 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Retinal Vessel Segmentation based on Fully Convolutional Networks
Nov 22, 2019
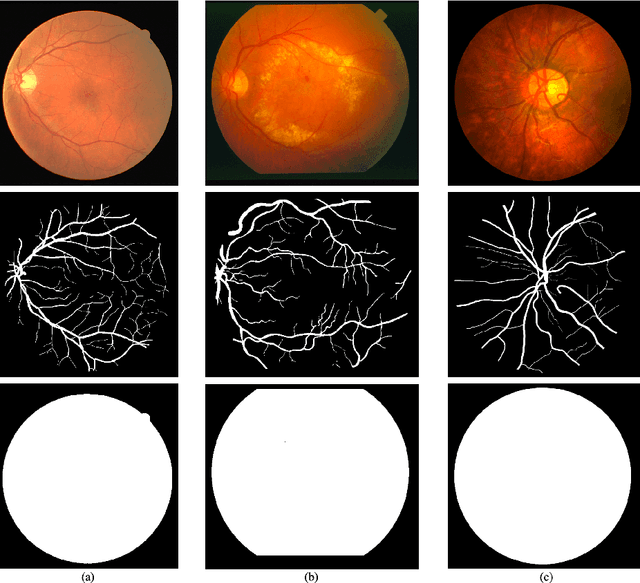
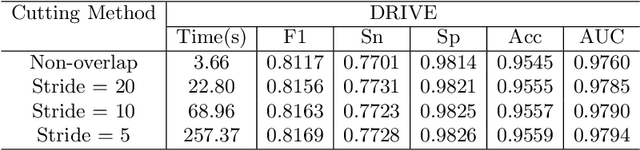
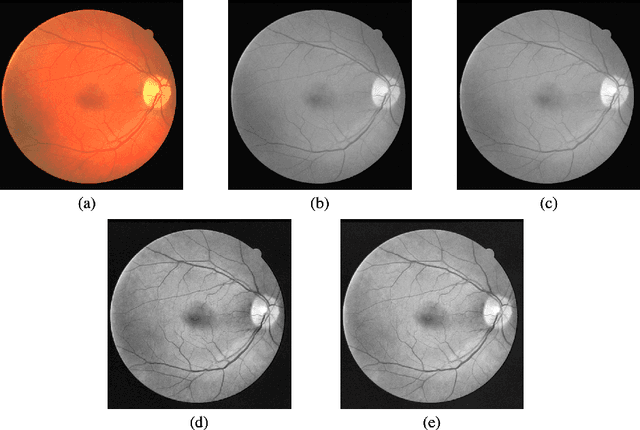
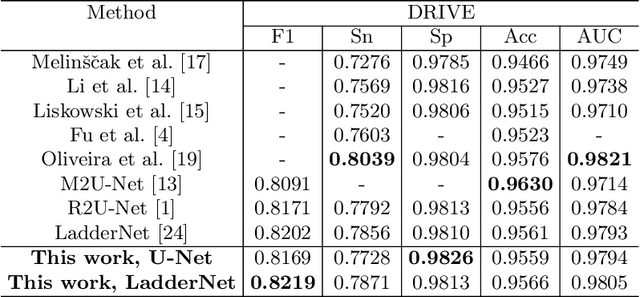
The morphological attributes of retinal vessels, such as length, width, tortuosity and branching pattern and angles, play an important role in diagnosis, screening, treatment, and evaluation of various cardiovascular and ophthalmologic diseases such as diabetes, hypertension and arteriosclerosis. The crucial step before extracting these morphological characteristics of retinal vessels from retinal fundus images is vessel segmentation. In this work, we propose a method for retinal vessel segmentation based on fully convolutional networks. Thousands of patches are extracted from each retinal image and then fed into the network, and data argumentation is applied by rotating extracted patches. Two architectures of fully convolutional networks, U-Net and LadderNet, are used for vessel segmentation. The performance of our method is evaluated on three public datasets: DRIVE, STARE, and CHASE\_DB1. Experimental results of our method show superior performance compared to recent state-of-the-art methods.
