 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multiplierless 16-point DCT Approximation for Low-complexity Image and Video Coding
Jun 23, 2016
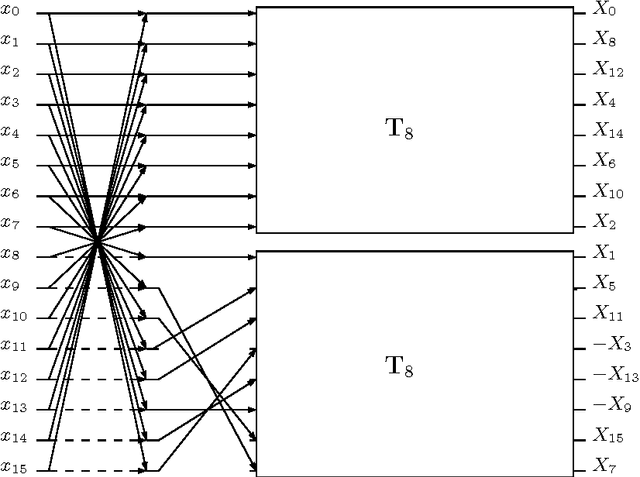
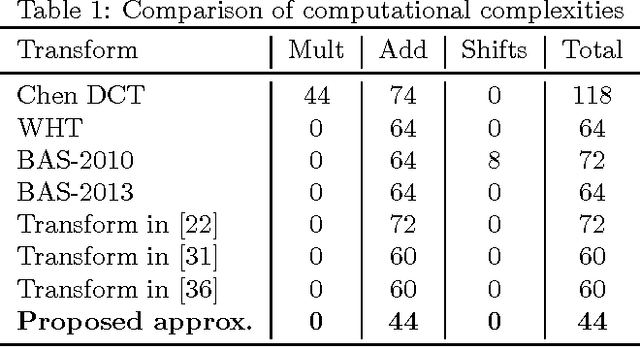
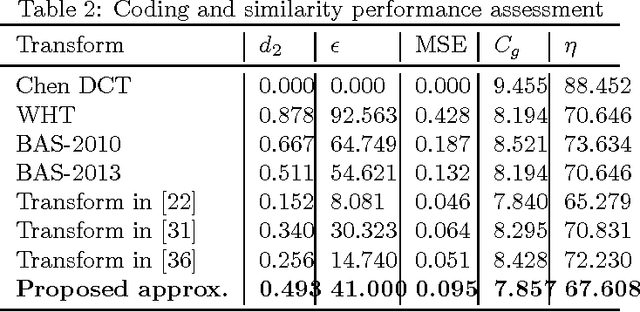
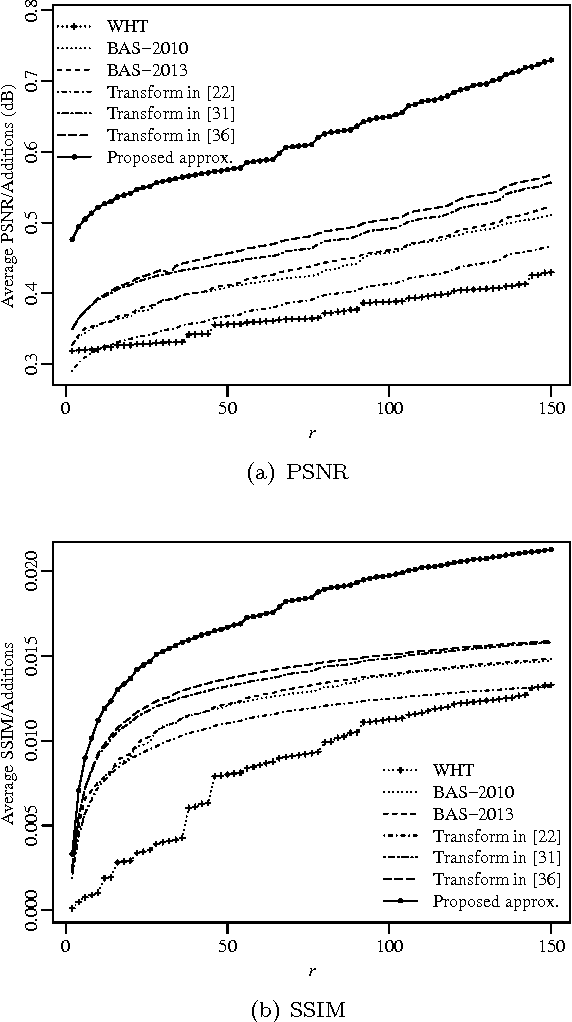
An orthogonal 16-point approximate discrete cosine transform (DCT) is introduced. The proposed transform requires neither multiplications nor bit-shifting operations. A fast algorithm based on matrix factorization is introduced, requiring only 44 additions---the lowest arithmetic cost in literature. To assess the introduced transform, computational complexity, similarity with the exact DCT, and coding performance measures are computed. Classical and state-of-the-art 16-point low-complexity transforms were used in