 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LiveSketch: Query Perturbations for Guided Sketch-based Visual Search
Apr 14, 2019
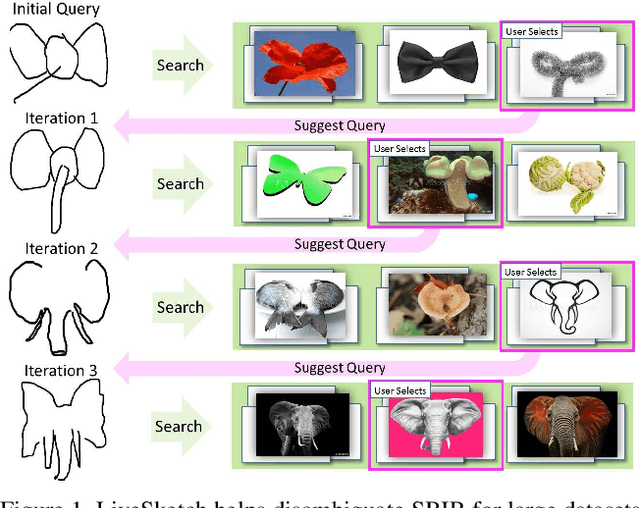

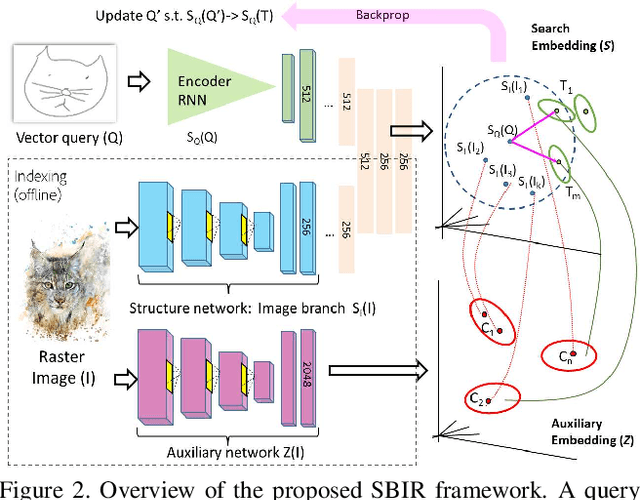
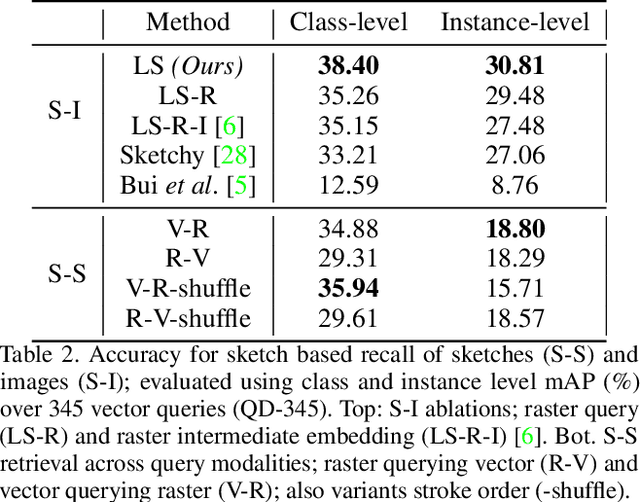
LiveSketch is a novel algorithm for searching large image collections using hand-sketched queries. LiveSketch tackles the inherent ambiguity of sketch search by creating visual suggestions that augment the query as it is drawn, making query specification an iterative rather than one-shot process that helps disambiguate users' search intent. Our technical contributions are: a triplet convnet architecture that incorporates an RNN based variational autoencoder to search for images using vector (stroke-based) queries; real-time clustering to identify likely search intents (and so, targets within the search embedding); and the use of backpropagation from those targets to perturb the input stroke sequence, so suggesting alterations to the query in order to guide the search. We show improvements in accuracy and time-to-task over contemporary baselines using a 67M image corpus.
