 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adaptive Gradient for Adversarial Perturbations Generation
Apr 12, 2019

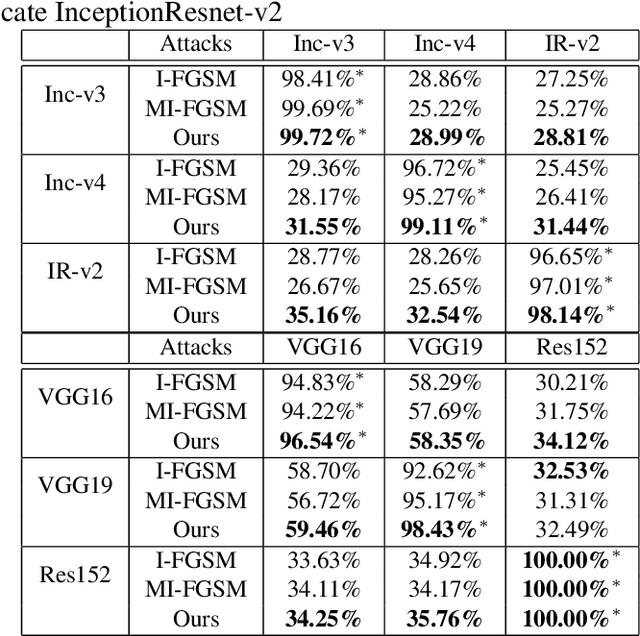
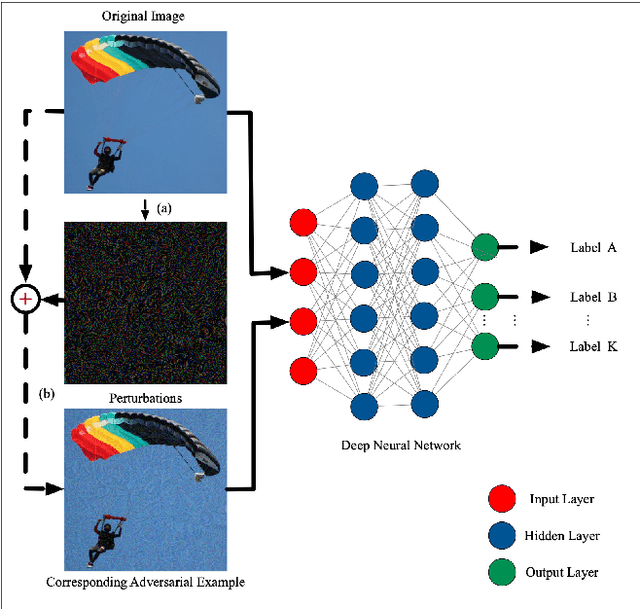
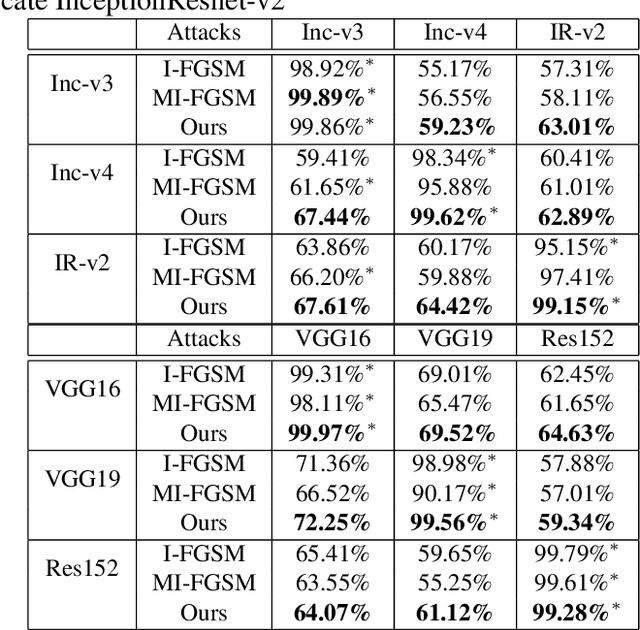
Deep Neural Networks have achieved remarkable success in computer vision, natural language processing, and audio tasks. However, in image classification domain, researches proved that deep neural models are easily fooled when affected by perturbation, which may cause server results. Many attack methods generate adversarial perturbation with large-scale pixel modification and low similarity between origin and corresponding adversarial examples, to address these issues, we propose an adversarial approach with the adaptive mechanism by self-adjusting perturbation intensity to seek the boundary distance between different classes directly which can escape local minimal in gradient processing. In this paper, we evaluate several traditional perturbations generating methods with our works. Experimental results show that our approach works well and outperform recent techniques in the change of misclassifying image prediction, and presents excellent efficiency in fooling deep network models.
