 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Analysis Dictionary Learning: An Efficient and Discriminative Solution
Mar 07, 2019

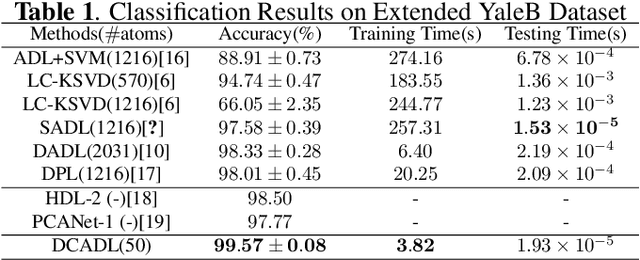
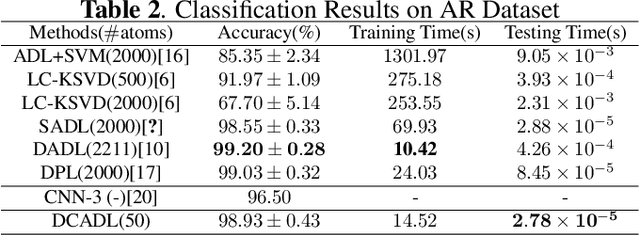

Discriminative Dictionary Learning (DL) methods have been widely advocated for image classification problems. To further sharpen their discriminative capabilities, most state-of-the-art DL methods have additional constraints included in the learning stages. These various constraints, however, lead to additional computational complexity. We hence propose an efficient Discriminative Convolutional Analysis Dictionary Learning (DCADL) method, as a lower cost Discriminative DL framework, to both characterize the image structures and refine the interclass structure representations. The proposed DCADL jointly learns a convolutional analysis dictionary and a universal classifier, while greatly reducing the time complexity in both training and testing phases, and achieving a competitive accuracy, thus demonstrating great performance in many experiments with standard databases.
Motion Corrected Multishot MRI Reconstruction Using Generative Networks with Sensitivity Encoding
Feb 20, 2019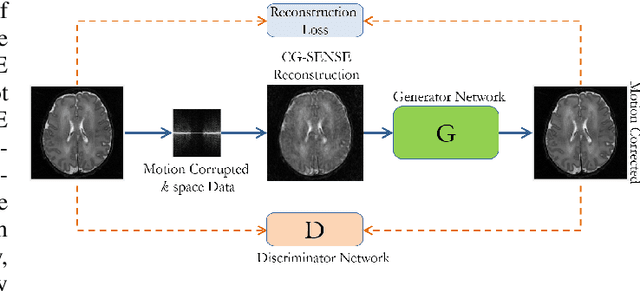
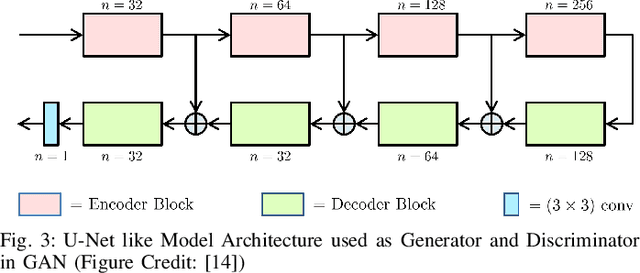

Multishot Magnetic Resonance Imaging (MRI) is a promising imaging modality that can produce a high-resolution image with relatively less data acquisition time. The downside of multishot MRI is that it is very sensitive to subject motion and even small amounts of motion during the scan can produce artifacts in the final MR image that may cause misdiagnosis. Numerous efforts have been made to address this issue; however, all of these proposals are limited in terms of how much motion they can correct and the required computational time. In this paper, we propose a novel generative networks based conjugate gradient SENSE (CG-SENSE) reconstruction framework for motion correction in multishot MRI. The proposed framework first employs CG-SENSE reconstruction to produce the motion-corrupted image and then a generative adversarial network (GAN) is used to correct the motion artifacts. The proposed method has been rigorously evaluated on synthetically corrupted data on varying degrees of motion, numbers of shots, and encoding trajectories. Our analyses (both quantitative as well as qualitative/visual analysis) establishes that the proposed method significantly robust and outperforms state-of-the-art motion correction techniques and also reduces severalfold of computational times.
