 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PSF--NET: A Non-parametric Point Spread Function Model for Ground Based Optical Telescopes
Mar 02, 2020
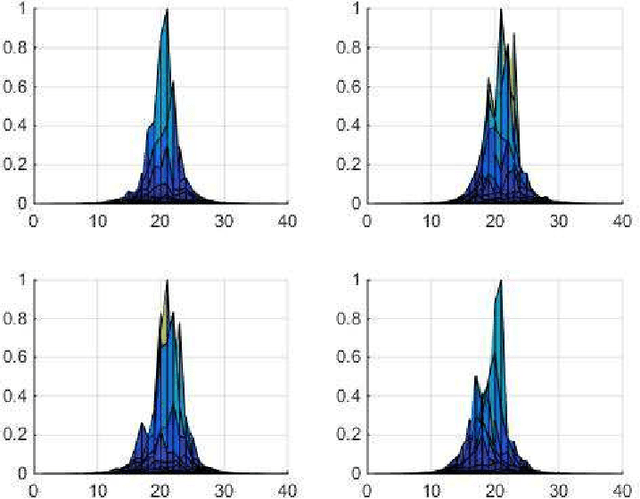
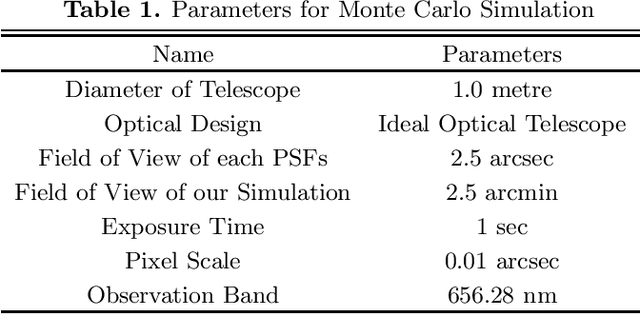
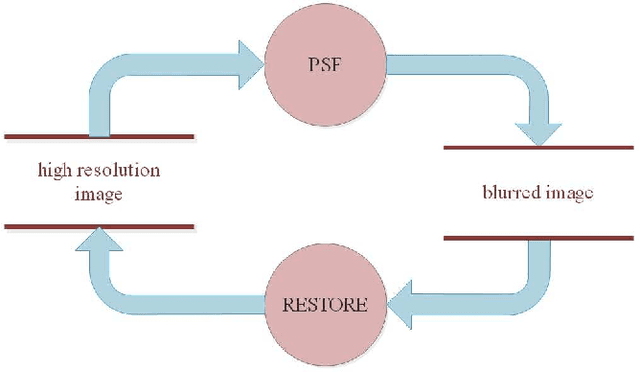
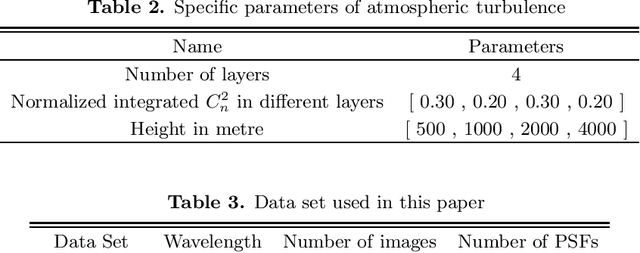
Ground based optical telescopes are seriously affected by atmospheric turbulence induced aberrations. Understanding properties of these aberrations is important both for instruments design and image restoration methods development. Because the point spread function can reflect performance of the whole optic system, it is appropriate to use the point spread function to describe atmospheric turbulence induced aberrations. Assuming point spread functions induced by the atmospheric turbulence with the same profile belong to the same manifold space, we propose a non-parametric point spread function -- PSF-NET. The PSF-NET has a cycle convolutional neural network structure and is a statistical representation of the manifold space of PSFs induced by the atmospheric turbulence with the same profile. Testing the PSF-NET with simulated and real observation data, we find that a well trained PSF--NET can restore any short exposure images blurred by atmospheric turbulence with the same profile. Besides, we further use the impulse response of the PSF-NET, which can be viewed as the statistical mean PSF, to analyze interpretation properties of the PSF-NET. We find that variations of statistical mean PSFs are caused by variations of the atmospheric turbulence profile: as the difference of the atmospheric turbulence profile increases, the difference between statistical mean PSFs also increases. The PSF-NET proposed in this paper provides a new way to analyze atmospheric turbulence induced aberrations, which would be benefit to develop new observation methods for ground based optical telescopes.
