 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HybridNetSeg: A Compact Hybrid Network for Retinal Vessel Segmentation
Nov 22, 2019
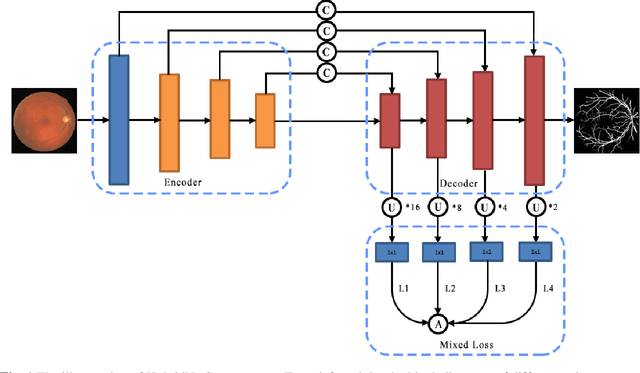



A large number of retinal vessel analysis methods based on image segmentation have emerged in recent years. However, existing methods depend on cumbersome backbones, such as VGG16 and ResNet-50, benefiting from their powerful feature extraction capabilities but suffering from high computational costs. In this paper, we propose a novel neural network (HybridNetSeg) dedicated to solving this drawback while further improving overall performance. Considering deformable convolution can extract complex and variable structural information, and larger kernel in mixed depthwise convolution makes contribution to higher accuracy. We have integrated these two modules and propose a Hybrid Convolution Block (HCB) using the idea of heuristic learning. Inspired by the U-Net, we use HCB to replace a part of the common convolution of the U-Net encoder, drastically reducing the parameter count to 0.71M while accelerating the inference process. Not only that, we also propose a multi-scale mixed loss mechanism. Extensive experiments on three major benchmark datasets demonstrate the effectiveness of our proposed method
MIMA: MAPPER-Induced Manifold Alignment for Semi-Supervised Fusion of Optical Image and Polarimetric SAR Data
Jun 13, 2019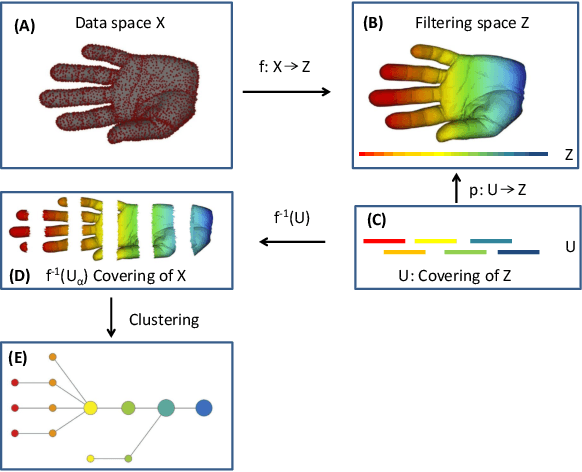
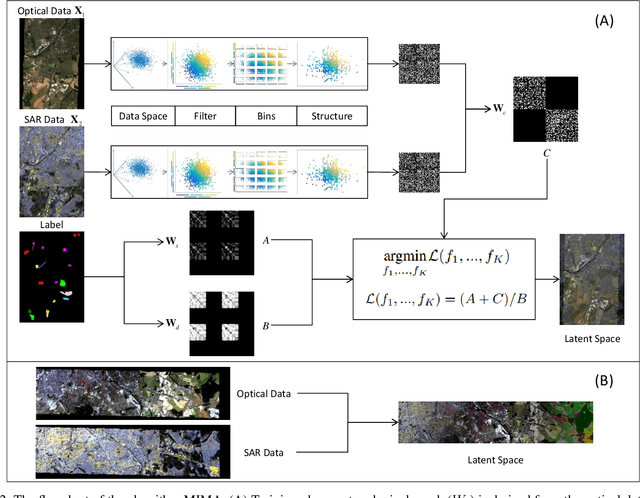


Multi-modal data fusion has recently been shown promise in classification tasks in remote sensing. Optical data and radar data, two important yet intrinsically different data sources, are attracting more and more attention for potential data fusion. It is already widely known that, a machine learning based methodology often yields excellent performance. However, the methodology relies on a large training set, which is very expensive to achieve in remote sensing. The semi-supervised manifold alignment (SSMA), a multi-modal data fusion algorithm, has been designed to amplify the impact of an existing training set by linking labeled data to unlabeled data via unsupervised techniques. In this paper, we explore the potential of SSMA in fusing optical data and polarimetric SAR data, which are multi-sensory data sources. Furthermore, we propose a MAPPER-induced manifold alignment (MIMA) for semi-supervised fusion of multi-sensory data sources. Our proposed method unites SSMA with MAPPER, which is developed from the emerging topological data analysis (TDA) field. To our best knowledge, this is the first time that SSMA has been applied on fusing optical data and SAR data, and also the first time that TDA has been applied in remote sensing. The conventional SSMA derives a topological structure using k-nearest-neighbor (kNN), while MIMA employs MAPPER, which considers the field knowledge and derives a novel topological structure through the spectral clustering in a data-driven fashion. Experiment results on data fusion with respect to land cover land use classification and local climate zone classification suggest superior performance of MIMA.
