 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Static and Dynamic Fusion for Multi-modal Cross-ethnicity Face Anti-spoofing
Dec 05, 2019

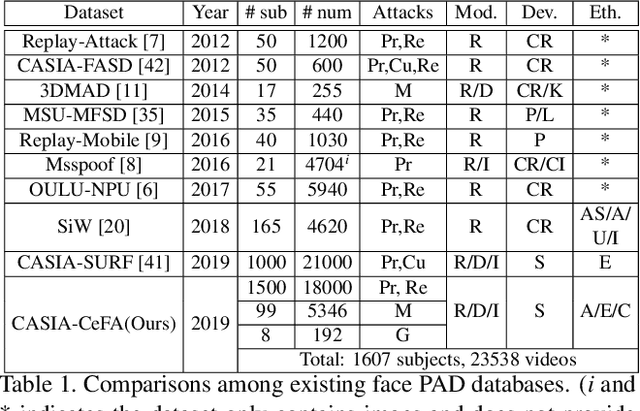
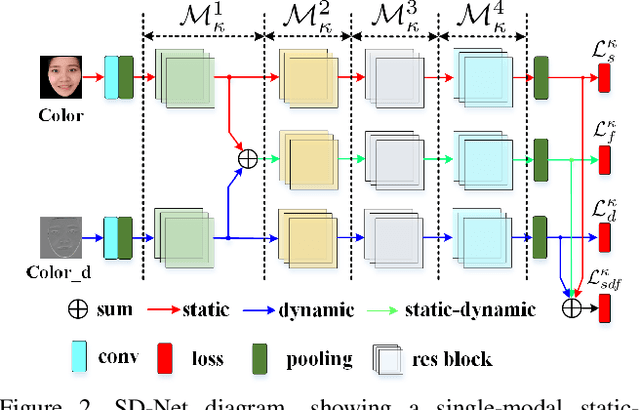
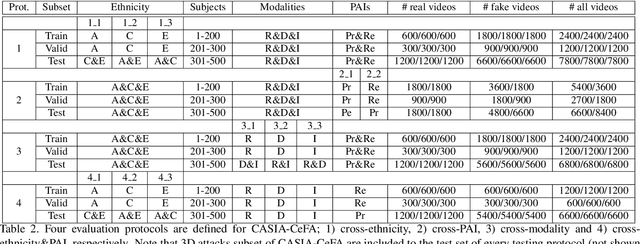
Regardless of the usage of deep learning and handcrafted methods, the dynamic information from videos and the effect of cross-ethnicity are rarely considered in face anti-spoofing. In this work, we propose a static-dynamic fusion mechanism for multi-modal face anti-spoofing. Inspired by motion divergences between real and fake faces, we incorporate the dynamic image calculated by rank pooling with static information into a conventional neural network (CNN) for each modality (i.e., RGB, Depth and infrared (IR)). Then, we develop a partially shared fusion method to learn complementary information from multiple modalities. Furthermore, in order to study the generalization capability of the proposal in terms of cross-ethnicity attacks and unknown spoofs, we introduce the largest public cross-ethnicity Face Anti-spoofing (CASIA-CeFA) dataset, covering 3 ethnicities, 3 modalities, 1607 subjects, and 2D plus 3D attack types. Experiments demonstrate that the proposed method achieves state-of-the-art results on CASIA-CeFA, CASIA-SURF, OULU-NPU and SiW.