Morphological Filtering in Shape Spaces: Applications using Tree-Based Image Representations
Jul 16, 2012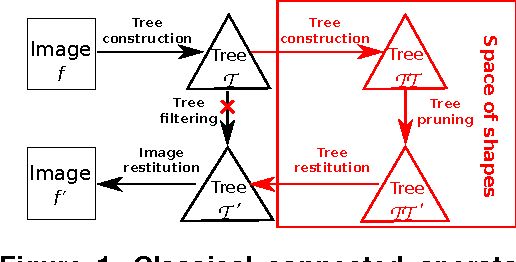

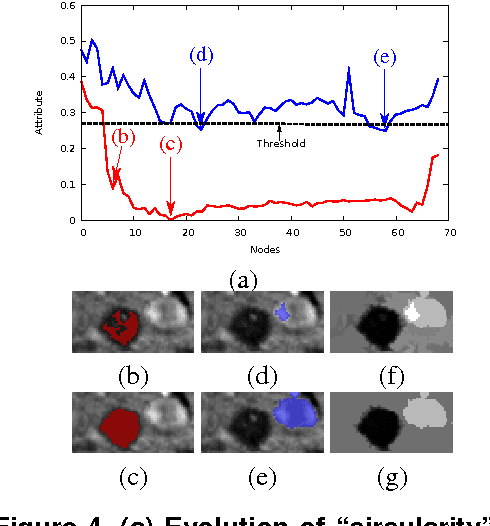
Connected operators are filtering tools that act by merging elementary regions of an image. A popular strategy is based on tree-based image representations: for example, one can compute an attribute on each node of the tree and keep only the nodes for which the attribute is sufficiently strong. This operation can be seen as a thresholding of the tree, seen as a graph whose nodes are weighted by the attribute. Rather than being satisfied with a mere thresholding, we propose to expand on this idea, and to apply connected filters on this latest graph. Consequently, the filtering is done not in the space of the image, but on the space of shapes build from the image. Such a processing is a generalization of the existing tree-based connected operators. Indeed, the framework includes classical existing connected operators by attributes. It also allows us to propose a class of novel connected operators from the leveling family, based on shape attributes. Finally, we also propose a novel class of self-dual connected operators that we call morphological shapings.
Deep Learning and Control Algorithms of Direct Perception for Autonomous Driving
Nov 12, 2019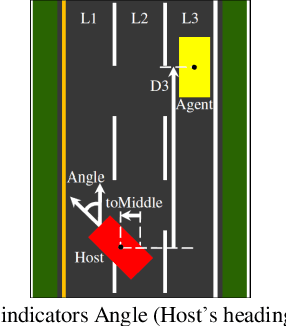
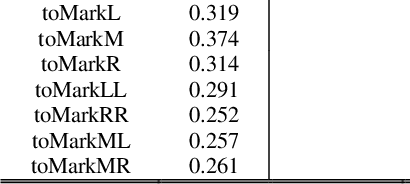
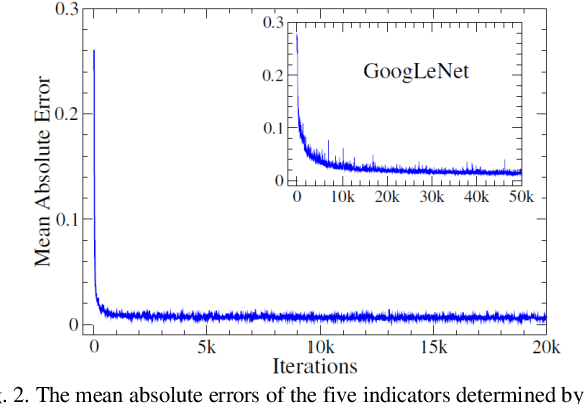

Based on the direct perception paradigm of autonomous driving, we investigate and modify the CNNs (convolutional neural networks) AlexNet and GoogLeNet that map an input image to few perception indicators (heading angle, distances to preceding cars, and distance to road centerline) for estimating driving affordances in highway traffic. We also design a controller with these indicators and the short-range sensor information of TORCS (the open racing car simulator) for driving simulated cars to avoid collisions. We collect a set of images from a TORCS camera in various driving scenarios, train these CNNs using the dataset, test them in unseen traffics, and find that they perform better than earlier algorithms and controllers in terms of training efficiency and driving stability. Source code and data are available on our website.
