 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Training Generative Networks with general Optimal Transport distances
Oct 01, 2019

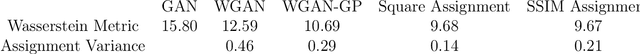
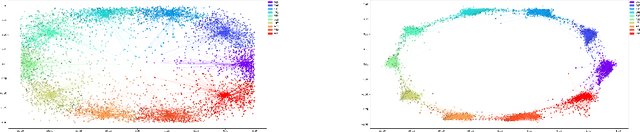
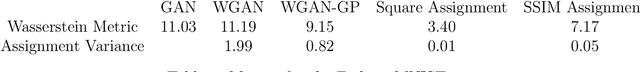
We propose a new algorithm that uses an auxiliary Neural Network to calculate the transport distance between two data distributions and export an optimal transport map. In the sequel we use the aforementioned map to train Generative Networks. Unlike WGANs, where the Euclidean distance is implicitly used, this new method allows to use any transportation cost function that can be chosen to match the problem at hand. More specifically, it allows to use the squared distance as a transportation cost function, giving rise to the Wasserstein-2 metric for probability distributions, which has rich geometric properties that result in fast and stable gradients descends. It also allows to use image centered distances, like the Structure Similarity index, with notable differences in the results.
Semi-supervised Anomaly Detection using AutoEncoders
Jan 06, 2020
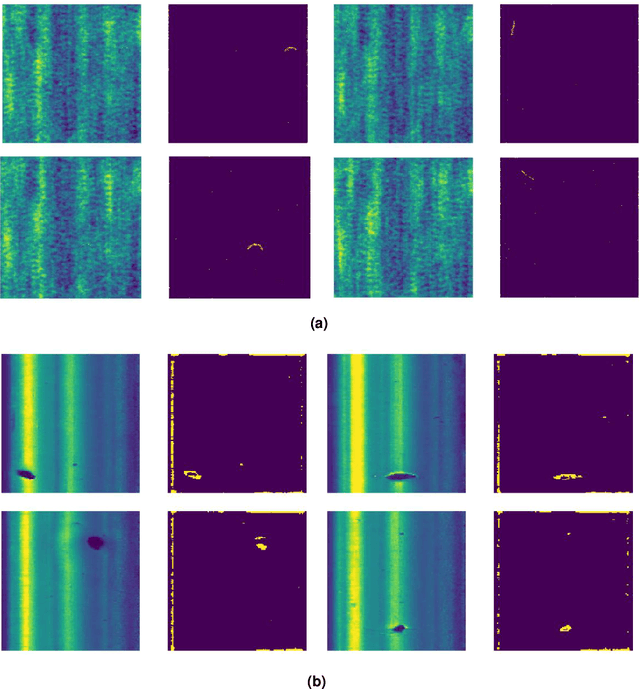
Anomaly detection refers to the task of finding unusual instances that stand out from the normal data. In several applications, these outliers or anomalous instances are of greater interest compared to the normal ones. Specifically in the case of industrial optical inspection and infrastructure asset management, finding these defects (anomalous regions) is of extreme importance. Traditionally and even today this process has been carried out manually. Humans rely on the saliency of the defects in comparison to the normal texture to detect the defects. However, manual inspection is slow, tedious, subjective and susceptible to human biases. Therefore, the automation of defect detection is desirable. But for defect detection lack of availability of a large number of anomalous instances and labelled data is a problem. In this paper, we present a convolutional auto-encoder architecture for anomaly detection that is trained only on the defect-free (normal) instances. For the test images, residual masks that are obtained by subtracting the original image from the auto-encoder output are thresholded to obtain the defect segmentation masks. The approach was tested on two data-sets and achieved an impressive average F1 score of 0.885. The network learnt to detect the actual shape of the defects even though no defected images were used during the training.
