 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Stopping Rules for Bag-of-Words Image Search and Its Application in Appearance-Based Localization
Dec 28, 2013
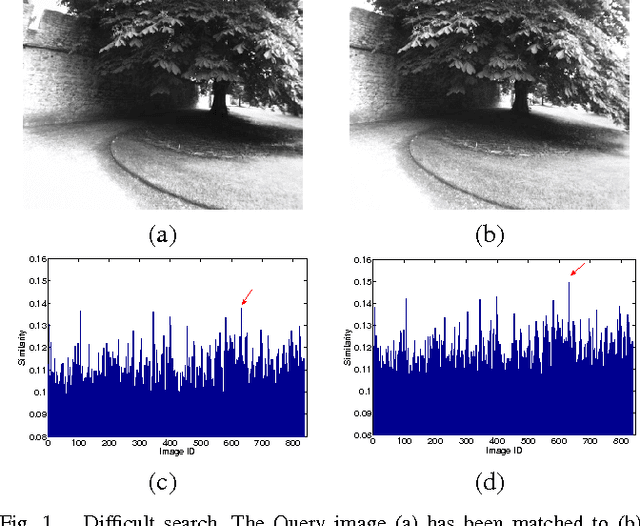
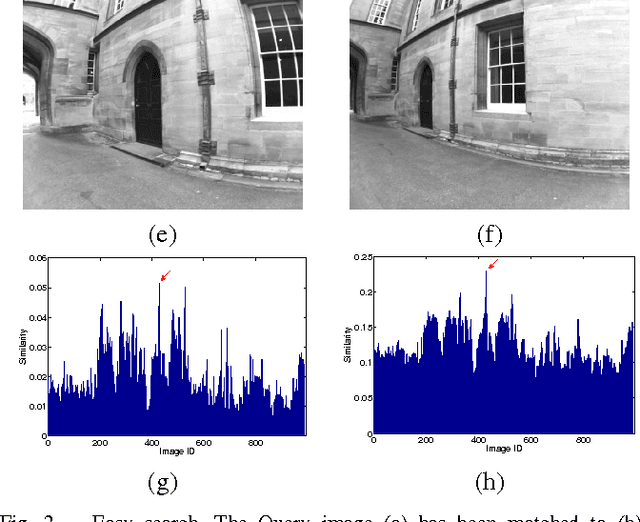

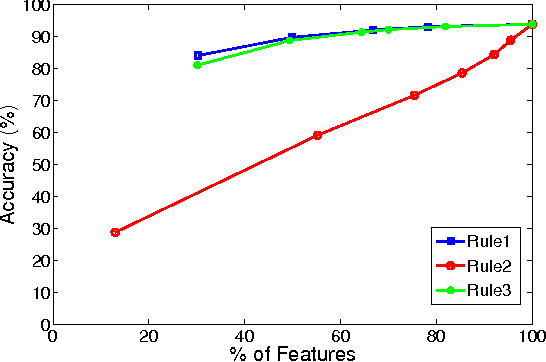
We propose a technique to improve the search efficiency of the bag-of-words (BoW) method for image retrieval. We introduce a notion of difficulty for the image matching problems and propose methods that reduce the amount of computations required for the feature vector-quantization task in BoW by exploiting the fact that easier queries need less computational resources. Measuring the difficulty of a query and stopping the search accordingly is formulated as a stopping problem. We introduce stopping rules that terminate the image search depending on the difficulty of each query, thereby significantly reducing the computational cost. Our experimental results show the effectiveness of our approach when it is applied to appearance-based localization problem.