Rethinking Atmospheric Turbulence Mitigation
May 17, 2019
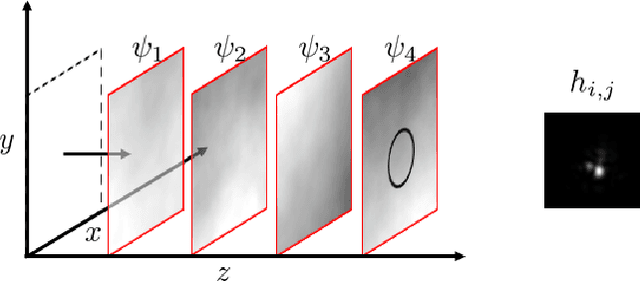
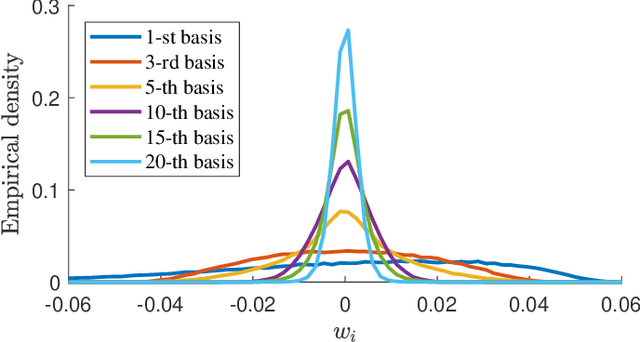
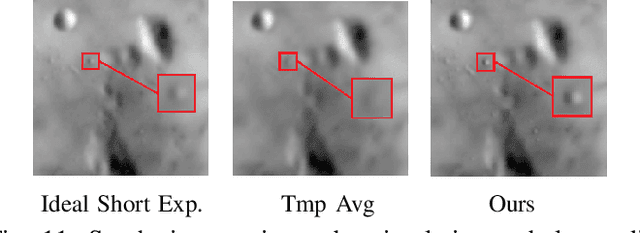
State-of-the-art atmospheric turbulence image restoration methods utilize standard image processing tools such as optical flow, lucky region and blind deconvolution to restore the images. While promising results have been reported over the past decade, many of the methods are agnostic to the physical model that generates the distortion. In this paper, we revisit the turbulence restoration problem by analyzing the reference frame generation and the blind deconvolution steps in a typical restoration pipeline. By leveraging tools in large deviation theory, we rigorously prove the minimum number of frames required to generate a reliable reference for both static and dynamic scenes. We discuss how a turbulence agnostic model can lead to potential flaws, and how to configure a simple spatial-temporal non-local weighted averaging method to generate references. For blind deconvolution, we present a new data-driven prior by analyzing the distributions of the point spread functions. We demonstrate how a simple prior can outperform state-of-the-art blind deconvolution methods.
