 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
U-net super-neural segmentation and similarity calculation to realize vegetation change assessment in satellite imagery
Sep 10, 2019

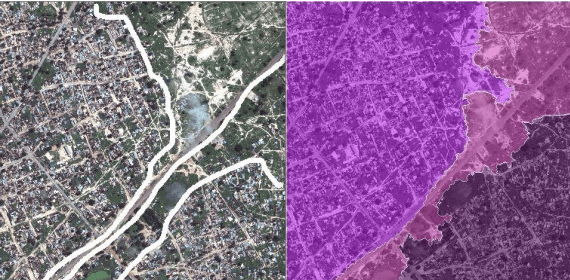
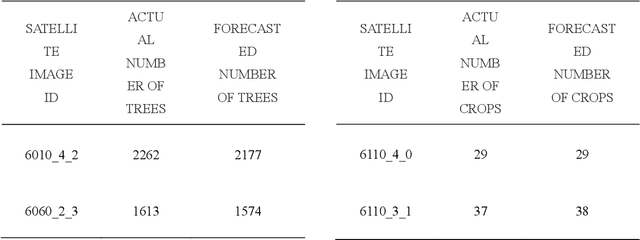
Vegetation is the natural linkage connecting soil, atmosphere and water. It can represent the change of land cover to a certain extent and serve as an indicator for global change research. Methods for measuring coverage can be divided into two types: surface measurement and remote sensing. Because vegetation cover has significant spatial and temporal differentiation characteristics, remote sensing has become an important technical means to estimate vegetation coverage. This paper firstly uses U-net to perform remote sensing image semantic segmentation training, then uses the result of semantic segmentation, and then uses the integral progressive method to calculate the forestland change rate, and finally realizes automated valuation of woodland change rate.
Learning eating environments through scene clustering
Nov 10, 2019
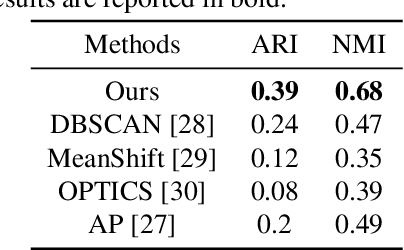
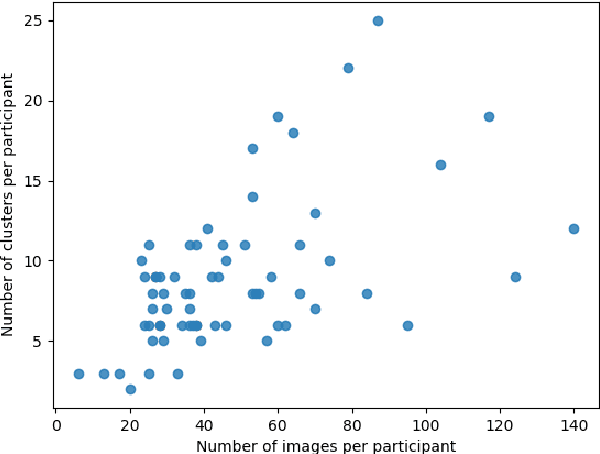
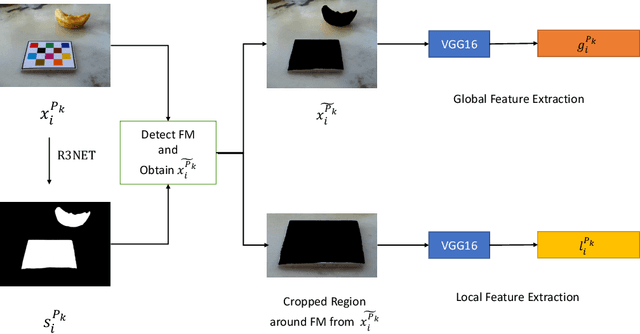
It is well known that dietary habits have a significant influence on health. While many studies have been conducted to understand this relationship, little is known about the relationship between eating environments and health. Yet researchers and health agencies around the world have recognized the eating environment as a promising context for improving diet and health. In this paper, we propose an image clustering method to automatically extract the eating environments from eating occasion images captured during a community dwelling dietary study. Specifically, we are interested in learning how many different environments an individual consumes food in. Our method clusters images by extracting features at both global and local scales using a deep neural network. The variation in the number of clusters and images captured by different individual makes this a very challenging problem. Experimental results show that our method performs significantly better compared to several existing clustering approaches.
