 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Face Hallucination Revisited: An Exploratory Study on Dataset Bias
Dec 21, 2018

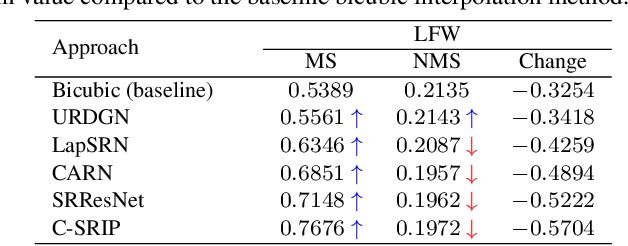
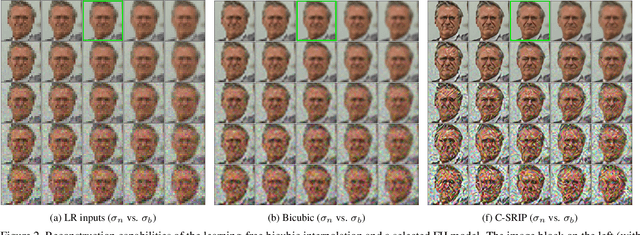
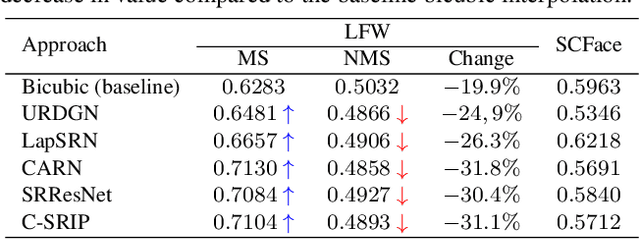
Contemporary face hallucination (FH) models exhibit considerable ability to reconstruct high-resolution (HR) details from low-resolution (LR) face images. This ability is commonly learned from examples of corresponding HR-LR image pairs, created by artificially down-sampling the HR ground truth data. This down-sampling (or degradation) procedure not only defines the characteristics of the LR training data, but also determines the type of image degradations the learned FH models are eventually able to handle. If the image characteristics encountered with real-world LR images differ from the ones seen during training, FH models are still expected to perform well, but in practice may not produce the desired results. In this paper we study this problem and explore the bias introduced into FH models by the characteristics of the training data. We systematically analyze the generalization capabilities of several FH models in various scenarios, where the image the degradation function does not match the training setup and conduct experiments with synthetically downgraded as well as real-life low-quality images. We make several interesting findings that provide insight into existing problems with FH models and point to future research directions.
One-Shot Texture Retrieval with Global Context Metric
May 16, 2019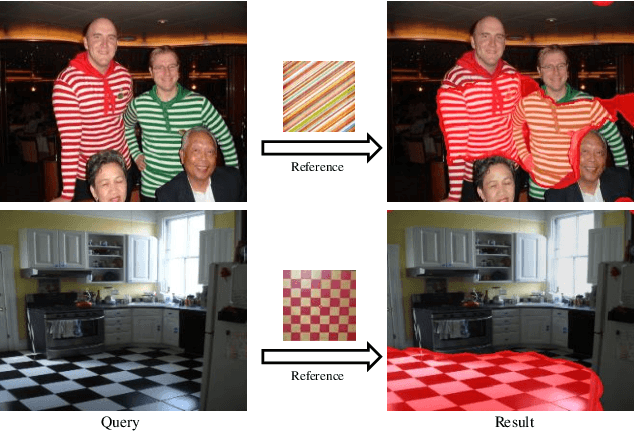
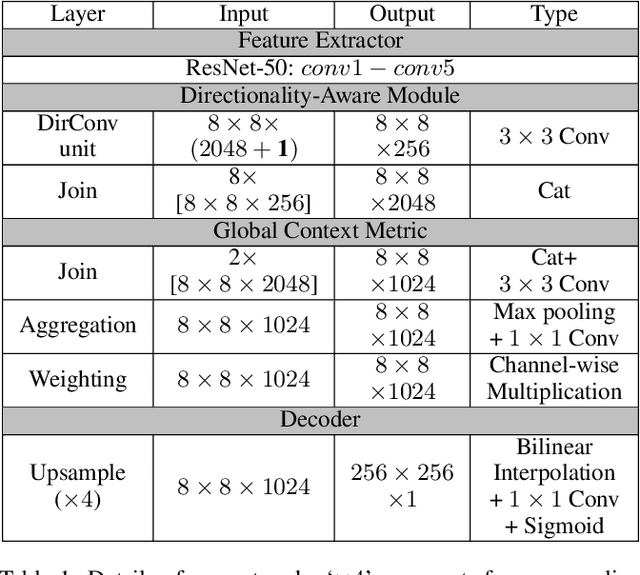
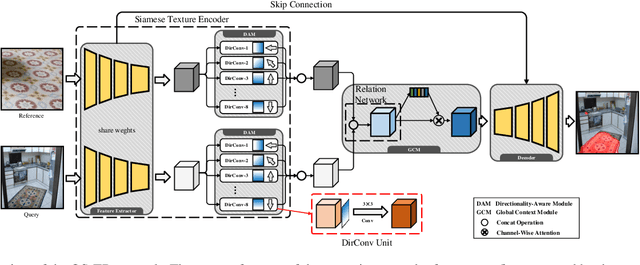

In this paper, we tackle one-shot texture retrieval: given an example of a new reference texture, detect and segment all the pixels of the same texture category within an arbitrary image. To address this problem, we present an OS-TR network to encode both reference and query image, leading to achieve texture segmentation towards the reference category. Unlike the existing texture encoding methods that integrate CNN with orderless pooling, we propose a directionality-aware module to capture the texture variations at each direction, resulting in spatially invariant