Semi-Supervised Learning using Differentiable Reasoning
Aug 13, 2019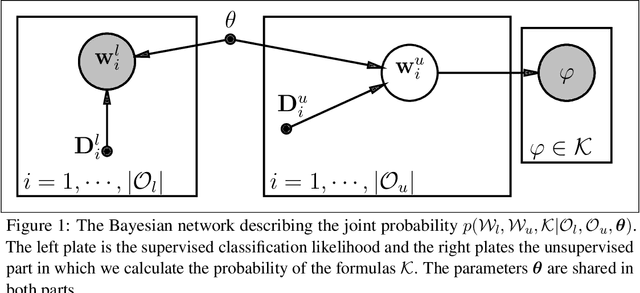
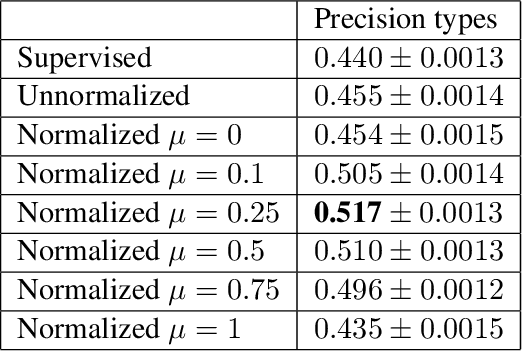


We introduce Differentiable Reasoning (DR), a novel semi-supervised learning technique which uses relational background knowledge to benefit from unlabeled data. We apply it to the Semantic Image Interpretation (SII) task and show that background knowledge provides significant improvement. We find that there is a strong but interesting imbalance between the contributions of updates from Modus Ponens (MP) and its logical equivalent Modus Tollens (MT) to the learning process, suggesting that our approach is very sensitive to a phenomenon called the Raven Paradox. We propose a solution to overcome this situation.
CEREALS - Cost-Effective REgion-based Active Learning for Semantic Segmentation
Oct 23, 2018

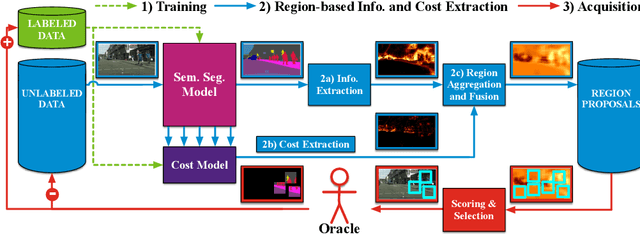
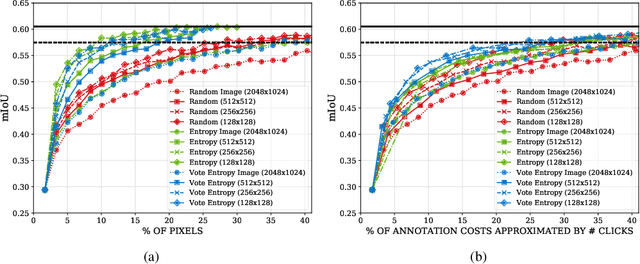
State of the art methods for semantic image segmentation are trained in a supervised fashion using a large corpus of fully labeled training images. However, gathering such a corpus is expensive, due to human annotation effort, in contrast to gathering unlabeled data. We propose an active learning-based strategy, called CEREALS, in which a human only has to hand-label a few, automatically selected, regions within an unlabeled image corpus. This minimizes human annotation effort while maximizing the performance of a semantic image segmentation method. The automatic selection procedure is achieved by: a) using a suitable information measure combined with an estimate about human annotation effort, which is inferred from a learned cost model, and b) exploiting the spatial coherency of an image. The performance of CEREALS is demonstrated on Cityscapes, where we are able to reduce the annotation effort to 17%, while keeping 95% of the mean Intersection over Union (mIoU) of a model that was trained with the fully annotated training set of Cityscapes.
