, which degrade the visibility of images. To address this problem, firstly, we proposed an unsupervised generative adversarial network (GAN) for generating realistic underwater images (color distortion and haze effect) from in-air image and depth map pairs based on improved underwater imaging model. Secondly, U-Net, which is trained efficiently using synthetic underwater dataset, is adopted for color restoration and dehazing. Our model directly reconstructs underwater clear images using end-to-end autoencoder networks, while maintaining scene content structural similarity. The results obtained by our method were compared with existing methods qualitatively and quantitatively. Experimental results obtained by the proposed model demonstrate well performance on open real-world underwater datasets, and the processing speed can reach up to 125FPS running on one NVIDIA 1060 GPU. Source code, sample datasets are made publicly available at https://github.com/infrontofme/UWGAN_UIE.
Character-Centric Storytelling
Sep 17, 2019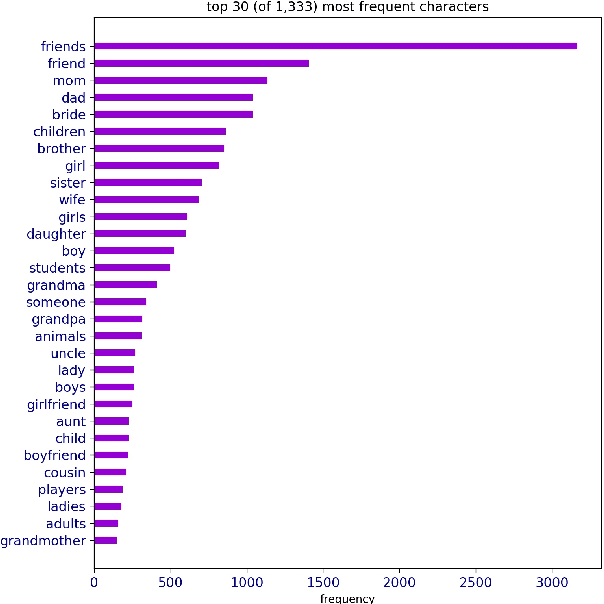
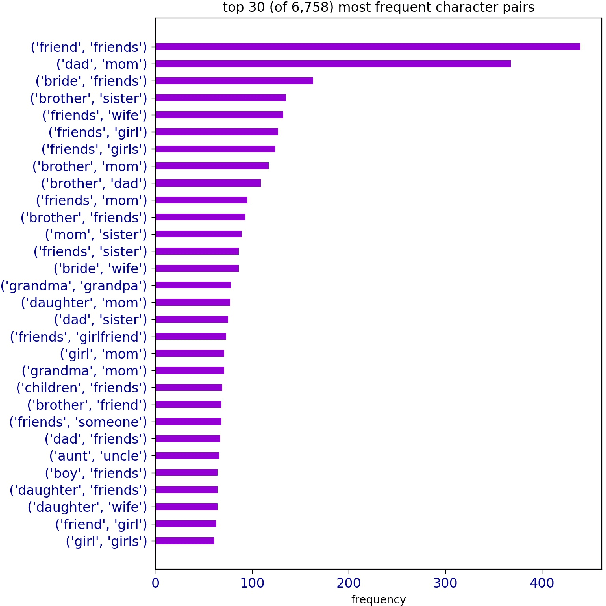
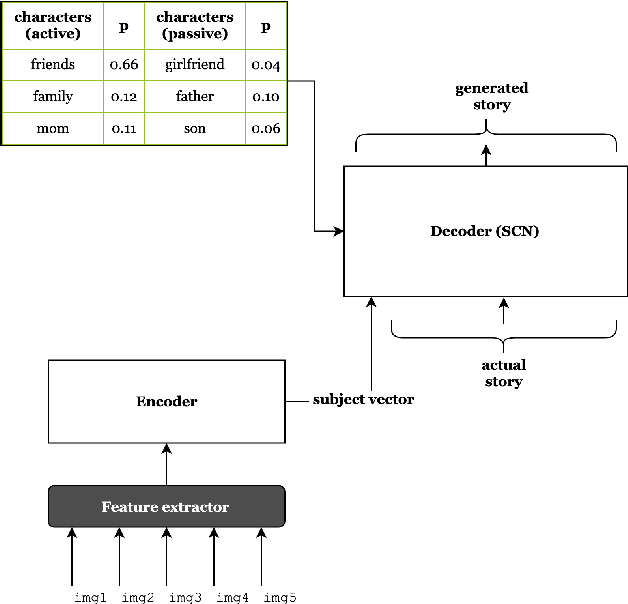
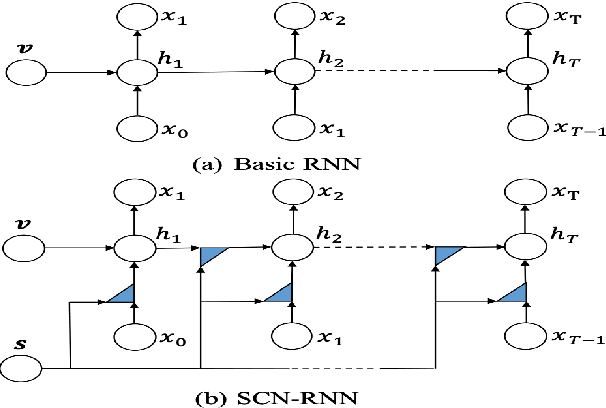