a comparative analysis. In the context of image compression, the proposed approximation was evaluated via PSNR and SSIM measurements, attaining the best cost-benefit ratio among the competitors. For video encoding, the proposed approximation was embedded into a HEVC reference software for direct comparison with the original HEVC standard. Physically realized and tested using FPGA hardware, the proposed transform showed 35% and 37% improvements of area-time and area-time-squared VLSI metrics when compared to the best competing transform in the literature.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020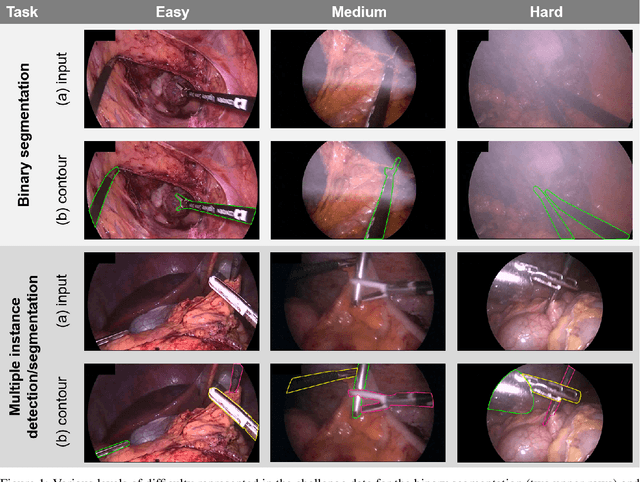
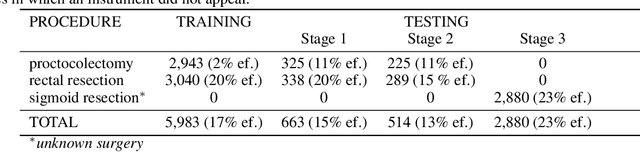
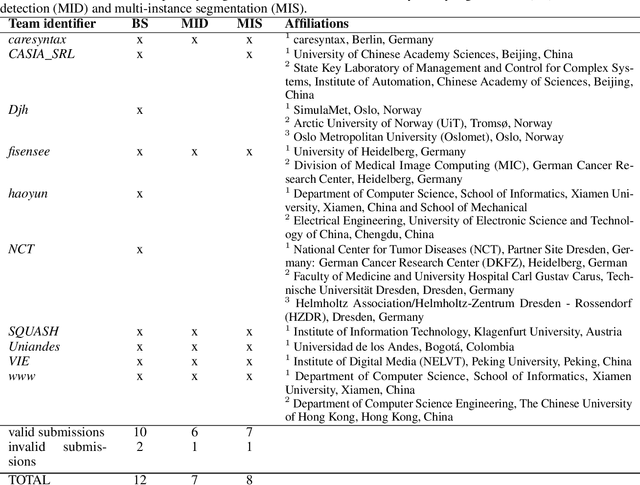
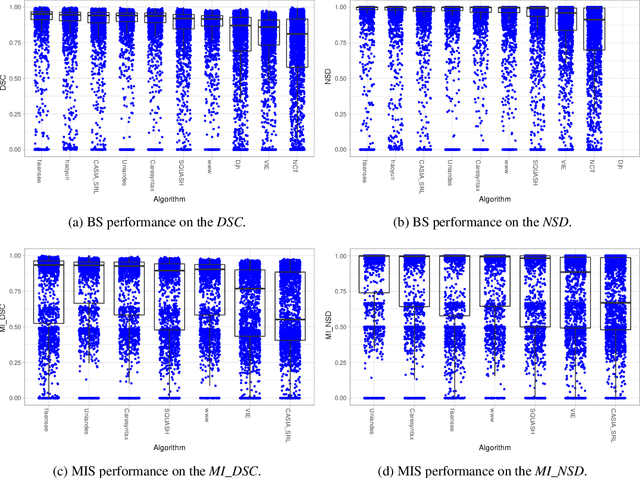
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).