representation. To segment new categories given only few examples, we incorporate a self-gating mechanism into relation network to exploit global context information for adjusting per-channel modulation weights of local relation features. Extensive experiments on benchmark texture datasets and real scenarios demonstrate the above-par segmentation performance and robust generalization across domains of our proposed method.
Dense Dilated Convolutions Merging Network for Land Cover Classification
Mar 09, 2020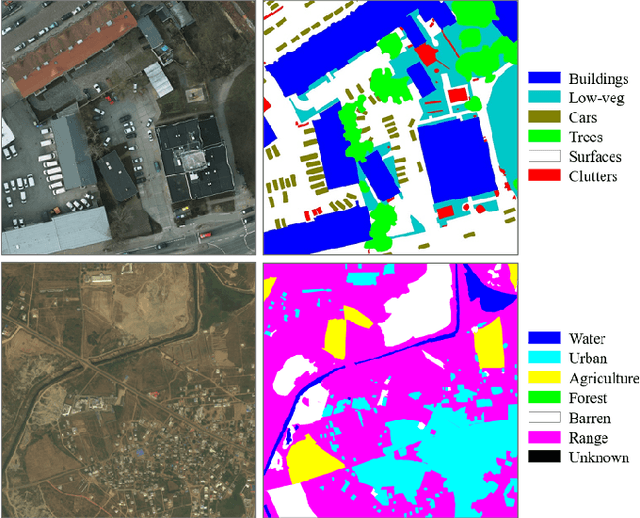
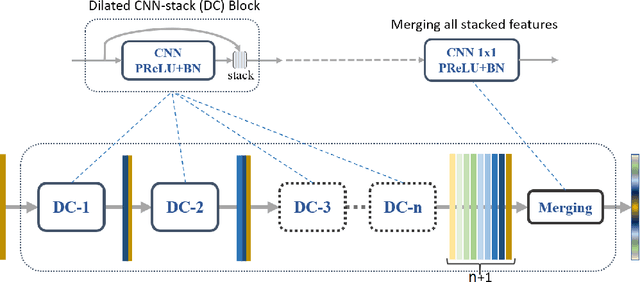
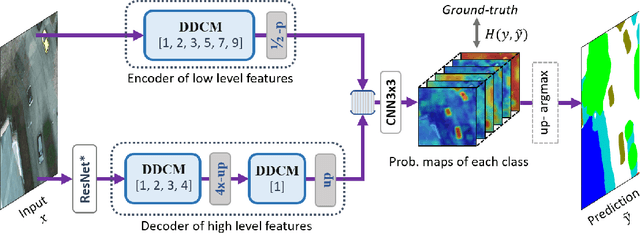
Land cover classification of remote sensing images is a challenging task due to limited amounts of annotated data, highly imbalanced classes, frequent incorrect pixel-level annotations, and an inherent complexity in the semantic segmentation task. In this article, we propose a novel architecture called the dense dilated convolutions' merging network (DDCM-Net) to address this task. The proposed DDCM-Net consists of dense dilated image convolutions merged with varying dilation rates. This effectively utilizes rich combinations of dilated convolutions that enlarge the network's receptive fields with fewer parameters and features compared with the state-of-the-art approaches in the remote sensing domain. Importantly, DDCM-Net obtains fused local- and global-context information, in effect incorporating surrounding discriminative capability for multiscale and complex-shaped objects with similar color and textures in very high-resolution aerial imagery. We demonstrate the effectiveness, robustness, and flexibility of the proposed DDCM-Net on the publicly available ISPRS Potsdam and Vaihingen data sets, as well as the DeepGlobe land cover data set. Our single model, trained on three-band Potsdam and Vaihingen data sets, achieves better accuracy in terms of both mean intersection over union (mIoU) and F1-score compared with other published models trained with more than three-band data. We further validate our model on the DeepGlobe data set, achieving state-of-the-art result 56.2% mIoU with much fewer parameters and at a lower computational cost compared with related recent work. Code available at https://github.com/samleoqh/DDCM-Semantic-Segmentation-PyTorch