Automated Pavement Crack Segmentation Using Fully Convolutional U-Net with a Pretrained ResNet-34 Encoder
Jan 21, 2020
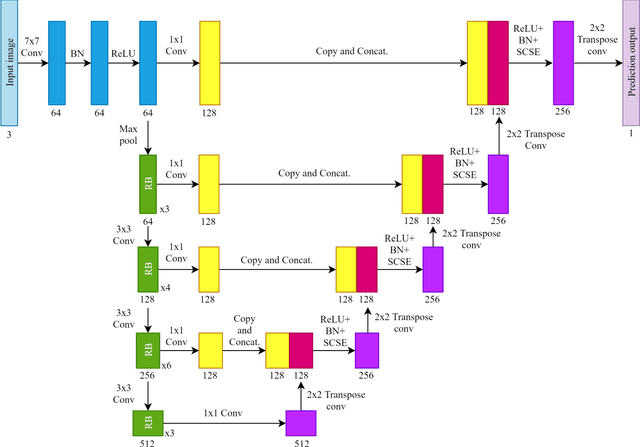
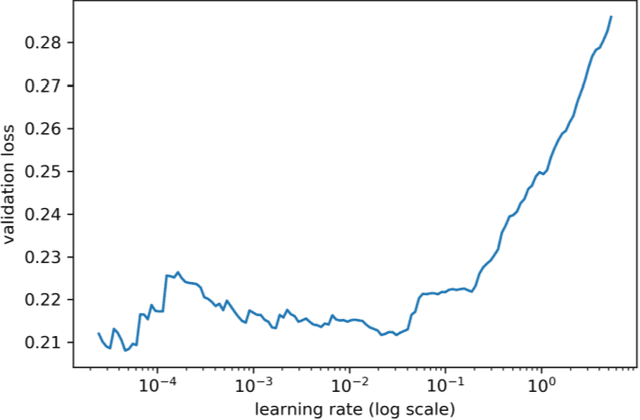
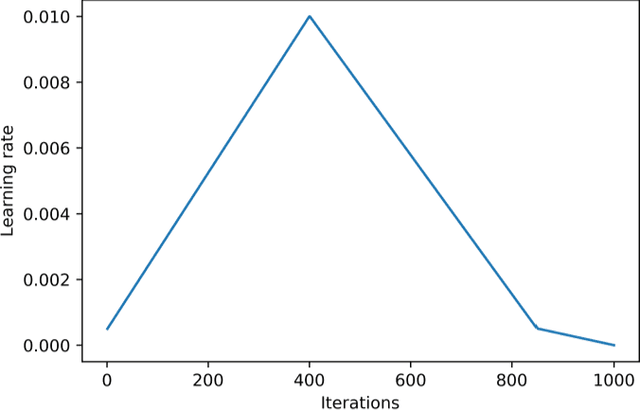
Automated pavement crack segmentation is a challenging task because of inherent irregular patterns and lighting conditions, in addition to the presence of noise in images. Conventional approaches require a substantial amount of feature engineering to differentiate crack regions from non-affected regions. In this paper, we propose a deep learning technique based on a convolutional neural network to perform segmentation tasks on pavement crack images. Our approach requires minimal feature engineering compared to other machine learning techniques. The proposed neural network architecture is a modified U-Net in which the encoder is replaced with a pretrained ResNet-34 network. To minimize the dice coefficient loss function, we optimize the parameters in the neural network by using an adaptive moment optimizer called AdamW. Additionally, we use a systematic method to find the optimum learning rate instead of doing parametric sweeps. We used a "one-cycle" training schedule based on cyclical learning rates to speed up the convergence. We evaluated the performance of our convolutional neural network on CFD, a pavement crack image dataset. Our method achieved an F1 score of about 96%. This is the best performance among all other algorithms tested on this dataset, outperforming the previous best method by a 1.7% margin.