Explaining Visual Models by Causal Attribution
Sep 19, 2019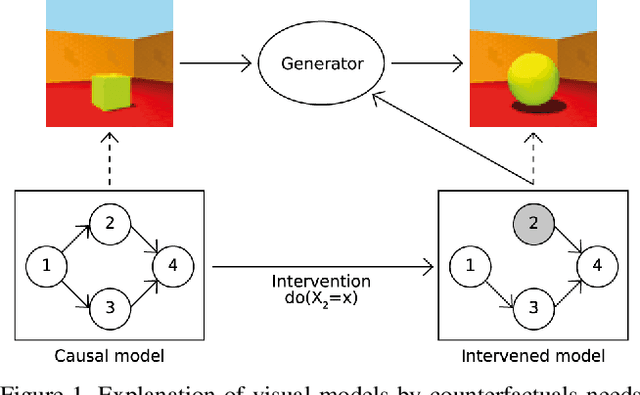
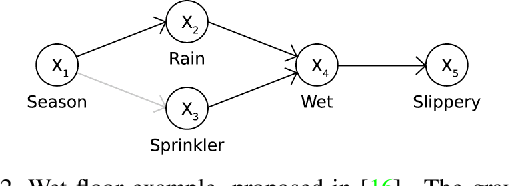

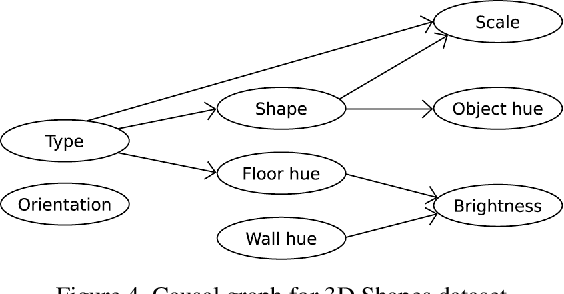
Model explanations based on pure observational data cannot compute the effects of features reliably, due to their inability to estimate how each factor alteration could affect the rest. We argue that explanations should be based on the causal model of the data and the derived intervened causal models, that represent the data distribution subject to interventions. With these models, we can compute counterfactuals, new samples that will inform us how the model reacts to feature changes on our input. We propose a novel explanation methodology based on Causal Counterfactuals and identify the limitations of current Image Generative Models in their application to counterfactual creation.
Recommending Themes for Ad Creative Design via Visual-Linguistic Representations
Feb 27, 2020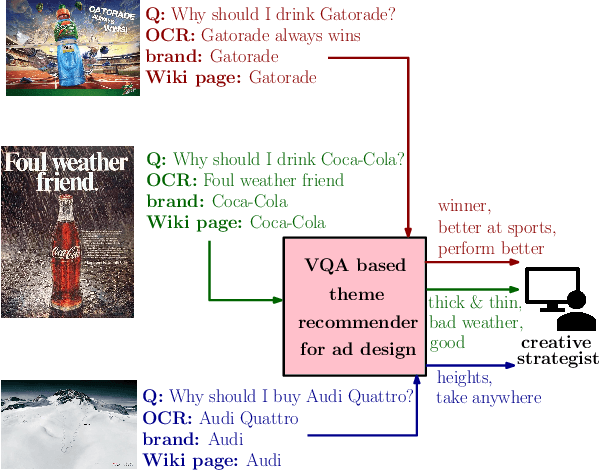
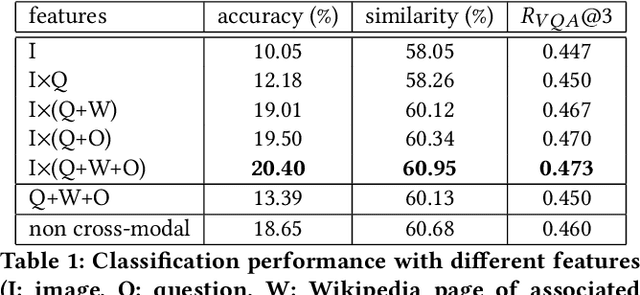
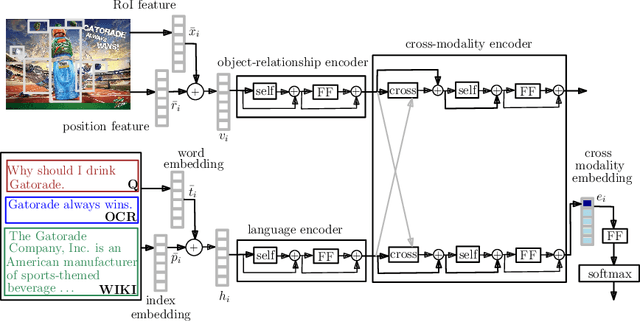
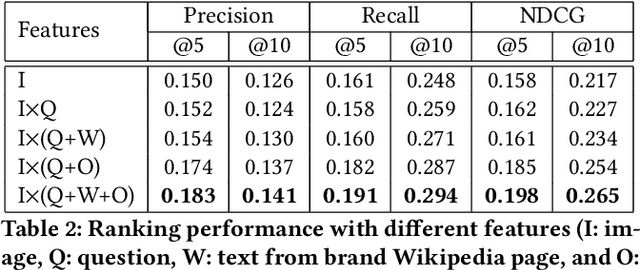
There is a perennial need in the online advertising industry to refresh ad creatives, i.e., images and text used for enticing online users towards a brand. Such refreshes are required to reduce the likelihood of ad fatigue among online users, and to incorporate insights from other successful campaigns in related product categories. Given a brand, to come up with themes for a new ad is a painstaking and time consuming process for creative strategists. Strategists typically draw inspiration from the images and text used for past ad campaigns, as well as world knowledge on the brands. To automatically infer ad themes via such multimodal sources of information in past ad campaigns, we propose a theme (keyphrase) recommender system for ad creative strategists. The theme recommender is based on aggregating results from a visual question answering (VQA) task, which ingests the following: (i) ad images, (ii) text associated with the ads as well as Wikipedia pages on the brands in the ads, and (iii) questions around