Understanding the Limitations of CNN-based Absolute Camera Pose Regression
Mar 18, 2019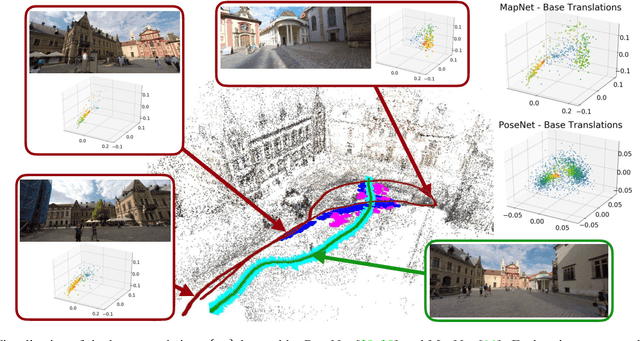

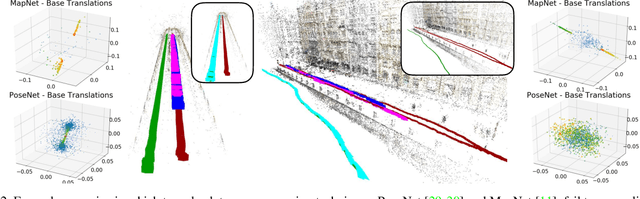
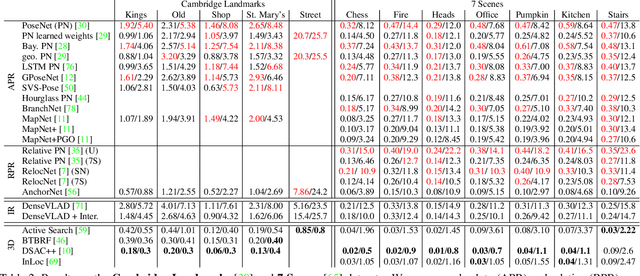
Visual localization is the task of accurate camera pose estimation in a known scene. It is a key problem in computer vision and robotics, with applications including self-driving cars, Structure-from-Motion, SLAM, and Mixed Reality. Traditionally, the localization problem has been tackled using 3D geometry. Recently, end-to-end approaches based on convolutional neural networks have become popular. These methods learn to directly regress the camera pose from an input image. However, they do not achieve the same level of pose accuracy as 3D structure-based methods. To understand this behavior, we develop a theoretical model for camera pose regression. We use our model to predict failure cases for pose regression techniques and verify our predictions through experiments. We furthermore use our model to show that pose regression is more closely related to pose approximation via image retrieval than to accurate pose estimation via 3D structure. A key result is that current approaches do not consistently outperform a handcrafted image retrieval baseline. This clearly shows that additional research is needed before pose regression algorithms are ready to compete with structure-based methods.
Quantum Semantic Learning by Reverse Annealing an Adiabatic Quantum Computer
Mar 25, 2020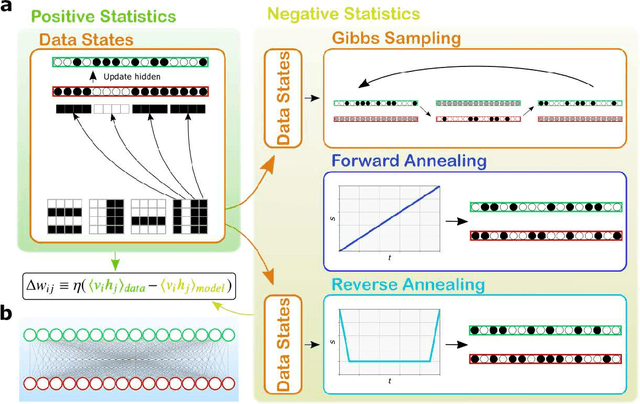
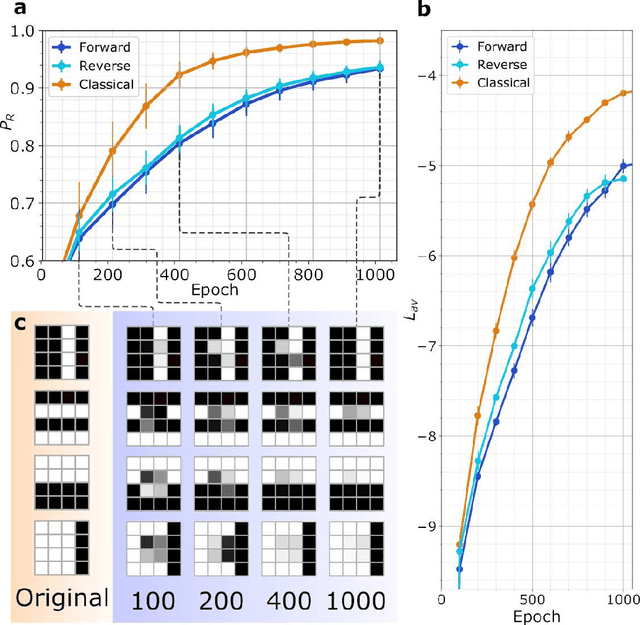
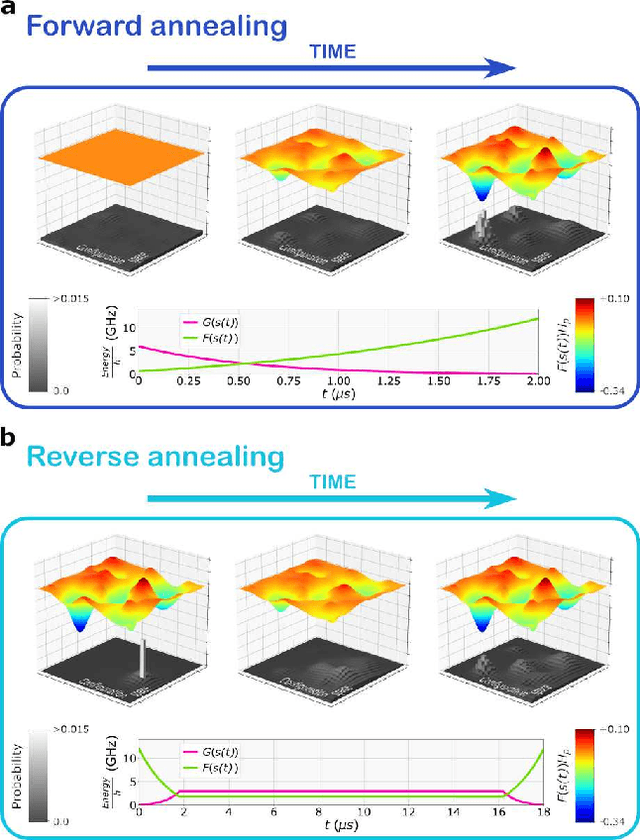
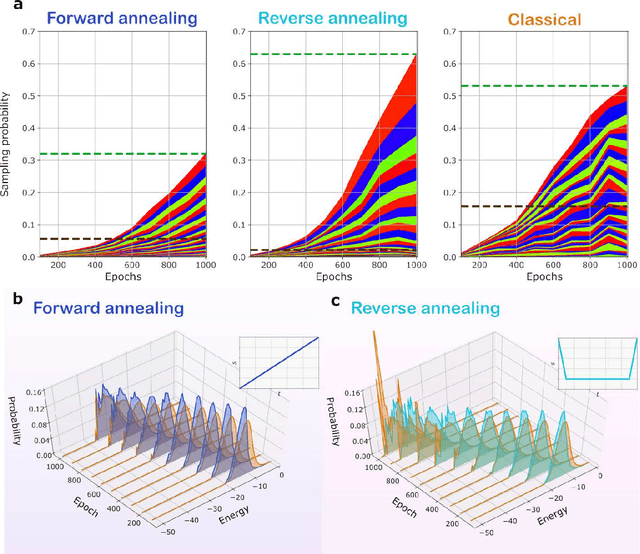
Boltzmann Machines constitute a class of neural networks with applications to image reconstruction, pattern classification and unsupervised learning in general. Their most common variants, called Restricted Boltzmann Machines (RBMs) exhibit a good trade-off between computability on existing silicon-based hardware and generality of possible applications. Still, the diffusion of RBMs is quite limited, since their training process proves to be hard. The advent of commercial Adiabatic Quantum Computers (AQCs) raised