Sequential vision-to-language or visual storytelling has recently been one of the areas of focus in computer vision and language modeling domains. Though existing models generate narratives that read subjectively well, there could be cases when these models miss out on generating stories that account and address all prospective human and animal characters in the image sequences. Considering this scenario, we propose a model that implicitly learns relationships between provided characters and thereby generates stories with respective characters in scope. We use the VIST dataset for this purpose and report numerous statistics on the dataset. Eventually, we describe the model, explain the experiment and discuss our current status and future work.
Color Constancy by GANs: An Experimental Survey
Dec 07, 2018
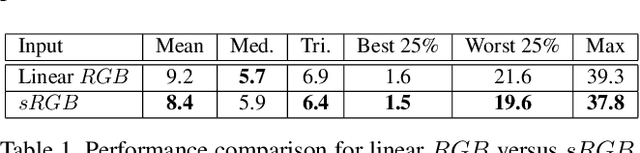
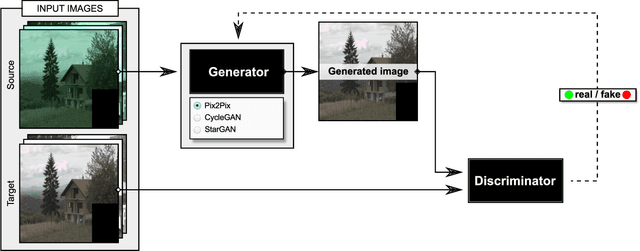
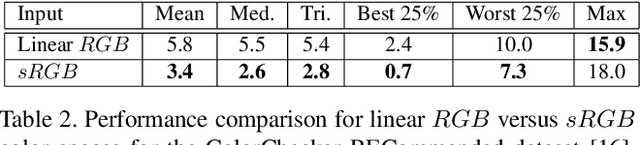
In this paper, we formulate the color constancy task as an image-to-image translation problem using GANs. By conducting a large set of experiments on different datasets, an experimental survey is provided on the use of different types of GANs to solve for color constancy i.e. CC-GANs (Color Constancy GANs). Based on the experimental review, recommendations are given for the design of CC-GAN architectures based on different criteria, circumstances and datasets.