the ad. We leverage transformer based cross-modality encoders to train visual-linguistic representations for our VQA task. We study two formulations for the VQA task along the lines of classification and ranking; via experiments on a public dataset, we show that cross-modal representations lead to significantly better classification accuracy and ranking precision-recall metrics. Cross-modal representations show better performance compared to separate image and text representations. In addition, the use of multimodal information shows a significant lift over using only textual or visual information.
Deep inspection: an electrical distribution pole parts study via deep neural networks
Jul 16, 2019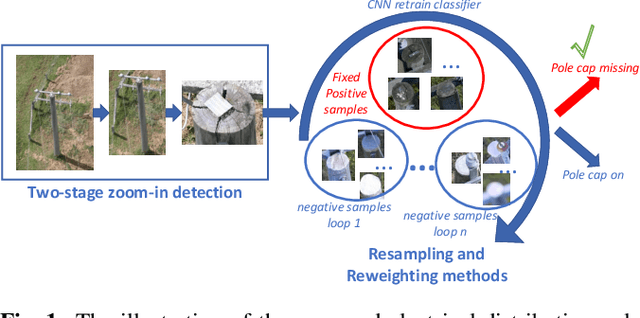

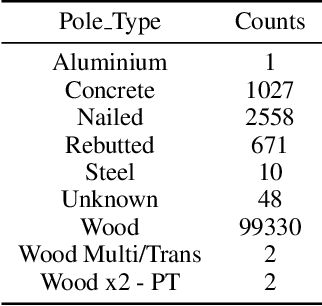

Electrical distribution poles are important assets in electricity supply. These poles need to be maintained in good condition to ensure they protect community safety, maintain reliability of supply, and meet legislative obligations. However, maintaining such a large volumes of assets is an expensive and challenging task. To address this, recent approaches utilise imagery data captured from helicopter and/or drone inspections. Whilst reducing the cost for manual inspection, manual analysis on each image is still required. As such, several image-based automated inspection systems have been proposed. In this paper, we target two major challenges: tiny object detection and extremely imbalanced datasets, which currently hinder the wide deployment of the automatic inspection. We propose a novel two-stage zoom-in detection method to gradually focus on the object of interest. To address the imbalanced dataset problem, we propose the resampling as well as reweighting schemes to iteratively adapt the model to the large intra-class variation of major class and balance the contributions to the loss from each class. Finally, we integrate these components together and devise a novel automatic inspection framework. Extensive experiments demonstrate that our proposed approaches are effective and can boost the performance compared to the baseline methods.