Rethinking Normalization and Elimination Singularity in Neural Networks
Nov 21, 2019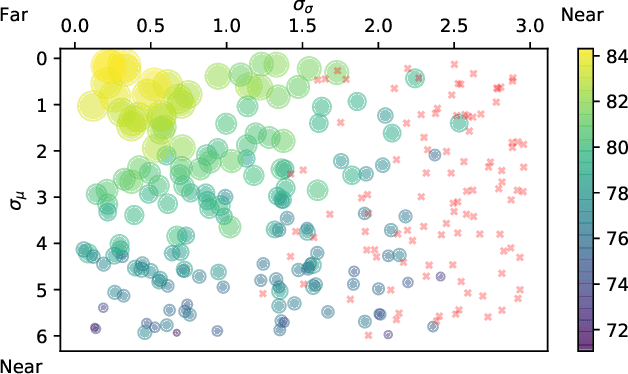
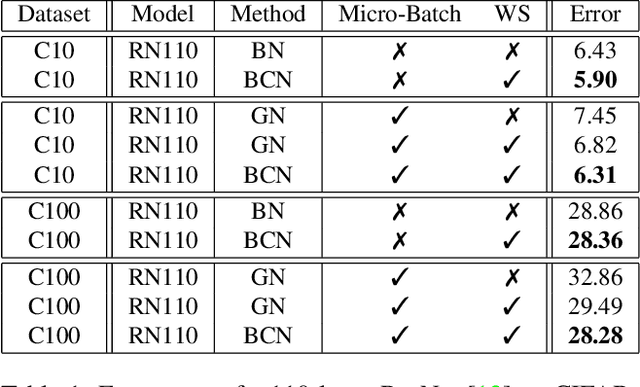
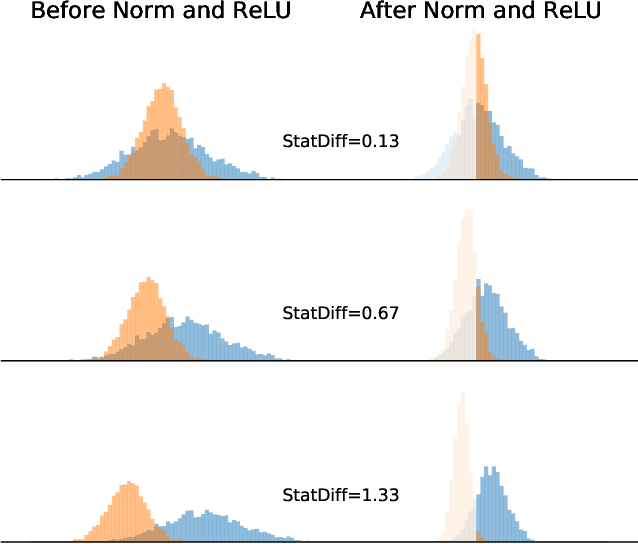
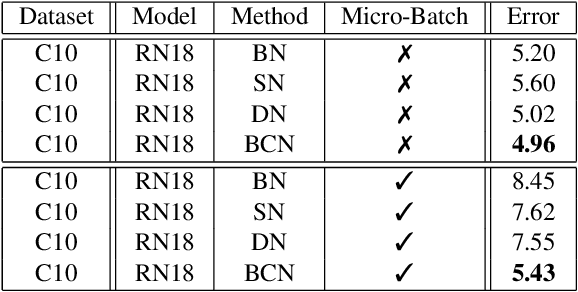
In this paper, we study normalization methods for neural networks from the perspective of elimination singularity. Elimination singularities correspond to the points on the training trajectory where neurons become consistently deactivated. They cause degenerate manifolds in the loss landscape which will slow down training and harm model performances. We show that channel-based normalizations (e.g. Layer Normalization and Group Normalization) are unable to guarantee a far distance from elimination singularities, in contrast with Batch Normalization which by design avoids models from getting too close to them. To address this issue, we propose BatchChannel Normalization (BCN), which uses batch knowledge to avoid the elimination singularities in the training of channel-normalized models. Unlike Batch Normalization, BCN is able to run in both large-batch and micro-batch training settings. The effectiveness of BCN is verified on many tasks, including image classification, object detection, instance segmentation, and semantic segmentation. The code is here: https://github.com/joe-siyuan-qiao/Batch-Channel-Normalization.