No Surprises: Training Robust Lung Nodule Detection for Low-Dose CT Scans by Augmenting with Adversarial Attacks
Mar 08, 2020

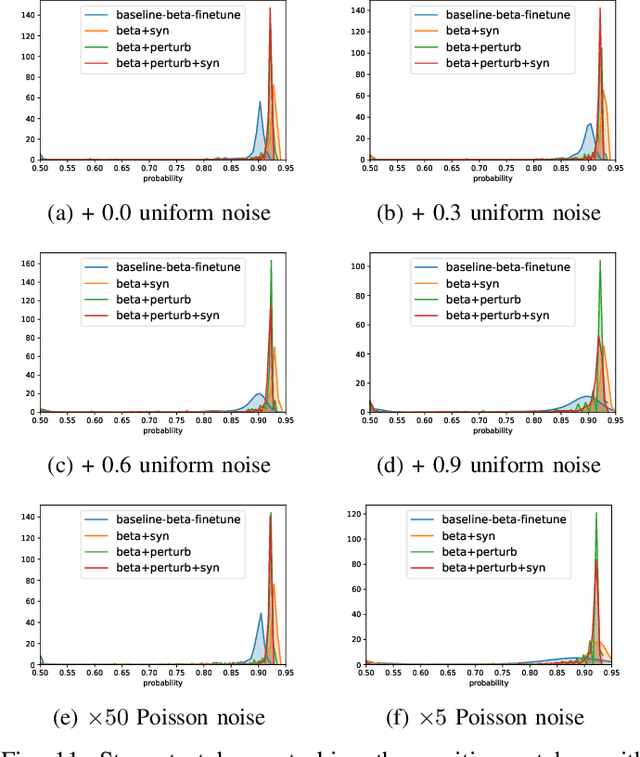
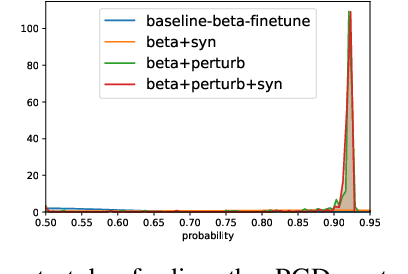
Detecting malignant pulmonary nodules at an early stage can allow medical interventions which increases the survival rate of lung cancer patients. Using computer vision techniques to detect nodules can improve the sensitivity and the speed of interpreting chest CT for lung cancer screening. Many studies have used CNNs to detect nodule candidates. Though such approaches have been shown to outperform the conventional image processing based methods regarding the detection accuracy, CNNs are also known to be limited to generalize on under-represented samples in the training set and prone to imperceptible noise perturbations. Such limitations can not be easily addressed by scaling up the dataset or the models. In this work, we propose to add adversarial synthetic nodules and adversarial attack samples to the training data to improve the generalization and the robustness of the lung nodule detection systems. In order to generate hard examples of nodules from a differentiable nodule synthesizer, we use projected gradient descent (PGD) to search the latent code within a bounded neighbourhood that would generate nodules to decrease the detector response. To make the network more robust to unanticipated noise perturbations, we use PGD to search for noise patterns that can trigger the network to give over-confident mistakes. By evaluating on two different benchmark datasets containing consensus annotations from three radiologists, we show that the proposed techniques can improve the detection performance on real CT data. To understand the limitations of both the conventional networks and the proposed augmented networks, we also perform stress-tests on the false positive reduction networks by feeding different types of artificially produced patches. We show that the augmented networks are more robust to both under-represented nodules as well as resistant to noise perturbations.
