 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Accelerating Object Detection by Erasing Background Activations
Feb 05, 2020

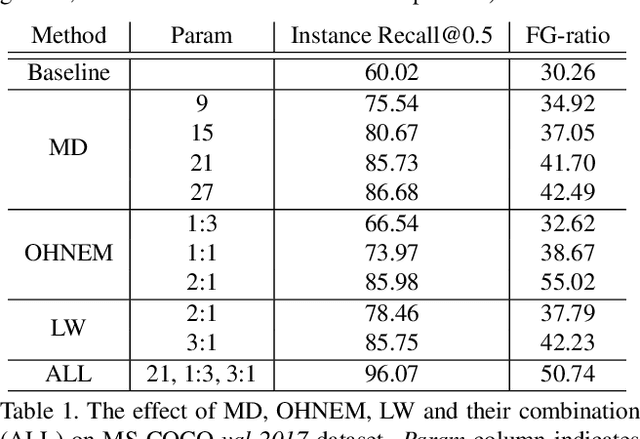
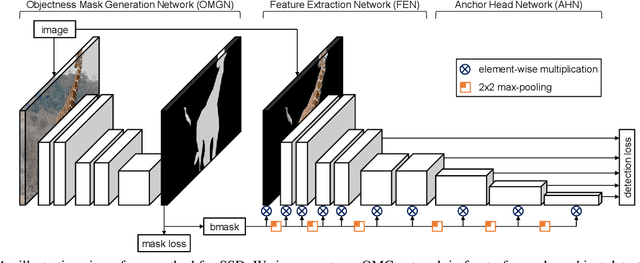
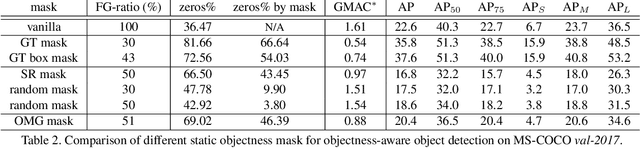
Recent advances in deep learning have enabled complex real-world use cases comprised of multiple vision tasks and detection tasks are being shifted to the edge side as a pre-processing step of the entire workload. However, since running a deep model on resource-constraint devices is challenging, the design of an efficient network is demanded. In this paper, we present an objectness-aware object detection method to accelerate detection speed by circumventing feature map computation on background regions where target objects don't exist. To accomplish this goal, we incorporate a light-weight objectness mask generation (OMG) network in front of an object detection (OD) network so that it can zero out background areas of an input image before being fed into the OD network. The inference speed, therefore, can be expedited with sparse convolution. By switching background areas to zeros for entire activations, the average number of zero values on MobileNetV2-SSDLite with ReLU activation is increased further, from 36% to 68% during inference step, which reduces 37.89\% MAC with negligible accuracy drop on MS-COCO. Moreover, experimental results also show similar trends in heavy networks such as VGG and RetinaNet with ResNet101, and an additional dataset, PASCAL VOC. The code will be released.
Transflow Learning: Repurposing Flow Models Without Retraining
Dec 05, 2019
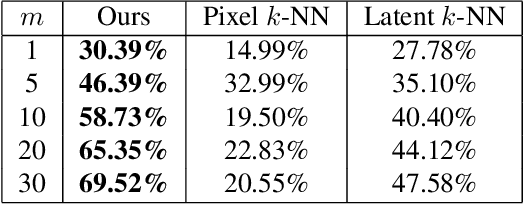
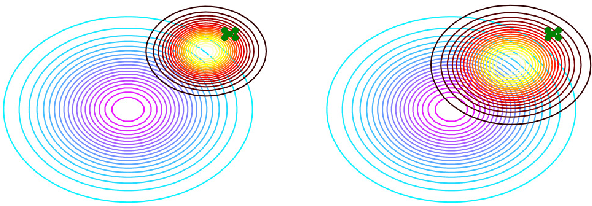

It is well known that deep generative models have a rich latent space, and that it is possible to smoothly manipulate their outputs by traversing this latent space. Recently, architectures have emerged that allow for more complex manipulations, such as making an image look as though it were from a different class, or painted in a certain style. These methods typically require large amounts of training in order to learn a single class of manipulations. We present Transflow Learning, a method for transforming a pre-trained generative model so that its outputs more closely resemble data that we provide afterwards. In contrast to previous methods, Transflow Learning does not require any training at all, and instead warps the probability distribution from which we sample latent vectors using Bayesian inference. Transflow Learning can be used to solve a wide variety of tasks, such as neural style transfer and few-shot classification.