Gesture-to-Gesture Translation in the Wild via Category-Independent Conditional Maps
Jul 31, 2019
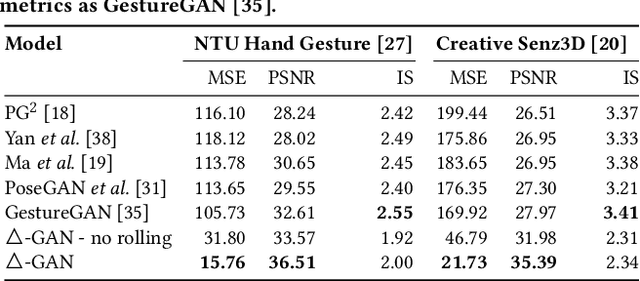
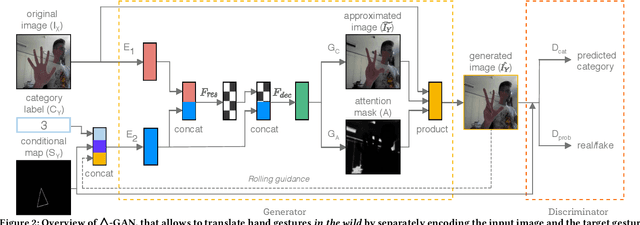
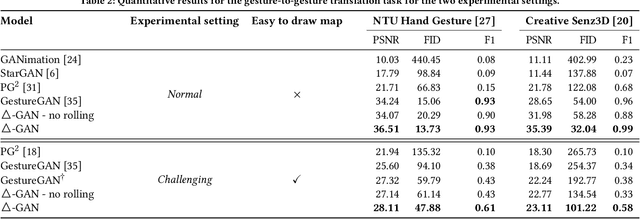
Recent works have shown Generative Adversarial Networks (GANs) to be particularly effective in image-to-image translations. However, in tasks such as body pose and hand gesture translation, existing methods usually require precise annotations, e.g. key-points or skeletons, which are time-consuming to draw. In this work, we propose a novel GAN architecture that decouples the required annotations into a category label - that specifies the gesture type - and a simple-to-draw category-independent conditional map - that expresses the location, rotation and size of the hand gesture. Our architecture synthesizes the target gesture while preserving the background context, thus effectively dealing with gesture translation in the wild. To this aim, we use an attention module and a rolling guidance approach, which loops the generated images back into the network and produces higher quality images compared to competing works. Thus, our GAN learns to generate new images from simple annotations without requiring key-points or skeleton labels. Results on two public datasets show that our method outperforms state of the art approaches both quantitatively and qualitatively. To the best of our knowledge, no work so far has addressed the gesture-to-gesture translation in the wild by requiring user-friendly annotations.