Generator evaluator-selector net: a modular approach for panoptic segmentation
Aug 27, 2019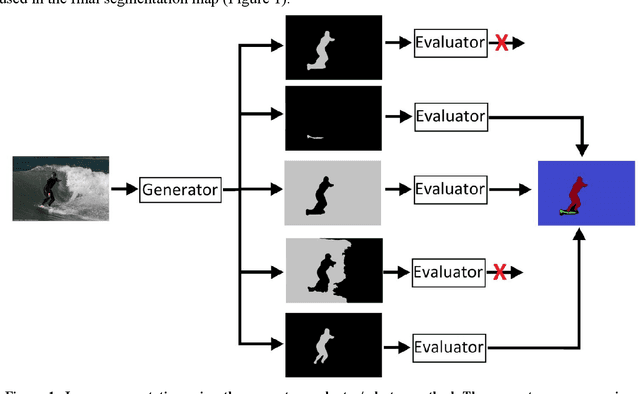
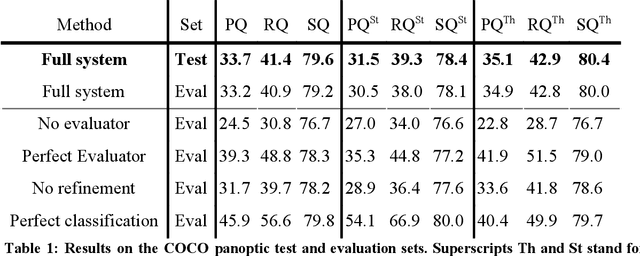
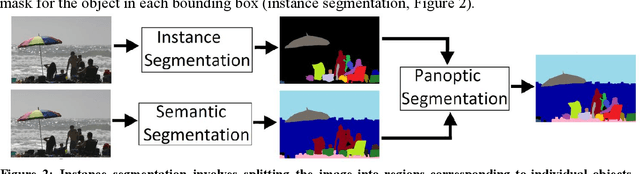
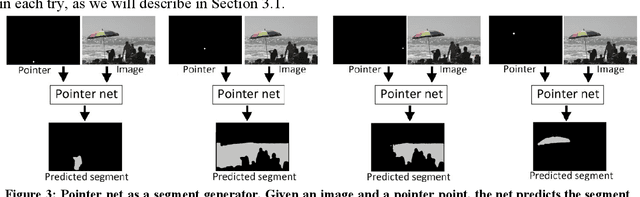
In machine learning and other fields, suggesting a good solution to a problem is usually a harder task than evaluating the quality of such a solution. This asymmetry is the basis for a large number of selection oriented methods that use a generator system to guess a set of solutions and an evaluator system to rank and select the best solutions. This work examines the use of this approach to the problem of image segmentation. The generator/evaluator approach for this case consists of two independent convolutional neural nets: a generator net that suggests variety segments corresponding to objects and distinct regions in the image and an evaluator net that chooses the best segments to be merged into the segmentation map. The result is a trial and error evolutionary approach in which a generator that guesses segments with low average accuracy, but with wide variability, can still produce good results when coupled with an accurate evaluator. Generating and evaluating each segment separately is essential in this case since it demands exponentially fewer guesses compared to a system that guesses and evaluates the full segmentation map in each try. Another form of modularity used in this system is separating the segmentation and classification into independent neural nets. This allows the segmentation to be class agnostic and hence capable of segmenting unfamiliar categories that were not part of the training set. The method was examined on the COCO Panoptic segmentation benchmark and gave competitive results to the standard semantic segmentation and instance segmentation methods.