Stroke Constrained Attention Network for Online Handwritten Mathematical Expression Recognition
Feb 20, 2020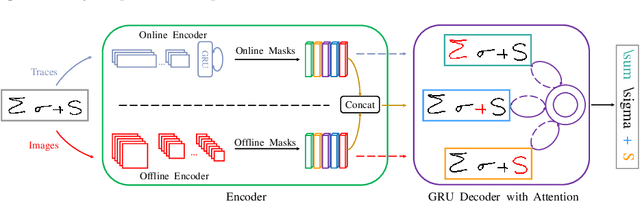
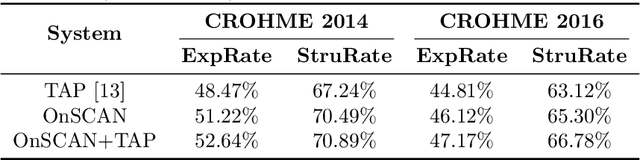
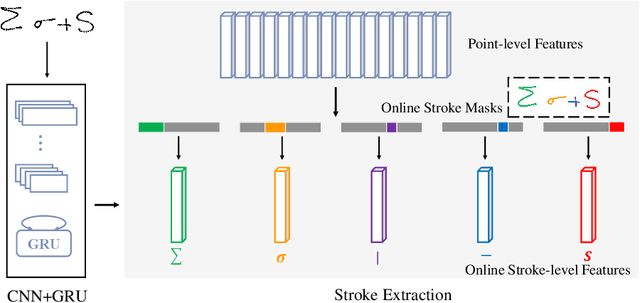
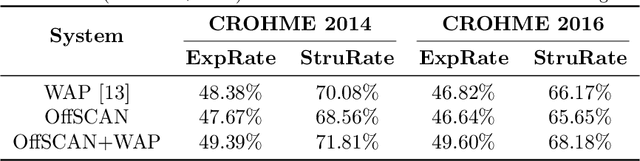
In this paper, we propose a novel stroke constrained attention network (SCAN) which treats stroke as the basic unit for encoder-decoder based online handwritten mathematical expression recognition (HMER). Unlike previous methods which use trace points or image pixels as basic units, SCAN makes full use of stroke-level information for better alignment and representation. The proposed SCAN can be adopted in both single-modal (online or offline) and multi-modal HMER. For single-modal HMER, SCAN first employs a CNN-GRU encoder to extract point-level features from input traces in online mode and employs a CNN encoder to extract pixel-level features from input images in offline mode, then use stroke constrained information to convert them into online and offline stroke-level features. Using stroke-level features can explicitly group points or pixels belonging to the same stroke, therefore reduces the difficulty of symbol segmentation and recognition via the decoder with attention mechanism. For multi-modal HMER, other than fusing multi-modal information in decoder, SCAN can also fuse multi-modal information in encoder by utilizing the stroke based alignments between online and offline modalities. The encoder fusion is a better way for combining multi-modal information as it implements the information interaction one step before the decoder fusion so that the advantages of multiple modalities can be exploited earlier and more adequately when training the encoder-decoder model. Evaluated on a benchmark published by CROHME competition, the proposed SCAN achieves the state-of-the-art performance.