HRank: Filter Pruning using High-Rank Feature Map
Mar 16, 2020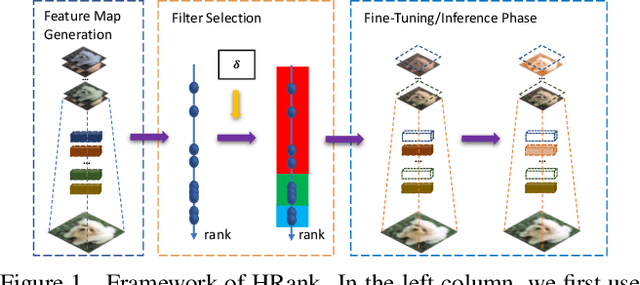
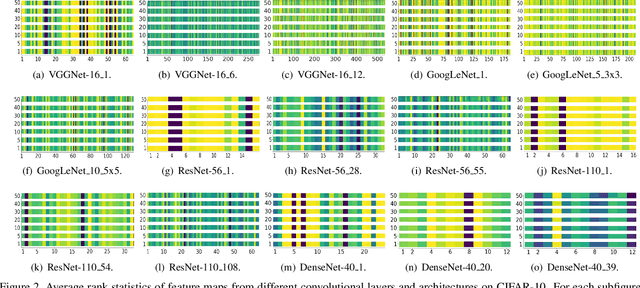
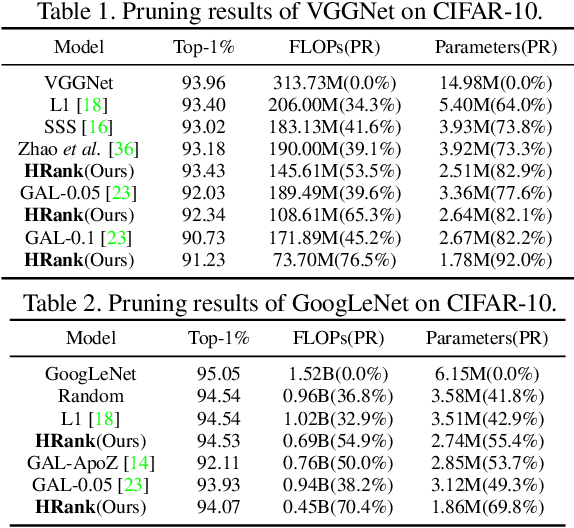
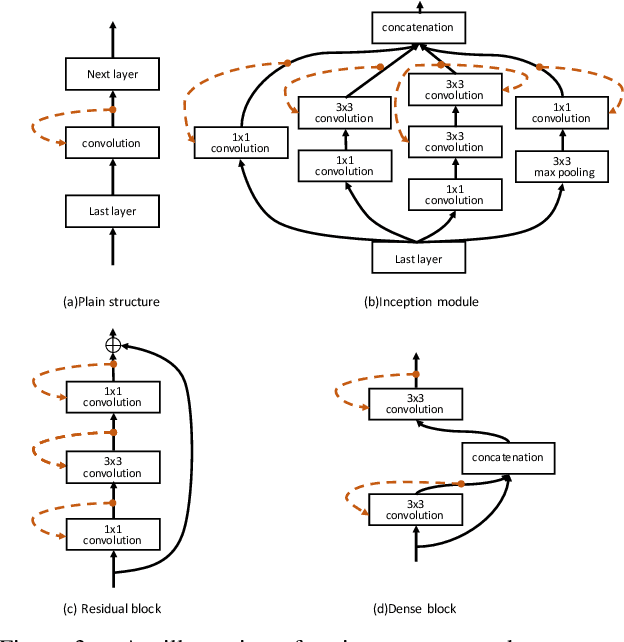
Neural network pruning offers a promising prospect to facilitate deploying deep neural networks on resource-limited devices. However, existing methods are still challenged by the training inefficiency and labor cost in pruning designs, due to missing theoretical guidance of non-salient network components. In this paper, we propose a novel filter pruning method by exploring the High Rank of feature maps (HRank). Our HRank is inspired by the discovery that the average rank of multiple feature maps generated by a single filter is always the same, regardless of the number of image batches CNNs receive. Based on HRank, we develop a method that is mathematically formulated to prune filters with low-rank feature maps. The principle behind our pruning is that low-rank feature maps contain less information, and thus pruned results can be easily reproduced. Besides, we experimentally show that weights with high-rank feature maps contain more important information, such that even when a portion is not updated, very little damage would be done to the model performance. Without introducing any additional constraints, HRank leads to significant improvements over the state-of-the-arts in terms of FLOPs and parameters reduction, with similar accuracies. For example, with ResNet-110, we achieve a 58.2%-FLOPs reduction by removing 59.2% of the parameters, with only a small loss of 0.14% in top-1 accuracy on CIFAR-10. With Res-50, we achieve a 43.8%-FLOPs reduction by removing 36.7% of the parameters, with only a loss of 1.17% in the top-1 accuracy on ImageNet. The codes can be available at https://github.com/lmbxmu/HRank.