LXMERT: Learning Cross-Modality Encoder Representations from Transformers
Aug 20, 2019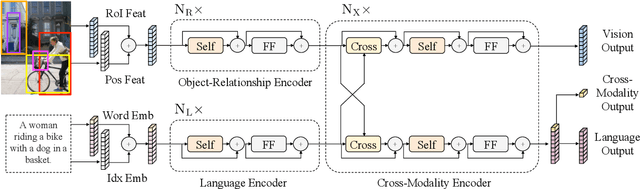
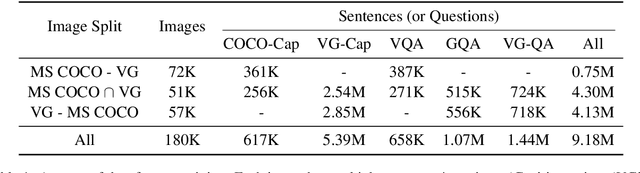
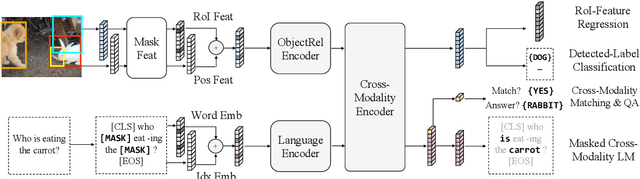
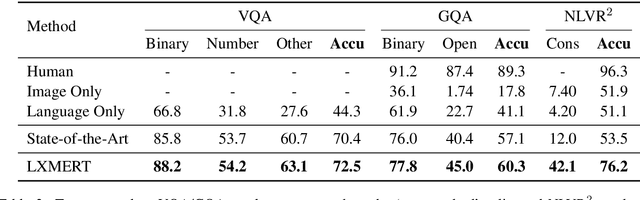
Vision-and-language reasoning requires an understanding of visual concepts, language semantics, and, most importantly, the alignment and relationships between these two modalities. We thus propose the LXMERT (Learning Cross-Modality Encoder Representations from Transformers) framework to learn these vision-and-language connections. In LXMERT, we build a large-scale Transformer model that consists of three encoders: an object relationship encoder, a language encoder, and a cross-modality encoder. Next, to endow our model with the capability of connecting vision and language semantics, we pre-train the model with large amounts of image-and-sentence pairs, via five diverse representative pre-training tasks: masked language modeling, masked object prediction (feature regression and label classification), cross-modality matching, and image question answering. These tasks help in learning both intra-modality and cross-modality relationships. After fine-tuning from our pre-trained parameters, our model achieves the state-of-the-art results on two visual question answering datasets (i.e., VQA and GQA). We also show the generalizability of our pre-trained cross-modality model by adapting it to a challenging visual-reasoning task, NLVR2, and improve the previous best result by 22% absolute (54% to 76%). Lastly, we demonstrate detailed ablation studies to prove that both our novel model components and pre-training strategies significantly contribute to our strong results. Code and pre-trained models publicly available at: https://github.com/airsplay/lxmert
HMRF-EM-image: Implementation of the Hidden Markov Random Field Model and its Expectation-Maximization Algorithm
Dec 18, 2012
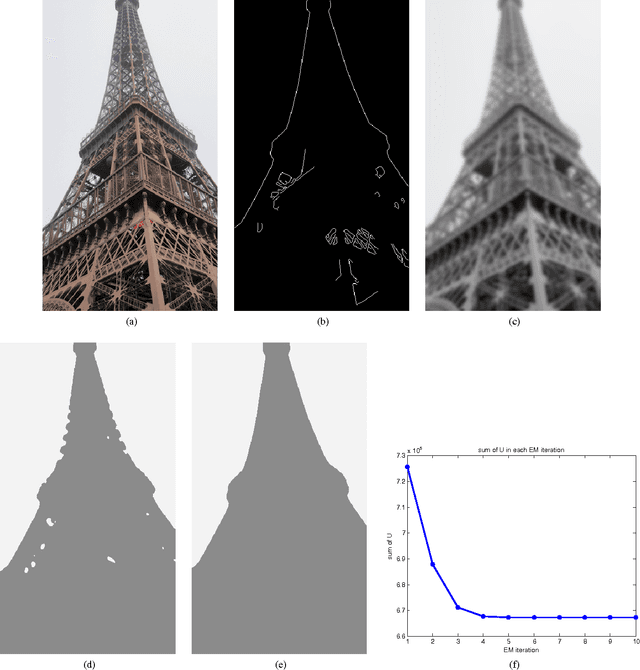
In this project, we study the hidden Markov random field (HMRF) model and its expectation-maximization (EM) algorithm. We implement a MATLAB toolbox named HMRF-EM-image for 2D image segmentation using the HMRF-EM framework. This toolbox also implements edge-prior-preserving image segmentation, and can be easily reconfigured for other problems, such as 3D image segmentation.