Recognizing Images with at most one Spike per Neuron
Jan 21, 2020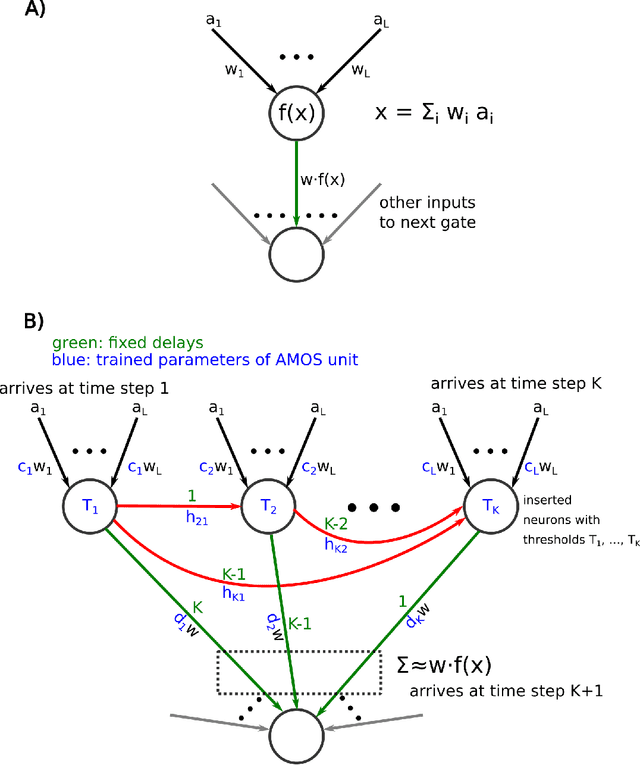

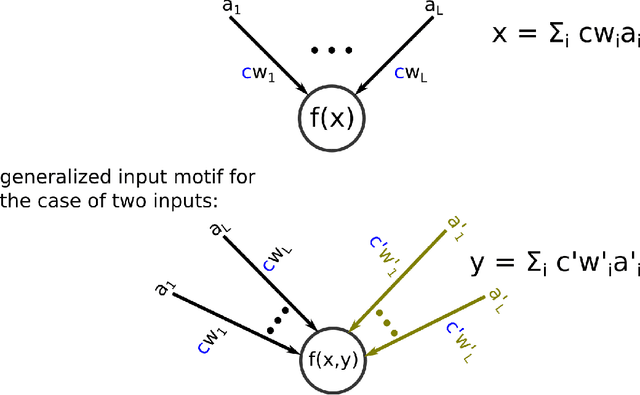

In order to port the performance of trained artificial neural networks (ANNs) to spiking neural networks (SNNs), which can be implemented in neuromorphic hardware with a drastically reduced energy consumption, an efficient ANN to SNN conversion is needed. Previous conversion schemes focused on the representation of the analog output of a rectified linear (ReLU) gate in the ANN by the firing rate of a spiking neuron. But this is not possible for other commonly used ANN gates, and it reduces the throughput even for ReLU gates. We introduce a new conversion method where a gate in the ANN, which can basically be of any type, is emulated by a small circuit of spiking neurons, with At Most One Spike (AMOS) per neuron. We show that this AMOS conversion improves the accuracy of SNNs for ImageNet from 74.60% to 80.97%, thereby bringing it within reach of the best available ANN accuracy (85.0%). The Top5 accuracy of SNNs is raised to 95.82%, getting even closer to the best Top5 performance of 97.2% for ANNs. In addition, AMOS conversion improves latency and throughput of spike-based image classification by several orders of magnitude. Hence these results suggest that SNNs provide a viable direction for developing highly energy efficient hardware for AI that combines high performance with versatility of applications.