Stories for Images-in-Sequence by using Visual and Narrative Components
Sep 22, 2018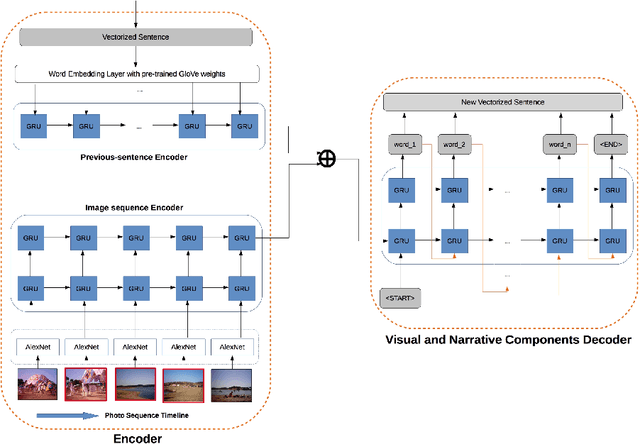
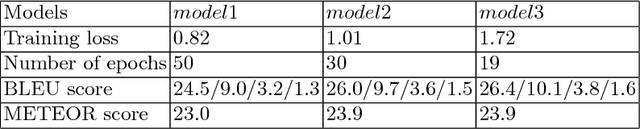
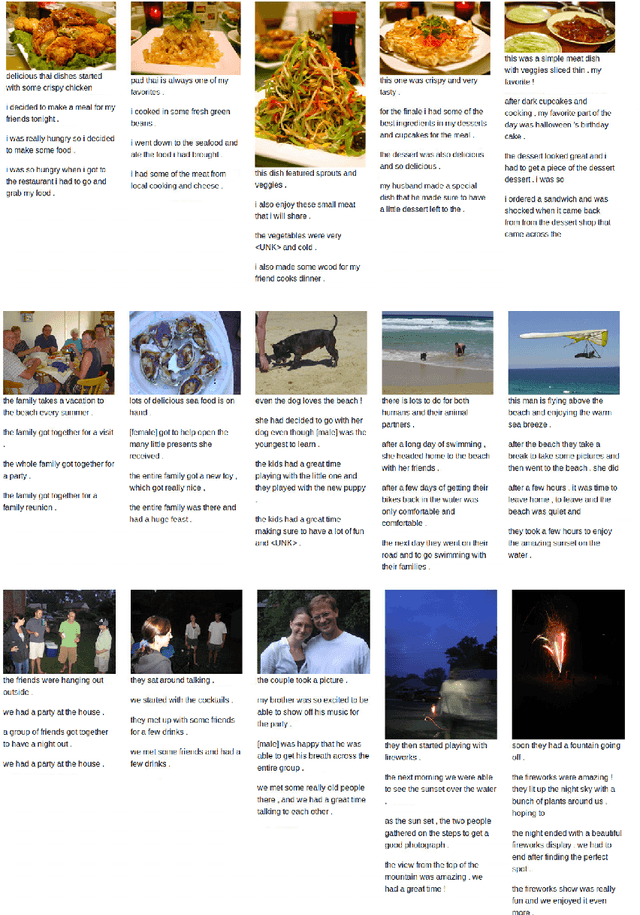
Recent research in AI is focusing towards generating narrative stories about visual scenes. It has the potential to achieve more human-like understanding than just basic description generation of images- in-sequence. In this work, we propose a solution for generating stories for images-in-sequence that is based on the Sequence to Sequence model. As a novelty, our encoder model is composed of two separate encoders, one that models the behaviour of the image sequence and other that models the sentence-story generated for the previous image in the sequence of images. By using the image sequence encoder we capture the temporal dependencies between the image sequence and the sentence-story and by using the previous sentence-story encoder we achieve a better story flow. Our solution generates long human-like stories that not only describe the visual context of the image sequence but also contains narrative and evaluative language. The obtained results were confirmed by manual human evaluation.