PVN3D: A Deep Point-wise 3D Keypoints Voting Network for 6DoF Pose Estimation
Nov 11, 2019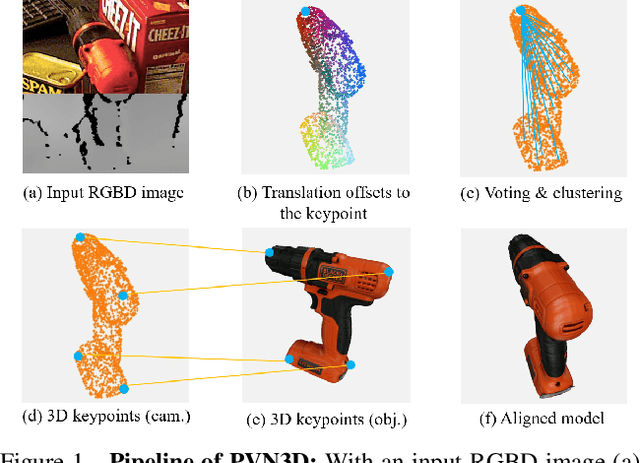
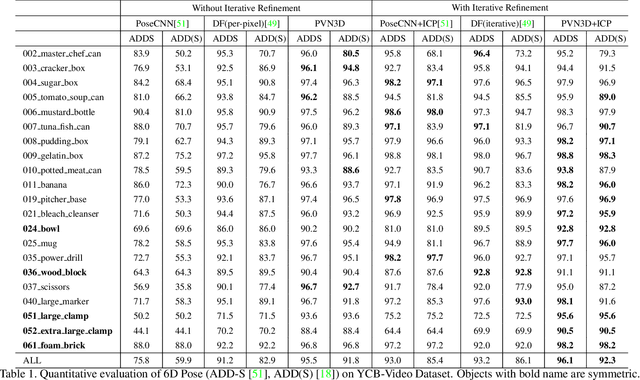
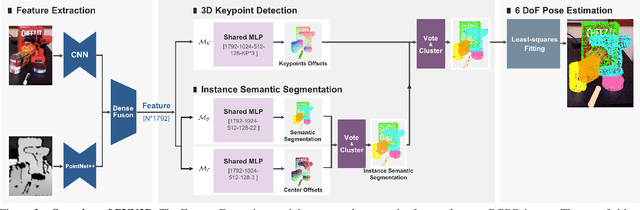
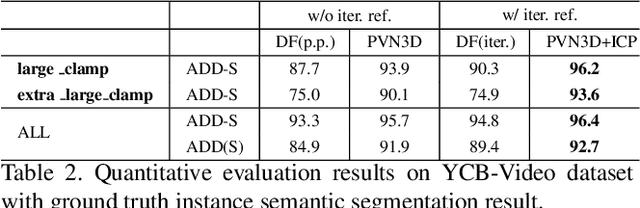
In this work, we present a novel data-driven method for robust 6DoF object pose estimation from a single RGBD image. Unlike previous methods that directly regressing pose parameters, we tackle this challenging task with a keypoint-based approach. Specifically, we propose a deep Hough voting network to detect 3D keypoints of objects and then estimate the 6D pose parameters within a least-squares fitting manner. Our method is a natural extension of 2D-keypoint approaches that successfully work on RGB based 6DoF estimation. It allows us to fully utilize the geometric constraint of rigid objects with the extra depth information and is easy for a network to learn and optimize. Extensive experiments were conducted to demonstrate the effectiveness of 3D-keypoint detection in the 6D pose estimation task. Experimental results also show our method outperforms the state-of-the-art methods by large margins on several benchmarks.