On the notion of number in humans and machines
Jun 27, 2019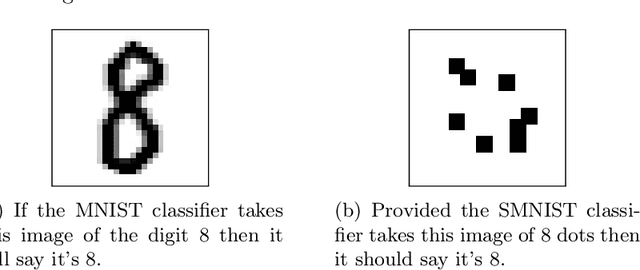
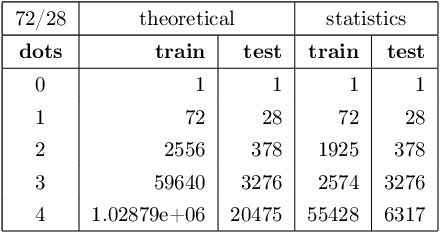

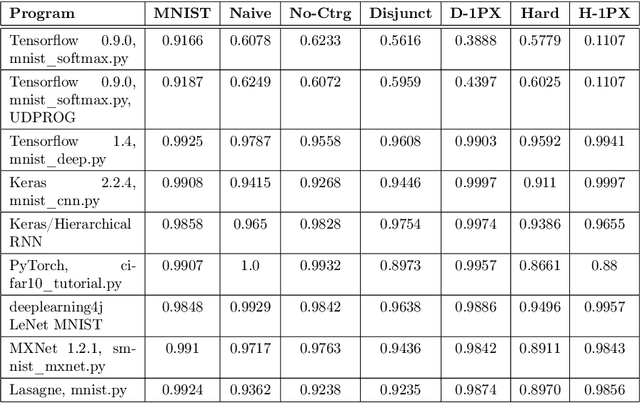
In this paper, we performed two types of software experiments to study the numerosity classification (subitizing) in humans and machines. Experiments focus on a particular kind of task is referred to as Semantic MNIST or simply SMNIST where the numerosity of objects placed in an image must be determined. The experiments called SMNIST for Humans are intended to measure the capacity of the Object File System in humans. In this type of experiment the measurement result is in well agreement with the value known from the cognitive psychology literature. The experiments called SMNIST for Machines serve similar purposes but they investigate existing, well known (but originally developed for other purpose) and under development deep learning computer programs. These measurement results can be interpreted similar to the results from SMNIST for Humans. The main thesis of this paper can be formulated as follows: in machines the image classification artificial neural networks can learn to distinguish numerosities with better accuracy when these numerosities are smaller than the capacity of OFS in humans. Finally, we outline a conceptual framework to investigate the notion of number in humans and machines.
Deep Verifier Networks: Verification of Deep Discriminative Models with Deep Generative Models
Nov 18, 2019
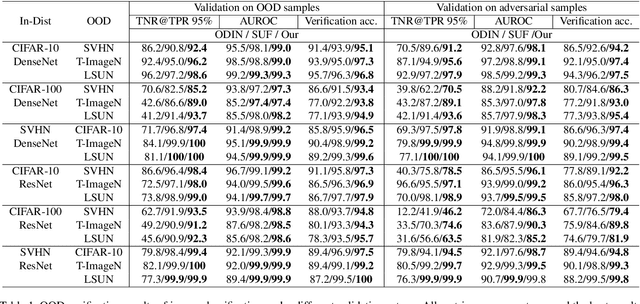
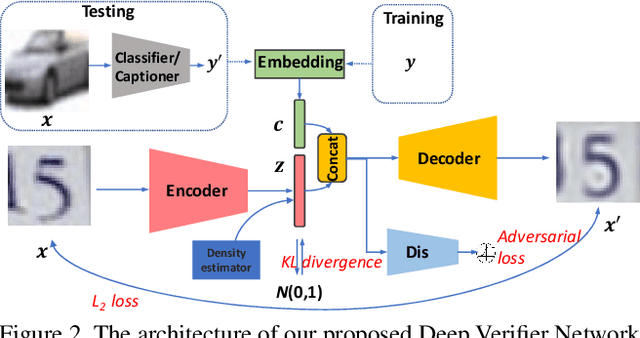

AI Safety is a major concern in many deep learning applications such as autonomous driving. Given a trained deep learning model, an important natural problem is how to reliably verify the model's prediction. In this paper, we propose a novel framework --- deep verifier networks (DVN) to verify the inputs and outputs of deep discriminative models with deep generative models. Our proposed model is based on conditional variational auto-encoders with disentanglement constraints. We give both intuitive and theoretical justifications of the model. Our verifier network is trained independently with the prediction model, which eliminates the need of retraining the verifier network for a new model. We test the verifier network on out-of-distribution detection and adversarial example detection problems, as well as anomaly detection problems in structured prediction tasks such as image caption generation. We achieve state-of-the-art results in all of these problems.