Efficient Video Semantic Segmentation with Labels Propagation and Refinement
Dec 26, 2019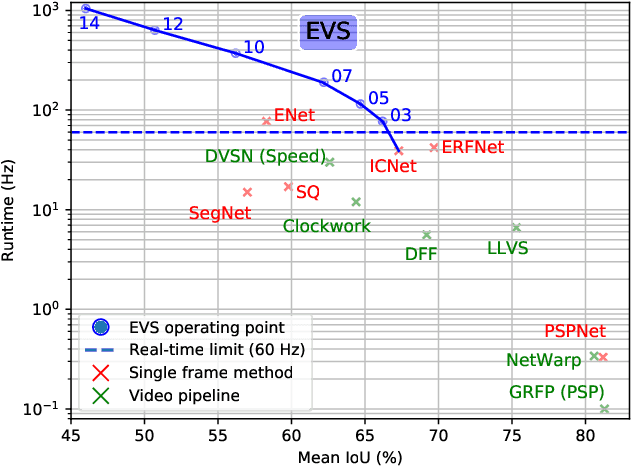

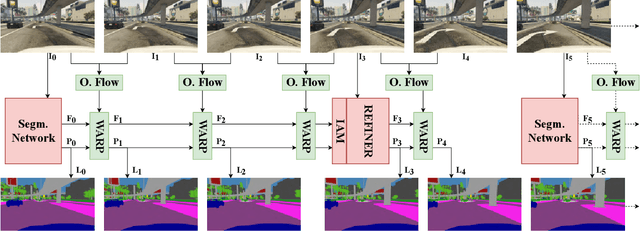
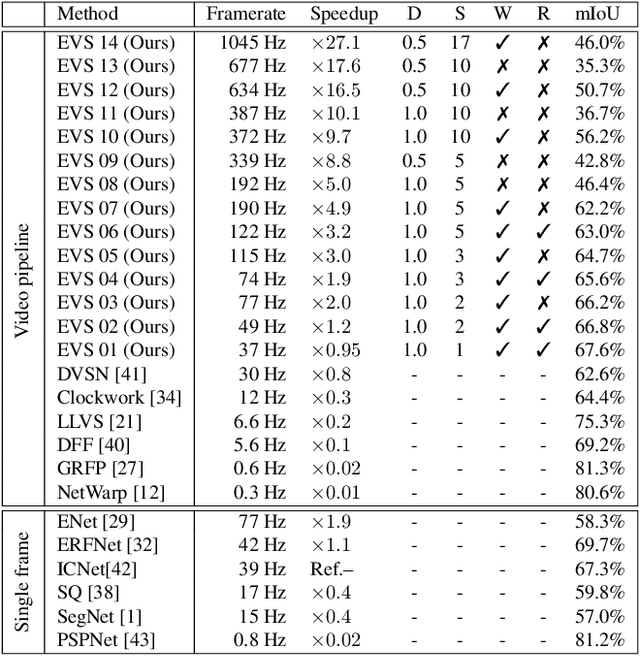
This paper tackles the problem of real-time semantic segmentation of high definition videos using a hybrid GPU / CPU approach. We propose an Efficient Video Segmentation(EVS) pipeline that combines: (i) On the CPU, a very fast optical flow method, that is used to exploit the temporal aspect of the video and propagate semantic information from one frame to the next. It runs in parallel with the GPU. (ii) On the GPU, two Convolutional Neural Networks: A main segmentation network that is used to predict dense semantic labels from scratch, and a Refiner that is designed to improve predictions from previous frames with the help of a fast Inconsistencies Attention Module (IAM). The latter can identify regions that cannot be propagated accurately. We suggest several operating points depending on the desired frame rate and accuracy. Our pipeline achieves accuracy levels competitive to the existing real-time methods for semantic image segmentation(mIoU above 60%), while achieving much higher frame rates. On the popular Cityscapes dataset with high resolution frames (2048 x 1024), the proposed operating points range from 80 to 1000 Hz on a single GPU and CPU.
A Non-Local Structure Tensor Based Approach for Multicomponent Image Recovery Problems
Oct 14, 2014
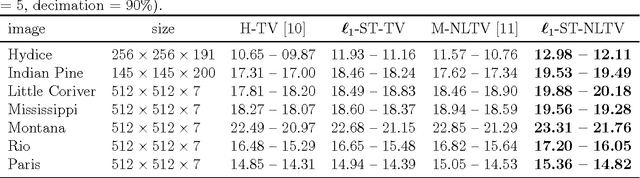


Non-Local Total Variation (NLTV) has emerged as a useful tool in variational methods for image recovery problems. In this paper, we extend the NLTV-based regularization to multicomponent images by taking advantage of the Structure Tensor (ST) resulting from the gradient of a multicomponent image. The proposed approach allows us to penalize the non-local variations, jointly for the different components, through various $\ell_{1,p}$ matrix norms with $p \ge 1$. To facilitate the choice of the hyper-parameters, we adopt a constrained convex optimization approach in which we minimize the data fidelity term subject to a constraint involving the ST-NLTV regularization. The resulting convex optimization problem is solved with a novel epigraphical projection method. This formulation can be efficiently implemented thanks to the flexibility offered by recent primal-dual proximal algorithms. Experiments are carried out for multispectral and hyperspectral images. The results demonstrate the interest of introducing a non-local structure tensor regularization and show that the proposed approach leads to significant improvements in terms of convergence speed over current state-of-the-art methods.