Illumination Robust Loop Closure Detection with the Constraint of Pose
Dec 27, 2019Background: Loop closure detection is a crucial part in robot navigation and simultaneous location and mapping (SLAM). Appearance-based loop closure detection still faces many challenges, such as illumination changes, perceptual aliasing and increasing computational complexity. Method: In this paper, we proposed a visual loop-closure detection algorithm which combines illumination robust descriptor DIRD and odometry information. The estimated pose and variance are calculated by the visual inertial odometry (VIO), then the loop closure candidate areas are found based on the distance between images. We use a new distance combing the the Euclidean distance and the Mahalanobis distance and a dynamic threshold to select the loop closure candidate areas. Finally, in loop-closure candidate areas, we do image retrieval with DIRD which is an illumination robust descriptor. Results: The proposed algorithm is evaluated on KITTI_00 and EuRoc datasets. The results show that the loop closure areas could be correctly detected and the time consumption is effectively reduced. We compare it with SeqSLAM algorithm, the proposed algorithm gets better performance on PR-curve.
Color Image Classification via Quaternion Principal Component Analysis Network
Mar 05, 2015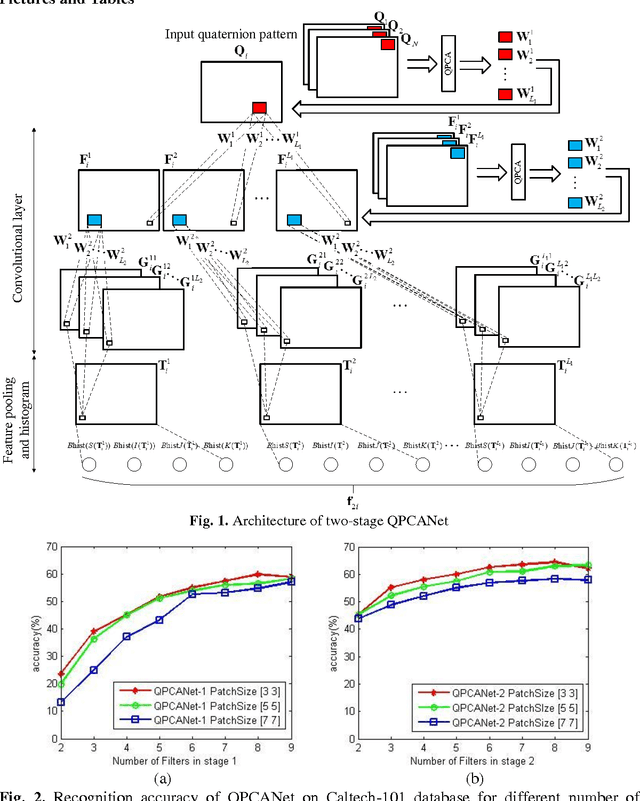

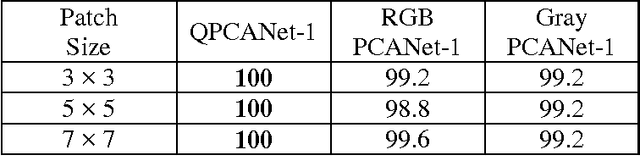

The Principal Component Analysis Network (PCANet), which is one of the recently proposed deep learning architectures, achieves the state-of-the-art classification accuracy in various databases. However, the performance of PCANet may be degraded when dealing with color images. In this paper, a Quaternion Principal Component Analysis Network (QPCANet), which is an extension of PCANet, is proposed for color images classification. Compared to PCANet, the proposed QPCANet takes into account the spatial distribution information of color images and ensures larger amount of intra-class invariance of color images. Experiments conducted on different color image datasets such as Caltech-101, UC Merced Land Use, Georgia Tech face and CURet have revealed that the proposed QPCANet achieves higher classification accuracy than PCANet.