Explaining Classifiers with Causal Concept Effect (CaCE)
Jul 16, 2019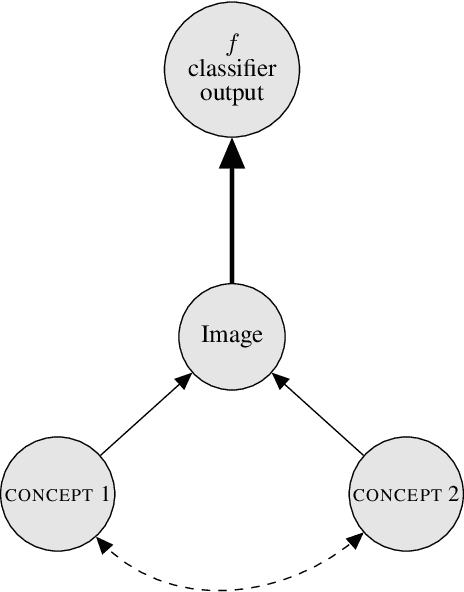
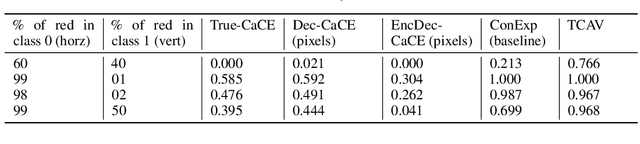


How can we understand classification decisions made by deep neural nets? We propose answering this question by using ideas from causal inference. We define the ``Causal Concept Effect'' (CaCE) as the causal effect that the presence or absence of a concept has on the prediction of a given deep neural net. We then use this measure as a mean to understand what drives the network's prediction and what does not. Yet many existing interpretability methods rely solely on correlations, resulting in potentially misleading explanations. We show how CaCE can avoid such mistakes. In high-risk domains such as medicine, knowing the root cause of the prediction is crucial. If we knew that the network's prediction was caused by arbitrary concepts such as the lighting conditions in an X-ray room instead of medically meaningful concept, this would prevent us from disastrous deployment of such models. Estimating CaCE is difficult in situations where we cannot easily simulate the do-operator. As a simple solution, we propose learning a generative model, specifically a Variational AutoEncoder (VAE) on image pixels or image embeddings extracted from the classifier to measure VAE-CaCE. We show that VAE-CaCE is able to correctly estimate the true causal effect as compared to other baselines in controlled settings with synthetic and semi-natural high dimensional images.
A deep learning based tool for automatic brain extraction from functional magnetic resonance images in rodents
Dec 03, 2019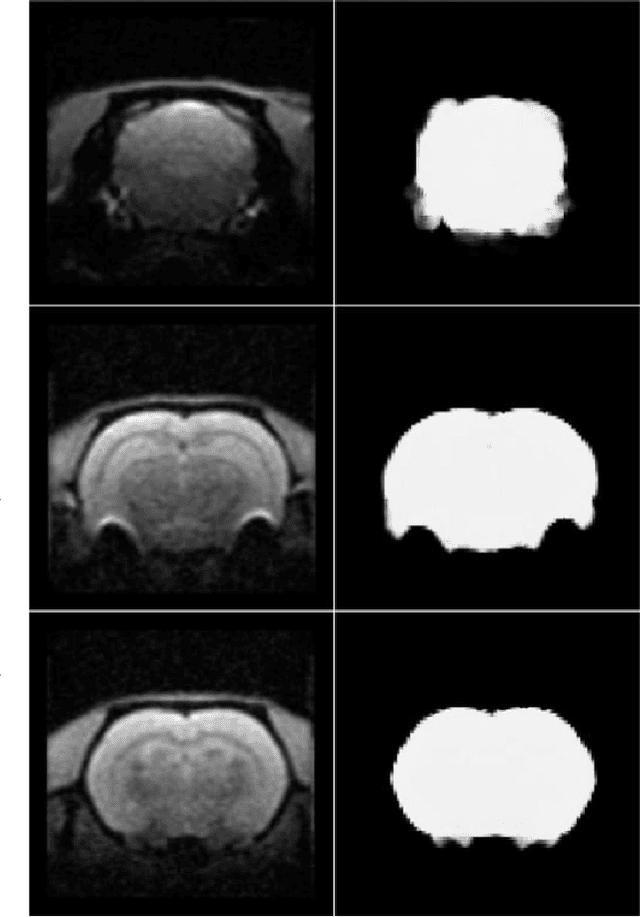
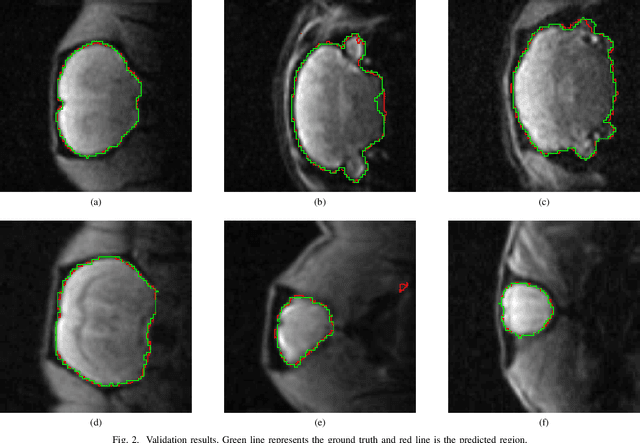
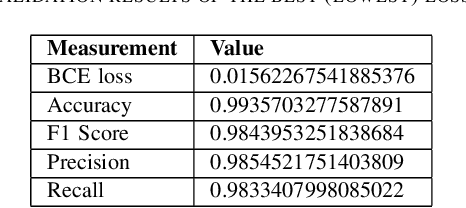
Removing skull artifacts from functional magnetic images (fMRI) is a well understood and frequently encountered problem. Because the fMRI field has grown mostly due to human studies, many new tools were developed to handle human data. Nonetheless, these tools are not equally useful to handle the data derived from animal studies, especially from rodents. This represents a major problem to the field because rodent studies generate larger datasets from larger populations, which implies that preprocessing these images manually to remove the skull becomes a bottleneck in the data analysis pipeline. In this study, we address this problem by implementing a neural network