Refine and Distill: Exploiting Cycle-Inconsistency and Knowledge Distillation for Unsupervised Monocular Depth Estimation
Mar 11, 2019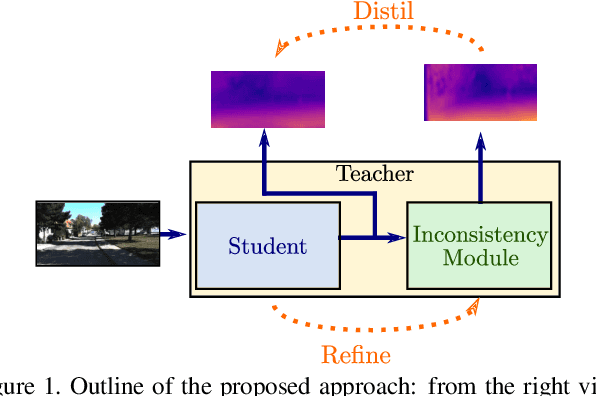
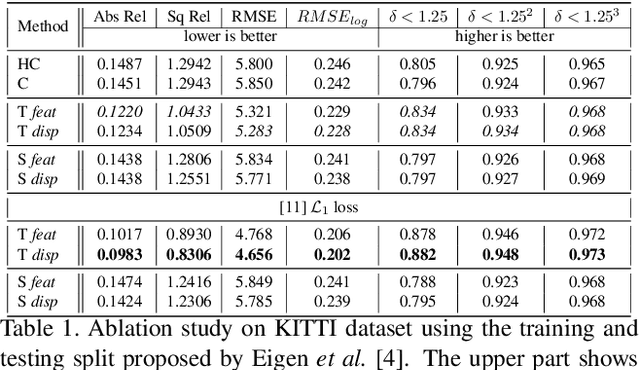
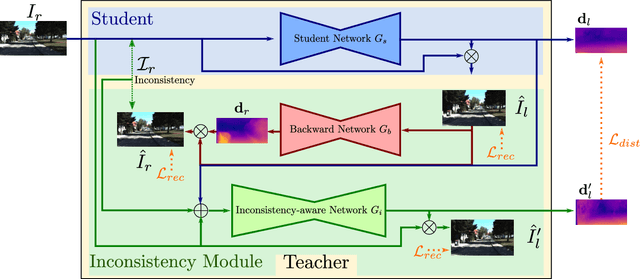
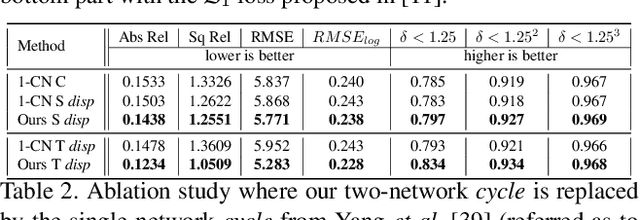
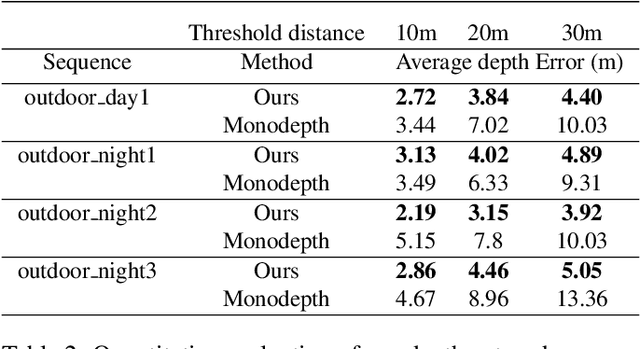
Nowadays, the majority of state of the art monocular depth estimation techniques are based on supervised deep learning models. However, collecting RGB images with associated depth maps is a very time consuming procedure. Therefore, recent works have proposed deep architectures for addressing the monocular depth prediction task as a reconstruction problem, thus avoiding the need of collecting ground-truth depth. Following these works, we propose a novel self-supervised deep model for estimating depth maps. Our framework exploits two main strategies: refinement via cycle-inconsistency and distillation. Specifically, first a \emph{student} network is trained to predict a disparity map such as to recover from a frame in a camera view the associated image in the opposite view. Then, a backward cycle network is applied to the generated image to re-synthesize back the input image, estimating the opposite disparity. A third network exploits the inconsistency between the original and the reconstructed input frame in order to output a refined depth map. Finally, knowledge distillation is exploited, such as to transfer information from the refinement network to the student. Our extensive experimental evaluation demonstrate the effectiveness of the proposed framework which outperforms state of the art unsupervised methods on the KITTI benchmark.