Fast Compressive Sensing Recovery Using Generative Models with Structured Latent Variables
Feb 19, 2019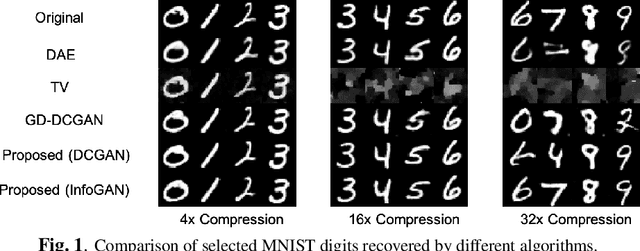
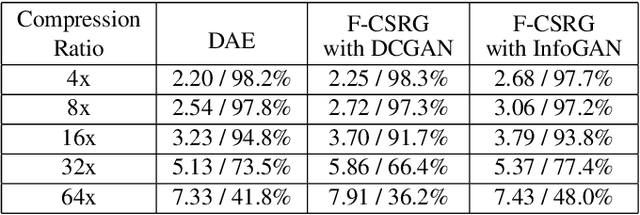

Deep learning models have significantly improved the visual quality and accuracy on compressive sensing recovery. In this paper, we propose an algorithm for signal reconstruction from compressed measurements with image priors captured by a generative model. We search and constrain on latent variable space to make the method stable when the number of compressed measurements is extremely limited. We show that, by exploiting certain structures of the latent variables, the proposed method produces improved reconstruction accuracy and preserves realistic and non-smooth features in the image. Our algorithm achieves high computation speed by projecting between the original signal space and the latent variable space in an alternating fashion.
Automated Pavement Crack Segmentation Using Fully Convolutional U-Net with a Pretrained ResNet-34 Encoder
Jan 11, 2020
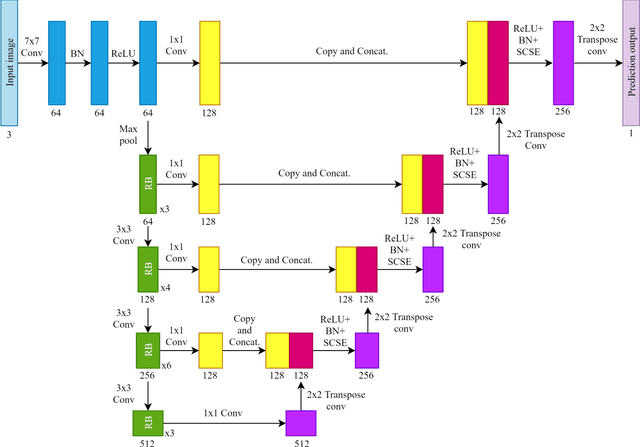
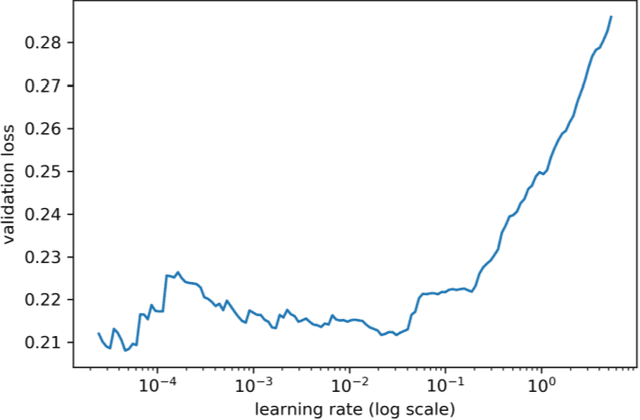
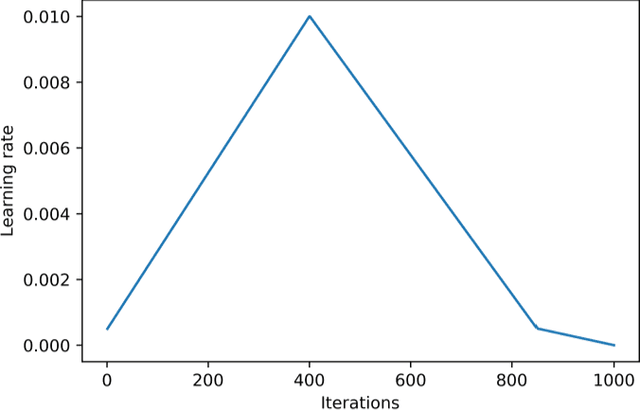
Automated pavement crack segmentation is a challenging task because of inherent irregular patterns and lighting conditions, in addition to the presence of noise in images. Conventional approaches require a substantial amount of feature engineering to differentiate crack regions from non-affected regions. In this paper, we propose a deep learning technique based on a convolutional neural network to perform segmentation tasks on pavement crack images. Our approach requires minimal feature engineering compared to other machine learning techniques. The proposed neural network architecture is a modified U-Net in which the encoder is replaced with a pretrained ResNet-34 network. To minimize the dice coefficient loss function, we optimize the parameters in the neural