Facial age estimation by deep residual decision making
Aug 28, 2019
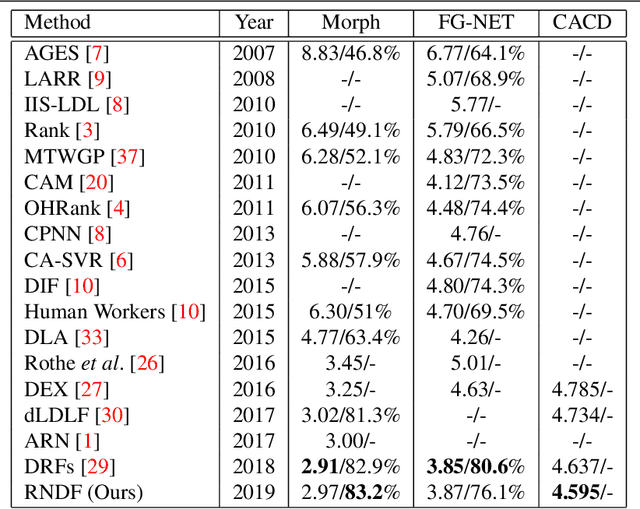

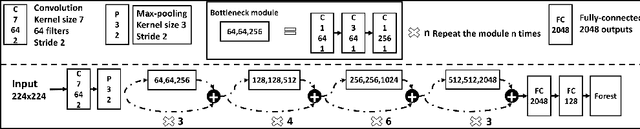
Residual representation learning simplifies the optimization problem of learning complex functions and has been widely used by traditional convolutional neural networks. However, it has not been applied to deep neural decision forest (NDF). In this paper we incorporate residual learning into NDF and the resulting model achieves state-of-the-art level accuracy on three public age estimation benchmarks while requiring less memory and computation. We further employ gradient-based technique to visualize the decision-making process of NDF and understand how it is influenced by facial image inputs. The code and pre-trained models will be available at https://github.com/Nicholasli1995/VisualizingNDF.
Towards Building a Real Time Mobile Device Bird Counting System Through Synthetic Data Training and Model Compression
Dec 28, 2019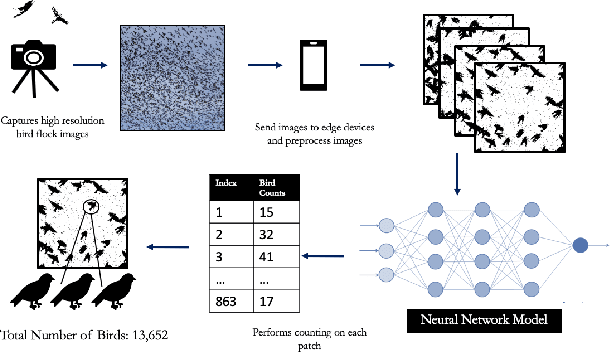

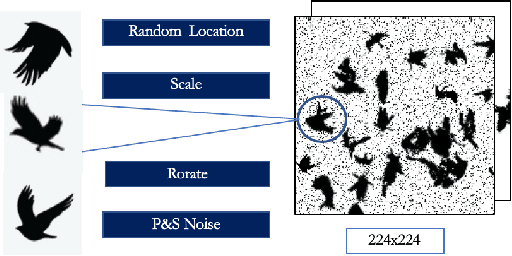
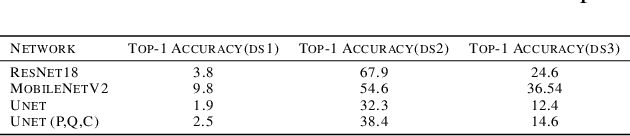
Counting the number of birds in an open sky setting has been an challenging problem due to the large number of bird flocks and the birds can overlap. Another difficulty is the lack of accurate training samples since the cost of labeling images of bird flocks can be extremely high and each sample picture can contain thousands of birds in a high resolution image. Inspired by recent work on training with synthetic data to perform crowd counting, we design a mechanism to generate synthetic bird dataset with precise bird count and the corresponding density maps. We then train a Unet model on the synthetic dataset to perform density map estimation that produces the count for each input. Our method is able to achieve MSE of approximately 12.4 on real dataset. In order to build a scalable system for fast bird counting under storage and computational constraints, we use model compression techniques and efficient model structures to increase the inference speed and save storage cost. We are able to reduce storage cost from 55MB to less than 5MB for the model with minimum loss of accuracy. This paper describes the pipelines of building an efficient bird counting system.