From Google Maps to a Fine-Grained Catalog of Street trees
Oct 07, 2019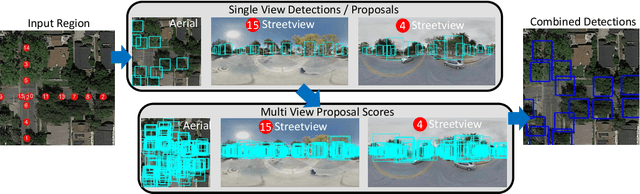
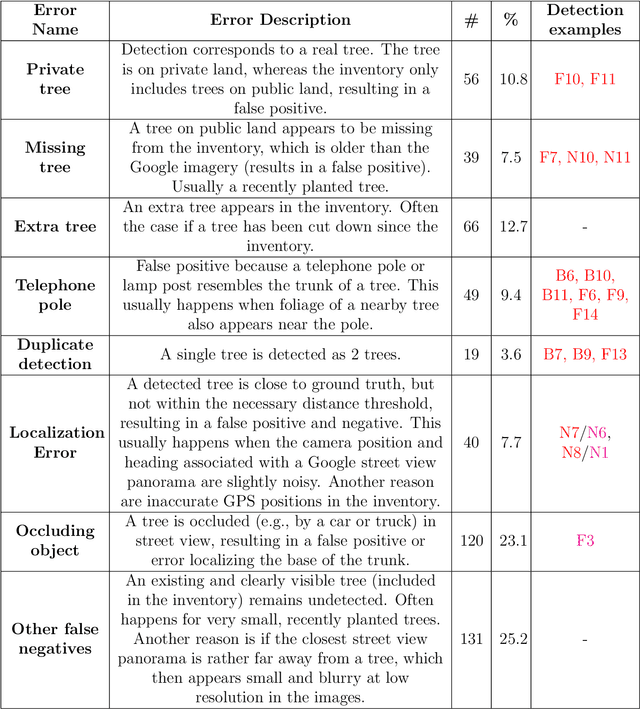

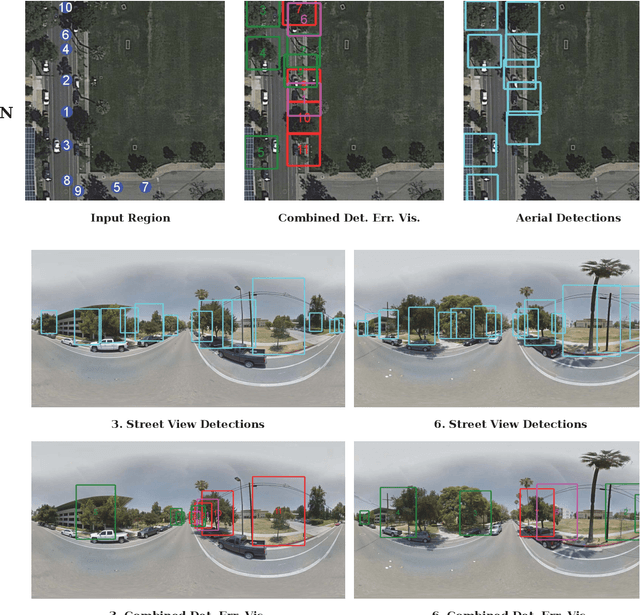
Up-to-date catalogs of the urban tree population are important for municipalities to monitor and improve quality of life in cities. Despite much research on automation of tree mapping, mainly relying on dedicated airborne LiDAR or hyperspectral campaigns, trees are still mostly mapped manually in practice. We present a fully automated tree detection and species recognition pipeline to process thousands of trees within a few hours using publicly available aerial and street view images of Google MapsTM. These data provide rich information (viewpoints, scales) from global tree shapes to bark textures. Our work-flow is built around a supervised classification that automatically learns the most discriminative features from thousands of trees and corresponding, public tree inventory data. In addition, we introduce a change tracker to keep urban tree inventories up-to-date. Changes of individual trees are recognized at city-scale by comparing street-level images of the same tree location at two different times. Drawing on recent advances in computer vision and machine learning, we apply convolutional neural networks (CNN) for all classification tasks. We propose the following pipeline: download all available panoramas and overhead images of an area of interest, detect trees per image and combine multi-view detections in a probabilistic framework, adding prior knowledge; recognize fine-grained species of detected trees. In a later, separate module, track trees over time and identify the type of change. We believe this is the first work to exploit publicly available image data for fine-grained tree mapping at city-scale, respectively over many thousands of trees. Experiments in the city of Pasadena, California, USA show that we can detect > 70% of the street trees, assign correct species to > 80% for 40 different species, and correctly detect and classify changes in > 90% of the cases.