Learning to Respond with Stickers: A Framework of Unifying Multi-Modality in Multi-Turn Dialog
Mar 10, 2020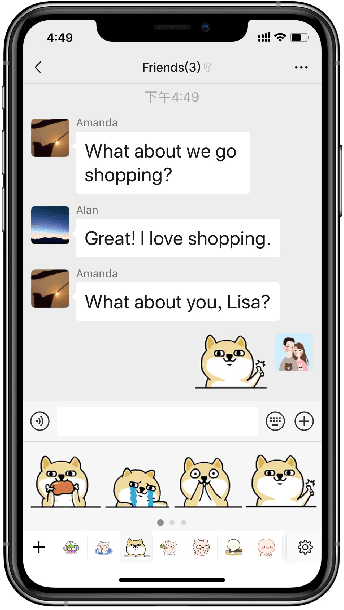
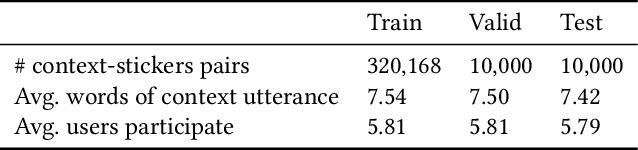
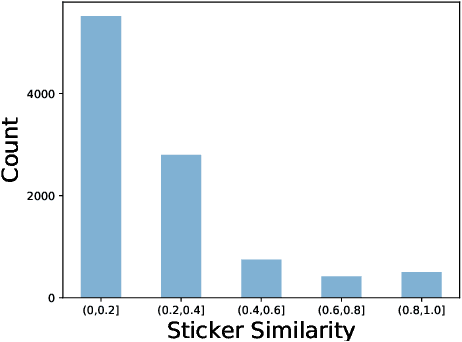

Stickers with vivid and engaging expressions are becoming increasingly popular in online messaging apps, and some works are dedicated to automatically select sticker response by matching text labels of stickers with previous utterances. However, due to their large quantities, it is impractical to require text labels for the all stickers. Hence, in this paper, we propose to recommend an appropriate sticker to user based on multi-turn dialog context history without any external labels. Two main challenges are confronted in this task. One is to learn semantic meaning of stickers without corresponding text labels. Another challenge is to jointly model the candidate sticker with the multi-turn dialog context. To tackle these challenges, we propose a sticker response selector (SRS) model. Specifically, SRS first employs a convolutional based sticker image encoder and a self-attention based multi-turn dialog encoder to obtain the representation of stickers and utterances. Next, deep interaction network is proposed to conduct deep matching between the sticker with each utterance in the dialog history. SRS then learns the short-term and long-term dependency between all interaction results by a fusion network to output the the final matching score. To evaluate our proposed method, we collect a large-scale real-world dialog dataset with stickers from one of the most popular online chatting platform. Extensive experiments conducted on this dataset show that our model achieves the state-of-the-art performance for all commonly-used metrics. Experiments also verify the effectiveness of each component of SRS. To facilitate further research in sticker selection field, we release this dataset of 340K multi-turn dialog and sticker pairs.