network by using an adaptive moment optimizer called AdamW. Additionally, we use a systematic method to find the optimum learning rate instead of doing parametric sweeps. We used a "one-cycle" training schedule based on cyclical learning rates to speed up the convergence. We evaluated the performance of our convolutional neural network on CFD, a pavement crack image dataset. Our method achieved an F1 score of about 96%. This is the best performance among all other algorithms tested on this dataset, outperforming the previous best method by a 1.7% margin.
OCCER- One-Class Classification by Ensembles of Regression models
Dec 26, 2019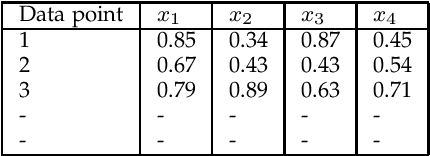
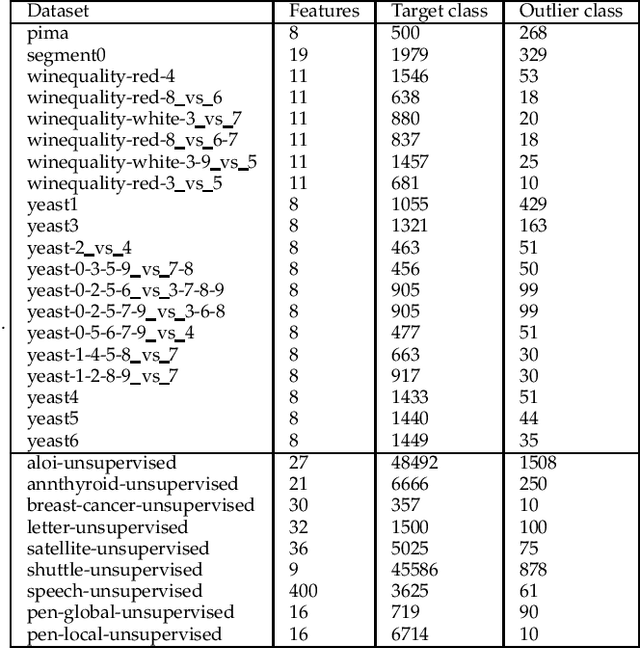
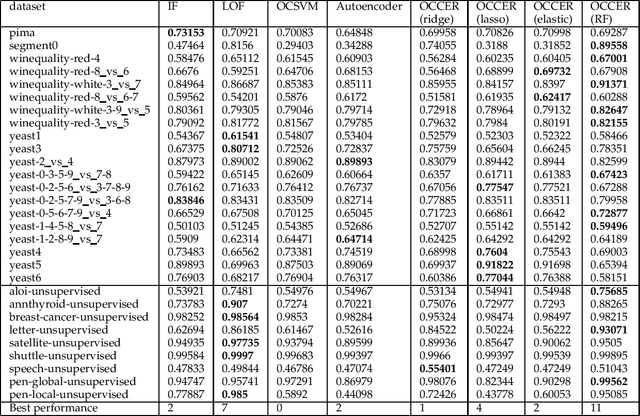
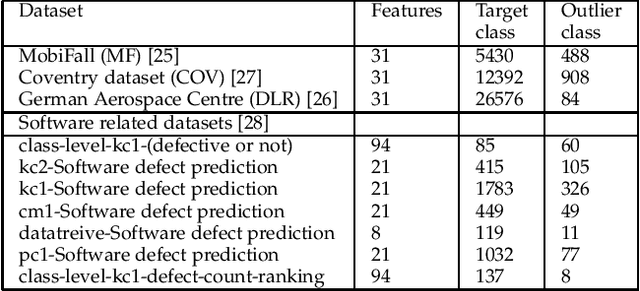
One-class classification (OCC) deals with the classification problem in which the training data has data points belonging to target class only. In this paper, we present a one-class classification algorithm; One-Class Classification by Ensembles of Regression models (OCCER) that uses regression methods to address OCC problems. The OCCEM algorithm coverts a OCC problem into many regression problems in the original feature space such that each feature of the original feature space is used as the target variable in one of the regression problems. Other features are used as the variables on which the dependent variable is depend upon. The errors of regression of a data point by all the regression models are used to compute the outlier score of the data point. An extensive comparison of the OCCER to the state-of-the-art OCC algorithms on several datasets was carried out to show the effectiveness of the proposed approach. We also show that OCCER algorithm can work well with the latent feature space created by autoencoders for image datasets. The implementation of OCCER is available at https://github.com/srikanthBezawada/OCCER.