Fast Compressive Sensing Recovery Using Generative Models with Structured Latent Variables
Feb 22, 2019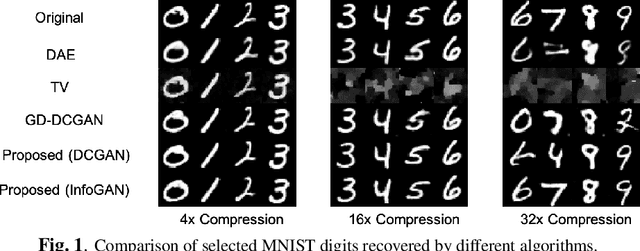
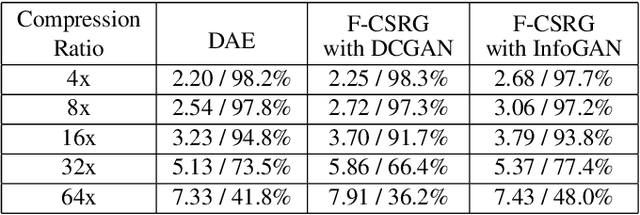

Deep learning models have significantly improved the visual quality and accuracy on compressive sensing recovery. In this paper, we propose an algorithm for signal reconstruction from compressed measurements with image priors captured by a generative model. We search and constrain on latent variable space to make the method stable when the number of compressed measurements is extremely limited. We show that, by exploiting certain structures of the latent variables, the proposed method produces improved reconstruction accuracy and preserves realistic and non-smooth features in the image. Our algorithm achieves high computation speed by projecting between the original signal space and the latent variable space in an alternating fashion.
Boosting Network Weight Separability via Feed-Backward Reconstruction
Oct 20, 2019

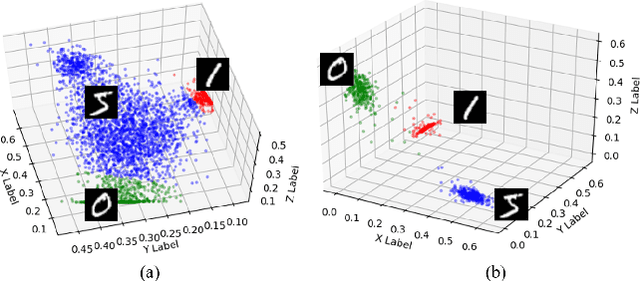
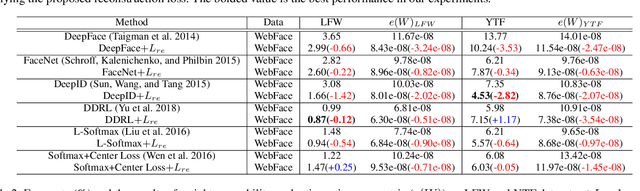
This paper proposes a new evaluation metric and boosting method for weight separability in neural network design. In contrast to general visual recognition methods designed to encourage both intra-class compactness and inter-class separability of latent features, we focus on estimating linear independence of column vectors in weight matrix and improving the separability of weight vectors. To this end, we propose an evaluation metric for weight separability based on semi-orthogonality of a matrix and Frobenius distance, and the feed-backward reconstruction loss which explicitly encourages weight separability between the column vectors in the weight matrix. The experimental results on image classification and face recognition demonstrate that the weight separability boosting via minimization of feed-backward reconstruction loss can improve the visual recognition performance, hence universally boosting the performance on various visual recognition tasks.