FDDWNet: A Lightweight Convolutional Neural Network for Real-time Sementic Segmentation
Nov 08, 2019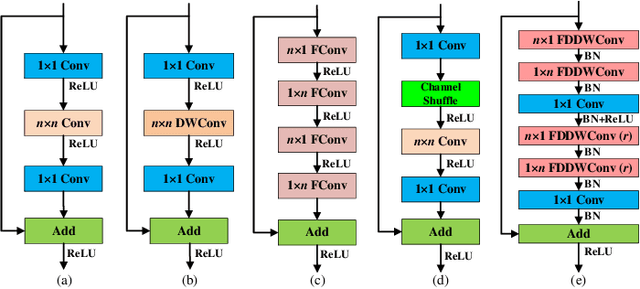
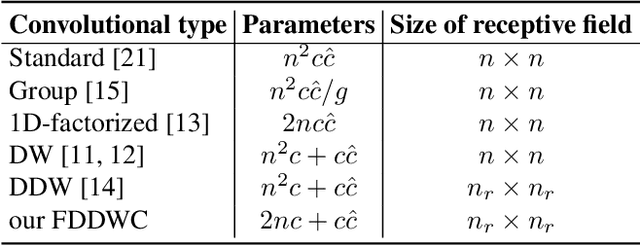
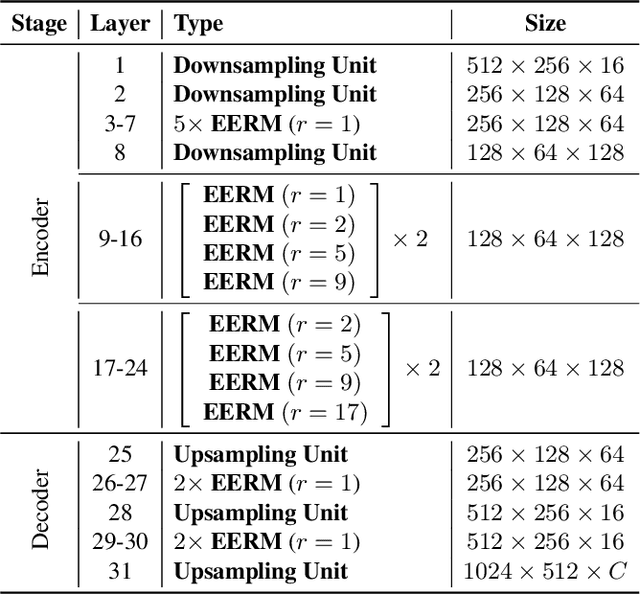

This paper introduces a lightweight convolutional neural network, called FDDWNet, for real-time accurate semantic segmentation. In contrast to recent advances of lightweight networks that prefer to utilize shallow structure, FDDWNet makes an effort to design more deeper network architecture, while maintains faster inference speed and higher segmentation accuracy. Our network uses factorized dilated depth-wise separable convolutions (FDDWC) to learn feature representations from different scale receptive fields with fewer model parameters. Additionally, FDDWNet has multiple branches of skipped connections to gather context cues from intermediate convolution layers. The experiments show that FDDWNet only has 0.8M model size, while achieves 60 FPS running speed on a single RTX 2080Ti GPU with a 1024x512 input image. The comprehensive experiments demonstrate that our model achieves state-of-the-art results in terms of available speed and accuracy trade-off on CityScapes and CamVid datasets.
Privacy Leakage Avoidance with Switching Ensembles
Nov 18, 2019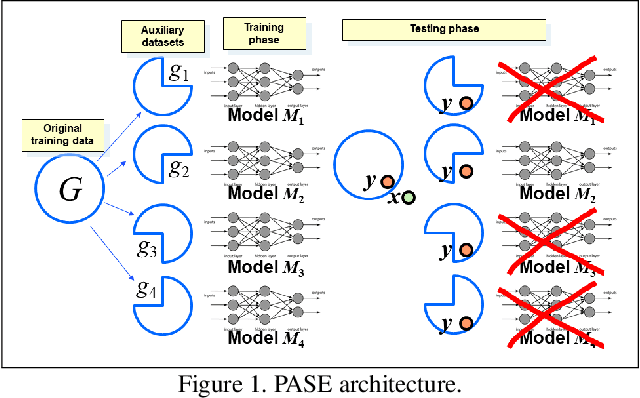
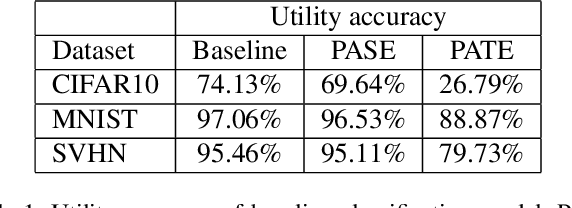
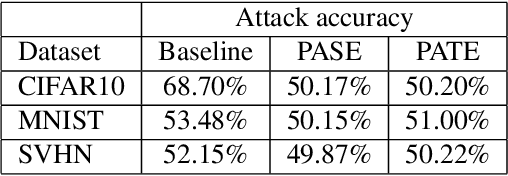
We consider membership inference attacks, one of the main privacy issues in machine learning. These recently developed attacks have been proven successful in determining, with confidence better than a random guess, whether a given sample belongs to the dataset on which the attacked machine learning model was trained. Several approaches have been developed to mitigate this privacy leakage but the tradeoff performance implications of these defensive mechanisms (i.e., accuracy and utility of the defended machine learning model) are not well studied yet. We propose a novel approach of privacy leakage avoidance with switching ensembles (PASE), which both protects against current membership inference attacks and does that with very small accuracy penalty, while requiring acceptable increase in training and inference time. We test our PASE method, along with the the current state-of-the-art PATE approach, on three calibration image datasets and analyze their tradeoffs.