Grand Challenge of 106-Point Facial Landmark Localization
May 09, 2019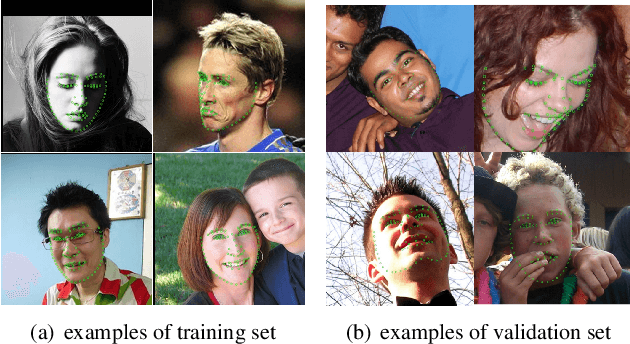
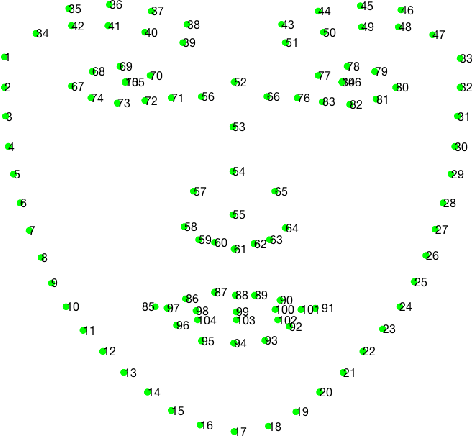

Facial landmark localization is a very crucial step in numerous face related applications, such as face recognition, facial pose estimation, face image synthesis, etc. However, previous competitions on facial landmark localization (i.e., the 300-W, 300-VW and Menpo challenges) aim to predict 68-point landmarks, which are incompetent to depict the structure of facial components. In order to overcome this problem, we construct a challenging dataset, named JD-landmark. Each image is manually annotated with 106-point landmarks. This dataset covers large variations on pose and expression, which brings a lot of difficulties to predict accurate landmarks. We hold a 106-point facial landmark localization competition1 on this dataset in conjunction with IEEE International Conference on Multimedia and Expo (ICME) 2019. The purpose of this competition is to discover effective and robust facial landmark localization approaches.
FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping
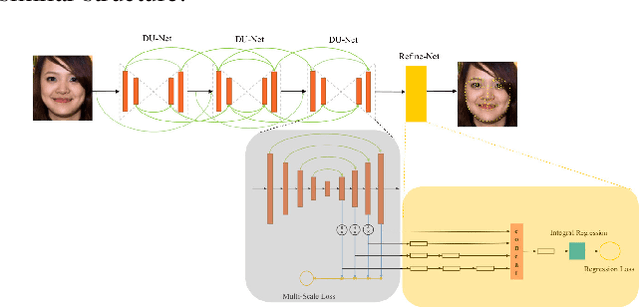
Dec 31, 2019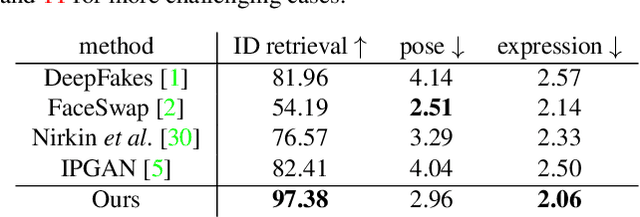


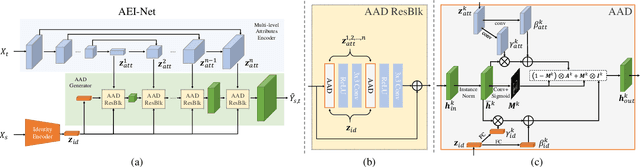
In this work, we propose a novel two-stage framework, called FaceShifter, for high fidelity and occlusion aware face swapping. Unlike many existing face swapping works that leverage only limited information from the target image when synthesizing the swapped face, our framework, in its first stage, generates the swapped face in high-fidelity by exploiting and integrating the target attributes thoroughly and adaptively. We propose a novel attributes encoder for extracting multi-level target face attributes, and a new generator with carefully designed Adaptive Attentional Denormalization (AAD) layers to adaptively integrate the identity and the attributes for face synthesis. To address the challenging facial occlusions, we append a second stage consisting of a novel Heuristic Error Acknowledging Refinement Network (HEAR-Net). It is trained to recover anomaly regions in a self-supervised way without any manual annotations. Extensive experiments on wild faces demonstrate that our face swapping results are not only considerably more perceptually appealing, but also better identity preserving in comparison to other state-of-the-art methods.