Deep Learning-based Face Pose Recovery
Apr 30, 2019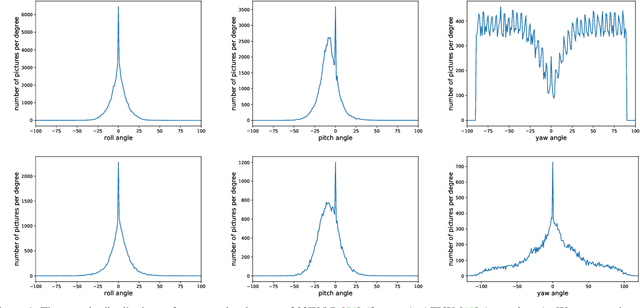
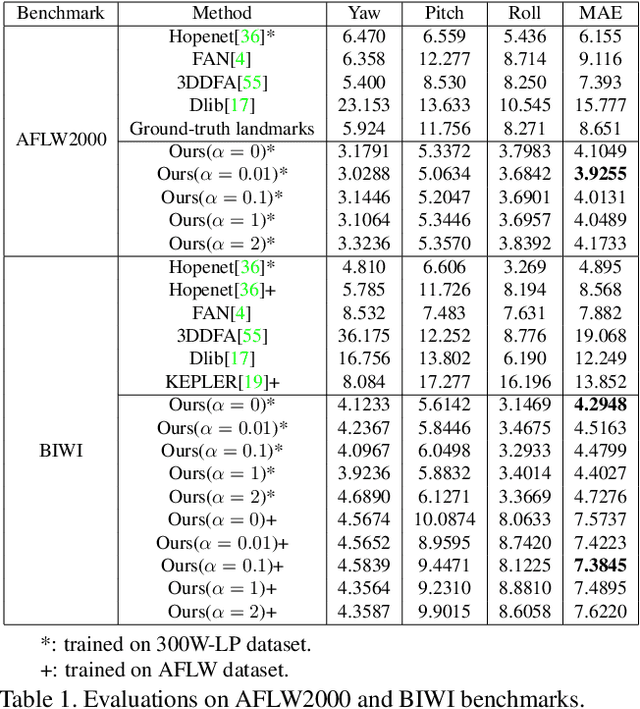
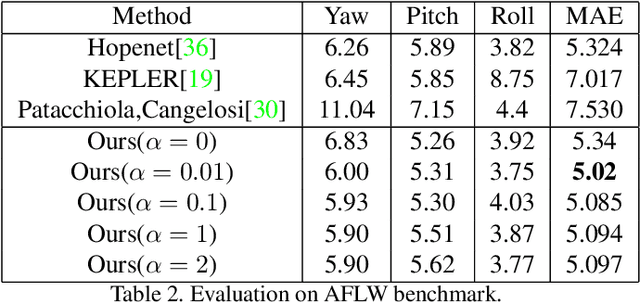
Facial pose estimation has gained a lot of attentions in many practical applications, such as human-robot interaction, gaze estimation and driver monitoring. Meanwhile, end-to-end deep learning-based facial pose estimation is becoming more and more popular. However, facial pose estimation suffers from a key challenge: the lack of sufficient training data for many poses, especially for large poses. Inspired by the observation that the faces under close poses look similar, we reformulate the facial pose estimation as a label distribution learning problem, considering each face image as an example associated with a Gaussian label distribution rather than a single label, and construct a convolutional neural network which is trained with a multi-loss function on AFLW dataset and 300WLP dataset to predict the facial poses directly from color image. Extensive experiments are conducted on several popular benchmarks, including AFLW2000, BIWI, AFLW and AFW, where our approach shows a significant advantage over other state-of-the-art methods.