Convolution Neural Network Architecture Learning for Remote Sensing Scene Classification
Jan 27, 2020
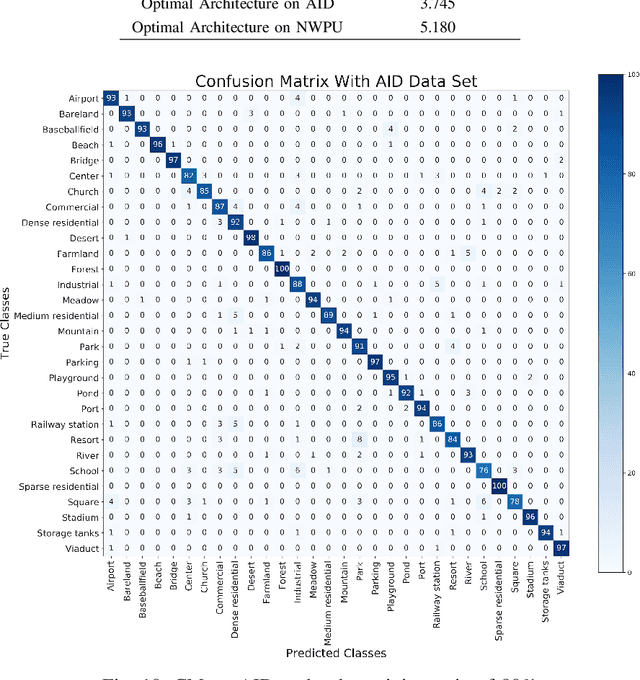
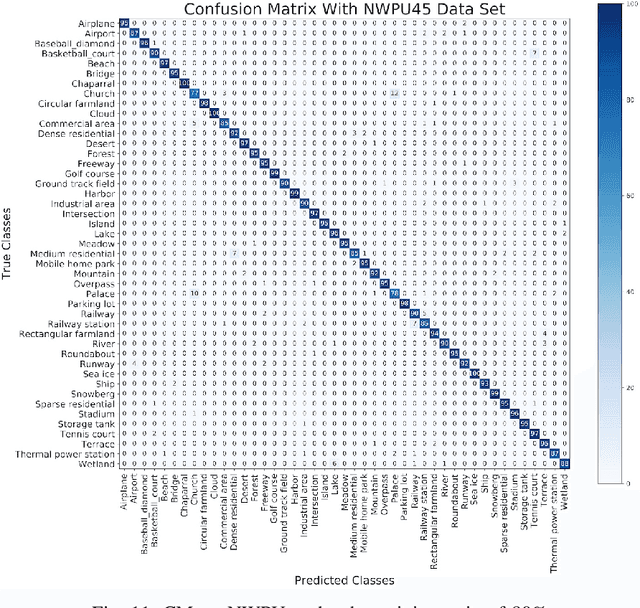
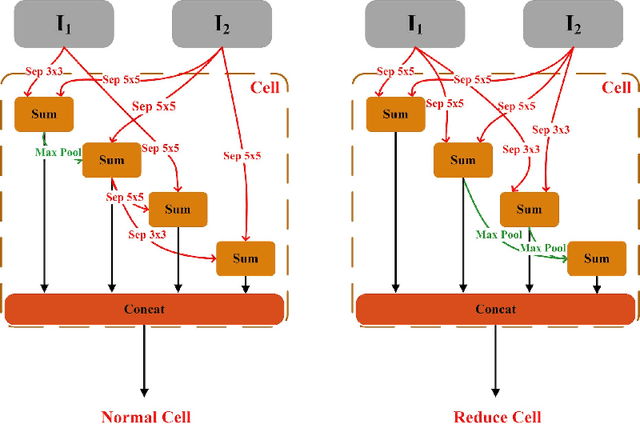
Remote sensing image scene classification is a fundamental but challenging task in understanding remote sensing images. Recently, deep learning-based methods, especially convolutional neural network-based (CNN-based) methods have shown enormous potential to understand remote sensing images. CNN-based methods meet with success by utilizing features learned from data rather than features designed manually. The feature-learning procedure of CNN largely depends on the architecture of CNN. However, most of the architectures of CNN used for remote sensing scene classification are still designed by hand which demands a considerable amount of architecture engineering skills and domain knowledge, and it may not play CNN's maximum potential on a special dataset. In this paper, we proposed an automatically architecture learning procedure for remote sensing scene classification. We designed a parameters space in which every set of parameters represents a certain architecture of CNN (i.e., some parameters represent the type of operators used in the architecture such as convolution, pooling, no connection or identity, and the others represent the way how these operators connect). To discover the optimal set of parameters for a given dataset, we introduced a learning strategy which can allow efficient search in the architecture space by means of gradient descent. An architecture generator finally maps the set of parameters into the CNN used in our experiments.