* 12 pages, 4 figures, ICT Innovations 2018
An empirical study of pretrained representations for few-shot classification
Oct 03, 2019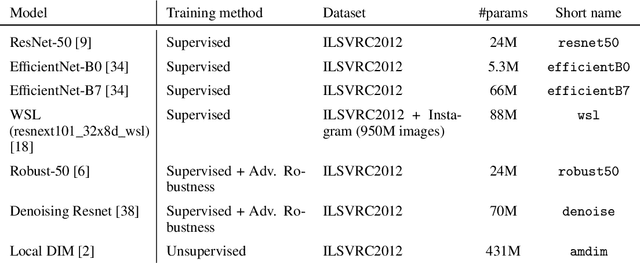
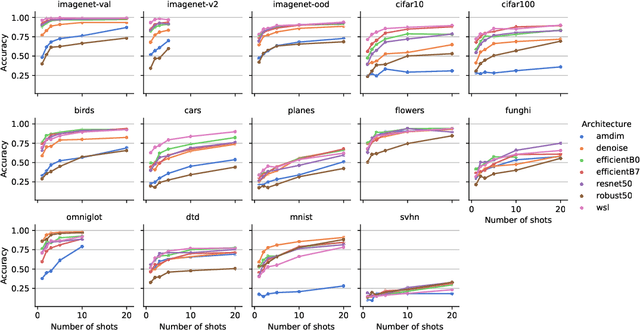
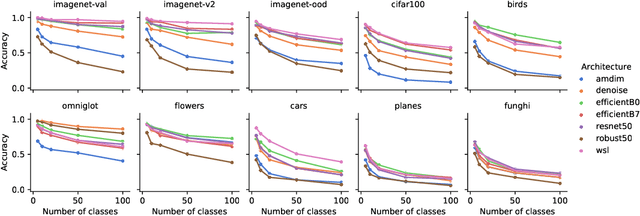
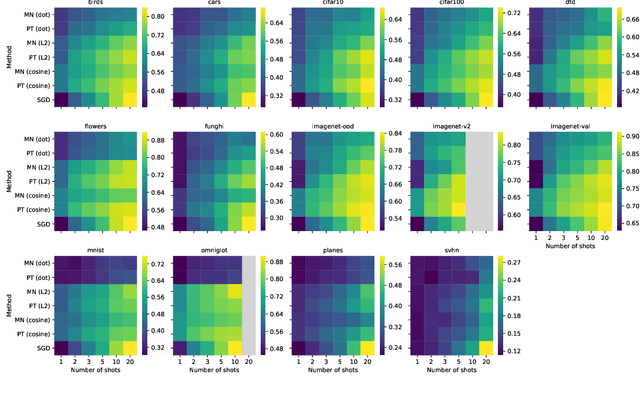
Recent algorithms with state-of-the-art few-shot classification results start their procedure by computing data features output by a large pretrained model. In this paper we systematically investigate which models provide the best representations for a few-shot image classification task when pretrained on the Imagenet dataset. We test their representations when used as the starting point for different few-shot classification algorithms. We observe that models trained on a supervised classification task have higher performance than models trained in an unsupervised manner even when transferred to out-of-distribution datasets. Models trained with adversarial robustness transfer better, while having slightly lower accuracy than supervised models.