Automatic Spatially-Adaptive Balancing of Energy Terms for Image Segmentation
Jun 23, 2009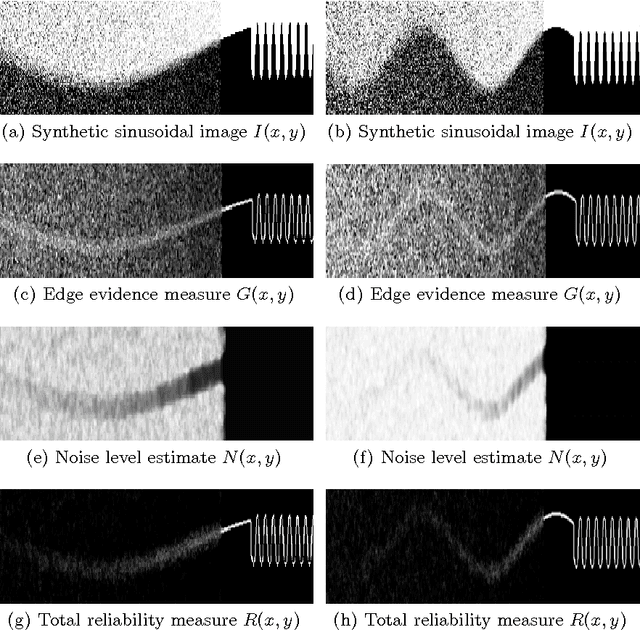
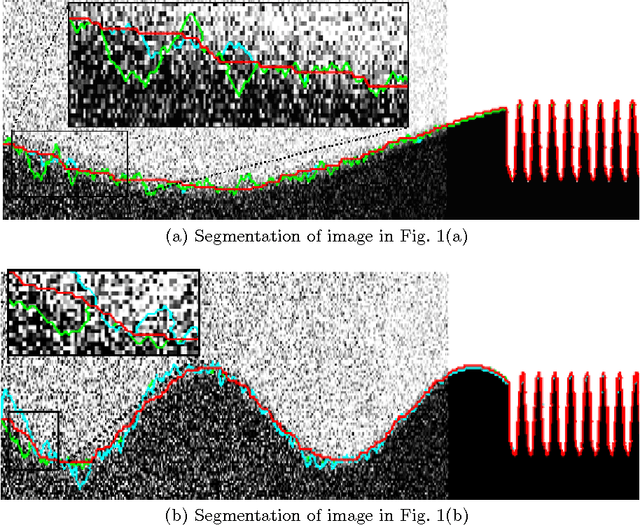
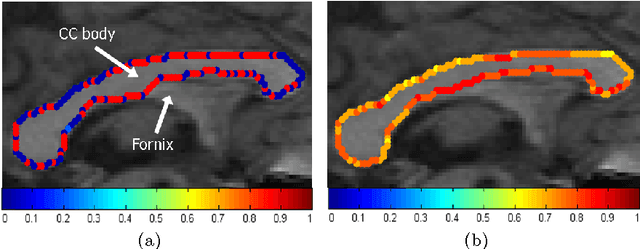
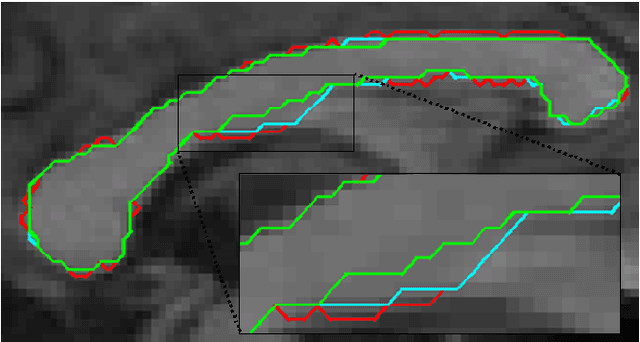
Image segmentation techniques are predominately based on parameter-laden optimization. The objective function typically involves weights for balancing competing image fidelity and segmentation regularization cost terms. Setting these weights suitably has been a painstaking, empirical process. Even if such ideal weights are found for a novel image, most current approaches fix the weight across the whole image domain, ignoring the spatially-varying properties of object shape and image appearance. We propose a novel technique that autonomously balances these terms in a spatially-adaptive manner through the incorporation of image reliability in a graph-based segmentation framework. We validate on synthetic data achieving a reduction in mean error of 47% (p-value << 0.05) when compared to the best fixed parameter segmentation. We also present results on medical images (including segmentations of the corpus callosum and brain tissue in MRI data) and on natural images.