the expectation that the implementations of RBMs on such quantum devices could increase the training speed with respect to conventional hardware. To date, however, the implementation of RBM networks on AQCs has been limited by the low qubit connectivity when each qubit acts as a node of the neural network. Here we demonstrate the feasibility of a complete RBM on AQCs, thanks to an embedding that associates its nodes to virtual qubits, thus outperforming previous implementations based on incomplete graphs. Moreover, to accelerate the learning, we implement a semantic quantum search which, contrary to previous proposals, takes the input data as initial boundary conditions to start each learning step of the RBM, thanks to a reverse annealing schedule. Such an approach, unlike the more conventional forward annealing schedule, allows sampling configurations in a meaningful neighborhood of the training data, mimicking the behavior of the classical Gibbs sampling algorithm. We show that the learning based on reverse annealing quickly raises the sampling probability of a meaningful subset of the set of the configurations. Even without a proper optimization of the annealing schedule, the RBM semantically trained by reverse annealing achieves better scores on reconstruction tasks.
Variational local structure estimation for image super-resolution
Sep 12, 2007


Super-resolution is an important but difficult problem in image/video processing. If a video sequence or some training set other than the given low-resolution image is available, this kind of extra information can greatly aid in the reconstruction of the high-resolution image. The problem is substantially more difficult with only a single low-resolution image on hand. The image reconstruction methods designed primarily for denoising is insufficient for super-resolution problem in the sense that it tends to oversmooth images with essentially no noise. We propose a new adaptive linear interpolation method based on variational method and inspired by local linear embedding (LLE). The experimental result shows that our method avoids the problem of oversmoothing and preserves image structures well.