Accuracy vs. Complexity: A Trade-off in Visual Question Answering Models
Jan 20, 2020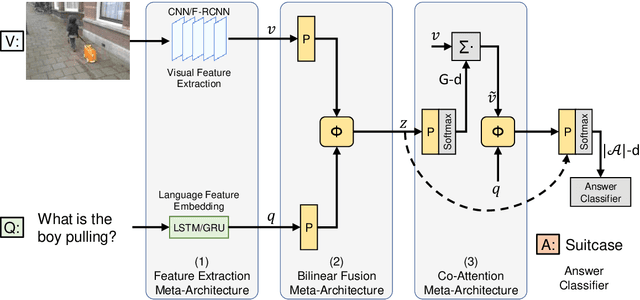
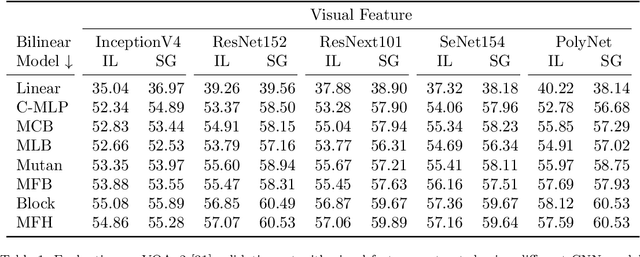
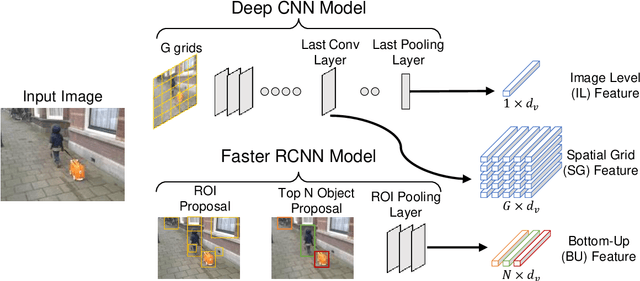
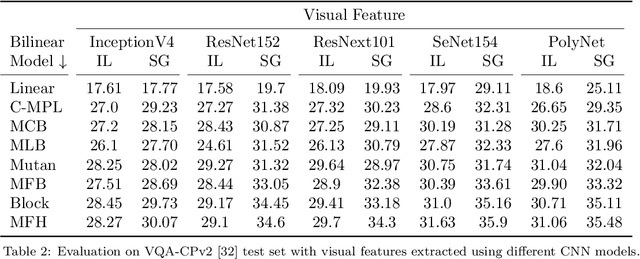
Visual Question Answering (VQA) has emerged as a Visual Turing Test to validate the reasoning ability of AI agents. The pivot to existing VQA models is the joint embedding that is learned by combining the visual features from an image and the semantic features from a given question. Consequently, a large body of literature has focused on developing complex joint embedding strategies coupled with visual attention mechanisms to effectively capture the interplay between these two modalities. However, modelling the visual and semantic features in a high dimensional (joint embedding) space is computationally expensive, and more complex models often result in trivial improvements in the VQA accuracy. In this work, we systematically study the trade-off between the model complexity and the performance on the VQA task. VQA models have a diverse architecture comprising of pre-processing, feature extraction, multimodal fusion, attention and final classification stages. We specifically focus on the effect of "multi-modal fusion" in VQA models that is typically the most expensive step in a VQA pipeline. Our thorough experimental evaluation leads us to two proposals, one optimized for minimal complexity and the other one optimized for state-of-the-art VQA performance.