The troublesome kernel: why deep learning for inverse problems is typically unstable
Jan 05, 2020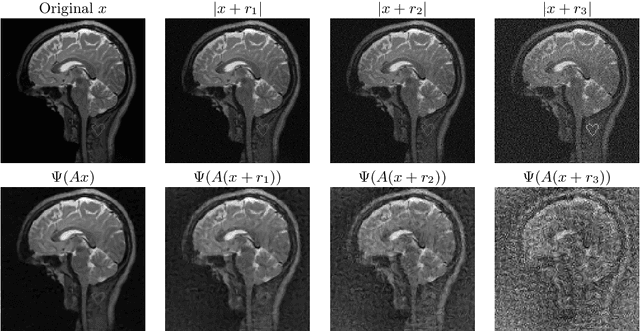

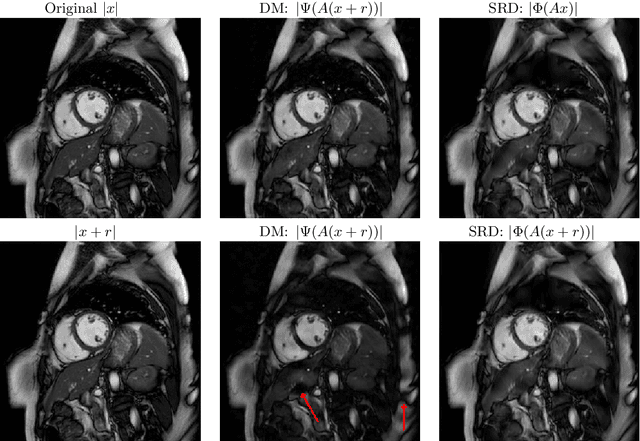
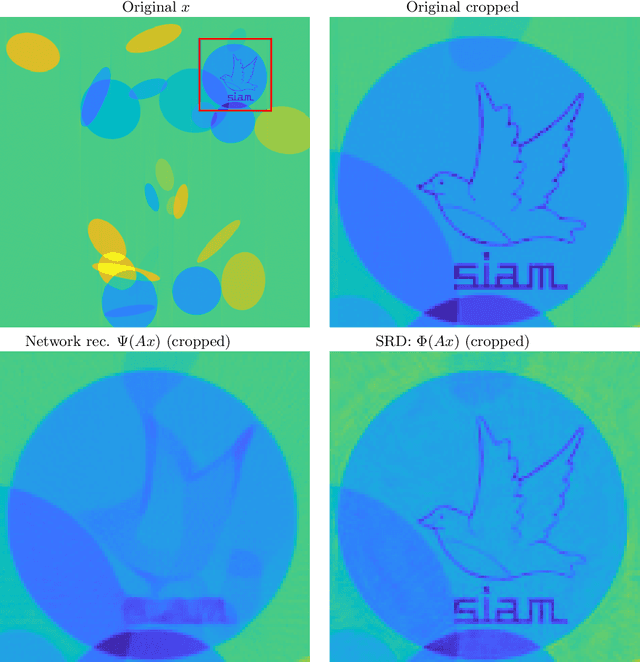
There is overwhelming empirical evidence that Deep Learning (DL) leads to unstable methods in applications ranging from image classification and computer vision to voice recognition and automated diagnosis in medicine. Recently, a similar instability phenomenon has been discovered when DL is used to solve certain problems in computational science, namely, inverse problems in imaging. In this paper we present a comprehensive mathematical analysis explaining the many facets of the instability phenomenon in DL for inverse problems. Our main results not only explain why this phenomenon occurs, they also shed light as to why finding a cure for instabilities is so difficult in practice. Additionally, these theorems show that instabilities are typically not rare events - rather, they can occur even when the measurements are subject to completely random noise - and consequently how easy it can be to destablise certain trained neural networks. We also examine the delicate balance between reconstruction performance and stability, and in particular, how DL methods may outperform state-of-the-art sparse regularization methods, but at the cost of instability. Finally, we demonstrate a counterintuitive phenomenon: training a neural network may generically not yield an optimal reconstruction method for an inverse problem.