Automated Relational Meta-learning
Jan 03, 2020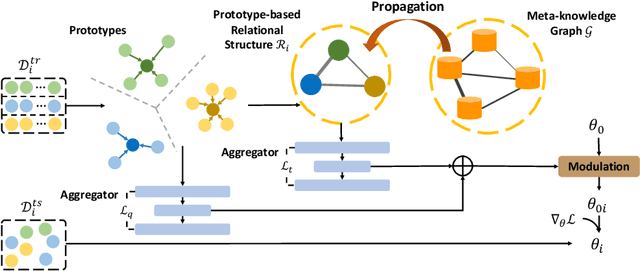
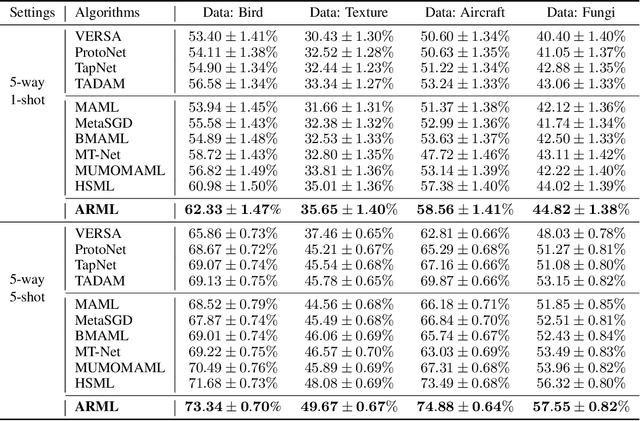
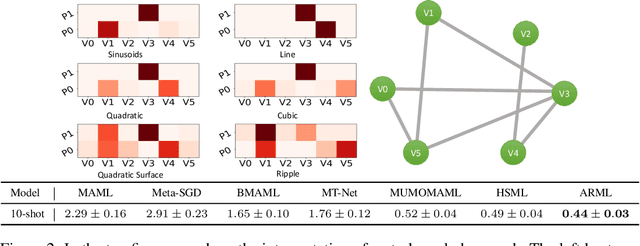
In order to efficiently learn with small amount of data on new tasks, meta-learning transfers knowledge learned from previous tasks to the new ones. However, a critical challenge in meta-learning is the task heterogeneity which cannot be well handled by traditional globally shared meta-learning methods. In addition, current task-specific meta-learning methods may either suffer from hand-crafted structure design or lack the capability to capture complex relations between tasks. In this paper, motivated by the way of knowledge organization in knowledge bases, we propose an automated relational meta-learning (ARML) framework that automatically extracts the cross-task relations and constructs the meta-knowledge graph. When a new task arrives, it can quickly find the most relevant structure and tailor the learned structure knowledge to the meta-learner. As a result, the proposed framework not only addresses the challenge of task heterogeneity by a learned meta-knowledge graph, but also increases the model interpretability. We conduct extensive experiments on 2D toy regression and few-shot image classification and the results demonstrate the superiority of ARML over state-of-the-art baselines.