Photo-Geometric Autoencoding to Learn 3D Objects from Unlabelled Images
Jun 04, 2019
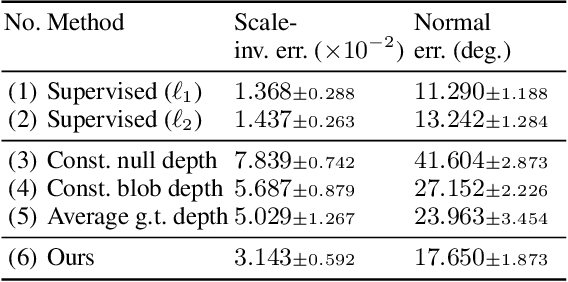
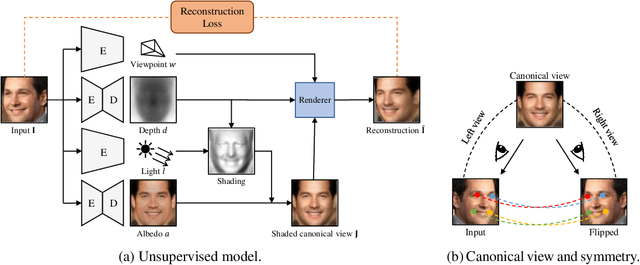

We show that generative models can be used to capture visual geometry constraints statistically. We use this fact to infer the 3D shape of object categories from raw single-view images. Differently from prior work, we use no external supervision, nor do we use multiple views or videos of the objects. We achieve this by a simple reconstruction task, exploiting the symmetry of the objects' shape and albedo. Specifically, given a single image of the object seen from an arbitrary viewpoint, our model predicts a symmetric canonical view, the corresponding 3D shape and a viewpoint transformation, and trains with the goal of reconstructing the input view, resembling an auto-encoder. Our experiments show that this method can recover the 3D shape of human faces, cat faces, and cars from single view images, without supervision. On benchmarks, we demonstrate superior accuracy compared to other methods that use supervision at the level of 2D image correspondences.
Walking on the Edge: Fast, Low-Distortion Adversarial Examples
Dec 05, 2019
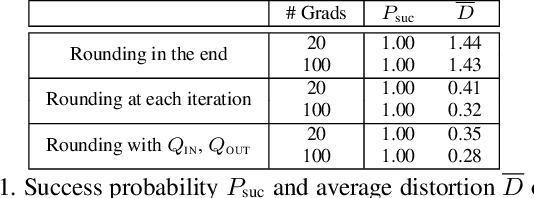
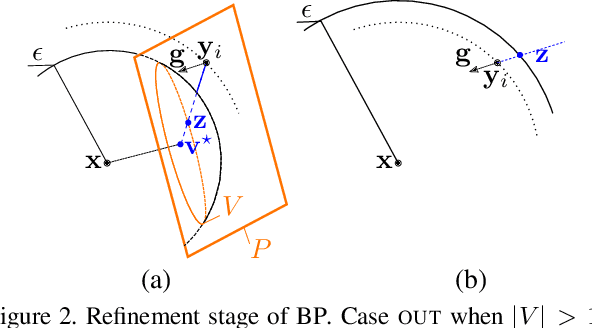
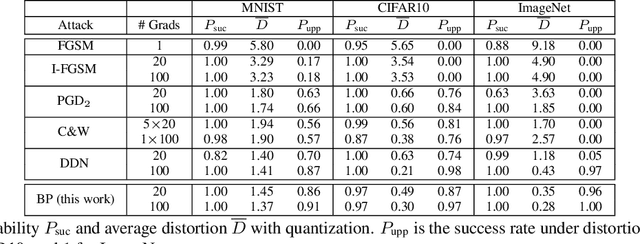
Adversarial examples of deep neural networks are receiving ever increasing attention because they help in understanding and reducing the sensitivity to their input. This is natural given the increasing applications of deep neural networks in our everyday lives. When white-box attacks are almost always successful, it is typically only the distortion of the perturbations that matters in their evaluation. In this work, we argue that speed is important as well, especially when considering that fast attacks are required by adversarial training. Given more time, iterative methods can always find better solutions. We investigate this speed-distortion trade-off in some depth and introduce a new attack called boundary projection (BP) that improves upon existing methods by a large margin. Our key idea is that the classification boundary is a manifold in the image space: we therefore quickly reach the boundary and then optimize distortion on this manifold.