Pixel Adaptive Filtering Units
Nov 24, 2019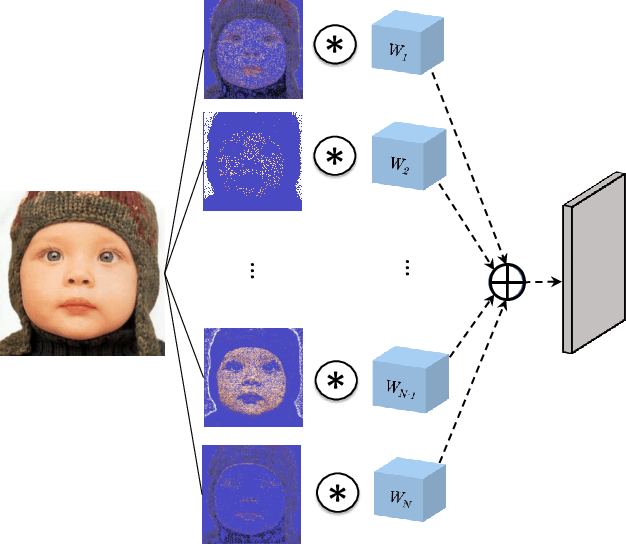
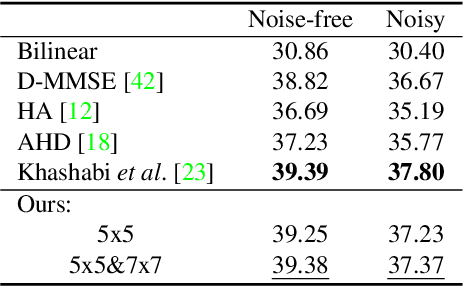
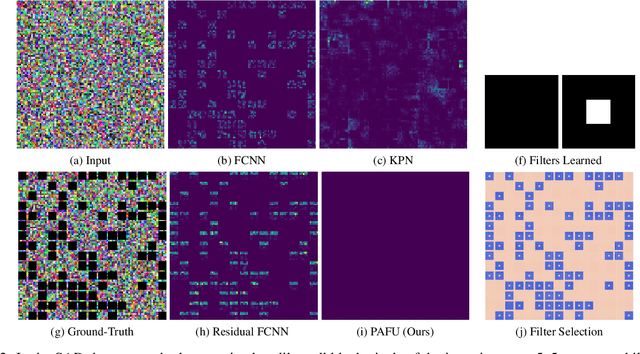
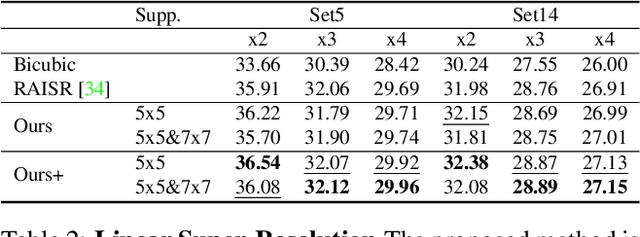
State-of-the-art methods for computer vision rely heavily on the translation equivariance and spatial sharing properties of convolutional layers without explicitly taking into consideration the input content. Modern techniques employ deep sophisticated architectures in order to circumvent this issue. In this work, we propose a Pixel Adaptive Filtering Unit (PAFU) which introduces a differentiable kernel selection mechanism paired with a discrete, learnable and decorrelated group of kernels to allow for content-based spatial adaptation. First, we demonstrate the applicability of the technique in applications where runtime is of importance. Next, we employ PAFU in deep neural networks as a replacement of standard convolutional layers to enhance the original architectures with spatially varying computations to achieve considerable performance improvements. Finally, diverse and extensive experimentation provides strong empirical evidence in favor of the proposed content-adaptive processing scheme across different image processing and high-level computer vision tasks.