Supporting DNN Safety Analysis and Retraining through Heatmap-based Unsupervised Learning
Feb 03, 2020
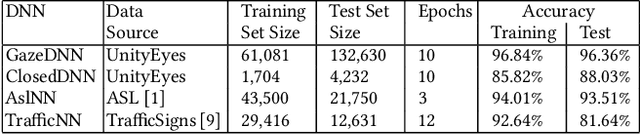
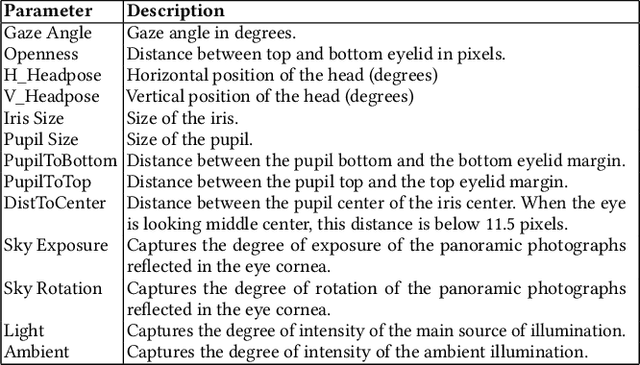
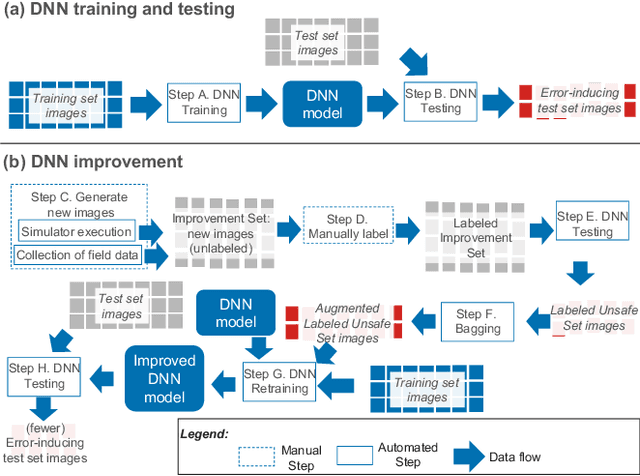
Deep neural networks (DNNs) are increasingly critical in modern safety-critical systems, for example in their perception layer to analyze images. Unfortunately, there is a lack of methods to ensure the functional safety of DNN-based components. The machine learning literature suggests one should trust DNNs demonstrating high accuracy on test sets. In case of low accuracy, DNNs should be retrained using additional inputs similar to the error-inducing ones. We observe two major challenges with existing practices for safety-critical systems: (1) scenarios that are underrepresented in the test set may represent serious risks, which may lead to safety violations, and may not be noticed; (2) debugging DNNs is poorly supported when error causes are difficult to visually detect. To address these problems, we propose HUDD, an approach that automatically supports the identification of root causes for DNN errors. We automatically group error-inducing images whose results are due to common subsets of selected DNN neurons. HUDD identifies root causes by applying a clustering algorithm to matrices (i.e., heatmaps) capturing the relevance of every DNN neuron on the DNN outcome. Also, HUDD retrains DNNs with images that are automatically selected based on their relatedness to the identified image clusters. We have evaluated HUDD with DNNs from the automotive domain. The approach was able to automatically identify all the distinct root causes of DNN errors, thus supporting safety analysis. Also, our retraining approach has shown to be more effective at improving DNN accuracy than existing approaches.
Cross-Modal Message Passing for Two-stream Fusion
Apr 30, 2019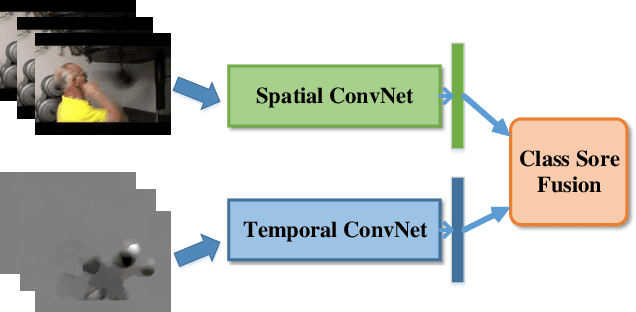