An adversarial learning framework for preserving users' anonymity in face-based emotion recognition
Jan 16, 2020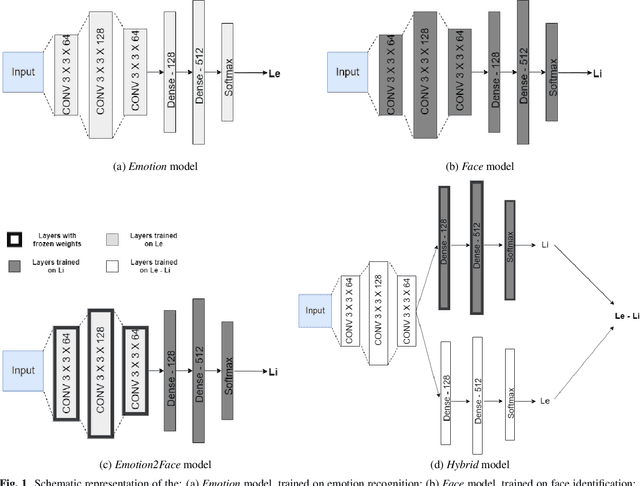
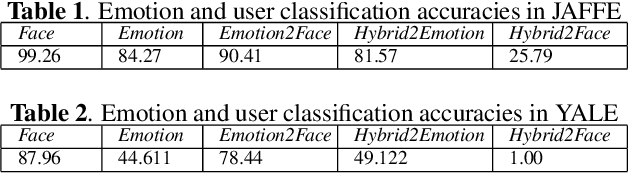
Image and video-capturing technologies have permeated our every-day life. Such technologies can continuously monitor individuals' expressions in real-life settings, affording us new insights into their emotional states and transitions, thus paving the way to novel well-being and healthcare applications. Yet, due to the strong privacy concerns, the use of such technologies is met with strong skepticism, since current face-based emotion recognition systems relying on deep learning techniques tend to preserve substantial information related to the identity of the user, apart from the emotion-specific information. This paper proposes an adversarial learning framework which relies on a convolutional neural network (CNN) architecture trained through an iterative procedure for minimizing identity-specific information and maximizing emotion-dependent information. The proposed approach is evaluated through emotion classification and face identification metrics, and is compared against two CNNs, one trained solely for emotion recognition and the other trained solely for face identification. Experiments are performed using the Yale Face Dataset and Japanese Female Facial Expression Database. Results indicate that the proposed approach can learn a convolutional transformation for preserving emotion recognition accuracy and degrading face identity recognition, providing a foundation toward privacy-aware emotion recognition technologies.
Evolution Attack On Neural Networks
Jun 21, 2019
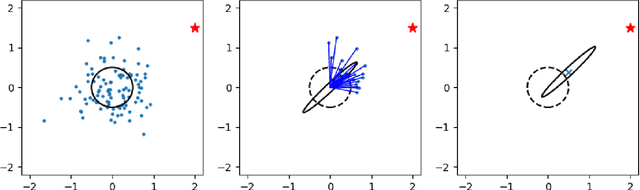
Many studies have been done to prove the vulnerability of neural networks to adversarial example. A trained and well-behaved model can be fooled by a visually imperceptible perturbation, i.e., an originally correctly classified image could be misclassified after a slight perturbation. In this paper, we propose a black-box strategy to attack such networks using an evolution algorithm. First, we formalize the generation of an adversarial example into the optimization problem of perturbations that represent the noise added to an original image at each pixel. To solve this optimization problem in a black-box way, we find that an evolution algorithm perfectly meets our requirement since it can work without any gradient information. Therefore, we test various evolution algorithms, including a simple genetic algorithm, a parameter-exploring policy gradient, an OpenAI evolution strategy, and a covariance matrix adaptive evolution strategy. Experimental results show that a covariance matrix adaptive evolution Strategy performs best in this optimization problem. Additionally, we also perform several experiments to explore the effect of different regularizations on improving the quality of an adversarial example.