Improved Few-Shot Visual Classification
Dec 12, 2019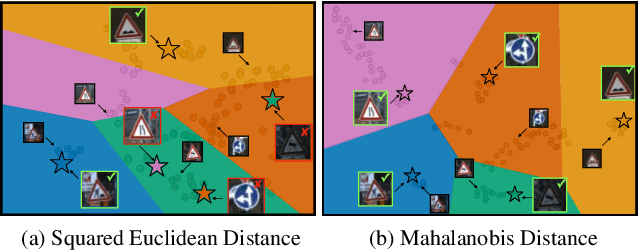

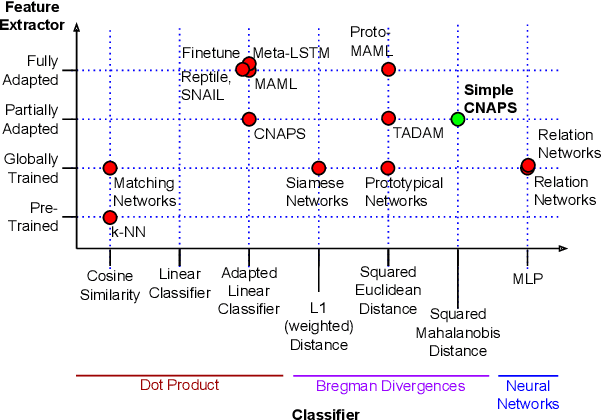

Few-shot learning is a fundamental task in computer vision that carries the promise of alleviating the need for exhaustively labeled data. Most few-shot learning approaches to date have focused on progressively more complex neural feature extractors and classifier adaptation strategies, as well as the refinement of the task definition itself. In this paper, we explore the hypothesis that a simple class-covariance-based distance metric, namely the Mahalanobis distance, adopted into a state of the art few-shot learning approach (CNAPS) can, in and of itself, lead to a significant performance improvement. We also discover that it is possible to learn adaptive feature extractors that allow useful estimation of the high dimensional feature covariances required by this metric from surprisingly few samples. The result of our work is a new "Simple CNAPS" architecture which has up to 9.2% fewer trainable parameters than CNAPS and performs up to 6.1% better than state of the art on the standard few-shot image classification benchmark dataset.
Learning Wavefront Coding for Extended Depth of Field Imaging
Dec 31, 2019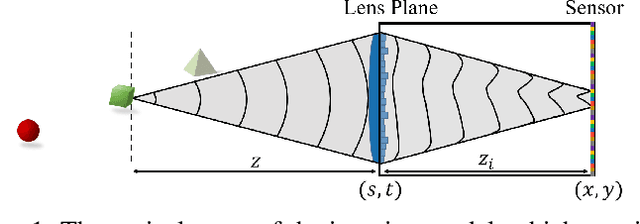

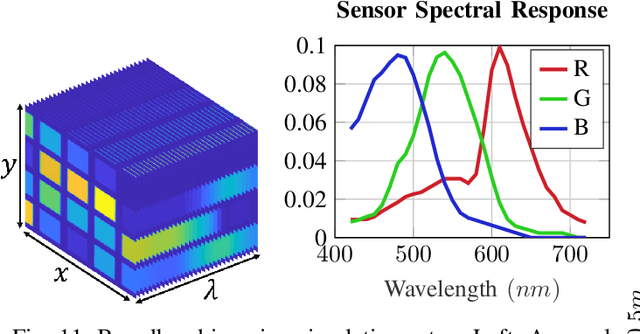

The depth of field constitutes an important quality factor of imaging systems that highly affects the content of the acquired spatial information in the captured images. Extended depth of field (EDoF) imaging is a challenging problem due to its highly ill-posed nature, hence it has been extensively addressed in the literature. We propose a computational imaging approach for EDoF, where we employ wavefront coding via a diffractive optical element (DOE) and we achieve deblurring through a convolutional neural network. Thanks to the end-to-end differentiable modeling of optical image formation and computational post-processing, we jointly optimize the optical design, i.e., DOE, and the deblurring through standard gradient descent methods. Based on the properties of the underlying refractive lens and the desired EDoF range, we provide an analytical expression for the search space of the DOE, which helps in the convergence of the end-to-end network. We achieve superior EDoF imaging performance compared to state of the art, where we demonstrate results with minimal artifacts in various scenarios, including deep 3D scenes and broadband imaging.