based method that uses a U-Net architecture to segment the brain area into a mask and removing the skull and other tissues from the image. We demonstrate several strategies to speed up the process of generating the training dataset using watershedding and several strategies for data augmentation that allowed to train faster the U-Net to perform the segmentation. Finally, we deployed the trained network freely available.
Towards Robust Learning-Based Pose Estimation of Noncooperative Spacecraft
Sep 01, 2019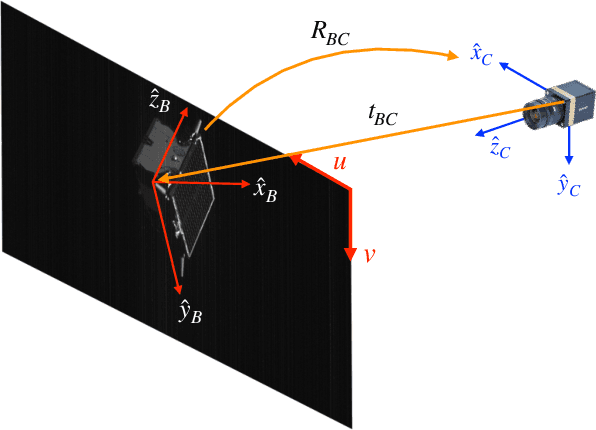

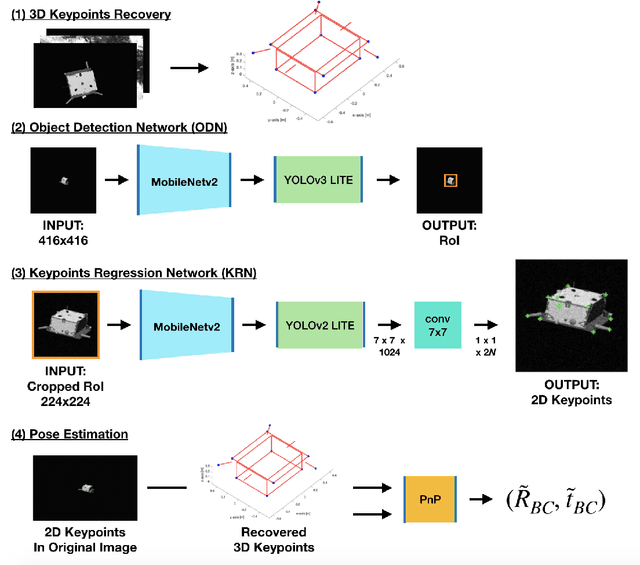

This work presents a novel Convolutional Neural Network (CNN) architecture and a training procedure to enable robust and accurate pose estimation of a noncooperative spacecraft. First, a new CNN architecture is introduced that has scored a fourth place in the recent Pose Estimation Challenge hosted by Stanford's Space Rendezvous Laboratory (SLAB) and the Advanced Concepts Team (ACT) of the European Space Agency (ESA). The proposed architecture first detects the object by regressing a 2D bounding box, then a separate network regresses the 2D locations of the known surface keypoints from an image of the target cropped around the detected Region-of-Interest (RoI). In a single-image pose estimation problem, the extracted 2D keypoints can be used in conjunction with corresponding 3D model coordinates to compute relative pose via the Perspective-n-Point (PnP) problem. These keypoint locations have known correspondences to those in the 3D model, since the CNN is trained to predict the corners in a pre-defined order, allowing for bypassing the computationally expensive feature matching processes. This work also introduces and explores the texture randomization to train a CNN for spaceborne applications. Specifically, Neural Style Transfer (NST) is applied to randomize the texture of the spacecraft in synthetically rendered images. It is shown that using the texture-randomized images of spacecraft for training improves the network's performance on spaceborne images without exposure to them during training. It is also shown that when using the texture-randomized spacecraft images during training, regressing 3D bounding box corners leads to better performance on spaceborne images than regressing surface keypoints, as NST inevitably distorts the spacecraft's geometric features to which the surface keypoints have closer relation.
Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders
Dec 05, 2018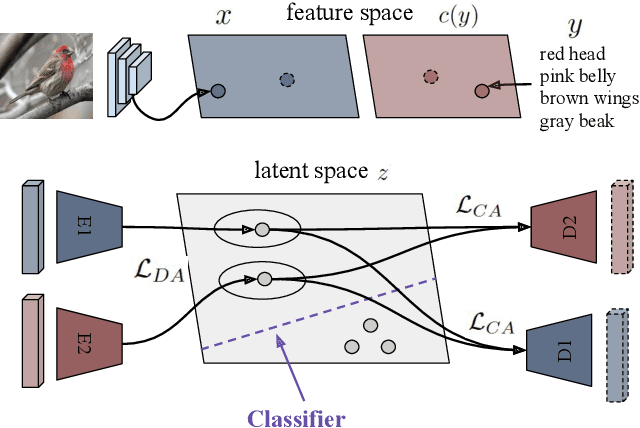

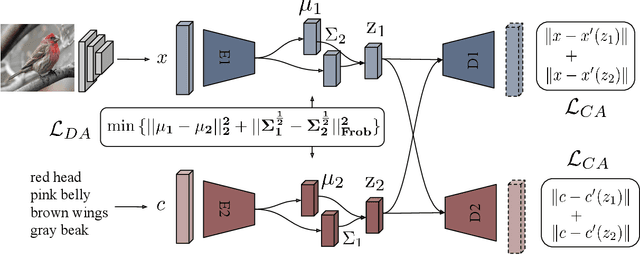
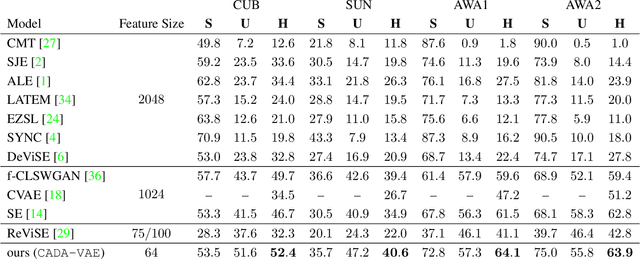
Many approaches in generalized zero-shot learning rely on cross-modal mapping between the image feature space and the class embedding space. As labeled images are rare, one direction is to augment the dataset by generating either images or image features. However, the former misses fine-grained details and the latter requires learning a mapping associated with class embeddings. In this work, we take feature generation one step further and propose a model where a shared latent space of image features and class embeddings is learned by modality-specific aligned variational autoencoders. This leaves us with the required discriminative information about the image and classes in the latent features, on which we train a softmax classifier. The key to our approach is that we align the distributions learned from images and from side-information to construct latent features that contain the essential multi-modal information associated with unseen classes. We evaluate our learned latent features on several benchmark datasets, i.e. CUB, SUN, AWA1 and AWA2, and establish a new state-of-the-art on generalized zero-shot as well as on few-shot learning. Moreover, our results on ImageNet with various zero-shot splits show that our latent features generalize well in large-scale settings.