Mask-CNN: Localizing Parts and Selecting Descriptors for Fine-Grained Image Recognition
May 23, 2016
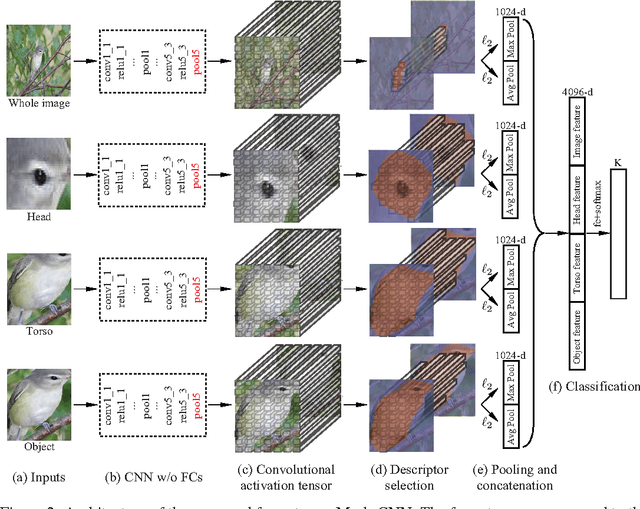
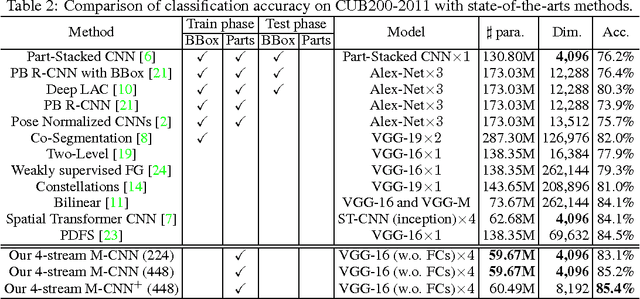
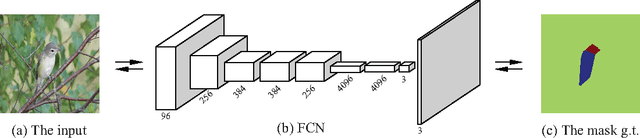
Fine-grained image recognition is a challenging computer vision problem, due to the small inter-class variations caused by highly similar subordinate categories, and the large intra-class variations in poses, scales and rotations. In this paper, we propose a novel end-to-end Mask-CNN model without the fully connected layers for fine-grained recognition. Based on the part annotations of fine-grained images, the proposed model consists of a fully convolutional network to both locate the discriminative parts (e.g., head and torso), and more importantly generate object/part masks for selecting useful and meaningful convolutional descriptors. After that, a four-stream Mask-CNN model is built for aggregating the selected object- and part-level descriptors simultaneously. The proposed Mask-CNN model has the smallest number of parameters, lowest feature dimensionality and highest recognition accuracy when compared with state-of-the-arts fine-grained approaches.