U-Net: Convolutional Networks for Biomedical Image Segmentation
May 18, 2015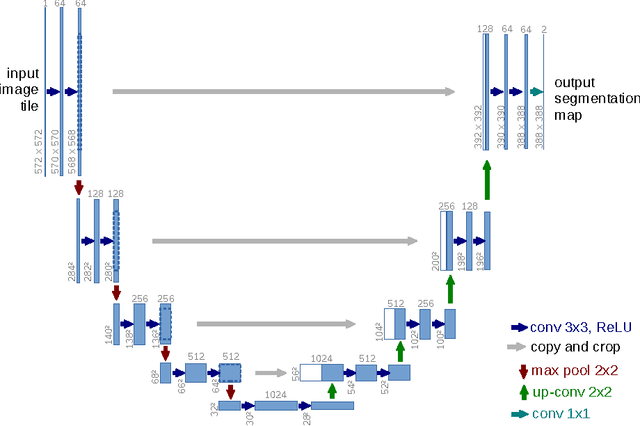
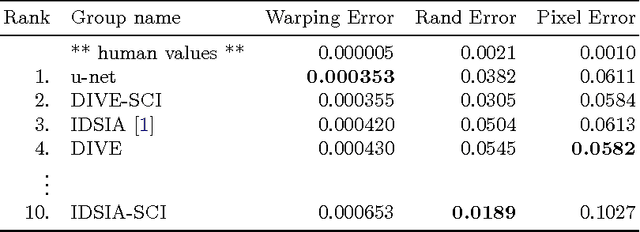
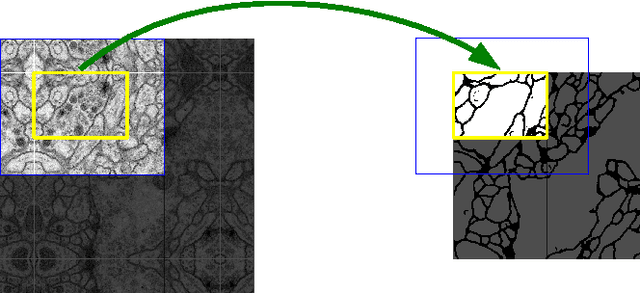

There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated samples more efficiently. The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method (a sliding-window convolutional network) on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks. Using the same network trained on transmitted light microscopy images (phase contrast and DIC) we won the ISBI cell tracking challenge 2015 in these categories by a large margin. Moreover, the network is fast. Segmentation of a 512x512 image takes less than a second on a recent GPU. The full implementation (based on Caffe) and the trained networks are available at http://lmb.informatik.uni-freiburg.de/people/ronneber/u-net .
Scalable Deep Neural Networks via Low-Rank Matrix Factorization
Oct 29, 2019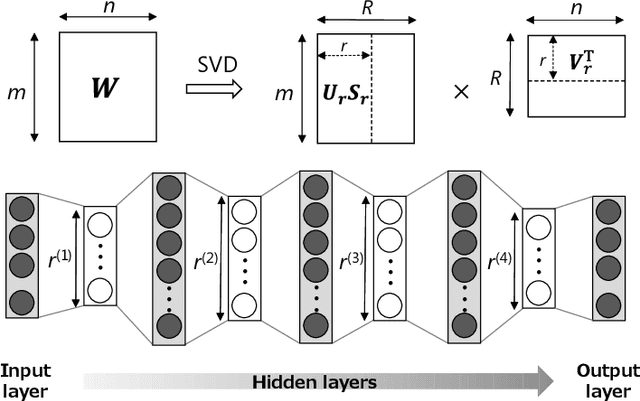

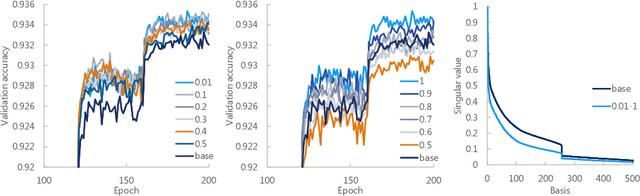
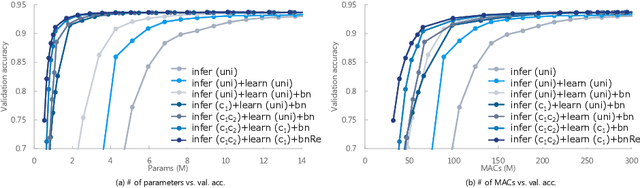
Compressing deep neural networks (DNNs) is important for real-world applications operating on resource-constrained devices. However, it is difficult to change the model size once the training is completed, which needs re-training to configure models suitable for different devices. In this paper, we propose a novel method that enables DNNs to flexibly change their size after training. We factorize the weight matrices of the DNNs via singular value decomposition (SVD) and change their ranks according to the target size. In contrast with existing methods, we introduce simple criteria that characterize the importance of each basis and layer, which enables to effectively compress the error and complexity of models as little as possible. In experiments on multiple image-classification tasks, our method exhibits favorable performance compared with other methods.