Unsupervised Event-based Learning of Optical Flow, Depth, and Egomotion
Dec 19, 2018
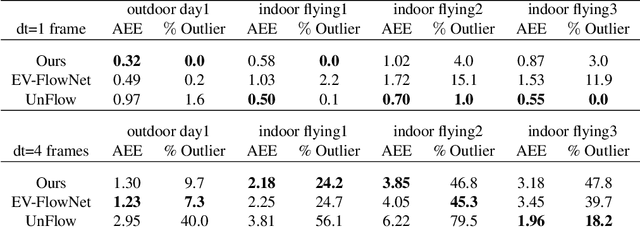
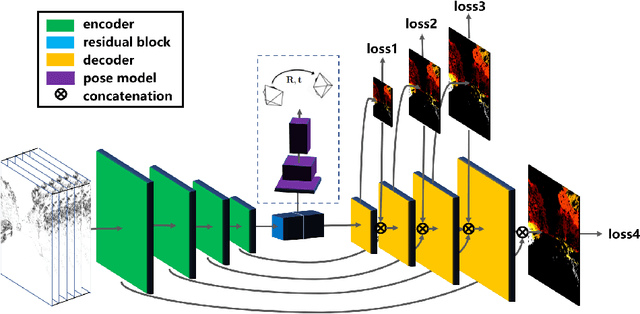
In this work, we propose a novel framework for unsupervised learning for event cameras that learns motion information from only the event stream. In particular, we propose an input representation of the events in the form of a discretized volume that maintains the temporal distribution of the events, which we pass through a neural network to predict the motion of the events. This motion is used to attempt to remove any motion blur in the event image. We then propose a loss function applied to the motion compensated event image that measures the motion blur in this image. We train two networks with this framework, one to predict optical flow, and one to predict egomotion and depths, and evaluate these networks on the Multi Vehicle Stereo Event Camera dataset, along with qualitative results from a variety of different scenes.
Learning beamforming in ultrasound imaging
Dec 19, 2018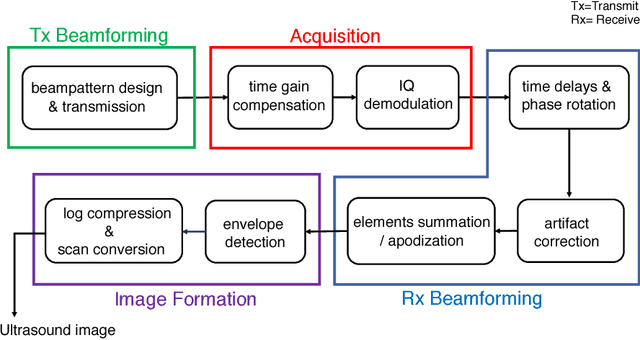
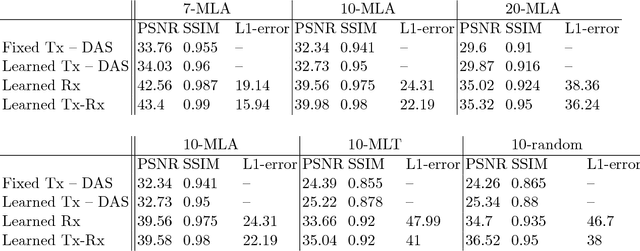
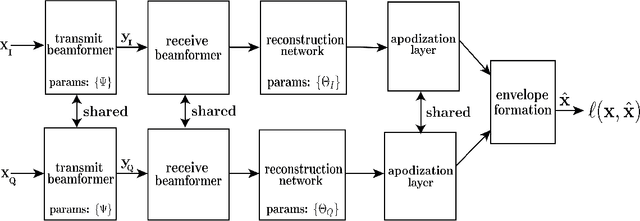

Medical ultrasound (US) is a widespread imaging modality owing its popularity to cost efficiency, portability, speed, and lack of harmful ionizing radiation. In this paper, we demonstrate that replacing the traditional ultrasound processing pipeline with a data-driven, learnable counterpart leads to significant improvement in image quality. Moreover, we demonstrate that greater improvement can be achieved through a learning-based design of the transmitted beam patterns simultaneously with learning an image reconstruction pipeline. We evaluate our method on an in-vivo first-harmonic cardiac ultrasound dataset acquired from volunteers and demonstrate the significance of the learned pipeline and transmit beam patterns on the image quality when compared to standard transmit and receive beamformers used in high frame-rate US imaging. We believe that the presented methodology provides a fundamentally different perspective on the classical problem of ultrasound beam pattern design.