A Combined Deep Learning-Gradient Boosting Machine Framework for Fluid Intelligence Prediction
Oct 16, 2019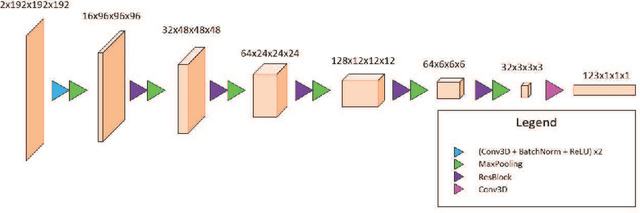
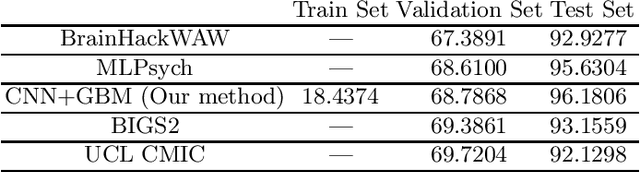

The ABCD Neurocognitive Prediction Challenge is a community driven competition asking competitors to develop algorithms to predict fluid intelligence score from T1-w MRIs. In this work, we propose a deep learning combined with gradient boosting machine framework to solve this task. We train a convolutional neural network to compress the high dimensional MRI data and learn meaningful image features by predicting the 123 continuous-valued derived data provided with each MRI. These extracted features are then used to train a gradient boosting machine that predicts the residualized fluid intelligence score. Our approach achieved mean square error (MSE) scores of 18.4374, 68.7868, and 96.1806 for the training, validation, and test set respectively.
* Challenge in Adolescent Brain Cognitive Development Neurocognitive Prediction
Robust Classification using Robust Feature Augmentation
May 31, 2019
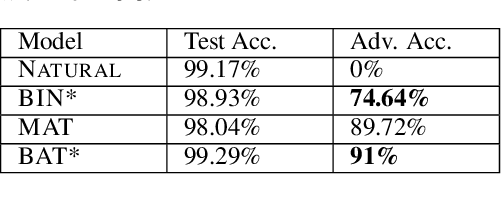
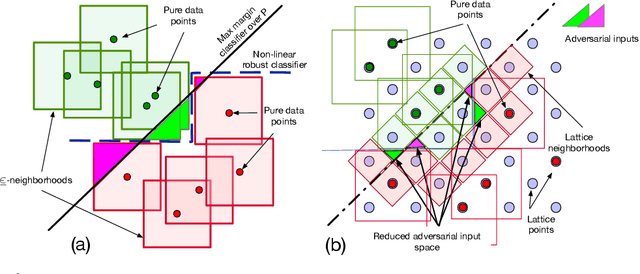

Existing deep neural networks, say for image classification, have been shown to be vulnerable to adversarial images that can cause a DNN misclassification, without any perceptible change to an image. In this work, we propose shock absorbing robust features such as binarization, e.g., rounding, and