Deep Denoising: Rate-Optimal Recovery of Structured Signals with a Deep Prior
May 22, 2018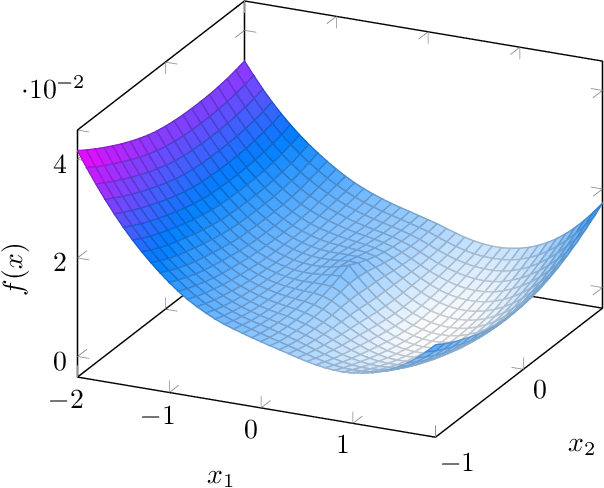
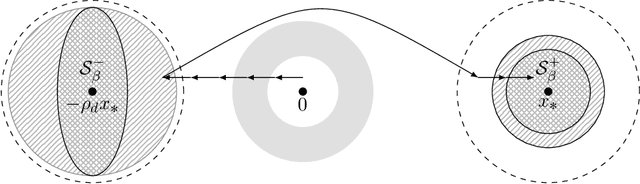

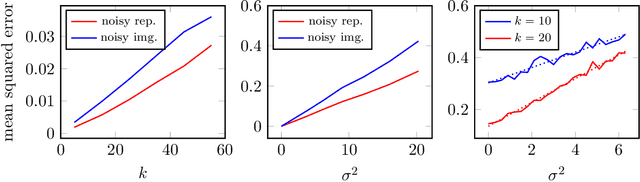
Deep neural networks provide state-of-the-art performance for image denoising, where the goal is to map a noisy image to a near noise-free image. The underlying principle is simple: images are well described by priors that map a low-dimensional latent representations to image. Based on a prior, a noisy image can be denoised by finding a close image in the range of the prior. Since deep networks trained on large set of images have empirically been shown to be good priors, they enable effective denoisers. However, there is little theory to justify this success, let alone to predict the denoising performance. In this paper we consider the problem of denoising an image from additive Gaussian noise with variance $\sigma^2$, assuming the image is well described by a deep neural network with ReLu activations functions, mapping a $k$-dimensional latent space to an $n$-dimensional image. We provide an iterative algorithm minimizing a non-convex loss that provably removes noise energy by a fraction $\sigma^2 k/n$. We also demonstrate in numerical experiments that this denoising performance is, indeed, achieved by generative priors learned from data.