Pix2Pix-based Stain-to-Stain Translation: A Solution for Robust Stain Normalization in Histopathology Images Analysis
Feb 03, 2020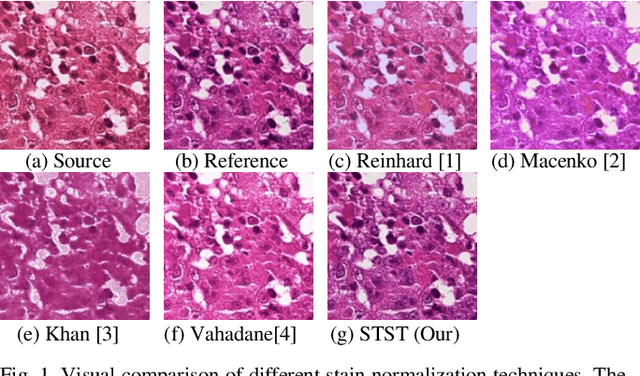
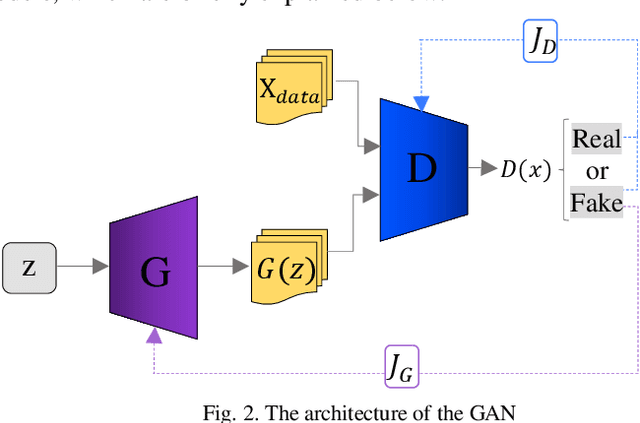
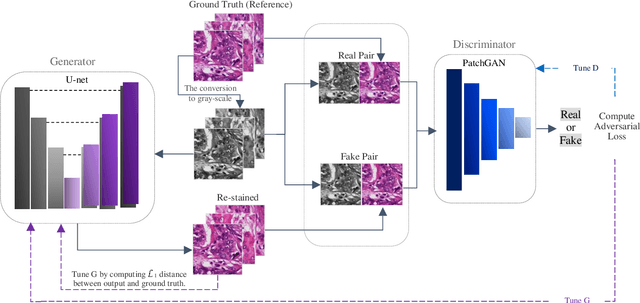
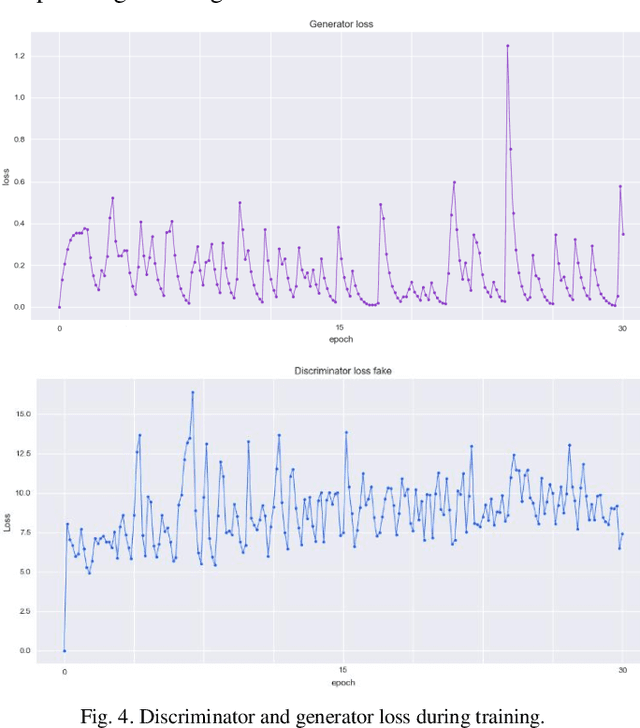
The diagnosis of cancer is mainly performed by visual analysis of the pathologists, through examining the morphology of the tissue slices and the spatial arrangement of the cells. If the microscopic image of a specimen is not stained, it will look colorless and textured. Therefore, chemical staining is required to create contrast and help identify specific tissue components. During tissue preparation due to differences in chemicals, scanners, cutting thicknesses, and laboratory protocols, similar tissues are usually varied significantly in appearance. This diversity in staining, in addition to Interpretive disparity among pathologists more is one of the main challenges in designing robust and flexible systems for automated analysis. To address the staining color variations, several methods for normalizing stain have been proposed. In our proposed method, a Stain-to-Stain Translation (STST) approach is used to stain normalization for Hematoxylin and Eosin (H&E) stained histopathology images, which learns not only the specific color distribution but also the preserves corresponding histopathological pattern. We perform the process of translation based on the pix2pix framework, which uses the conditional generator adversarial networks (cGANs). Our approach showed excellent results, both mathematically and experimentally against the state of the art methods. We have made the source code publicly available.