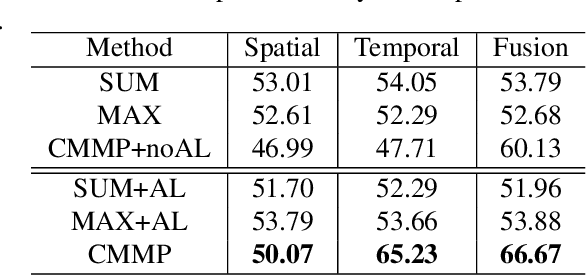
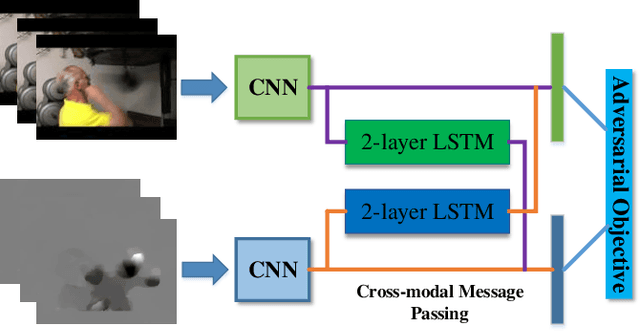
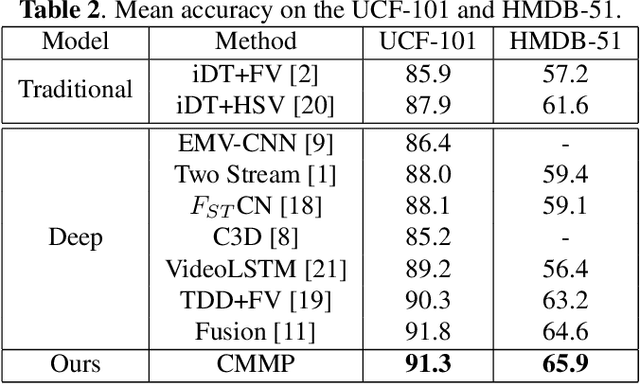
Processing and fusing information among multi-modal is a very useful technique for achieving high performance in many computer vision problems. In order to tackle multi-modal information more effectively, we introduce a novel framework for multi-modal fusion: Cross-modal Message Passing (CMMP). Specifically, we propose a cross-modal message passing mechanism to fuse two-stream network for action recognition, which composes of an appearance modal network (RGB image) and a motion modal (optical flow image) network. The objectives of individual networks in this framework are two-fold: a standard classification objective and a competing objective. The classification object ensures that each modal network predicts the true action category while the competing objective encourages each modal network to outperform the other one. We quantitatively show that the proposed CMMP fuses the traditional two-stream network more effectively, and outperforms all existing two-stream fusion method on UCF-101 and HMDB-51 datasets.
On the Subspace of Image Gradient Orientations
May 16, 2010

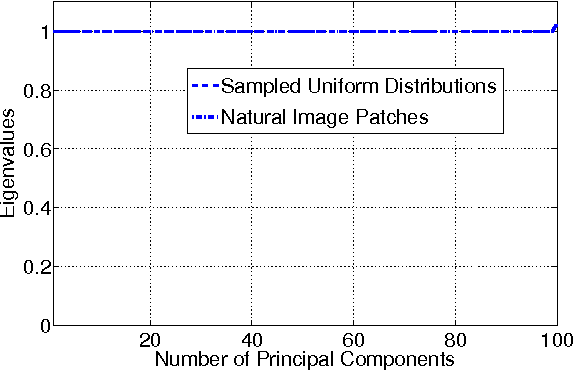
We introduce the notion of Principal Component Analysis (PCA) of image gradient orientations. As image data is typically noisy, but noise is substantially different from Gaussian, traditional PCA of pixel intensities very often fails to estimate reliably the low-dimensional subspace of a given data population. We show that replacing intensities with gradient orientations and the $\ell_2$ norm with a cosine-based distance measure offers, to some extend, a remedy to this problem. Our scheme requires the eigen-decomposition of a covariance matrix and is as computationally efficient as standard $\ell_2$ PCA. We demonstrate some of its favorable properties on robust subspace estimation.