group extraction, e.g., color or shape, to augment the classification pipeline, resulting in more robust classifiers. Experimentally, we show that augmenting ML models with these techniques leads to improved overall robustness on adversarial inputs as well as significant improvements in training time. On the MNIST dataset, we achieved 14x speedup in training time to obtain 90% adversarial accuracy com-pared to the state-of-the-art adversarial training method of Madry et al., as well as retained higher adversarial accuracy over a broader range of attacks. We also find robustness improvements on traffic sign classification using robust feature augmentation. Finally, we give theoretical insights for why one can expect robust feature augmentation to reduce adversarial input space
Feature-Fused Context-Encoding Network for Neuroanatomy Segmentation
May 07, 2019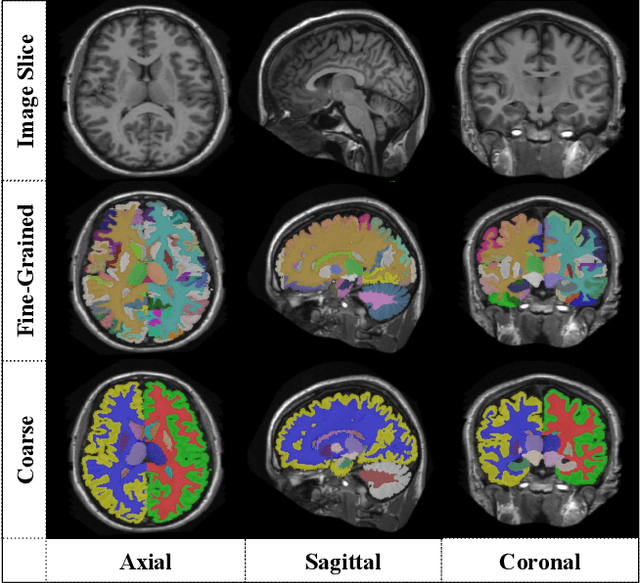
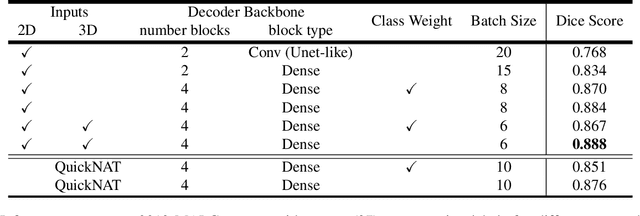
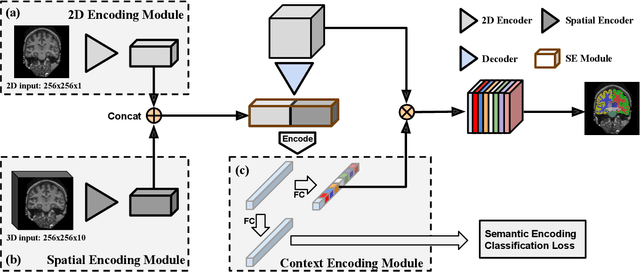
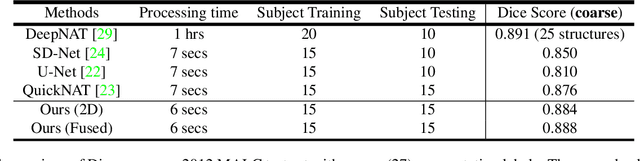
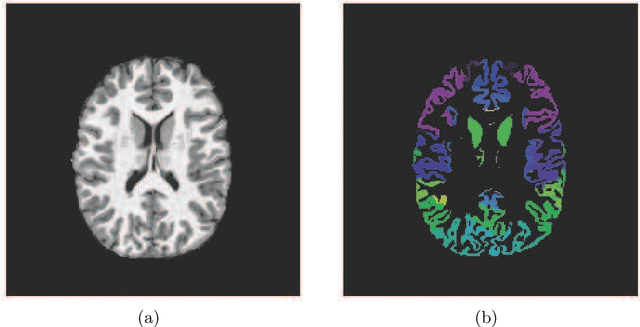
Automatic segmentation of fine-grained brain structures remains a challenging task. Current segmentation methods mainly utilize 2D and 3D deep neural networks. The 2D networks take image slices as input to produce coarse segmentation in less processing time, whereas the 3D networks take the whole image volumes to generated fine-detailed segmentation with more computational burden. In order to obtain