Soft-Root-Sign Activation Function
Mar 01, 2020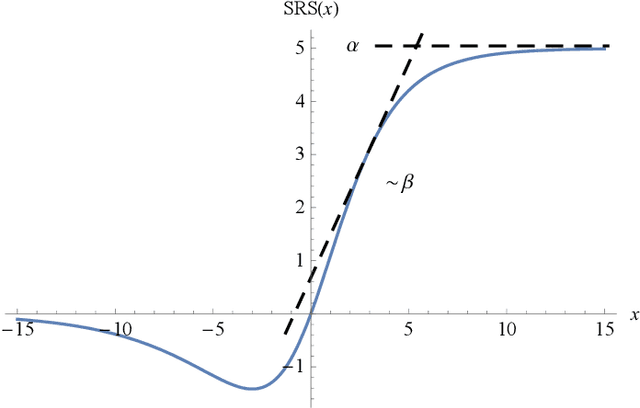
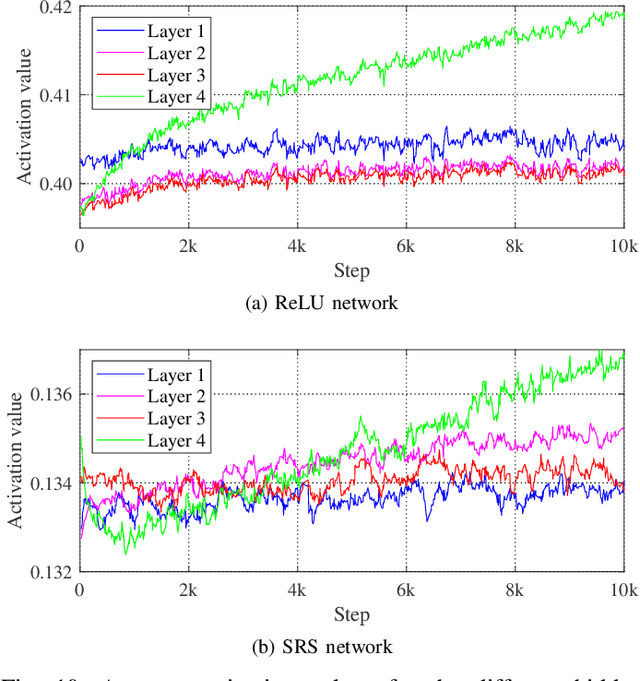
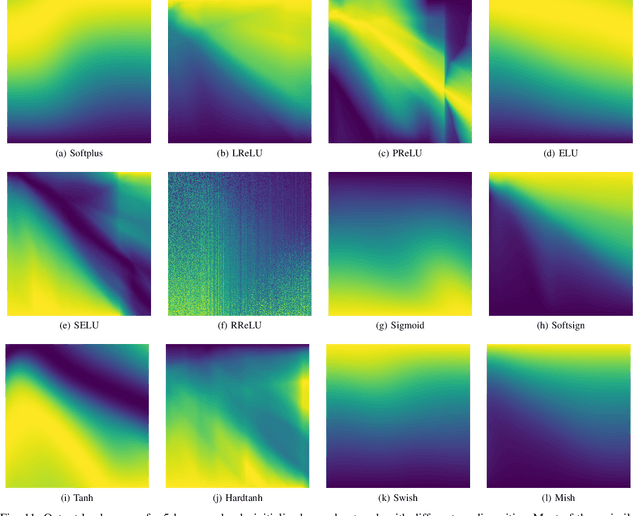
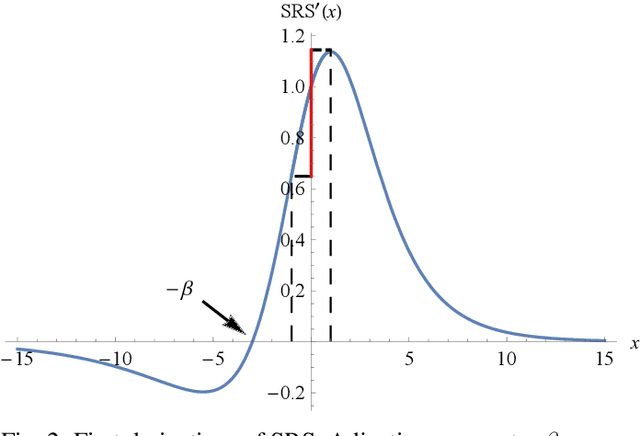
The choice of activation function in deep networks has a significant effect on the training dynamics and task performance. At present, the most effective and widely-used activation function is ReLU. However, because of the non-zero mean, negative missing and unbounded output, ReLU is at a potential disadvantage during optimization. To this end, we introduce a novel activation function to manage to overcome the above three challenges. The proposed nonlinearity, namely "Soft-Root-Sign" (SRS), is smooth, non-monotonic, and bounded. Notably, the bounded property of SRS distinguishes itself from most state-of-the-art activation functions. In contrast to ReLU, SRS can adaptively adjust the output by a pair of independent trainable parameters to capture negative information and provide zero-mean property, which leading not only to better generalization performance, but also to faster learning speed. It also avoids and rectifies the output distribution to be scattered in the non-negative real number space, making it more compatible with batch normalization (BN) and less sensitive to initialization. In experiments, we evaluated SRS on deep networks applied to a variety of tasks, including image classification, machine