Land Cover Change Detection via Semantic Segmentation
Nov 28, 2019
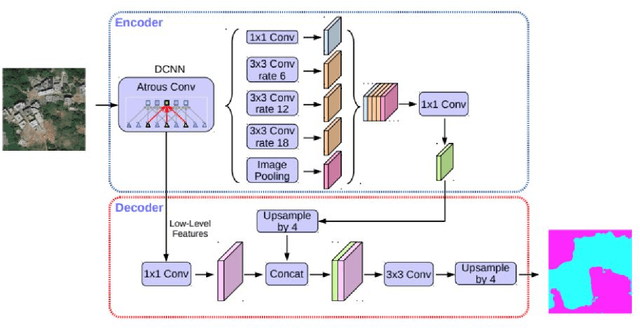
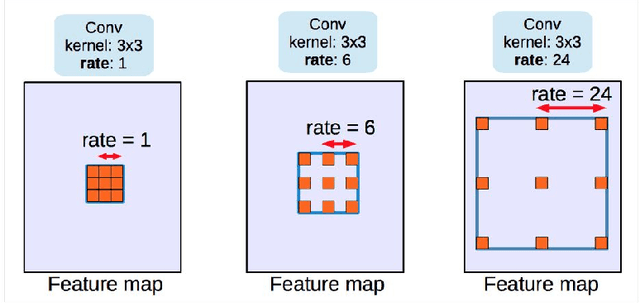

This paper presents a change detection method that identifies land cover changes from aerial imagery, using semantic segmentation, a machine learning approach. We present a land cover classification training pipeline with Deeplab v3+, state-of-the-art semantic segmentation technology, including data preparation, model training for seven land cover types, and model exporting modules. In the land cover change detection system, the inputs are images retrieved from Google Earth at the same location but from different times. The system then predicts semantic segmentation results on these images using the trained model and calculates the land cover class percentage for each input image. We see an improvement in the accuracy of the land cover semantic segmentation model, with a mean IoU of 0.756 compared to 0.433, as reported in the DeepGlobe land cover classification challenge. The land cover change detection system that leverages the state-of-the-art semantic segmentation technology is proposed and can be used for deforestation analysis, land management, and urban planning.