A Comparison of Stereo-Matching Cost between Convolutional Neural Network and Census for Satellite Images
May 22, 2019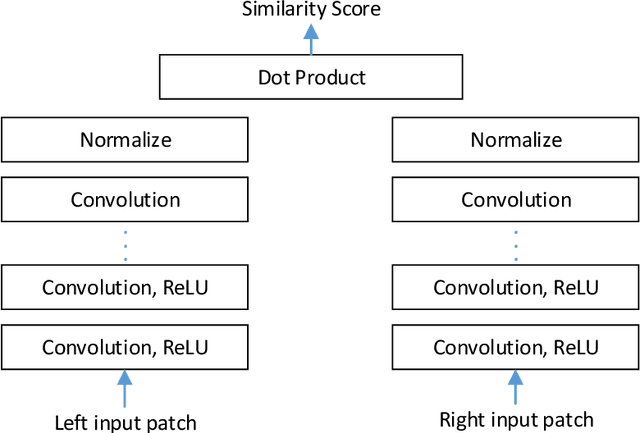
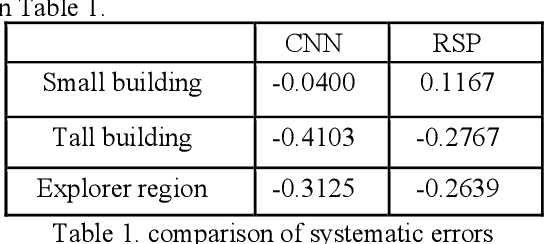
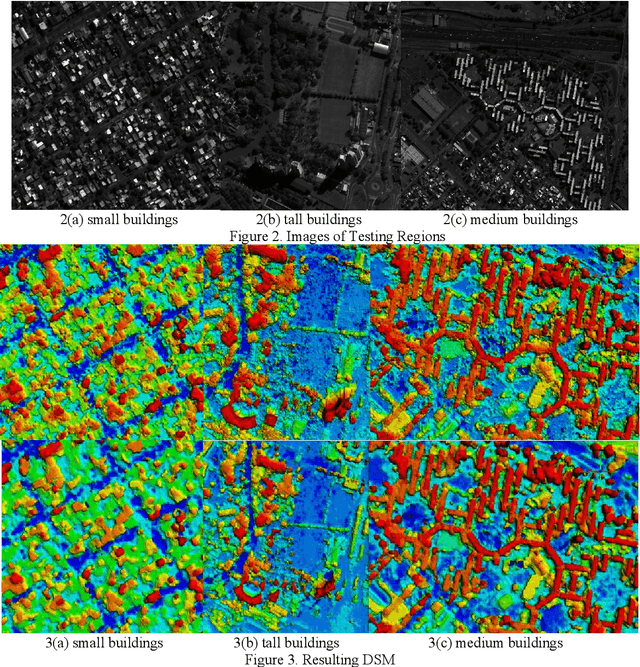
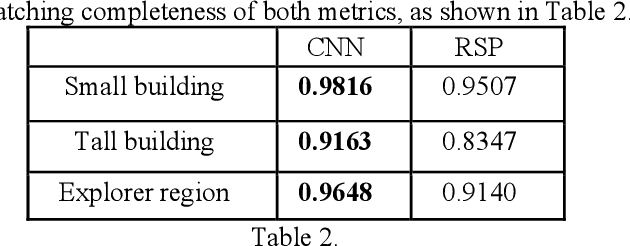
Stereo dense image matching can be categorized to low-level feature based matching and deep feature based matching according to their matching cost metrics. Census has been proofed to be one of the most efficient low-level feature based matching methods, while fast Convolutional Neural Network (fst-CNN), as a deep feature based method, has small computing time and is robust for satellite images. Thus, a comparison between fst-CNN and census is critical for further studies in stereo dense image matching. This paper used cost function of fst-CNN and census to do stereo matching, then utilized semi-global matching method to obtain optimized disparity images. Those images are used to produce digital surface model to compare with ground truth points. It addresses that fstCNN performs better than census in the aspect of absolute matching accuracy, histogram of error distribution and matching completeness, but these two algorithms still performs in the same order of magnitude.