Semi-Supervised Learning using Differentiable Reasoning
Aug 13, 2019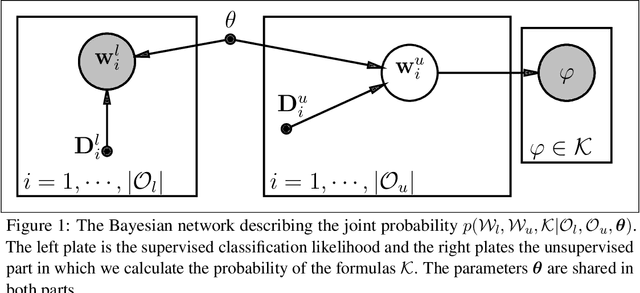
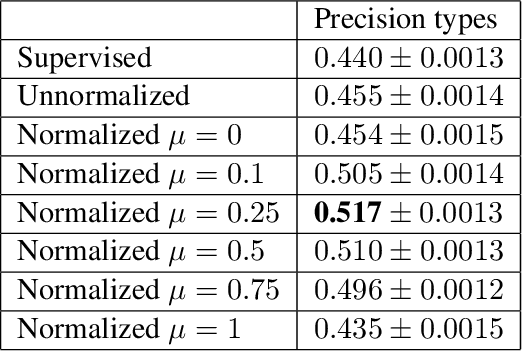


We introduce Differentiable Reasoning (DR), a novel semi-supervised learning technique which uses relational background knowledge to benefit from unlabeled data. We apply it to the Semantic Image Interpretation (SII) task and show that background knowledge provides significant improvement. We find that there is a strong but interesting imbalance between the contributions of updates from Modus Ponens (MP) and its logical equivalent Modus Tollens (MT) to the learning process, suggesting that our approach is very sensitive to a phenomenon called the Raven Paradox. We propose a solution to overcome this situation.
Analysis Dictionary Learning: An Efficient and Discriminative Solution
Mar 07, 2019
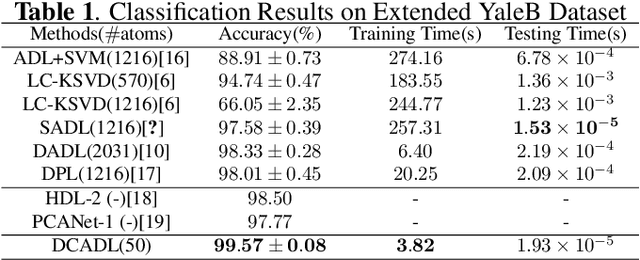
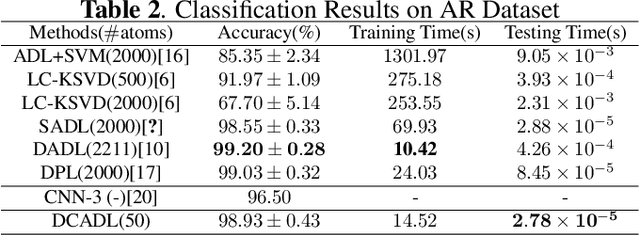

Discriminative Dictionary Learning (DL) methods have been widely advocated for image classification problems. To further sharpen their discriminative capabilities, most state-of-the-art DL methods have additional constraints included in the learning stages. These various constraints, however, lead to additional computational complexity. We hence propose an efficient Discriminative Convolutional Analysis Dictionary Learning (DCADL) method, as a lower cost Discriminative DL framework, to both characterize the image structures and refine the interclass structure representations. The proposed DCADL jointly learns a convolutional analysis dictionary and a universal classifier, while greatly reducing the time complexity in both training and testing phases, and achieving a competitive accuracy, thus demonstrating great performance in many experiments with standard databases.