translation and generative modelling. Our SRS matches or exceeds models with ReLU and other state-of-the-art nonlinearities, showing that the proposed activation function is generalized and can achieve high performance across tasks. Ablation study further verified the compatibility with BN and self-adaptability for different initialization.
Semantic Redundancies in Image-Classification Datasets: The 10% You Don't Need
Jan 29, 2019
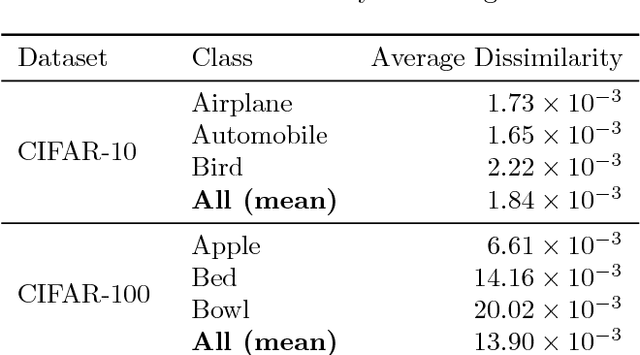
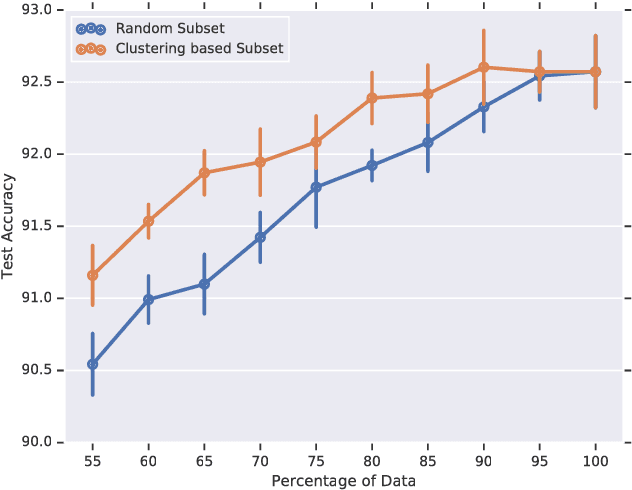

Large datasets have been crucial to the success of deep learning models in the recent years, which keep performing better as they are trained with more labelled data. While there have been sustained efforts to make these models more data-efficient, the potential benefit of understanding the data itself, is largely untapped. Specifically, focusing on object recognition tasks, we wonder if for common benchmark datasets we can do better than random subsets of the data and find a subset that can generalize on par with the full dataset when trained on. To our knowledge, this is the first result that can find notable redundancies in CIFAR-10 and ImageNet datasets (at least 10%). Interestingly, we observe semantic correlations between required and redundant images. We hope that our findings can motivate further research into identifying additional redundancies and exploiting them for more efficient training or data-collection.