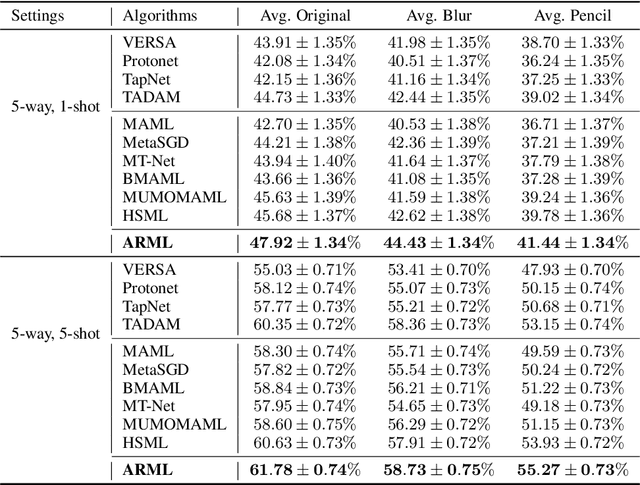
Learning Similarity Attention
Nov 18, 2019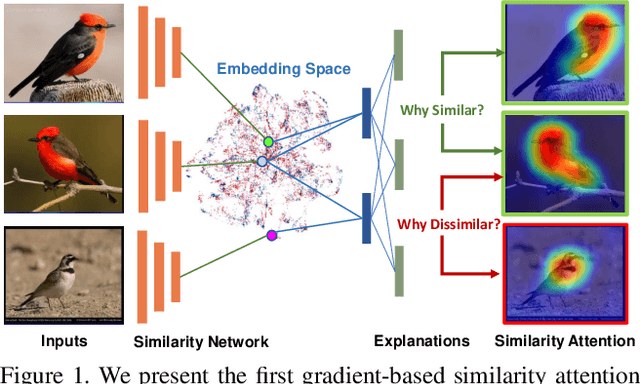
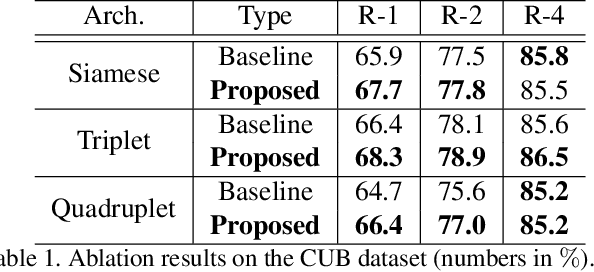
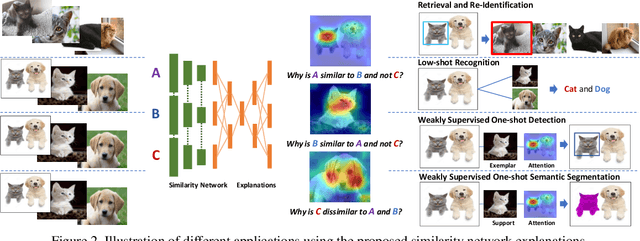
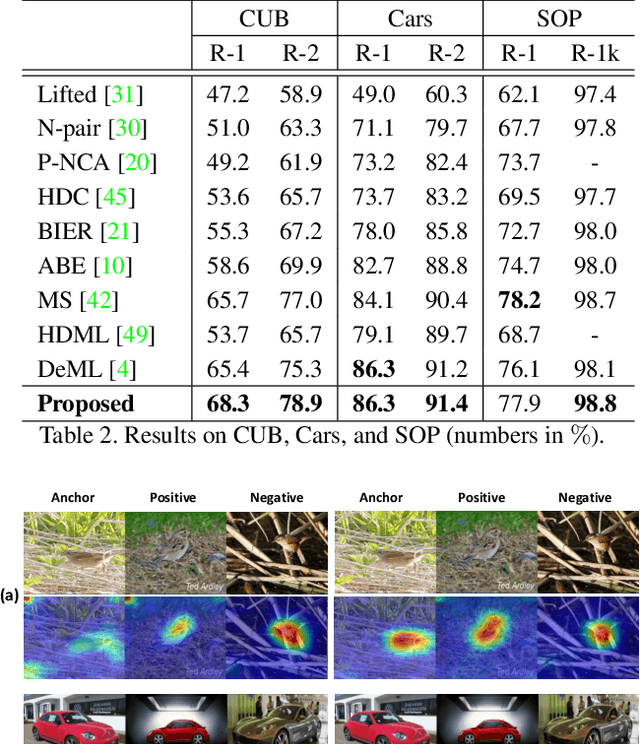
We consider the problem of learning similarity functions. While there has been substantial progress in learning suitable distance metrics, these techniques in general lack decision reasoning, i.e., explaining why the input set of images is similar or dissimilar. In this work, we solve this key problem by proposing the first method to generate generic visual similarity explanations with gradient-based attention. We demonstrate that our technique is agnostic to the specific similarity model type, e.g., we show applicability to Siamese, triplet, and quadruplet models. Furthermore, we make our proposed similarity attention a principled part of the learning process, resulting in a new paradigm for learning similarity functions. We demonstrate that our learning mechanism results in more generalizable, as well as explainable, similarity models. Finally, we demonstrate the generality of our framework by means of experiments on a variety of tasks, including image retrieval, person re-identification, and low-shot semantic segmentation.