Learn to Explain Efficiently via Neural Logic Inductive Learning
Oct 06, 2019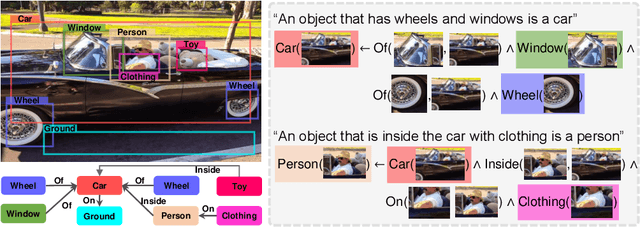
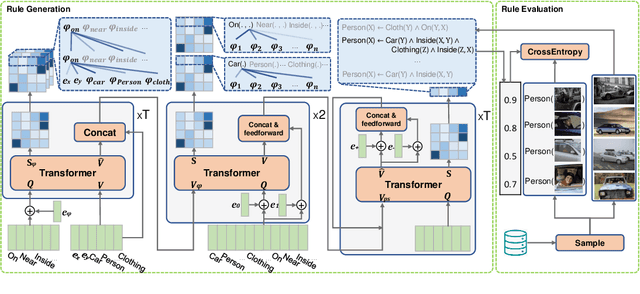
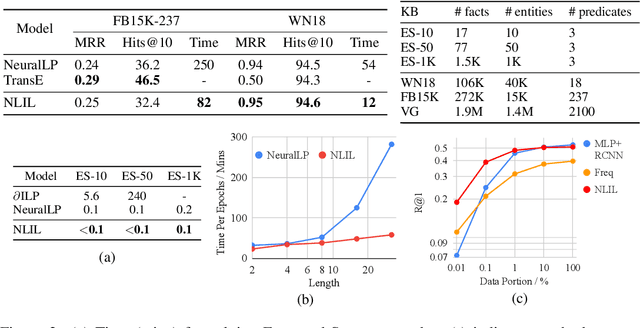
The capability of making interpretable and self-explanatory decisions is essential for developing responsible machine learning systems. In this work, we study the learning to explain problem in the scope of inductive logic programming (ILP). We propose Neural Logic Inductive Learning (NLIL), an efficient differentiable ILP framework that learns first-order logic rules that can explain the patterns in the data. In experiments, compared with the state-of-the-art methods, we find NLIL can search for rules that are x10 times longer while remaining x3 times faster. We also show that NLIL can scale to large image datasets, i.e. Visual Genome, with 1M entities.
Modified Distribution Alignment for Domain Adaptation with Pre-trainedInception ResNet
Apr 04, 2019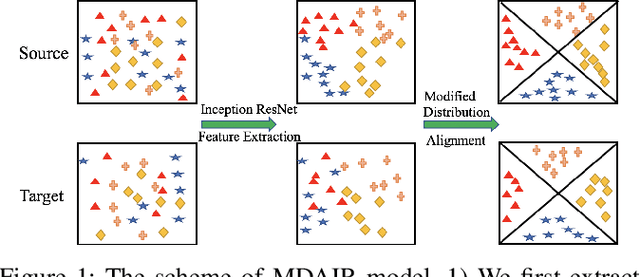
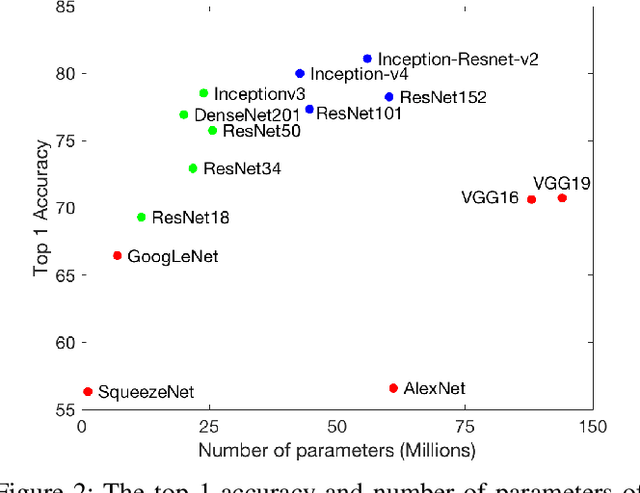

Deep neural networks have been widely used in computer vision. There are several well trained deep neural networks for the ImageNet classification challenge, which has played a significant role in image recognition. However, little work has explored pre-trained neural networks for image recognition in domain adaption. In this paper, we are the first to extract better-represented features from a pre-trained Inception ResNet model for domain adaptation. We then present a modified distribution alignment method for classification using the extracted features. We test our model using three benchmark datasets (Office+Caltech-10, Office-31, and Office-Home). Extensive experiments demonstrate significant improvements (4.8%, 5.5%, and 10%) in classification accuracy over the state-of-the-art.