SiamMan: Siamese Motion-aware Network for Visual Tracking
Jan 18, 2020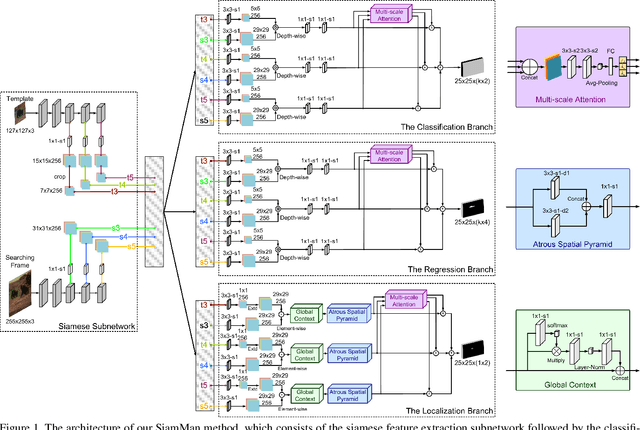
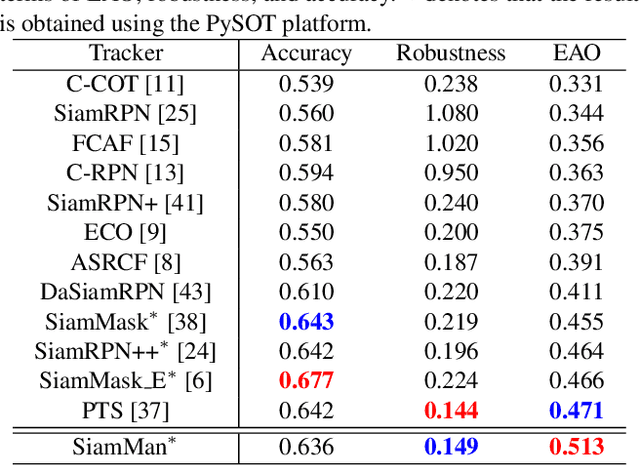
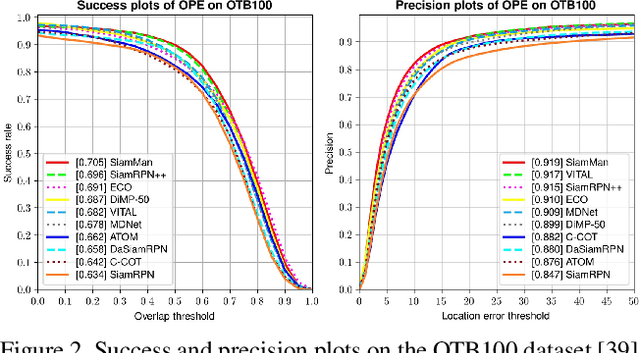
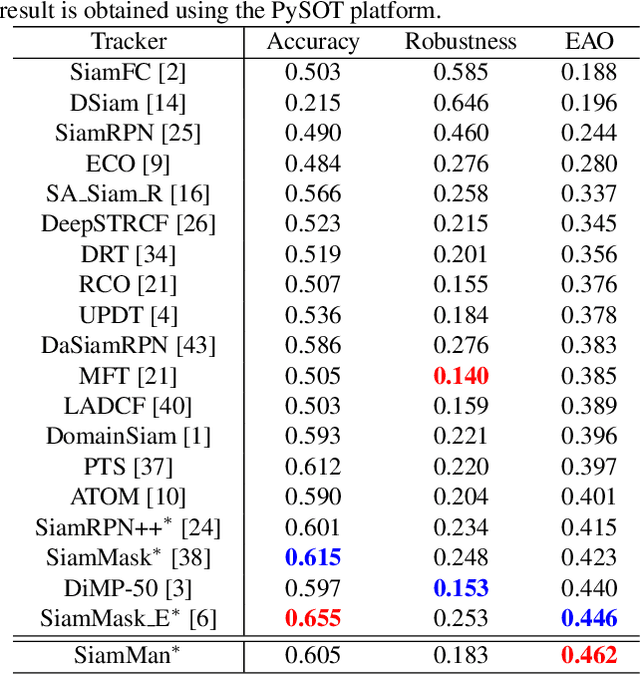
In this paper, we present a novel siamese motion-aware network (SiamMan) for visual tracking, which consists of the siamese feature extraction subnetwork, followed by the classification, regression, and localization branches in parallel. The classification branch is used to distinguish the foreground from background, and the regression branch is adopt to regress the bounding box of target. To reduce the impact of manually designed anchor boxes to adapt to different target motion patterns, we design the localization branch, which aims to coarsely localize the target to help the regression branch to generate accurate results. Meanwhile, we introduce the global context module into the localization branch to capture long-range dependency for more robustness in large displacement of target. In addition, we design a multi-scale learnable attention module to guide these three branches to exploit discriminative features for better performance. The whole network is trained offline in an end-to-end fashion with large-scale image pairs using the standard SGD algorithm with back-propagation. Extensive experiments on five challenging benchmarks, i.e., VOT2016, VOT2018, OTB100, UAV123 and LTB35, demonstrate that SiamMan achieves leading accuracy with high efficiency. Code can be found at https://isrc.iscas.ac.cn/gitlab/research/siamman.