Unbiased Scene Graph Generation via Rich and Fair Semantic Extraction
Feb 01, 2020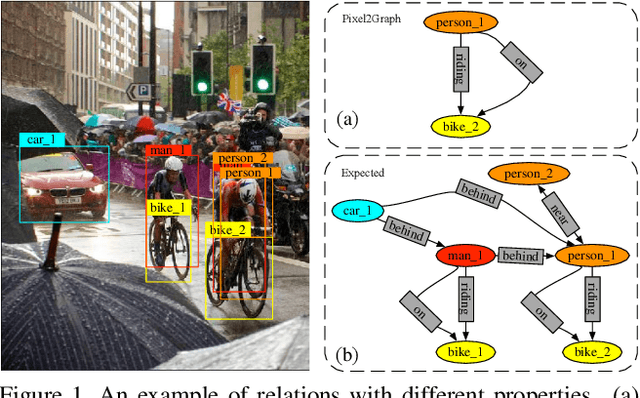
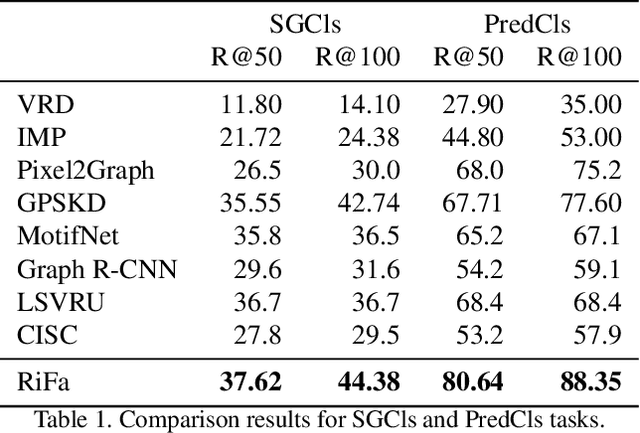
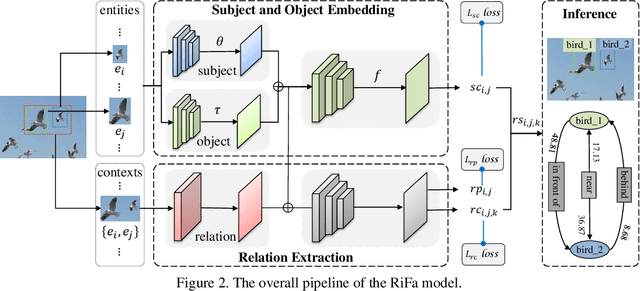
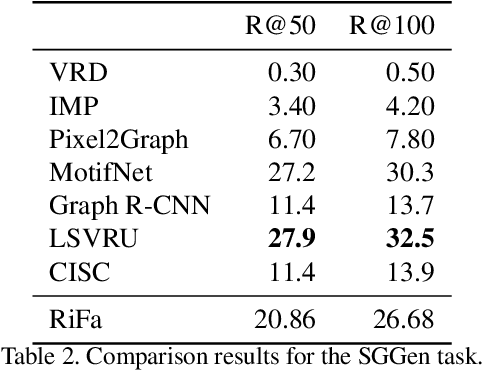
Extracting graph representation of visual scenes in image is a challenging task in computer vision. Although there has been encouraging progress of scene graph generation in the past decade, we surprisingly find that the performance of existing approaches is largely limited by the strong biases, which mainly stem from (1) unconsciously assuming relations with certain semantic properties such as symmetric and (2) imbalanced annotations over different relations. To alleviate the negative effects of these biases, we proposed a new and simple architecture named Rich and Fair semantic extraction network (RiFa for short), to not only capture rich semantic properties of the relations, but also fairly predict relations with different scale of annotations. Using pseudo-siamese networks, RiFa embeds the subject and object respectively to distinguish their semantic differences and meanwhile preserve their underlying semantic properties. Then, it further predicts subject-object relations based on both the visual and semantic features of entities under certain contextual area, and fairly ranks the relation predictions for those with a few annotations. Experiments on the popular Visual Genome dataset show that RiFa achieves state-of-the-art performance under several challenging settings of scene graph task. Especially, it performs significantly better on capturing different semantic properties of relations, and obtains the best overall per relation performance.
Simultaneous Detection and Removal of Dynamic Objects in Multi-view Images
Dec 11, 2019
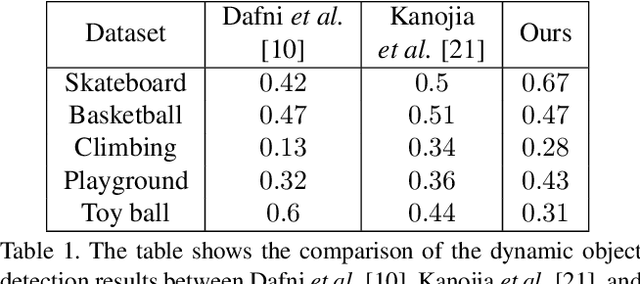


Consider a set of images of a scene consisting of moving objects captured using a hand-held camera. In this work, we propose an algorithm which takes this set of multi-view images as input, detects the dynamic objects present in the scene, and replaces them with the static regions which are being occluded by them. The proposed algorithm scans the reference image in the row-major order at the pixel level and classifies each pixel as static or dynamic. During the scan, when a pixel is classified as dynamic, the proposed algorithm replaces that pixel value with the corresponding pixel value of the static region which is being occluded by that dynamic region. We show that we achieve artifact-free removal of dynamic objects in multi-view images of several real-world scenes. To the best of our knowledge, we propose the first method which simultaneously detects and removes the dynamic objects present in multi-view images.