Dipole and Quadrupole Moments in Image Processing
Feb 24, 2009This paper proposes an algorithm for image processing, obtained by adapting to image maps the definitions of two well-known physical quantities. These quantities are the dipole and quadrupole moments of a charge distribution. We will see how it is possible to define dipole and quadrupole moments for the gray-tone maps and apply them in the development of algorithms for edge detection.
AdaFilter: Adaptive Filter Fine-tuning for Deep Transfer Learning
Dec 09, 2019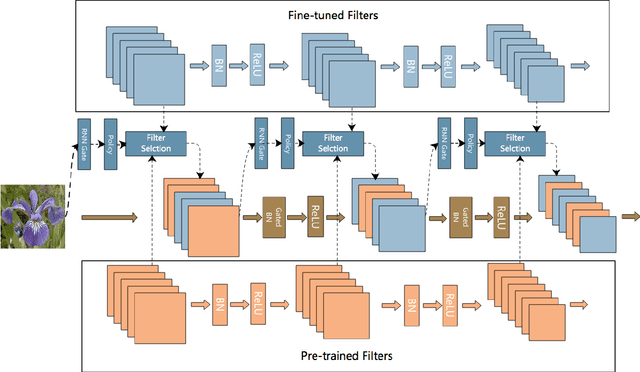
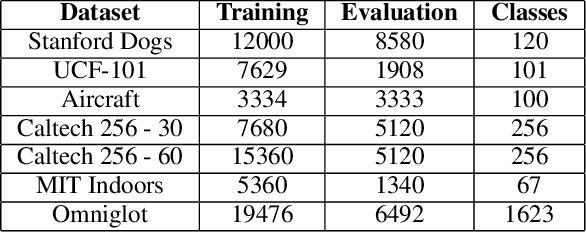
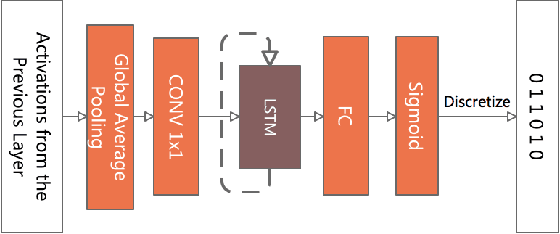

There is an increasing number of pre-trained deep neural network models. However, it is still unclear how to effectively use these models for a new task. Transfer learning, which aims to transfer knowledge from source tasks to a target task, is an effective solution to this problem. Fine-tuning is a popular transfer learning technique for deep neural networks where a few rounds of training are applied to the parameters of a pre-trained model to adapt them to a new task. Despite its popularity, in this paper, we show that fine-tuning suffers from several drawbacks. We propose an adaptive fine-tuning approach, called AdaFilter, which selects only a part of the convolutional filters in the pre-trained model to optimize on a per-example basis. We use a recurrent gated network to selectively fine-tune convolutional filters based on the activations of the previous layer. We experiment with 7 public image classification datasets and the results show that AdaFilter can reduce the average classification error of the standard fine-tuning by 2.54%.