How to Pre-Train Your Model? Comparison of Different Pre-Training Models for Biomedical Question Answering
Nov 02, 2019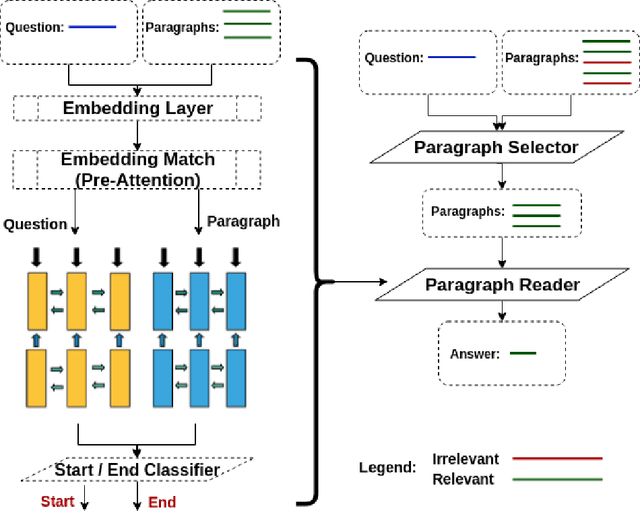
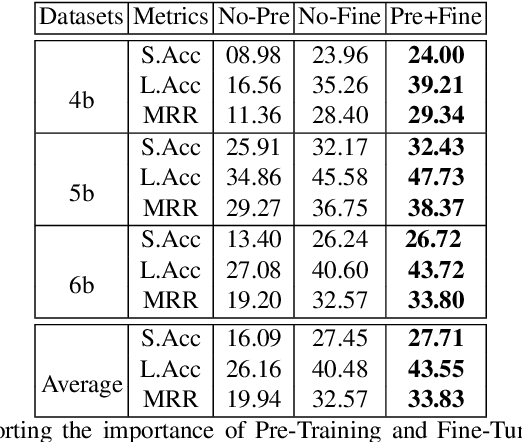
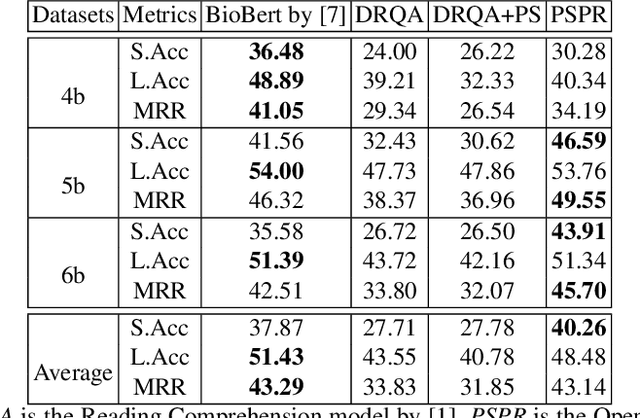
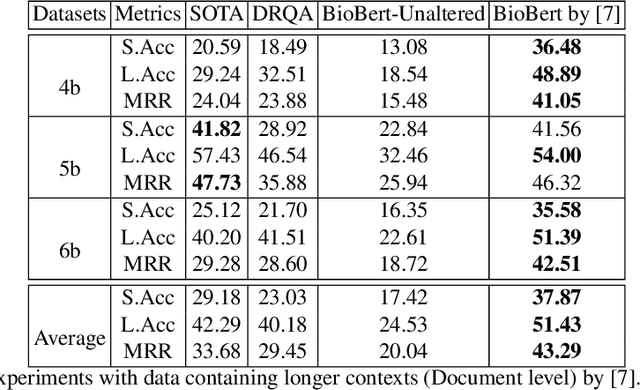
Using deep learning models on small scale datasets would result in overfitting. To overcome this problem, the process of pre-training a model and fine-tuning it to the small scale dataset has been used extensively in domains such as image processing. Similarly for question answering, pre-training and fine-tuning can be done in several ways. Commonly reading comprehension models are used for pre-training, but we show that other types of pre-training can work better. We compare two pre-training models based on reading comprehension and open domain question answering models and determine the performance when fine-tuned and tested over BIOASQ question answering dataset. We find open domain question answering model to be a better fit for this task rather than reading comprehension model.