Adversarial Learning of General Transformations for Data Augmentation
Sep 21, 2019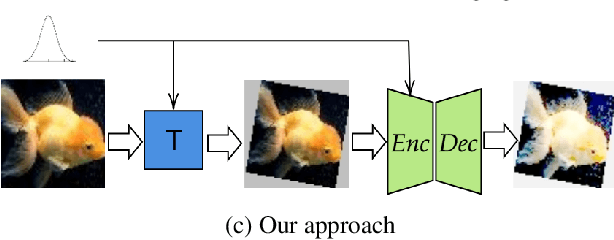
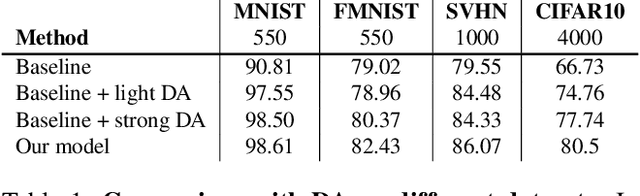
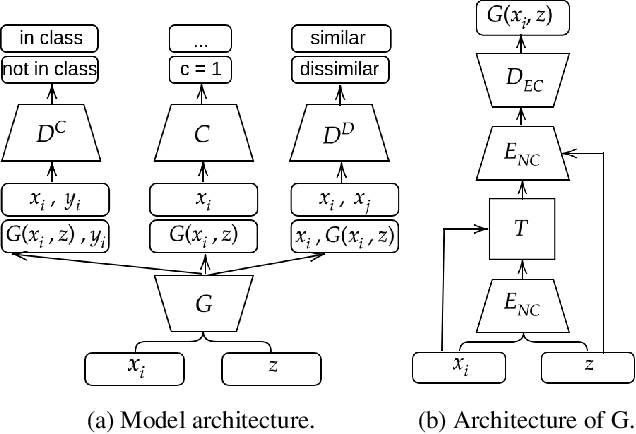
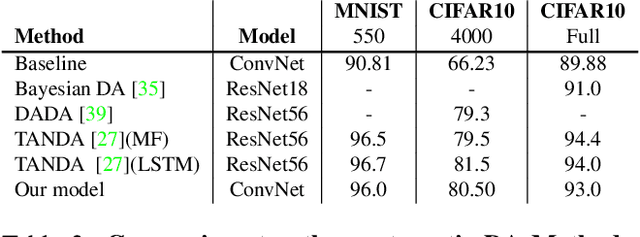
Data augmentation (DA) is fundamental against overfitting in large convolutional neural networks, especially with a limited training dataset. In images, DA is usually based on heuristic transformations, like geometric or color transformations. Instead of using predefined transformations, our work learns data augmentation directly from the training data by learning to transform images with an encoder-decoder architecture combined with a spatial transformer network. The transformed images still belong to the same class but are new, more complex samples for the classifier. Our experiments show that our approach is better than previous generative data augmentation methods, and comparable to predefined transformation methods when training an image classifier.
Facial Expression Representation Learning by Synthesizing Expression Images
Nov 30, 2019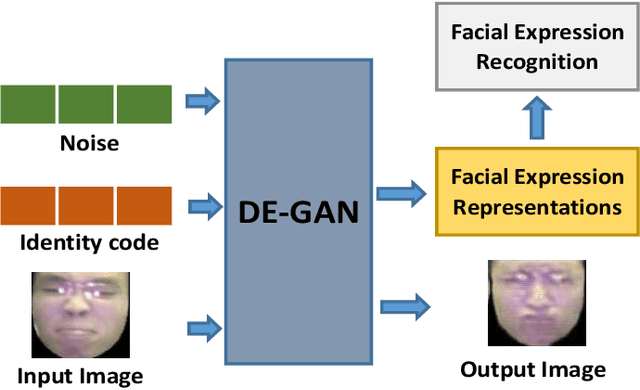
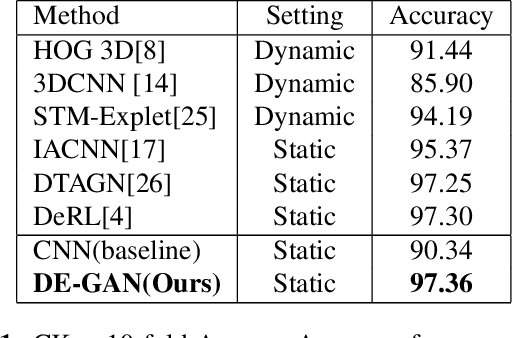
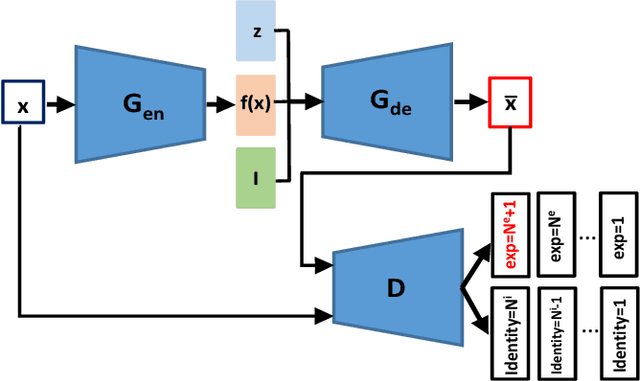
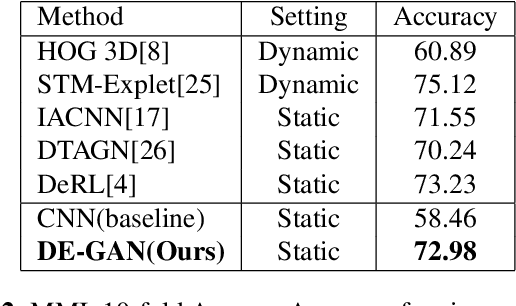
Representations used for Facial Expression Recognition (FER) usually contain expression information along with identity features. In this paper, we propose a novel Disentangled Expression learning-Generative Adversarial Network (DE-GAN) which combines the concept of disentangled representation learning with residue learning to explicitly disentangle facial expression representation from identity information. In this method the facial expression representation is learned by reconstructing an expression image employing an encoder-decoder based generator. Unlike previous works using only expression residual learning for facial