Curiosity-driven Reinforcement Learning for Diverse Visual Paragraph Generation
Aug 29, 2019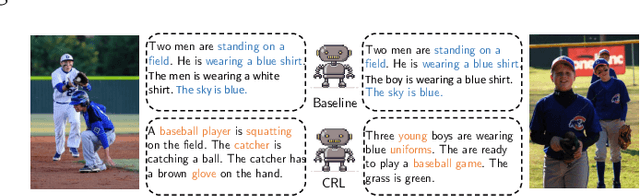
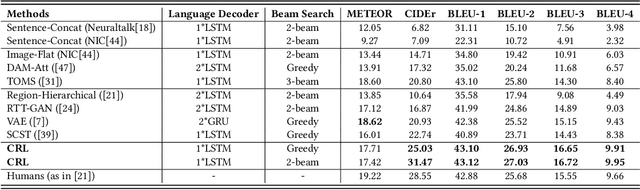
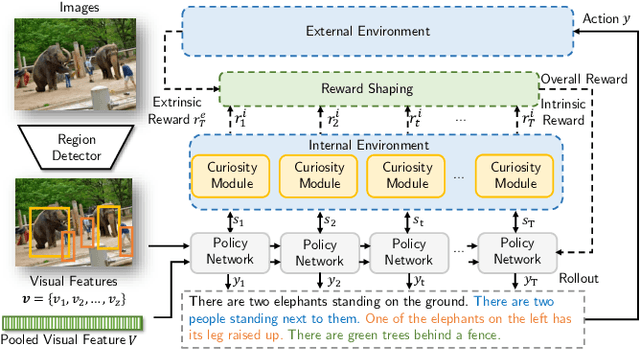
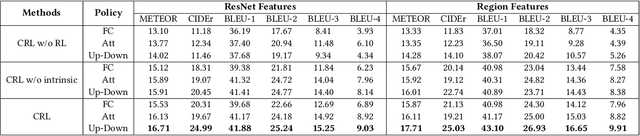
Visual paragraph generation aims to automatically describe a given image from different perspectives and organize sentences in a coherent way. In this paper, we address three critical challenges for this task in a reinforcement learning setting: the mode collapse, the delayed feedback, and the time-consuming warm-up for policy networks. Generally, we propose a novel Curiosity-driven Reinforcement Learning (CRL) framework to jointly enhance the diversity and accuracy of the generated paragraphs. First, by modeling the paragraph captioning as a long-term decision-making process and measuring the prediction uncertainty of state transitions as intrinsic rewards, the model is incentivized to memorize precise but rarely spotted descriptions to context, rather than being biased towards frequent fragments and generic patterns. Second, since the extrinsic reward from evaluation is only available until the complete paragraph is generated, we estimate its expected value at each time step with temporal-difference learning, by considering the correlations between successive actions. Then the estimated extrinsic rewards are complemented by dense intrinsic rewards produced from the derived curiosity module, in order to encourage the policy to fully explore action space and find a global optimum. Third, discounted imitation learning is integrated for learning from human demonstrations, without separately performing the time-consuming warm-up in advance. Extensive experiments conducted on the Standford image-paragraph dataset demonstrate the effectiveness and efficiency of the proposed method, improving the performance by 38.4% compared with state-of-the-art.