Learning from Synthetic Animals
Dec 17, 2019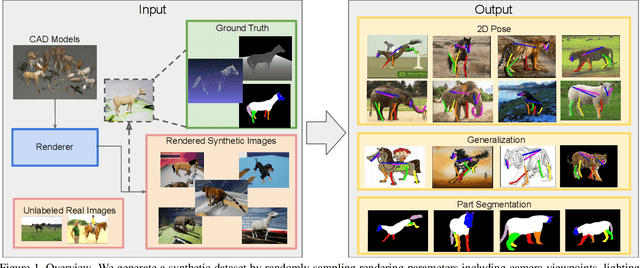
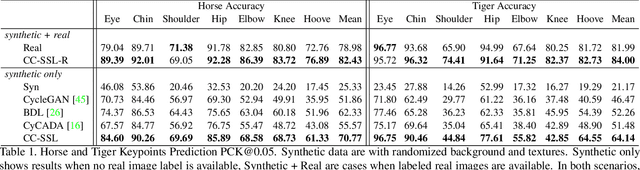
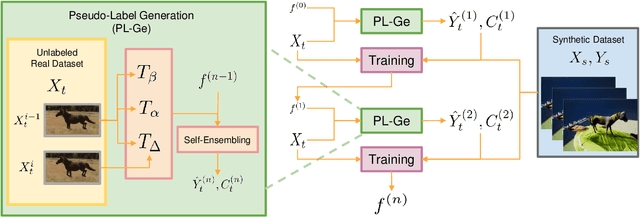

Despite great success in human parsing, progress for parsing other deformable articulated objects, like animals, is still limited by the lack of labeled data. In this paper, we use synthetic images and ground truth generated from CAD animal models to address this challenge. To bridge the gap between real and synthetic images, we propose a novel consistency-constrained semi-supervised learning method (CC-SSL). Our method leverages both spatial and temporal consistencies, to bootstrap weak models trained on synthetic data with unlabeled real images. We demonstrate the effectiveness of our method on highly deformable animals, such as horses and tigers. Without using any real image label, our method allows for accurate keypoints prediction on real images. Moreover, we quantitatively show that models using synthetic data achieve better generalization performance than models trained on real images across different domains in the Visual Domain Adaptation Challenge dataset. Our synthetic dataset contains 10+ animals with diverse poses and rich ground truth, which enables us to use the multi-task learning strategy to further boost models' performance.
A Deep Learning Approach for Robust Corridor Following
Nov 18, 2019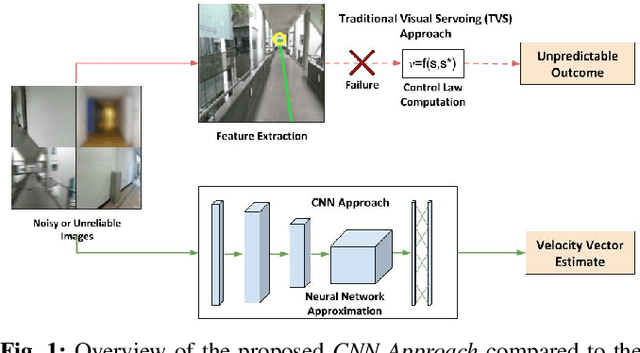
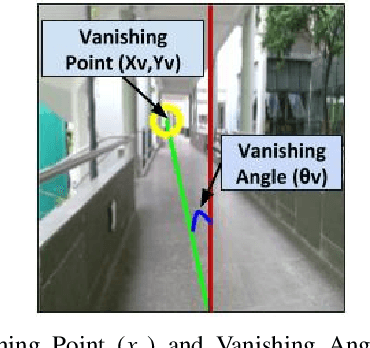

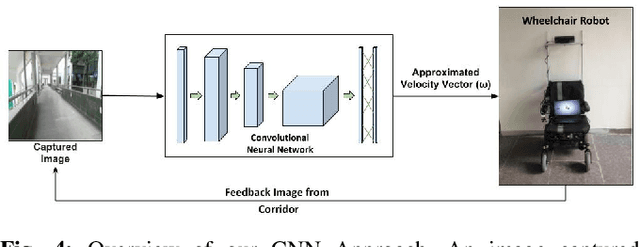
For an autonomous corridor following task where the environment is continuously changing, several forms of environmental noise prevent an automated feature extraction procedure from performing reliably. Moreover, in cases where pre-defined features are absent from the captured data, a well defined control signal for performing the servoing task fails to get produced. In order to overcome these drawbacks, we present in this work, using a convolutional neural network (CNN) to directly estimate the required control signal from an image, encompassing feature extraction and control law computation into one single end-to-end framework. In particular, we study the task of autonomous corridor following using a CNN and present clear advantages in cases where a traditional method used for performing the same task fails to give a reliable outcome. We evaluate the performance of our method on this task on a Wheelchair Platform developed at our institute for this purpose.