expression recognition, our method learns the disentangled expression representation along with the expressive component recorded by the encoder of DE-GAN. In order to improve the quality of synthesized expression images and the effectiveness of the learned disentangled expression representation, expression and identity classification is performed by the discriminator of DE-GAN. Experiments performed on widely used datasets (CK+, MMI, Oulu-CASIA) show that the proposed technique produces comparable or better results than state-of-the-art methods.
Design and Interpretation of Universal Adversarial Patches in Face Detection
Nov 30, 2019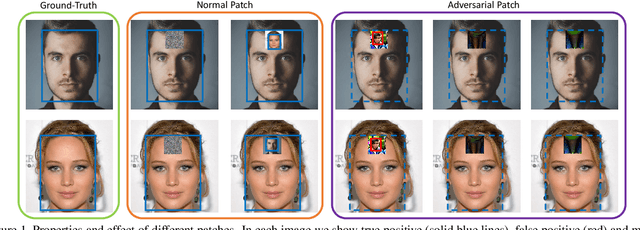
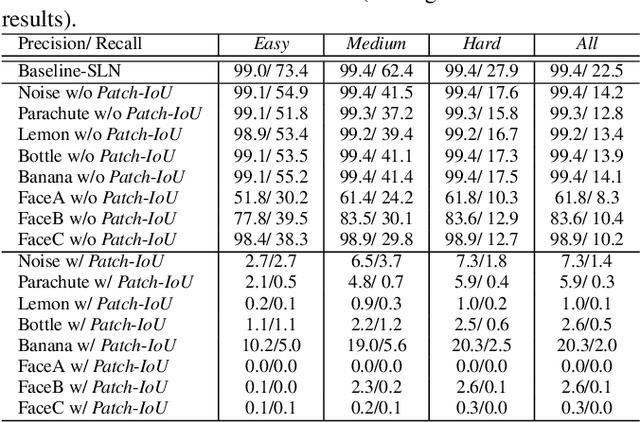

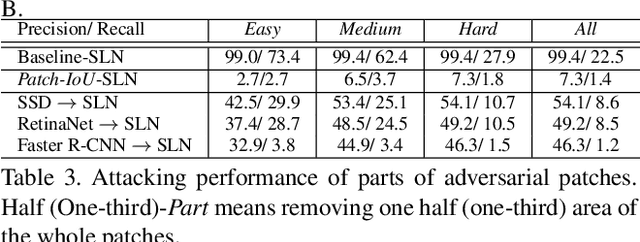
We consider universal adversarial patches for faces - small visual elements whose addition to a face image reliably destroys the performance of face detectors. Unlike previous work that mostly focused on the algorithmic design of adversarial examples in terms of improving the success rate as an attacker, in this work we show an interpretation of such patches that can prevent the state-of-the-art face detectors from detecting the real faces. We investigate a phenomenon: patches designed to suppress real face detection appear face-like. This phenomenon holds generally across different initialization, locations, scales of patches, backbones, and state-of-the-art face detection frameworks. We propose new optimization-based approaches to automatic design of universal adversarial patches for varying goals of the attack, including scenarios in which true positives are suppressed without introducing false positives. Our proposed algorithms perform well on real-world datasets, deceiving state-of-the-art face detectors in terms of multiple precision/recall metrics and transferring between different detection frameworks.