GeoGAN: A Conditional GAN with Reconstruction and Style Loss to Generate Standard Layer of Maps from Satellite Images
Feb 14, 2019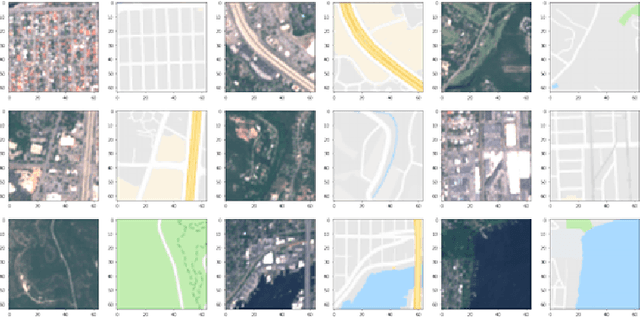
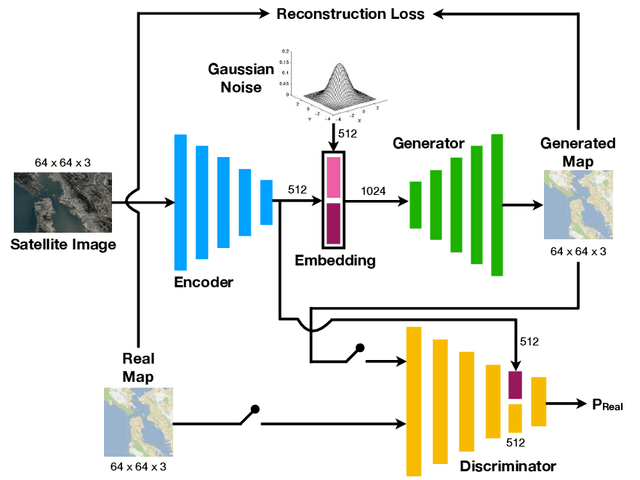
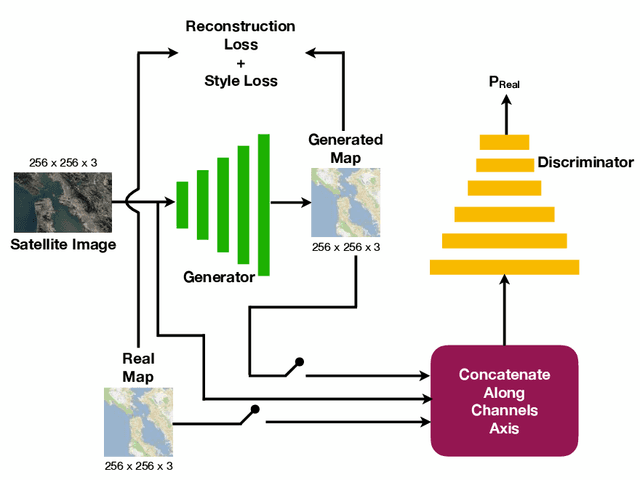
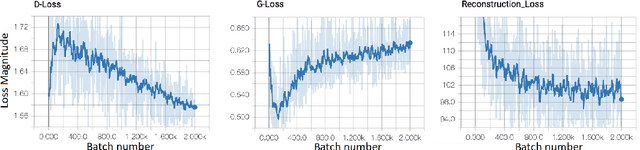
Automatically generating maps from satellite images is an important task. There is a body of literature which tries to address this challenge. We created a more expansive survey of the task by experimenting with different models and adding new loss functions to improve results. We created a database of pairs of satellite images and the corresponding map of the area. Our model translates the satellite image to the corresponding standard layer map image using three main model architectures: (i) a conditional Generative Adversarial Network (GAN) which compresses the images down to a learned embedding, (ii) a generator which is trained as a normalizing flow (RealNVP) model, and (iii) a conditional GAN where the generator translates via a series of convolutions to the standard layer of a map and the discriminator input is the concatenation of the real/generated map and the satellite image. Model (iii) was by far the most promising of three models. To improve the results we also added a reconstruction loss and style transfer loss in addition to the GAN losses. The third model architecture produced the best quality of sampled images. In contrast to the other generative model where evaluation of the model is a challenging problem. since we have access to the real map for a given satellite image, we are able to assign a quantitative metric to the quality of the generated images in addition to inspecting them visually. While we are continuing to work on increasing the accuracy of the model, one challenge has been the coarse resolution of the data which upper-bounds the quality