Two-stage breast mass detection and segmentation system towards automated high-resolution full mammogram analysis
Feb 27, 2020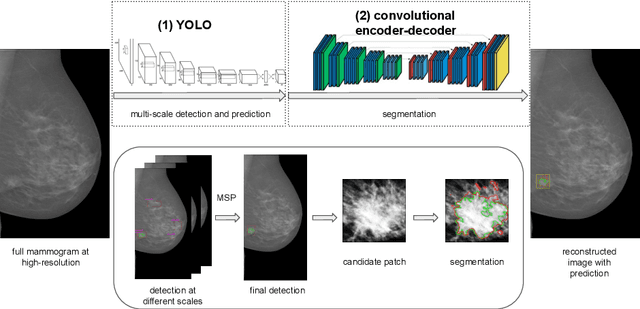
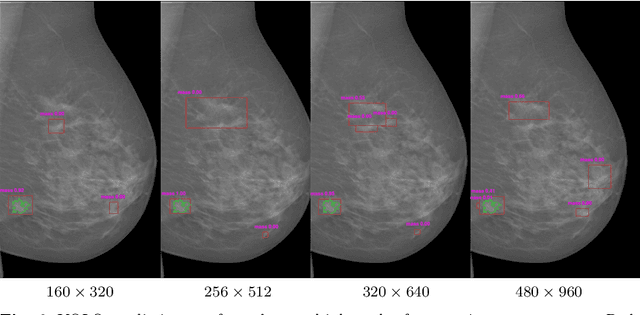
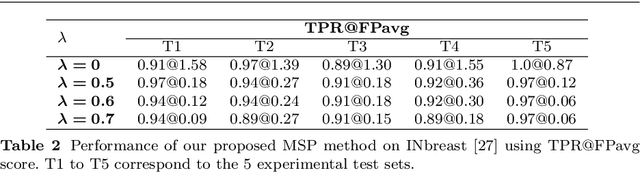
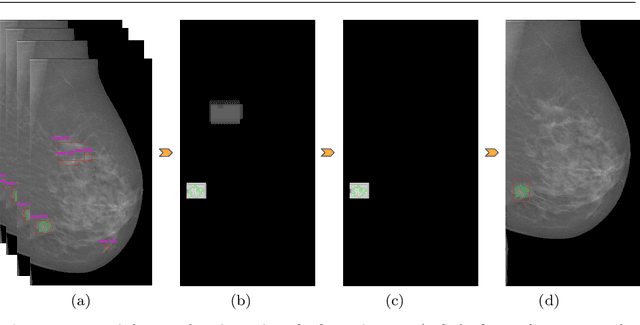
Mammography is the primary imaging modality used for early detection and diagnosis of breast cancer. Mammography analysis mainly refers to the extraction of regions of interest around tumors, followed by a segmentation step, which is essential to further classification of benign or malignant tumors. Breast masses are the most important findings among breast abnormalities. However, manual delineation of masses from native mammogram is a time consuming and error-prone task. An integrated computer-aided diagnosis system to assist radiologists in automatically detecting and segmenting breast masses is therefore in urgent need. We propose a fully-automated approach that guides accurate mass segmentation from full mammograms at high resolution through a detection stage. First, mass detection is performed by an efficient deep learning approach, You-Only-Look-Once, extended by integrating multi-scale predictions to improve automatic candidate selection. Second, a convolutional encoder-decoder network using nested and dense skip connections is employed to fine-delineate candidate masses. Unlike most previous studies based on segmentation from regions, our framework handles mass segmentation from native full mammograms without user intervention. Trained on INbreast and DDSM-CBIS public datasets, the pipeline achieves an overall average Dice of 80.44% on high-resolution INbreast test images, outperforming state-of-the-art methods. Our system shows promising accuracy as an automatic full-image mass segmentation system. The comprehensive evaluation provided for both detection and segmentation stages reveals strong robustness to the diversity of size, shape and appearance of breast masses, towards better computer-aided diagnosis.