Location Augmentation for CNN
Oct 14, 2018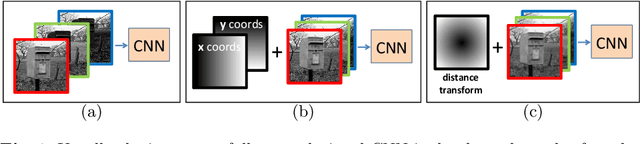
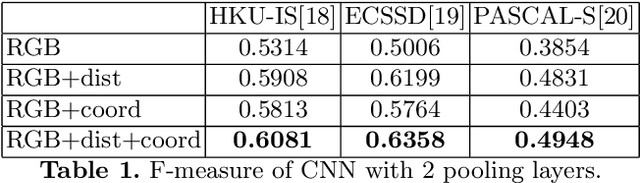
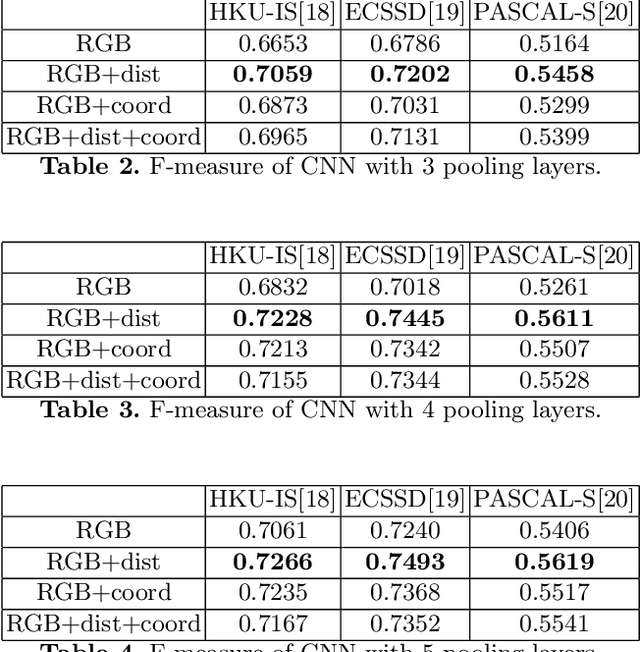
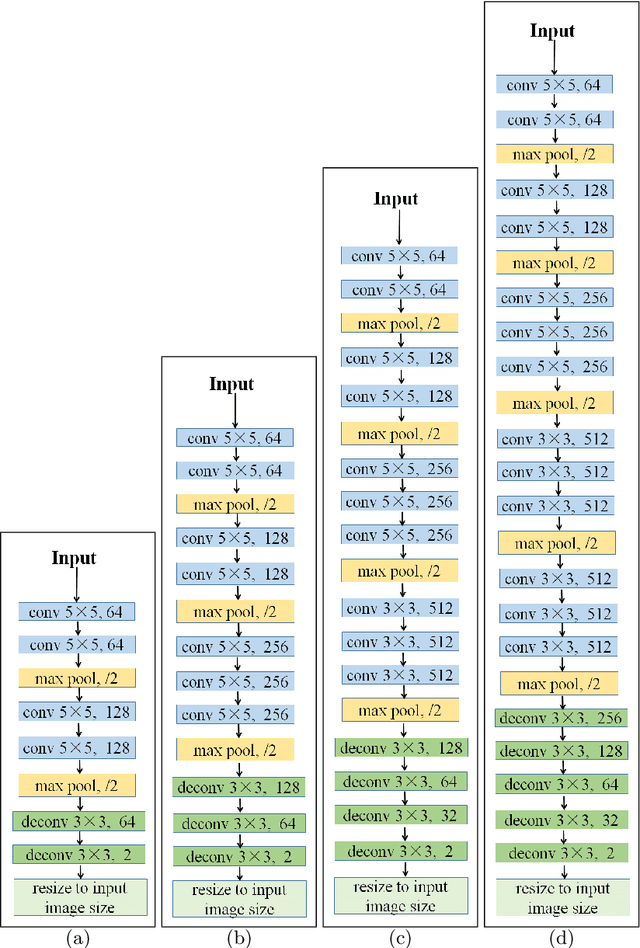
CNNs have made a tremendous impact on the field of computer vision in the last several years. The main component of any CNN architecture is the convolution operation, which is translation invariant by design. However, location in itself can be an important cue. For example, a salient object is more likely to be closer to the center of the image, the sky in the top part of an image, etc. To include the location cue for feature learning, we propose to augment the color image, the usual input to CNNs, with one or more channels that carry location information. We test two approaches for adding location information. In the first approach, we incorporate location directly, by including the row and column indexes as two additional channels to the input image. In the second approach, we add location less directly by adding distance transform from the center pixel as an additional channel to the input image. We perform experiments with both direct and indirect ways to encode location. We show the advantage of augmenting the standard color input with location related channels on the tasks of salient object segmentation, semantic segmentation, and scene parsing.
Estimating localized complexity of white-matter wiring with GANs
Oct 02, 2019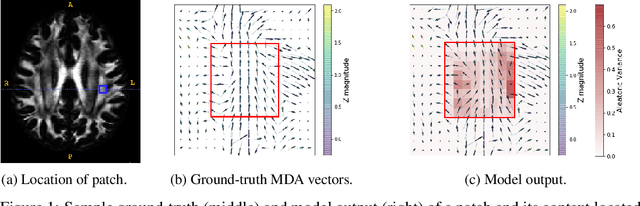
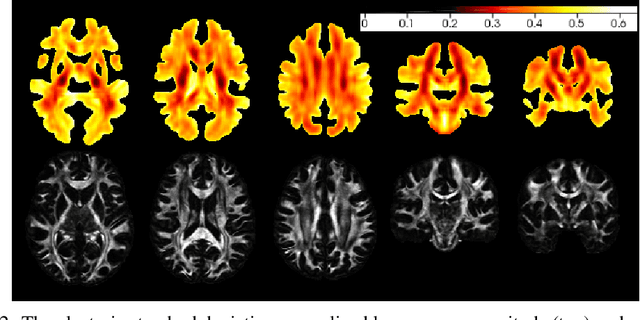