DeepHashing using TripletLoss
Dec 17, 2019


Hashing is one of the most efficient techniques for approximate nearest neighbour search for large scale image retrieval. Most of the techniques are based on hand-engineered features and do not give optimal results all the time. Deep Convolutional Neural Networks have proven to generate very effective representation of images that are used for various computer vision tasks and inspired by this there have been several Deep Hashing models like Wang et al. (2016) have been proposed. These models train on the triplet loss function which can be used to train models with superior representation capabilities. Taking the latest advancements in training using the triplet loss I propose new techniques that help the Deep Hash-ing models train more faster and efficiently. Experiment result1show that using the more efficient techniques for training on the triplet loss, we have obtained a 5%percent improvement in our model compared to the original work of Wang et al.(2016). Using a larger model and more training data we can drastically improve the performance using the techniques we propose
CG-GAN: An Interactive Evolutionary GAN-based Approach for Facial Composite Generation)
Nov 28, 2019

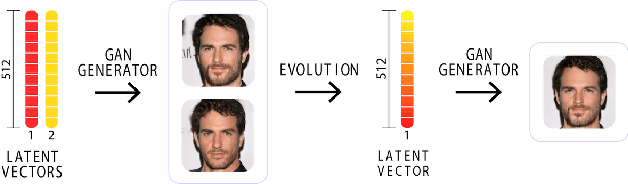
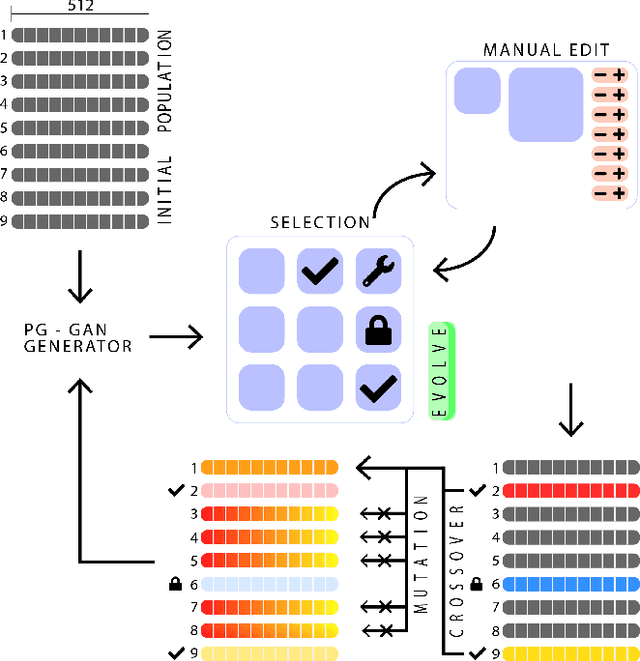
Facial composites are graphical representations of an eyewitness's memory of a face. Many digital systems are available for the creation of such composites but are either unable to reproduce features unless previously designed or do not allow holistic changes to the image. In this paper, we improve the efficiency of composite creation by removing the reliance on expert knowledge and letting the system learn to represent faces from examples. The novel approach, Composite Generating GAN (CG-GAN), applies generative and evolutionary computation to allow casual users to easily create facial composites. Specifically, CG-GAN utilizes the generator network of a pg-GAN to create high-resolution human faces. Users are provided with several functions to interactively breed and edit faces. CG-GAN offers a novel way of generating and handling static and animated photo-realistic facial composites, with the possibility of combining multiple representations of the same perpetrator, generated by different eyewitnesses.