Image-based Vehicle Classification System
Apr 10, 2012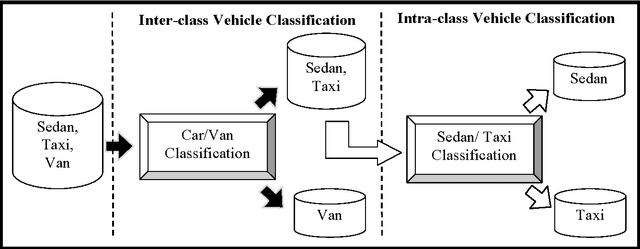
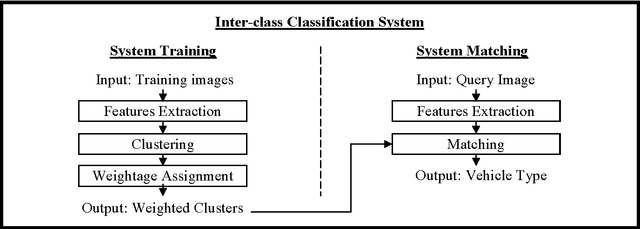
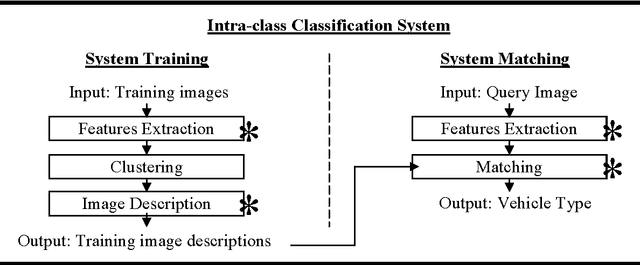
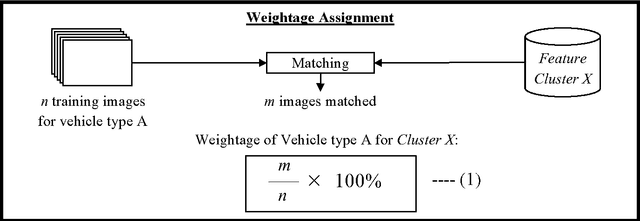
Electronic toll collection (ETC) system has been a common trend used for toll collection on toll road nowadays. The implementation of electronic toll collection allows vehicles to travel at low or full speed during the toll payment, which help to avoid the traffic delay at toll road. One of the major components of an electronic toll collection is the automatic vehicle detection and classification (AVDC) system which is important to classify the vehicle so that the toll is charged according to the vehicle classes. Vision-based vehicle classification system is one type of vehicle classification system which adopt camera as the input sensing device for the system. This type of system has advantage over the rest for it is cost efficient as low cost camera is used. The implementation of vision-based vehicle classification system requires lower initial investment cost and very suitable for the toll collection trend migration in Malaysia from single ETC system to full-scale multi-lane free flow (MLFF). This project includes the development of an image-based vehicle classification system as an effort to seek for a robust vision-based vehicle classification system. The techniques used in the system include scale-invariant feature transform (SIFT) technique, Canny's edge detector, K-means clustering as well as Euclidean distance matching. In this project, a unique way to image description as matching medium is proposed. This distinctiveness of method is analogous to the human DNA concept which is highly unique. The system is evaluated on open datasets and return promising results.