In-vivo examination of the physical connectivity of axonal projections through the white matter of the human brain is made possible by diffusion weighted magnetic resonance imaging (dMRI) Analysis of dMRI commonly considers derived scalar metrics such as fractional anisotrophy as proxies for "white matter integrity," and differences of such measures have been observed as significantly correlating with various neurological diagnosis and clinical measures such as executive function, presence of multiple sclerosis, and genetic similarity. The analysis of such voxel measures is confounded in areas of more complicated fiber wiring due to crossing, kissing, and dispersing fibers. Recently, Volz et al. introduced a simple probabilistic measure of the count of distinct fiber populations within a voxel, which was shown to reduce variance in group comparisons. We propose a complementary measure that considers the complexity of a voxel in context of its local region, with an aim to quantify the localized wiring complexity of every part of white matter. This allows, for example, identification of particularly ambiguous regions of the brain for tractographic approaches of modeling global wiring connectivity. Our method builds on recent advances in image inpainting, in which the task is to plausibly fill in a missing region of an image. Our proposed method builds on a Bayesian estimate of heteroscedastic aleatoric uncertainty of a region of white matter by inpainting it from its context. We define the localized wiring complexity of white matter as how accurately and confidently a well-trained model can predict the missing patch. In our results, we observe low aleatoric uncertainty along major neuronal pathways which increases at junctions and towards cortex boundaries. This directly quantifies the difficulty of lesion inpainting of dMRI images at all parts of white matter.