Assessing four Neural Networks on Handwritten Digit Recognition Dataset (MNIST)
Nov 16, 2018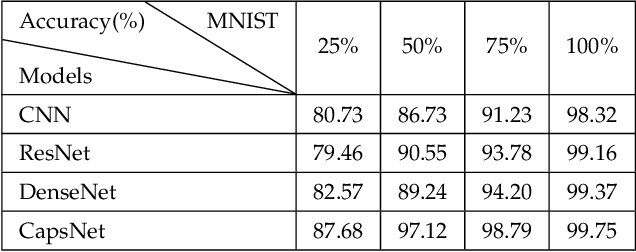
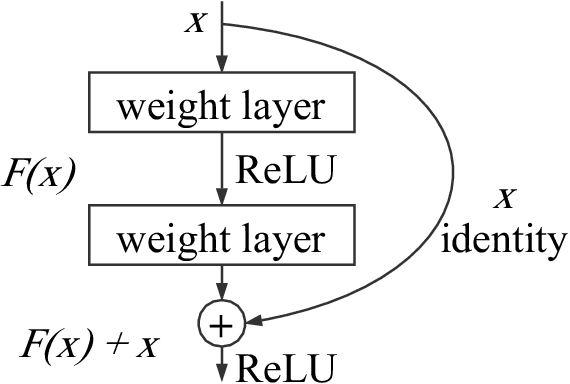
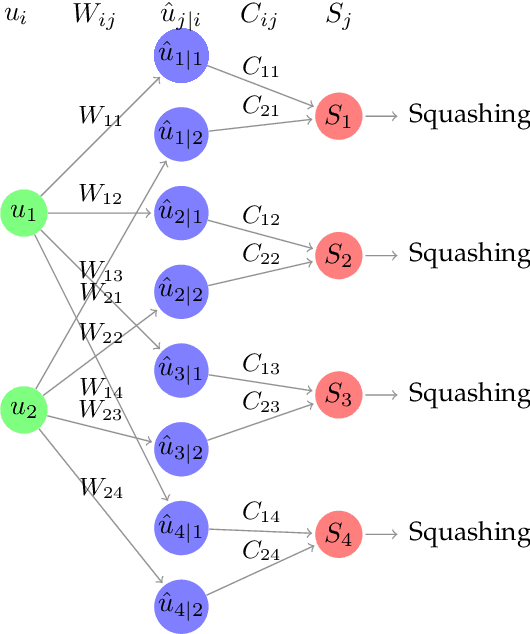
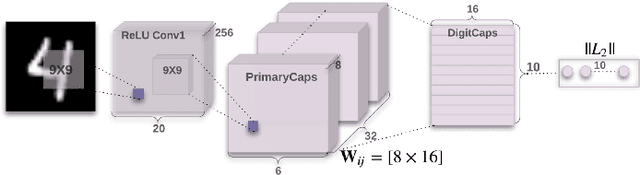
Although the image recognition has been a research topic for many years, many researchers still have a keen interest in it. In some papers, however, there is a tendency to compare models only on one or two datasets, either because of time restraints or because the model is tailored to a specific task. Accordingly, it is hard to understand how well a certain model generalizes across image recognition field. In this paper, we compare four neural networks on MNIST dataset with different division. Among of them, three are Convolutional Neural Networks (CNN), Deep Residual Network (ResNet) and Dense Convolutional Network (DenseNet) respectively, and the other is our improvement on CNN baseline through introducing Capsule Network (CapsNet) to image recognition area. We show that the previous models despite do a quite good job in this area, our retrofitting can be applied to get a better performance. The result obtained by CapsNet is an accuracy rate of 99.75\%, and it is the best result published so far. Another inspiring result is that CapsNet only needs a small amount of data to get the excellent performance. Finally, we will apply CapsNet's ability to generalize in other image recognition field in the future.