S3: A Spectral-Spatial Structure Loss for Pan-Sharpening Networks
Jun 13, 2019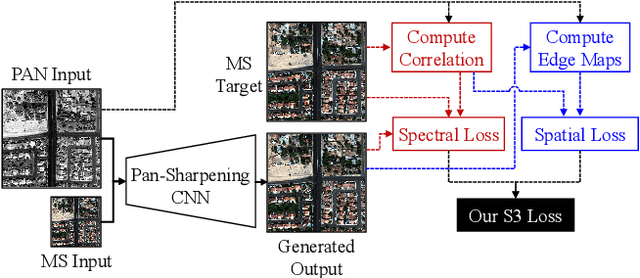



Recently, many deep-learning-based pan-sharpening methods have been proposed for generating high-quality pan-sharpened (PS) satellite images. These methods focused on various types of convolutional neural network (CNN) structures, which were trained by simply minimizing L1 or L2 losses between network outputs and the corresponding high-resolution multi-spectral (MS) target images. However, due to different sensor characteristics and acquisition times, high-resolution panchromatic (PAN) and low-resolution MS image pairs tend to have large pixel misalignments, especially for moving objects in the images. Conventional CNNs trained with L1 or L2 losses with these satellite image datasets often produce PS images of low visual quality including double-edge artifacts along strong edges and ghosting artifacts on moving objects. In this letter, we propose a novel loss function, called a spectral-spatial structure (S3) loss, based on the correlation maps between MS targets and PAN inputs. Our proposed S3 loss can be very effectively utilized for pan-sharpening with various types of CNN structures, resulting in significant visual improvements on PS images with suppressed artifacts.
The Elephant in the Room
Aug 09, 2018


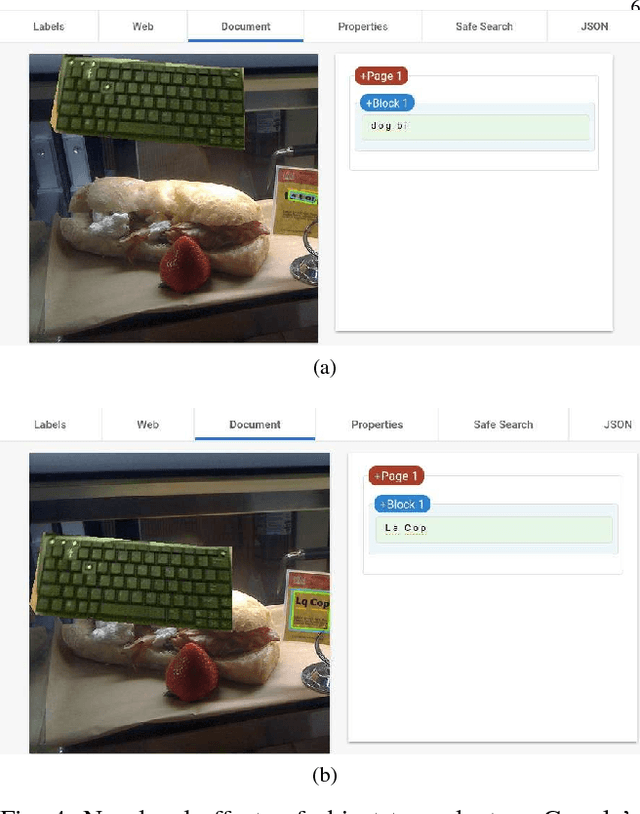
We showcase a family of common failures of state-of-the art object detectors. These are obtained by replacing image sub-regions by another sub-image that contains a trained object. We call this "object transplanting". Modifying an image in this manner is shown to have a non-local impact on object detection. Slight changes in object position can affect its identity according to an object detector as well as that of other objects in the image. We provide some analysis and suggest possible reasons for the reported phenomena.