accurate fine-grained segmentation efficiently, in this paper, we propose an end-to-end Feature-Fused Context-Encoding Network for brain structure segmentation from MR (magnetic resonance) images. Our model is implemented based on a 2D convolutional backbone, which integrates a 2D encoding module to acquire planar image features and a spatial encoding module to extract spatial context information. A global context encoding module is further introduced to capture global context semantics from the fused 2D encoding and spatial features. The proposed network aims to fully leverage the global anatomical prior knowledge learned from context semantics, which is represented by a structure-aware attention factor to recalibrate the outputs of the network. In this way, the network is guaranteed to be aware of the class-dependent feature maps to facilitate the segmentation. We evaluate our model on 2012 Brain Multi-Atlas Labelling Challenge dataset for 134 fine-grained structure segmentation. Besides, we validate our network on 27 coarse structure segmentation tasks. Experimental results have demonstrated that our model can achieve improved performance compared with the state-of-the-art approaches.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020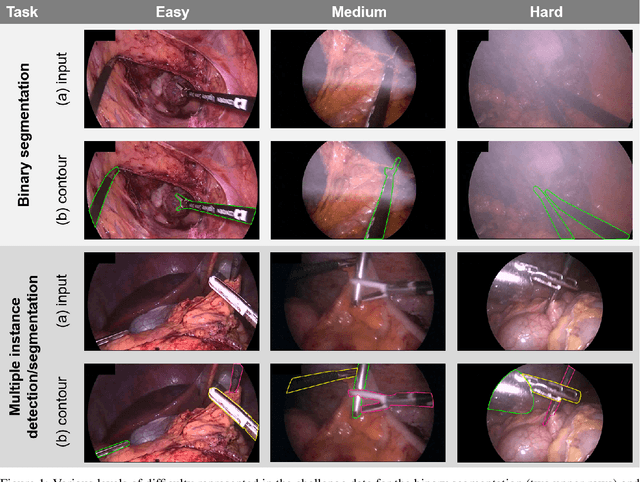
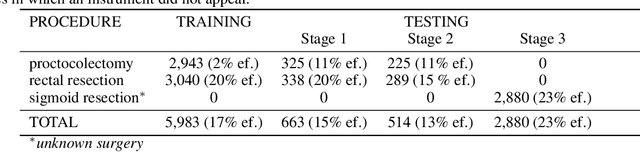
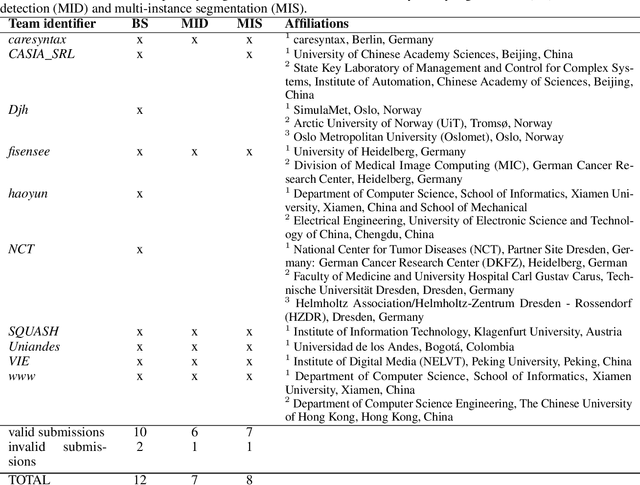
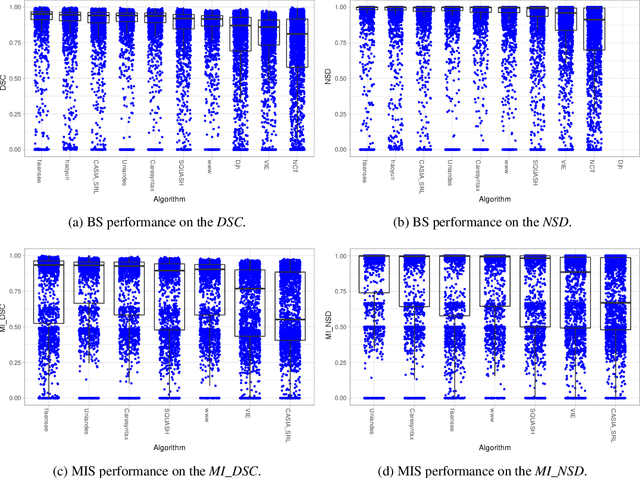
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).