Learning to Globally Edit Images with Textual Description
Oct 13, 2018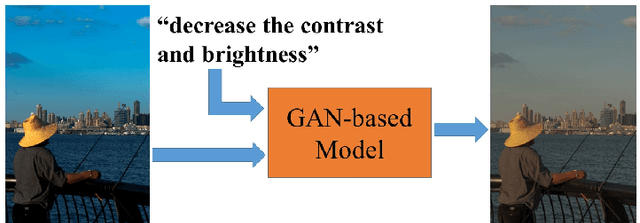


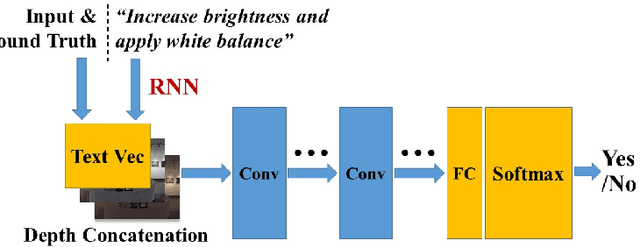
We show how we can globally edit images using textual instructions: given a source image and a textual instruction for the edit, generate a new image transformed under this instruction. To tackle this novel problem, we develop three different trainable models based on RNN and Generative Adversarial Network (GAN). The models (bucket, filter bank, and end-to-end) differ in how much expert knowledge is encoded, with the most general version being purely end-to-end. To train these systems, we use Amazon Mechanical Turk to collect textual descriptions for around 2000 image pairs sampled from several datasets. Experimental results evaluated on our dataset validate our approaches. In addition, given that the filter bank model is a good compromise between generality and performance, we investigate it further by replacing RNN with Graph RNN, and show that Graph RNN improves performance. To the best of our knowledge, this is the first computational photography work on global image editing that is purely based on free-form textual instructions.
Facial Recognition with Encoded Local Projections
Sep 11, 2018
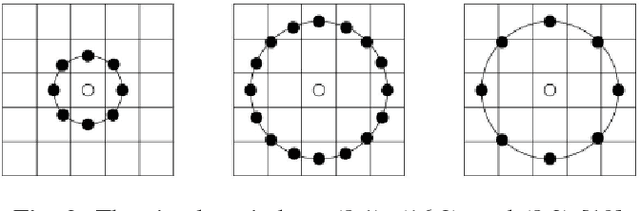

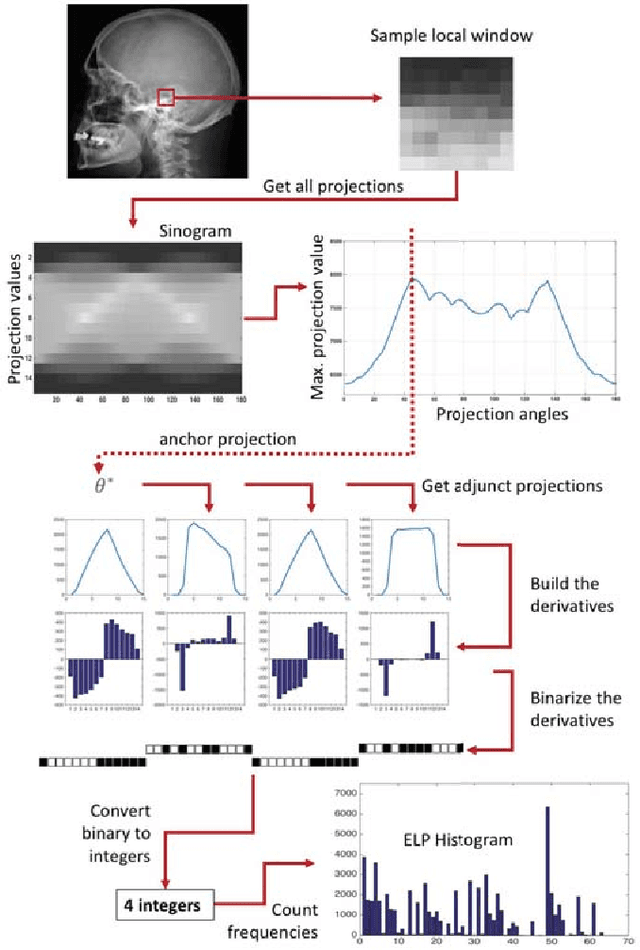
Encoded Local Projections (ELP) is a recently introduced dense sampling image descriptor which uses projections in small neighbourhoods to construct a histogram/descriptor for the entire image. ELP has shown to be as accurate as other state-of-the-art features in searching medical images while being time and resource efficient. This paper attempts for the first time to utilize ELP descriptor as primary features for facial recognition and compare the results with LBP histogram on the Labeled Faces in the Wild dataset. We have evaluated descriptors by comparing the chi-squared distance of each image descriptor versus all others as well as training Support Vector Machines (SVM) with each feature vector. In both cases, the results of ELP were better than LBP in the same sub-image configuration.