Consensus-based Optimization for 3D Human Pose Estimation in Camera Coordinates
Nov 28, 2019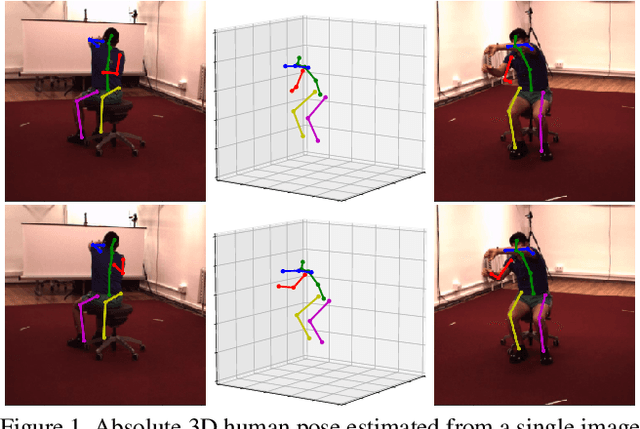
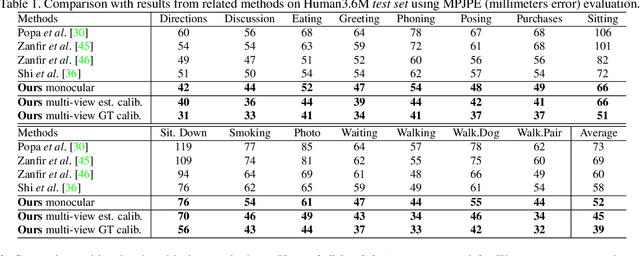
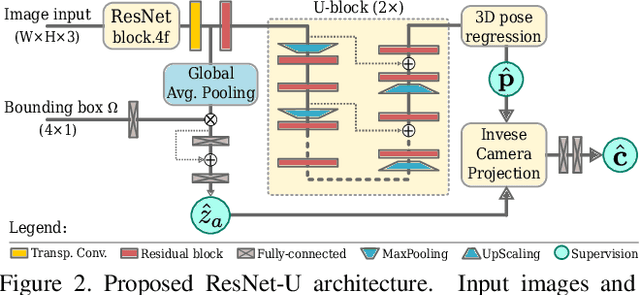
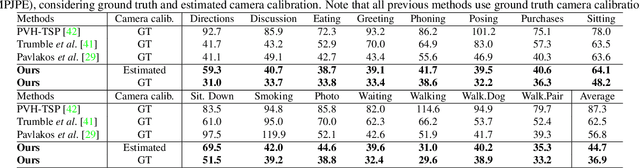
3D human pose estimation is frequently seen as the task of estimating 3D poses relative to the root body joint. Alternatively, in this paper, we propose a 3D human pose estimation method in camera coordinates, which allows effective combination of 2D annotated data and 3D poses, as well as a straightforward multi-view generalization. To that end, we cast the problem into a different perspective, where 3D poses are predicted in the image plane, in pixels, and the absolute depth is estimated in millimeters. Based on this, we propose a consensus-based optimization algorithm for multi-view predictions from uncalibrated images, which requires a single monocular training procedure. Our method improves the state-of-the-art on well known 3D human pose datasets, reducing the prediction error by 32% in the most common benchmark. In addition, we also reported our results in absolute pose position error, achieving 80mm for monocular estimations and 51mm for multi-view, on average.