of the results of our model. Nevertheless, as will be seen in the results, the generated map is more accurate in the features it produces since the generator architecture demands a pixel-wise image translation/pixel-wise coloring. A video presentation summarizing this paper is available at: https://youtu.be/Ur0flOX-Ji0
Large-scale mammography CAD with Deformable Conv-Nets
Feb 19, 2019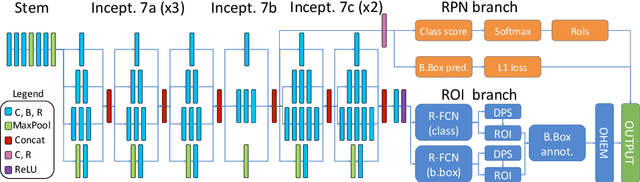

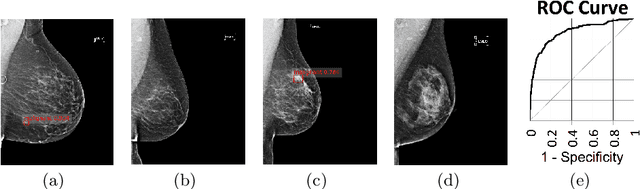
State-of-the-art deep learning methods for image processing are evolving into increasingly complex meta-architectures with a growing number of modules. Among them, region-based fully convolutional networks (R-FCN) and deformable convolutional nets (DCN) can improve CAD for mammography: R-FCN optimizes for speed and low consumption of memory, which is crucial for processing the high resolutions of to 50 micrometers used by radiologists. Deformable convolution and pooling can model a wide range of mammographic findings of different morphology and scales, thanks to their versatility. In this study, we present a neural net architecture based on R-FCN / DCN, that we have adapted from the natural image domain to suit mammograms -- particularly their larger image size -- without compromising resolution. We trained the network on a large, recently released dataset (Optimam) including 6,500 cancerous mammograms. By combining our modern architecture with such a rich dataset, we achieved an area under the ROC curve of 0.879 for breast-wise detection in the DREAMS challenge (130,000 withheld images), which surpassed all other submissions in the competitive phase.
An Iterative Convolutional Neural Network Algorithm Improves Electron Microscopy Image Segmentation
Jun 18, 2015
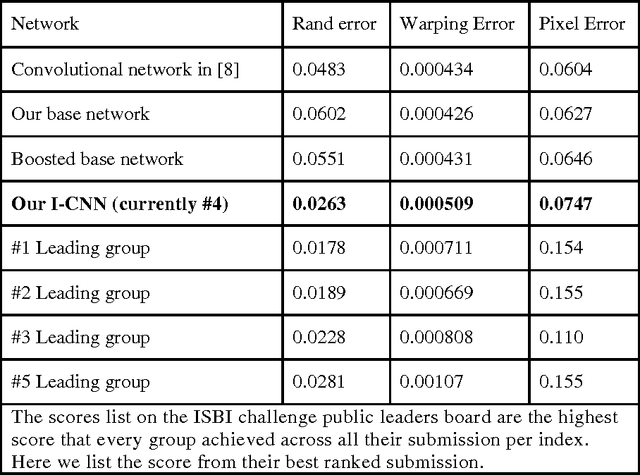
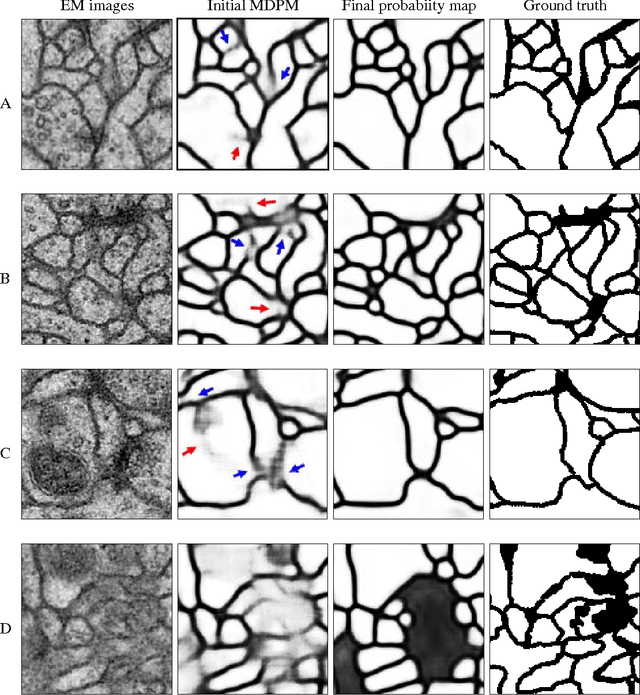
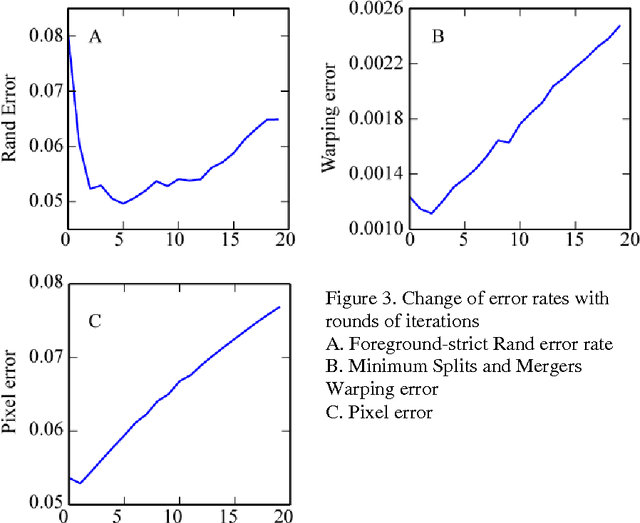