Measuring the Utilization of Public Open Spaces by Deep Learning: a Benchmark Study at the Detroit Riverfront
Feb 04, 2020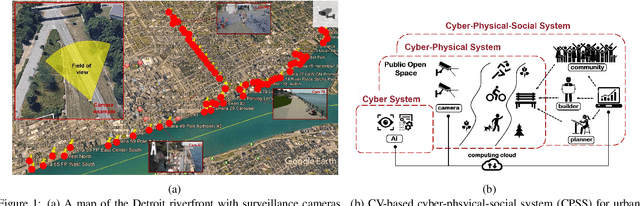
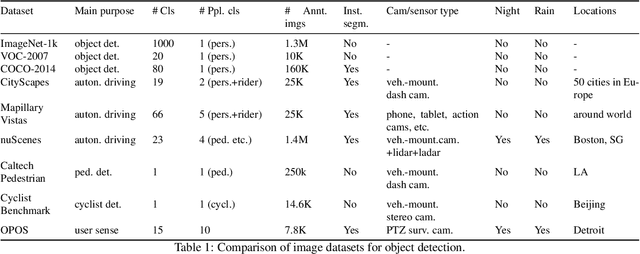

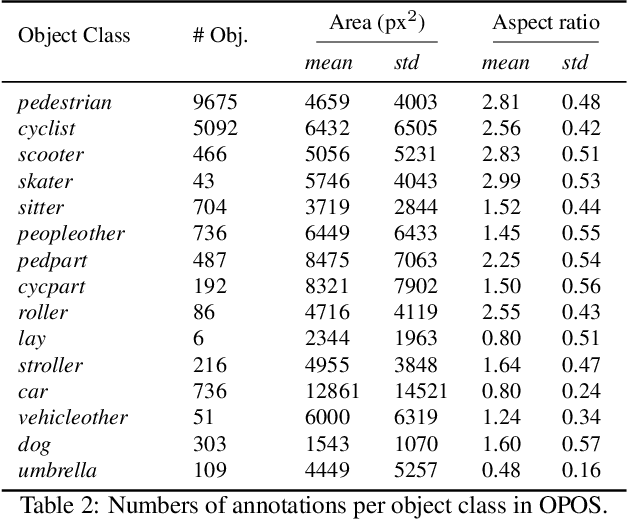
Physical activities and social interactions are essential activities that ensure a healthy lifestyle. Public open spaces (POS), such as parks, plazas and greenways, are key environments that encourage those activities. To evaluate a POS, there is a need to study how humans use the facilities within it. However, traditional approaches to studying use of POS are manual and therefore time and labor intensive. They also may only provide qualitative insights. It is appealing to make use of surveillance cameras and to extract user-related information through computer vision. This paper proposes a proof-of-concept deep learning computer vision framework for measuring human activities quantitatively in POS and demonstrates a case study of the proposed framework using the Detroit Riverfront Conservancy (DRFC) surveillance camera network. A custom image dataset is presented to train the framework; the dataset includes 7826 fully annotated images collected from 18 cameras across the DRFC park space under various illumination conditions. Dataset analysis is also provided as well as a baseline model for one-step user localization and activity recognition. The mAP results are 77.5\% for {\it pedestrian} detection and 81.6\% for {\it cyclist} detection. Behavioral maps are autonomously generated by the framework to locate different POS users and the average error for behavioral localization is within 10 cm.