Deep Attentive Features for Prostate Segmentation in 3D Transrectal Ultrasound
Jul 03, 2019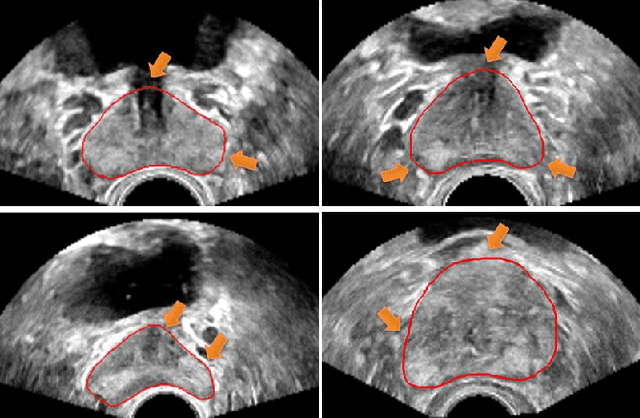

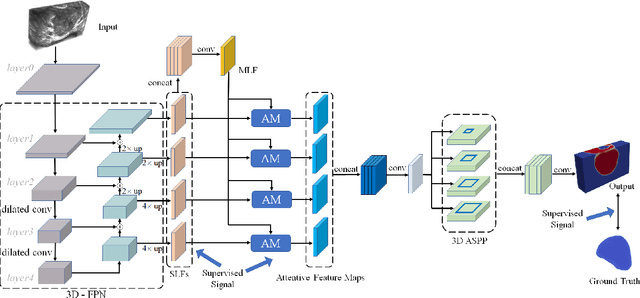
Automatic prostate segmentation in transrectal ultrasound (TRUS) images is of essential importance for image-guided prostate interventions and treatment planning. However, developing such automatic solutions remains very challenging due to the missing/ambiguous boundary and inhomogeneous intensity distribution of the prostate in TRUS, as well as the large variability in prostate shapes. This paper develops a novel 3D deep neural network equipped with attention modules for better prostate segmentation in TRUS by fully exploiting the complementary information encoded in different layers of the convolutional neural network (CNN). Our attention module utilizes the attention mechanism to selectively leverage the multilevel features integrated from different layers to refine the features at each individual layer, suppressing the non-prostate noise at shallow layers of the CNN and increasing more prostate details into features at deep layers. Experimental results on challenging 3D TRUS volumes show that our method attains satisfactory segmentation performance. The proposed attention mechanism is a general strategy to aggregate multi-level deep features and has the potential to be used for other medical image segmentation tasks. The code is publicly available at https://github.com/wulalago/DAF3D.
Planning Beyond the Sensing Horizon Using a Learned Context
Aug 24, 2019

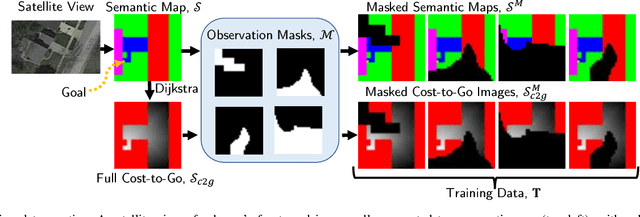
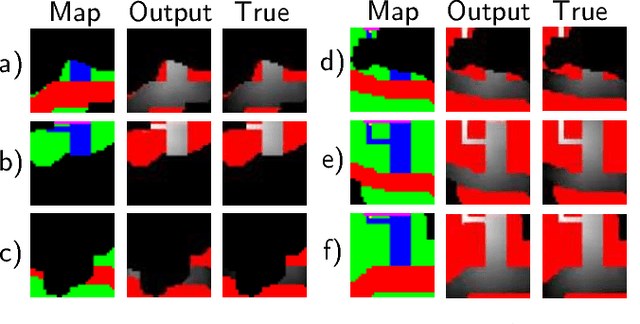
Last-mile delivery systems commonly propose the use of autonomous robotic vehicles to increase scalability and efficiency. The economic inefficiency of collecting accurate prior maps for navigation motivates the use of planning algorithms that operate in unmapped environments. However, these algorithms typically waste time exploring regions that are unlikely to contain the delivery destination. Context is key information about structured environments that could guide exploration toward the unknown goal location, but the abstract idea is difficult to quantify for use in a planning algorithm. Some approaches specifically consider contextual relationships between objects, but would perform poorly in object-sparse environments like outdoors. Recent deep learning-based approaches consider context too generally, making training/transferability difficult. Therefore, this work proposes a novel formulation of utilizing context for planning as an image-to-image translation problem, which is shown to extract terrain context from semantic gridmaps, into a metric that an exploration-based planner can use. The proposed framework has the benefit of training on a static dataset instead of requiring a time-consuming simulator. Across 42 test houses with layouts from satellite images, the trained algorithm enables a robot to reach its goal 189\% faster than with a context-unaware planner, and within 63\% of the optimal path computed with a prior map. The proposed algorithm is also implemented on a vehicle with a forward-facing camera in a high-fidelity, Unreal simulation of neighborhood houses.