To build the connectomics map of the brain, we developed a new algorithm that can automatically refine the Membrane Detection Probability Maps (MDPM) generated to perform automatic segmentation of electron microscopy (EM) images. To achieve this, we executed supervised training of a convolutional neural network to recover the removed center pixel label of patches sampled from a MDPM. MDPM can be generated from other machine learning based algorithms recognizing whether a pixel in an image corresponds to the cell membrane. By iteratively applying this network over MDPM for multiple rounds, we were able to significantly improve membrane segmentation results.
Feature2Mass: Visual Feature Processing in Latent Space for Realistic Labeled Mass Generation
Sep 17, 2018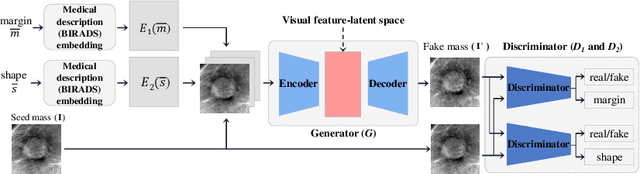
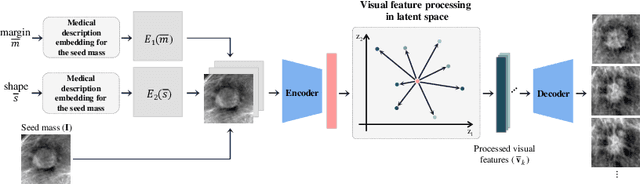
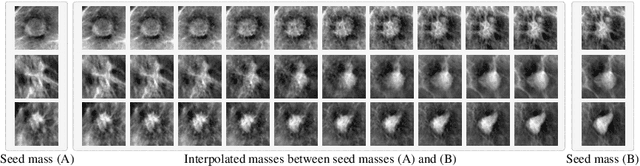
This paper deals with a method for generating realistic labeled masses. Recently, there have been many attempts to apply deep learning to various bio-image computing fields including computer-aided detection and diagnosis. In order to learn deep network model to be well-behaved in bio-image computing fields, a lot of labeled data is required. However, in many bioimaging fields, the large-size of labeled dataset is scarcely available. Although a few researches have been dedicated to solving this problem through generative model, there are some problems as follows: 1) The generated bio-image does not seem realistic; 2) the variation of generated bio-image is limited; and 3) additional label annotation task is needed. In this study, we propose a realistic labeled bio-image generation method through visual feature processing in latent space. Experimental results have shown that mass images generated by the proposed method were realistic and had wide expression range of targeted mass characteristics.